

記住我
Epilepsy is a neurological disorder characterized by epileptic seizures (Chang and Lowenstein, 2003; Fisher et al., 2014), which are often accompanied by intense shaking or convulsions. According to statistics from the World Health Organization, neurological disorders rank as the second leading cause of global mortality. It is estimated that an additional 5 million individuals are diagnosed with epilepsy worldwide annually (World Health Organization, 2022). Therefore, epilepsy deserves significant attention and focus to improve its prevention and treatment efforts. The unpredictability, suddenness, and recurrence of epileptic seizures can cause additional anxiety for individuals with epilepsy and their families. Epilepsy also has a negative impact on society, as the stigma and bias against individuals with epilepsy can lead to feelings of shame and social isolation for the affected individuals. This stigma can hinder societal development and progress. Therefore, epilepsy prediction and treatment became particularly important. Seizures are controllable with medication in about 70% of cases, so early prediction of epilepsy reduces the worry about epilepsy, as having enough period to stop a seizure before it occurs reduces the patient’s suffering to a great extent.
Seizure prediction is one of the hot topics in clinical research, which is a challenging task. Seizures are the result of excessive and abnormal neuronal activity in the cerebral cortex, so epilepsy can usually be detected by electroencephalography (EEG). EEG reflects the electrical activity of neurons in the brain, and more than 80% of people with epilepsy can be monitored for abnormalities by EEG. Therefore, it is of great value to analyze EEG in the diagnosis of epilepsy. With the development of modern science, a variety of methods have been developed to automatically predict seizures. Most of these methods are based on EEG analysis.
In the literature, there are several prediction methods that can be used to confirm the challenge of predicting seizures. The combination of manual feature extraction from time-series signals and traditional machine learning classifiers has indeed made significant contribution to epilepsy detection (Sharma et al., 2019). Lu et al. (2021) employed support vector machines for automatic classification of epileptic EEG signals. They chose sample entropy and Higuchi fractal dimension as features, and achieved 89.8% accuracy. Non-linear features show effectiveness in epilepsy detection or prediction. Manual feature makes the model easier to interpret and better able to capture the essential features of the data. It can also be customized for different research tasks and applications. Our purpose is to explore the prediction of epilepsy based on nonlinear features. Appropriate feature selection determines the accuracy of the system, but relying only on features and SVM cannot adequately access the hidden information of the data, requiring a combination of other techniques and methods. With the development of neural networks, various neural network methods are gradually being applied to the detection and prediction of epilepsy. Among these neural networks, recurrent neural networks, convolutional neural networks and graphical neural networks have become prominent. He et al. (2022) utilized a graph attention network as the front end to extract spatial features, and used a bidirectional long short-term memory network as the back end to capture temporal relationships. As a result, the seizure detection accuracy on CHB-MIT is 98.52%. Yu et al. (2022) utilized manual features and hidden deep features for complementary fusion through the feature fusion module. These fused features were then input into a Multiplicative Long Short-Term Memory network, achieving an average sensitivity of 95.56% and a false positive rate of 0.27/h. In addition, neural networks have been proved to be effective in epilepsy detection or prediction. we will further study neural network epilepsy prediction. Singh and Malhotra (2022) using the spectral power and average spectral amplitude of each band as the characteristic inputs of the two-layer LSTM, and achieved 98.14% accuracy, 98.51% sensitivity and 97.78% specificity. Zhang et al. (2021) combined with multidimensional sample entropy and Bi-LSTM, the seizure prediction accuracy was 80.09% and the FPR was 0.26/h. Tuncer and Bolat (2022) using EEG instantaneous frequency and spectral entropy as features, Bi-LSTM can also be used to classify seizures well. The results show that the combination of artificial features and Bi-LSTM still has high efficiency in predicting seizures. Prathaban and Balasubramanian (2021) reconstructed the EEG with sparse and converted it into a two-dimensional image. Then, in order to explain the relationship between channels, the 2D image is transformed into a three-dimensional image of time, signal value and channel representation, and a 3D optimized convolutional neural network was used to predict epileptic seizures. It shows that epilepsy prediction based on the 3D neural network can be realized. However, it should be noted that features with high redundancy can affect the performance of the model. Only by selecting features and reducing redundancy between features can we improve the calculation efficiency of the model and optimize the performance of the model. Xing et al. (2022) segmented EEG signals into five frequency bands: α, β, γ, θ, and δ, calculated their power spectral density values, merged spatial information from multiple electrodes, and then applied them to a 3D neural network, a bidirectional long and short-term memory network. This method successfully realized the emotion classification. The study also incorporated spatial information from electrodes into the analysis of emotion recognition. The principle of EEG acquisition is the waveform of the potential difference between two electrodes on the scalp, so the position of the electrodes reflects the state of other adjacent electrodes. This means that we can get some information about the EEG signal from the spatial information of the electrodes. Therefore, we will select features, combines manual features, 3D neural network, and Bi-ConvLSTM3D to form a neural network structure model that preserves spatial information: P3DCNN-BiConvLSTM3D-Attention3D. Using this model can better intervene epileptic seizures and reduce the negative impact of epilepsy.
The article is structured as follows: In Section 2, we provide a brief description of the dataset, signal pre-processing, selected feature types, mRMR algorithm, and 3D feature construction. Section 3 presents an overview of the EEG spatial information modelling, P3DCNN-BiConvLSTM3D-Attention3D model application, and evaluation metrics. We then discuss and compare the results with previous studies. Finally, we provide our conclusions.
2 Materials and methodsEpileptic signals are essentially nonlinear, so nonlinear characteristics are part of the research. Using a single feature may not be able to effectively capture epilepsy-related information, and too many features will reduce the efficiency of the algorithm. Therefore, multiple features are used to represent the features of epileptic signals. The Max-Relevance and Min-Redundancy algorithm (mRMR) is used to select important non-linear features while maximizing their relevance and minimizing redundancy.
