Adverse Drug Event (ADE) refers to harm caused by medical interventions associated with drugs, involving overdoses, allergic reactions, adverse drug reactions, and medical errors [1], [2]. It is estimated that ADEs constitute 30 % of all hospital adverse events [3], [4]. Medical errors, including ADEs, were the third leading cause of death in the United States (US) in 2013 [5], [6]. Experiencing an ADE can result in longer hospitalizations, serious morbidity and mortality, and additional healthcare costs [7], [8], [9], [10], [11].
Majority of ADEs are preventable, and lessons learned from previous ADEs provide guidance for the prevention of future ADEs [8]. Hence, pharmacovigilance aims to characterize, detect, monitor, and prevent ADEs [12], [13].
Electronic health records (EHRs), which contain multiple documents that record detailed patient treatments and responses, are nearly ubiquitous in the United States in clinical settings. Documents within EHR, such as progress notes and discharge summaries can be utilized as resources for ADE detection and research [8], [14]. However, reviewing and manually extracting ADE-related information from clinical notes in EHRs is hard, costly, and more specifically, not realistic [8]. Hence, it is imperative to make use of natural language processing (NLP) techniques for the automatic collection of ADEs [5].
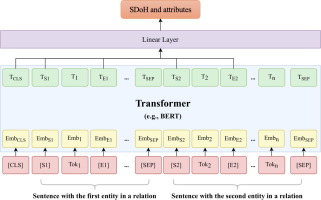
Typically, there are two tasks associated with ADE extraction: named entity recognition (NER) and relation classification (RC). ADE mentions and drug-related attributes should be identified in the NER task [15]. The RC task aims to assign the relation between the drug entity and other entities [8].
There were several challenges covering the task of ADE collections. The 2018 National NLP Clinical Challenge (n2c2) Shared Task on Adverse Drug Events and Medication Extraction and the 2018 Medication and Adverse Drug Event (MADE) 1.0 Challenge are chosen for methodological review because they offer standardized benchmark datasets for extracting medication and adverse drug event information from clinical text, a crucial task in healthcare informatics. Researchers prefer these challenges due to their direct relevance to clinical NLP, real-world applications, and the opportunity to advance NLP techniques, compare methods, and publish results in reputable venues. They provide a structured and transparent platform for evaluating and improving NLP methods in the context of clinical data extraction. Therefore, the objective of the article is to conduct a review about the use of machine learning (ML)/ deep learning (DL) models in ADE extraction from clinical text. In this review, only the studies using the two benchmark datasets in second track of the 2018 n2c2 Shared Task on ADEs and Medication Extraction, and 2018 MADE 1.0 Challenge were considered for the convenience of comparison. In this article, our primary emphasis is on examining the variations in methods, including models and inherent features, for ADE extraction in the NER and RC tasks using the benchmark data sets of the two challenges. We aim to investigate the impact of ensembles and knowledge-based features on the NER task. Additionally, the influence of embeddings on both NER and RC tasks will be explored.




留言 (0)