
記住我








Artificial intelligence (AI) has had a tremendous impact on science and is transforming almost every industry. In medical diagnostics, recent years have seen algorithms evolve with accuracies at par with or even superior to medical specialists.1–6 Commonly cited benefits of clinical AI solutions for radiology include increasing image quality, increasing safety by reducing missed findings, decreasing reading time, or triage of urgent findings, hence optimizing workflows.7–12 Further, AI tools for radiology have been shown to be especially beneficial for non-radiology clinicians, for example, interpreting musculoskeletal radiographs13,14 or chest x-rays5 in an emergency setting. Although the scientific evidence for diagnostic AI solutions is continuously growing, the widespread implementation of clinical algorithms is still lacking.15–17
Reasons for a slow implementation may include the excessive number of AI vendors and solutions, as well as technical and legal burdens to integrate these complex new technologies into existing infrastructures.18–20 A curated, central, and cloud-based AI platform, which allows the implementation of different solutions under one common technical and legal framework, may lower these burdens.21,22 However, additional costs are also an issue, with return on investment remaining elusive and reimbursement remaining sparse.19,20 Just recently, the United States included the first AI solution for acute stroke care in the “new technology add-on payment.”23
Numerous surveys have outlined a growing interest of radiologists and other physicians in AI, but also highlighted often little exposure to the new technology (both clinically and scientifically), mainly due to the lack of clinical implementation and missing formal training.15–17,24–30 Several structured courses and curricula have been proposed and evaluated successfully,31,32 and the leading radiological societies also started to offer their own resources and specialized certificates.33
The purpose of this study was to analyze the effect of implementing an established AI solution into clinical routine on physicians' perception and knowledge, by longitudinally surveying radiologists and traumatologists before and after, and matching them on an individual level by self-generated identification codes.
MATERIALS AND METHODS Ethics StatementApproval of the institutional ethics committee was obtained for this study (approval number 22-0720). Informed consent was waived due to the anonymous and voluntary character of the survey.
Survey DesignThe study was designed in a prospective, 2-stage process: a pre-interventional survey was conducted between August 8 and September 9, 2022. Next, the intervention consisted of the widespread implementation of a commercially available AI algorithm for fracture detection on radiographs (see “AI Algorithm”). Three months after introducing the AI algorithm into clinical routine, the second post-interventional survey was open from November 11, 2022, to March 2, 2023, with the AI algorithm constantly being available.
All participants were informed about the newly available algorithm via circular email, including a short manual explaining the AI results, and an overview of the scientific evidence and published metrics of the algorithm (sensitivity, specificity, area under the receiver operating characteristic curve).
Study data from questionnaires were collected using the online platform SoSci Survey (v3.4.12) hosted at institutional servers. The target group of the survey included all radiologists and traumatologists at one of the largest European university hospitals with multiple sites. At our institution, musculoskeletal emergencies are commonly seen by trauma surgeons, orthopedic surgeons, or general surgeons, whom we refer to collectively as “traumatologists.” Individuals were called by circular email and informed about the intended scientific publication of the study, and participation was voluntary and anonymous. In addition to demographic data such as age, gender, work experience, and professional group affiliation (radiology, traumatology), questions were asked about technical affinity, previous experience with AI regarding clinical or scientific use, and questions about their assessment and expectations for AI solutions. Individual assessment was gauged on a 7-point ascending Likert scale, ranging from −3 over 0 to +3, with only the extremes labeled (−3, “strongly disagree”; +3, “strongly agree”).
For the post-interventional survey, questions were nearly identical, with some additional questions regarding the frequency of using radiographs and using the AI results, as well as self-perceived changes in attitude toward AI and open comments. All questions were reviewed by the authors in consensus and piloted on a small sample of 4 to eliminate ambiguity.
