
記住我
Brain–computer interface (BCI) is a human–computer interaction technology that allows people to directly communicate with a computer or control peripheral device without their surrounding muscles (Vaid et al., 2015). This technology is useful for patients with movement disorders and partial brain injuries, as it helps them realize simple operation and communication (Wolpaw et al., 2000). At present, electroencephalography (EEG)-BCI systems mainly include event-related potentials evoked by endogenous events based on cognitive function (Li et al., 2019), visually evoked potentials (VEP) based on visual stimulation (Mary Judith and Baghavathi Priya, 2021), and event-related area synchronization and event-based active motor imagery in the phenomenon of correlation synchronization (Munzert et al., 2009). Steady-state visually evoked potential (SSVEP) is one of the most popular EEG patterns in the field of BCI. Owing to its advantages such as high information transmission rate (ITR), low requirement on user training, and easy evocation, SSVEP is widely applied to various fields such as medical care, industries, communication, smart home, gaming, robotics, and vehicle control (Zhao et al., 2016; Angrisani et al., 2018; Dehzangi and Farooq, 2018; Farmaki et al., 2019; Nayak et al., 2019; Chai et al., 2020; Shao et al., 2020).
Single-person BCI system’s performance is subject to individual differences between users and their physical or mental conditions, and this weakness becomes more prominent as BCI system develops further (Song et al., 2022). In contrast, multi-person-coordinated BCI can better serve the future socialized human–computer interaction and will most certainly dominate this field both in terms of research and application. Studies have shown that increasing the number of users can substantially improve BCI performance (Valeriani et al., 2016). In human behavior research, teams’ performance is always better than that of individuals. The distinction in performance between teams and individuals is even greater when humans acquire diversified skills, judgments, and experiences under time constraints (Katzenbach and Smith, 2015). As single-person EEG signals have significant individual differences, by collecting multi-person EEG signals and fusing these signals in a reasonable way, signals with more distinctive features can be obtained, and the BCI performance can be improved. EEG signals from multiple subjects can significantly improve ITR in the system compared to single EEG signals (Bianchi et al., 2019). Subjects who need to stare at the stimulation area for a long time are prone to fatigue due to visual stimulation in SSVEP-BCI, which affects the quality of EEG signal acquisition, and this is particularly evident for some subjects (Peng et al., 2019). SSVEP-cBCI can make up for this deficiency by increasing the user dimension and improve the information transmission rate. Acknowledging this viewpoint, this paper explores three feature fusion methods, which include (1) parallel connecting features, (2) serial concatenating features, and (3) feature averaging. These approaches will be explained in detail in section “Methods.” The three feature fusion methods aim to improve the signal-to-noise ratio by merging multi-person EEG information to get refined new features to enhance the BCI performance.
As a branch of machine learning, deep learning has achieved great success in solving problems in computer vision and natural language processing. It is different from traditional machine learning as it does not entail manual feature extraction (LeCun et al., 2015). Using gradient descent learning to optimize convolutional neural network (CNN) parameters successfully solved the problem of handwritten digit classification (LeCun et al., 1998). However, owing to the complexity of EEG signals, the application of deep learning neural networks in EEG signal detection is still in the exploratory stage. Cecotti and Graser (2010) developed a four-layer CNN for P300 detection. At present, the SSVEP EEG signal classification method converts the original EEG signal through FFT and then inputs it into CNN for classification (Cecotti, 2011; Zhang et al., 2019; Ravi et al., 2020). As a superb CNN model designed for EEG, EEGNet exhibits good classification performance, but other models perform better in some moments. In this study, some details of the basic EEGNet were adjusted, and the network structure was modified to adapt to the newly created fusion features. The transfer learning (TL) training strategy using a THU benchmark dataset as the source task training set was adopted to initially train the parameters of the convolutional layer and build the basic feature extractor. Using the data collected by the laboratory as the target task training set and test set, the CNN parameters were further optimized to construct SSVEP-cBCI. In this paper, the classification model is trained with the TL-CNN method, which reduces the required amount of training collected data and improves the classification accuracy. And the feature fusion approach further improves BCI performance in classification accuracy, ITR and stability.
