
記住我


All three trainings stated learning objectives that included understanding the advantages of considering sex and/or gender, mastery of proper terminology, best practices in research design, and how to evaluate other studies. Below, we summarize our findings regarding the content.
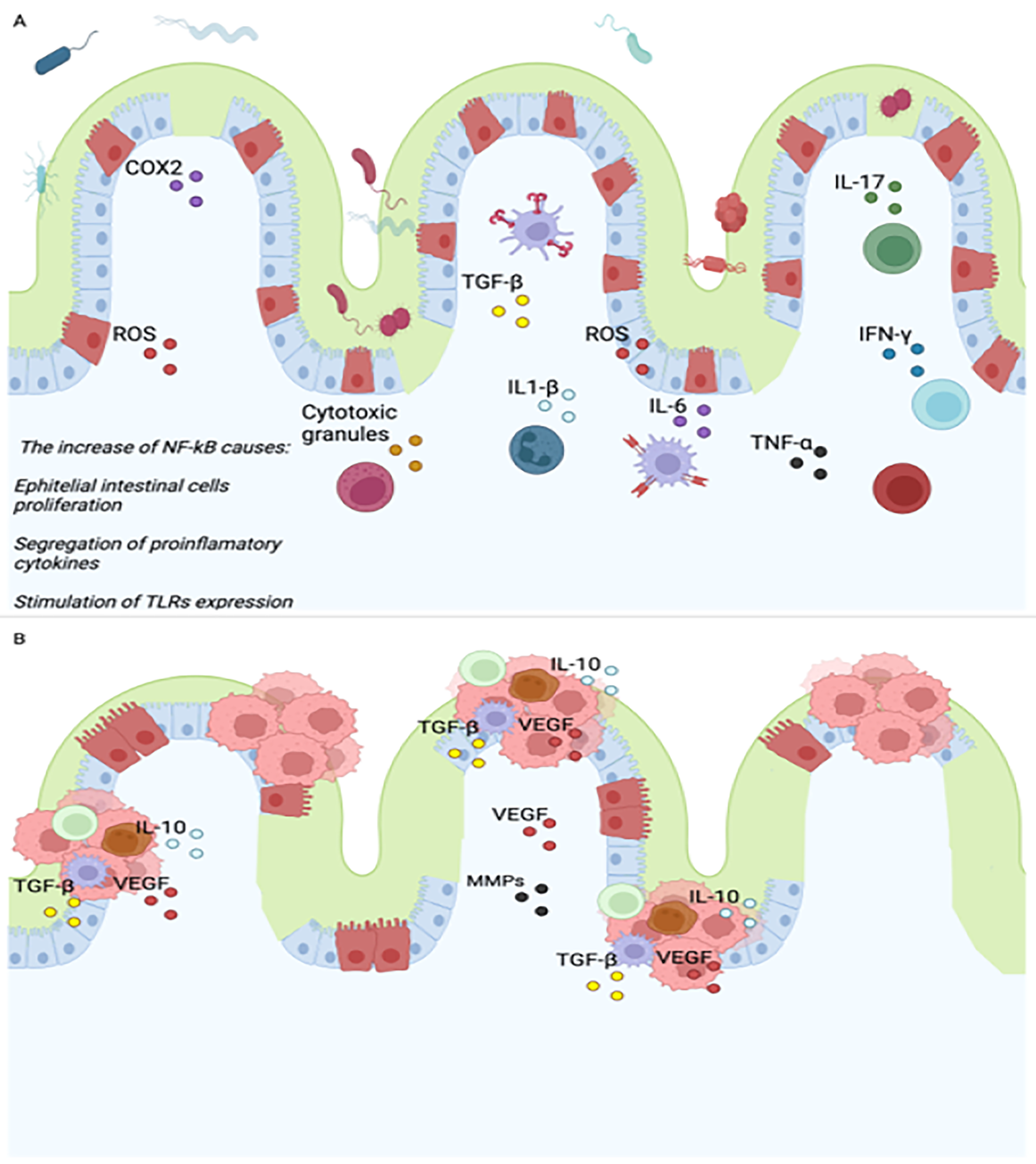
Rationale for sex and gender research policiesEach of the trainings emphasized the need for and importance of sex and gender research policies, often citing the same rationales. Generalizability was a major focus of each training, with the explicit or implicit notion that results from studies on one sex or studies that do not account for sex cannot be generalized to both females and males. NIH explicitly stated that “the results of a study with subjects of a single sex cannot be generalized to the other” and that not accounting for sex leads to “erroneous conclusions” or “erroneous assumptions that results apply to both sexes.” LIBRA stated that overgeneralization occurs “when the study is conducted in one sex but results are presented as if they apply to both sexes.” CIHR similarly stated that overgeneralization may occur when sex is not accounted for, and that “there is a risk of harm by assuming that the study results apply to everyone.” Risk of harm by not considering sex and gender in research was frequently leveraged in all three trainings to highlight the importance of sex and gender policies. Few examples of harm were offered; in all three courses, they were taken primarily from a 2001 US Government Accountability Office (GAO) report about increased risk of adverse drug events in women. This report itself [21] clarifies that most of the drugs with adverse events mentioned in the report were prescribed mostly to women, which explains the disparity in adverse events [22, 23]; however, none of the trainings mentioned this detail.
