
記住我
Brain tumors, also known as intracranial tumors in medical terminology, are abnormal masses of tissue characterized by uncontrolled cell growth and proliferation. According to the National Brain Tumor Society (1), gliomas account for approximately one-third of all brain tumors. Gliomas predominantly originate from glial cells, which surround and support the neurons in the cerebral cortex. These glial cells include ependymal cells, oligodendrocytes, and astrocytes. Gliomas put pressure on the brain or spinal cord, causing symptoms such as headaches, changes in personality, and weakness in the arms, etc. (2). They can disrupt brain function and pose a significant threat to an individual’s life. The exact cause of gliomas remains unclear, and they can develop in all age groups, with a higher incidence observed in adults. Early detection and diagnosis of gliomas are critical to the effectiveness of treatment. Therefore, it is important to identify and diagnose gliomas in a timely manner to improve therapeutic outcomes.
In recent years, advances in medical imaging techniques such as positron emission tomography (PET), computed tomography (CT), and magnetic resonance imaging (MRI) have become increasingly important in the detection and diagnosis of disease. These different imaging modalities have the ability to identify distinct tumor regions within soft tissue (3). Typically, gliomas can be identified using a variety of MRI modalities, including T1-weighted (T1), T1-weighted with contrast enhancement (T1-CE), T2-weighted (T2), and T2-weighted fluid-attenuated inversion recovery (FLAIR). Each of these imaging modalities offers unique perspectives and insights into the properties of the tumor, resulting in different representations of the tumor on the images, as shown in Figure 1. After acquiring multimodal volumetric data of gliomas, a meticulous pixel-by-pixel segmentation process is applied to each individual slice until the entire 3D brain volume is accurately delineated into informative areas, establishing the ground truth (GT). The resulting segmentation output is then central to subsequent stages, including diagnosis, treatment planning, surgical strategies, and ongoing monitoring of tumor dynamics and changes.
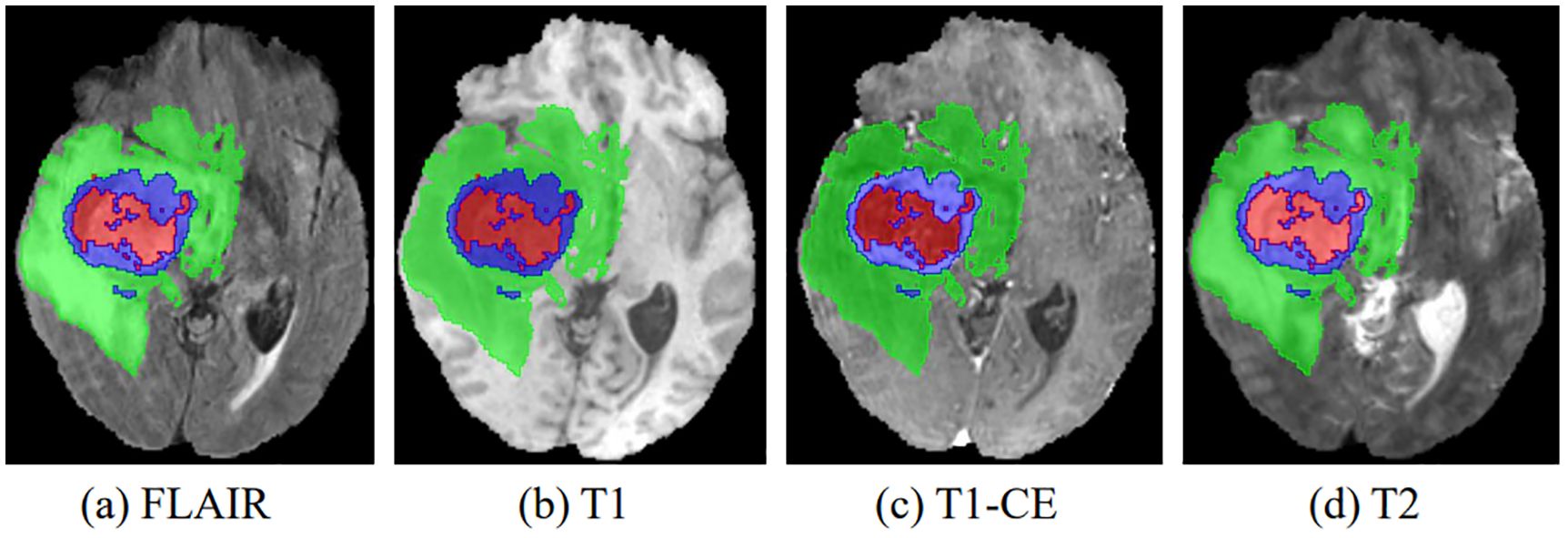
Figure 1. The four multimodal MR images with glioma tumors are: (A) FLAIR, (B) T1, (C) T1-CE, and (D) T2. Different colors are used to differentiate tumor subregions: red for necrotic and non-enhanced tumor (NCR/NET), green for peritumoral edema (ED), and blue for enhanced tumor (ET).
In the search for valuable insights into brain tumors, radiologists have traditionally relied on manual segmentation of MRI images, using their expertise in anatomy and physiology (4). However, manual pixel-level segmentation of brain tumors by radiologists is a labor-intensive process (5). Radiologists face significant challenges during manual segmentation due to factors such as indistinct boundaries of gliomas, which includes peritumoral edema, necrotic cores, and tumor core enhancement. As a result, manual segmentation efforts by radiologists typically yield Dice scores in the range of 74% to 85% (6). Furthermore, manual segmentation is time-consuming, with radiologists spending 3–5 hours annotating an MRI scan for a single patient (7). Therefore, fully automated glioma segmentation methods are of paramount clinical importance and practical value (8).
Glioma segmentation faces significant challenges characterized by high heterogeneity and regional imbalances. First, high heterogeneity is evident in the wide variety of tumor shapes, structures, and locations. As shown in Figure 1, gliomas exhibit considerable inter-patient variability in structural characteristics, geometric configurations, and spatial distributions. This inherent variability poses a significant impediment to the accuracy of glioma segmentation. Consequently, an optimal model must effectively capture both local features (such as texture and edges) and global features (including shape, location, and structure) of gliomas. However, most existing convolutional neural networks (CNNs) focus primarily on extracting features at the local level, falling short of achieving a comprehensive representation.
Second, regional imbalance arises from the large size differences between the brain tumor, the background, and various tumor subregions. In the case of the BraTS2020 dataset, pixels within the tumor region represent only 1.1% of the total pixels. This tiny fraction of the tumor region may inadvertently cause the model to prioritize the background region, hindering accurate characterization of tumor features. Moreover, the proportions of each tumor subregion within the total tumor are significantly different (58%, 19.8%, and 22.2% for the whole tumor (WT), enhanced tumor (ET), and tumor core (TC), respectively). This unbalanced distribution among subregions presents a substantial challenge for the model in classifying categories within these smaller proportions.
Many existing methods incorporate global information to address the challenges mentioned above. Typically, these methods use atrous convolution to expand the receptive field. However, in scenarios involving data types with smaller regions, such as brain tumors, atrous convolution may miss pixels, making it less suitable. A limited number of methods have used self-attention mechanisms to establish long-range dependencies. For example, Chen et al. (9) introduced a Parallel Self-Attention (PSSA) mechanism that transforms self-attention into a standard convolution operation on an appropriately transformed feature. This innovation effectively unifies self-attention and convolution. However, this approach diffuses local features into global features through layer stacking, which may dampen the performance of the method. Notably, the Transformer architecture excels at capturing global representations and requires fewer computational resources compared to traditional self-attention mechanisms (10). For example, Zhang et al. (11) proposed the parallel branched TransFuse network, which combines both Transformer and CNN architectures. This network includes a BiFusion module, consisting of spatial attention and channel attention, to facilitate feature fusion between the two branches. However, a limitation of this approach is the lack of fusion between the Transformer and CNN branches during the down sampling process, as these branches remain independent.
