
記住我
Working memory (WM) is crucial for preparing and organizing goal-directed behaviors, with its functions of storing and manipulating incoming information. This process is capacity-limited, demanding a balance between stability (preserving the WM content from irrelevant information) and flexibility (updating WM with relevant information) (Trutti et al., 2021). It involves three temporal subprocesses: encoding, maintenance, and retrieval. Over the years, various models of WM functioning have been created, but the new ones are based more on the dynamics of the ongoing processes. The dynamic-processing model of working memory (Rose, 2020) assumes that relevant information is retained by creating representations through recurrent activity and/or strengthening the synaptic weights between neurons. These processes are very dynamic and context-dependent. One of the leading hypotheses in functional neuroimaging studies on false memory retrieval is the sensory reactivation hypothesis. It suggests that memory retrieval reactivates the processes from the encoding stage, with true memories involving activation of sensory areas (see Abe, 2012). However, recent findings indicate that content representations during retrieval differ from those during encoding. Memory retrieval appears to be more of a constructive and dynamic process involving the frontoparietal cortex, rather than just the reactivation of the sensory cortex as suggested by the sensory reactivation hypothesis (see Favila et al., 2020 for a review). To investigate the dynamic of working memory processes, we designed an fMRI experiment with four visual working memory tasks: two with visuospatial and two with verbal stimuli based on the Deese–Roediger–McDermott (DRM) paradigm (Deese, 1959; Roediger and McDermott, 1995), and additionally resting-state procedure. The DRM paradigm is widely used in memory research, as it separates the WM subprocesses like encoding and retrieval.
In recent years, a variety of innovative methods have been applied to the analysis of fMRI data. These include machine learning algorithms, nonlinear time series analysis, and complex network methodologies (Ochab et al., 2022; Singh et al., 2022; Wen et al., 2018; Onias et al., 2014). Significant research has focused on utilizing machine learning techniques and neural networks for fMRI data analysis. The main idea behind this approach is to analyze the neuroimaging data not from the point of view of the single voxel, but by identifying the patterns of neural activity over many brain areas. Thus, classification based on advanced computational algorithms is one of the most efficient methods for identifying neural activity and extracting the complex relationship between the experimental conditions and spatial-temporal patterns of brain responses measured by the fMRI technique (O'Toole et al., 2007). However, the machine learning algorithms and neural network types must be matched to the problem investigated to obtain statistically reasonable results, which is not a trivial problem due to the variety of computational methods, e.g., linear discriminant analysis (LDA), support vector machines (SVM), random forests (RF), neural networks classifiers and many others. Therefore, the performance of machine learning algorithms has been examined in many neuroscience studies, including research related to the classification and diagnosis of Alzheimer's, Huntington and schizophrenia disease (Sarraf and Tofighi, 2016; Patel et al., 2016), cognitive functions (Wen et al., 2018), sleep studies (Li et al., 2018b) and conscious visual perceptions (Haynes and Rees, 2005).
The goal of this paper is twofold. First, we would like to apply some of the most commonly used machine learning algorithms and neural networks in the study with working memory and verify their effectiveness in classifying the tasks (recognition between the visuospatial and verbal stimuli) and phases of the experiments (encoding and retrieval). In this study, we considered a set of linear and nonlinear classifiers and a residual neural network. We also regarded two kinds of data organizations, i.e. in the temporal-spatial form and single-time points from each observation. Secondly, based on the results from classification experiments, we would like to determine the brain regions that are the most important for classifiers; thus, important from the point of view of information processing in the brain. To this end, we proposed a novel algorithm and compared the results with the outcomes from the literature.
2 Experiment and data 2.1 Data descriptionFunctional magnetic resonance imaging (fMRI) data from four short-term memory tasks and a resting-state procedure were analyzed. Based on questionnaires and genotyping of the PER3 gene, 66 participants out of 5,354 volunteers were selected to perform the tasks in the MR scanner during two sessions: morning and evening. After further data quality control, 58 participants were included in the analysis. The order of the sessions as well as the versions of the tasks (there were two equivalent versions of each task) were counterbalanced between participants. The experiment was conducted on one day (if the morning session was the first) or two days (if the evening session was the first). Participants spent the night before or between sessions in the room located in the laboratory, and their quality of sleep during that night and the week preceding the experiment was controlled using actigraphs.
The short-term memory tasks were based on Deese-Roediger-McDermott (DRM) paradigm (Deese, 1959; Roediger and McDermott, 1995), which allows separating the encoding and retrieval processes, and is dedicated to studying short-term memory distortions. Two tasks evaluated the perceptual similarity (focusing on global, GLO, and local, LOC, information processing of abstract objects), and the remaining two the verbal similarity (semantic, SEM, and phonological, PHO, task). More specifically, in GLO task, the stimuli were abstract figures requiring holistic processing; in LOC task, the objects required local processing and differed in one specific detail. On the other hand, in SEM task, participants had to remember four Polish words matched by semantic similarity, and in PHO task, matched by phonological similarity.
In each task, the goal of a participant was to memorize the memory set (encoding phase, 1.2–1.8 s), and then (after a mask or distractor) recognize if the currently displayed stimulus, called probe, was present in the preceding set (retrieval phase, 2 s). There were three possible conditions of the probe: positive (the stimulus was the same as presented in the encoding phase), negative (the stimulus was completely different) or a lure (the stimulus resembled those presented in the memory set). Participants were asked to answer with the right-hand key for “yes” and the left-hand key for “no” responses. Then, after intertrial interval (on average 8.4 s), a fixation point (450 ms) and a blank screen (100 ms), the new memory set was presented on the screen. Each task had 60 sets of stimuli followed by 25 positive probes, 25 lures, and 10 negative probes. The examples of experimental tasks are depicted in Supplementary Figure 1.