A second rationale for sex and gender research policies, referenced in each of the trainings, was reproducibility. The NIH Primer relied most heavily on reproducibility as a motivating factor, and typically paired it with references to rigor and transparency with statements such as: “SABV is a key focus of the NIH initiative to enhance reproducibility in biomedical research through rigor and transparency in studies.” CIHR’s usage of reproducibility was narrower, limited to the issue that there are “problems with reproducibility when the sex of cells, tissues, and animals are not explicitly recorded and reported.” One of the videos in the LIBRA training stated that depositing raw data by sex (or race, as mentioned by the speaker) “is key for reproducibility.”
“Precision medicine” was frequently leveraged as a rationale for sex and gender research policies, with references to the promise of sex-specific treatments appearing in all three trainings. CIHR stated that discovering sex differences will “improve health by tailoring treatments differently for men and women.” NIH stated explicitly that SABV will “allow better translation for personalized sex-specific treatment” and called for not only sex-specific therapeutic interventions but also sex-specific recommendations for clinicians and policymakers. LIBRA was more focused in its invocation of sex-specific medicine, describing the findings of its two case studies as leading to potential diagnostic markers specific to women.
Both CIHR and NIH emphasized that including males and females will further understanding of mechanisms underlying sex differences related to health; CIHR stated, “Sex matters in biomedical research… because mechanisms are needed to explain observational similarities and differences in the epidemiology of the disease under study, as well as response to treatment.” Whereas NIH suggested that investigating underlying mechanisms was not a requirement of SABV policy, CIHR emphasized that research including females and males needs to “include a clear objective to elucidate the mechanisms of any differences/similarities that may arise.” In one of the research scenarios offered by CIHR, for example, principal investigators were criticized for not proposing to show how the outcome measures were affected by hormones, even though exploring such mechanisms was not a primary focus of their study.
Both the CIHR and NIH trainings contained somewhat vague references to efficient use of resources. According to CIHR, “inefficiencies may occur” if sex is not accounted for at all stages of design, analysis, and reporting. NIH warned that not incorporating SABV results in “wasted money and resources” and “failure to maximize return on investment.”
Descriptions of sex differencesCommon examples of sex differences given in the trainings included differences in substance use, cardiovascular disease, pain, and mental health. The nature and size of sex differences were often described using hyperbolic language; for example, the NIH Primer stated that there is “abundant evidence that there are distinct biological differences between females and males,” and repeatedly referred to these as “fundamental” or “basic” differences. LIBRA similarly described sex differences as self-evident, for example that “it’s very well known that there are big differences between males and females” and that “sex hormones are obviously very important translationally and during the clinic.” While CIHR contained comparatively less hyperbolic language, it did include statements such as, “the influence of sex on health extends from the cellular to the societal level” and that “sex should be analyzed at all levels, from chromosomes and cells to whole organisms.” This sentiment was echoed by the Primer: “Sex and gender factors can be addressed distinctly from cells to selves.”
