
記住我
Emotion plays a critical role in human decision-making, particularly in sports, where emotional stimuli significantly impact athletes' decision-making processes. Emotional stimuli refer to emotional responses triggered by external environments or internal psychological states, such as anger, happiness, and fear (Robazza et al., 2022). These emotional responses affect athletes' reaction speed, judgment accuracy, and strategy choices during competitions. For instance, anger may lead to aggressive decisions, while fear may result in conservative strategies. However, current research on the relationship between emotional stimuli and sports decision-making faces many challenges (Niubò Solé et al., 2022). The diversity and complexity of emotions make their impact difficult to quantify and standardize. Additionally, real-time accurate detection and analysis of emotional changes remain a challenge.
Deep learning technology has made significant progress in the study of sports decision-making. Through large-scale data and complex models, deep learning can capture subtle differences and complex patterns in sports behavior, providing more precise behavior predictions and decision support. For example, convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been widely used in athlete action recognition and trajectory prediction (Wang T. Y. et al., 2023; Ramesh and Mahesh, 2022). Additionally, deep reinforcement learning (DRL) has been employed to optimize athletes' strategy choices, enhancing their performance in competitions (Tamminen and Watson, 2022). However, most of these studies focus on athletes' actions and strategies, with relatively little emphasis on the inclusion and analysis of emotional factors. The integration of emotion recognition and decision-making remains a challenging problem. Facial recognition is an important method for emotion recognition, allowing real-time acquisition of athletes' emotional states through the analysis of facial expressions (Rahimian et al., 2022). Advances in facial recognition technology in terms of accuracy and real-time processing make it significant in sports decision-making research. Facial expressions, as a crucial manifestation of emotions, can provide key emotional information for sports decision-making. For example, during competitions, real-time monitoring of athletes' facial expressions can help assess their emotional states and adjust training plans or competition strategies accordingly (Ding N. et al., 2022). Furthermore, combining deep learning with facial recognition technology can improve the accuracy of emotion recognition, providing more reliable data support for sports decision-making (Perolat et al., 2022). Therefore, facial recognition holds promising applications in studying the impact of emotional stimuli on sports decision-making. In summary, emotional stimuli have a profound impact on sports decision-making. However, current research faces numerous challenges in quantifying and standardizing the influence of emotions (Wang T. Y. et al., 2023). While deep learning technology has shown great potential in sports decision-making research, the incorporation and analysis of emotional factors remain insufficient (Ciaccioni et al., 2023). As an essential means of emotion recognition, facial recognition is significant in studying the impact of emotions on sports decision-making. By integrating deep learning with facial recognition, we can better understand and utilize emotional information, optimizing athletes' decision-making processes.
In recent years, many studies have explored the integration of emotion recognition and sports decision-making, achieving significant progress. Some of these studies have employed deep learning models to improve the accuracy and efficiency of emotion recognition and behavior prediction. A study proposed a convolutional neural network (CNN)-based emotion recognition model to detect athletes' emotional states during training and competitions (Jekauc et al., 2024). This model uses multiple convolutional layers to extract features from facial expressions and employs fully connected layers for emotion classification. The model was trained on standard emotion datasets and tested in actual sports scenarios. Although the model achieved high accuracy in emotion recognition, it performed poorly in handling real-time video streams, exhibiting latency issues. Another study developed an emotion recognition model combining recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) (Liu et al., 2023). This model captures emotional changes in time series using RNNs and utilizes LSTMs to handle long-term dependencies, recognizing behavior patterns under different emotional states. The study trained and validated the model using datasets containing facial expressions and physiological signals. Despite its excellent performance in capturing emotional changes, the model's high computational complexity led to long training times, making it unsuitable for real-time applications. A different research proposed a multimodal emotion recognition model combining CNNs and multilayer perceptrons (MLPs) (Geetha et al., 2024). This model leverages CNNs to extract image features and uses MLPs to process emotion-related physiological signals. The study demonstrated that this multimodal approach improved emotion recognition accuracy, especially when combining visual and physiological data. However, the model's reliance on high-quality multimodal data posed challenges in data collection and synchronization, limiting its broad application. Another study introduced a Transformer-based emotion recognition model, utilizing multi-head attention mechanisms to capture complex relationships between emotional features (Tang et al., 2024). This model was trained on emotion recognition datasets and showed outstanding performance in various emotion recognition tasks. The Transformer model accelerated emotion recognition through parallel processing and enhanced its ability to handle large-scale data. However, the model required extensive training data and computational resources, making it difficult to deploy in resource-constrained real-world applications.
