
記住我
Cancer cells are masters of adaptation, often using irreversible genomic changes to survive treatment (Labrie et al., 2022). While traditional drug discovery focuses on blocking temporary, protein-level responses, it overlooks the fast-acting genomic responses on extrachromosomal DNA (ecDNA, Figure 1A), which are harder to detect and even harder to target. This blind spot leaves 15% of cancer patients without effective therapies (Kim et al., 2020). EcDNA is a distinct form of genetic alteration that amplifies oncogenes outside the constraints of chromosomal DNA, providing cancer cells with unique evolutionary advantages. Unlike chromosomal mutations, deletions, or stable amplifications integrated within homogeneous staining regions (HSRs), ecDNA is a dynamic structure capable of rapid replication and uneven segregation during cell division. In tumors, ecDNA is believed to drive tumor heterogeneity by creating cell-to-cell genetic and molecular differences that influence drug responses. This variability allows certain cells to adapt and persist during therapy, contributing to the development of drug resistance.
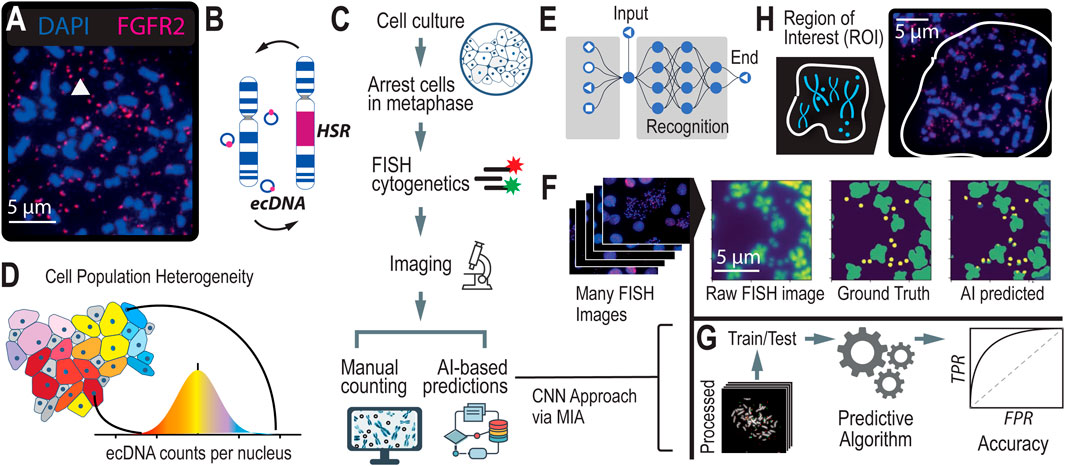
Figure 1. Scaling Annotations of ecDNA in Metaphase FISH images using AI (A). Microscopy methods, such as scanning electron microscopy (SEM) and DNA Fluorescence in situ Hybridization (FISH) are gold standard approaches for visualizing ecDNA. DNA FISH uses fluorescent probes that bind to specific DNA sequences that indicate which regions of the genome are amplified by ecDNA. Multiple species can be observed depending on which fluorescent probe is detected. (B) Under stress, ecDNAs can re-enter chromosomes to form homogeneous staining regions (HSRs). (C) FISH is the gold standard method for detecting and analyzing ecDNA in cell nuclei. It consists of several steps which include cell cycle synchronization, fixation, and hybridization. With advances in AI, time-intensive manual labeling and counting of ecDNA is accelerated and can be scaled up. (D) Asymmetric division of ecDNA molecules into daughter cells during replication and division leads to a heterogeneous population of cells with various ecDNA counts and species. (E) Convolutional Neural Networks is a computer vision approach that is well suited to image segmentation. (F) A computer vision approach applied to detecting and counting ecDNAs in metaphase FISH images. (G) Using ground truth (i.e., manually labeled metaphase FISH images), we can assess the accuracy of the computer vision method at detecting and counting ecDNAs per cell nucleus. (H) Region of Interest (ROI), defined as the human-annotated boundary representing the nuclear spread of a single cell. This is the area within the image where ecDNA is predicted and counted.
Next-generation sequencing has revolutionized cancer biology, enabling unprecedented insights into the genetic landscape of cancer. Large-scale consortia such as The Cancer Genome Atlas (TCGA), the Dependency Map (DepMap) (Barretina et al., 2012; Tsherniak et al., 2017), and the Cancer Cell Line Encyclopedia (CCLE) have generated extensive multi-omics datasets, characterizing thousands of cancer genomes and tumor samples. Among these datasets, whole-genome sequencing (WGS), whole-exome sequencing (WES), and ATAC-seq are the most comprehensively covered across samples. Leveraging this data, computational algorithms (Yang et al., 2023; Deshpande et al., 2019) have been developed to detect unique structural variants, including ecDNA and double minute chromosomes (DMs), which frequently appear in cancer cell nuclei. These advancements have fundamentally shifted our understanding of cancer genome structure and karyotype, opening new avenues for research and potential therapeutic interventions.
However, despite their transformative potential, sequencing-based approaches have significant limitations in practice. While they are effective at identifying amplified genes and reconstructing the circular structures of the most dominant ecDNA species, their prediction accuracies typically range between 60%–70% (Fessler et al., 2024). This level of accuracy is often insufficient for precise detection and characterization, particularly when detecting ecDNA in cells with fewer copy number counts. Additionally, a major limitation of sequence-based prediction algorithms is that they are not able to distinguish between ecDNA and other amplification types, such as HSRs, which are chromosomal regions that can also exhibit gene amplification with “copy-paste-amplify” patterns (Figure 1B).
