Social [e.g., education] and behavioral [e.g., smoking] determinants of health (hereafter SDoH for simplicity) are increasingly recognized as important factors affecting a wide range of health, functional, and quality of life outcomes, as well as healthcare fairness and disparities. For example, up to 75 % of cancer occurrences are associated with SDoH, [1] which affect individual cancer risks and influence the likelihood of survival, early prevention, and health equity. [2], [3], [4] SDoH are associated with the frequency of opioid use and are important factors in preventing opioid misuse. [5], [6], [7] Various national and international organizations, such as the World Health Organization (WHO) [8], Healthy People 2030 [9], American Hospital Association (AHA) [10], National Institutes of Health (NIH), and Centers for Disease Control and Prevention (CDC) [11] have unanimously highlighted the importance of SDoH to people’s health. There is an increasing interest in studying the role of SDoH in health outcomes and healthcare disparities, yet SDoH are not well-documented in electronic health records (EHRs). In February 2018, the International Classification of Diseases, Tenth Revision, Clinical Modification (ICD-10-CM) Official Guidelines for Coding and Reporting approved that healthcare providers involved in the care of a patient can document SDOH using Z codes (Z55–Z65); however, current reporting of SDoH using ICD-10-CM Z codes is relatively low (2.03 % at patient-level) [12] and most individual-level SDoH are only documented in clinical narratives. [13] Natural language processing (NLP) systems that extract comprehensive SDoH information from clinical narratives are needed.
SDoH are often referred to as factors related to the conditions and status where people are born, live, and work, and are distinct from medical determinants of health (MDoH, e.g., diseases, medical procedures) from healthcare. [9] The definition of SDoH varies across different organizations. Still, common SDoH categories usually include economic stability, education access and quality, social and community context, neighborhood and built environment, and healthcare access and quality. [9] There is growing evidence on the significant association of SDoH with healthcare outcomes such as mortality [14], morbidity [15], mental health status [16], functional limitations [17], and substance use including opioid crisis [7]. For example, Galea et al. [18] estimated the number of cancer deaths attributable to SDoH in the United States and reported that low education, racial segregation, low social support, poverty, and income inequality attributed to cancer deaths were comparable to pathophysiological and behavioral causes. Albright et al. [5] identified education, housing stability, and employment status significantly associated with the frequency of opioid abuse.[5], [6] Cantu et al. [7] examined three counties with opioid misuse in Ohio and identified social and economic instability such as unemployment, criminalization of substance use, limited access to healthcare, poverty, and social isolation among the root causes. As SDoH are not well-documented in structured EHRs, many studies [8], [19], [20] have explored SDoH collected using surveys.
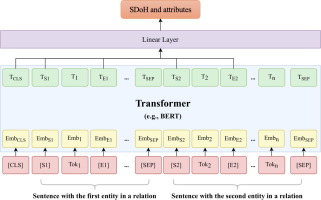
Extracting SDoH from clinical narratives is a typical task of clinical concept extraction or named entity recognition (NER), which identifies phrases of interest (represented using the beginning position and ending position in the text) and determines their semantic categories (e.g., homelessness, smoking). While SDoH were more frequently captured in clinical narratives than structured codes, they were captured only in a subset of notes. Therefore, researchers typically identify the subset of notes with SDoH mentions using note types or key words, to facilitate the developing of corpora. Previous studies [13] have applied NLP methods to extract a single SDoH category from clinical narratives such as homelessness and housing insecurity [21], [22], employment status [23], suicide detection [24], marital status [25], and substance use [26], [27]. Rule-based and traditional machine learning models have been applied. Recent studies developed corpora with multiple common SDoH categories and applied deep learning-based NLP models. Yetisgen et al. [28] developed a corpus of 13 SDoH categories using notes from the publicly available MTSample dataset; Lybarger et al. [29] developed a corpus of 12 SDoH using clinical notes from the University of Washington and applied deep learning models including bidirectional long short-term memory (bi-LSTM) and BERT; Feller et al. [30] developed a corpus of 5 SDoH categories using notes from Columbia University Medical Center and applied traditional machine learning models; Stemerman et al. [16] developed a corpus of 6 SDoH categories and applied the BI-LSTM model; Gehrmann et al. [31] and Han et al. [32] explored SDoH using clinical notes from the Medical Information Mart for Intensive Care III (MIMIC-III) dataset; Feller et al. [33] developed a corpus of 6 SDOH categories using notes from Columbia University Irving Medical Center. We also have developed an SDoH corpus and transformer-based NLP methods [34], examined the extraction ratio for a lung cancer cohort [35], and identified potential disparity for treatment options in a type 2 diabetes cohort [36]. As SDoH is not routinely collected in EHRs, previous studies used “key words” or “section names” to identify the notes or sections potentially with mentions of SDoH for annotation. For example, Gundlapalli et al. [21] used key words “homeless” to identify notes related with homeless; Feller et al. [30] used distributional semantic distance to identify sections contains SDoH; the n2c2 NLP challenge [37] identified social history sections for development of corpora.
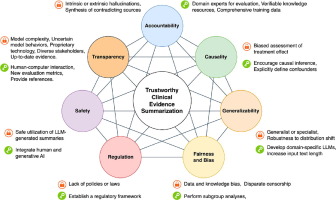
Most recent studies for SDoH often applied deep learning models [38]. The 2022 n2c2 organized an NLP challenge focusing on SDoH, which greatly improved the adoption of transformer-based large language models (LLMs)[37]. Recent studies have explored transformer architectures such as BERT and RoBERTa [39], [40]. Most NLP methods for SDoH were developed without a disease domain, yet researchers must apply these methods to a disease-specific cohort to study the role of SDoH in EHR-based retrospective cohorts. It is unclear how well current NLP systems can be used to extract SDoH for retrospective patient cohorts and across different disease domains. Until now, there is no off-the-shelf NLP package to facilitate the use of SDoH for EHR-based studies. It is important to develop not only accurate but fair and inclusive NLP methods to prevent potential disparities caused by medical AI systems. The research community has become increasingly aware of potential bias of LLM-based NLP methods for healthcare. Recent studies have discovered the potential bias of LLMs and NLP for healthcare. [41], [42] For example, a study reported an NLP method to detect Opioid misuse had systematic bias in false negative rate (32 %) for the Black population compared to the White population (17 %). [43] Yet, there is no study to examine the bias in extracting SDoH for different race and gender groups.
The goals of this study were (1) to develop an SDoH corpus and an open-source NLP package, SODA (i.e., SOcial DeterminAnts), with pre-trained state-of-the-art transformer models for SDoH extraction from clinical narratives, (2) examine potential bias of SODA for different race and gender groups and test the generalizability of SDoH extraction across two disease domains including cancer and opioid use, and (3) examine extraction rates for various SDoH categories in 3 cancer-specific (breast, lung, colorectal) cohorts, and variations of extraction rates among race and gender groups. We developed a SDoH corpus using clinical notes of cancer and a smaller cross-disease validation corpus using opioid use patients identified at the University of Florida (UF) Health and compared transformer models including Bidirectional Encoder Representations from Transformers (BERT) [44] and RoBERTa [45], DeBERTa [46], Longformer [47], and GatorTron [48]. Then, we explored strategies to customize the cancer-specific NLP model to an opioid user cohort. We integrated SODA with pre-trained clinical models into an open-source software package.





留言 (0)