While these studies have made significant advances in emotion recognition and sports decision-making, several shortcomings remain. CNN-based models perform poorly in handling real-time video streams. RNN and LSTM models have high computational complexity, making them unsuitable for real-time applications. Multimodal approaches depend on high-quality data, limiting their widespread application, and Transformer models demand significant computational resources, making them challenging to deploy in real-world applications. These limitations indicate that the effectiveness and efficiency of current emotion recognition technologies in practical applications still need improvement. Therefore, this research aims to improve emotion recognition models by integrating pre-trained ResNet-50, dual-direction attention mechanisms, and multi-layer transformer encoders (MTE). By addressing the shortcomings of existing models, we hope to provide more accurate and efficient emotion recognition and decision support in sports behavior decision-making.
To address these limitations, this study proposes the RDA-MTE model, which integrates a pre-trained ResNet-50, dual-direction attention mechanisms, and a Multi-layer Transformer Encoder (MTE). The model is designed to improve the accuracy and robustness of emotion recognition, particularly in sports decision-making scenarios. The combination of these advanced components allows for more efficient feature extraction, enhanced feature interaction, and improved handling of complex emotional states. We aim to improve emotion recognition, providing reliable emotional data for sports behavior decision-making, even when faced with diverse and challenging scenarios. The RDA-MTE model offers notable improvements in both accuracy and robustness for emotion recognition in sports scenarios. Its architecture enables efficient handling of complex emotional states while maintaining resource efficiency, making it highly adaptable to diverse and challenging environments. The model's ability to manage long-range dependencies and enhance feature interactions contributes to its reliability in supporting sports behavior decision-making.
Based on our research, we have made the following major contributions:
• We propose a novel emotion recognition network, RDA-MTE, which combines a pre-trained ResNet-50, a dual-direction attention mechanism, and a Multi-layer Transformer Encoder (MTE). This model significantly improves the accuracy and real-time performance of emotion recognition with limited data and computational resources. It provides an efficient solution for emotion recognition research, addressing the deficiencies of existing models in handling complex emotional states.
• By introducing the dual-direction attention mechanism, we enhance the interaction between features, enabling the model to perform excellently in processing complex emotional states. This enhancement enhances both the accuracy and robustness of emotion recognition, while also introducing new insights and methodologies for related research.
• Our research demonstrates the broad application prospects of RDA-MTE in practical scenarios, particularly in sports behavior decision-making. By providing accurate emotional data support, our model can help athletes and coaches better understand and manage emotions, thereby optimizing training and competition strategies and improving sports performance.
2 Related work 2.1 Transformers in computer visionThe Transformer architecture, initially successful in natural language processing, was quickly adopted in the field of computer vision. Transformers rely on multi-head attention mechanisms and parallel processing capabilities, excelling at capturing complex relationships between features, particularly in large-scale data processing and long-distance dependency capture (Parvaiz et al., 2023). Transformers significantly improved the performance of visual tasks through the self-attention mechanism and fully parallel processing! (Park and Kim, 2022). Researchers proposed the Vision Transformer (ViT), which treats an image as a sequence of image patches and serializes these patches into input tokens, allowing the application of the Transformer's self-attention mechanism (Touvron et al., 2022). The performance of ViT on the ImageNet dataset demonstrated the potential of Transformers in visual tasks. Further studies showed that the application of Transformers in visual tasks could be enhanced by introducing hierarchical window attention mechanisms, improving the model's efficiency and scalability, and addressing the computational complexity issues when processing high-resolution images (Han et al., 2022). These improved Transformer models achieved outstanding performance in various computer vision tasks, such as object detection and image segmentation.