In this way, sequencing alone cannot differentiate between freely mobile ecDNA, which can independently replicate and segregate during cell division, and HSRs, which are stable and integrated into chromosomes. However, it is important to note that ecDNA and HSRs are not mutually exclusive entities and can interconvert under certain conditions. This dynamic interconversion further complicates the interpretation of sequencing-based methods, which may miss critical aspects of cancer biology, including the role of ecDNA in driving tumor heterogeneity and drug resistance. Therefore, to accurately detect and characterize ecDNA within cancer cell nuclei, it is essential to integrate additional approaches, such as high-resolution nuclear imaging or functional assays, alongside sequencing data. These complementary methods provide the necessary context and precision, enabling a more comprehensive understanding of ecDNA’s role in cancer, including its potential to transition between ecDNA and HSR forms.
Currently, the only methods capable of accurately detecting and quantifying ecDNA, as well as determining its precise location within cell nuclei, are gold-standard cytogenetic imaging techniques. Techniques like Fluorescence in situ Hybridization (FISH) and G-banding karyotyping use fluorescence-based methods to visualize ecDNA within the nucleus (Figure 1C). In FISH, cells are typically arrested in metaphase when chromosomes are condensed and spread out, allowing for better visualization of ecDNA. The cell nuclei are stained with fluorescent dyes, such as DAPI, to enhance visibility. When the genetic sequence of ecDNA is known, fluorescent probes can be designed to hybridize with specific regions on the ecDNA, providing unambiguous localization within the nucleus. A standard practice in the field involves generating 20–100 images of individual cell nuclei to capture the heterogeneity in ploidy and ecDNA counts across a cell population (Figure 1D). However, the subsequent manual annotation and analysis of these images are time-intensive and low-throughput, limiting the scalability of these image-based approaches. This laborious process underscores the need for more efficient methods that can achieve the same level of accuracy without the associated bottlenecks.
Leveraging AI to automate the detection of ecDNA and HSRs in metaphase FISH images represents a transformative shift from traditional, labor-intensive karyotyping methods. By training computer vision models to identify ecDNA in metaphase FISH images (Figure 1E), we can overcome the historical challenges of scalability, enhancing both accuracy and precision in detection. This approach complements sequence-based prediction methods by providing a robust alternative that directly visualizes ecDNA. Several efforts (Turner et al., 2017; Rajkumar et al., 2019) have been made to automate image-based detection of ecDNA using various approaches, such as thresholding and Convolutional Neural Networks (CNNs, Figure 1E). These models employ supervised learning, where they are trained on manually labeled imaging data (i.e., “ground truth” data), with each ecDNA precisely identified and annotated by experts. These annotations supply the model with the exact coordinates of ecDNA in each image, enabling the algorithm to learn the features necessary to predict the presence of ecDNA in non-annotated images (Figure 1F). Accuracy of the model is determined by comparing the predicted counts or locations of ecDNA within metaphase FISH images to the ground truth data (Figure 1G).
Autodetection of ecDNA in metaphase FISH images remains a significant challenge due to several factors. Metaphase FISH images are often noisy, with considerable cell-to-cell variation that complicates traditional image processing techniques. Key issues that reduce prediction accuracy include high noise ratios in pixel intensities, variations in the size and morphology of chromosomes versus ecDNA, and a severe class imbalance where the majority of the image is background or chromosomes. Existing algorithms (Turner et al., 2017; Rajkumar et al., 2019) struggle to generalize across different image types, particularly when transitioning from low-resolution, black-and-white, tiled images to high-resolution images. These models, trained on lower-quality images, are heavily dependent on the specific microscope and image processing conditions, making them non-transferable. As a result, they detect only 30%–40% of the ecDNA in our images and suffer from a high false negative rate, especially when ecDNA is close to chromosomes. Moreover, these models are outdated and not publicly available for retraining. There is a critical need for updated, publicly available CNN-based models that can be retrained with higher-resolution images to enhance the accurate detection of ecDNA in metaphase FISH images.
Recently, the Microscopy Image Analyzer (MIA) was developed as an end-to-end interface designed to help researchers scale image analysis across large datasets. MIA is unique in its ability to integrate image processing, analysis, and interpretation within a single platform, providing a streamlined approach that significantly reduces the time and effort required for manual annotation. We applied MIA to our specific challenge of auto-detecting ecDNA in metaphase FISH images, leveraging its capabilities to create a high-throughput post-processing pipeline (Figure 1F). This pipeline dramatically increased the accuracy of ecDNA detection by refining image segmentation, reducing noise, and improving feature recognition. Currently, the field lacks standardized methods for processing and analyzing metaphase FISH images, making our contribution particularly valuable for researchers interested in automating ecDNA detection. Additionally, we have applied this approach to pharmacological studies to monitor changes in ecDNA during drug treatment. These experiments require the analysis of numerous images across many conditions, making the ability to scale and autodetect essential for reducing the time and labor involved in such studies.
