Study aim, design and setting
We sought to evaluate the longitudinal predictive performance of T2D PGS for incident T2D by creating simulated scenarios that varied in depth of clinical data availability at the time of each patient’s initial clinical encounter in the MGH PCP network. We extracted two decades of clinical data for 284,602 patients who had received primary care through the network from an EHR repository including outpatient, emergency department, and inpatient visits. Patients were eligible to be in the study cohort if they had at least two clinical encounters between January 1, 2000, and December 31, 2020, and available genetic data through the MGB Biobank (N = 15,355). The MGB Biobank is a large biorepository with genetic data for over 50K participants aged 18 years or older who had been recruited from affiliated hospitals, clinics, or cohorts or provided electronic informed consent [16]. After excluding patients with a T2D diagnosis before or within 6 months of their first encounter, 14,712 patients remained for downstream analysis. The MGB institutional review board approved the study.
Clinical characteristics of participants
Sociodemographic variables included baseline age, self-reported race/ethnicity, educational attainment, and gender. Baseline clinical diagnoses for coronary heart failure, peripheral vascular disease, proteinuria, and hypertension (HTN) were defined with ICD-10 code-based algorithms between January 1, 2000, and up to 6 months after the initial encounter. T2D [17], coronary artery disease (CAD), and chronic kidney disease (CKD) duration at baseline was calculated from the diagnosis date to the date of the initial encounter. Mean lab values were extracted between 18 months before the initial encounter and 6 months after the initial encounter. For BMI, we used any available BMI measured during the follow-up period as repeated measurements exhibited low variability (median standard deviation of BMI: 0.95) and very few BMI measurements were available in that two-year window.
Calculation of T2D CRS
We implemented the Framingham T2D CRS, comprising age, sex, parental history of T2D, BMI, systolic blood pressure (SBP), high-density lipoprotein (HDL), total cholesterol, triglyceride, fasting glucose, and waist circumference [15]. We used family history as a proxy for parental history. As waist circumference and fasting status for glucose were not available, both variables were set as constants in the CRS, and random glucose was included as an independent variable. The CRS was then log-transformed to be normally distributed, and standardized. The full CRS implemented can be found in the Supplementary Methods (Additional file 1).
Outcome
The start of observation time was January 1, 2000, or 6 months after the first clinical encounter if it occurred after January 1, 2000. Incidence of T2D was defined with ICD-10 code-based algorithms (Additional file 2: Table S1) during the observation time and right-censored at initial disease occurrence or the last clinical encounter before December 15, 2021.
Genotyping data preparation
Genotypes were measured using either the Illumina Multi-Ethnic Genotyping Array (MEGA) or the Illumina Global Screening Array (GSA). We accessed MEGA genotyping data for 36K participants and GSA genotyping data for 18K participants from the MGB Biobank then processed by batch. Briefly, the quality control steps included filtering out variants based on minor allele frequency (MAF) levels (< 5%), missingness (> 0.05), genotyping batch bias (P < 5 × 10−5), and Hardy-Weinberg equilibrium (P < 1 × 10−10) and palindromic single nucleotide variants (AT or CG). Individuals were also removed if their self-reported sex did not match their genetic sex or if they had a high ratio of heterozygote variants. These clean datasets were phased using Shapeit4, imputed using the TOPMed r2 reference panel, then union merged. Quality control, phasing, and imputation steps were not stratified by self-reported race subgroups except for variant filtering based on Hardy-Weinberg equilibrium and participant filtering based on heterozygosity.
To calculate Principal Components (PCs) and genetic ancestry probabilities for individuals in MGB Biobank, we first created an intersection of common (MAF > 5%, genotyping rate > 0.95%), independent (R2 < 0.1) variants from both the HGDP/1000G dataset and MGB Biobank. Next, PCs were calculated among the HGDP/1000G dataset and MGB Biobank was projected into this PC space. Genetic ancestry probabilities were calculated using a random forest classification model, trained on PCs and continental ancestry data from HGDP/1000G and applied to MGB Biobank. In our analysis, we assigned an individual to a continental ancestry if that genetic ancestry probability was > 0.5.
Calculation of T2D PGS
We selected large GWAS meta-analyses for our traits of interest of which full summary statistics were available for the calculation of PGS. For T2D we meta-analyzed the published MVP/DIAMANTE meta-analyses results with T2D GWAS from the FINNGEN Biobank r6 [18, 19]. Genome-wide PGS were calculated using PRScs with the provided EUR 1000G HapMap3 LD reference files [20]. Posterior weights from PRScs were used to calculate the PGS in the MGB biobank with the PLINK --score function. To account for PGS variability in our multi-ancestry cohort, we implemented a modified PGS adjustment strategy based on previously published methods [10, 21]. Briefly, we fitted a linear model of each disease-specific PGS against genetic ancestry probabilities. Adjusted PGS were calculated as the residual between the predicted and actual PGS in the entire dataset.