In the resting-state procedure (REST), participants were instructed to lie in the scanner with their eyes open and not to think about anything in particular. They were not involved in any cognitive process. Participants' awakeness was monitored using an eye-tracking system (Eyelink 1000, SR research, Mississauga, ON, Canada).
Structural and functional data were collected on a 3T scanner Skyra (Siemens Magnetom, Erlangen, Germany) in Małopolska Center of Biotechnology in Kraków, Poland, with a 64-channel head coil. For tasks, 709 volumes (for GLO, LOC, and SEM), and 736 volumes (for PHO task) with a T2*-weighted echo-planar sequence were acquired. For the resting-state procedure, 335 volumes with a gradient-echo single-short echo planar imaging sequence were acquired. The following scanning parameters were used: TR = 1,800 ms, TE = 27 ms, flip angle = 75°, FOV = 256 mm, voxel size: 4 × 4 × 4 mm). Structural data were acquired for each participant using a T1-weighted MPRAGE sequence with isotropic voxels (1 × 1 × 1.1 mm) using the following parameters: 256 × 256 mm matrix, 192 slices, TR = 2,300 ms, TE = 2.98 ms. Stimuli were projected on a screen behind a participant's head. The participants viewed the screen in a 45° mirror fixated on the top of the head coil.
2.2 Data preprocessingThe flow chart in Figure 1 summarizes data preprocessing steps. Following the paper that introduced the dataset (Fafrowicz et al., 2019), we performed the preprocessing using the Statistical Parametric Mapping software package (SPM12, Welcome Department of Imaging Neuroscience, UCL, London, United Kingdom) implemented in MATLAB (Mathworks, Inc., MA, United States). Scans were slice-time corrected, realigned by inclusion of field maps, co-registered, and normalized to the EPI template in Montreal Neurological Institute (MNI) stereotactic space with a voxel resolution 3 × 3 × 3 mm. Then, data were spatially smoothed using a Gaussian kernel of FWHM 6 mm, covariates like motion parameters, mean signal, white matter, and CSF were removed by linear regression. The signal was then filtered with a 0.01–0.1 Hz filter, detrended, and despiked.
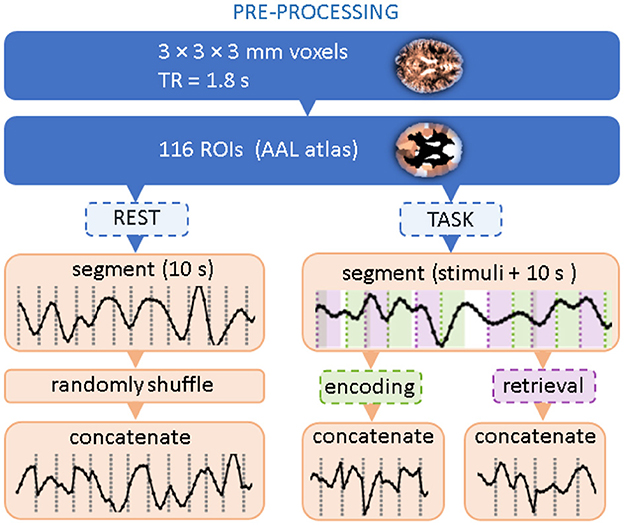
Figure 1. Flow chart of data preprocessing. Two topmost steps correspond to standard BOLD signal processing and coarse-graining into atlas-based Regions of Interest. The dashed boxes indicate that only a part of the experimental time series is selected.
The signals were then averaged within 116 brain Regions of Interest (ROIs) using the Automated Anatomical Labeling (AAL1) brain atlas (Tzourio-Mazoyer et al., 2002). For a given experimental session, they formed a data matrix with 116 rows corresponding to the ROIs and the number of columns corresponding to the length of the time series. Further processing steps follow (Ochab et al., 2022): for each session, we extracted all data segments (i.e., columns) related to the encoding or retrieval phase; for each phase, the segments were then concatenated in order of appearance. The segments started at the stimulus onset and were 10s long (6–7 TRs) each, which means that the encoding segments encompassed the presentation of the distractor and the retrieval segments encompassed the inter-trial interval. For a given session, the concatenation of segments from all 60 stimuli resulted in a 400-TR-long time series. Data for the resting state with eyes open were preprocessed similarly to the task data. First, in the absence of stimuli that would set the position of the segments, 400-TR long series were randomly chosen. Then, they were divided into consecutive, non-overlapping segments of 10s. Then, these segments were randomly shuffled and concatenated.
2.3 Classification tasksWe create eight classification problems using the data described in Section 2.1, four for each of the two phases of encoding (ENC) and retrieval (RET). Their variants are binary or 4-class problems depending on whether we group similar stimuli or not, e.g. global and local stimuli are both graphical and can be grouped into a single class. They can be further complicated by adding the resting state as an additional class, resulting in a 3- or 5-class classification. Table 1 lists the resulting experimental setups.

Table 1. Classification of the tasks due to the number of classes.
For each of the listed setups, we randomly split the available data into training and testing subsets using a ratio of 90:10.
