
記住我


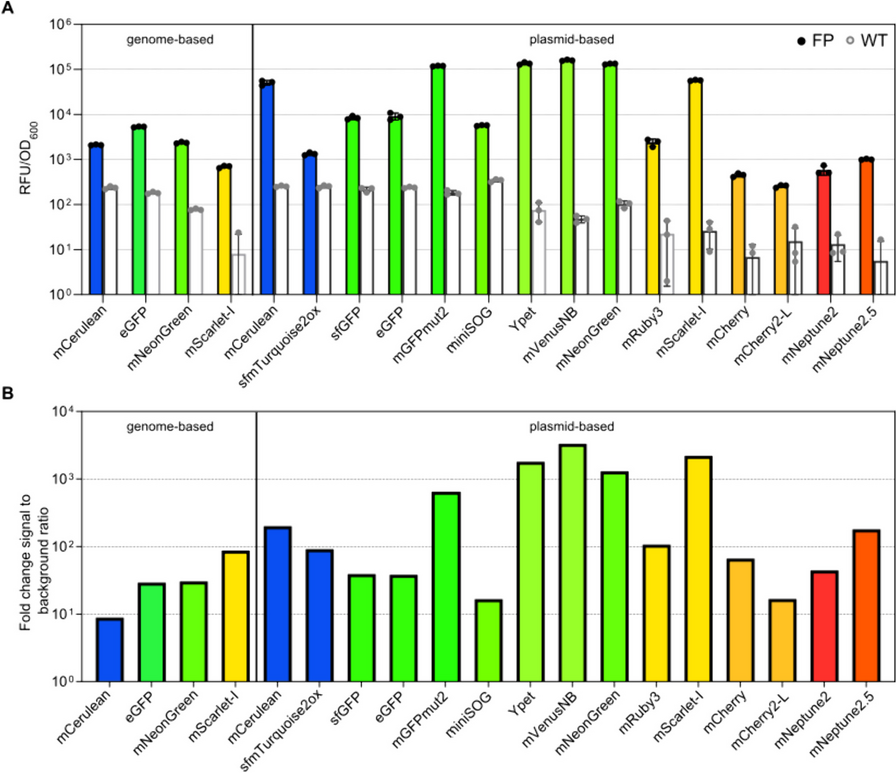
Figure 1 summarises the important steps that should be performed in order to develop a model that can be used reliably for making parameter predictions:
Fig. 1
Brief overview of the model development process for predictive models
Both structural and practical identifiability analyses are required in order to develop a predictive model with increased reliability.
Structural identifiability analysisAccessible definitionFor an intuitive approach to structural identifiability, consider the equations below:
$$y\left(t\right)=a\times 2$$
(1)
$$y\left(t\right)=^\times 2$$
(2)
$$y\left(t\right)=a+b$$
(3)
where \(a\) and \(b\) are unknown parameters and \(y\left(t\right)\), the measured output, is always known. Parameter \(a\) in Eqn(1) can be identified as one unique solution because \(y\left(t\right)\) can be divided by 2 to identify \(a\). Parameter \(a\) can also be identified in Eqn(2); however, this will result in two solutions; a negative value and a positive value, thus \(a\) is said to be locally identifiable. Lastly, since neither of the parameters \(a\) nor \(b\) are known, Eqn(3) is said to be structurally unidentifiable. This is because an infinite number of possible values for \(a\) and \(b\) can give rise to the same response.
Technical definitionThe basic form for the mathematical models to be considered is as follows:
$$M:\left\ \dot\left(t,p\right)=f\left(x\left(t\right),u\left(t\right),p\right),\\ y\left(t,p\right)=g\left(x\left(t\right),p\right),\\ _=x(_,p)\end\right.$$
(4)
where \(f\) and \(g\) are vector functions of their arguments, \(p\in }^\) is a p-dimensional vector of parameters, \(x(t)\in }^\) is the n-dimensional state variable vector, \(u(t)\in }^\) is the r-dimensional input vector and \(y(t)\in }^\) are the m-dimensional measured outputs [15].