In the present study, we develop a unique DeepGlioSeg framework that enables glioma segmentation in multimodal MRI data. This network adopts a U-shaped architecture with skip connections, strategically used to support the continuous exploitation of contextual information. The DeepGlioSeg network introduces a central CTPC (CNN-Transformer Parallel Combination) module as its core component, comprising parallel branches for both CNN and Transformer networks. This innovative module facilitates the fusion of local and global features within glioma images through the collaborative interaction of these two branches. As a result, it effectively captures both the global and local features of gliomas, mitigating the challenges posed by the high heterogeneity in tumor shape, structure, and location. As shown in Figure 2, this module consistently outperforms convolution-based feature maps in accurately capturing the intricate shape and structure of gliomas. In addition, the DeepGlioSeg network employs a weighted loss approach to address the issue of region imbalance. It extends the generalized Dice loss to account for multiple regions and adjusts the contribution of each region with weighted values. Specifically, larger loss weights are assigned to categories associated with smaller regions, thereby increasing the focus on the tumor region.
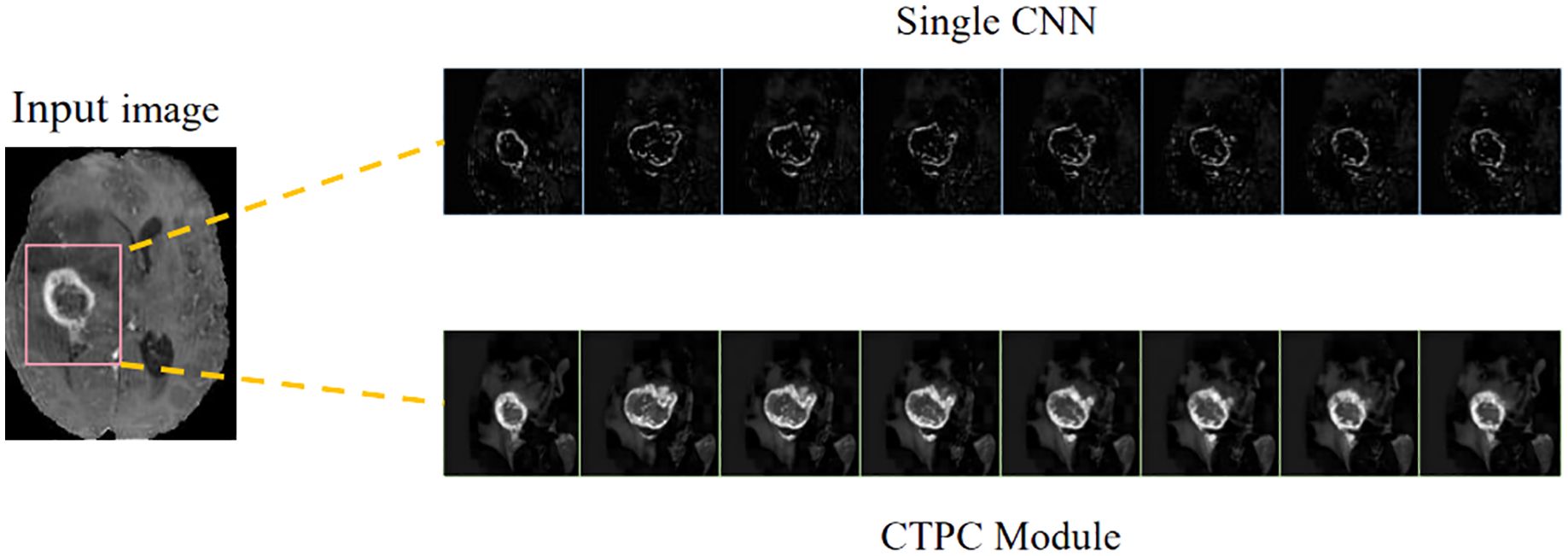
Figure 2. Comparison of feature maps between the CTPC module and CNN.
We summarize our contributions as follows:
1. Our method introduces a CTPC module, which includes both a Transformer branch and a parallel CNN branch. This module facilitates the fusion of local and global features within glioma images through the interactive cooperation of these two branches, enhancing contextual relationships.
2. Our method assigns specific weights to each region based on the volume ratio of the region relative to the background. This weighting mechanism increases attention to the tumor region.
3. To evaluate the robustness of our algorithm, we curated a private brain tumor dataset consisting of data from 232 patients. Extensive experiments were performed on this private dataset, as well as on three publicly available datasets. The results consistently demonstrate the effectiveness of our proposed approach.
2 Related works2.1 Brain tumor segmentation methodsPrevious research on brain tumor segmentation in MR images can be categorized into (1) machine learning-based segmentation methods and (2) CNN-based segmentation methods. Machine learning-based methods have been adapted for brain tumor segmentation tasks, such as support vector machines (SVM) (12) and random forests (13). For example, Bauer and colleagues (14) employed SVM classification methods in conjunction with hierarchical conditional random field regularization to improve the segmentation of brain tumor images.
CNNs have been extensively applied to brain tumor segmentation tasks, yielding remarkable results. For instance, spatial attention gates and channel attention gates were introduced into the U-Net network architecture by Xu et al. (15). Additionally, Xu et al. (15) developed a new FCN with a feature reuse module and a feature integration module (F2-FCN), enabling the extraction of more valuable features by reusing features from different layers. Shen and Gao (16) introduced a network with an encoding path that operates independently across channels and a decoding path focusing on feature fusion. This network utilizes self-supervised training and presents a novel approach to domain adaptation on the feature map, mitigating the risk of losing important restoration information within channels.
Cascaded methods have also emerged as a key research focus in brain tumor segmentation, achieving notable advancements through various strategies. For instance, Le Folgoc et al. (17) introduced lifted auto-context forests, a multi-level decision tree structure that optimizes segmentation via auto-context mechanisms. Wang et al. (18) proposed a cascaded anisotropic convolutional neural network, enhancing tumor edge and structure segmentation with anisotropic convolutional kernels. Lachinov et al. (19) iteratively refined segmentation results using a cascaded 3D U-Net variant, demonstrating its efficacy on the BraTS2018 dataset. Weninger et al. (20) designed a two-step approach with a 3D U-Net for tumor localization, followed by another for detailed segmentation into core, enhanced, and peritumoral edema regions. Finally, Ghosal et al. (21) developed a deep adaptive convolutional network with an adaptive learning mechanism that dynamically adjusts parameters, addressing the complexity of multimodal MRI.
2.2 Segmentation combined with CNN and transformerThe application of Transformer architecture to image segmentation has recently gained prominence, particularly in its integration with CNNs, a fusion that has yielded remarkable results in the field of medical image segmentation (9, 22–24). For example, Cao et al. (22) constructed a Transformer-based U-type skip connection encoder-decoder architecture called Swin-Unet. It is the first pure Transformer segmentation network and successfully demonstrates the applicability of transformers in the visual data domain. Building on Swin-Unet, more and more methods have begun to explore the fusion of Transformer and CNN. For instance, Hatamizadeh et al. (23) presented the architecture of UNet Transformer (UNETR), which uses a pure Transformer as the backbone for learning features in the encoding part, while only CNN is used in the decoding part.