In all non-neural classifiers, a sample of input data always has the dimensions of 116 × 1 (number of brain regions times one time point). We also conduct additional experiments taking into account the time dimension of the data, where we train neural networks on samples of dimensions 116 × 6 (sequences of six time points). We elaborate on this experiment in Section 5.2.
3 ModelsWe have conducted the fMRI classification by dividing machine learning methods into classical linear and non-linear discriminators, and neural networks. In total, ten classifiers were compared in the study.
3.1 Linear classifiers 3.1.1 Ridge classifierRidge classifier was proposed in Hoerl and Kennard (1970). The method addresses the problem of parameter estimation for multi-collinear independent variables. Ridge achieves that by adding a penalty term L2, which is equal to the square of the coefficients. However, while the L2 regularization minimizes coefficients, it never reduces them to zero (Hoerl and Kennard, 1970).
3.1.2 Logistic regressionLogistic regression is another linear estimation algorithm that was tested in the study. Unlike the Ridge Classifier, the logistic regression uses a cross-entropy loss function to output the probability for the classification (Brown and Mues, 2012).
3.1.3 Support vector machines using stochastic gradient descent (SGD)Loss optimization in linear models can also be performed using stochastic gradient descent SGD. It attempts to discover the gradients of the cost function for a random selection of data points. By conducting this operation, stochastic gradient descent can lead to much faster convergence of the algorithm. This timing advantage is crucial in the case of Support Vector Machines, which tend to build complex hyperplanes (Wang et al., 2012).
3.1.4 Gaussian naive BayesGaussian naive Bayes is a subset of the Naive Bayes models. The model assumes a Gaussian distribution of the data and a lack of feature dependencies within it. Due to its simplicity, the classifier often performs well on highly dimensional data. It can converge faster than discriminative algorithms such as Random Forest or Logistic Regression. The Gaussian Naive Bayes can also serve as a baseline due to its probabilistic nature (Brown and Mues, 2012; Jahromi and Taheri, 2017).
3.1.5 Linear discriminant analysis (LDA)LDA is another linear method that was evaluated in the study. LDA operates in two stages. First, it extracts all the feature values linearly. Then it uses those mappings and attempts to linearly separate classes by presenting points of opposite classes as far as possible from each other (Wu et al., 1996).
3.2 Non-linear classifiersIn contrast to the discriminators utilizing linear functions, non-linear classifiers attempt to match the data by minimizing functions that do not share regular slopes. This approach allows for creating more strict boundaries between classified data points, hence increasing the goodness of a fit. However, at the same time, this can lead to non-linear classifiers overfitting.
3.2.1 Quadratic discriminant analysis (QDA)Unlike LDA, which relies on the assumption of linear divisibility of the feature values, Quadratic Discriminant Analysis, uses non-linear attributes to separate data points. This proves to be generally more accurate, especially in the problems with high dimensionality (Wu et al., 1996).
3.2.2 Random forest classifierRandom forest classifier is a model composed of a collection of decision trees. In simple terms, decision trees can accept both numeric and categorical inputs to build sets of rules. Those rules are distributed throughout the trees. The data input can then flow in a top-to-bottom way and be filtered to produce respective outputs and classification results. Random forests use sets of such rules to provide even more accurate classification boundaries (Brown and Mues, 2012; Anyanwu and Shiva, 2009).
3.2.3 Light gradient boosting machine (LGBM)Over the last few years, boosting methods have been receiving more attention as their performance shows improvement over simple tree-based approaches. The reason for this phenomenon originates in the architecture of the boosted models. Boosting combines multiple models that are built iteratively, rather than in parallel. This ensures that each consecutively built algorithm attempts to minimize the errors made by previous models (Yaman and Subasi, 2019). Light gradient boosting is a special case of such an application, as it proves to outperform most of the other machine learning algorithms in a variety of benchmarks (Ke et al., 2017).
3.3 Performance baseline 3.3.1 Dummy classifierTo assess the reliability of the performed experiments, We created a dummy classifier whose sole purpose was to create a baseline for the other methods. The dummy classifier was fit in such a way that it ignored the input features and relied only on the distribution of the classified classes in making predictions.
3.4 Neural networksOne of the motivations for using deep neural networks, specifically the ones employing convolutional layers (like convolutional and residual networks), is the ability to process spatial data. In our case, the original BOLD data can be considered as having two dimensions—the first corresponds to the spatial distribution of the ROI, and the second corresponds to the temporal character of the time series. Each data sample consists of up to six discrete measurements, one TR apart, corresponding to the duration of the encoding/retrieval phases. We hypothesize that having the data in the temporal-spatial form and a model processing this data structure can yield better results than using single-time observations.
3.4.1 Layered convolutional network (CNN)The 1D convolution is often used for processing temporal data due to its ability to effectively handle sequential information in a channel-wise manner (Kiranyaz et al., 2019; Bai et al., 2018). The CNN architecture we use comprises two 1D convolutional layers (all the convolutional layers use filters of size 3), 1D maximal pooling, another 1D convolution, a linear layer with dropout, and the final softmax layer to calculate class probabilities. Crucially, all the convolutions move along the temporal dimension. This setup allows interactions between any subset of brain regions.