Sex and gender: definitions and operationalizationAll three trainings emphasized the importance of terminology, particularly a distinction between the terms “sex” and “gender.” LIBRA considered the confusion of sex and gender to be one of the three main mistakes in sex and gender research. In all the trainings, sex was equated with “biology.” Gender was defined as “socially constructed” and largely behavioral by CIHR, cultural by NIH, and socio-cultural by LIBRA. Gender was noted in all three trainings to apply to humans only, although CIHR allowed for “rare exceptions, such as in research involving animal behaviours that are dependent on context or environment.” One of the speakers in the LIBRA course referred to the “gender” of mice. Both sex and gender were implicitly or explicitly defined as binary throughout all three trainings, whether through language such as “both sexes,” “both women and men,” “the opposite sex,” or through lack of discussion of intersex or transgender individuals. CIHR occasionally presented an intersex symbol on a slide, and repeatedly referred to “gender-diverse people” as distinct from men, women, boys, and girls, without elaboration. Only CIHR noted that gender can change over time. None of the trainings mentioned that sex can change in some species; CIHR noted specifically that sex cannot change.
All three trainings stated that both sex and gender are relevant to health, but sex was presented as more relevant to biological research. SABV (NIH’s policy) addresses only sex, but SGBA (CIHR’s policy) and SGR (LIBRA’s framework) include both sex and gender. The trainings noted the entanglement of sex and gender to varying degrees. Referring to this entanglement, the Primer used the language “inextricably linked,” CIHR used “interconnected” or “interacting,” and LIBRA used “interact.” CIHR suggested the usage of “sex/gender” when the two are inseparable, and pointed out that some observed sex differences could be explained by gender. However, many differences were asserted to certainly be caused by sex, such as a difference in kidney function.
Operationalization of sex differed among the courses. According to NIH, sex is “encoded in DNA” and defined by chromosomal complement (XX vs. XY). While this chromosomal definition was repeated many times throughout the Primer, other options for operationalization of sex were presented on one of the slides, including self-report or observation. CIHR defined sex as a set of attributes associated with chromosomes, gene expression, and hormone levels. LIBRA did not explicitly define or operationalize sex but did note that one advantage of studying non-human animals is that “the sex variable can be broken down into its constituent parts,” referring to chromosomes and hormones. CIHR and NIH instructed researchers to “properly identify” the sex of animal models, tissues, or cells (CIHR) and report operational definitions (NIH). However, no explanations or examples of proper operationalization or determination of sex were given in any of the trainings.
All three trainings referred to the sex of cultured cells and argued that the chromosomal complement of a cell defines its sex. NIH and LIBRA both asserted that “every cell has a sex.” CIHR stated that “cells and tissues can generally be classified as female or male by the chromosomal complement,” a view reiterated by NIH and LIBRA. Despite blanket references to “male and female cells” and instructions to “take into account the sex of cells,” there were instances in which the trainings acknowledged the complexity and controversy regarding whether and how cells can be “sexed.” The Primer noted, for example, that “NIH recognizes current challenges to the authentication of the sex of established cell lines.” LIBRA mentioned the complicated interplay between chromosomes and androgen receptors in cell culture and further noted that “primary cells may obscure sex differences because of the in vitro environment.”
Other than the idea that gender is distinct from sex, the NIH and LIBRA training materials did not contain further information about its operationalization. Operationalization of gender was, in contrast, a major focus of the CIHR training. Module 3 in particular covered gender scales and methods for measuring gender. The challenges noted included working with secondary datasets that do not contain sufficient information and anticipating all gender-related variables. Ultimately, however, CIHR advised to not adjust for variables such as social support, employment status, and education because these differ for men and women and adjustment would therefore erase the effect of gender.
Generalization of sex-related findings from non-human animals to humansIn all three trainings, it was assumed or explicitly stated that sex differences in non-human animals can be generalized to humans. We noted one exception during the expert interview in LIBRA, when the interviewee remarked that mouse strain is a key factor in generalizability and replicability of findings: “Another very important thing that is probably not adequately stressed even by funding agencies is that… there are many strains of mice, which have a different susceptibility to cancer. So even there, unless you argue that you want to validate all your experiments in different mouse strains, not only males and females, you can see that it’s actually becoming impossible.” Nonetheless, in one case study in LIBRA, results from a single experiment in one strain of knockout mice were generalized to recommend a strategy for assessing colon cancer risk in women.