Section “Methods” elaborates on the personnel, equipment, and experimental paradigms associated with the experiments, the three multi-person features fusion methods, the specific structure of the modified CNN in this study, and its difference from EEGNet. Then the following part introduces the specific training method of TL. In section “Results,” the classification accuracy and ITR difference of the three feature fusion methods and those predicted by a single-person CNN are compared. Finally, some significant conclusions are drawn, and the specific usage of the three feature fusion methods in this experiment is analyzed.
Methods Experimental setup The structure of cBCI systemThe cBCI system mainly has two structural forms: distributed and centralized (Wang and Jung, 2011). In both systems, experiments are simultaneously conducted on more than one subject. In the distributed cBCI, subjects’ EEG information is collected individually for subsequent data preprocessing, feature extraction, and pattern recognition through the corresponding BCI subsystem. The results corresponding to each subject are then transmitted to the integrated classifier, and the final decision is produced through decision-making layer’s voting mechanism, while in the centralized cBCI, as shown in Figure 1, subjects’ EEG information is collected individually for sequential data preprocessing and feature extraction. The EEG data features of all subjects are fused for pattern recognition to make the final decision for the group. The model adopted in this study is a centralized cBCI system, which does not rely on the voting mechanism of the distributed system, and classification is carried out with a CNN based on TL (TL-CNN).
FIGURE 1
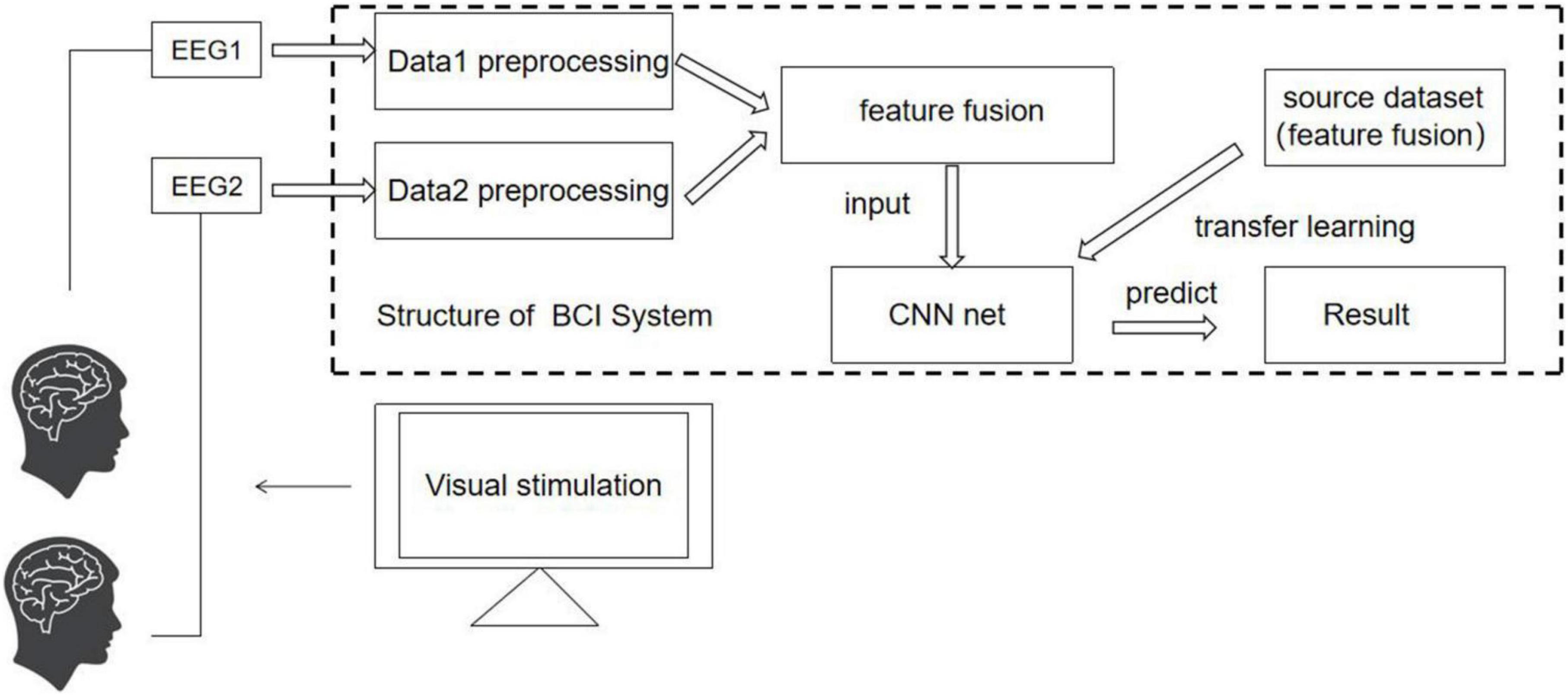
Figure 1. Centralized cBCI structure designed in this study.