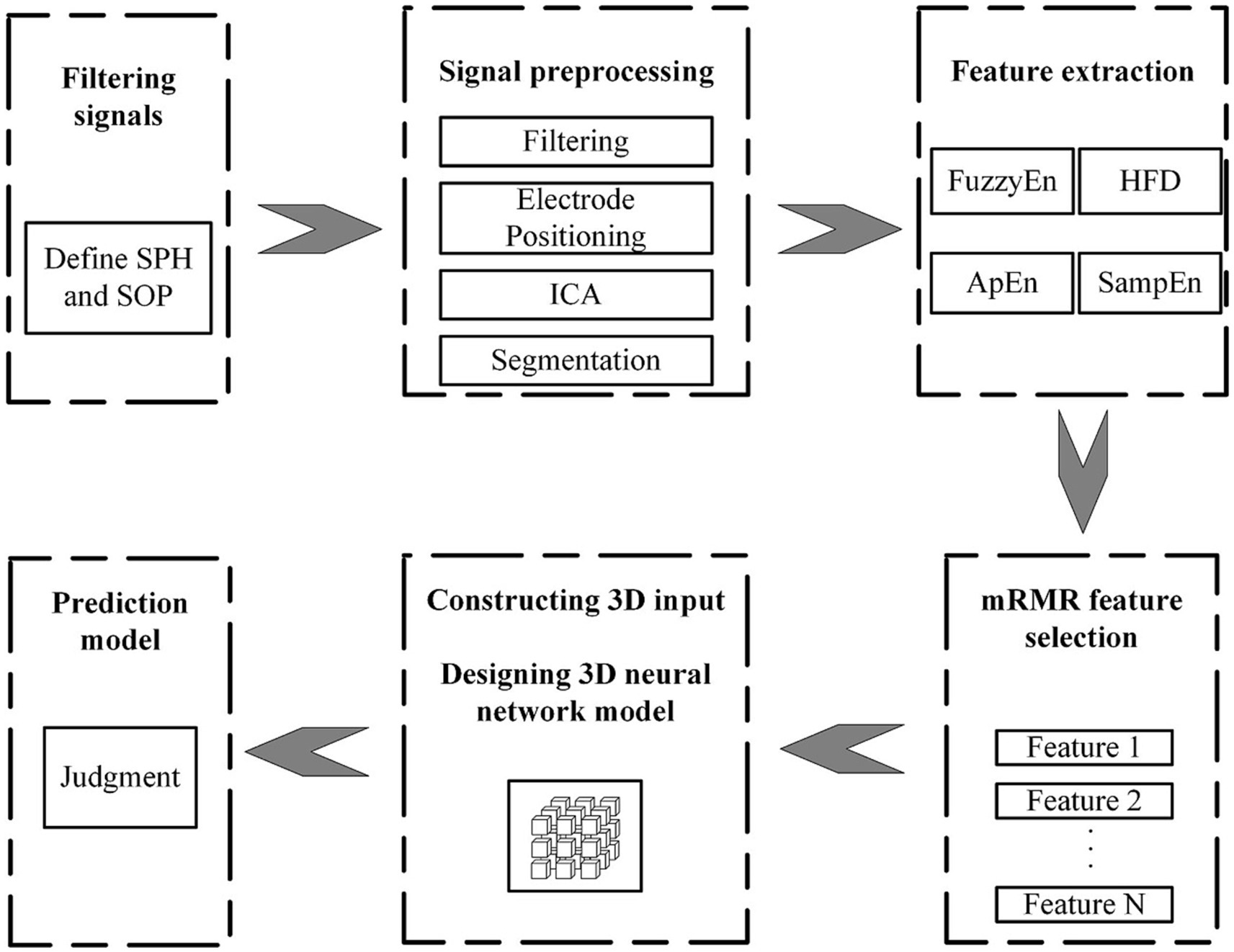
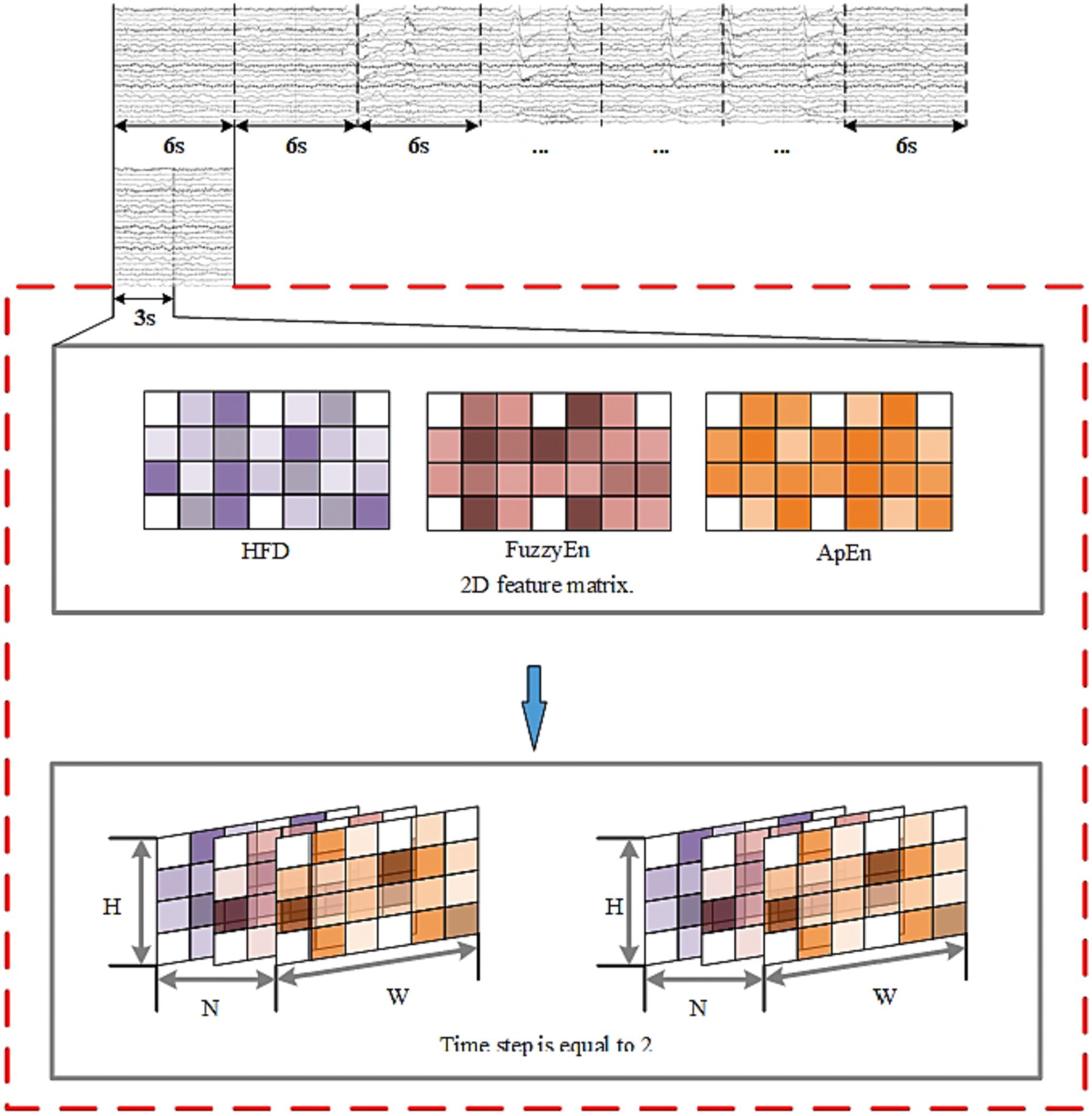
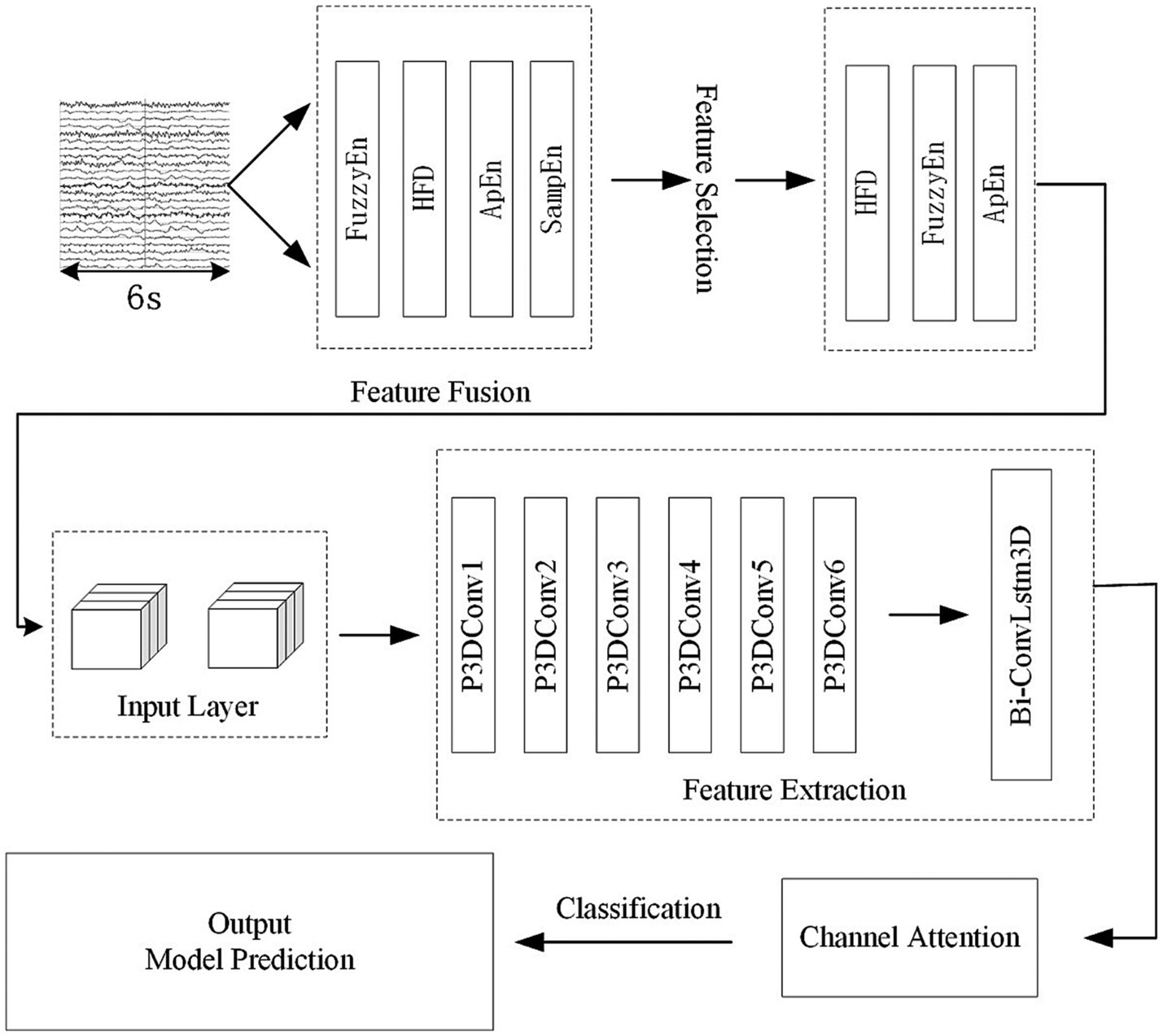
Figure 1 shows the algorithmic process of this study. The process begins with the selecting and preprocessing of EEG signals from the dataset. Following this, several feature are extracted. Apply the mRMR algorithm to obtain highly significant features and then combine them with the spatial relationship of the electrode channels to create 3D features with spatial features. Input 3D features into the P3DCNN Biconvlstm3D model, and finally add the channel attention mechanism to improve the performance and efficiency of the model. The KNN and SVM are used to conduct synchronous comparison experiments.
