
記住我


Value-based care programs incentivize hospitals to improve quality of patient care while reducing unnecessary costs.1 In the United States, frequent acute care utilization in emergency department (ED) or inpatient settings by the top 5% of patients constitutes over half of health care costs.2–6 Patients at risk of high future health care utilization (high-risk patients) may benefit from tailored medical and social interventions; these interventions may simultaneously decrease health care costs.7
To identify high-risk patients, health care systems have developed predictive models for risk stratification, all of which are subject to certain limitations.8 A limitation of many implemented risk stratification models is reliance on readmission as the sole outcome without consideration of ED utilization.9 The Emergency Medical Treatment and Active Labor Act stipulates that all patients are entitled to receive ED care regardless of ability to pay.10 In safety net hospitals and large urban centers, the ED may serve as the only setting in which patients who are uninsured or experiencing homeless interact with the health care system.11 Some ED visits are preventable, and frequent ED visits can indicate a combination of poor health management, inadequate access to care, and social stressors.12 Risk models that expand to the ED are often limited to disease-specific states or subgroups, rather than targeting the general patient population.13,14
Another limitation of many traditional predictive models for risk stratification is that social risk factors, particularly homelessness and incarceration history, are not consistently incorporated during model development despite their association with high acute care utilization.15 Prediction models, including commercial or “out of the box” models that have been tested on majority-White or commercially insured populations, may not be appropriate for safety net hospitals; patients from safety net system patients are less likely to be White, experience more housing instability, and live in more socially disadvantaged neighborhoods compared with patients from other health care systems.16
As the largest safety net system in the United States, NYC Health + Hospitals (H+H) serves more than 1,000,000 patients annually in the New York City metropolitan area. In 2016, H+H developed its first payor-agnostic predictive model of high-risk patients trained on internal administrative and electronic health record (EHR) data.17 To improve H+H’s ability to prospectively identify patients with high medical and social needs, we developed a new payer-agnostic risk model by incorporating enriched data on social factors and using advanced statistical techniques.
METHODS Study PopulationThe study sample included patients aged 18 years or older who visited any H+H facility during July 2016 to June 2017. We excluded patients who were pregnant [International Classification of Diseases (ICD)-10 CM primary billing diagnoses: Z34.xx, Z3A.xx, O00.xx–O16.xx, O20.xx–O48.xx, O60.xx–O75.xx, O80.xx–O92.xx, O95.xx–O99.xx], incarcerated, received care only in ancillary care settings (eg, radiology), or whose data lacked the identifiers needed to link records across data sources (name, date of birth, and sex). We did not incorporate data on patient deaths because of significant underreporting of these data in our legacy EHR system. Incorporating patient death data during model development was not common practice in other models described in the literature.5,18
Data SourcesWe used clinical, scheduling, and administrative data from H+H facilities across multiple data sources, including the QuadraMed and Epic EHR systems, Correctional Health Services, and American Community Survey.19
OutcomesWe chose total days of acute care utilization (ED or inpatient setting) within the year as the outcome of interest. This outcome was chosen rather than number of acute care visits used in other models because we aimed to balance acuity (ie, long stays) and frequency (ie, many repeat ED visits) within our population. We tested 3 versions of this outcome of interest for the year July 2017 to June 2018: ≥10 acute days (per prior H+H model),17 ≥5 acute days, and continuous number of acute days.
We defined the number of inpatient days as the time between admission and discharge dates. For admissions not yet discharged by the end of the study period, we censored the stay at June 30, 2018.
Candidate PredictorsWe tested 67 predictors within the domains of social determinants of health or social proxies, clinical diagnoses, prescriptions, health care utilization, and patient demographics. For each patient, we calculated the number of ED visits, inpatient visits, outpatient visits, and acute days during the measurement year (capped at 30 d for each individual patient); we created an indicator for patients with ≥90 acute days. We applied the New York University ED classification algorithm to our billing diagnosis data to flag ED visits that were “emergent ED but PC treatable” or “nonemergent.”20
Social needs screenings happen heterogeneously across H+H facilities, and no comprehensive variables for social risk were available in our EHR. As proxy variables for social instabilities, we tested the number of missed outpatient visits and zip code changes within 1 year.17 In the new model, we also included NYC jail discharge records from 2015 to 2017 to account for recent incarceration history. We identified homelessness by matching patient and shelter addresses, searching for key words (eg, “homeless” and “undomiciled”) in patient addresses, using homelessness documentation from registration forms, flagging ICD-10 codes (problem list, encounter diagnosis, or billing data), and by identifying patients with ≥10 zip code changes in a year.21 Using American Community Survey data, we identified patients residing in zip codes where ≥30% of residents live beneath the federal poverty line.