Results and discussionImage processing pipeline for MIAThe quality of images and annotations plays a crucial role in the success of computer vision models, particularly in tasks such as detecting ecDNA in non-annotated images. High-quality images with precise annotations are essential for the computer to accurately learn and identify the critical features necessary for reliable ecDNA detection. Poor image quality or inaccurate annotations can lead to misrepresentations of features, ultimately undermining the model’s performance and predictive accuracy. In this section, we discuss the comprehensive steps we took to post-process our image database, focusing on rigorous image ranking and quality control (QC) measures. By ensuring that only the highest quality images were used for training and validation, we aimed to optimize the performance of our MIA-based model for ecDNA detection.
Pre-processing of metaphase FISH imagesAccessing image qualityImage quality can vary due to several technical and biological factors, including the type of cell line used, cell-to-cell variations, post-imaging processing, sample handling, probe potency, and the characteristics of the microscope. A raw image must undergo post-imaging processing to qualify for counting. It is common for any human to over- or under-process an image and incorrectly annotate ecDNAs or HSRs, which generates false negatives and/or positives. Additionally, the biology of the nuclei itself introduces variability. For instance, each image may contain one or more cell nuclei that have burst open, exposing chromosomes and ecDNA. However, the way these nuclei burst on the microscope slide is non-uniform and can occur on slightly different planes, resulting in some nuclei being more in focus than others. Cell-to-cell karyotypic differences after bursting, such as the number and clustering of chromosomes, also greatly fluctuate visibility of ecDNA. This variability makes counting ecDNA within a single nucleus subjective and can lead to inconsistencies in manual annotation. Moreover, the use of DNA probes involves heating samples to accelerate probe hybridization, which can degrade the samples and make them more difficult to image accurately.
It is important to create a database of images from which an AI algorithm can train on that are consistent and generalizable. Any overlapping nuclei, debris clouds, or low resolution images decrease the confidence of attribution and negatively impacts the ability of the algorithm to learn correct features for future predictions. While we found that it can be rare to find extremely well resolved and separated bursted nuclei that generate data with high confidence, we tagged and excluded images with lower confidence from training using a systematic grade-based approach.
We ranked images on a scale from 0 to 4 based on several key quality parameters:
1. Resolution and Focus: This parameter assesses the sharpness and clarity of the chromosomes in the image. Images where chromosomes are blurry and indistinguishable, such that the chromosome arms cannot be clearly seen, receive a lower score (0–1). Conversely, images with sharp, well-defined chromosomes receive a higher score (3–4).
2. Uniformity: Uniformity refers to the evenness and consistency of the image. This is evaluated by observing the spatial distribution of the bursted nuclei. If the nuclei are unevenly spread, with overlapping or indistinct regions, the image is marked lower. If the nuclei are evenly distributed with clear boundaries and minimal overlap, the image receives a higher score.
3. Spatial Distinction: This parameter assesses how well the bursted nuclei and chromosomes are separated from surrounding artifacts or debris. If a nucleus is too clustered or overlaps with its surroundings, making it difficult to distinguish individual chromosomes, the image is ranked lower (0–1). Images with well-separated, distinct nuclei that have a clear “splash zone” with no overlap are ranked higher (3–4).
4. Debris and Artifacts: The amount of debris or artifacts in the image is also considered. Images with minimal debris and clean backgrounds are ranked higher, while those with significant debris (Supplementary Figure 1) or distracting artifacts are ranked lower.
Images marked as “0” represent the lowest quality, characterized by poor resolution, lack of uniformity, and high debris, while images marked as “4” are of the highest quality, with clear, well-focused chromosomes, uniform distribution, and minimal artifacts. This ranking system ensures that only the best quality images are used for further analysis and model training.
Assessing annotation qualityAnnotation quality in metaphase FISH images for counting ecDNA is a complex and time-consuming task, often leading to inconsistencies due to its subjective nature. Different researchers may label ecDNA differently, resulting in variations in the data. Typically, metaphase FISH images use DAPI dye to localize ecDNA, which stains all nucleotides but does not differentiate between chromosomal DNA and ecDNA. While using DNA probes that hybridize to specific regions of ecDNA could reduce ambiguity, the exact sequences of ecDNA are not always known. Additionally, these probes are expensive, and there can be heterogeneity in ecDNA sequences within a single sample, leading to incomplete labeling if some ecDNA contain the targeted genes and others do not.
Given these challenges, it is more practical to develop algorithms that predict the location of ecDNA in metaphase FISH images using DAPI dye alone. However, different researchers may employ various methods to annotate ecDNA using DAPI, such as adjusting contrast to differentiate between DNA and debris or comparing the general shape and size of potential ecDNA across images. These subjective approaches can lead to significant variation in manual annotations, as there are no clear, standardized criteria for what constitutes an ecDNA. Furthermore, the fact that ecDNA can change shape and size from cell to cell complicates the establishment of consistent annotation rules, making it difficult to generalize across samples.
The annotation of the 3,000 images used in this study was carried out by multiple students over several years. Consequently, the annotation styles, approaches, and quality varied, creating a challenging dataset for machine learning. To address this, our post-processing image ranking system was essential in selecting the most consistent and representative images for training the algorithm. While the model is designed to learn the patterns of ecDNA from the majority of correct annotations, discrepancies in the data—such as errors in labeling of ecDNA that is not visible in the DAPI channel due to its proximity to or overlap with chromosomes—can negatively impact the model’s measured accuracy, making it appear less effective than it actually is.