Longitudinal matching of respondents pre-intervention and postintervention was based on self-generated pseudonymization codes taken from the literature,34,35 which consisted of the first letter of the mother's first name (A–Z), the first letter of the place of birth (A–Z), and the digit of the day of the date of birth (1–31), thereby allowing for a theoretical total of >20,000 individual combinations. This matching technique allowed for same individual follow-up and hence higher-powered statistical analysis.
AI AlgorithmThe implemented AI algorithm is the commercially available, FDA-approved, and CE-certified algorithm Gleamer BoneView (v2.0; Gleamer, Paris, France) for fracture detection on conventional radiographs (examples given in Fig. 1). The algorithm was externally validated in 2 large-scale, large caseload (480 and 600, respectively), multicenter studies, and showed a stand-alone performance for fracture detection with an area under the receiver operating characteristic curve of 0.94 and 0.97.13,14
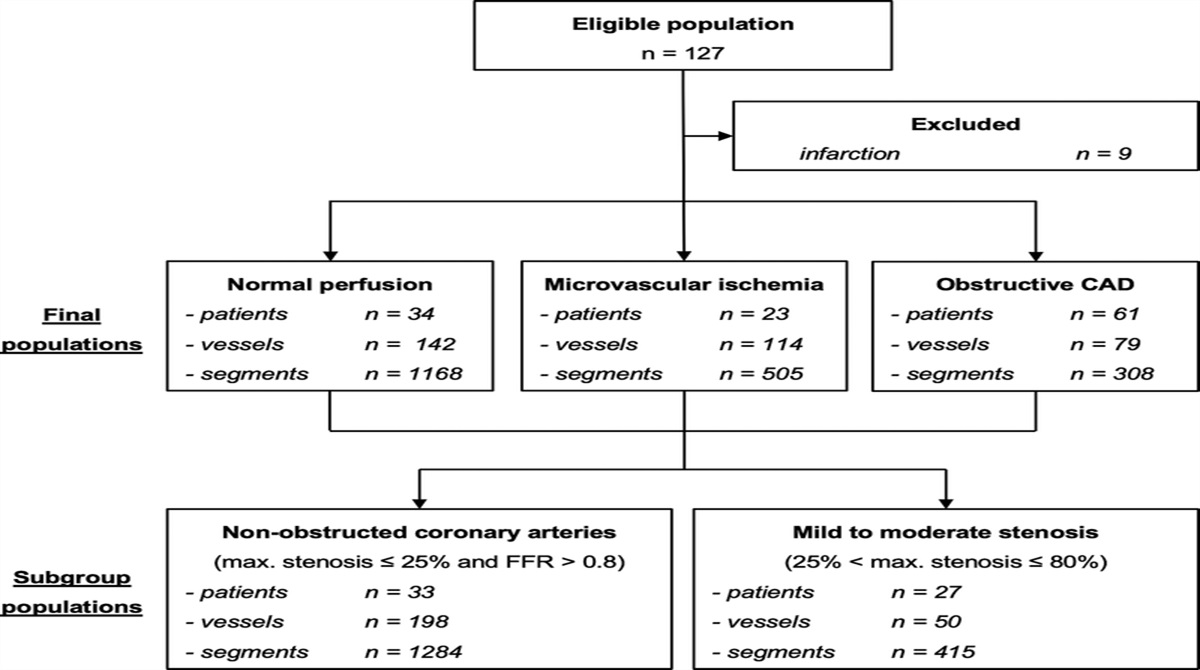
 FIGURE 1:
FIGURE 1: Flowchart of the included respondents of the survey.
Among a large and diverse set of readers (12 physicians from 2 disciplines and 24 physicians from 6 disciplines), AI support showed a significant gain in sensitivity (+8.7%/+10.4%) and in specificity (+4.1%/+5.0%), compared with evaluation without AI support, while marginally or non-significantly lowering reading time.13,14 The algorithm consists of a deep convolutional neural network based on the “Detectron 2” framework, which has been trained and internally validated on >60,000 radiographs of trauma patients from 22 hospitals and private radiology institutes with 270,000 iterations in the training batch.13,14
The technical implementation at our site was accomplished by a data protection compliant pipeline provided by the commercially available AI platform deepcOS (deepc, Munich, Germany). In this process, image data were de-identified on a local server on-premises, encrypted, and sent for analysis to a secure cloud solution.
