Model Tuning or Prompt Tuning? A Study of Large Language Models for Clinical Concept and Relation Extraction
In the recent decade, natural language processing (NLP) has experienced a change from fully supervised learning to pretraining/fine-tuning, and eventually prompt-based learning [1] – where additional information, i.e., a prompt, was attached to the input to control the behavior of machine learning models. Prompt-based learning has demonstrated better learning abilities through large language models (LLMs). [1], [2], [3] At present, the performance of prompt-based learning highly depends on (1) the selection of the prompt types, i.e., hard/discrete prompts (manually crafted clear text) or soft/continuous prompts (trainable continuous embeddings), [1] and (2) the algorithms to adopt LLMs for downstream tasks, i.e., model tuning - updating the parameters of LLM models in finetuning, or prompt tuning - only updating the parameters of prompts while keep LLM parameters unchanged (i.e., frozen) in finetuning. Prompt tuning algorithms could unload researchers from labor-intensive prompt engineering and reduce computing costs by keeping LLMs frozen. Nevertheless, most existing works in clinical NLP are based on hard prompts using model-tuning; there is a lack of studies exploring the use of soft prompts and prompt-tuning.
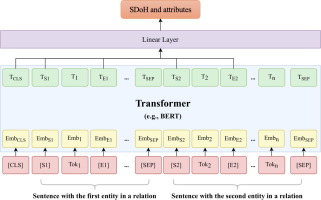
This study seeks to develop soft prompt-based learning methods to adopt LLMs for patient information extraction. We systematically examined 4 strategies including (1) traditional fine-tuning without prompts, (2) hard prompting with unfrozen LLMs, (3) soft prompting with unfrozen LLMs, and (4) soft prompting with frozen LLMs. We examined the 4 training strategies for clinical concept extraction and relation extraction using 2 clinical benchmark datasets and 7 pretrained models. This study provides valuable insights into the selection of prompting and training strategies in adopting LLMs for clinical concept and relation extraction.




留言 (0)