Experimental paradigmIn this experiment, the EEG data were collected and transferred from the EEG amplifier to the software Curry8 (Neuroscan). Three electrodes were placed on O1, Oz, and O2 according to the International 10–20 system. Using the double mastoid as reference and ground electrodes, the impedance of all electrodes was reduced to below 5 kΩ. The sampling frequency is 256 Hz, and a band-pass filter between 5 and 40 Hz is used in the data processing to filter out low-frequency noise and 50 Hz power frequency noise.
Ten healthy subjects (8 males, 2 females, 21–27 years old) participated in the experiments. All participants had normal or corrected vision. Four of them had participated in SSVEP experiments previously. All participants read and signed the informed consent forms. Subjects sat on a comfortable chair 60 cm in front of a standard 24-inch monitor (60 Hz refresh rate, 1,920 × 1,080 screen resolution). The SSVEP stimulation interface is shown in Figure 2, and the four stimulation squares are all 50 × 50 pixels. The refresh frequency of the display equals integer multiples of the stimulation frequency of the four color blocks, which can ensure stable stimulation frequency and avoid frequency deviation. The stimulation frequencies of the four color blocks are 8.6, 10, 12, and 15 Hz, respectively. It was evidenced that stimulation frequencies of 10 and 12 Hz can stably induce high-amplitude SSVEP signals (Chen et al., 2015), and the stimulation duration was set to be 4 s. To avoid interference caused by simultaneous flickering of the four color blocks, the phases of the four color blocks are set as 1.35π, 0.35π, 0.9π, and 0.35π, respectively. Prolonged staring at the flickering stimulus color blocks made the subjects feel tired and distracted them, resulting in a frequency deviation of the SSVEP signal. To improve the concentration of the subjects and the quality of SSVEP EEG signals, random labels were used to remind the subjects to look at the corresponding stimulus squares.
FIGURE 2

Figure 2. SSVEP stimulation interface and label reminder method. (A) Stimulus interface. (B) Random tag prompt.
0.02 s after the five-pointed star appeared, the four color blocks started to flash. After the flashing, a rest time of 2 s was given to the subject to adjust the viewing angle. During the experiment, the subjects were asked to focus on the corresponding color block and blink as few times as possible. Each color block flashed twice in total, and there was a 1-min rest between two consecutive experiments.
Multi-Person feature extraction and fusion Multi-Person feature extractionThe EEG data filtered and processed by the fourth-order Butterworth filter is converted from the time domain to the frequency domain by FFT transformation (Chen et al., 2015). Low-frequency (8.6, 10, 12, and 15 Hz) stimulation area was used in these experiments. The features of the frequency band from 6 to 32 Hz were selected from the FFT-transformed data to further filter out noise and improve feature quality.
The characteristics of the SSVEP signal are as follows:
,,,]},,,]},,,]},,,,,]}],"socialLinks":[,"type":"Link","color":"Grey","icon":"Facebook","size":"Medium","hiddenText":true},,"type":"Link","color":"Grey","icon":"Twitter","size":"Medium","hiddenText":true},,"type":"Link","color":"Grey","icon":"LinkedIn","size":"Medium","hiddenText":true},,"type":"Link","color":"Grey","icon":"Instagram","size":"Medium","hiddenText":true}],"copyright":"Frontiers Media S.A. All rights reserved","termsAndConditionsUrl":"https://www.frontiersin.org/legal/terms-and-conditions","privacyPolicyUrl":"https://www.frontiersin.org/legal/privacy-policy"}'>
留言 (0)