Primary statistical analyses
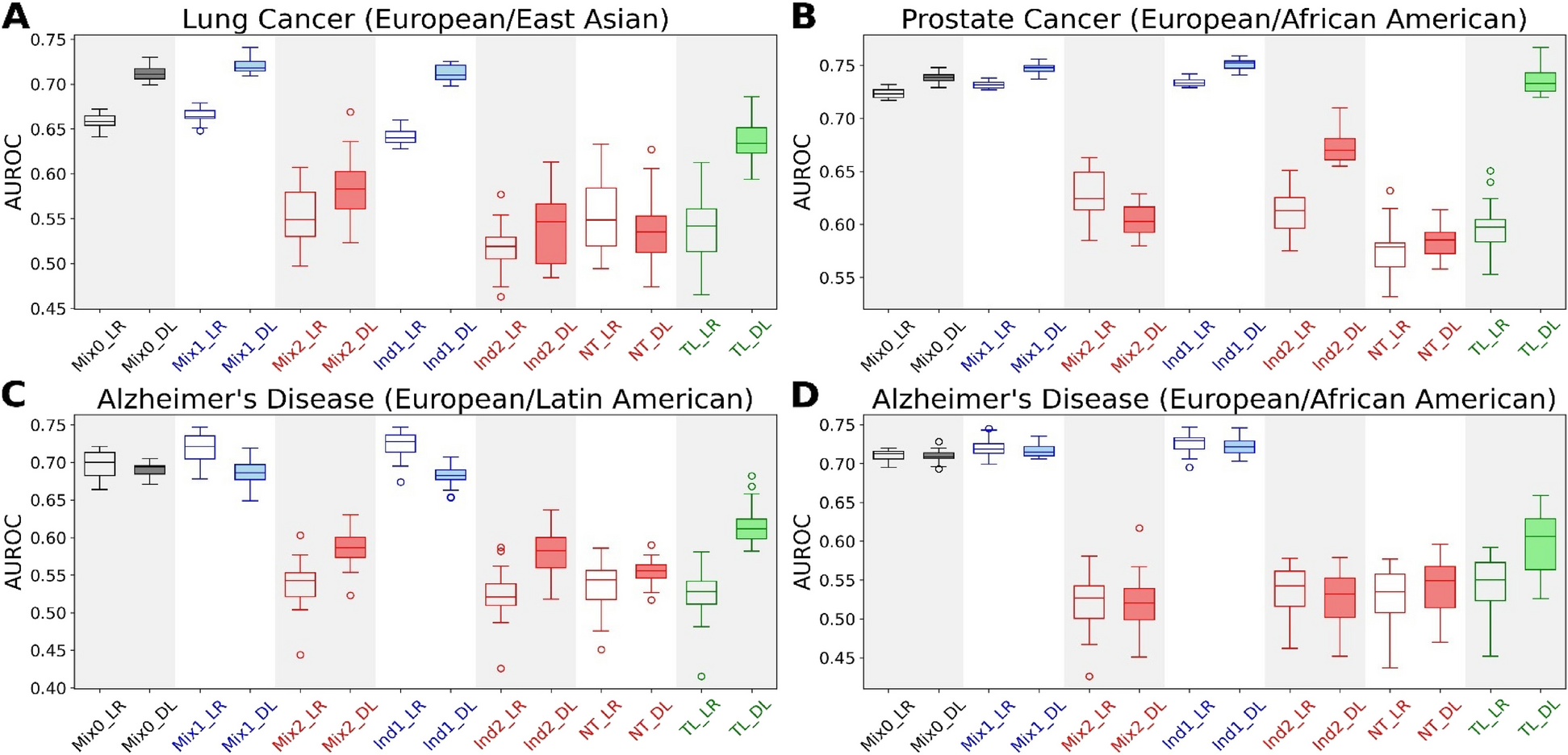
We tested the association of PGS with T2D incidence in Cox models adjusted for the available clinical variables in each scenario, including all participants in the primary analysis regardless of ancestry, and corrected for 10 PCs in all models to account for population stratification. As a sensitivity analysis, we converted the PGS into a categorical variable to compare individuals of high genetic risk based on a percentile cutoff to those of average genetic risk based on the interquartile range (IQR) within each scenario. We explored three different high-risk cutoffs: 5%, a less stringent 10%, and a more stringent 2% which has been suggested for T2D [22]. For purposes of model comparison, we chose 5% as the primary analysis due to being a middle ground between high genetic risk and sample size drop offs when selecting a cutoff value. Kaplan-Meier curves and Cox models were generated using the lifelines package in Python [23]. The estimated probability of incident T2D was calculated as the predicted probability of developing T2D during the follow-up time. Logistic regression models were fit with T2D developed during the follow-up as the response variable and all available clinical risk factors of a specific scenario, the T2D PGS, and the first 10 PCs as predictor variables. These were the same predictor variables used in the combined clinical and PGS Cox models. Models were trained then applied on all participants within a scenario. Tertiles of PGS were defined among participants within each scenario.