3.4.2 Residual network (ResNet)Residual networks (ResNets) (He et al., 2016) are a more powerful neural network type, in our case also utilizing convolutions. They consist of an input convolution, followed by several residual blocks of layers, depending on the network depth. Each of the blocks comprises two convolutional operations (3 × 3 filters), batch normalization (Ioffe and Szegedy, 2015), and a shortcut connection (1 × 1 filters). In the final layers, average pooling is performed, and a linear operation computes logits for each label. We utilize 2D convolutions to capture both spatial and temporal interactions between different ROIs. Taking inspiration from Li et al. (2018a) and Suk et al. (2017), we organize the ROIs in a structured format within a 2D matrix. This enables our network to effectively learn interactions between brain regions neighboring in the AAL atlas (typically, spatially adjacent or contralateral), allowing for the extraction of both local spatial relationships and temporal patterns simultaneously. Figure 2 shows a schematic overview of a typical architecture of a residual network.
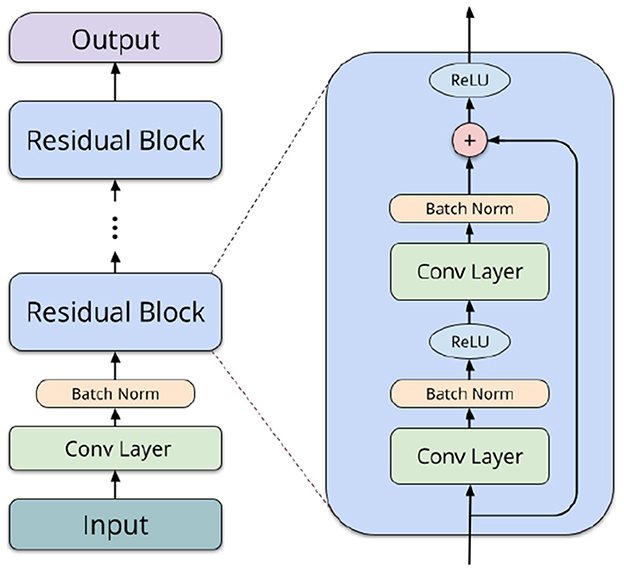
Figure 2. Schematic overview of a residual network block.
4 MethodsThis section expands on two out of the several models described in Section 3: LGBM and ResNet. This selection was made after the initial results, where LGBM and ResNet models proved to be the most promising ones (LGBM scores were comparable or higher than all other models, but for ResNet in two encoding experiments). Consequently, we included here the hyperparameter tuning and feature explanation procedures of the two models only.
4.1 Model training and tuning 4.1.1 LGBM hyperparameter tuningIn our preliminary calculations, the tested machine learning algorithms were capable of resolving the complexity of correlations and differences within our sample of the fMRI data with varying accuracy. Therefore, we decided to pick the most promising model—LGBM—and improve it with hyperparameter tuning (Feurer and Hutter, 2019).
To perform the parameter searches, we used Optuna, a state-of-the-art hyperparameter optimization framework (Akiba et al., 2019). We conducted 100 repetitions of each experiment, such as ENC2 or RET4. Within each repetition, there were 100 hyperparameter searches, and optional pruning of trials with unpromising initial results. This procedure reduces the bias of human-produced parameters and can be utilized again, even if the data distributions have changed (Akiba et al., 2019). The parameters used for the experiments can be seen in Table 2. Henceforth, we refer to the hyperparameter-tuned Light Gradient Boosting model as “tuned LGBM.”
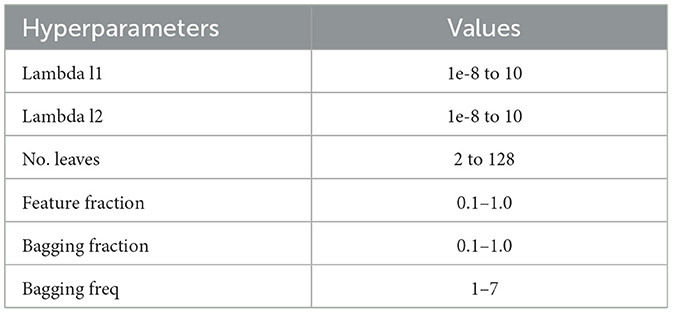
Table 2. LGBM hyperparameter tuning values.
4.1.2 Neural network training and hyperparameter tuningIn neural network experiments, each model is trained from scratch for up to 100 epochs. Early stopping was employed to finish the training process before epoch 100 if no improvement in validation loss was recorded for five epochs in a row. All networks were trained using the Adam optimizer (Kingma and Ba, 2014) together with a scheduler to reduce learning rate on loss function plateaus.
We perform a hyperparameter search for each task, where each task deals with a different data collection phase (either encoding or retrieval) and a varying number of classes—depending on whether the labels are simplified, by joining similar stimuli, and the addition of resting state data. Table 3 lists hyperparameters and their value ranges searched during training for ResNets and, similarly, Table 4 lists the hyperparameters for the 1D convolutional model.
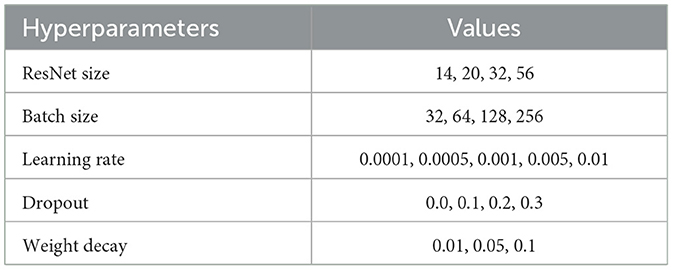
Table 3. Residual network hyperparameter tuning values.