Figure 1. Flow chart of multi feature selection and temporal spatial epilepsy prediction.
2.1 CHB-MIT datasetThe present work used a public dataset created jointly by Children’s Hospital Boston (CHB) and the Massachusetts Institute of Technology (MIT). The dataset is called CHB-MIT. The dataset contains 24 cases, of which 21 cases and 1 cases were from the same female patient, and an interval between data collection was one and a half years. The participants included 5 males ranging in age from 3 to 22 and 17 females ranging in age from 1.5 to 19. The dataset consists of 967.55 h of scalp EEG records, including 178 recorded seizures.
2.2 Preprocessing of EEG signalsDue to the low amplitude of EEG signals, they are susceptible to external environmental interference, such as powerline frequency (60 Hz or 50 Hz) interference. In addition, physiological activity can introduce artifacts into EEG signals, mainly including eye artifacts and muscle artifacts caused by eye movement and blinking. Therefore, in order to obtain relatively clean EEG signals, signal preprocessing must be done before feature extraction. Firstly, the EEG signals is filtered by using a band-pass filter in the range of 0.5 to 75 Hz. Because this study needed to consider the influence of electrode placement, it is very important to locate the electrodes in the preprocessing phase. Use the pop_chanedit function in EEGLAB to locate scalp electrode. The EEG signals were processed using EEGLAB’s Independent Component Analysis (ICA) through the pop_runica function. Use pop_selectcomps function to remove these components manually to obtain relatively clean EEG. The processed EEG signals were subsequently segmented.
2.3 Feature type selectionNonlinear dynamics analysis methods may better suit for analysis of the complex and nonlinear EEG waveform recorded from the brain than traditional linear methods, such as time and frequency domain analysis. Nonlinear features can effectively capture the characteristics of biological systems, and can also be used in the analysis of EEG (Acharya et al., 2013). Due to the instability and non-stationary of epileptic signals, we extract the following non-linear features from the EEG signals: Higuchi Fractal Dimension (HFD) (Sharma and Joshi, 2022), Approximate Entropy (ApEn) (Srinivasan et al., 2007), Sample Entropy (SampEn) (Arunkumar et al., 2016), and Fuzzy Entropy (FuzzyEn) (Xiang et al., 2015), FuzzyEn works equally well for fuzzy time series and can describe the degree of ambiguity of the series (Versaci and Morabito, 2003). These nonlinear features were subjected to feature selection.
Fractal dimension is a measure used to quantify the complexity of signals. In this study, we used HFD to characterize the fractal dimension of the signal. HFD is computed by the following steps (Higuchi, 1988):
Step 1: constructing a new time series as Eq. (1):
xmk=xm,xm+k,xm+2k,…,xm+N−mk×k (1)Step 2: Eqs. (2) and (3)can be used to calculate the duration of the time series.
Lmk=1k∑i=1N−mkxm+ik−xm+i−1kN−1N−mk·k (2) Lk=1k∑m=1kLmk (3)Step 3: the HFD is calculated as follows Eq. (4):
ApEn is an index to measure the complexity of time series. It is a nonlinear dynamics parameter, which is used to measure regularity and volatility of time series by comparing the similarity of template vectors. ApEn is computed as below (Pincus, 1991):
In general, for a time series xn=x1,x2,..,xN consisting of N data points, the method for calculating ApEn is as follows:
First, constructing an m-dimensional vector X1m,…,XN−m+1m , where Xim=xi,xi+1,…,xi+m−1,1≤i≤N−m+1 .
Second, define the distance dijm between vectors Xim and Xjm as the Chebyshev distance as Eq. (5) which is the maximum absolute difference between their corresponding elements.
dijm=DchebychevXimXjm=maxk=0,…,m−1|xi+k−xj+k| (5)Third, count the number of j for which dijm is less than or equal to the similarity threshold r , and define the approximate count ci . For 1≤i≤N−m+1 , cim,r is designated as the ratio of the approximate count to the total count as Eq. (6).
cim,r=1N−m+1ci (6)Fourth, define ϕm,r as Eq. (7):
ϕm,r=1N−m+1∑i=1N−m+1lncim,r (7)Fifth, increase the dimension to m+1 and obtain ϕm+1,r .
Sixth, define ApEn as Eq. (8):
ApEnmr=ϕm,r−ϕm+1,r (8)SampEn is an improvement on ApEn. The following steps are used to calculate SampEn (Richman and Moorman, 2000):
For a sequence xn , calculate the maximum distance between Xi and Xjas dXi,Xj=maxk∈0,m−1xi+k−xj+k . Then calculate the ratio relationship: Bimr=1N−mnumdXi,Xj<r , where r is the similarity threshold. Bm=1N−m+1∑i=1N−m+1Bimr . Next, increase the dimension to m+1 and obtain Bm+1r . The formula for calculating SampEn is as Eq. (9):
SampEnmrN=−lnBm+1rBmr (9)Bm is never equal to zero. This is because the distance between each pair of vectors Xi and Xj is greater than zero, and the value of Bimr is always greater than zero. So the value of Bm is always greater than zero.