Furthermore, not limited to Transformer, there has been increasing exploration of the application of self-attention mechanisms. For example, Chen et al. (9) theoretically derived a global self-attention approximation scheme that approximates self-attention by performing convolution operations on transformed features. Building on this, some approaches have developed multi-module structures that combine convolution and self-attention to integrate both local and non-local interactions. For instance, Petit et al. (24) presented the U-transformer model, which combines the U-type image segmentation structure with the self-attention and cross-attention mechanisms of the Transformer.
Recent advancements in hybrid CNN-Transformer architectures have significantly improved glioma segmentation by enhancing boundary precision and integrating local and global features. Gai et al. (25) proposed RMTF-Net, which combines ResBlock and mixed transformer features with overlapping patch embedding and a Global Feature Integration (GFI) module to improve decoding quality. Zhu et al. (26) developed a multi-branch hybrid Transformer that combines the Swin Transformer for semantic extraction and a CNN for boundary detection, incorporating a Sobel-based edge attention block to enhance tumor boundary preservation. Hu et al. (27) introduced ERTN, a dual-encoder model with a rank-attention mechanism to prioritize key queries, balancing performance and efficiency. These studies showcase diverse strategies for leveraging CNN-Transformer hybrids to address segmentation challenges, particularly in cases with complex tumor boundaries.
2.3 Category imbalanceA common problem in pixel-level semantic segmentation is class imbalance. This issue tends to reduce accuracy in regions belonging to the minority class (28, 29). For example, Hossain et al. (30) suggested that an effective way to address class imbalance is to adjust the loss function. They propose the bifocal loss function (DFL) to correct the problem of vanishing gradients in focal loss (FL). They introduce a regularization term to impose constraints on the negative class labels, which increases the loss for classes that are difficult to classify. Bressan et al. (31) used pixel-level weights in the training phase to dynamically adjust the importance of individual pixels, either increasing or decreasing their weight as needed. In other words, the contribution of each pixel in the loss function is weighted, which increases the importance of minority class pixels. Pan et al. (32) also faced the challenge of unbalanced foreground and background voxels when performing coronary segmentation. They use the concept of focal loss to optimize the network and achieve good results. To address the significant class imbalance problem observed in brain tumors, we follow the approach of the GDL loss function and assign more weight to small class regions, minimizing the model’s focus on background regions.
3 MethodologyThe proposed DeepGlioSeg framework consists of two phases: (1) the training phase, which includes data preprocessing, loss calculation, and parameter updating, and (2) the inference phase, which includes data preprocessing, learned model import, and postprocessing. A diagram summarizing this framework is shown in Figure 3.
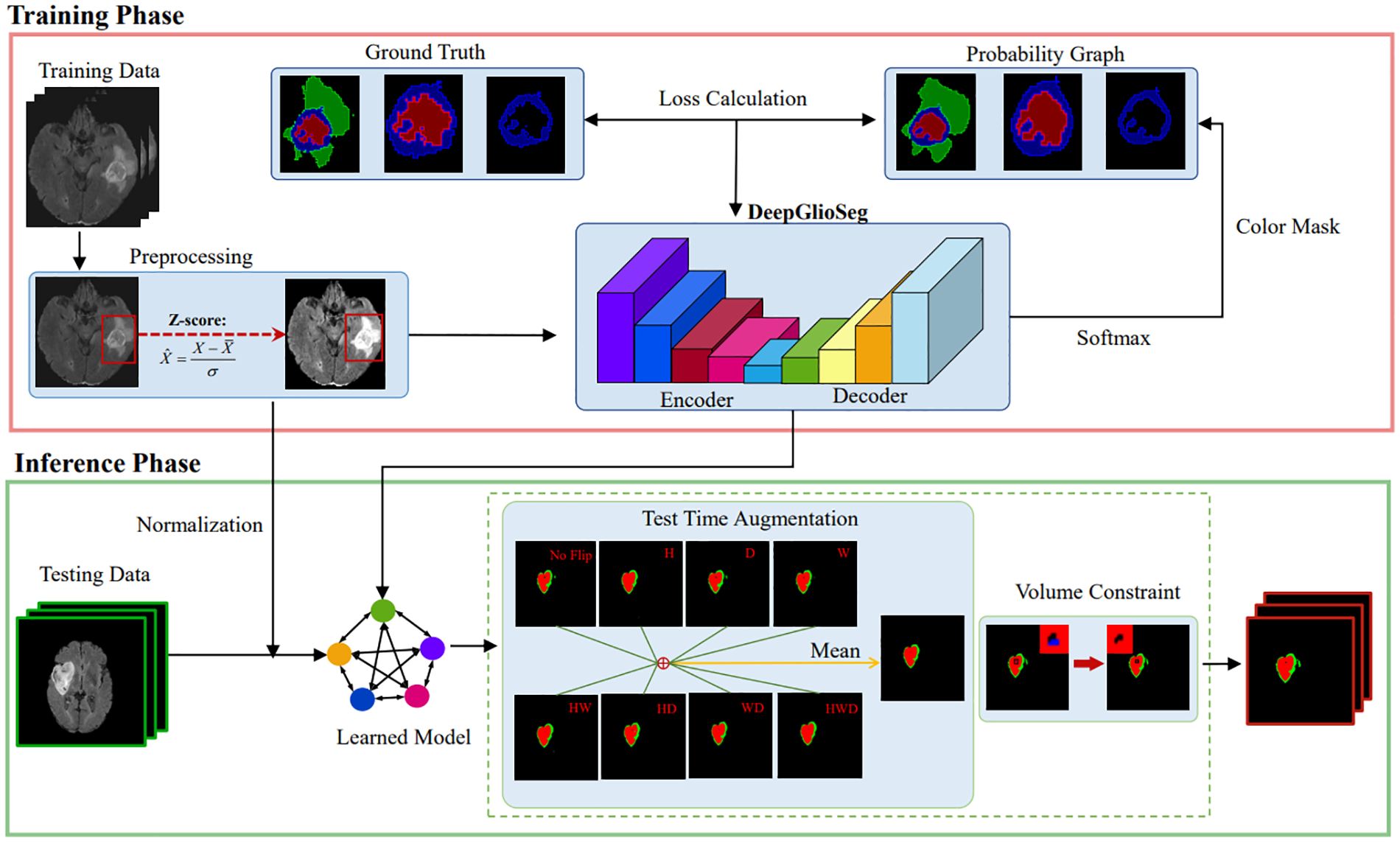
Figure 3. The diagram of the proposed DeepGlioSeg for automated glioma segmentation in multimodal MRI images.
3.1 PreprocessingWe used the BraTS and ZZH datasets, where each brain MRI scan includes FLAIR, T1, T1-CE, and T2 modalities, each with distinct eigenvalue distributions due to contrast differences. These variations pose challenges such as slower convergence and overfitting due to inconsistent intensity scales across modalities. To address these issues, we normalized voxel values within brain regions by subtracting the mean and dividing by the standard deviation. This standardization facilitated effective learning and mitigated convergence issues. Voxel values in non-brain regions were set to zero to eliminate interference from irrelevant background data. The normalization formula is as follows:
where X′ represents the processed image, X symbolizes the original voxel value in the brain region, μB signifies the average intensity value of the brain region, and σB indicates the standard deviation of the brain region. This approach ensures that the model can focus on meaningful information while reducing variability caused by background noise. To further enhance robustness and generalization, we applied data augmentation techniques such as random rotations, flips, and elastic deformations. These augmentations prevent overfitting by exposing the model to diverse variations, improving its performance on unseen data in real-world clinical settings.