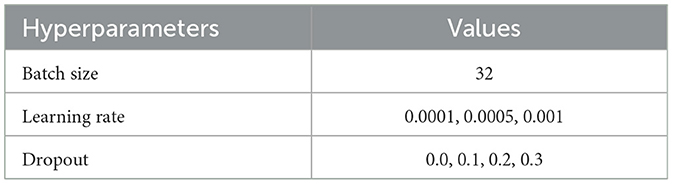
Table 4. 1D CNN hyperparameter tuning values.
4.2 Algorithms for data importance extraction 4.2.1 ROI importance estimation for LGBMIn addition to obtaining classification metrics for the experiments carried out, we were also interested in determining which particular ROIs were the most vital features for the classifier. To this end, we extracted ROI importance scores from the LGBM models using the default LGBM feature importance estimation method (Ke et al., 2017), i.e. the number of splits. The method, applicable to any tree-based model, counts the number of times a given feature (ROI activations) was used to split the data to grow the decision tree. We report the results of the tuned LGBM in the Supplementary material.
Unfortunately, such scores—as many others (see, e.g. Molnar, 2020, Ch. 8.1.4, 9.1.3, 9.5)—cannot account for possible correlations between the features. This lack could result, for example, in a pair of equally informative and highly correlated features being recognized as an important and an unimportant one; if, however, the former was removed from the data, the latter would take over its importance. To alleviate this problem, we performed an additional feature pruning procedure as described in the Algorithm 1: at each step, (i) the most important feature was removed from the training set, (ii) importance scores of the remaining features were recomputed, (iii) to correct for the decreasing number of features, the mean of importance across the remaining features was subtracted from the importance of each individual feature. The process finished when all features have been removed. To obtain the final corrected score, such demeaned scores were averaged over all the steps in which ROI was present in the model. The process is illustrated in Figure 3. Given the significant computational time and resources required for feature pruning, we limited the validation to untuned LGBM models.

Algorithm 1. Importance algorithm with ROI pruning.
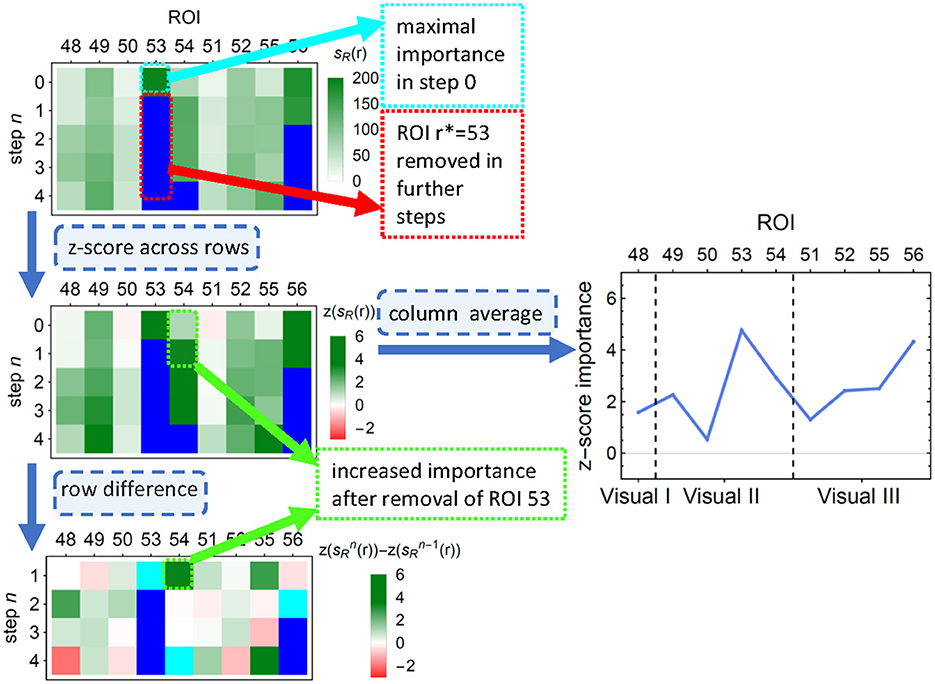
Figure 3. An illustration of the first few steps of Algorithm 1 on a subsample of LGBM classification results. (Top) Each row depicts the LGBM split scores. In consecutive steps, ROIs number 53, 56, 81 (not shown), and 54 are removed, and the scores are recalculated. (Middle left) Importance values are z-scored to correct for the decreasing number of features. (Middle right) The average across all removal iterations forms the final importance score of an ROI. ROIs are ordered into functionally associated groups of brain regions. (Bottom) The differences between importance scores indicate how classification is affected by feature correlations. Cyan (blue) pixels—regions removed in a given step n (in a previous step); green (red) pixels—regions whose importance increased (decreased) due to the removal. This diagram corresponds to the upper right corner in the top panel of Figure 7.
4.2.2 ROI importance estimation for ResNetsBy design, deep neural networks are black-box models, i.e., there is no simple way to obtain insight about why they generated a certain prediction. As opposed to a linear model, in deep neural networks the input representation is non-linearly transformed multiple times. Because of that, to extract interpretable knowledge about a network's decision process, we have to resort to various heuristics.