In the field of emotion recognition, researchers have begun exploring the application of Transformer models. Transformer-based emotion recognition models use multi-head attention mechanisms to capture the complex relationships between facial expression features. Compared to traditional convolutional neural networks (CNNs), Transformers offer better global feature extraction capabilities (Li et al., 2023). Specifically, the multi-head attention mechanism in the Transformer architecture can concurrently attend to various segments of the input data, capturing both global and local emotional features (Ding M. et al., 2022). This capability is especially important when dealing with high-dimensional data such as images and videos, as it can more effectively integrate information and recognize complex emotional states. Transformer models have also been applied to emotion recognition in sports contexts. These models help capture subtle facial expressions and emotional responses to stress and exertion during sports activities such as training and competitions (Mekruksavanich and Jitpattanakul, 2022). By analyzing emotions like anxiety and motivation, they contribute to performance analysis and decision-making systems for athletes (Ramzan and Dawn, 2023).
Experiments have shown that Transformer models perform excellently in various emotion recognition tasks, surpassing traditional CNN models in accuracy and significantly improving processing speed (Tang et al., 2022). This is mainly due to the parallel processing capability of Transformer models, allowing them to handle large amounts of data in a relatively short time (Pan et al., 2022). However, Transformer models in emotion recognition applications also face some challenges. First, the Transformer architecture requires a large amount of training data to optimize model parameters and ensure performance in practical applications (Wu et al., 2022). For emotion recognition tasks, obtaining sufficiently large and accurately labeled emotion datasets is a difficult task. Second, the computational complexity of Transformer models is high, requiring substantial hardware resources, which limits their application in resource-constrained environments (Wang et al., 2022). Additionally, Transformer models need further optimization to improve adaptability to real-time video streams when dealing with dynamic emotional changes.
Despite these challenges, the application prospects of Transformer architectures in emotion recognition are broad. Their powerful feature extraction and parallel processing capabilities provide significant advantages in handling complex emotional features and large-scale data (Cao et al., 2022). With advancements in hardware technology and the enrichment of emotion datasets, Transformer-based emotion recognition models are expected to play a more significant role in practical applications.
2.2 Multimodal emotion recognitionMultimodal emotion recognition enhances accuracy and robustness by integrating data from multiple sources. These systems typically combine visual, audio, and physiological signals to capture more comprehensive and detailed emotional features (Zhang et al., 2023b). This method overcomes the limitations of single-modality emotion recognition approaches by leveraging information from different modalities, thus improving the model's performance in various complex scenarios (Pan et al., 2023). In the domain of sports, multimodal emotion recognition has shown great potential. Studies have combined facial expression analysis with physiological signals, such as heart rate and skin conductance, to monitor athletes' emotional responses during high-pressure situations (Zhou et al., 2020). For instance, the fusion of visual features with heart rate variability helps track emotions like fear and anxiety during physical exertion, offering insights into how these emotions influence athletic performance (Shoumy et al., 2020). This multimodal approach is particularly effective in dynamic, real-time sports environments.
Multimodal emotion recognition research has made significant progress. For example, the visual modality primarily includes facial expressions and eye movement features, while the audio modality encompasses characteristics such as the frequency, pitch, and rhythm of speech (Ahmed et al., 2023). By integrating these two modalities, it is possible to capture emotional changes more comprehensively. When a person is speaking, analyzing both their vocal characteristics and facial expressions can lead to a more accurate determination of their emotional state. Studies have shown that multimodal emotion recognition systems that combine visual and audio features perform excellently in handling different emotional states, particularly in recognizing subtle emotional changes and complex emotional expressions (Chen et al., 2022).
The fusion of visual and physiological signals is another crucial direction in multimodal emotion recognition. Physiological signals include heart rate, galvanic skin response (GSR), and electroencephalography (EEG) (Wang S. et al., 2023). These physiological signals exhibit significant changes with emotional states. By combining these signals with visual features such as facial expressions, the accuracy of emotion recognition can be further enhanced. For instance, when a person is nervous or anxious, their heart rate and GSR increase, and these changes can be combined with facial expression features to provide more comprehensive emotion recognition information (Le et al., 2023). Research has found that the integration of visual and physiological signals has significant advantages in detecting latent emotional states and complex emotional reactions. In multimodal emotion recognition methods, feature-level fusion involves integrating features from various modalities during the extraction stage to create a unified feature representation (Garcia-Garcia et al., 2023). This method includes techniques such as feature concatenation, feature weighted averaging, and principal component analysis (PCA). By concatenating visual and audio feature vectors, a high-dimensional feature vector can be formed, enhancing the feature representation capacity (Sharafi et al., 2022). Decision-level fusion involves combining the outputs of multiple classifiers during the classification stage to obtain the final recognition result. Common methods include voting, weighted voting, and Bayesian inference. By combining predictions from multiple classifiers, we can enhance the precision and reliability of emotion recognition, particularly in addressing complex recognition tasks. Hybrid fusion methods combine the advantages of both feature-level and decision-level fusion (Zhang et al., 2023a). Feature-level fusion can be performed during the feature extraction stage to form a comprehensive feature representation, followed by decision-level fusion of the outputs of multiple classifiers during the classification stage (Zhao et al., 2022). This approach can fully utilize the advantages of various fusion techniques, further improving recognition performance.