The images used to train this model were first ranked on a scale from 0 to 4, with 0 indicating images that are highly subjective and difficult to count due to unclear focus, and 4 indicating images that are clearly well-counted and in focus. After an initial ranking, the annotations were reviewed more closely, especially in cases where multiple fluorescent images were merged. Particular attention was given to the DAPI channel, as this is crucial for accurate ecDNA detection. If many annotation markers were found to be skewed, missing, or incorrect, the image received a lower rank. Additionally, notes were taken on potential improvements to enhance image quality for future use.
From the 2,312 images that were reviewed and ranked from previous experiments, about 1,242 images were ranked a 3 or 4 and were chosen to be used for highest quality training data. The table below displays descriptions for each rank and examples in their FISH probe merged with DAPI and grayscale DAPI only with annotations. Images that had little annotation issue were flagged to be perfected and upgraded in ranking.
Generating regions of interestIn the context of counting ecDNAs within cell nuclei, generating regions of interest (ROIs, Figure 1H) in metaphase FISH images is a critical initial step. Metaphase FISH images typically contain multiple nuclei, some of which may be intact while others are bursted, revealing the underlying chromosomes and ecDNAs. These images can be complex, with overlapping structures and varying degrees of focus, making it challenging to accurately count ecDNAs without precise guidance. By defining ROIs, researchers can direct the algorithm to focus specifically on the areas of interest—namely, the individual nuclei or their remnants—thereby filtering out irrelevant parts of the image. This targeted approach significantly enhances the accuracy of ecDNA counts, ensuring that the algorithm is analyzing only the relevant nuclear material and not extraneous background or overlapping cells. By clearly delineating ROIs, the post-processing steps are streamlined, leading to more reliable and reproducible results in the study of ecDNA within cancer cells.
With the selected set of high quality images, it was essential to address the presence of debris (Supplementary Figure 1), as well as chromosomes and ecDNA that had drifted from other nuclei, particularly at the edges of the images. These extraneous elements were not originally annotated and needed to be removed to focus on the relevant data. To achieve this, a lasso tool was employed to draw a region of interest (ROI) that encapsulated all annotated ecDNA while minimizing the inclusion of non-annotated material. The resulting ROIs were saved as binary masks. During this process, image contrast was significantly enhanced to differentiate and either include or exclude faintly visible features. For nuclei that were close together but clearly separated, each was carefully reviewed, with distinct cells isolated into their own ROIs when possible or otherwise removed from the dataset. This approach resulted in a variety of ROI shapes, ranging from tight circles to elongated ovals and irregular polygons, effectively tracing around unburst nuclei and isolated debris clouds. Debris and debris clouds were differentiated from ecDNA based on their size and their distance to the centroid of the bursted nuclei. For example, the size of ecDNA from NCI-H2170 cells was estimated to be approximately 0.25 µm (Supplementary Figure 2) from a prior study (Madren et al., 2024), using Scanning Electron Microscopy (SEM) and Correlative Light Electron Microscopy (CLEM) (Madren et al., 2024).
As previously mentioned, subjectivity can arise when interpreting the boundaries of a cell’s bursted nuclei radius and distinguishing between circularized debris and ecDNA, leading to inconsistencies in annotations between different individuals. Defining ROIs not only provides the algorithm with a focused area for counting and segmentation but also reduces the influence of these subjective interpretations. By constraining the analysis to clearly defined areas, we minimize the need for multiple revisions of the boundary during post-prediction review. Additionally, this approach facilitates a more consistent and reliable evaluation of ground truth image annotations, ensuring that they can be accurately reviewed and audited within a well-defined context.
Expanding image annotationsOur images were annotated by placing a dot on a single pixel to mark the location of ecDNA. However, this dot may not always align perfectly with the pixel of highest intensity for that ecDNA, which can impact the quality of annotations and subsequently affect the performance of machine learning algorithms. Recognizing the importance of precise annotations in training an algorithm, we developed a method to improve these annotations. We created a mask around each annotated pixel, shaped like a diamond, to include nearby pixels surrounding the ecDNA mark. This approach provided a more comprehensive representation of the ecDNA, allowing the algorithm to better identify and classify ecDNA by capturing a broader context of the signal. This enhancement was crucial in improving the accuracy and robustness of our machine learning model.
Evaluation datasets: human error, ceiling performance, and full model benchmarkingHuman errorTo better understand the amount of human error involved in annotating metaphase FISH images, we conducted an experiment where we selected a subset of metaphase FISH images. Three different individuals were asked to annotate this subset independently, and one individual annotated the same subset in three separate replicates. Our findings revealed that across the three individuals, there was a 8% ± 1% error in the annotations, indicating the presence of human error. This analysis suggests that any algorithm trained on such data is inherently limited by this level of technical error, implying that the maximum achievable accuracy for the algorithm is constrained by the variability in human annotations. This establishes a benchmark for understanding the limitations of our model’s performance and provides a realistic expectation for its accuracy (Figure 2A).