When to include females and malesA major focus of each training was how to decide whether to include females and males or conduct a single-sex study. All the trainings emphasized the importance of literature searches to determine what is already known about sex differences in the area of interest. CIHR and LIBRA placed this material in the context of human prevalence, arguing that including males and females is important when there are known sex differences in the condition being studied or modeled. For example, CIHR noted that a female-only study of the mechanisms underlying bladder cancer in mice was “not scientifically sound” because the prevalence of the disease is four times higher in men than women. Both LIBRA and CIHR recommended including females and males when evidence of sex differences is absent or equivocal.
Advice about inclusion was less straightforward when the literature showed evidence of sex similarities. CIHR presented a scenario in which researchers were using only male mice “to keep the numbers of animals to a minimum.” The learner was instructed that, because the literature showed that the sexes do not differ with respect to the mechanism under study, this reasoning is sound. There was, however, neither an explanation of why a single-sex study is better than one that also includes females, given the established lack of a sex difference, nor a consideration for the potential cost of discarding females. The advice also appeared to conflict with the instruction for human studies that “if data from early phase trials do not indicate potential sex-related differences, it cannot be assumed that clinically relevant differences do not exist.”
All three trainings endorsed a single-sex approach when the condition being studied occurs primarily in one sex, for example prostate cancer (LIBRA) or breast cancer (CIHR). Single-sex approaches were also deemed acceptable when a condition had already been studied in one sex and researchers want to study another (LIBRA). Limiting a study to one sex simply because previous studies were conducted in that sex was deemed unacceptable, however (CIHR).
The trainings differed with respect to whether single-sex studies are justified when resources are limited. NIH condoned single-sex studies when animals are scarce, such as non-human primates. At the same time, NIH also argued that cost is never an acceptable reason to exclude one sex. CIHR recommended that when feasibility is the justification for a single-sex study, that choice must be acknowledged as a limitation and the implications for impact must be considered.
A major point made by both CIHR and LIBRA was that inclusion of females and males is not necessary in studies of “basic” biology. For example, CIHR claimed that sex is not relevant to understand protein-protein interactions and other molecular mechanisms, and inclusion of males and females would “not strengthen the quality” of such studies. Similarly, LIBRA argued that sex is “clearly” not relevant in studies of protein-protein interactions. Notably, none of the trainings offered a rationale or evidence supporting an advantage of single-sex approaches to studying molecular processes. On the contrary, a major overall theme of all three trainings was that basic, protein-based mechanisms, such as drug-receptor interactions and regulation of gene expression, do differ between the sexes. Although CIHR insisted that “there are no sex differences in protein-protein interactions” the next sentence stated that there are “different” pharmacokinetic mechanisms in males and females. For CIHR, the advice to conduct single-sex studies of molecular processes was overridden by a sex difference in prevalence of a related condition; in an example research scenario, researchers were studying an asthma-related protein in adult mice. Because there were no known sex differences in the protein, the researchers proposed a single-sex study. Despite the lack of sex differences at the molecular level, however, CIHR deemed the study not scientifically sound because in human children, asthma is more common in boys than girls.
A substantially different endorsement of single-sex studies was offered by LIBRA. In Module 2, learners were told that “single-sex studies are an obvious choice” for researchers interested in how “cells or animals differ according to age, hormonal status, circadian cycle, etc.” That is, LIBRA seemed to say that sex is not relevant when the independent variable of interest is something other than sex. By this logic, longitudinal studies looking at changes over development or changes over the circadian cycle should not be required to include females and males. This advice, given both in the instructional and quiz portions of LIBRA Module 2, presented an interesting contrast with both NIH and CIHR policy.
Accounting for hormones and hormonal cyclesAdvice about tracking ovarian cycles sometimes seemed to conflict, even within a particular training. CIHR noted in Module 1 that “consensus among experts suggests that controlling for fluctuations in gonadal hormones in initial experiments is unnecessary.” Yet, later in the same module, researchers were advised to “acknowledge how variability in endogenous hormone levels will be accounted for.” Elsewhere in Module 1, CIHR advised researchers to consider documenting or controlling hormonal status “where appropriate,” which was clarified as cases in which “there is evidence that reproductive hormone variability affects the dependent measure.” Similarly, NIH’s Module 2 argued that according to meta-analyses, females are not more variable than males when estrous cycles are not controlled; earlier in the same module, however, the training stated that “researchers working with animal models should consider the influence of male and female hormones and the hormonal cycle in experimental design.” LIBRA drew a distinction between cycles in rodents and those in humans; it was argued in Module 1 that the rodent estrous cycle is too short for gene transcription to change from phase to phase (an incorrect assertion) [24, 25]; in contrast, researchers studying premenopausal women were advised to track the stage of cycle.