For model (4), a parameter \(_\) is said to be identifiable if the following equation holds true:
$$y\left(t,p\right)=y\left(t,^\right)\Rightarrow_=_^$$
(5)
where \(^\) is an alternative parameter vector. If Eqn(5) holds for any \(_^\), then \(_\) is said to be globally identifiable. If Eqn(5) holds for a neighbourhood vector of \(_^\), then \(_\) is said to be locally identifiable. Finally, if Eqn(5) does not hold true for any \(_\) locally or globally then \(_\) is said to be structurally unidentifiable. For a model to be deemed to be structurally identifiable, all its parameters must be at least locally identifiable.
Methods for performing structural identifiability analysisThere are multiple methods that can be used to perform SIA [14]. The two methods that will be used in this paper are the Taylor series approach and the Exact Arithmetic Rank (EAR) approach. The Taylor series approach is a simple concept to understand and a simple way to analyse the structural identifiability of parameters. The EAR approach has been developed into a freely available MATHEMATICA tool [19], which enables users to enter their system of ODEs, input(s), and output(s), and will determine if the system is at least locally identifiable. This tool also identifies which parameters need to be known (a priori) in order for the system to be identifiable [14, 20,21,22,23].
In the Taylor series approach, a 1-dimensional observation function \(y\left(t\right)\) can be expanded as a Taylor series around a known time point, which in practice is usually a known initial condition when \(t=0\):
$$y\left(t\right)=y\left(0\right)+^\left(0\right)\left(t\right)+\frac^}(0)}^+\dots +\frac^\left(0\right)}^+$$
(6)
where \(^\) refers to the first derivative of \(y\) and \(n\) refers to the nth term in the Taylor series expansion. It is assumed that all derivatives that appear as coefficients in the Taylor series of the observed outputs are unique and measurable and are thus known [13, 14]. Therefore, it is possible to investigate the solutions for the unknown parameters within these coefficients. A single or multiple solution(s) (not infinite solutions) would indicate that the parameter is identifiable like Eqns (3-4). As the number of coefficients derived from the Taylor series expansion is infinite, for linear systems, there are limits which have been determined on the maximum number of coefficients that are needed in order to determine whether a model is at least locally identifiable [14]. For linear systems the maximum number of coefficients is \(2n-1\) , where \(n\) is the number of states. The same upper bound rule can be applied for non-linear systems, however, this is not a strict upper bound limit [14]. For example, if a linear system of ODEs comprises of two states then a third linearly independent coefficient would be the last coefficient that could be used in order to determine the structural identifiability of the system.
Like the Taylor series approach, the observation \(y\left(t\right)\) in the EAR approach is also differentiated with respect to time. However, the derivatives here are based on partial derivatives with respect to the states, inputs, and the parameters. Once computed the Jacobian matrix is formed of these partial derivatives and its rank is then assessed [24]. A Jacobian with full rank would indicate that all the columns (i.e., the parameters) are linearly independent from each other which would suggest that the model is at least locally identifiable. A deficient matrix rank would suggest that some of the parameters are dependent on each other (which would make this model structurally unidentifiable) and would also provide information on the number of degrees of freedom required for the parameter set/model to be deemed at least locally identifiable.
To interpret this analysis in an intuitive way, consider Eqn(3). Parameters \(a\) and \(b\) are entirely dependent on each other, in other words any value that is placed for \(a\), will also always change the value of \(b\).
Practical identifiability analysisStructural identifiability only considers the structure of the system of ODEs, the model inputs and, in particular, what the measured outputs are. It does not consider how the outputs are measured, in other words the associated data. PIA aims to assess whether the parameters can be at least locally identified based on the system of ODEs and the associated experimental data. It is worth emphasising that a model needs to be structurally identifiable for it to be practically identifiable. While there are multiple methods for performing a PIA, this study will focus on the profile likelihood approach.
