Evidence-based Medicine (EBM) aims to improve healthcare decisions by integrating the best available evidence, clinical proficiency, and patient values. One widely utilized method for generating optimally accessible evidence is the systematic review of Randomized Controlled Trials (RCT). This involves identifying, appraising, and synthesizing evidence from relevant studies addressing a clinical question. In addition, in the current era of big data, there is a growing recognition of the need to broaden our focus beyond RCTs and embrace diverse evidence sources. For example, Real World Data (RWD), such as electronic health records, insurance billing databases, and disease registries [1], generates vital Real World Evidence. It offers unique and current insights into treatment effectiveness in broader patient populations, as well as long-term effects and rare side effects, often overlooked in RCTs [2], [3]. Given the sheer volume of RCTs, RWD, and other data sources, there is a critical need to summarize the evidence into a more digestible and comprehensive format to facilitate the accessibility and applicability of the findings.
Clinical evidence summarization can be defined as the act of collecting, extracting, appraising, and synthesizing relevant and reliable evidence to answer a specific clinical question. However, due to the rapid growth of the biomedical literature and clinical data, clinical evidence summarization is struggling to keep up. In the meantime, the proliferation of misinformation or biased/incomprehensive summaries resulting from unreliable or contradicting evidence erodes the public’s trust in biomedical research [4], [5]. Given such concerns, we need to develop new and trustworthy methods to reform systematic reviews.
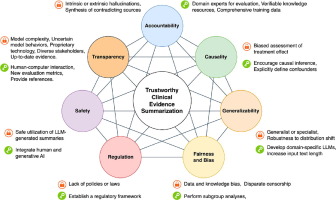
In recent years, dramatic advances in Generative AI, particularly Large Language Models (LLMs), have demonstrated a remarkable potential for assisting in systematic reviews [6]. Recently, LLMs have been explored to summarize meta-analyses [7] and clinical trials [8], [9]. Before the era of LLMs, AI methods were also deployed to extract evidential information [10], [11], [12], [13], [14], [15] and retrieve publications on a given topic [16], [17], [18]. However, achieving trustworthy AI for clinical evidence summarization remains a complex undertaking. In this perspective, we discuss the trustworthiness of generative AI and the associated challenges and recommendations in the context of fully and semi-automated medical evidence summarization (Fig. 1).





留言 (0)