Human subjects
Blood samples, pedigree information, and access to results of laboratory work were obtained from individuals or parents/guardians if minors after informed consent was given. Patients were diagnosed with ADPKD according to the Pei-Ravine criteria33. The radiographic diagnostic criteria were based on ultrasonography with unknown genotypes, including ≥3 cysts in one or both kidneys in age 15 to 39, ≥2 cysts in each kidney in age 40 to 59, and ≥4 cysts in each kidney in age ≥60. A total of 1421 individuals from 920 families (745 male, median age 44, interquartile range, IQR 33–56) were enrolled in this cohort. The study was approved by the institutional review boards of the National Health Research Institutes and Kaohsiung Medical University Hospital. All participants provided written informed consent to take part in the study.
Primer design, long-range PCR, and multiplex PCR
DNA was extracted according to the standard method from peripheral blood obtained from all study participants after informed consent. The panel is composed of polycystic-related genes, including ALG8, DNAJB11, GANAB, PKD1, PKD2, and PKHD1. A total of seven long-range PCRs of the PKD1 gene were designed to avoid amplification of the pseudogene-overlapping region in exon 1 to exon 33 of PKD1. The long-range PCR method and primers were modified from a previous publication16. Briefly, 100 ng of genomic DNA was used in a 10 μl PCR reaction. A simplified protocol consisting of a three-step touchdown PCR composed of the first step of 95 °C for 3 min, 24 cycles of 95 °C for 30 s, initial 70 °C for 30 s (with a decrease of 0.5 °C per cycle), and 72 °C for 3 min. A second step with 30 cycles of 95 °C for 30 s, 58 °C for 30 s, and 72 °C for 3 min, with a final extension step of 72 °C for 10 min. Q solution was added in the long-range PCR, except PKD1 exon 1 PCR where a 10% DMSO was used. Two microliters of long-range PCR product were mixed followed by a 4000-fold dilution to avoid genomic DNA carry-over. The final product was used as input for target DNA enrichment by the multiplex PCR. The Fluidigm 48.48. Access Array System was used for multiplex PCR as previously described34. Two 48.48 Access Array chips were used, one for PKD1 exon 1 to exon 33 region and one for all other target regions. Primers were pooled to generate 2-plex (PKD1 pseudogene region) or 4-plex primer pools per multiplex PCR. Every sample master mix contained 50 ng DNA, 1X FastStart High Fidelity Reaction Buffer with MgCl2, 5 % DMSO, dNTPs (200 μM each), FastStart High Fidelity Enzyme Blend, and 1X Access Array loading reagent. 48 different DNA or long-range PCR samples were mixed with 48 different multiplex primer pools on one 48.48 Access Array followed by thermal cycling. Subsequently harvested amplicon pools were submitted to another PCR step to tag PCR products with 48 different barcodes and Illumina sequence-specific adaptors. Barcoded PCR products were pooled from 48 individuals and submitted to next-generation resequencing on an Illumina MimiSeq platform with 2 × 150 bp paired-end runs according to the manufacturer’s protocol. Exon 1 of PKD1 was amplified and Sanger sequenced separately if the read depth was insufficient for analysis. All primer sequences were listed in Supplementary Table 5.
Bioinformatics
CLCbio Genomic Workbench (Qiagen, USA) was used for analysis. Identified variants were labeled as pathogenic/likely pathogenic, VUS, or benign according to the guidelines of the American College of Medical Genetics and Genomics (ACMG) and analyzed with Varsome The Human Genomics Community35,36. Variant pathogenicity was determined by the order of ACMG-Databases-family segregation. Variant not classified as pathogenic/likely pathogenic by ACMG guideline was considered pathogenic or likely pathogenic if the same variant segregated in the family and existed in the ClinVar Database37, the Leiden Open Variation Database38, or the ADPKD Variant Database39. Classified pathogenic/likely pathogenic variants that did not segregate in the family were considered as VUS. Detected variants of pathogenic, likely pathogenic, and unknown significance were confirmed by Sanger sequencing. Segregation analysis was performed if DNA from family members were available.
Microsatellite analysis
Microsatellite analysis was performed in a total of 111 PKD2 p.Arg803* families. Five polymorphic markers located outside the PKD2 region, including D4S1534, D4S1542, D4S1563, D4S1544, and D4S414 were selected as previously described23. Primer sequences were described in Supplementary Table 5. Microsatellite analysis was performed as a previous publication40. Briefly, the 5′ end of each forward primer was tagged with the following universal tag sequence: 5′-GAGAGAAAGGGAAGGGAG-3′. A universal primer, consisting of the same sequence as the added tag, was fluorescently labeled with 6-FAM or TET. PCR products were separated on an automated capillary sequencer (3130XL, Applied Biosystems) and results were analyzed with the Peak Scanner 2 (Applied Biosystems).