Four sets of modal sequences, each with a size of 240×240×155, were merged to obtain 4-channel 3D image data with a size of 240×240×155×4. Each training example has a corresponding label with a size of 240×240×155. The labels consist of four categories: background (label: 0), necrotic and non-enhanced tumor (label: 1), peritumoral edema (label: 2), and GD-enhanced tumors (label: 4). Finally, based on hardware and computational considerations, a training patch with a size of 128×128×128 was extracted from the training case.
3.2 DeepGlioSeg network architectureThe general design of DeepGlioSeg is shown in Figure 4A, which features a symmetric encoder-decoder architecture with skip connections. The basic concept revolves around the alternating stacking of CTPC modules and down sampling layers, combining local features with global representations at different resolution levels. Importantly, the CTPC module maintains consistent feature map sizes, while deconvolution gradually restores resolution. Throughout the network, all convolutional layers are complemented by batch normalization layers and ReLU activation functions. To mitigate overfitting, an initial convolutional layer with dropout functionality is included at the beginning of the model. Additionally, eight successive convolutional layers are implemented at the base of DeepGlioSeg to enhance feature extraction.
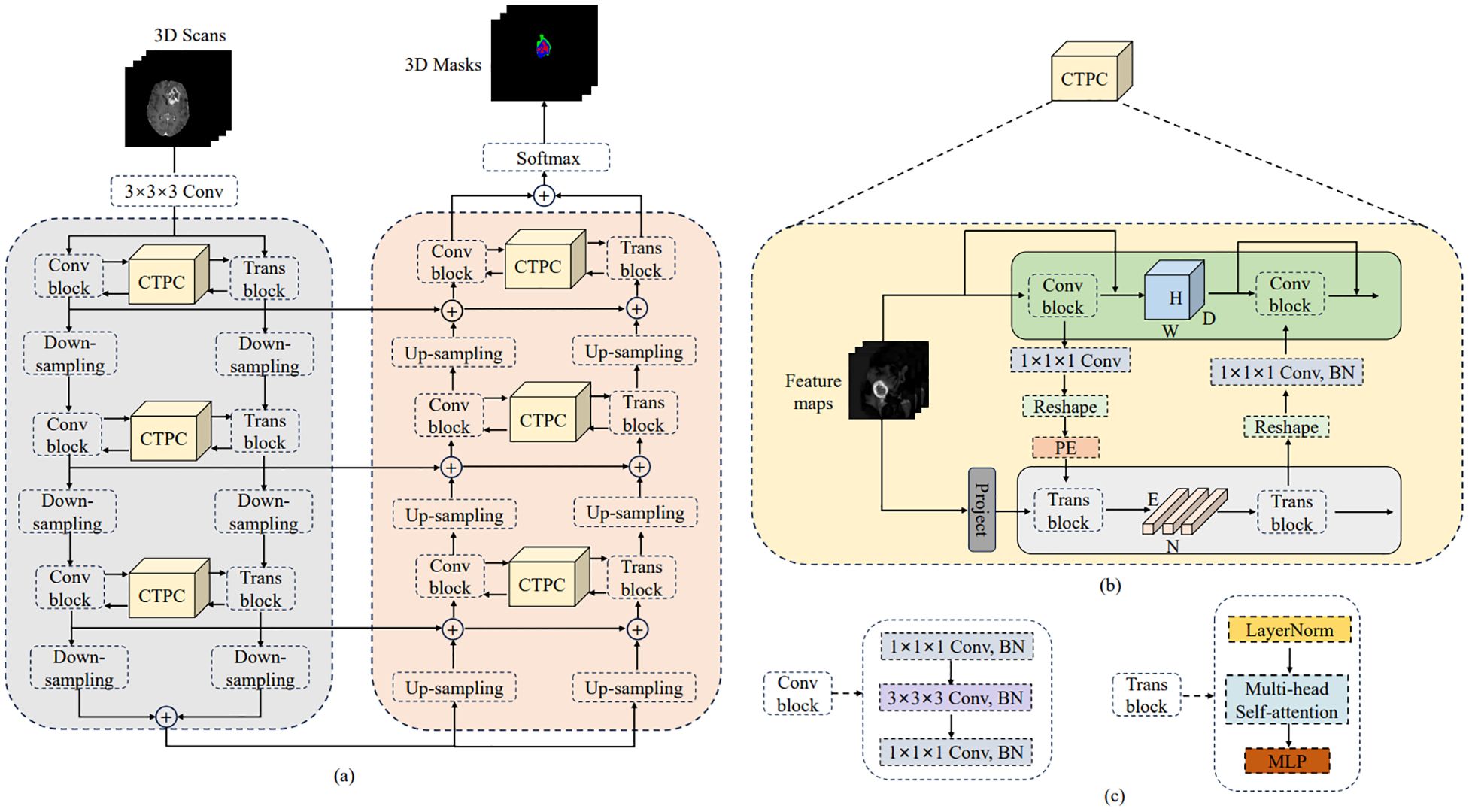
Figure 4. Overview of the proposed DeepGlioSeg network architecture: (A) The architecture of DeepGlioSeg. (B) The specific implementation steps of the CTPC module. (C) The detailed composition of the Conv block and Trans block.
To manage the computational demands within the Transformer branch, the Feature Fusion Pathway (FFP) employs different down sampling steps corresponding to various resolution levels while maintaining a patch embedding size of 4096. It is important to note that the feature map input to the Transformer remains constant at 16×16×16.
3.3 CTPC module structureIn deep learning, CNNs collect local features at different resolutions by applying convolutional operations, effectively preserving local details as feature maps. Vision Transformers, on the other hand, are specifically designed to aggregate global representations by iteratively processing compressed patch embeddings through a series of self-attention modules. The CTPC module, as shown in Figure 4B, consists of three essential elements: the CNN module, the Transformer branch, and the FFP. These components are integrated to facilitate feature fusion between the two branches, effectively enhancing the feature extraction capabilities of the network.
3.3.1 CNN branchAs shown in Figure 4C, the CNN branch consists of two iterative convolution modules. Each module contains a sequence of a 1×1×1 downward convolution layer, a 3×3×3 spatial convolution layer, a 1×1×1 upward convolution layer, and a residual link connecting the module’s input and output. While the Vision Transformer encodes image patches into word vectors, potentially leading to a loss of local detail, the CNN branch operates differently. In a CNN, the convolutional kernel glides over the neighborhood map, enabling it to extract continuous local features. This feature allows for the preservation of intricate and detailed local features to a significant extent. As a result, the CNN branch serves as a continuous supplier of local detail to the Transformer branch.
3.3.2 Transformer branchThe Transformer branch includes a multi-head self-attention module and a multi-layer perceptron (MLP) block, as shown in Figure 4C. Layer normalization is applied before both the multi-head self-attention module and the MLP block. Additionally, two residual connections are incorporated at corresponding positions. To balance computational efficiency and feature map resolution, the CNN branch output is down sampled to a 16×16×16 patch embedding.
3.3.3 Feature fusion pathThe FFP functions to connect and align the shape disparity between the feature map in the CNN pathway and the patch embedding in the Transformer pathway. It actively promotes the continuous integration of local features with global representations through interactive mechanisms. Notably, the shape of the feature stream differs between the CNN and Transformer pathways. Specifically, the CNN feature map has a shape of C×H×W×D, where C, H, W, and D denote the channel, height, width, and depth, respectively. In contrast, the patch embedding takes the form E×C, where E is the embedding size and C is the number of image patches. Prior to inputting the feature map into the Transformer branch, channel alignment of the feature map and patch embedding is achieved by a 1×1×1 convolution. The volume dimensions are then compressed to 16×16×16 using the down sampling module, with different steps chosen for different resolution levels. Finally, the patch embedding is obtained via a reshape operation.