Research designs and reporting resultsExploratory vs. confirmatory research and statistical powerNIH emphasized that choices about experimental design, particularly relating to power, depend on whether detection of sex differences is a main goal of the study. In this way, NIH distinguished between research intended to confirm sex differences and research that is exploratory in nature: “consider whether your intent is to (1) look for sex differences OR (2) to appropriately consider and control for sex when evaluating the effect of your experimental condition or intervention.” The same directive, although emphasized less, was found in LIBRA: Whether to power your study “depends on whether you’re interested in [sex differences] or not.” CIHR’s position on the matter was more nuanced. In Module 1, learners were instructed to always test for sex differences, even when underpowered: “Large differences can often be detected even with small sample sizes.” For human clinical studies in particular, however, CIHR advised always powering to detect sex differences. On the same slide, it was recommended that assessing sex differences should be planned “once the overall treatment effect has been shown to be significant,” suggesting that if the treatment was not effective when the sexes were considered together, then there would be no reason to test for sex differences. This suggestion seemed to conflict with directives elsewhere in the training, as well as on that slide, that data should always be disaggregated by sex “in order to identify potential differences in dose response.”
Neither CIHR nor LIBRA offered detailed guidance about how to calculate power. LIBRA’s advice was simply to “consult a statistician.” LIBRA went on to advise that a sample size of eight would never offer enough power whereas a sample size of 16 is ideal, but no power calculation or discussion of effect size was presented to support these statements. CIHR offered only that power analyses should always be done. Further, in the CIHR training, nearly every mention of power co-occurred with a mention of including males and females in equal numbers; these two concepts were used interchangeably at times. Only NIH went into more detail about how power is calculated but their guidance did not take sex as a variable into account. In Module 3, NIH advised that if a researcher’s goal is to detect sex differences in response to treatment, a power analysis must be conducted and the study powered accordingly. Subsequently, instructions were provided on how to calculate power for a comparison between treated and untreated groups; sex as a variable was not considered, however, and no guidance was presented on how to calculate power to detect either the effect of interest within each sex or a sex difference in the response to treatment. We noted NIH’s recommendation that “a t-test will yield the most accurate result in your power analysis” (a t-test is, to our knowledge, not a method for calculating power).
The trainings disagreed with each other about whether sample sizes must be increased to consider the influence of sex or gender. CIHR noted that power analyses are likely to show that sample size must be increased. LIBRA reiterated this concern, noting that researchers conducting power analyses are likely to see the required numbers of animals “skyrocket.” LIBRA spent considerable space on the issue, covering the balance between “statistical significance” and the financial and ethical cost of including more animals. LIBRA went so far as to say that sufficient power to compare the sexes can be accomplished only with a doubling of sample size. In contrast, NIH pushed back against the idea that including females and males always requires a doubling of sample size, emphasizing that main effects of treatment can usually be detected in a group of males and females just as easily as a single-sex group without increasing numbers overall. It is important to note, however, that whereas LIBRA’s point was about detecting sex differences in the response to treatment, NIH’s point was about detecting main effects of treatment, not comparisons of those effects between sex. NIH’s insistence that sample size does not need to be increased conflicted with their guidance throughout the rest of the training that data be disaggregated by sex for analysis and reporting, which would profoundly reduce power unless sample size were increased. Perhaps to mitigate the loss of power, NIH stated, “For some designs that consider SABV, but are not intended to detect sex differences, examination of the data will allow the observation of potential trends in the data related to sex. Decisions can then be made whether to follow up with a study explicitly designed and powered to detect sex differences.”