FuzzyEn is used to measure the uncertainty or information content of fuzzy sets or fuzzy systems. FuzzyEn is defined as Chen et al. (2007):
To calculate the mean-removed template vector, Xi=xixi+1…xi+m−1T−x¯i, where x¯i=1/m∑j=0m−1xi+j . The Gaussian function definition is employed Eqs. (10–12):
Φmr=1N−m+1∑i=1N−m+11N−m∑j=1,j≠iN−m+1Di,jm (10) Di,jm=exp−di,jmnr (11) di,j (12)m=dXi,Xj=maxk∈0,m−1|xi+k−x¯i−xj+k−x¯j|The formula for computing FuzzyEn is as follows Eq. (13):
FuzzyEnXmr=logΦmr−logΦm+1r (13) 2.4 Feature filtering based on mRMRThis algorithm is to find a set of features in the original feature set that have the max-relevance with the final output result, but have the min-redundancy between the features. In order to minimize the redundancy of features and obtain the most information with the least features, we use the mRMR method to select feature (Peng et al., 2005). Using this algorithm, we can choose the features with the highest information, thus improving the performance and accuracy of the model. The experimental process is as follows: we subject pre-processed EEG signals to feature extraction and use the mRMR method to select feature group with the max-relevance and min-redundancy. Effective feature selection can extract highly correlated features for epilepsy detection, while eliminating those features with poor correlation. The combination of these features better captures the integrity of the signal, reduces the complexity and improving the efficiency of network learning. This method achieves the highest accuracy with fewer features, mRMR is computed by the following steps (Peng et al., 2005):
Define the mutual information between xi and xj as Eq. (14):
Ixixj=∬pxixjlogpxixjpxipxjdxidxj (14)Using mutual information, the mRMR criterion can be obtained as Eqs. (15, 16):
maxDSc,D=1S∑xi∈SIxic (15) minRS,R=1S2∑xi,xj∈SIxixj (16)Where S represents the feature set, with |S| being the dimensionality. Ixic represents for the mutual information between feature xi and target c , while Ixixj represents for the mutual information between xi and xj . D and R denote the relevance and redundancy, respectively.
The mRMR algorithm considers both of the above criteria as Eq. (17):
maxΦDR,Φ=D−R (17)To solve the equation above, we use an incremental search algorithm. That is, on the basis of the features that have been selected, find the one that maximises the Eq. (18) in the remaining feature space. In fact, it is equivalent to computing and then sorting each of the remaining features.
maxxj∈X−Sm−1Ixjc−1m−1∑xi∈Sm−1Ixixj (18)In the process of feature selection, the mRMR algorithm calculates feature importance based on HFD, ApEn, SampEn and fuzzy, and selects the most important variables one by one. Figure 2 shows the feature importance scores obtained by using the mRMR algorithm.
Figure 2. Importance score of each feature.
According to the results in Figure 2, it is obvious that this group of features are arranged in descending order of importance score: HFD, FuzzyEn, ApEn, and SampEn. It should be noted that SampEn has the lowest score, indicating that it has higher redundancy and relatively low correlation with other characteristics.
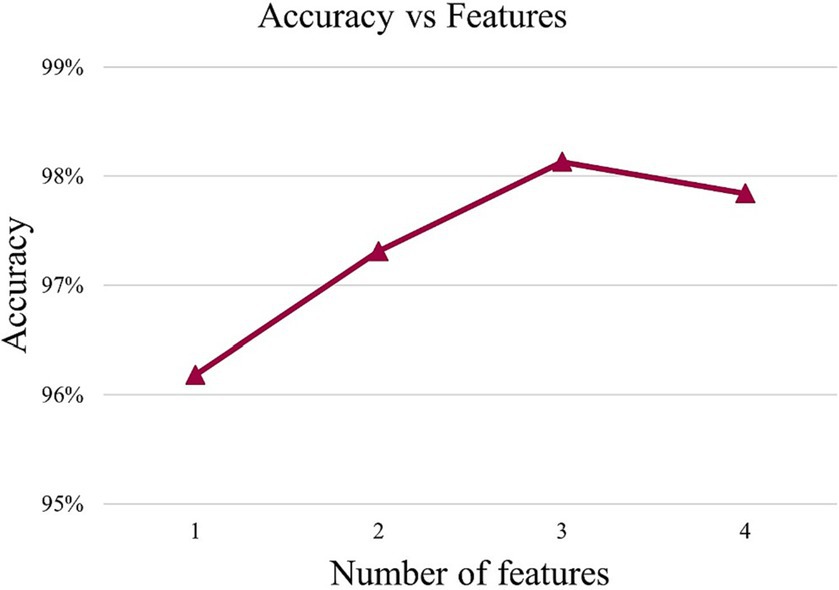
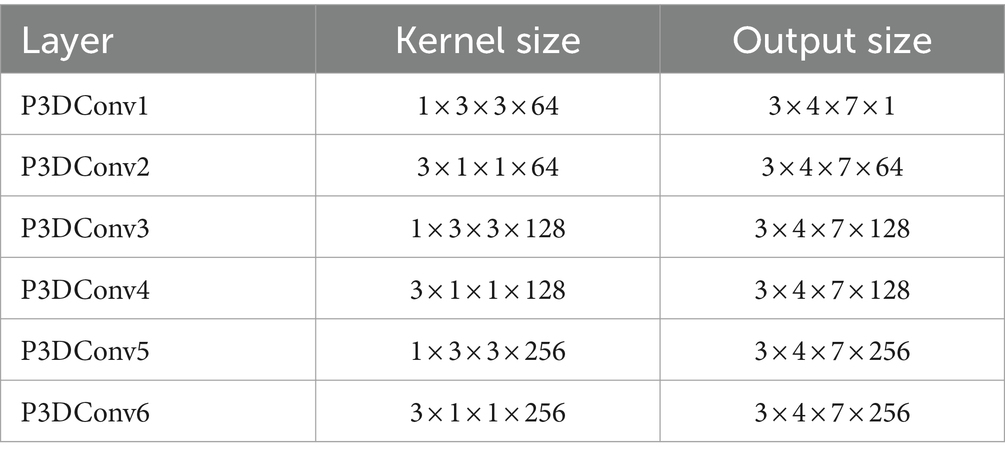
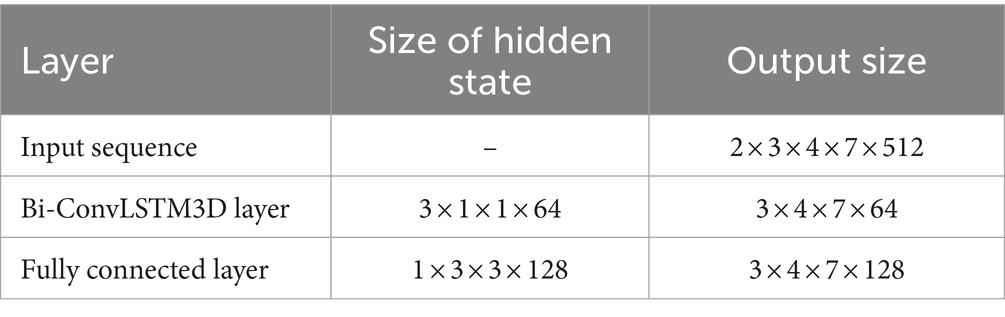
In order to find the appropriate number of features, this article conducted experiments using different numbers of feature sets from high to low importance scores in HFD, FuzzyEn, ApEn, and SampEn. By comparing the effects of different feature numbers on the accuracy of the model, the optimal feature number is determined, as shown in Figure 3. It can be observed that with the increase of the number of features, the accuracy of the model is also improves, reaching the highest point at three features. However, with the addition of the fourth feature, the accuracy of the model drops. Therefore, it is very important to strike a balance between minimizing redundancy and maximizing relevance in the process of feature selection to ensure the best prediction performance. The effect of Figure 3 also reflects the correctness of the results of Figure 2. The model chosen is also the P3DCNN-BiConvLSTM3D-Attention3D model proposed in present work, which is selected using accuracy as an evaluation metric. The parameter settings are shown in Tables 1, 2.
Figure 3. Accuracy values under different features.
Table 1. Pseudo 3D convolution feature extraction architecture.
Table 2. 3D RNN feature extraction architecture.
In conclusion, HFD, FuzzyEn and ApEn have been chosen as the features used in the experiments. The selected multiple features were combined with the 2D electrode channel spatial feature matrix. To normalize the data, import the StandardScaler class from the scikit-learn library and use the fit_transform method.