3.3.4 Position embeddingTo capture essential positional information crucial for the segmentation task, we introduced learnable positional embeddings that are merged with the patch embedding by direct addition. When transitioning from the Transformer branch back to the CNN branch, it is necessary to upsample the patch embedding to restore it to the original shape of the CNN feature map. A 1×1×1 convolutional layer is then applied to harmonize the channel dimensions. Finally, the resulting output is combined with the feature map. Throughout this process, batch normalization is used to regulate the features.
3.4 Loss functionThere is a significant data imbalance between tumor and non-tumor tissue for the purpose of identifying and delineating brain tumors and their subregions. Sudre et al. (33) noted that as the degree of data imbalance increases, the loss function based on overlap measurement is less susceptible to fluctuations compared to weighted cross-entropy. Therefore, the Dice coefficient was utilized to focus on different tumor subregions. The formula for the Dice coefficient is given by:
LDice=1−2∑i=1Npigi+ϵ∑i=1Npi+∑i=1Ng+ϵ(2)In this formula, gi represents the ground truth label for pixel i in category c, and pi denotes the predicted probability of pixel i belonging to category l. The term N represents the total number of pixels in the image, and ϵ is a small constant added to avoid division by zero, ensuring the stability of the loss function.
For multi-class segmentation tasks, a weight wl is typically introduced based on the frequency of each category l. According to the statistical analysis of the proportion of each category, the weights were set to 0.1, 1, 2, and 2 for the background, WT, TC, and ET, respectively. The Multi-class Generalized Dice Loss (Multi-GDL) was then used as the model’s loss function, which can be written as:
LGDL=1−2∑l=1Lwl∑i=1Npi(l)gi(l)+ϵ∑l=1Lwl(∑i=1Npi(l)+∑i=1Ngi(l))+ϵ(3)In the above formula, L represents the total number of classes, and pi(l) and gi(l) denote the predicted probability and ground truth label for pixel i in class l, respectively. The weight wl ensures that the contribution of each class is appropriately adjusted based on its frequency, addressing the issue of data imbalance.
3.5 PostprocessingIn the inference phase, the original image was sliced from left to right and from top to bottom into eight inference blocks of size 128×128×128 and post-processed with test-time augmentation (TTA) and volume-constraint (VC). For each inference block, seven different flips ((x), (y), (z), (x, y), (x, z), (y, z), (x, y, z)) were performed, as shown in Figure 5A. The flipped data were then fed into the model, and the corresponding inference results were obtained. The rotation angles of the different inference results were restored, and the average value was taken as the final output.
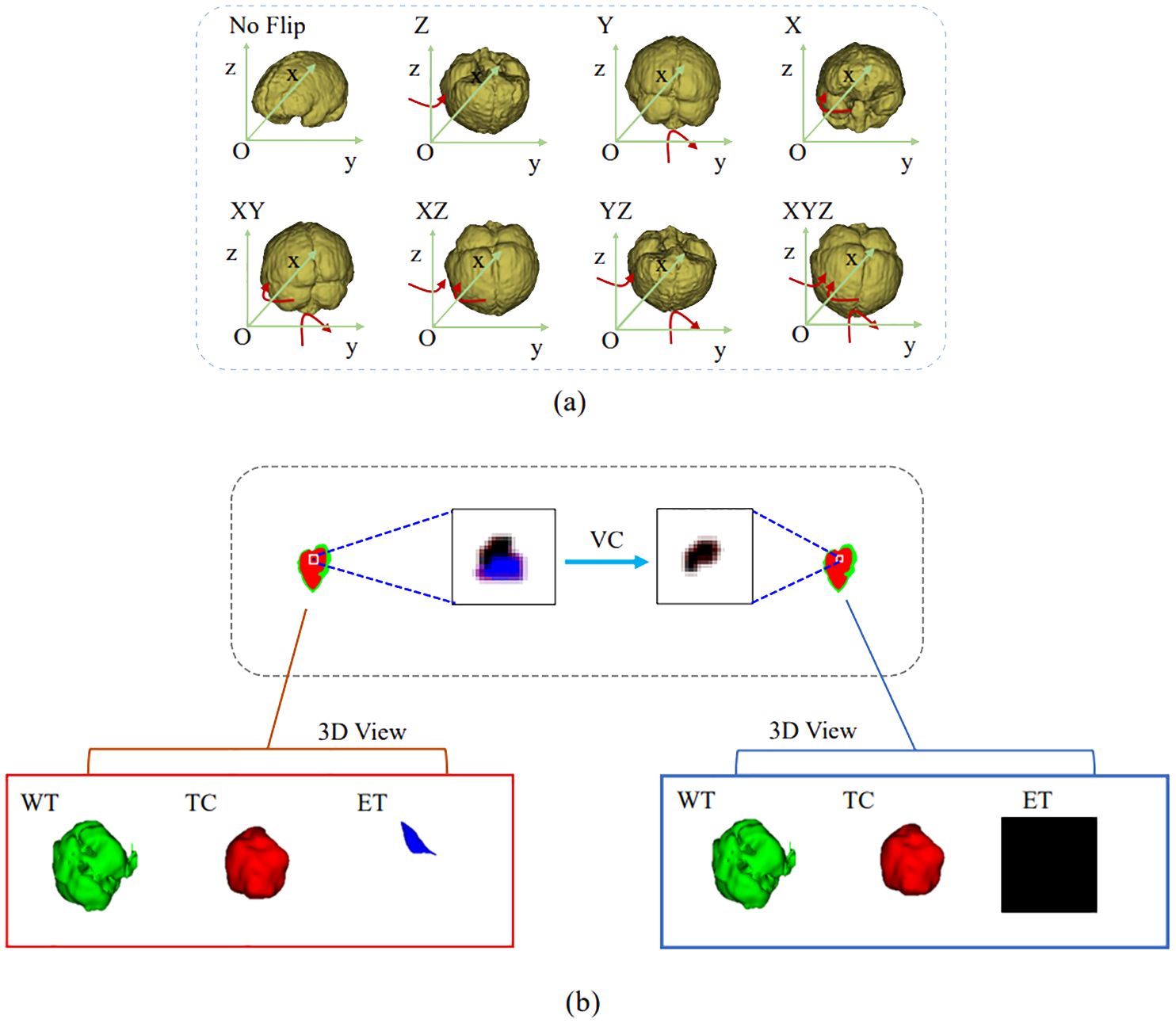
Figure 5. Results obtained by the postprocessing: (A) TTA; (B) VC. TTA was performed using 7 different flips: (x), (y), (z), (x, y), (x, z), (y, z), (x, y, z). VC replaces the ET predicted by the model if its volume is below the 500-voxel threshold.
For VC, if the reference segmentation for the ET is missing, the BraTS evaluation assigns a reward of 0 for false positive predictions, and the Dice score is 1. Therefore, in this study, if the ET volume predicted by the model was less than the threshold of 500, the ET region was reclassified as necrotic and non-enhanced tumor tissue. As shown in Figure 5B, the ET region is replaced with necrotic and non-enhanced tumors after volume restriction.
4 Experimental setting4.1 DatasetThree public benchmark datasets and one private dataset were used to evaluate the effectiveness of the proposed DeepGlioSeg. The Brain Tumor Segmentation Challenge provided the BraTS2019, BraTS2020, and BraTS2021 datasets used in this study (6, 34, 35). The BraTS2019 dataset consists of 335 training cases and 125 validation cases. The BraTS2020 dataset contains 369 training examples and 125 validation examples. The BraTS2021 dataset includes 1251 training samples and 219 validation samples.