We used the Elixhauser Comorbidity Index to create 31 chronic disease indicators and a composite Elixhauser score to reflect each patient’s chronic disease burden.22 We added a specific indicator for sickle cell disease, a strong predictor in our previous model.17 We adapted the Kim and Schneeweiss Frailty Index for patients aged 65 years or above.23 On the basis of input from clinical partners, we included antipsychotic and anticoagulant prescriptions as predictors.
Statistical Analysis MethodsWe divided the dataset into a 70% training set for model training, tuning, and variable selection and a 30% validation set for evaluating model performance. Across the 3 outcomes of interest, we trained 3 types of models: logistic regression, classification and regression tree (CART), and least absolute shrinkage and selection operator (LASSO).
To prevent overestimation of model performance because of overfitting, we performed a 5-fold cross-validation on the training set to tune each model. We then evaluated each model’s performance on the validation set. We evaluated model performance using a panel of statistics: root mean square error, R2, and mean absolute error for regression models; area under the receiver operating curve (AUC) and F1 value for classification models; and sensitivity, specificity, and positive predictive value (PPV) for predefined cut points across both classification and regression models. We set cut points at top 1% and top 5% of patients ranked by the predicted outcome. To ensure that the final model would be clinically meaningful and programmatically actionable, we prioritized top 1% PPV in consultation with program partners to finalize the model’s threshold for categorizing patients as high risk, balancing potential high-risk patient case load at each facility with available programmatic resources.
IRBThe study was approved by the Institutional Review Board at the Biomedical Research Alliance of New York.
SoftwareWe used RStudio v1.1, SAS Enterprise Guide v7.1, SQL Server Management Studio v17.3, and Tableau 10.5 for data preparation, analyses, and visualization.
RESULTS ParticipantsOf 841,199 adult patients who visited H+H during July 2016 to June 2017, 833,969 patients met inclusion criteria. Of these patients, we randomly assigned 583,778 patients to the model training cohort and 250,191 patients to the validation cohort.