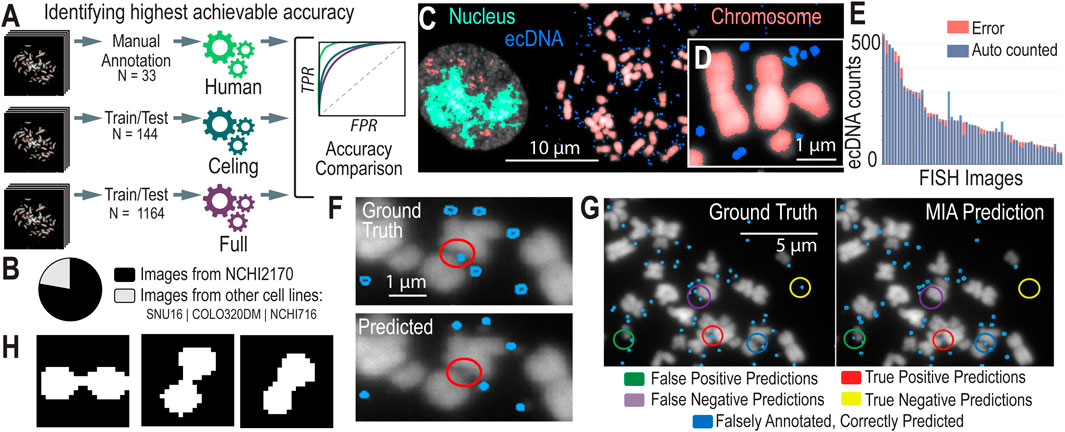
Figure 2. AI Models and Assessment of their Accuracies (A). We created different models to test the highest possible accuracy that we could expect our model to reach. (B) The breakdown of images used to train the Convolutional Neural Networks (CNNs) by cell line model system. (C) CNN-predicted chromosomes, ecDNA, and in-tact nuclei from a metaphase FISH image. (D) A zoomed-in image of ecDNA near chromosomes, highlighting the challenges in detecting individual ecDNAs when they cluster close together. (E) Accuracy metrics for the full (n = 1,164) model, showing the distribution of error (the difference in ecDNAs predicted versus manually counted) across images. (F) Existing algorithms struggle to predict ecDNAs in close proximity to chromosomes. (G) Annotated results from MIA, showing instances of true positives/negatives and false positives/negatives as well as cases where MIA finds ecDNA that were not correctly annotated. (H) Contour detection of conjoined segmentations. The figure illustrates examples of closely clustered ecDNA entities that are identified as a single object by the algorithm. Contour detection enables the separation of these conjoined objects into distinct segments, improving the accuracy of ecDNA boundary identification and differentiation.
Ceiling performanceTo determine the highest achievable accuracy of MIA, we focused on a subset of hand-picked, top-quality metaphase FISH images that were most amenable to automated AI learning. We selected 144 metaphase FISH images that ranked highest according to our stringent image quality criteria, ensuring they were clear, well-focused, and exhibited minimal noise or overlap. By training MIA on this cherry-picked dataset, we aimed to create a “ceiling model” that represents the maximum potential accuracy of ecDNA detection under ideal conditions. While we anticipate that this model will demonstrate superior performance, we also recognize that it may not be generalizable to more diverse or lower-quality images. Nonetheless, this approach provides valuable insight into the upper limits of algorithmic accuracy, establishing a benchmark for what can be achieved in optimal scenarios.
Full modelTo develop a robust and generalizable model, we created a full model dataset by selecting images with a ranking of 3 or higher, ensuring a higher standard of image quality for training. This dataset comprises 1,164 images, with 78% derived from our primary model system, NCI-H2170 cells, while the remaining 22% come from a diverse set of cell line model systems that harbor ecDNA, including NCIH716, SNU16, and COLO320 (Figure 2B). By incorporating a variety of cell lines, this dataset aims to strike a balance between achieving high accuracy and maintaining broad applicability across different cellular contexts. The full model represents our comprehensive effort to train an algorithm capable of accurately detecting ecDNA across a range of image qualities and biological conditions.
SegmentationSegmentation in computer vision is the process of dividing an image into distinct segments or regions, where each segment corresponds to different objects or parts within the image. The primary objective of segmentation is to simplify or transform the representation of an image into something more meaningful and easier to analyze, making it a critical step for tasks like ecDNA recognition.
Semantic segmentation is particularly effective for identifying and analyzing ecDNA within cell nuclei in FISH (Fluorescence in situ Hybridization) images, as demonstrated in previous approaches (Rajkumar et al., 2019). By classifying each pixel in an image into predefined categories—such as “ecDNA,” “chromosome,” “unbursted nuclei,” or “background”—semantic segmentation treats all objects of the same category as a single class (Figure 2C). While it does n’t distinguish between different instances of the same object, it excels in detecting and segmenting ecDNA within the complex cellular environment (Figure 2D). This approach overcomes challenges posed by overlapping structures and varying signal intensities in metaphase FISH images, enabling more accurate analysis of ecDNA.
Microscopy Image Analyzer (MIA) builds on these principles by incorporating various image processing techniques, including semantic segmentation, depending on the specific model or task. MIA is designed for flexibility and adaptability across different types of microscopy images, including those used for ecDNA detection in metaphase FISH images. While it can employ semantic segmentation similar to previous approaches, MIA primarily focuses on streamlining the analysis of large-scale image datasets through object detection, classification, and region-of-interest (ROI) selection (Figure 1H). By applying techniques like thresholding, edge detection, and ROI selection, MIA enables researchers to identify and quantify features of interest—such as ecDNA—in a high-throughput, efficient manner.