Our approach, outlined in Algorithm 2, is inspired by methods that perturb the input data during evaluation and measure the decrease in performance (Ribeiro et al., 2016). More formally, given a trained fixed ResNet model f and a validation set X = (x1, x2, …, xn), we sample batches from the validation set, XB = (xB1, …, xBk) and perturb in them a subset R of ROIs X~B=P(XB,R). Both the perturbed batch X~B and the original XB are then passed to the model and have their predictions compared. Finally, differing predictions contribute to the scores collected for each perturbed ROI in R.

Algorithm 2. Importance algorithm with data perturbation.
In more detail, the perturbation function P(·, R) is assumed to change only a subset of the input space so that this modified subset of features would now be unusable by the model f. We choose a zeroing perturbation function P∅(x, R), which sets to 0 a subset of feature representation of x — in our case, a subset of k ROIs chosen uniformly at random for each batch XB. For each original data point x ∈ XB and its perturbed counterpart, x~∈X~B we compare their prediction p = f(x) and p~=f(x~) and note if they differ. If they do, we add one to the batch score
In other words, the score s is a percentage of predictions in the perturbed batch differing from the predictions in the original batch. We store it in a buffer, for each zeroed ROI r ∈ R in this batch. The per-batch scores s are collected over multiple iterations and batches for each r ∈ ROIs, and their average is the final importance score S[r].
The procedure was run for N= 10,000 iterations, with k = 12 out of 116 ROIs zeroed in each batch – the choice was arbitrary, but it involves a reasonable trade-off between the coverage of potential multichannel interactions and the computational cost of the procedure (with the number of iterations limited as above, one could only cover all pairwise interactions). A dropout layer in the model architecture enhances parameter randomization, promoting the generalization of the identified ROIs. Still, using a probabilistic scoring method did not significantly affect the results.
4.3 Evaluation metricsWe evaluated precision, recall, F1, and classifier convergence times as suggested in Taha and Hanbury (2015). Our main focus was on F1 scores and convergence times. Given that the data had varying numbers of samples for each class, we used the weighted micro-averaged F1 score to account for the class imbalance. The F1 formula below shows how the final score is calculated, given precision, recall, and F1 score for each class i. This ensures that each class's contribution is proportional to its prevalence in the data set.
Precision=TPTP+FP Recall=TPTP+FN F1i=2×Precisioni×RecalliPrecisioni+Recalli F1=∑i=1N(Wi×F1i)∑i=1NWiwhere TP is the number of true positives, FP is the number of false positives, and FN is the number of false negatives. The weights Wi correspond to the number of true samples of class i.
5 Results 5.1 Classifier performance comparisonAs indicated in the Evaluation Metrics subsection, we made final comparisons based on F1 and convergence time. The combined results can be seen in Figures 4, 5, and Table 5.
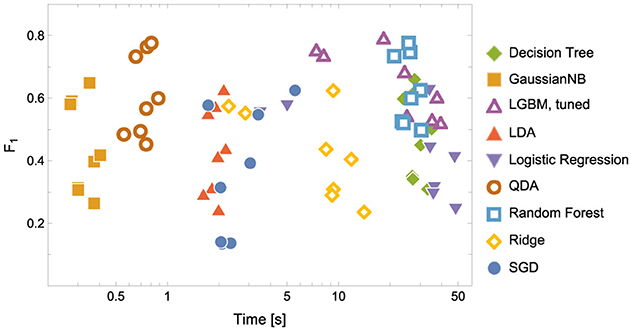
Figure 4. Model Convergence Times and F1 scores achieved on the test data for discriminators. Notice the logarithmic horizontal time axis. Each point corresponds to the result of a single experiment (i.e., ENC2, ENC3 and so on); cf. the left panel in Figure 5.
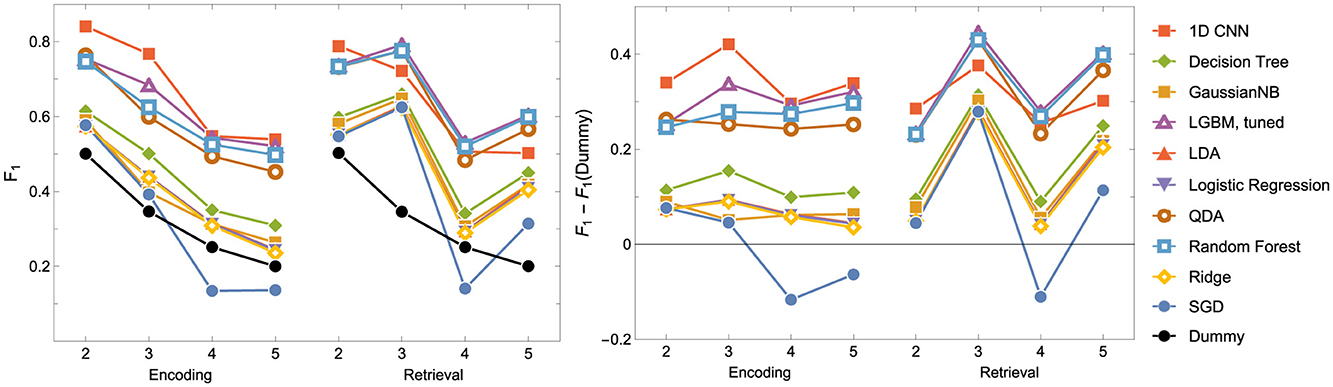
Figure 5. F1 score for the Encoding and Retrieval experimental phase and different classifiers. For all models other than the CNN, the data used for training were instantaneous brain activations (1 TR × 116 ROI vectors).