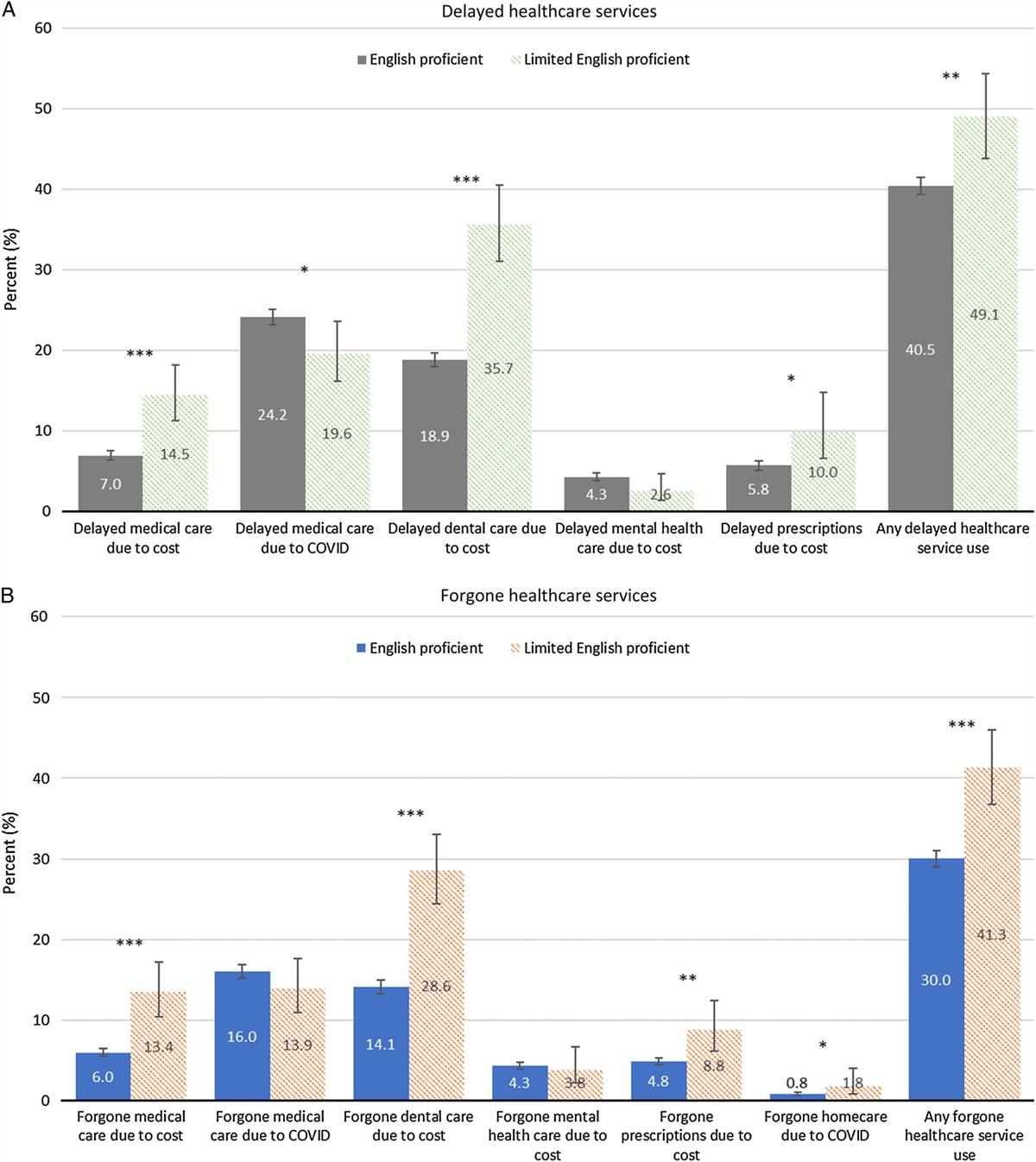
Patients in the training and validation cohorts lacked substantial differences in candidate predictors (Table, Supplemental Digital Content 1, https://links.lww.com/MLR/C567). Within the training cohort, most patients were female (56.7%) and non-White (90.7%). The average age was 45.1 years, and most patients were either Medicaid (38.1%) or Self-Pay (33.2%) (Table 1). Regarding social determinants of health and social proxies, 27.4% of patients had missed ≥2 appointments, 1.9% were experiencing homeless or had a history of homelessness, 2.9% had a history of incarceration, and 30.8% lived in a neighborhood where >30% of residents live below the federal poverty line. On average, patients had 2 acute days; 5.8% of patients had ≥5 acute days and 2.8% had ≥10 acute days.
TABLE 1 - Patient Characteristics by Cohort N (%) Characteristic Training Cohort (N=583,778) Validation Cohort (N=250,191) Male 252,796 (43.3) 108,339 (43.3) Age, mean (SD) 45.1 (17.1) 45.0 (17.1) Ethnicity/race Non-Hispanic White 54,031 (9.3) 22,893 (9.2) Hispanic 197,699 (33.9) 85,274 (34.1) Non-Hispanic Black 204,564 (35.0) 87,524 (35.0) Other/Unknown 127,484 (21.8) 54,500 (21.8) No. acute days, mean (SD)* 2.0 (4.6) 2.0 (4.5) No. ED visits, mean (SD) 1.0 (2.0) 1.0 (2.0) No. inpatient visits, mean (SD) 0.2 (0.6) 0.2 (0.6) 1+ emergent PC treatable ED visits† 12,711 (2.2) 5424 (2.2) Most recent payer Medicaid 222,352 (38.1) 95,455 (38.2) Medicare 72,792 (12.5) 31,234 (12.5) Self-pay 194,071 (33.2) 83,216 (33.3) Other 94,563 (16.2) 40,286 (16.1) Alcohol use 34,772 (6.0) 14,815 (6.0) Psychosis 24,258 (4.2) 10,373 (4.2) Substance use 30,232 (5.2) 12,920 (5.2) Congestive heart failure 12,896 (2.2) 5575 (2.2) Renal failure 15,761 (2.7) 6748 (2.7) No. chronic conditions, mean (SD) 1.3 (1.8) 1.3 (1.8) Antipsychotic prescription 17,838 (3.1) 7638 (3.1) No. zip code changes, mean (SD) 0.1 (0.8) 0.1 (0.9) No. payer changes, mean (SD) 0.5 (1.6) 0.5 (1.6) Missed visits 0–1 424,078 (72.6) 181,918 (72.7) 2+ 159,700 (27.4) 68,273 (27.3) Homelessness 11,024 (1.9) 4735 (1.9) History of incarceration 16,762 (2.9) 7052 (2.8)*Number of acute days from July 2016 to June 2017 and capped at 30 days for each individual patient.