Accuracy and performanceWe began by testing the accuracy and performance of our ceiling model. Accuracy was assessed by comparing the total ecDNA count in each image within the validation set against the annotated ground truth. This metric guided the initial iterations of model improvement. The first training sets consisted of approximately 144 ultra-high-confidence, hand-picked images. When evaluated against a validation set of 45 selected images, the model exhibited an absolute difference in total counts of around 8% compared to the ground truth. While this level of accuracy was unexpectedly high, it likely represents the upper limit of achievable performance. In subsequent iterations, models were trained on a larger dataset comprising 1,164 images, which were refined by selecting ROIs and filtered to include only images with ranks of 3 and 4. After incorporating contour detection (discussed below) to address conjoined segmentations, the error rate for the resulting models, evaluated on a new set of 55 higher quality images (33 ranked 3+), was 7.62% (Figure 2E).
After achieving accuracy levels comparable to human annotations, we introduced an additional precision metric to further evaluate model performance. This metric involved comparing the predicted segmentation masks generated by the model to the ground truth masks (created using a pixel-patched approach to address class imbalance). Specifically, we assessed whether each unique object in the ground truth had at least one pixel overlap with a predicted mask, considering these overlapping objects as correctly identified. However, we refined the process to ensure that each object in the ground truth was exclusively matched to a single predicted object, preventing multiple predictions from being counted as overlaps with the same ground truth object. This approach helped us identify and balance false positives and negatives that might otherwise have been missed, thereby improving the overall quality of the training set.
Comparison to existing approachesPrevious approaches to automating ecDNA detection, such as ecDetect and ecSeg (Turner et al., 2017; Rajkumar et al., 2019), have made significant strides in addressing the challenges of accurately counting and localizing ecDNA within cell nuclei. ecDetect primarily relies on size thresholding to distinguish ecDNA from other nuclear components, applying a filter to isolate the region of interest (ROI) before analysis. However, this method can struggle with noise and closely clustered ecDNA, leading to potential inaccuracies in annotation and resolution (Figure 2F). ecSeg, on the other hand, utilizes a U-Net architecture with a ResNet50 backbone and focuses on segmenting images into patches for analysis. While effective, ecSeg was trained on a relatively small dataset of 483 annotated images, which may limit its generalizability and resolution at the chromosomal level.
Using the Microscopy Image Analyzer (MIA) tool builds on these previous methods by incorporating advanced image post-processing techniques that enhance annotation quality and improve resolution. Trained on nearly 1,300 high-quality images, MIA benefits from a larger and more diverse training dataset and introduces a refined segmentation process that accurately identifies and separates closely clustered ecDNA, resolving them even when colocalized around or between chromosomes (Figure 2G). Unlike ecDetect, MIA’s method does not rely heavily on size thresholding, allowing it to maintain high accuracy without filtering out subtle ecDNA signals.
Moreover, MIA’s ability to classify chromosomes within the segmented ROIs provides an additional layer of precision, which is crucial for distinguishing between ecDNA and chromosomal artifacts. This capability directly impacts the overall accuracy of ecDNA detection, as it reduces false positives and negatives that arise from misclassification in complex cellular environments. By comparing the performance of MIA with ecDetect and ecSeg (Table 1, Sections A and B; Supplementary Table 1), we demonstrate significant improvements in both the accuracy of ecDNA identification and the ability to handle unannotated images.
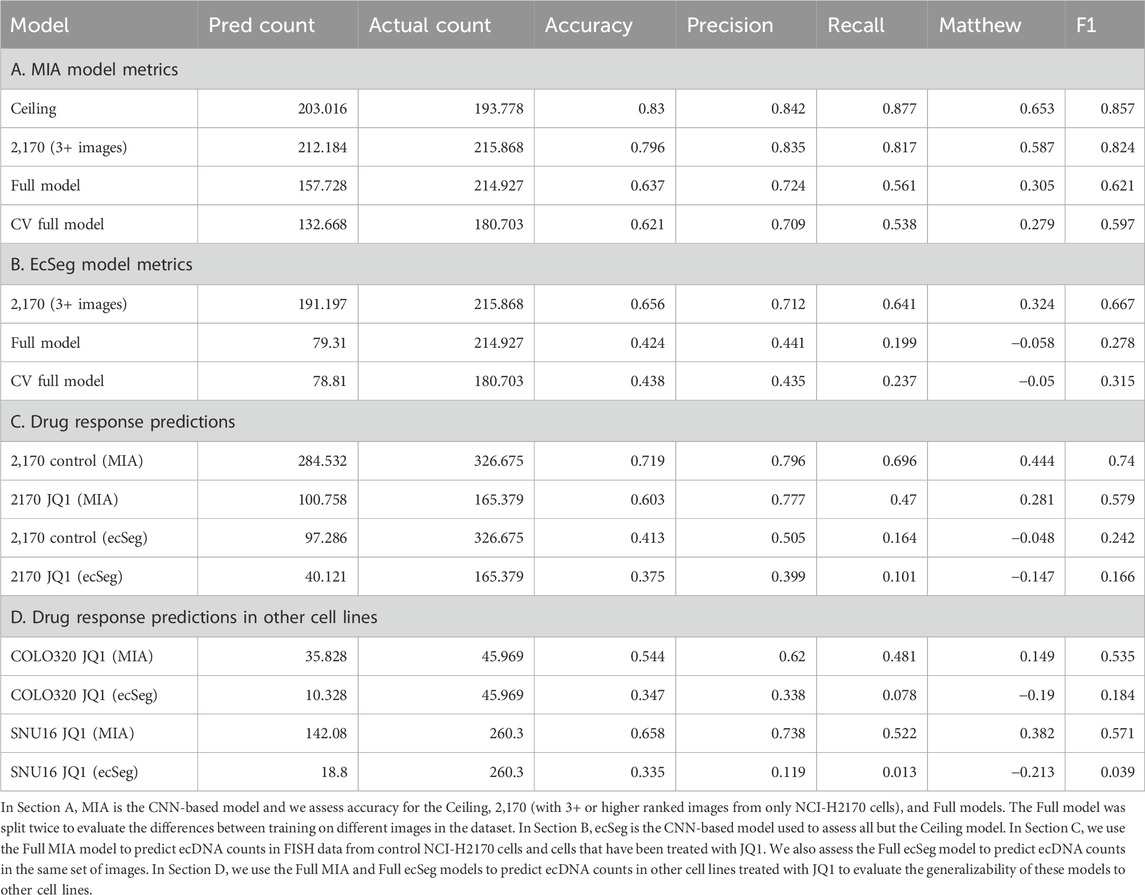
Table 1. Accuracy metrics across all models.