Multimodal emotion recognition offers significant advantages in many aspects. Firstly, multimodal fusion can effectively improve the accuracy of emotion recognition (Mocanu et al., 2023). For example, combining visual and audio features can maintain high recognition rates under various environmental conditions. Secondly, multimodal fusion can enhance the model's robustness in handling complex environments and varying conditions by combining different types of features. For instance, multimodal fusion can maintain high recognition performance under changes in lighting, background interference, and variations in emotional expression (Yoon, 2022). Finally, multimodal fusion techniques compress high-dimensional data while preserving feature representativeness and discriminative power, thereby enhancing model processing efficiency.
However, multimodal emotion recognition also faces some challenges. Firstly, collecting and synchronizing multimodal data is both complex and costly. Different modalities of data need to be collected at the same time and accurately synchronized, posing high demands on data collection equipment and technology (Ma et al., 2023). Secondly, processing multimodal data requires higher computational resources, increasing the system's complexity and the difficulty of real-time processing. To address these challenges, researchers continuously optimize multimodal fusion algorithms and model structures, exploring techniques such as data augmentation and transfer learning to enhance the model's performance in practical applications. Overall, multimodal emotion recognition significantly enhances accuracy and robustness by integrating features from diverse sources and types. With continuous technological advancements, multimodal emotion recognition methods are expected to demonstrate their vast potential in more practical applications.
3 Method 3.1 Overview of our networkWe propose a novel emotion recognition network, RDA-MTE, which combines a pre-trained ResNet-50, bidirectional attention mechanism, and a multi-layer transformer encoder (MTE) to enhance the accuracy and real-time performance of emotion recognition. This network provides reliable emotional data support for sports behavior decision-making. ResNet-50, as a feature extractor, leverages its pre-trained convolutional layers to effectively capture subtle features in facial expressions. The primary role of this component is to extract high-quality visual features initially while reducing the training time and computational resource requirements. Building on the features extracted by ResNet-50, we introduce a bidirectional attention mechanism. This mechanism enhances the interaction between features by computing the global dependencies of the input features, thereby better capturing the complex relationships between facial expression features and improving the accuracy and robustness of emotion recognition. The MTE further encodes the features processed by the bidirectional attention mechanism, capturing long-distance dependencies. The transformer model has significant advantages in capturing long-distance dependencies and processing sequential data. Through the attention mechanism, it can process large-scale data in parallel, improving the efficiency and accuracy of emotion recognition. The incorporation of the multi-layer transformer encoder enables RDA-MTE to effectively handle complex emotional features and excel in emotion recognition tasks. The construction process of our RDA-MTE network is as follows: First, the pre-trained ResNet-50 is used to extract high-quality visual features from the input facial expression images. Each convolutional layer of ResNet-50 can capture feature information at different levels, ultimately resulting in a rich feature representation. Based on the features extracted by ResNet-50, a bidirectional attention mechanism is applied. By computing the global dependencies of the input features, the bidirectional attention mechanism can simultaneously focus on local and global information, enhancing the interaction between features. Finally, the features processed by the bidirectional attention mechanism are input into the multi-layer transformer encoder. The transformer model captures long-distance dependencies through the multi-head attention mechanism and further encodes the features. The introduction of MTE allows the model to process large-scale data in parallel, enhancing processing efficiency and accuracy. The features encoded by MTE are then input into a fully connected layer for emotion classification. The classifier learns the distinguishing information of different emotional features and ultimately outputs the emotion recognition results. Figure 1 illustrates the overall structure of our RDA-MTE model.