†On the basis of algorithm developed by the NYU Center for Health and Public Service Research. It aims at classifying ED visits into (1) emergent visit but PC treatable; (2) nonemergent visit; and (3) others based on billing diagnosis codes.
ED indicates emergency department; PC, primary care.
Five variables contained missing data, including race and ethnicity (missing for 1.4% of patients), preferred spoken language (1.6%), and marital status, zip code, and most recent payer (each <1%). We recoded missing data as a level for categorical variables.
Model PerformanceAfter tuning each model via cross-validation, we compared model performance and model parsimony in the validation cohort (Table 2). The number of predictors retained by the models ranged from 17 to 43 predictors. The LASSO model predicting number of acute days had the most parsimonious model with 17 predictors. The only other model with comparable parsimony is the CART model predicting number of acute days with 18 predictors.
TABLE 2 - Model Performance in Validation Cohort Algorithm Logistic Logistic LASSO LASSO LASSO CART Outcome 10+ Days 5+ Days 10+ Days 5+ Days No. Days No. Days No. variables 33 34 30 34 17 18 Model fit PPV (10+ or 5+ days) (%) 50.5 55.7 50.0 56.3 NA NA Sensitivity (%) 10.8 11.6 9.3 10.5 NA NA AUC 0.86 0.80 0.83 0.79 NA NA F1 0.18 0.19 0.16 0.18 NA NA RMSE NA NA NA NA 3.33 3.32 R 2 NA NA NA NA 0.19 0.19 Top 1% model statistics* PPV (top 1%) (%) 44.6 44.6 44.6 44.8 47.6 50.8 Sensitivity (%) 16.2 16.2 16.2 16.2 17.3 15.6 F1 0.24 0.24 0.24 0.24 0.25 0.24 Top 5% model statistics† PPV (top 5%) (%) 34.7 35.4 35.0 36.0 35.2 34.9 Sensitivity (%) 29.9 30.5 30.3 31.1 30.4 30.5 F1 0.32 0.33 0.32 0.33 0.33 0.32*To compare performances across classification and regression models with various predicted outcomes, we redefined each model’s predicted “event” if the predicted outcome (predicted number of acute days or predicted probability) is ranked among the top 1% and the remaining 99% would be classified as predicted “nonevent.” The observed “event” was defined as patients who had 10 or more acute days whereas patients who had 9 or less acute days were classified as observed “nonevent.”
†Predicted “event” was defined as predicted outcome ranked among the top 5%, whereas the remaining 95% were considered as predicted “nonevent”. Patients with 5 or more acute days in the outcome year were classified as observed “event” whereas patients with 4 or less acute days were defined as observed “nonevent”.
AUC indicates area under the receiver operating curve; CART, classification and regression trees; LASSO, least absolute shrinkage and selection operator; PPV, positive predictive value; RMSE, root mean square error.
Among the classification models, models predicting ≥5 acute days had lower discrimination than models predicting ≥10 acute days (AUC: 0.79–0.80 vs. 0.83–0.86). AUCs were more similar when comparing across different modeling algorithms predicting the same outcome (eg, LASSO vs. logistic regression predicting ≥10 acute days) than when comparing across the same modeling algorithm predicting different outcomes. Models predicting ≥5 acute days had slightly higher F1 values (0.18–0.19 vs. 0.16–0.18), PPV (55.6% vs. 50.5%), and sensitivity (10.5%–11.6% vs. 9.3%–10.8%) compared with models predicting ≥10 acute days.