Analyzing and reporting sex-based dataA major theme of all three trainings was that data should always be analyzed separately for females and males. LIBRA stated, for example, “Study outcome measures, that is the effects of treatment, separately in each sex.” Although separate analyses do not allow for statistical comparison between females and males and in fact constitute a widespread and well-described logical error [10, 11, 20, 26,27,28], CIHR and LIBRA clearly considered such an approach an acceptable method to look for sex differences. CIHR stated, “Sex considerations [can] be taken into account by performing analyses in males and females separately;” in CIHR’s quizzes, approaches with separate analyses were marked as “correct,” e.g., a proper sex comparison can be achieved by “separating the data into two groups and then running the analyses separately for each group.” These quizzes required the acknowledgment of such analytical approaches as a “strength.” According to LIBRA, “disaggregating the data by considering the sexes separately can unmask sex differences.” In a LIBRA quiz, learners were asked to draw conclusions about sex differences from separate analyses of males and females. Notably, Module 3 of LIBRA consisted of two case studies presented as examples of how sex can and should be considered in research; both studies made claims that the sexes differed when the sexes were not quantitatively compared.
Despite the emphasis on separate analyses of data from females and males, all three trainings also covered a more appropriate approach: factorial designs that included sex-by-treatment interactions. Such approaches were typically presented as alternatives to separate analyses that should be used only under certain conditions, however. NIH, for example, mentioned testing for an interaction only after the sexes were analyzed separately. Similarly, LIBRA advised learners to first study outcome measures separately in each sex, then “compare, via statistics, outcome measures in females and males to establish the presence of sex differences.” Both NIH and LIBRA endorsed factorial designs only for studies powered to detect significant sex by treatment interactions; NIH suggested comparing outcome measures between sexes “using statistical tests” only in the context of a powered, confirmatory study. One statement in Module 3 stood out, however: “It may not be possible to power your study to detect a meaningful interaction between sex and treatment. In these cases, you should add a sex-by-treatment interaction term in the statistical model.” Thus, NIH seemed to argue here that interaction terms should be included only when underpowered, conflicting with other directives in the training. In a quiz, NIH recommended adding a sex-by-treatment interaction term in the statistical model “in all studies that consider SABV,” which appeared to conflict with other slides stating that interaction terms be included only under certain conditions. CIHR noted similarly that although comparing the sexes statistically should, theoretically, always be done, testing for interactions requires a larger sample size than conducting analyses within sex (which is not accurate, if the goal of within-sex analyses is to detect either an effect of a manipulation or a sex difference in that effect). CIHR stated further that interaction terms were generally not preferred because they are less “intuitive” and more “difficult to calculate and interpret” than the results of separate analyses. “When analyses are presented separately by sex,” CIHR explained, “this provides the clearest picture of where exposures might differ for men and women.”
In addition to strongly recommending that all data be analyzed separately for males and females, all three trainings emphasized the importance of separate reporting. All trainings recommended publishing raw data with the sex indicated for each sample as well as disaggregated demographic and descriptive data, which facilitates meta-analysis. But all three trainings went well beyond that minimum to recommend that all results be presented by sex as well, for example in separate graphs. The Primer even emphasized that reporting results “by sex” is a minimum requirement for compliance with SABV policy. Only the Primer mentioned being cautious about separate reporting, suggesting on one slide that sex-based analyses should be provided “as supplemental information, along with appropriate caveats, [which] allows you to share information that may inspire new hypotheses without overreaching your original study design.”
Reporting the sex of research participants and nonhuman animalsEach training mentioned the importance of reporting the sex of samples/participants. CIHR advised, “Always report the sex of animals, tissues, or cells used in the study.” LIBRA similarly stated, “Always report the sex of the cells, tissues, and animals you used, as well as the gender of human participants.” LIBRA also encouraged proper reporting, calling the practice of omitting sex information “sex insensitivity.” The NIH Primer noted that reporting sex is a requirement of some journals. Both NIH and LIBRA referred to the Sex and Gender Equity in Research (SAGER) guidelines, pointing out that they recommend sex be reported in the title of publications. NIH recommended that for single-sex studies, the word “specific” be included in the title, e.g., “Male-specific deficits in reward learning in a mouse module of alcohol use disorder,” even though a single-sex study cannot demonstrate that any finding is specific to one sex.
There was comparatively little coverage of reporting how sex was determined. The NIH Primer briefly advised researchers to “report operational definitions” of sex, emphasizing the contexts of cell culture and human studies in particular. LIBRA mentioned reporting operational definitions only in passing, in a single sentence inside a lecture. CIHR did not cover reporting definitions other than to recommend that researchers “properly identify” the sex of the animals or tissue/cell donor.