We calculated the change in model performance using the c-index [24] upon adding PGS to several clinical base models: scenario 1 age and sex; scenario 2 age, sex, family history of T2D, BMI, and systolic blood pressure (SBP); scenario 3 age, sex, family history of T2D, BMI, SBP, and random glucose; scenario 4 age, sex, family history of T2D, BMI, SBP, HDL, total cholesterol, and triglycerides combined into a clinical risk score (CRS) and random glucose as an independent variable. We evaluated the performance of the full CRS in our models using the pre-computed, published weights for each individual variable from the Framingham T2D CRS [15]. Full formulas for the cox models used in each scenario can be found in the Supplementary Methods (Additional file 1).
In a sensitivity analysis, we created separate models built on individual variables without using pre-computed CRS weights in our complete cases. In another sensitivity analysis, we imputed missing lab values (max of 8% total missing) for individuals missing only one lab (HDL, cholesterol, triglycerides, or glucose) using multivariate feature imputation, imputing missing values using predictions modelled on all available clinical risk factors.
For scenario 2, scenario 3, and the imputation sensitivity analysis in scenario 4, BMI values were log-transformed to be normally distributed. Outlying BMI values, defined as those with a log BMI value more than 4 standard deviations away from the mean log BMI value, were also removed. For scenario 3 and all scenario 4 analyses, glucose was double log-transformed to be normally distributed. For scenario 3 and the imputation sensitivity analysis in scenario 4, triglycerides were log-transformed.
Stratified statistical analyses
For each scenario, we tested for significant statistical interaction between the PGS and the clinical variable available in each scenario that was most associated with T2D, adjusting for all available variables per scenario. We then stratified our analyses by the clinical variable available in each scenario that was most associated with T2D. For scenario 1, we tested for an interaction between PGS and a binary age cutoff, and stratified by the recommended age cutoff from the ADA and CDC to commence screening for T2D at routine health examinations [25, 26], 40 years. For scenario 2, we tested for an interaction between PGS and log-transformed BMI and stratified by the median BMI of our dataset (27.5 kg/m2). For scenario 3, we tested for an interaction between PGS and double log-transformed random glucose and stratified by a random glucose cutoff of 100 mg/dL (threshold for impaired fasting glucose, presuming blood tests were drawn fasting). For scenario 4, we tested for an interaction between PGS and log-transformed CRS and stratified by the median CRS value.
PGS prediction of CKD and CAD as T2D-related complications
As CKD and CAD are two leading causes of death in people with T2D [27, 28], we tested whether PGS can improve prediction of incident CAD and CKD over CRS. For CKD we used the SCORED CRS, which required age, sex, and diagnoses of anemia, HTN, T2D, CHD, congestive heart failure, peripheral vascular disease, and proteinuria diagnoses [29]. The equation used to calculate the CKD CRS can be found in the Supplementary Methods (Additional file 1). For CAD we used the Framingham CAD CRS, which required age, sex, smoking, total cholesterol, HDL measurements, SBP, and HTN treatment [30]. We used HTN diagnosis as a substitute for HTN treatment. The equation used to calculate the CAD CRS can be found in the Supplementary Methods (Additional file 1).
We considered two scenarios for these analyses: (1) a clinical visit without labs and (2) a clinical visit with labs. For CAD, the clinical variables in each scenario were (1) age, sex, smoking status, and SBP and (2) age, sex, smoking status, SBP, HDL, and total cholesterol combined into a CRS. The Cox model formulas used for CAD incidence can be found in the Supplementary Methods (Additional file 1). For CKD, the clinical variables per model (1) age, sex, diagnosis history, SBP, diastolic blood pressure (DBP), weight, and HTN, and (2) the risk factors from (1) and anemia status determined by hemoglobin count combined into a CRS. The Cox model formulas used for CKD incidence can be found in the Supplementary Methods (Additional file 1).
Using the PRScs method, we constructed CKD and CAD PGS with the summary statistics from the CKD Gen Consortium [31], and Nelson et al. of UK Biobank SOFT CAD GWAS with CARDIoGRAMplusC4D 1000 Genomes-based GWAS and the Myocardial Infarction Genetics and CARDIoGRAM [32]. We then generated incidence models using the pertinent clinical variables from their respective CRS available by T2D status.

留言 (0)