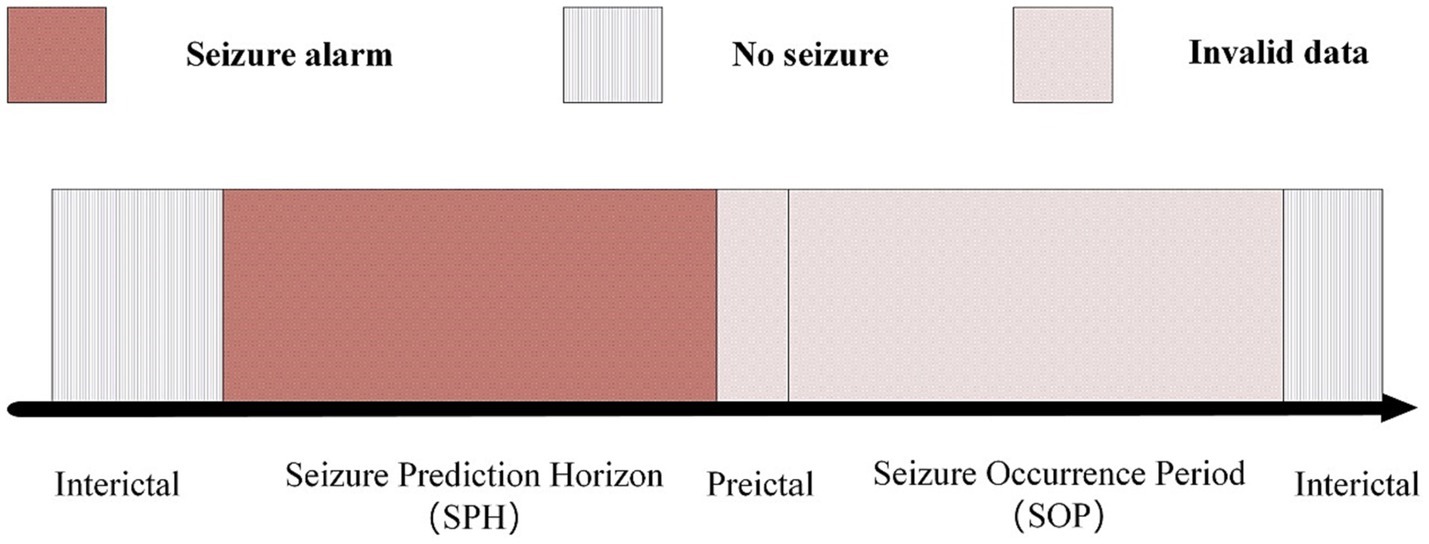
3 Epileptic-states classificationAccording to the EEG records of epileptic patients, their condition can be divided into two periods: the interictal period and the Seizure Occurrence Period (SOP). The interictal period represents to the time when the patient is in a normal state, and the SOP represents to the time range when the patient has epileptic symptoms. The main goal of epilepsy prediction is to detect seizures within the range of Seizure Prediction Horizon (SPH). An appropriate SPH should include an appropriate time range for taking adequate intervention or preventive measures before actual seizures. A long prediction range can cause patient anxiety and pose a challenge to using neural network prediction models, while a short prediction range may result in insufficient preparation time for patients and healthcare providers, ultimately failing to achieve the goal of epilepsy prediction. Achieving an appropriate balance is crucial in epilepsy prediction.
Truong et al. (2018) established the time interval of SPH from 5 min before the actual seizure occurrence. Within this period, patients were provided only 5 min to prepare. To provide ample time for both the physician and the patient, we defines the SPH range as 15 min prior to the seizure up to 5 min before the seizure itself, as illustrated in Figure 4.
Figure 4. Epilepsy different stages state diagram.
In present work, positive samples are retrieved during the 15 to 5 min interval leading up to seizure onset, as seizures are likely to occur during the following 15 min. Negative samples are segments without signs of imminent seizure within 15 min. The number of positive and negative samples of the dataset used in CHB-MIT was 11,300:11,400, which was generated because the time window used in this study was 6 s and each patient had a large number of EEG recordings, each recordings is at least two hours. To balance the positive and negative samples, the same 1:1 positive and negative samples were used for each patient.
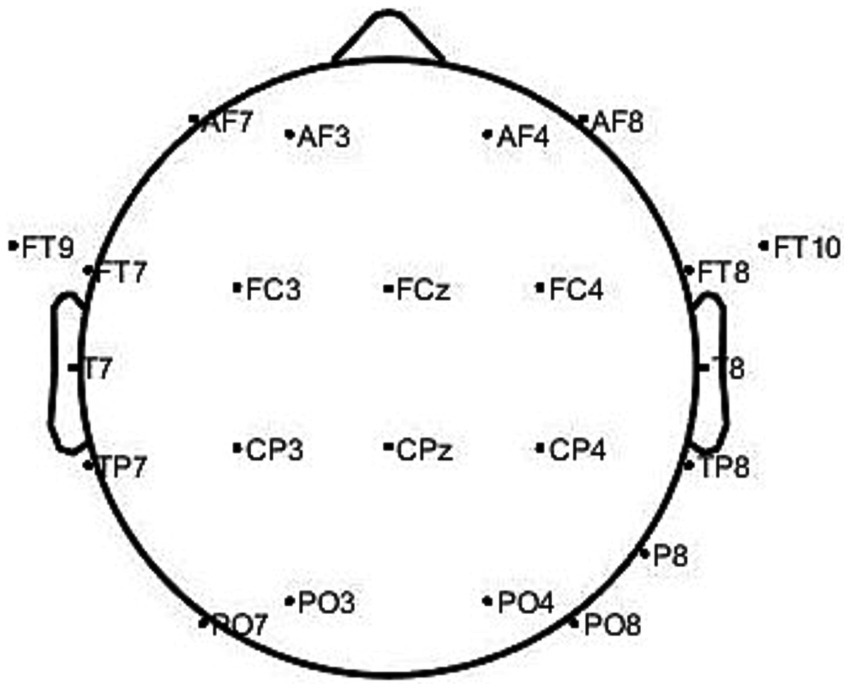
3.1 Three-dimensional feature construction of EEGThe CHB-MIT uses 23 electrodes for recording, which conforms to the positioning and naming of the international 10–20 system for EEG electrode placement standards. The dataset’s electrode names are as follows: AF7, AF3, AF4, AF8, FT9, FT7, FC3, FCz, FC4, FT8, FT10, T7, T8, TP7, CP3, CPz, CP4, TP8, P8, PO7, PO3, PO4, and PO8. Figure 5 shows a mapping of the actual spatial distribution of these scalp electrodes on the head.
Figure 5. 23 electrodes scalp localization map.
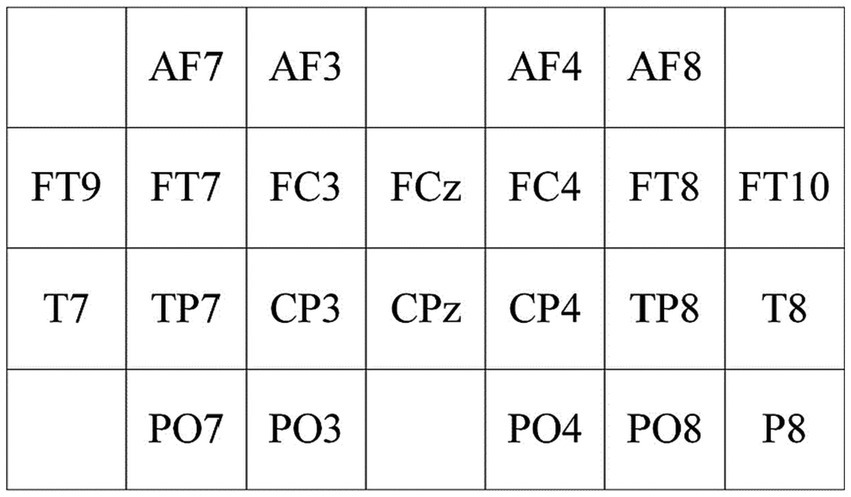
To extract spatial features between scalp electrodes, a spatial feature matrix with a 4 × 7 two-dimensional electrode channel is designed based on Figure 5, as illustrated in Figure 6. From Figure 6, the relative spatial relationships between different electrodes can be clearly understood.