Reporting negative findingsAll three trainings emphasized that the results of sex comparisons should be reported even when null. CIHR stated, “Report what you find, including null findings related to sex differences,” and “Any sex differences or similarities found, including null findings, [should] be reported in resultant publications to reduce publication bias, enable meta-analysis, support the identification of confounding variables and advance understanding.” The NIH Primer admonished, “Remember, analyses that do not indicate the presence of a sex difference are just as important as those that identify a sex difference… Report not only when you have identified a possible difference, but when your analyses suggest no difference according to sex.” The Primer went on to say, “To avoid needless repetition of studies by other investigators, report when analyses indicate the presence of a sex difference and when analyses suggest no difference based on sex.” LIBRA similarly stated, “Sex- and gender-based analyses should be reported regardless of positive or negative outcome.” Although there was no explicit instruction about the statistical invalidity of accepting a null hypothesis, we noted caveats about assuming that a null result shows good evidence for a sex similarity. For example, LIBRA warned that “if you happen to observe no sex differences this does not mean that they are not present in the process under investigation.” NIH also stated that “A lack of information supporting a sex-based difference in a biological process is not evidence that no difference exists,” and instructed researchers to “consider reviewing epidemiological work in the subject area for any evidence of sex-skewed incidence, prevalence, or outcomes.”
Discussion of limitationsAs noted above, all three trainings endorsed exploratory subgroup analysis, even when underpowered, to test for potential sex differences. Only NIH mentioned the limitations of this approach. The Primer noted that authors must report whether sex differences were hypothesized a priori and whether the study was powered to detect sex differences, as well as explain that post-hoc findings are exploratory until replicated. NIH further stated that authors must “interpret and report findings within the specific limitations of the study’s design,” and “discuss appropriate generalizations as well as limitations.” Importantly, NIH recommended discussing “the potential influence of variables that interact with or are impacted by sex in your results.” Nonetheless, despite these caveats, there was a pervasive lack of specificity. No particular limitations were discussed, including those relevant to subset analysis – only that “subset analysis should be reported with appropriate restrictions.” Examples were not provided.
Talking to the mediaThe NIH Primer was the only training that referenced talking to the media. It noted that specific guidance about speaking to the media is lacking. It advised that when researchers do share their work with the public, they should be conservative and not go beyond what the data show.
Potential pedagogical issuesUneven levels of expertise assumedAlthough the majority of each training seemed to assume little experience with study design or handling of data, both the CIHR and NIH courses sometimes seemed uneven in their assumptions about audience. For example, although it did not seem to assume any statistical expertise elsewhere in the course, the Primer contained the following unexplained terms on a single slide in Module 3: “superiority,” “non-inferiority,” “equivalence of treatments,” “one-sided” vs. “two-sided t-tests,” “minimum clinically important effects,” “repeated measures,” “clusters,” and “correlations between measurements.” These terms were included in a complex figure on how to calculate power to detect a main effect of treatment; the figure did not address power to detect sex differences. A button linking to the “3R’s” for more information was not functional, leading to an HTTP 503 error. On a single slide in Module 4, which covered reporting, we noted the unexplained terms “biological replicate,” “pseudoreplication,” and “interim analysis,” again outside the context of SABV specifically. Although each of these terms might be accessible to certain subgroups of scientists, the level of the vocabulary was uneven with respect to the rest of the Primer, which took an elementary approach overall. In addition, although the SABV policy (and presumably the training) was intended to reach preclinical researchers, there were many references in the Primer to terms such as “drop-out rates,” “stratification” and “confidence intervals,” which are typically used in clinical research. CIHR and LIBRA were more internally consistent in the level of knowledge they assumed, although CIHR used some undefined statistical terms such as “multivariate regression analysis” and “second-level sub-group disaggregation.”
Presenting material only in quizzesA large percentage of the CIHR material consisted of quizzes. In most cases, the questions asked in the quizzes had not been covered by the preceding material; that is, the material was presented only in the context of a quiz. In those cases, CIHR seemed to expect learners to master the material by trial and error.