AI-generated results were returned as secondary captures to the local server, re-identified, and assigned to patients' records. The procedure was simplified by PACS-sided auto-routing of all musculoskeletal radiographs from the emergency room (ER), and the implemented AI algorithm would automatically only analyze images from the following body regions: shoulder and clavicle, arm and elbow, hand and wrist, rib cage, thoracolumbar spine, pelvis and hip, leg and knee, and foot and ankle (eg, radiographs from the cervical spine were not analyzed, as the software has no FDA-approval for this specific use case). Average processing time was less than 5 minutes from the native image being sent to our PACS until the availability of AI results, which were usually directly accessible at the time of reporting. In the rare case auto-routing would fail or results were desired for images taken outside the ER, manual sending to the AI platform was also possible.
Data AnalysisOnly completely answered questionnaires were considered for analysis. Apart from descriptive statistics, statistical analysis for nonparametric data included Wilcoxon signed rank test for matched-pair comparison (same individual pre-intervention and post-intervention), Mann-Whitney U test (differences between professions), and Spearman rank correlation (pre-post analysis). All analyses and visualizations were performed using Python (v3.10.9) with recent SciPy and Seaborn libraries. Two-sided significance testing was conducted with an α of 5% (P < 0.05).
RESULTS DemographicsA total of 71 participants completed the survey pre-intervention (22 women, 44 radiologists, 27 traumatologists). Of these, 47 matched respondents also completed the survey post-intervention (66.2% follow-up) and were eligible for analysis, consisting of 15 women (31.9%), 34 radiologists (72.3%), and 13 traumatologists (27.7%). The mean ± SD age was 34.8 ± 7.8 years (range, 25–56 years) with 7.8 ± 7.0 years (range, 0–27 years) of work experience, which implies that the cohort consists of differently experienced physicians, from residents to senior attendings, with national board certification usually taking place after 5 years of training (for both radiologists and traumatologists). A flowchart is shown in Figure 1, and demographics are summarized in Table 1.
 FIGURE 2:
FIGURE 2: Examples of the implemented AI solution: yellow boxes indicated “suspected fracture,” and dashed lines indicate “doubtful fracture.” Secondary captures with AI-generated results were displayed in the PACS next to the original images. A, Rare injury pattern with combined metaphyseal fractures at proximal and distal metacarpal V (boxer's fracture). B, Avulsion fracture of the styloid process of the metatarsal V (pseudo-Jones fracture), only partially included on the lateral view of the ankle, later confirmed on additional x-ray of the foot. C, Acute compression fracture of L1, later confirmed on CT. D, Displaced fracture of the fourth rib and possibly undisplaced fractures of the seventh to eighth rib. E, Impacted subcapital fracture of the left femoral neck.
TABLE 1 - Demographics of Respondents of the Survey Variable Value Respondents (total) 47 (100%) Radiologists 34 (72.3%) Traumatologists 13 (27.7%) Sex (female) 15 (31.9%) Age, y 34.8 ± 7.8 Work experience, y 7.8 ± 7.0Data are shown as either counts (n) and percentages (%) or means ± SD.
All questions and responses are summarized in Table 2, with frequency distributions of answers shown in Figure 3.