The ZZH dataset was collected by the first affiliated hospital of Zhengzhou University with institutional review board approval (reference number: 2019-KY-231). It consists of 232 patient records in the same format as the BraTS datasets. Each sample was manually labeled by two radiologists at the first affiliated hospital of Zhengzhou University. The dataset was split into training, validation, and test sets in a 7:1:2 ratio. The training set was used to train the model, the validation set was used to guide hyperparameter tuning and early stopping, and the test set was used to evaluate generalization. This approach prevents data leakage and ensures an unbiased performance evaluation.
4.2 Evaluation metricsThe Dice similarity coefficient (Dice), Sensitivity (Sen), and Hausdorff distance (Haus95) are used to assess the segmentation performance of the model. Considering the glioma’s anatomical features and structure, the model’s performance in segmenting the following three tumor sub-regions is evaluated: WT (necrotic and non-enhanced tumor, peritumoral edema, and enhanced tumor), TC (necrotic and non-enhanced tumor, enhanced tumor), and ET (enhanced tumor).
4.3 Experimental detailsThe optimization method used is Adam with a learning rate of 0.0002, and training is performed with a batch size of 4. DeepGlioSeg is trained for approximately 1000 iterations. A minimum loss value threshold is set, and the average loss value of each epoch is calculated during training. Training is stopped when the loss value drops below the set threshold. The size of the image input to the model is 128×128×128×4.
After each downsampling layer, the size of the feature map is halved, and the number of channels is doubled. The number of initial convolution kernels is 16. The loss weights for the four regions—ET, WT, TC, and background—are set to [2, 1, 2, 0.1]. The following data augmentation techniques are applied: (1) random cropping of the data from 240×240×155 to 128×128×128; (2) random mirroring and rotation in the axial, coronal, and sagittal planes with a probability of 0.5; and (3) random intensity shifts in the range [-0.1, 0.1] and scaling factors in the range [0.8, 1.2]. The network is trained using Multi-GDL, and L2 normalization is applied to regularize the model, with the weight decay rate set to 1e-5.
5 Results5.1 Ablation study5.1.1 CTPC module configurationWe conducted experiments to identify the optimal configuration of the CTPC module for better segmentation performance. Table 1 summarizes the impact of different CTPC configurations on model performance. The baseline model employs a standard encoder-decoder architecture with separate CNN and Transformer branches, which independently extract local and global features. Although effective individually, the lack of integration between these branches limits the model’s ability to combine local and global information, reducing segmentation accuracy.
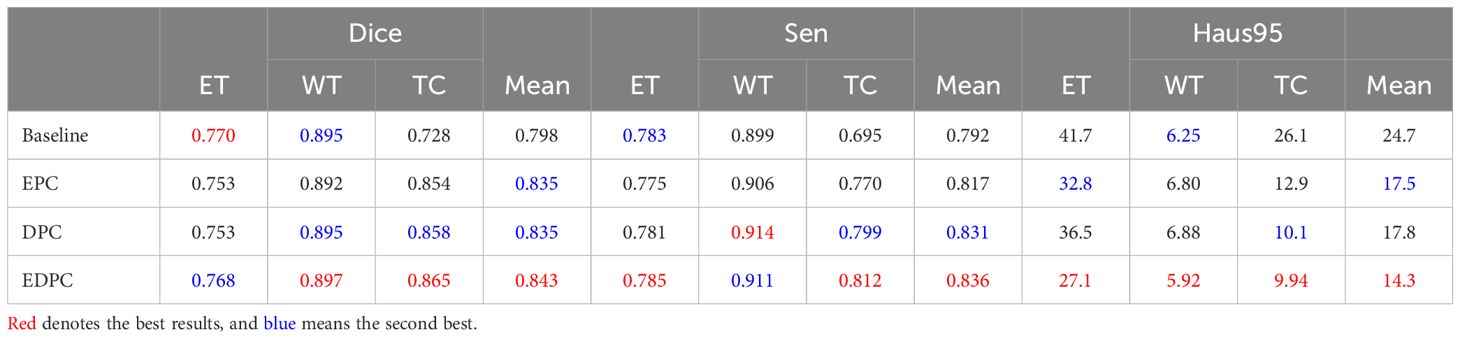
Table 1. Qualitative comparison of results on the BraTS2020 dataset, including the model architecture without the CTPC module (Baseline), encoding path configuration (EPC), decoding path configuration (DPC), and encoding-decoding path configuration (EDPC).
DeepGlioSeg addresses this by incorporating the CTPC module, which enables the simultaneous fusion of local and global features. Unlike the baseline, where features are processed separately, the CTPC module integrates the outputs from both branches, fusing local and global features into a unified representation. This enhanced feature fusion improves segmentation accuracy, particularly for complex and heterogeneous tumor regions. The fully embedded CTPC model achieved a 4.5% improvement in Dice score (84.3% vs. 79.8%) over the baseline, demonstrating the effectiveness of this integration.
The CTPC module addresses challenges in feature alignment and compatibility between CNN and Transformer outputs. By using 1×1×1 convolutions for channel alignment, it ensures CNN features match the Transformer input dimensions, preserving local detail while facilitating global feature integration. Downsampling reduces the volume dimensions to 16×16×16, balancing computational efficiency with feature richness for global context. The final reshaping generates patch embeddings that facilitate effective local-global interaction, making the CTPC module highly effective for capturing complex patterns, crucial for tumor segmentation tasks.
5.1.2 Learnable position embeddingIn the work of Dosovitskiy (36), a learnable embedding was incorporated into the embedded patch sequence and complemented with position embeddings to preserve critical positional information. Similarly, for glioma segmentation, we introduced a learnable position embedding to encode crucial positional information for the task. Within the CTPC module, the CNN and Transformer branches enable the fusion of feature streams through a shared pathway. Before passing the CNN feature stream into the Transformer branch, we used standard one-dimensional learnable position embeddings to encode position information. The embeddings were then added to the feature map via summation. As shown in Table 2, the introduction of learnable position embeddings improved the average Dice score by 1% (84.3% vs. 83.3%).

Table 2. Ablation study of the CTPC architecture on the BraTS2020 dataset, testing the impact of different components. .
5.1.3 Strided convolutionAs shown in Figure 3, downsampling the feature map from the CNN branch is necessary to achieve spatial dimension alignment. Peng et al. (37) used average pooling in the feature coupling unit for this purpose. However, pooling can filter out valuable information during downsampling. To mitigate this, we chose strided convolution as the downsampling module. Strided convolution enables multiple downsampling steps while facilitating further feature extraction by adjusting the step size. The network uses four resolution levels (128, 64, 32, 16) from top to bottom, with downsampling modules having step sizes of 8, 4, 2, and 1, respectively. To ensure computational consistency, we maintained the patch embedding size in the Transformer branch at 4096. As shown in Table 2, using strided convolution as the downsampling module within the FFP improved the average Dice score by 0.7% (84.3% vs. 83.6%).
5.1.4 PostprocessingDuring inference, we used a dual post-processing approach involving TTA and VC. We evaluated the impact of these strategies on segmentation performance through comparative experiments, summarized in Table 3. The combined use of both strategies led to a 3.5% improvement in the average Dice score (84.3% vs. 80.8%). Importantly, these strategies improved performance without introducing additional computational complexity. We calculated a p-value for this metric, which was less than 0.05, supporting this improvement.

Table 3. Effect of post-processing on segmentation performance on the BraTS2020 dataset, evaluating strategies such as no post-processing (None), only TTA, and a combination of TTA and VC.