Figure 6. 2D electrode channel positioning matrix diagram.
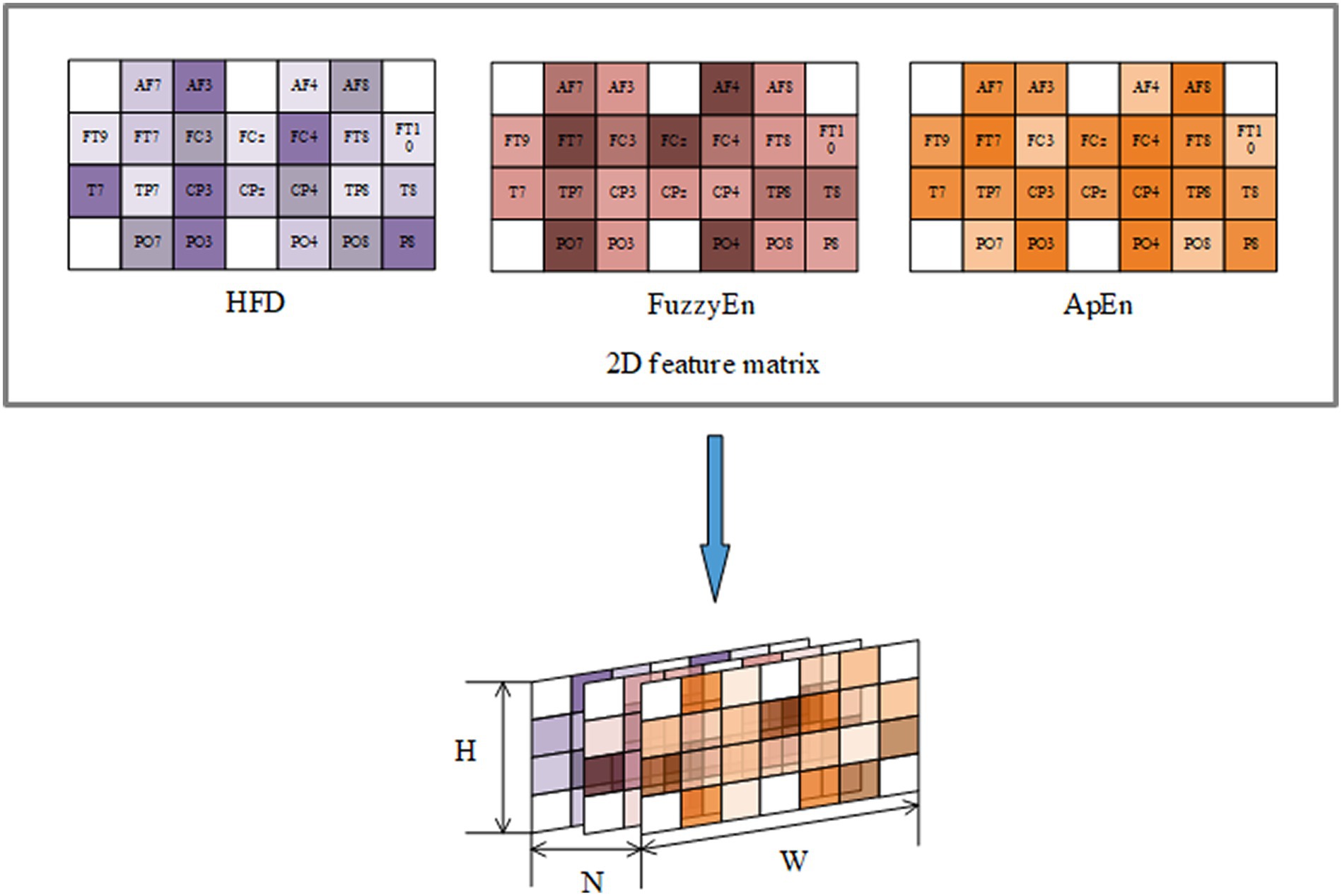
To represent the EEG signals from a multi-feature perspective, the selected features were combined into a feature set: By arranging the 2D matrices of each feature after StandardScaler transformation, can obtain a 3D feature input composed of three features as illustrated in Figure 7. H represents the height of the matrix set to 4, W represents the width of the matrix set to 7, and N represents the number of selected important features, which is 3 in this case.
Figure 7. 3D feature map.
3.2 Pseudo-3DCNN structure learningThe proposed work utilizes a pseudo-3D CNN merged with a bidirectional ConvLSTM3D as the primary algorithm. By using 3D neural networks, the algorithm can preserve the electrode space information and information from multiple features. Assuming a conventional 3D convolutional kernel size is k∗k∗b , where k is the spatial dimension of the filter and b is the feature dimension of the filter, 3D convolution is computationally expensive and memory-intensive when learning features. In order to solve this problem, we can understand a 3D convolutional filter with a size of k∗k∗b as a k∗k∗1 convolutional filter for 2DCNN and a 1∗1∗b convolutional filter for 1DCNN. The k∗k∗1 convolution filter is used to obtain spatial information, while the 1∗1∗b convolution filter is used to obtain information about nonlinear characteristics. This method is called pseudo-3D (Qiu et al., 2017). In this study, we used pseudo-3D to extract EEG information from multiple dimensions, including spatial, nonlinear, and temporal. This not only reduces the computation and complexity of 3D convolution, but also realizes a more sensible feature extraction process. In order to extract the feature information of each nonlinear feature, each feature uses a convolution kernel with the size of k∗k∗1 . Then, a convolution kernel of the size 1∗1∗b is used to extract the information between these features. Pseudo 3D networks can adopt different convolution kernel sizes, stride sizes, and padding methods in both temporal and spatial dimensions to meet different needs.
3.3 P3DCNN-BiConvLstm3D-Attention3D modelIt is equally important to extract temporal information for EEG while extracting spatial and feature information. Traditional BiLSTM is usually used to capture temporal correlations when processing temporal data, but it cannot effectively preserve spatial information features in the data. In contrast, Bi-ConvLSTM3D can simultaneously extract spatial relationships and temporal correlations from the data. This type of network is particularly suitable for the data in this study and can better handle 3D type data. Therefore, this study used Bi-ConvLSTM3D.
The purpose of this study was to determine whether the EEG signals belonged to SPH segments. Segments from 15 min before the seizure to 5 min before the seizure were designated as positive samples, and the remaining segments were designated as negative samples. For continuously recorded EEG signals, the data need to be segmented. In this paper, the EEG data were segmented into 6-s segments using a non-overlapping sliding window method.
The algorithm flow is illustrated in Figures 8–10 and the steps of alogrithm as Eqs. (19–24).
Figure 8. EEG segmentation and 3D feature construction.