TABLE 2 - Summary of the Mean Scores Pre-implementation and Post-implementation of the AI Solution Question (Short Label) Pre Post P “I see the clinical use of AI positive.” (Self: AI positive) 2.28 ± 0.88 2.38 ± 0.87 0.275 ns “I see myself as tech-savvy.” (Self: Tech-savvy) 1.06 ± 1.31 0.94 ± 1.39 0.345 ns “I am familiar with the scientific use of AI.” (Self: Scientific AI) 0.30 ± 1.69 0.53 ± 1.65 0.167 ns “I am familiar with the clinical use of AI.” (Self: Clinical AI) 0.40 ± 1.58 1.00 ± 1.37 0.003 ** “I can assess the chances of AI.” (Self: Chances AI) 1.21 ± 1.25 1.70 ± 1.02 0.002 ** “I can assess the risks of AI.” (Self: Risks AI) 0.96 ± 1.35 1.34 ± 1.17 0.028 * “AI makes me safer.” (AI: Safer) 1.21 ± 1.40 1.64 ± 1.09 0.048 * “AI makes me faster.” (AI: Faster) 0.98 ± 1.67 1.21 ± 1.69 0.261 ns “AI reduces missed findings.” (AI: Reduce Missed) 1.28 ± 1.54 1.94 ± 1.07 0.003 ** “AI provokes relevant wrong findings.” (AI: More Wrong) −0.34 ± 1.45 −0.64 ± 1.54 0.162 ns “AI replaces the radiology report.” (AI: Replace Report) −2.04 ± 1.02 −2.34 ± 0.94 0.038 * “AI speeds up the workflow in the ER.” (AI: Speed Up ER) 0.17 ± 1.75 0.64 ± 1.71 0.026 * “AI has my blind trust.” (AI: Blind Trust) −2.55 ± 1.02 −2.55 ± 1.02 1.000 ns “AI has no added clinical value.” (AI: No Value) −2.02 ± 1.33 −2.26 ± 1.15 0.409 nsData are shown as mean ± SD. Responses were gauged on a 7-point Likert scale (ranging from −3, “strongly disagree,” to +3, “strongly agree”). Statistical analysis was performed on matched-pairs (same individual pre-intervention/post-intervention; n = 47) using Wilcoxon signed rank test; results are summarized with asterisks (*P < 0.05, **P < 0.01, ***P < 0.001; ns, not significant) (AI, artificial intelligence; ER, emergency room).
 FIGURE 3:
FIGURE 3: Survey responses pre-implementation and post-implementation of the AI solution, summarized by histograms with kernel density estimation. Answers were either gauged on a 7-point Likert scale (ranging from −3, “strongly disagree,” to +3, “strongly agree”) or as labeled on the y axis (AI, artificial intelligence; ER, emergency room).
On a 7-point Likert scale from −3 (“strongly disagree”) to +3 (“strongly agree”), at baseline, respondents generally rated the “clinical use of AI” very positive (mean ± SD, 2.28 ± 0.88) with no response below “neutral” and described themselves as moderately “tech-savvy” (1.06 ± 1.31). Self-reported knowledge about the “chances of AI” (1.21 ± 1.25) was slightly higher than about the “risks” (0.96 ± 1.35). There was a broad distribution with different levels of experience with “scientific” (0.30 ± 1.69) or “clinical use of AI” (0.40 ± 1.58). Respondents rated AI to make them “safer” (1.21 ± 0.40), “faster” (0.98 ± 1.67), and “reduce missed findings” (1.28 ± 1.54), with a rather neutral rating that “AI speeds up workflows in the ER” (0.17 ± 1.75). There was relatively little concern that AI could provoke “relevant wrong findings” (−0.34 ± 1.45) and unanimous disagreement that AI could “replace the radiology report” (−2.04 ± 1.02). Participants further showed strong rejection toward “blind trust” in AI (−2.55 ± 1.02), but also denied the statement that AI holds “no added clinical value” (−2.02 ± 1.33). When comparing these responses to those who were lost to follow-up, no significant differences were found (Supplement Table S1, https://links.lww.com/RLI/A869).
Usage of the AI Algorithm (Intervention)During the intervention, the AI algorithm processed ~3000 cases/month (mean, 2962 ± 145), with each case containing 1 or more radiographs. The majority of participants (76.6%) reported seeing multiple radiographs daily, with 38.3% seeing >10 per day and 21.3% seeing even >30 per day. Nearly a third (31.2%) said to use the AI results “always,” and cumulative nearly three quarters (74.5%) used them half of the time or more, whereas no one used them “never” (0.0%).