We systematically tested voxel count (VC) thresholds ranging from 100 to 1000 voxels to optimize the Dice score across tumor subregions, focusing on improving segmentation quality. As shown in Figure 6, a 500-voxel threshold achieved the best balance between false positives and true positives. At lower thresholds (e.g.,<500 voxels), over-segmentation occurred, leading to excessive false positives, particularly in the ET region, where small noise regions were incorrectly classified as tumor. Conversely, higher thresholds (>500 voxels) risked under-segmentation, excluding small but clinically significant tumor regions, reducing sensitivity and potentially missing subtle pathological features. The 500-voxel threshold effectively mitigated these issues, ensuring more robust and accurate segmentation across all tumor subregions.
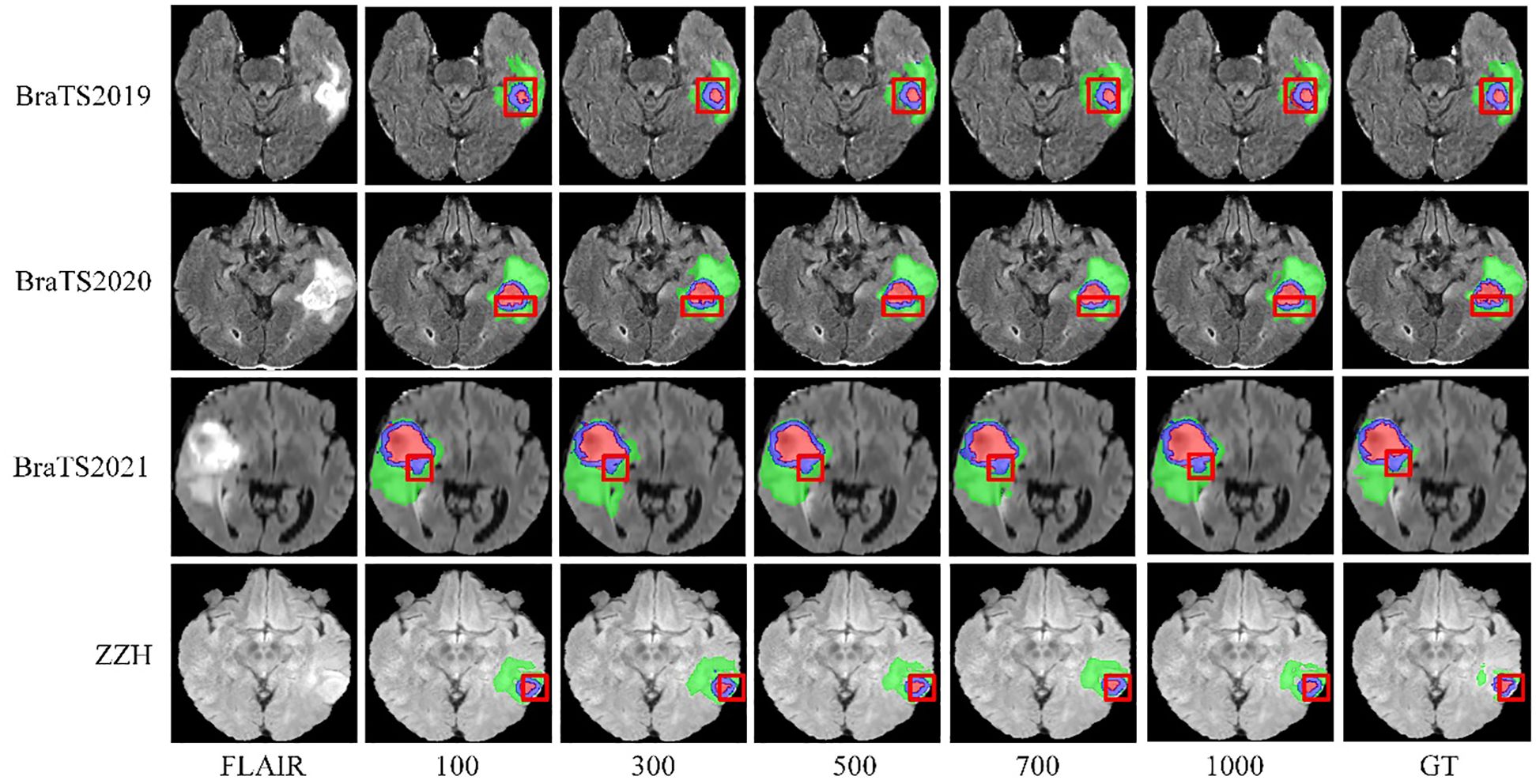
Figure 6. Visualization of results from different threshold selections in the VC post-processing technique on both the BraTS and ZZH datasets.
To further justify this choice, we conducted a sensitivity analysis to evaluate the impact of different VC thresholds on segmentation performance. The results, summarized in Table 4, indicate that a threshold of 500 voxels consistently yielded the highest average Dice score while maintaining a favorable balance between precision and sensitivity across the four datasets. For the BraTS2019 dataset, the average Dice score reaches a maximum of 0.834 at a 500-voxel threshold, compared to 0.816 and 0.811 at thresholds of 100 and 1000, respectively. Sensitivity and precision also achieve their highest values of 0.838 and 0.842 at the 500-voxel threshold. In the BraTS2020 dataset, the average Dice score reaches a maximum of 0.843 when the threshold is 500, with sensitivity and precision also reaching their maximum values of 0.836 and 0.855, respectively. For the BraTS2021 dataset, when the threshold is 500, all evaluation metrics show excellent performance, with the average Dice score at 0.865, sensitivity at 0.855, and precision at 0.846. For the ZZH dataset, although all metrics are relatively low across all thresholds, at the 500-voxel threshold, the Dice coefficient, sensitivity, and precision are 0.616, 0.639, and 0.653, respectively, showing a relative advantage compared to the performance under other thresholds. Overall, setting the threshold at 500 for volume constraints generally yields better segmentation results.
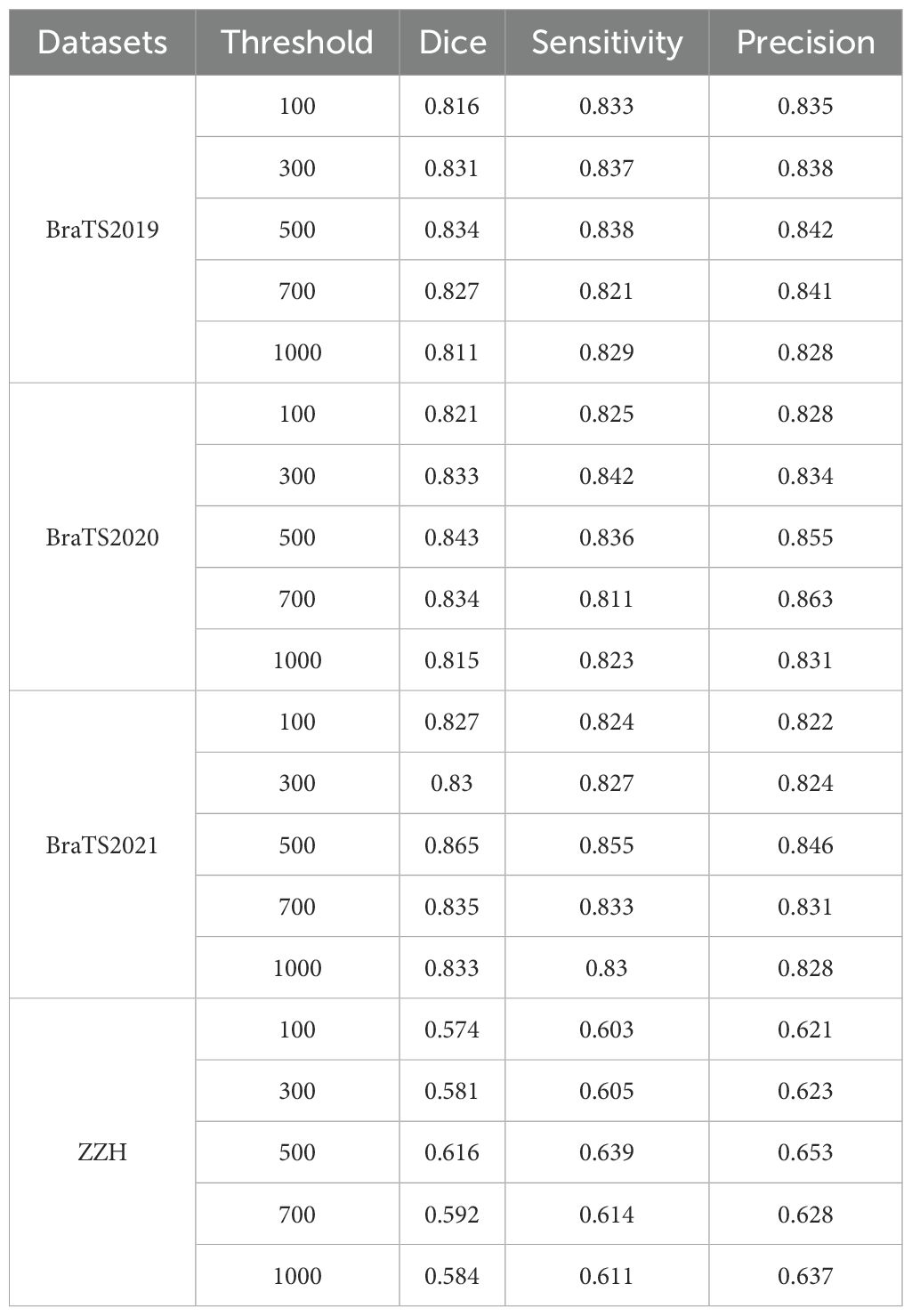
Table 4. Comparison of segmentation performance with different thresholds across all the datasets.