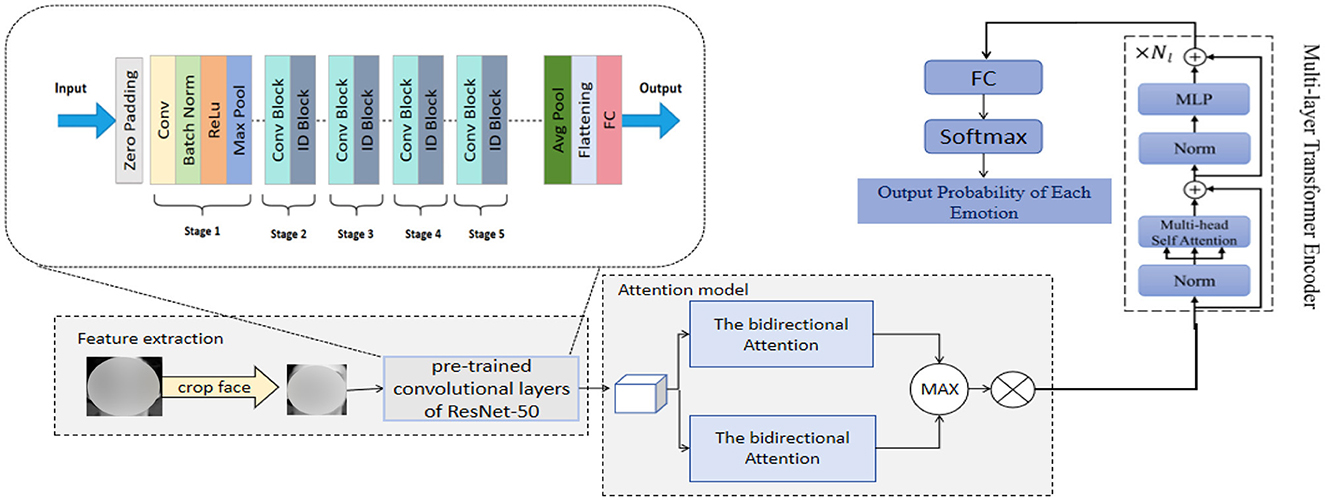
Figure 1. The overall structure of the RDA-MTE model.
The application of the RDA-MTE model in emotion recognition is of great significance, especially in the field of sports behavior decision-making. Emotions directly affect the behavioral decisions of athletes. Real-time and accurate recognition of athletes' emotional states can provide valuable data support for coaches and athletes, helping to formulate training plans and competition strategies. By recognizing athletes' emotional states, training intensity and methods can be adjusted in a timely manner, avoiding the impact of emotional fluctuations on training effects. In competitions, real-time emotion recognition can help coaches adjust tactics based on athletes' emotional states, thereby increasing the probability of winning. Additionally, long-term monitoring of athletes' emotional changes can facilitate emotional intervention and management, improving psychological resilience and performance. In summary, the RDA-MTE model enhances the accuracy and real-time performance of emotion recognition, providing scientific support for sports behavior decision-making and contributing to the overall improvement of training effectiveness and competition results.
3.2 ResNet-50 feature extractorResNet-50 is a deep convolutional neural network model that addresses the issues of vanishing and exploding gradients in the training of deep neural networks by introducing residual blocks. The core idea behind ResNet-50 is the use of skip connections, which allow input information to bypass one or more layers of the neural network and be directly transmitted to the output (Tian et al., 2022). This preserves the original information and accelerates the training process. Comprising 50 layers, ResNet-50 has a strong feature extraction capability, effectively capturing both fine details and high-level semantic information in images. Figure 2 shows the structure of ResNet-50. In the model architecture diagram, ResNet-50 consists of multiple residual blocks, each containing several convolutional layers and skip connections. This design enables ResNet-50 to maintain high feature extraction efficiency while avoiding the vanishing gradient problem, ensuring effective training of deep networks.