Interpretation of example dataNIH and LIBRA repeatedly asked learners to draw conclusions about a study’s findings on the basis of bar graphs alone, without the statistical results that should accompany the presentation of the data. In one of the LIBRA case studies, for example, conclusions were drawn without sufficient evidence: although no quantitative sex comparisons were presented, the commentary noted that “global demethylation is more pronounced in female cells.” Similarly, in the NIH Primer, example graphs were presented without the F or p values necessary to interpret the result. The NIH graphs sometimes suggested outcomes different from those stated in the commentary, e.g., whether effects were significant. In one particularly interesting example, the “same” data were graphed before and after disaggregating by sex. However, it was obvious that the two datasets could not be the same (Fig. 1).
Fig. 1
An impossible dataset. The NIH Primer illustrates the idea that when data from males and females are pooled, sex differences can be masked. (A) depicts a graph featured in a slide from the Primer Module 3 (see Fig. S1A). On this slide, which is part of a quiz, learners are asked to draw a conclusion about whether the intervention had an effect. No statistical results are presented. The “correct” answer is that the intervention had no effect. In the explanation of the correct answer, learners are told that such a result would be “evidence for the null hypothesis.” (B) depicts a graph from the next quiz question (see Fig. S1B), which claims to contain “the data from the same experiment disaggregated by sex.” Learners are again asked to draw a conclusion without seeing the results of statistical tests. The “correct” answer is that the intervention had an effect. Our analysis of the dataset presented in (B) (see Supplemental Methods) shows that the sex difference in the control group in (B) would be one of the largest quantitative sex differences ever described in any species (Cohen’s d = 23.24). After the intervention in (B), the sex difference flips to what would again be one of the largest ever measured, but in the opposite direction. (C) We reconstructed the dataset shown in (B) (see Fig. 1 Supplemental Methods and Table S3) and plotted the data pooled by sex with accurate error bars, showing the impossibility that the dataset in (A) could be the same as in (B)
There was some confusion, particularly in the NIH Primer, regarding the interpretation of ANOVA results. For example, Module 3 Lesson 4 of the Primer presented an example in which “the results of the two-way ANOVA indicated only the main effect of sex, no main effect of drug, and no interaction… In this case, females have a different response to the drug than males.” Absent a statistically significant sex-by-drug interaction, however, there would be no evidence that the females and males responded to the drug differently. A main effect of sex tells us that the outcome measure differed between sexes independently of the treatment, not that the difference was related to treatment (i.e., it was likely pre-existing).
Similar mix-ups between main effects, interactions, and post-hoc comparisons of means permeated the NIH Primer. For example, the Primer stated that comparisons of the outcome measure itself between males and females will indicate whether there is a “sex difference in the treatment” (presumably the response to treatment was intended). Further, as noted above, the training emphasized the importance of statistical power to detect sex by treatment interactions but the instructions on calculating power pertained only to the detection of main effects. The following text appeared near the end of the section on factorial designs (parenthetic statements added): “The ability of [factorial] analysis to determine the extent to which the outcome is altered by being male or female (main effect of sex) AND receiving drug or no drug (main effect of treatment) is invaluable to researchers examining the influence of sex on a potential treatment.” Note that “the influence of sex on a potential treatment” refers to the interaction, not the main effects; main effects do not give relevant information about sex-specific responses.
Endorsement of flawed research designs and interpretationsWe noted multiple endorsements of flawed experimental design and interpretation of results, particularly in the NIH Primer. One of the quizzes in the Primer, for example, asked learners to identify the best design for specifying the most effective dosage of a drug. The “correct” answer was a study with only two drug conditions: no drug (control) and drug (treatment). To find the most effective dose, however, more than one dose must be tested. Another part of the NIH training recommended pooling samples of the same sex together (i.e., in cell culture), which violates assumptions of statistical independence across sources of tissue and confounds sex with other variables, such as culture plate, making it difficult to isolate sex as a variable of interest. Finally, in Module 3, the Primer stated that “a statistical comparison would indicate evidence for the null hypothesis,” indicating a problematic interpretation of the assumptions and methodology underlying null hypothesis significance testing.
Other online coursesOur internet searches produced hits related not only to online training materials but also to other resources such as peer-reviewed literature reviews, opinion pieces, and government reports. Table S4 summarizes the most notable resources.
留言 (0)