Profile likelihood analysis: technical explanationIn the profile likelihood approach, a particular parameter pi is discretised using a step size (determined by many factors including the upper and lower boundary values of pi and the initial pi estimate) and the other parameters in the model (called nuisance parameters) are then reoptimised using the new values of pi to fit to the data. The loglikelihood ratio is used to determine whether the new fit to the data is significantly different or improved with respect to the previous fit to the data (e.g. a model with pi(1) compared to a model with pi(2)) [25]. A likelihood based 95% CI threshold is generated based on the \(^\) distribution and the mode’s number of degrees of freedom. If the 95% CI is finite, then the parameter is practically identifiable. If the 95% CI is infinite, then the parameter is practically unidentifiable.
Profile likelihood analysis: accessible explanationFigure 2 visualises the general steps for computing the profile likelihood for the parameters:
Fig. 2
Simplistic overview of practical identifiability analysis using the profile likelihood process. NLL: negative log likelihood. A Example model with parameter estimate. B Example model fitting to observed data. C Chi- squared (\(^\)) distribution (orange) for the associated model. D Model simulation based on different values for \(a\). E Different negative loglikelihood values based on the different parameter estimates. F: profile likelihood of \(a\). Note that some tools will use \(^\) and negative loglikelihood interchangeably for the profile likelihood plots. Each of the steps are explained below
Figure 2A depicts a simple structurally identifiable model (\(y=a\left(t\right)+3\)) with one parameter (\(a\)) as well as an estimated value obtained for \(a\). Figure 2B provides an exemplar fitting of the model (black dashed line) to the observed data (blue dots). Based on the observations and the number of parameters, the number of degrees of freedom for this particular model can be computed. In this example, the number of degrees of freedom is nine as there are 10 observations and one parameter that can vary. Figure 2C visualises a \(^\) distribution which, together with the number of degrees of freedom for \(y=a\left(t\right)+3\), can be used to obtain the 95% CI.
Figure 2D visualises a structurally identifiable parameter as the value of \(a\) changes (depicted by the different coloured lines in the plot), the output response also changes. In parameter estimation, the data are assessed to evaluate how probable it is that the data can be generated based on the estimated parameter value, this statistic is known as the likelihood (usually, the goal is to minimise the negative log likelihood [26]). In Figure 2E, the different values used for \(a\) generate different loglikelihood values. These values are compared to each other using the loglikelihood ratio to determine if there is a significant difference between them. Figure 2F provides a practically identifiable profile likelihood curve. The blue dashed line depicts the profile likelihood where different values for \(a\) are compared to the previous estimates and generate different \(^\) values (which are computed using the likelihood ratio - note that in some tools the y-axis is also referred to as the negative log likelihood as well as \(^\)). The red line depicts the 95% CI which the estimates need to cross on both sides in order for the parameter to be deemed as practically identifiable. If the 95% CIs are finite then the parameter is practically identifiable (e.g., \(a\)). However, if the 95% CIs are infinite then the parameter is practically unidentifiable.
Implementation of identifiability tools and associated codesBoth the Taylor series approach and the EAR approach were performed in MATHEMATICA. The PIA was conducted in MATLAB using the data2dynamics toolkit [27, 28]. All of the relevant scripts and codes used for both structural and practical identifiability can be found in the associated Github repository [29].
Models and data used for the analysisAll the models that have been used for this study have been published [30,31,32]. Data were extracted from the published reports using web plot digitizer, a tool that can be used to extract approximate data from figures [33]. Thus it is important to note that the PIA performed here is based on approximate data observations and not the actual data observations. The models have been rewritten in terms of notation for ease of interpreting the model states and parameters. All other assumptions are included in each of the relevant model sections.
Model 1A two-state mRNA model comprising of reactions including transcription, mRNA degradation, translation and protein degradation was developed to assess the mechanism of mRNA and protein regulation during cooler temperatures [30]. The system of ODEs defining the model are as follows:
$$\frac=_-_\times mRNA$$
(7)
$$\frac=_\times mRNA-_\times Protein$$
(8)
where \(mRNA\) denotes mRNA activity and \(Protein\) depicts protein activity. \(_\) to \(_\) refer to the transcription rate, mRNA degradation rate, translation rate and protein degradation rate, respectively. For this model, we assume that both model states are observed and thus measured and all parameters \(_\) to \(_\) are unknown. The initial conditions are assumed to be \(mRNA \left(0\right)=2.5\) and \(Protein \left(0\right)=6.5\), both with arbitrary units (a.u.).