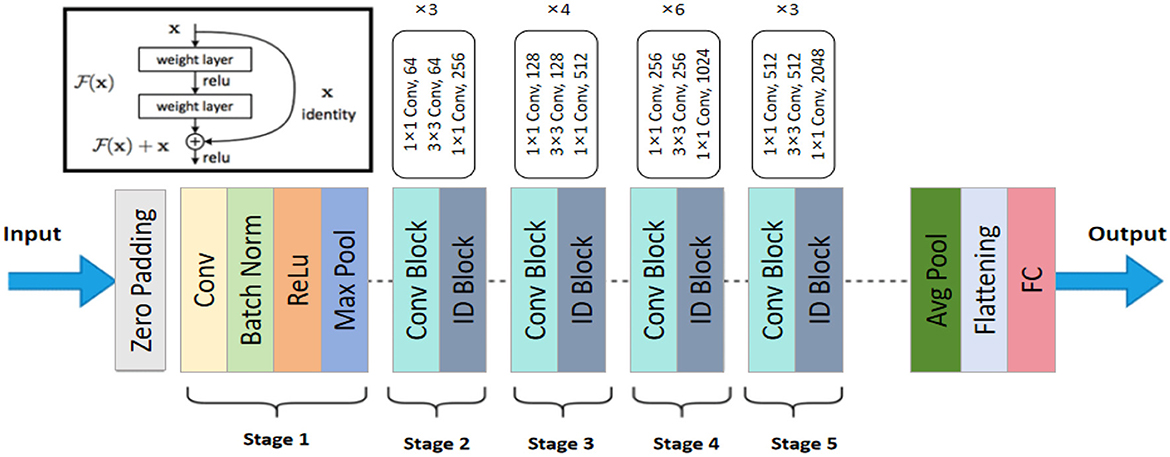
Figure 2. The architecture of the ResNet-50 used in the RDA-MTE model. The network consists of an initial convolutional layer followed by batch normalization and ReLU activation. It includes five stages of convolutional (Conv) and identity (ID) blocks, with each stage having varying numbers of blocks and convolutional filters. The final layers include an average pooling (Avg Pool) layer and a fully connected (FC) layer, producing the output features used for emotion recognition.
In our RDA-MTE model, ResNet-50 serves as the feature extractor, playing a crucial role. First, by utilizing the pre-trained convolutional layers of ResNet-50, we can extract high-quality visual features from the input facial expression images. These features include the geometric structure of the face, texture details, and variations in lighting, providing a rich feature representation for subsequent processing. The pre-training process involves training ResNet-50 on a large-scale dataset, such as ImageNet, which contains millions of labeled images across thousands of categories. This extensive pre-training allows the model to learn a wide variety of visual features that are transferable to other tasks, such as facial expression recognition. Figure 3 illustrates the pre-training process of ResNet-50 on ImageNet.

Figure 3. The pre-training process of ResNet-50. The process starts with training the ResNet-50 model on the ImageNet dataset to create a pre-trained model. This pre-trained model is then adapted for emotion recognition by adding a new dense layer and fine-tuning it using a cleaned facial expression dataset. The final result is a model with pre-trained convolutional layers of ResNet-50, fine-tuned for emotion recognition tasks.
Second, the pre-trained ResNet-50 model significantly reduces training time and computational resource requirements, improving the initial performance and stability of the model. This approach allows us to quickly and accurately extract essential features from facial expressions, laying a solid foundation for subsequent emotion recognition. By leveraging the knowledge gained during the pre-training phase, our RDA-MTE model benefits from enhanced feature extraction capabilities, leading to more accurate and robust emotion recognition results.
Here are the core mathematical formulations for ResNet-50:
Residual block:
xl+1=F(xl,)+xl (1)where xl is the input to the l-th layer, F(xl,) is the residual mapping to be learned, and Wl are the weights of the l-th layer.
Residual mapping:
F(xl,)=Wl,2σ(Wl,1xl) (2)where Wl, 1 and Wl, 2 are the weights of the l-th layer, and σ denotes the ReLU activation function.
Output of residual block:
y=WoutF(xl,)+bout (3)where y is the output of the network, Wout are the weights of the output layer, and bout is the bias of the output layer.
Loss function:
L=1N∑i=1Nℓ(yi,y^i) (4)where L is the loss function, N is the number of samples, yi is the predicted value, ŷi is the ground truth, and ℓ is the loss for each sample.
Binary cross-entropy loss:
ℓ(yi,y^i)=−(y^ilog(yi)+(1−y^i)log(1−yi)) (5)where ℓ(yi, ŷi) is the binary cross-entropy loss for sample i.