Responses Post-intervention and ChangesDifferences in responses from pre-intervention to post-intervention are visualized in Figure 4. Our post-interventional survey highlighted the educative point of implementing an AI algorithm into clinical routine (results are shown as means [pre] vs [post]): we found a significant increase in experience with the “clinical use of AI” (0.40 vs 1.00, P = 0.003), as well as in self-reported knowledge about “chances” (1.21 vs 1.70, P = 0.002) and “risks of AI” (0.96 vs 1.34, P = 0.028). No significant changes were seen in familiarity with “scientific use of AI,” general “AI positiveness,” or “tech-savviness” (P = 0.167, P = 0.275, P = 0.345).
 FIGURE 4:
FIGURE 4: Comparison of assessments between pre-interventional and post-interventional surveys. Values are depicted as means with SD as error bars. Answers were gauged on a 7-point Likert scale (ranging from −3, “strongly disagree,” to +3, “strongly agree”) Statistical analysis was performed on matched-pairs (same individual pre-intervention/post-intervention) using Wilcoxon signed rank test; significant changes are annotated with asterisks (*P < 0.05, **P < 0.01, ***P < 0.001; ns, not significant). (AI, artificial intelligence; ER, emergency room).
After using the AI solution in clinical practice, physicians significantly increased their rating that AI makes them “safer” (1.21 vs 1.64, P = 0.048) and “reduces missed findings” (1.28 vs 1.94, P = 0.003), where the latter showed the highest increase among all items. Overall, there was only a non-significant trend that AI could make readers “faster” (0.98 vs 1.21, P = 0.261) but a significant increase that it could generally “speed up the workflows in the ER” (0.17 vs 0.64, P = 0.026).
The statement that AI could “replace the report” was already rated low at baseline, but further decreased significantly after the intervention (−2.04 vs −2.34, P = 0.038). No significant changes were found regarding “relevant wrong findings,” “blind trust,” or “no value” (P = 0.162, P = 1.000, P = 0.409).
Additional post-interventional questions for the perceived change confirmed some “increase in AI positivity” (1.09 ± 1.14), “increased knowledge about AI” (0.72 ± 0.95), and “increased trust in AI” (0.89 ± 1.05), whereby nearly all answers were at least neutral (“0”) or above, and only 1 participant (“AI positive”), respectively; 2 participants (“trust”) rated these with “−1.” The majority strongly wished to “continue using AI” (2.11 ± 1.05) and endorsed they wanted to “use more clinical AI” (2.13 ± 1.06) in the future.
Correlations Between ResponsesThe full matrix of all significant correlations (P < 0.05) is shown in Figure 5. Already at baseline, we found a strong correlation between self-reported experience with “clinical” or “scientific” AI and knowledge about its “chances” and “risks” (r = 0.60–0.78; all P's < 0.001), and a little less pronounced correlation between these and “tech-savviness” (r = 0.41–0.43; all P's ≤ 0.005). Furthermore, those with higher experience pre-intervention also rated AI higher to make them “safer” (r = 0.49–0.50; all P's < 0.001) and “reduce missed findings” (r = 0.36–0.41; all P's ≤ 0.013), which post-intervention showed the biggest increase among participants. All expectations favorable for AI showed a positive correlation between each other pre-intervention and post-intervention (“safer,” “faster,” “reduce missed,” “speed up ER,” r = 0.31–0.75; all P's < 0.001). A negative correlation was found between higher ratings for “no value” with lower ratings for general “AI positiveness” (r = −0.48; P < 0.001) and lower ratings of favorable attributes such as “safer,” “reduce missed,” and “speed up ER” (r = −0.47, −0.45, −0.42; all P's ≤ 0.003). Post-intervention, a slight positive correlation was found between “no value” and “more wrong findings” (r = 0.31; P = 0.032), confirming the attitude of more skeptical participants.