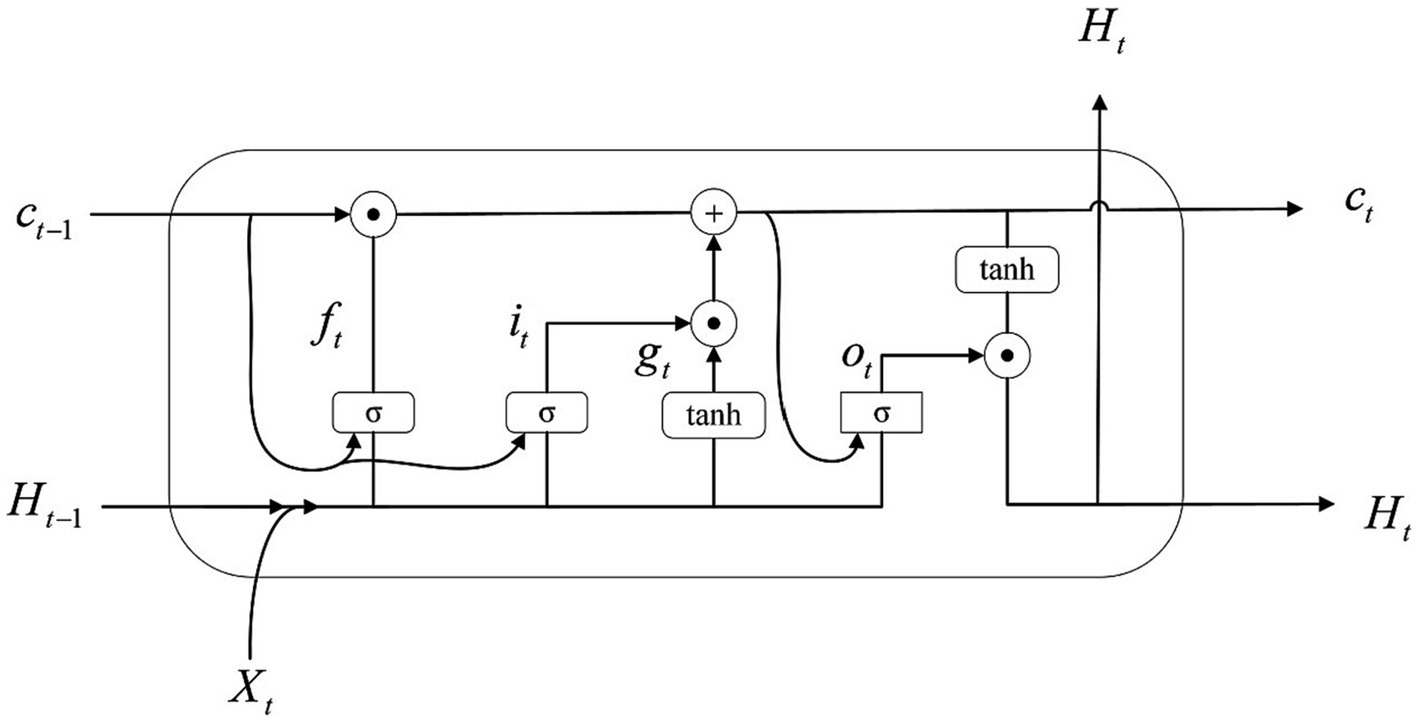
Figure 9. the structure of ConvLSTM3D cells.
Figure 10. Overall architecture of the model.
ConvLSTM3D is defined as Li et al. (2022):
it=σWXi∗Xt+WHi∗Ht−1+Wci⊙ct−1+bi (19) ft=σWXf∗Xt+WHf∗Ht−1+Wcf⊙ct−1+bf (20) gt=tanhWXc∗Xt+WHc∗Ht−1+bc (21) ct=ft⊙ct−1+it⊙gt (22) ot=σWXo∗Xt+WHo∗Ht−1+Wco⊙ct+b0 (23) Ht=ot⊙tanhct (24)Where Xt represents the three-dimensional characteristics of each time window, and the Ht represents the hidden state. σ represents the Sigmoid function, and i,f,o correspond to the input gate, forget gate, cell gate (Li et al., 2022). The weights and biases indexed by X,H,i,f,o,c are learned through backpropagation. The symbol ⊙represents matrix multiplication. The symbol ∗represents the convolution operation. Figure 9 illustrates the details of this implementation.
The whole model includes the construction and input of three-dimensional EEG, spatial and nonlinear feature extraction, temporal feature extraction, channel attention mechanism and classifier. The training process is as follows: Use the features selected by mRMR to construct 3D features. The time-step is set to 2 and each step lasts for 3 s. The time distribution layer is used to wrap the pseudo-3DCNN, which can independently apply the layers or networks of the neural network to each time step of the sequence. We use Keras’ TimeDistributed layer to achieve this function. Then, the data is extracted through a temporal feature extraction layer to obtain temporal correlations. Finally, useful channels are enhanced by the 3D channel attention mechanism, and then it is sent to the full connection layer to determine the category of data segments. Table 1 illustrates the architecture of the pseudo-3D CNN layers; the temporal feature extraction layer takes two 3D blocks from the output of the convolutional layers as input, and the Bi-ConvLSTM3D layer captures temporal features and spatial information while preserving spatial information. Table 2 illustrates the architecture of RNN.
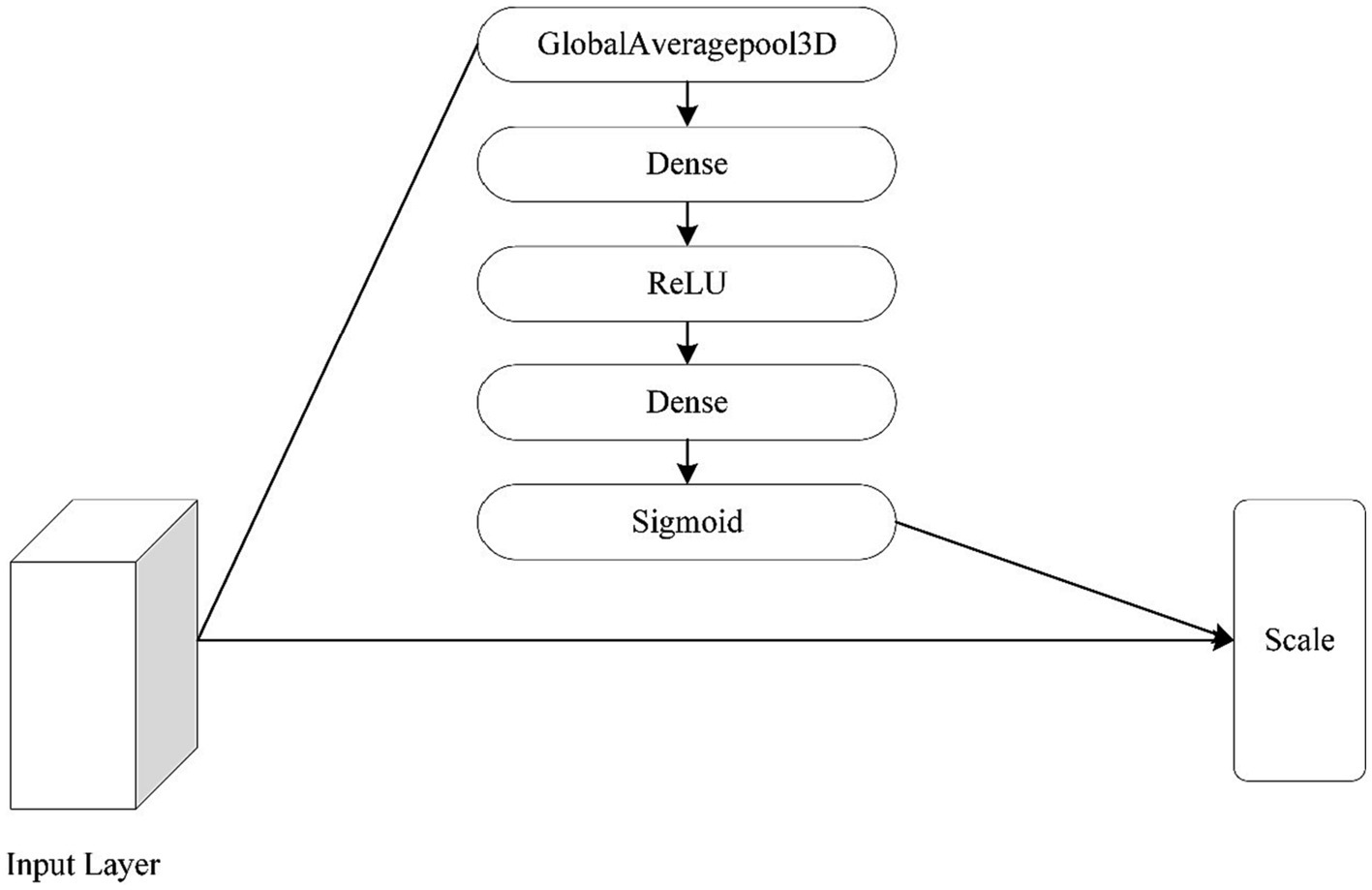
The attention mechanism was also changed to a 3D type of attention mechanism, as the focus of this paper is on the 3D module. The specific operation of the channel attention mechanism is as follows: Squeeze-Excitation-Scale (Hu et al., 2018). The squeeze is the use of global average pooling to compress the three-dimensional features of each channel into a real number. The excitation is to generate a weight value for each channel, use two fully connected layers and an activation layer to construct the correlation between channels, and output the same number of weights and channels. The Scale is the process of weighting the active weights to each channel. Figure 11 shows the network structure of the channel attention mechanism.