Gradient descent update:
Wl←Wl-η∂L∂Wl (6)where Wl are the weights of layer l, η is the learning rate, and ∂L∂Wl is the gradient of the loss with respect to the weights.
Batch normalization and activation:
xl+1=σ(BN(F(xl,)+xl)) (7)where BN denotes the batch normalization function applied to the output of the residual block, and σ is the activation function.
Emotion recognition is a crucial prerequisite for implementing sports behavior decision-making. By accurately identifying the emotional states of athletes, valuable data support can be provided to coaches and athletes, helping them to better formulate training plans and competition strategies. The powerful feature extraction capability of ResNet-50 allows our RDA-MTE model to efficiently and accurately extract facial expression features, thereby enhancing the accuracy and real-time performance of emotion recognition. This improvement not only performs excellently in laboratory environments but also provides scientific evidence for sports behavior decision-making in practical applications, optimizing training effects and competition outcomes. In summary, the ResNet-50 feature extractor plays a pivotal role in our model by efficiently extracting facial expression features, significantly improving the accuracy and real-time performance of emotion recognition, and providing reliable data support for sports behavior decision-making. The application of this technology not only enhances the performance of emotion recognition models but also lays the foundation for achieving more scientific and precise sports behavior decision-making.
3.3 The bidirectional attentionThe bidirectional attention mechanism is a method for enhancing the information processing capability of neural networks by calculating the interdependencies among elements in the input sequence, allowing the model to capture both global and local information more effectively (Feng et al., 2022). In traditional unidirectional attention mechanisms, attention weights consider information from only one direction. In contrast, the bidirectional attention mechanism computes attention weights in both directions, enhancing the model's understanding of the structure and features of the input data. Figure 4 illustrates the structure of the bidirectional attention mechanism. In the model architecture diagram, it can be seen that the input features are processed through attention calculations in both forward and backward directions to obtain attention weights. These weights are then used to weight the input features, resulting in enhanced feature representations.

Figure 4. The architecture of the bidirectional attention mechanism. The mechanism starts with the feature map, which undergoes X and Y linear GDConv operations. The outputs are concatenated and processed through a 1 × 1 Conv2d layer. This is followed by two separate 1 × 1 Conv2d layers, with sigmoid activations, generating the attention map. This process enhances the interaction between features by computing global dependencies of the input features.
In our RDA-MTE model, the introduction of the bidirectional attention mechanism makes significant contributions. First, by calculating the global dependencies of the input features, the bidirectional attention mechanism enhances the interaction between features. This mechanism better captures the complex relationships among facial expression features, improving the accuracy and robustness of emotion recognition. Specifically, the bidirectional attention mechanism simultaneously focuses on both local and global information in facial expressions, enabling the model to perform better in handling complex emotional states. For instance, when input features are processed through the bidirectional attention mechanism, the model can recognize the importance of local regions such as the eyes and mouth and relate these local features to the overall facial expression, thereby forming a more comprehensive and accurate representation of emotions. The bidirectional attention mechanism, by incorporating attention calculations in both forward and backward directions, allows the model to infer the importance of subsequent features from current features and to trace back the importance of current features from subsequent features. This approach captures richer emotional feature information.
Here are the core mathematical formulations for the bidirectional attention Attention mechanism:
Forward attention scores:
eij(f)=w(f)⊤tanh(W(f)xi+U(f)hj-1(f)+b(f)) (8)where eij(f) is the forward attention score, w(f), W(f), and U(f) are learnable parameters, xi is the input feature, hj-1(f) is the previous hidden state, and b(f) is the bias term.
Backward attention scores:
eij(b)=w(b)⊤tanh(W(b)xi+U(b)hj+1(b)+b(b)) (9)where eij(b) is the backward attention score, w(b), W(b), and U(b) are learnable parameters, xi is the input feature, hj+1(b) is the next hidden state, and b(b) is the bias term.
Forward attention weights:
αij(f)=exp(eij(f))∑k=1Texp(eik(f)) (10)where αij(f) is the forward attention weight, eij(f) is the forward attention score, and T is the length of the input sequence.
Backward attention weights:
αij(b)=exp(eij(b
留言 (0)