 FIGURE 5:
FIGURE 5: Matrix of Spearman correlation (r s) of survey results preimplementation (lower left triangle of the matrix) and postimplementation (upper right triangle of the matrix) of the AI solution. Only significant correlations (P < 0.05) are shown. Items solely included in the postinterventional survey (prefixed with “POST”) are grayed out in the last 7 rows of the preinterventional results (left lower triangle), as there are only postinterventional results (upper right triangle, last 7 columns) (AI, artificial intelligence; ER, emergency room).
An interesting moderate negative correlation was found for “age,” as older respondents reported lower experience with “clinical AI” at baseline (r = −0.34; P = 0.027), and post-intervention were also less likely to up-vote the items “safer,” “reduce missed,” or “speed up ER” (r = −0.30, −0.35, −0.31; all P's ≤ 0.046). This equally held true for more years of “work experience,” with a negative correlation to “reduce missed findings” (r = −0.31; P = 0.035), but more interesting also indicated a lower frequency of “usage of AI results” (r = −0.34; P = 0.019). On the other hand, an increased “usage of AI results” correlated strongly with higher ratings for “safer,” “reduce missed findings,” “faster”, and “speed up ER” (r = 0.57, 0.59, 0.42, 0.45; all P's ≤ 0.003). A higher vote on “blind trust” for AI correlated strongly with AI to “replace the radiology report” (r = 0.39 [pre] and 0.53 [post]; both P's ≤ 0.006), but it has to be mentioned that for both theses there were merely different levels of “disagreement” and nearly no rating above neutral (“0”).
The wish to “continue AI” usage correlated strongly with favorable AI attributes (r = 0.40–0.69; all P's ≤ 0.005), with the highest correlation for “reduce missed findings,” which was equally observed for the wish for “more AI solutions” (r = 0.35–0.57; all P's ≤ 0.017).
Differences by ProfessionWe found some notable differences between the professions through the intervention: radiologists rated AI significantly higher to make them “safer” (1.94 vs 0.85, P = 0.003), “faster” (1.53 vs 0.38, P = 0.030), and reported a significantly higher “usage of AI results” (P < 0.001) compared with the participating traumatologists. On the other hand, traumatologists reported on average a slightly higher frequency of “usage of x-rays” (P = 0.045). All other items showed no significant differences. A visual representation is shown as a spider plot in Figure 6.
 FIGURE 6:
FIGURE 6: Spider plot visualizing the differences in assessment of AI solutions split post-intervention by profession into radiologists (n = 34) and traumatologists (n = 13). Plotting based on the 7-point Likert scale responses (ranging from −3, “strongly disagree,” to + 3, “strongly agree”), frequencies of usage were normalized to a 7-point scale for plotting. Using Mann-Whitney U test, significant differences are annotated with asterisks, all unmarked items are nonsignificant (*P < 0.05, **P < 0.01, ***P < 0.001; ns, not significant) (AI, artificial intelligence; ER, emergency room).
Overall, it has to be noted that more radiologists than traumatologists participated in both parts of the study (34 vs 14), whereas traumatologists were on average older and more experienced (age: 39.8 ± 9.1 vs 33.4 ± 5.9, P = 0.014; work years: 12.5 ± 8.7 vs 6.0 ± 5.4 years; P = 0.009) (full results shown in Table 3).