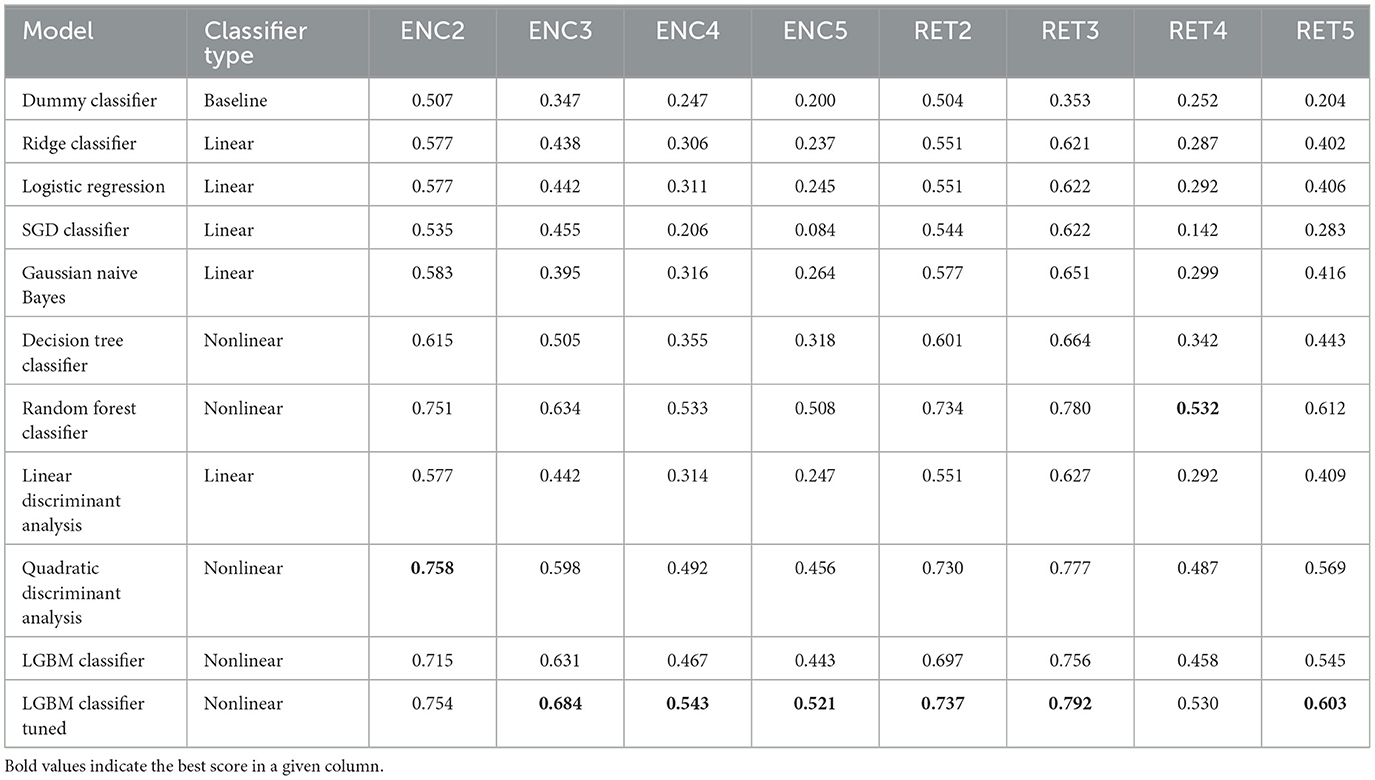
Table 5. Model evaluation results—F1 scores achieved on the test data (single time point: 1 TR × 116 ROIs).
Based on the results, a few major conclusions can be drawn.
1. In terms of model convergence times and F1 scores, the nonlinear classifiers achieved the best performance (see Figure 4). Additionally, Quadratic Discriminant Analysis achieved the highest F1 score in the shortest amount of time, at least one order of magnitude less than other nonlinear discriminators.
2. The nonlinear models have shown better accuracy compared to the linear models when examining the experimental data split into encoding and retrieval phases (see Figure 5). The F1 measure tends to decrease as the number of considered classes for the encoding phase increases. However, after correcting the results with dummy classifiers, a nearly constant relationship between accuracy and the number of classes is observed. Furthermore, including the resting state in tasks improves the performance of the discriminators, especially during the retrieval phase, where tasks involving the resting state achieve the highest accuracy. This also highlights differences in the data structures recorded in different experimental phases.
3. When looking at the results for the discriminators in Table 5, we found that the best model accuracy came from the tuned LGBM Classifier (nonlinear discriminators). The only exceptions were ENC2 and RET4, where Quadratic Discriminant Analysis and random Forest Classifiers performed slightly better than the tuned LGBM Classifier, respectively.
5.2 Classifiers based on neural networksIn our study, we applied CNNs and ResNets with various parameters (e.g., the number of residual blocks). Results on their performance are collected in Figure 6 and Table 6. We hypothesized that models processing temporal-spatial data can yield better results than using single-time observations. Consequently, we involved two approaches as mentioned above, i.e. as an input to ResNet, we used 1-time point data related to the instantaneous view of the brain state and 6-time points corresponding to the dynamics of the brain during the processing of the tasks.