Models with continuous outcomes performed similarly across both modeling modality and predictive outcome (root mean square error=3.32–3.33, R2=0.19). The LASSO and CART models that predicted number of acute days as a continuous outcome required <20 predictors. After dichotomizing the predicted days outcome using a ≥10 days threshold, the LASSO model’s PPV for the top 1% of predicted high utilizers was 47.6%. The LASSO model had higher sensitivity and F1 value for the predicted top 1% than the CART model. LASSO and CART models had a higher top 1% PPV when predicting continuous versus binary outcomes. When we expanded to the top 5% of predicted high utilizers, differences in PPV, sensitivity, and F1 value were attenuated.
We selected the LASSO model predicting number of acute days as our final model because it balanced parsimony (17 variables), PPV (47.6% for top 1%), and sensitivity (17.3% for top 1%). This final model slightly overpredicted patient’s acute days in the outcome year when the predicted days were within the range of 2–4 acute days and underpredicted for >6 predicted acute days (Fig. 1).
 FIGURE 1:
FIGURE 1: Calibration of final model in validation cohort. Predicted acute days (x-axis) based on the final model versus observed acute days (y-axis) in the outcome year within the validation cohort. Predicted acute days above 12 are not shown since they only account for 0.2% of patients. Black circle dots represent the median, and orange diamonds represent the average of observed acute days for each predicted acute days. The black solid vertical line is the interquartile range of observed acute days. The diagonal dotted line is a reference line representing perfect calibration. The blue solid curve is a fitted line (using general additive model) based on the relationship between observed acute days and predicted acute days.
Model SpecificationThe top binary predictors for the final model were psychosis diagnosis (β=1.17), history of incarceration (β=0.47), antipsychotic medication prescription (β=0.40), and substance use disorder diagnosis (β=0.38) (Table 3). Top continuous predictors were inpatient visits (β=0.36), ED visits (β=0.35), and number of chronic conditions (β=0.21). We observed a near-linear relationship between predicted acute days and average observed acute days (Fig. 2).
TABLE 3 - Estimated Coefficients of Final Prediction Model for Future Acute Days Intercept 0.15 — — Demographics Utilization Most recent payer—Medicare 0.06 No. ED Visits 0.35 Most recent payer—self-pay −0.04 No. inpatient visits 0.36 Most recent payer—other −0.08 No. acute days* 0.08 — 1+ emergent PC treatable ED visits −0.08 Clinical indicators Social determinants Alcohol use 0.19 No. zip code changes 0.08 Psychosis 1.17 No. payer changes 0.004 Substance use 0.38 2+ missed visits 0.04 Congestive heart failure 0.05 Homelessness 0.28 Renal failure 0.02 History of incarceration 0.47 No. elixhauser chronic conditions 0.21 — — Antipsychotic prescription 0.40 — —*Number of acute days from July 2016 to June 2017 and capped at 30 days for each individual patient.
ED indicates emergency department; PC, primary care.
 FIGURE 2:
FIGURE 2: Predicted versus average observed acute days in validation cohort. Bars illustrate the percent of adult patients in the validation cohort respective to each predicted acute day bucket. Circles represent the average observed acute days per predicted acute day bucket in the prediction year July 2017 to June 2018.
DISCUSSIONUsing administrative and EHR data, we designed a homegrown model to identify patients at risk of high future ED and inpatient utilization in New York City’s safety net hospital system. We tested a broad array of candidate predictors and found that psychosocial risk factors, chronic comorbidities, and past health care utilization were particularly strong predictors of high acute care utilization. To select the final model, we developed and validated several classification and regression models; we assessed each model using multiple performance metrics. The final model successfully predicted approximately half of the patients who would go on to have very high acute care utilization. This model is parsimonious, clinically interpretable, and designed with the ultimate goal of linking high-risk patients with programmatic resources to improve outcomes in a clinically salient time frame.