TABLE 3 - Summary of the Mean Scores Comparing Radiologists and Traumatologists Post-intervention Question (Short Label) Radiologists Traumatologists P Age, y 33.4 ± 5.9 39.8 ± 9.1 0.014 * Work experience, y 6.0 ± 5.4 12.5 ± 8.7 0.009 ** “I see the clinical use of AI positive.” (Self: AI positive) 2.38 ± 0.78 2.38 ± 1.12 0.368 ns “I see myself as tech-savvy.” (Self: Tech-savvy) 0.85 ± 1.44 1.15 ± 1.28 0.575 ns “I am familiar with the scientific use of AI.” (Self: Scientific AI) 0.56 ± 1.78 0.46 ± 1.33 0.781 ns “I am familiar with the clinical use of AI.” (Self: Clinical AI) 1.09 ± 1.38 0.77 ± 1.36 0.341 ns “I can assess the chances of AI.” (Self: Chances AI) 1.71 ± 1.00 1.69 ± 1.11 0.930 ns “I can assess the risks of AI.” (Self: Risks AI) 1.32 ± 1.07 1.38 ± 1.45 0.645 ns “AI makes me safer.” (AI: Safer) 1.94 ± 0.95 0.85 ± 1.07 0.003 ** “AI makes me faster.” (AI: Faster) 1.53 ± 1.60 0.38 ± 1.71 0.030 * “AI reduces missed findings.” (AI: Reduce Missed) 2.09 ± 0.93 1.54 ± 1.33 0.202 ns “AI provokes relevant wrong findings.” (AI: More Wrong) −0.94 ± 1.30 0.15 ± 1.86 0.058 ns “AI replaces the radiology report.” (AI: Replace Report) −2.26 ± 1.02 −2.54 ± 0.66 0.589 ns “AI speeds up the workflow in the ER.” (AI: Speed Up ER) 0.79 ± 1.67 0.23 ± 1.83 0.345 ns “AI has my blind trust.” (AI: Blind Trust) −2.53 ± 1.11 −2.62 ± 0.77 0.921 ns “AI has no added clinical value.” (AI: No Value) −2.41 ± 1.10 −1.85 ± 1.21 0.063 ns “I see the clinical use of AI more positive.” (POST: More AI positive) 1.09 ± 1.14 1.08 ± 1.19 0.891 ns “I gained knowledge about clinical AI.” (POST: More AI Knowledge) 0.68 ± 0.88 0.85 ± 1.14 0.824 ns “I gained trust in clinical AI.” (POST: More Trust in AI) 0.88 ± 1.04 0.92 ± 1.12 0.920 ns “I wish to continue using AI.” (POST: Wish Continue AI) 2.21 ± 0.95 1.85 ± 1.28 0.450 ns “I wish to use more clinical AI.” (POST: Wish More AI) 2.26 ± 0.93 1.77 ± 1.30 0.230 ns “How many radiographs did you see on average?” (POST: Usage X-rays) 3.03 ± 1.31 3.85 ± 0.90 0.045 * “How often did you use AI results?” (POST: Usage AI results) 4.09 ± 1.06 2.31 ± 1.25 <0.001 ***Data are shown as means ± SD. Responses were gauged on a 7-point Likert scale (from −3, “strongly disagree,” to +3, “strongly agree”). The last 2 questions were gauged on different 6-point ascending ordinal scales (“Usage X-rays” 0: none, 1: <5/month, 2: 1–5/week, 3: 1–10/day, 4: 10–30/day, 5: >30/day; “Usage AI results” 0: never, 1: 1%–24%, 2: 24%–49%, 3: 50%–74%, 4: 75%–99%, 5: always). Statistical analysis was performed using Mann-Whitney U test (radiologists: n = 34; traumatologists: n = 13); results are summarized with asterisks (*P < 0.05, **P < 0.01, ***P < 0.001; ns, not significant) (AI, artificial intelligence; ER, emergency room).
Post-intervention, we received open comments from 10 participants (21.3%), including 7 traumatologists and 3 radiologists (30.0% female; mean age, 39.1 ± 8.0 years). Of these, 4 respondents (2 traumatologists, 2 radiologists) expressed general thanks and positive recognition for implementing the AI. Three senior traumatologists (work experience 8, 15, and 25 years) strongly warned against the uncritical and thus potentially dangerous use of the software, one of them demanding more sophisticated and detailed algorithms, for example, also considering displacement or misalignment, to detect unstable injury patterns. One junior radiologist (1 year experience) noted that obviously displaced fractures were sometimes not annotated by the AI. One experienced traumatologist (11 years' experience) asked for the scientific evidence (the announcement of the AI implementation was circulated by email and included a summary of the studies and links), and another surgeon (10 years' experience) generally disliked seeing the additional AI-annotated images.