Model 2A three-state bioreactor model was developed to characterise cell growth in a bioreactor set-up [32]. The system of ODEs defining the model are given as follows:
$$\frac=_\times \left(GF - Glucose\right)-_\times X$$
(9)
$$\frac=-_\times }+_\times X$$
(10)
$$\frac= ((_\times \frac}}_+}}\times \frac_}_+}\right)}^})- _)\times X$$
(11)
where \(Glucose\) and \(Lactate\) refer to the concentrations of glucose and lactate in the bioreactor respectively. \(X\) refers to the concentration of the cells in the bioreactor. \(_\) is the dilution rate and GF is the glucose concentration in the feed, both of which are provided by the modeller. In the published study, \(_\) is 0.033 hr-1 and \(GF\) is 7mM. \(_\) and \(_\) refers to the consumption rate of glucose and production rate of lactate respectively. \(_\) is the maximum growth rate of the cells. \(_\) and \(_\) are the saturation constant of glucose and inhibition constant of lactate respectively. The original paper utilises this model along with an intracellular metabolic model in order to perform the predictions. However, given that only the ODEs are given, the analysis will be based on the ODE system alone. The following assumptions are made about the model: All states are observed and all parameters: _\), \(_\), \(_\), \(_\), \(_\)} are unknown. The initial conditions for each of the state are as follows: \(Glucose\left(0\right)=\) 1.01mM, \(Lactate\left(0\right)=\) 3.98mM and \(X\left(0\right)=\) 0.46 x106 cells/mL.
Model 3A two-state model was developed for erythroblast growth inhibition [31]. The system of ODEs defining the model is as follows:
$$\frac=\frac_\times X}^}\times \left(}-}\right)}\right)}$$
(12)
$$\frac=\frac_\times X}^}\times \left(}-}\right)}\right)}-_\times }$$
(13)
Where \(X\) and \(I\) refer to concentration of the cells and the inhibitor concentration respectively. \(_\) and \(_\) refer to the growth rate and the inhibitor decay rate respectively. \(}\) and \(b\) refer to the inhibitory sensitivity and threshold respectively. This model has been adapted from model 3 of the original study and assumes that only \(X\) is observed. While in the original model the exponent term was \(^}\times \left(}-}\right)}\), the parameter estimates provided in the article match with the model system presented above. The parameters \(_\) and \(_\) were replaced by \(}\) and \(b\) respectively to dissociate them from being rate parameters. All parameters _\), \(_\), \(a\), \(b\)} are assumed to be unknown. The initial conditions are assumed to be \(X \left(0\right)=\) 4.45x106 cells/mL, and \(I \left(0\right)=\) 0x106 cells/mL.
To utilise the EAR tool, this system of ODEs will need to be simplified (in order for it to align with software requirements that the model is polynomial in form) by introducing a new state to replace the exponential term. This can be performed as follows:
$$^}\times \left(}-}\right)}=^}\times }}\times ^}\times }}$$
(14)
\(^}\times }}\) can be replaced by a parameter \(_\) and \(^}\times }}\) can be replaced by a new state termed \(\varphi\). A differential equation defining this new state also needs to be derived to yield the augmented model to have the required state space form, thus the new augmented system of ODEs for model 3 is given by:
$$\frac=\frac_\times X}_\times \varphi \right)}$$
(15)
$$\frac=\frac_\times X}_\times \varphi \right)}-_\times }$$
(16)
$$\frac=\varphi \times }\times (\frac_\times X}_\times \varphi \right)}-_\times })$$
(17)
The initial condition for \(\varphi\) is 1 a.u. and this state is also not observed.
留言 (0)