Figure 11. The architecture of convolutional block attention module.
In the P3DCNN model, batch normalization is performed after every two pseudo-3DCNN layers. In this paper, the number of parameters for pseudo-3DCNN is 364,720, the number of parameters for Bi-ConvLSTM3D is 1,050,624, and the number of parameters for Attention3D is 66,112.
3.4 Evaluation criteriaIn present work, the performance of the classification model is evaluated using the cross-validation method, the main idea of which is as follows: for all the data, divide it into k subsets of unrelated samples, i.e., D=D1∪D2∪…∪Dki,Di∪Dj=∅i≠j , and then each time select a subset of samples to be used for testing, and the rest of the data are all used for training, and after k times of training in this way, average the k results and calculate the final result. In this paper sets k to 5. And independently conduct five 5-fold cross-validation to obtain the average ACC and STD to evaluate the performance of the model.
Choosing appropriate evaluation criteria is beneficial for enhancing the credibility of model performance. In addition, to evaluate the effectiveness of the epilepsy prediction models in this study, accuracy (Acc), sensitivity, precision and specificity were used as evaluation metrics, these metrics as Eqs. (25–28).
Acc=TP+TNTP+TN+FP+FN (25) Sensitivity=TPTP+FN (26) Precision=TPTP+FP (27) Specificity=TNFP+TN (28)Where TP, TN, FP, FN represents true positives, true negatives, false positives, and false negatives.
4 Results and discussionThe proposed model in this paper is compared with other baseline methods on the CHB-MIT dataset. The details and parameters of these methods are as follows.
SVM: Support Vector Machine is a supervised machine learning model for general linear classification. It is widely used for both classification and regression tasks. SVM maps the feature vectors of instances into points in space and then separates these points with a hyperplane for classification. SVM is suitable for small to medium-sized datasets, as well as nonlinear and high-dimensional classification problems. Since this study involves a three-dimensional feature structure, SVM was chosen as one of the baseline methods. The kernel of SVM is set to ‘rbf’, and the decision_function_shape is set to “ovo”.
K-Nearest Neighbors (KNN): The basic idea of this algorithm is to compare the attribute features of the test dataset with the corresponding attribute features in the training dataset. In the training dataset, it finds the k nearest “neighbors” and determines the class of the test dataset sample based on the majority class among these k neighbors. In this comparative experiment, the value of n_neighors used for KNN is set to 5, and the metric is set to ‘minkowski’.
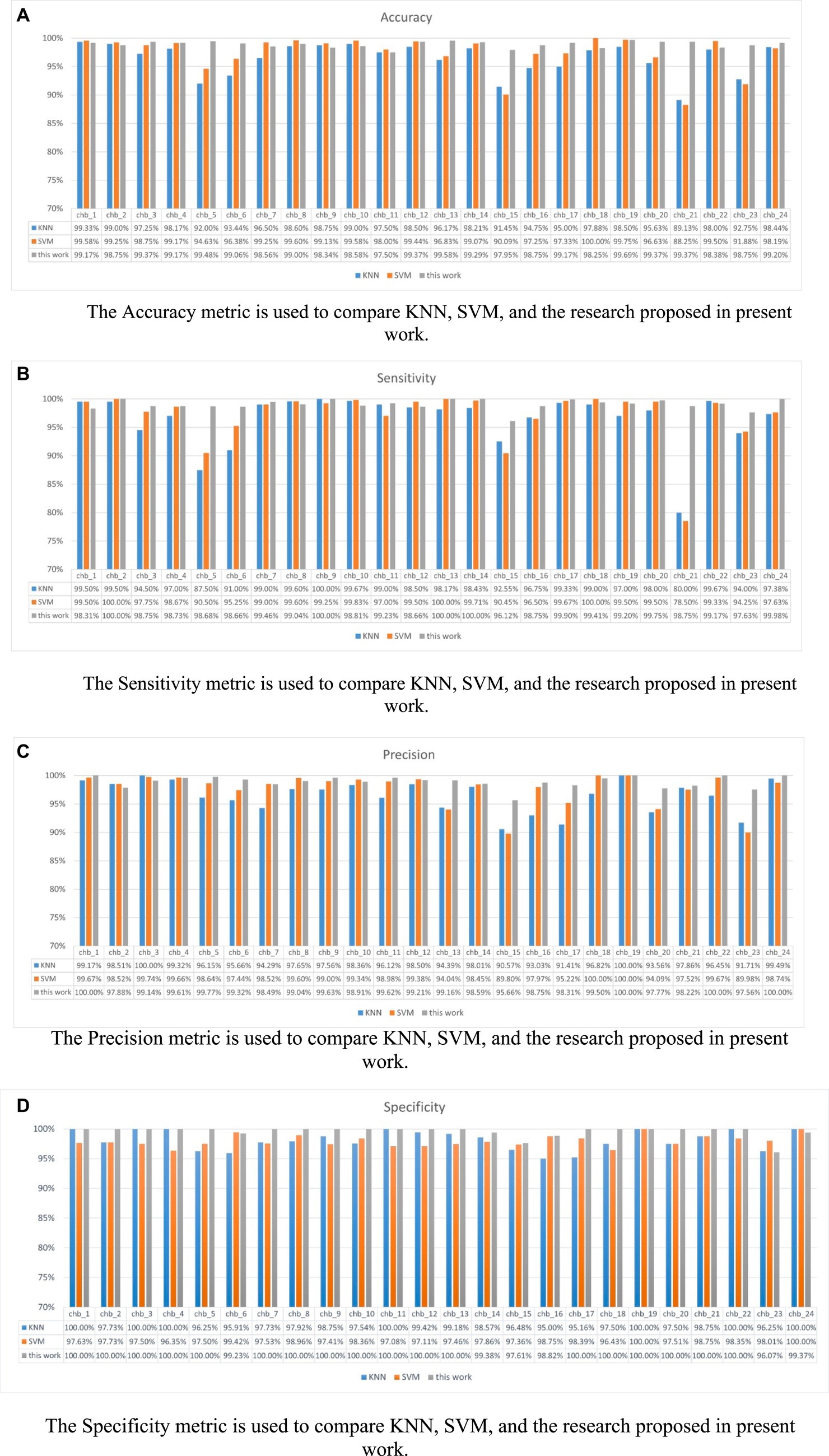
Figure 12 shows the performance of KNN, SVM, and P3D-BiConvLstm3D-Attention3D on the CHB-MIT dataset. From Figure 12, it can be observed that the proposed model in this study demonstrates effectiveness and generalizability on the CHB-MIT dataset. The top two rows and the last row of Table 3 depict the average ACC and STD of these methods. We can observe that compared with the other baseline methods, our model achieves the highest ACC and the lowest STD. Our model has an accuracy of 98.13%, which is 1.72% and 0.74% higher than KNN and SVM, respectively.
Figure 12. Shows the metrics for each subject under different models. (A) Accuracy (B) Sensitivity (C) Precision (D) Specificity. (A) The Accuracy metric is used to compare KNN, SVM, and the research proposed in present work. (B) The Sensitivity metric is used to compare KNN, SVM, and the research proposed in present work. (C)
留言 (0)