DISCUSSIONIn this prospective pre-post analysis, we investigated the impact of implementing AI into clinical routine on the perception of radiologists and traumatologists. We were able to show that AI solutions can receive higher acceptance when they are applied in practice. To our knowledge, this study is the first of this kind in the field of AI for radiology.
Our findings underline the concept of AI as a “second reader”14,20,36 in the given setting of fracture detection on radiographs: post AI implementation, radiologists and traumatologists rated the AI significantly higher to make them “safer” and “reduce missed findings,” with only a non-significant trend that it would make them “faster.” This is in line with results from the external validation studies of the algorithm, which showed a significant increase in sensitivity and specificity, while only marginally or non-significantly reducing reading times.13,14 However, we did find a slight increase that AI could speed up workflows in the ER. This could be because a higher accuracy of the readings might avoid or streamline additional examinations more efficiently, but the determination of the exact reasons is beyond the scope of this study.
An often-quoted fear in public discussions and reflected in recent surveys is that AI could overtake the human workforce, thus in our case replace the radiological report and consequently replace the radiologists themselves.20,25,28,37 However, our results do not support this hypothesis: already rated low at baseline, “AI could replace the radiological report” was significantly down-voted after the intervention, which was equally observed among both radiologists and traumatologists. This further supports the idea of AI as a “second reader” or “safety net”, and not as a replacement for radiologists.37
Respondents generally showed a very positive attitude toward the clinical use of AI and only little belief it could bring “no added clinical value,” which has been echoed across different specialties in numerous studies previously.15,17,24–29 Accompanying, we saw a strong correlation between “AI positiveness” and all favorable expectations toward AI (eg, “safer,” “reduce missed”, and “faster”), whereas a negative correlation was only found with “no value” and “more wrong findings”, outlining the sentiment of more skeptical respondents.
The implementation of AI itself proved an educative point: participants showed a significant gain in familiarity with clinical AI, its chances, and its risks after using it daily in their work. Already at baseline, we found a strong correlation between previous usage of AI and self-perceived knowledge about it, which confirmed true for participants post-intervention and was in line with former results.24 Also in previous surveys, radiologists expressed high interest in AI, but regularly complained about missing access to it and lacking formal training.20,24,29 Arguably, our study suggests the teaching effect of exposure to the new technology in clinical routine via a “hands-on” approach, while additional structured courses and curricula are desirable, and have already been developed and successfully evaluated.31,32
Overall, we saw a unanimous wish among participants to “continue using AI” and a strong endorsement for the use of “more clinical AI,” which shows the strong perceived benefits of supportive AI solutions in clinical routine. However, there were some points of critique, which have to be taken into account. Generally, older and more experienced physicians were more skeptical, were less likely to use AI results, and saw fewer benefits. This might be because experienced readers often show less pronounced improvement with AI support, but in numerous studies, their improvement also showed to be significant.5,12–14
Furthermore, we found some notable differences between the professions: radiologists reported a higher usage of AI results and rated “safer” and “faster” higher than their fellow traumatologists. One reason for this could be in the different clinical workflows: while traumatologists see and examine patients in person, they are able to gather additional clinical information to strengthen their diagnosis. On the other hand, radiologists rely on the image itself, and often enough only little additional information is passed on, therefore each imaging clue becomes more valuable. On average, traumatologists reported seeing a higher number of radiographs, which might be contrasted by some radiologists, who only report radiographs during (night) shifts and may be reading predominantly CT or MRI otherwise. However, it was also 3 senior traumatologists warning against the uncritical use of the provided AI support. In fact, results should always be checked for plausibility, as training bias may lead to systematic errors,38 and a recent study demonstrated the
留言 (0)