Genotyping, haplotype, and principal component analysis
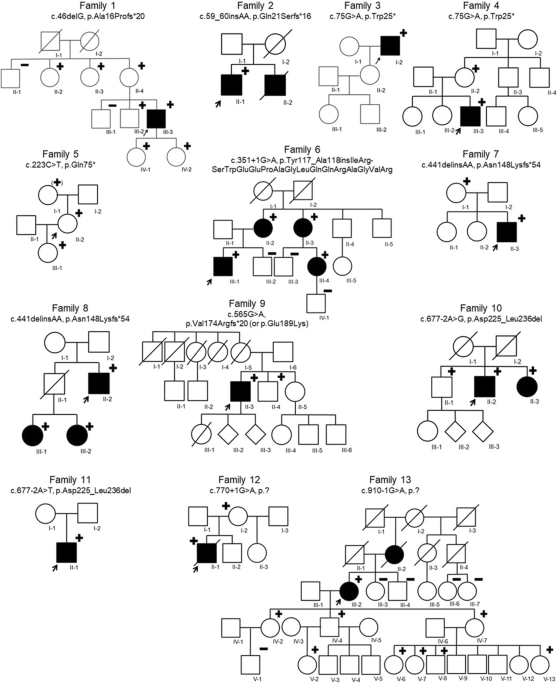
A total of 78 families (96 individuals) harboring PKD2 p.Arg803* were selected for haplotype analysis. A total of 480 health controls were selected from Taiwan Biobank (https://taiwanview.twbiobank.org.tw/data_appl). The Axiom Genome-Wide TWB 2.0 Array which contained 752,921 SNP probes was used for genotyping41. Data analysis was performed by using Axiom Analysis Suites 5.0.1 (Thermo Fisher Scientific). The CEL files from the microarray were converted to PLINK format via PLINK1.9 (www.cog-genomics.org/plink/1.9/). Haplotype reconstruction was first conducted by manually phasing the region in the families with affected members. Twelve families in the disease group were manually phased first, and their shared haplotypes were set as known phases and analyzed with other cases by PHASE2.1, a program based on a Bayesian statistical method using coalescent-based models that considers the joint distribution of haplotypes and infer loci from unphased genotype data42,43. Posterior distributions in PHASE were estimated by Gibbs sampling, a Markov-Chain Monte Carlo algorithm44, and the haplotype with the highest probability was chosen to represent each individual. For principal component analysis, the population structure of 96 PKD2 p.Arg803* carriers, 480 control individuals from Taiwan Biobank, and eleven population samples from the HapMap 3 project (https://www.sanger.ac.uk/resources/downloads/human/hapmap3.html) were analyzed by PLINK1.9. The SNPs selection for PCA were according to Wei et al.41 with the following criteria: minor allele frequency >5%, low inter-marker linkage disequilibrium (r2 < 0.3), call-rate larger than 99%, and Hardy-Weinberg equilibrium (p > 10−4).
Age of mutation analysis
DMLE + 2.3 was used to estimate the age of mutation by comparing the linkage disequilibrium between mutation position and linked markers in unrelated health controls and affected cases45. Multiple parameters were set as default for Bayesian estimation. The population growth rate was calculated by averaging Taiwan’s population growth rate from 1960 to 2020 in a medium-variant projection (1.31%). The proportion of PKD2 p.Arg803* disease allele frequency was obtained from TOPMed data in the dbSNP Database46.
Analysis of PKD2 p.Arg803* variant associated with renal function decline
To explore the influences of the PKD2 p.Arg803* variant on the eGFR decline, we conducted a repeated measures mixed model incorporating random intercept and slope. A total of 57 PKD2 p.Arg803* individuals (28 male, 738 measurements) and 26 PKD2 non-p.Arg803* truncation individuals (20 male, 446 measurements) were included. The longitudinal eGFR in the study was calculated using the CKD-EPI creatinine equation47. Each patient’s follow-up year for eGFR measurements was determined as the period from the date of the first eGFR measurement to the date of the subsequent measures. We put the age at baseline, sex, follow-up year, quadratic follow-up year, and the interaction term between time and group effect using the forced entry approach. The model was performed using SAS (version 9.4, SAS Institute, Cary, NC, USA). A p value < 0.05 was considered statistical significance.
Reference sequences and variant nomenclature
The following NCBI Ref sequences were used, ALG8: NM_024079.5, DNAJB11: NM_016306.6, GANAB: NM_198335.4, PKD1: NM_001009944.3, PKD2: NM_000297.4, PKHD1: NM_138694.4. The standard nomenclature recommended by Human Genome Variation Society was used to number nucleotides and name mutations or variants48.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.

留言 (0)