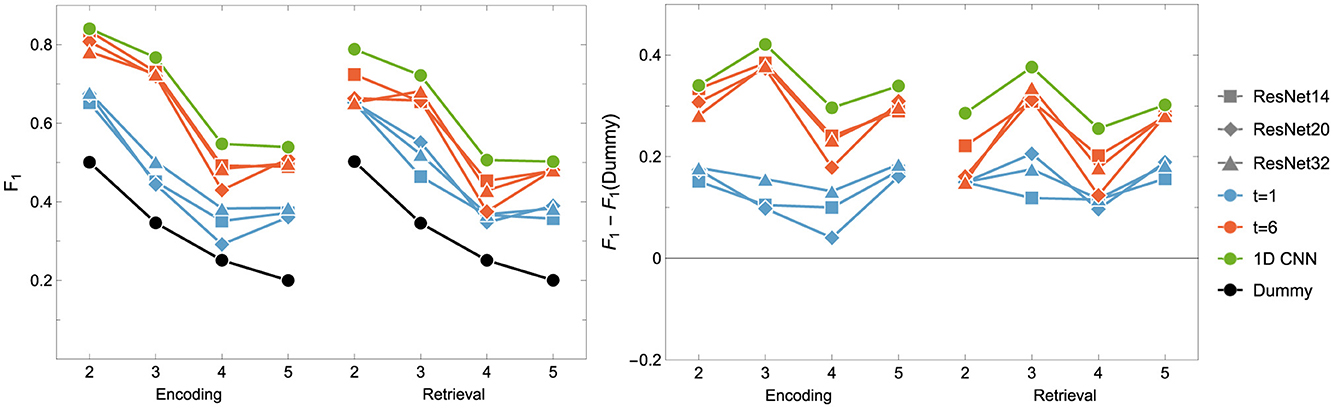
Figure 6. F1 score for the Encoding and Retrieval experimental phase and different neural networks: ResNet (blue and orange) and (green) CNN. The data used for training were either instantaneous brain activations (t = 1; 1 TR × 116 ROIs) or data segments of 6 time points (t = 6; 6 TRs × 116 ROIs) for comparison with the other classifiers. CNNs used only t = 6 data format.
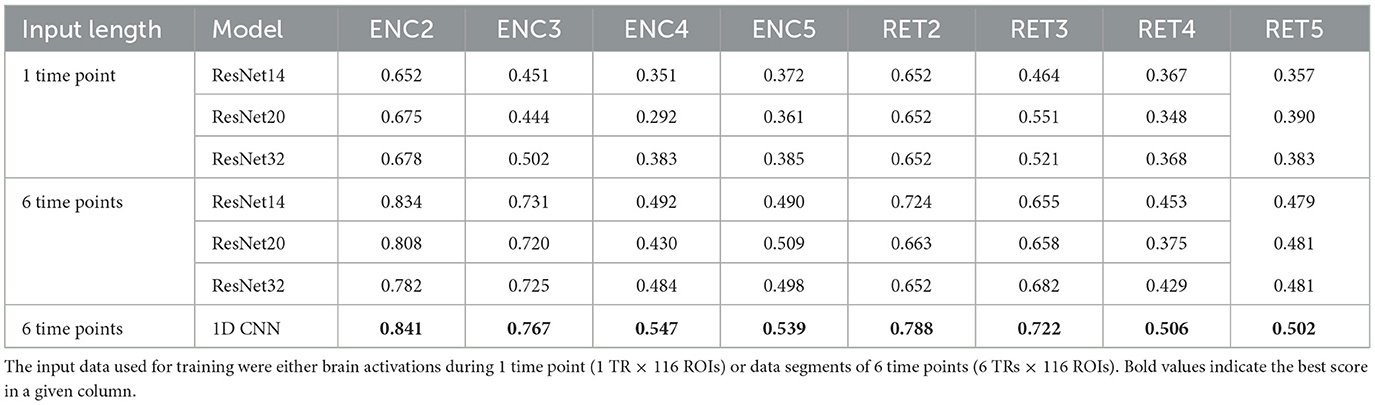
Table 6. Neural retworks evaluation results—F1 scores achieved on the test data.
It can be easily drawn that the networks give more accurate results when data in 6-time point segments are used to train the model. Moreover, the higher number of residual blocks within the middle layer does not imply better network performance, which is evident when results for the encoding phase for the 1-time point and the 6-time point are compared. For the former case (1-time point), the best results are obtained for ResNet32, whereas in the latter case, ResNet14 gives better outcomes. Interestingly, the model outperforms the non-neural classifiers only for ENC2 and ENC3 cases. Adding the resting state to the tasks enhances the accuracy only when four classes are considered, i.e. F1 for ENC4 (RET4) is lower than ENC5 (RET5). The best 1D CNNs found have performance better than any of the considered ResNets, even though they have a considerably simpler architecture. Interestingly, for the encoding phase, they perform comparably or better than any non-neural classifier, but are comparable or worse for the retrieval phase.
5.3 Explainability: ROI importanceThe ROI pruning procedure, Algorithm 1, allowed us to see whether, after removing a highly significant feature r*, some other remaining ROIs considerably changed their scores. Such changes are visualized in the upper panel of Figure 7 and in Figure 11, where in each row of the heatmap green (red) pixels indicate the regions whose importance increased (decreased) due to the removal of a single ROI (cyan tips of blue vertical lines). These changes can be interpreted as the model compensating for the information loss due to the r* removal by using similar information obtained from the several remaining ROIs, whose importance increased. We observed those remaining features improving their importance scores, with just a small overall F1 performance decrease. The importance of the other remaining ROIs would decrease if the information they carried was only useful in combination with the one that had been removed.
留言 (0)