5.1.5 Loss functionBrain tumor segmentation faces significant category imbalances, both between tumor and non-tumor tissue and among different tumor subregions. To address this, we assigned class weights based on category frequencies. Incorporating class weights into the GDL function increased the average Dice score by 5.2% (84.3% vs. 79.1%), as shown in Table 5, demonstrating its effectiveness in handling class imbalance.

Table 5. Comparison of segmentation performance with different loss functions on the BraTS2020 dataset.
Glioma MRI datasets inherently exhibit imbalances among tumor regions, with the TC and ET being significantly smaller compared to the WT. To address this imbalance and emphasize clinically critical regions, we assigned higher weights to the ET and TC during training. Specifically, the model was configured with weights of 0.1 for the background, 1 for the WT, and 2 for the ET and TC, as shown in Table 6. This weighting strategy improved the Dice scores for the smaller regions by encouraging the model to prioritize them over the disproportionately large background and WT regions. We observed that increasing the weights for the ET and TC significantly enhanced their segmentation accuracy, ensuring better representation of these clinically significant areas. Simultaneously, reducing the background weight to 0.1 prevented the model from overfitting to irrelevant regions, which often dominate the data due to their larger size. Conversely, assigning higher weights to the background degraded the segmentation performance on the smaller regions, as the model became biased toward identifying the dominant background area. The selected weight configuration effectively strikes a balance by focusing on critical tumor subregions while minimizing distractions from the background, resulting in segmentation that is both accurate and clinically relevant.
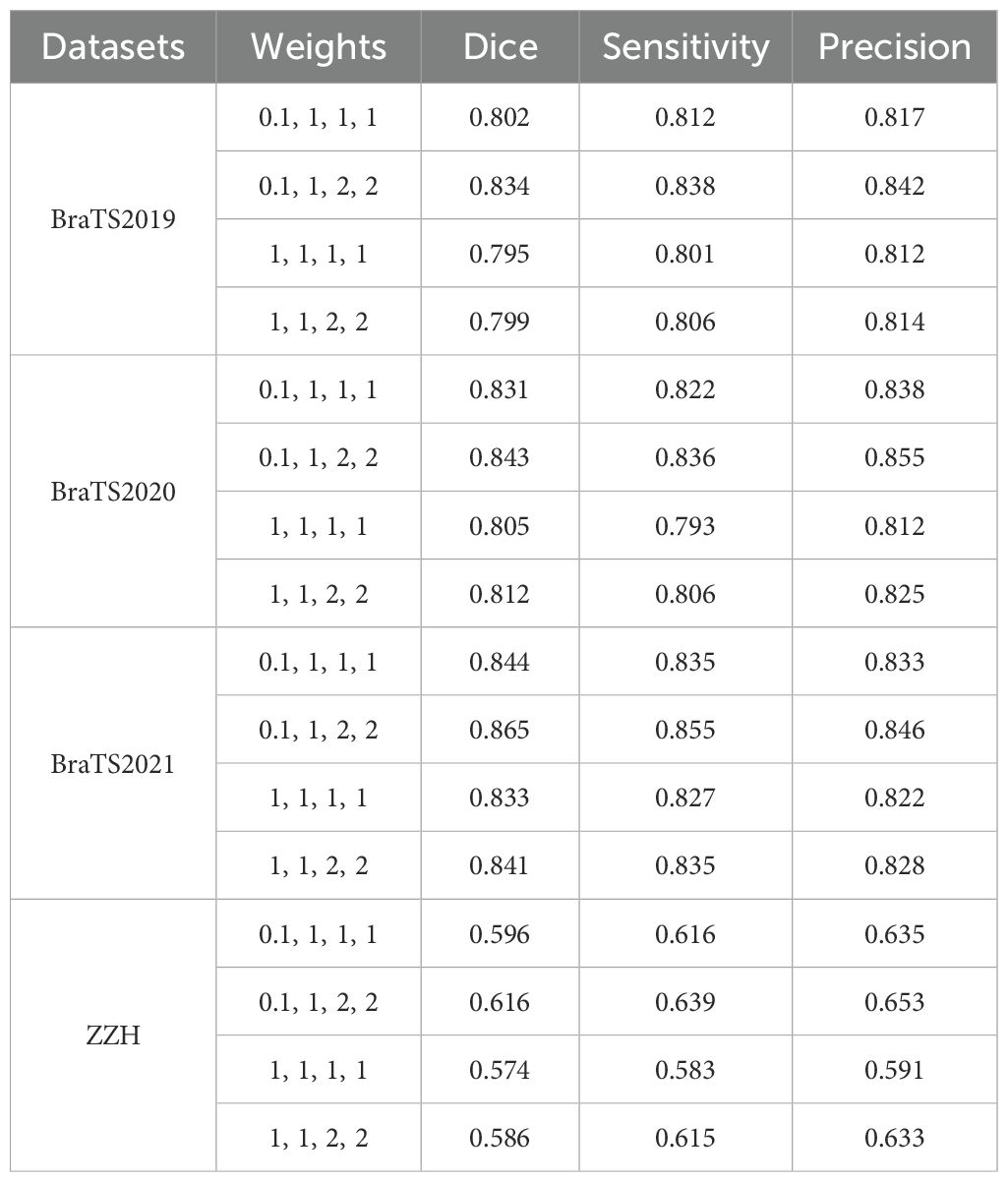
Table 6. Comparison of segmentation performance with different weights using the GDL on all the datasets used.
5.1.6 CNN branch and transformer branchThe CTPC module consists of two primary components: the CNN and Transformer branches. To better understand their contributions, we conducted ablation studies, with results summarized in Table 7. Removing the CNN branches caused a significant drop in segmentation performance, highlighting their critical role in the CTPC framework.
留言 (0)