From a pharmacokinetics (PK) perspective, drug-drug interactions (DDIs) happen when one drug (the “perpetrator”) modifies the absorption, distribution, metabolism, and/or excretion (ADME) of another drug (the “victim”) [1], [2]. These interactions are the main focus of the guidelines provided by the US Food and Drug Administration (FDA) regarding DDIs [3], [4]. These guidelines recommend comprehensive methods for the scientific evaluation of DDI potential, including the criteria to decide when clinical DDI studies are necessary during pharmaceutical product development. Consequently, PK DDI mechanisms are thoroughly explored in the drug development phase. However, conducting clinical DDI studies during the drug development phase remains a significant challenge in assessing DDI risks, notably for serious adverse drug reactions (SADRs), which are critical to investigate yet difficult to detect and assess. This difficulty arises from the limited effectiveness of clinical trials, which may be due to the relatively small number of participants, a biased patient population compared to general patients in clinical practice due to inclusion/exclusion criterion in clinical trials, and the high cost and time-consuming nature of conducting these studies [5].
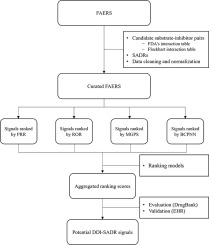
This gap between mechanistic understanding and clinical evidence of DDIs poses significant challenges to ensuring drug safety in the post-market phase. To close this gap, informatics-driven DDI studies have emerged over the last decade, aided by the exponential growth of big data. Notably, disproportionality analysis using the FDA Adverse Event Reporting System (FAERS) database, the largest repository of spontaneously reported adverse events in the world, presents a promising avenue for discovering clinical evidence of SADRs associated with known PK DDIs [6], [7], [8]. The four mainstream disproportionality approaches are proportional reporting ratio (PRR) [9], reporting odds ratio (ROR) [10], Multi-item gamma Poisson shrinker (MGPS) [11], and Bayesian confidence propagating neural network (BCPNN) [12]. Each detection model has distinct benefits and inherent drawbacks. The key benefits of frequentist approaches such as PRR and ROR are that they are more intuitive, easier to implement, and more sensitive than existing Bayesian methods. However, one of the main limitations of frequentist approaches is the sampling variance issue [5], [13]. To address this issue, Bayesian methods such as MGPS and BCPNN use a prior distribution to shrink the relative reporting ratio (RRR) or information component (IC) towards a predefined value, helping to reduce the impact of random variation due to small sample sizes [11], [12]. However, the use of a prior distribution can introduce bias if the chosen prior does not accurately represent the true underlying distribution of the data [13]. In summary, no method has been shown to be superior to others, and head-to-head comparisons are complicated by the lack of uniformly accepted gold standards of causality and a calculation of costs and utilities associated with correct and incorrect classifications in pharmacovigilance [13], [14]. Additionally, the utility of disproportionality methods is further limited by the inherent limitations of the FAERS database, such as biased sampling and a lack of comprehensive patient histories. Consequently, conclusions drawn from the FAERS database should be regarded more as hypotheses rather than conclusive evidence of causality. These challenges necessitate a more sophisticated approach to enhance the reliability and validity of the detected signals.
Addressing these limitations, our study introduced a novel pipeline that incorporated ranking algorithms alongside validation strategies utilizing multi-source Electronic Health Records (EHRs). By integrating the advantages of the existing disproportionality methods while mitigating their weaknesses through aggregation, we aimed to prioritize the most reliable DDI-SADR signals for further validation. It is noted that our methodology is differentiated from traditional machine learning approaches, which have primarily focused on predicting interactions involving new drugs and categorizing them into PK and pharmacodynamics (PD) types. Instead, our focus is on enhancing the post-market surveillance of known PK DDIs and their associated SADRs.
Our hypothesis posited that the ranking approaches would outperform any individual disproportionality method in detecting clinically relevant DDI-SADR signals. By validating these signals through comprehensive EHR databases, we sought to provide a more accurate and reliable method for identifying potential SADRs associated with PK DDIs. This approach not only highlighted the potential of integrating advanced data analysis techniques with pharmacovigilance efforts but also contributed significantly to the field by improving the accuracy of post-market drug safety evaluations in the absence of a gold standard. Through this study, we underscored the critical need for innovative strategies to enhance the detection and validation of DDI-SADR signals, thereby advancing the goal of safeguarding public health in the post-market phase.




留言 (0)