Similar to previously published research, social risk factors were important predictors of acute care utilization.5 Five social risk factors (number of zip code changes, number of payer changes, homelessness, ≥2 missed visits, and history of incarceration) were retained in all models, regardless of model selection algorithm or predictive outcome. This finding highlights the importance of considering these risk factors in model development, particularly for safety net hospitals. A unique strength of our model was our ability to include history of incarceration; this was possible because H + H correctional services is the primary health care provider for persons incarcerated within the NYC jail system. Incarceration history was among the strongest predictors of high acute care utilization, suggesting that other institutions might consider incorporating this variable into their models if available.
The strongest clinical factors for predicting high acute care utilization were the diagnosis of psychosis, prescription of antipsychotic medications, and substance use disorders. In contrast, the presence of individual comorbidities such as renal failure and congestive heart failure, were weaker predictors. Previously published models of high acute care utilization have generally included physical health conditions but have inconsistently included mental health and substance use disorder diagnoses factors,5 but our study adds to a growing body literature suggesting the importance of substance use and mental health as predictors of high acute care utilization.
Our findings are subject to several limitations. Because we used internal administrative and EHR data rather than insurance claims data, we did not capture health care utilization occurring outside of the H+H system. Although insurance claims data would likely have improved our model’s predictive accuracy, these data would be unavailable for the 30% of adult patients at H+H without health insurance and are often less timely than EHR data.24 We did not incorporate free text data from clinical notes via natural language processing, because of processing power limitations within our system.25 Therefore, we likely undercounted social risk factors, which may be written as free text within the chart rather than captured in standard data elements. We did not incorporate patient’s deceased status, which may improve the accuracy of our prediction and validation. Also, because of limited computational power, we did not test other machine learning algorithms, such as gradient boosting, random forest, and neural network, which might have out-performed our final model.26 Lastly, we did not incorporate laboratory results data, which were commonly used in other predictive modeling studies, because these data were unavailable at the time of the study.18
Despite these limitations, we demonstrate a feasible approach to predictive modeling for high acute care utilization in a safety net hospital using EHR data. Our model is tailored to the unique H+H population and enhanced by the inclusion of important social determinants of health that have been historically neglected. Our approach to model development could serve as an example to other safety net hospitals that serve similar patient populations.
After evaluating both top 1% and top 5% thresholds to define “high risk” within our system, we ultimately selected 3.6 acute days (analogous to top 5% of our adult patient population) as the threshold for determining high-risk status. This decision was based on input from programmatic partners with consideration for care management capacity. Choosing this threshold allowed for the expansion of care and services to more patients, including those with more chronic conditions but fewer psychosocial risk factors. We integrated our high-risk patient predictions into the Epic EHR system in 2019, which allowed clinical providers, social workers, care managers, health home workers, and other team members to view a patient’s high-risk status in their Epic chart. This flag has since been used to drive workflows across H+H to promote disease management and coordinate health care services. Our Managed Care, Health Home, Care Transition, and Community Health Worker teams are able to use the high-risk flag as a single source of truth to connect our most vulnerable patients to additional resources, including proactive patient outreach during the COVID-19 pandemic. Implementing an adult risk stratification system that incorporated social determinants afforded our safety net system the opportunity to focus staff time on patient segmentation and targeting.
ACKNOWLEDGMENTSThe authors thank Nichola Davis, Jeremy Gold, Laura Jacobson, Jenny Smolen, and Jeremy Ziring.