Post-processing analysesContour detectionContour detection is a technique used in image processing and computer vision to identify and delineate the boundaries or edges of objects within an image. A contour represents a curve that connects all the continuous points along a boundary that share the same color or intensity. In the context of image segmentation, contour detection is crucial for accurately separating and defining the shapes and structures of different objects within an image, such as nuclei, chromosomes, or ecDNA.
When dealing with conjoined segmentations—instances where multiple objects (e.g., closely clustered ecDNA) are touching or overlapping (Figure 2H), contour detection helps to identify the precise boundaries of each individual object. This allows for the separation of these conjoined objects into distinct segments, thereby improving the accuracy of the model in distinguishing between different ecDNA entities or other features in the image.
To enhance the accuracy of ecDNA detection, we applied contour detection as a critical post-processing step. By accurately delineating the boundaries of individual ecDNA within these complex regions, we were able to significantly improve the model’s ability to distinguish between different ecDNA entities. The improvement after using contour detection underscores the importance of advanced post-processing techniques in refining the performance of computer vision models for complex biological image analysis.
Merging data from other fluorescent channelsOnce MIA was executed to predict ecDNA in unannotated images, our next step was to identify the specific genes located on these predicted ecDNA, enabling us to count and differentiate between different ecDNA species and assess oncogene amplification levels. In our case, we labeled two oncogenes known to localize to ecDNA in each cell line: ERBB2 and MYC for NCI-H2170 cells, and FGFR2 and MYC for SNU16 and NCIH716 cells. Beyond using DAPI fluorescence, which provides a general overview of nucleic acids in our images, we employed FISH DNA probes that bind directly to genomic regions within each of these genes. To accurately map the predicted ecDNA locations with the actual locations identified through other channels (e.g., FITC and Texas Red), we developed a post-processing script. This script enabled the alignment of MIA-predicted ecDNA with the fluorescent signals from the gene-specific probes. When comparing the results of this script to human annotations, we found that the accuracy ranged within 97% ± 2% (Supplementary Figures 3–5; Supplementary Table 2), demonstrating the effectiveness of our approach (See Supplementary Methods for more details).
Applications in systems pharmacology: changes in ecDNA during drug treatmentApproximately 15% of tumors harbor ecDNA (Kim et al., 2020), yet research into the critical response mechanisms involving ecDNA remains limited, and only a few drugs have been thoroughly explored. Identifying treatments that specifically target cancer cells with ecDNA presents a significant challenge. To address this challenge, we developed CytoCellDB (Fessler et al., 2024), a comprehensive global data resource designed to streamline drug response evaluations. This platform allowed us to systematically assess drug efficacy across 139 cell lines harboring ecDNA and over 400 cell lines without ecDNA, providing a robust framework for efficiently identifying impactful treatments. Through this approach, we identified a cell line whose ecDNA had not yet been reported, that co-amplifies ERBB2 and MYC on the same ecDNA amplicon. The discovery of new ecDNA model systems highlight the potential of CytoCellDB to uncover new insights in ecDNA and cancer research.
Co-amplification of oncogenes on ecDNAs presents unique opportunities for diversification of gene and gene dosage combinations across cells in a population. As demonstrated by Figure 3A, there are three identified “species” of unique ecDNA and one unidentified species. These different ecDNA species localize different genes or gene combinations on the same fragment of ecDNA, “mix and matching” genes that are not commonly that close to one another in genomic space. For example, the gene MYC is encoded in chromosome 8 and the gene ERBB2 is encoded in chromosome 17. Suddenly, on ecDNA they become neighbors in the ecDNA species that co-localize these genes on the same amplicon. In NCI-H2170’s case, we see ecDNA that localizes MYC and ERBB2 separately, and those that co-amplify these genes. We also see an “unknown” entity that amplifies genes other than MYC or ERBB2. These different species generate far more population genetic diversity than having one species alone. Increasing genetic population heterogeneity may be a strategy of these cancer cells to diversify their populations to increase the likelihood of generating advantageous traits to overcome drug resistance or changing environments, effectively “hedging their bets” (Figure 3B).