REFERENCES 2. Zook CJ, Moore FD. High-cost users of medical care. N Engl J Med. 1980;302:996–1002. 3. Sommers A, Cohen M. Medicaid’s High Cost Enrollees: How Much Do They Drive Program Spending?. Henry J. Kaiser Family Foundation; 2006. 4. Raven MC, Billings JC, Goldfrank LR, et al. Medicaid patients at high risk for frequent hospital admission: real-time identification and remediable risks. J Urban Health. 2009;86:230–241. 5. Wammes JJG, van der Wees PJ, Tanke MAC, et al. Systematic review of high-cost patients’ characteristics and healthcare utilisation. BMJ Open. 2018;8:e023113. 6. Cohen SB Rockville. The concentration of health care expenditures and related expenses for costly medical conditions, 2012. Statistical Brief (Medical Expenditure Panel Survey (US)). 2001. Available at: https://www.ncbi.nlm.nih.gov/books/NBK470837/ 7. Powers BW, Modarai F, Palakodeti S, et al. Impact of complex care management on spending and utilization for high-need, high-cost Medicaid patients. Am J Manag Care. 2020;26:e57–e63. 8. Gawande A. The hot spotters: can we lower medical costs by giving the neediest patients better care? New Yorker. 2011:40–51. 9. Goldstein BA, Navar AM, Pencina MJ, et al. Opportunities and challenges in developing risk prediction models with electronic health records data: a systematic review. J Am Med Inform Assoc. 2017;24:198–208. 10. Fields WW, Asplin BR, Larkin GL, et al. The Emergency Medical Treatment and Labor Act as a federal health care safety net program. Acad Emerg Med. 2001;8:1064–1069. 11. Kushel MB, Perry S, Bangsberg D, et al. Emergency department use among the homeless and marginally housed: results from a community-based study. Am J Public Health. 2002;92:778–784. 12. Johnson PJ, Ghildayal N, Ward AC, et al. Disparities in potentially avoidable emergency department (ED) care: ED visits for ambulatory care sensitive conditions. Med Care. 2012;50:1020–1028. 13. Das LT, Abramson EL, Stone AE, et al. Predicting frequent emergency department visits among children with asthma using EHR data. Pediatr Pulmonol. 2017;52:880–890. 14. Karter AJ, Warton EM, Lipska KJ, et al. Development and validation of a tool to identify patients with type 2 diabetes at high risk of hypoglycemia-related emergency department or hospital use. JAMA Intern Med. 2017;177:1461–1470. 15. Labby D, Wright B, Broffman L, et al. Drivers of high-cost medical complexity in a Medicaid population. Med Care. 2020;58:208–215. 16. Joynt Maddox KE, Reidhead M, Hu J, et al. Adjusting for social risk factors impacts performance and penalties in the hospital readmissions reduction program. Health Serv Res. 2019;54:327–336. 17. Ziring J, Gogia S, Newton-Dame R, et al. An all-payer risk model for super-utilization in a large safety net system. J Gen Intern Med. 2018;33:596–598. 18. Kansagara D, Englander H, Salanitro A, et al. Risk prediction models for hospital readmission: a systematic review. JAMA. 2011;306:1688–1698. 19. US Census Bureau. American Community Survey Data Profiles 2012-2016 ACS 5-Year Data Profile. Accessed July 25, 2018. https://www.census.gov/acs/www/data/data-tables-and-tools/data-profiles/2016/ 20. Billings J, Parikh N, Mijanovich T. Emergency department use in New York City: a substitute for primary care? Issue Brief (Commonw Fund). 2000;433:1–5. 21. Jacobson L, Newton-Dame R, B K, et al. Using Data to Provide Better Health Care to New York’s Homeless. 2019. Accessed August 12, 2020. https://hbr.org/2019/05/using-data-to-provide-better-health-care-to-new-yorks-homeless 22. Quan H, Sundararajan V, Halfon P, et al. Coding algorithms for defining comorbidities in ICD-9-CM and ICD-10 administrative data. Med Care. 2005;43:1130–1139. 23. Kim DH, Schneeweiss S. Measuring frailty using claims data for pharmacoepidemiologic studies of mortality in older adults: evidence and recommendations. Pharmacoepidemiol Drug Saf. 2014;23:891–901. 24. Kharrazi H, Chi W, Chang HY, et al. Comparing population-based risk-stratification model performance using demographic, diagnosis and medication data extracted from outpatient electronic health records versus administrative claims. Med Care. 2017;55:789–796. 25. Vest JR, Grannis SJ, Haut DP, et al. Using structured and unstructured data to identify patients’ need for services that address the social determinants of health. Int J Med Inform. 2017;107:101–106. 25. Huang Y, Talwar A, Chatterjee S, et al. Application of machine learning in predicting hospital readmissions: a scoping review of the literature. BMC Med Res Methodol. 2021;21:96.
留言 (0)