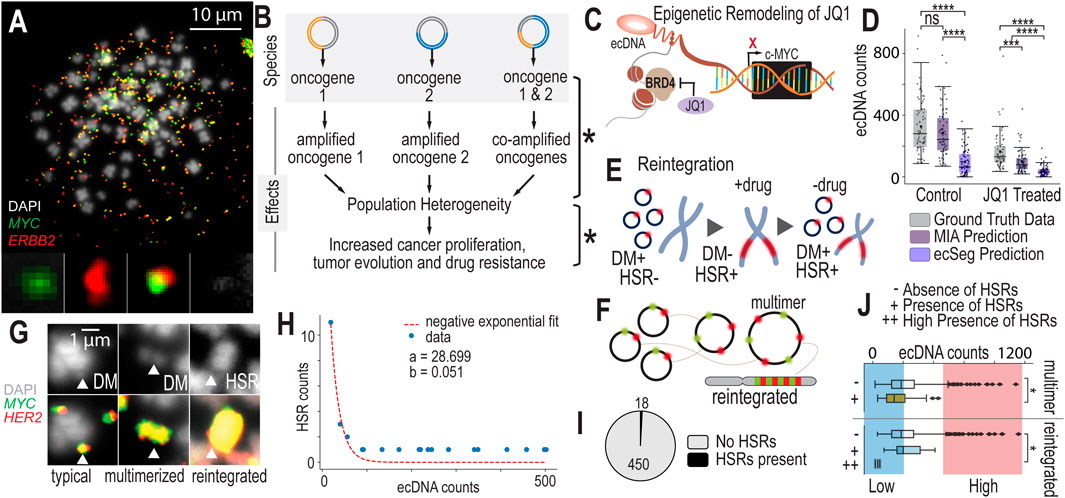
Figure 3. Scaling Data Analytics to Probe ecDNA-Mediated Drug Response Mechanisms (A). Metaphase FISH image with dual probe labeling of NCI-H2170 cells that have four or more ecDNA species present in most of their cell nuclei. (B) Having multiple species of ecDNA present across cell nuclei can generate widespread cell-to-cell heterogeneity. As ecDNA segregates unevenly into daughter cells, each of these species will segregate unevenly. This generates extreme population genetic heterogeneity in terms of copy number variation differences across cells. This heterogeneity could lead to accelerated adaptation and drug resistance. (C) JQ1 is a molecule that was recently discovered to impact ecDNA higher-order clustering. It inhibits BRD4, impacting MYC transcriptional activity. Because MYC is often amplified on ecDNA, JQ1 may globally influence cells that harbor ecDNA-based MYC amplications. (D) Experimental results and AI-predicted ecDNA counts for MIA and ecSeg comparing ecDNA counts in control (untreated) and drug-treated (JQ1) NCI-H2170 cells. Significance was determined using a Mann-Whitney-Wilcoxon test with p-values < 0.0001 (****) and < 0.001 (***). (E) Under treatment, cells eliminate their ecDNA rapidly and reintegrate them into chromosomes, forming homogeneous staining regions (HSRs). (F) Drug treatment increases the number of multimerized ecDNAs that are seen in metaphase FISH images, which may be a precursor to chromosomal reintegration. (G) FISH data showing different structural views of ecDNA during drug treatment, including double minutes, multimerized ecDNA or “hubs” and HSRs. (H) A model predicting ecDNA reintegration rate during drug treatment. (I) The fraction of cells that were observed to have HSRs during metaphase FISH image analysis. (J) Cells with lower ecDNA counts are more likely to be observed to have HSRs compared to cells with high ecDNA levels. Significance was determined with a Chi-Square test with p-value < 0.05 (*). Similarly, cells with lower ecDNA levels are more likely to have multimerized structures compared to cells with high levels of ecDNA.
Currently, we lack a systematic method to quantify changes in ecDNA during treatment. Previous studies that have studied the effects of drugs on ecDNA have been fragmented and inconsistent, with significant variations in cell lines, drugs, dosages, and time points. This lack of standardization has led to an incomplete understanding of the dynamic processes involved in ecDNA drug response. Most research to date has primarily focused on the effects of chemotherapeutic agents (Haque et al., 2001; Storlazzi et al., 2010; Kitajima et al., 2001; van Leen et al., 2022), such as methotrexate, hydroxyurea, cisplatin, etoposide, doxorubicin, and vincristine, on DM reintegration. Interestingly, tyrosine kinase inhibitors (TKIs) have been shown to induce reversible reintegration of DMs (Nathanson et al., 2014), highlighting the complexity of the interactions between drugs, ecDNA and cellular adaptation strategies.
Recent studies suggest that epigenetic remodeling agents, such as JQ1, exert unique effects on cell lines harboring ecDNA. JQ1 and other epigenetic modulators alter chromatin accessibility, effectively modifying the “openness” or “closed-ness” of DNA regions, including those amplified on ecDNA. JQ1 specifically targets BRD4, a BET bromodomain protein known to enhance MYC transcription. BRD4 may also tether double minutes (DMs, a type of ecDNA) in transcriptional “hubs” (Zhou et al., 2020; Wu et al., 2019; Hung et al., 2021). By inhibiting BRD4, JQ1 not only disrupts ecDNA-specific transcription (Wu et al., 2019) but also impacts the broader transcriptional landscape, reducing the activity of oncogenes amplified on ecDNA, such as MYC and PVT1 (Figure3C). This dual impact of JQ1 on both transcription and chromatin organization highlights its potential as a therapeutic agent in ecDNA-driven cancers.
In addition to these transcriptional effects, JQ1 may disrupt ecDNA “hubs,” the spatially organized groups of ecDNA molecules that cluster together. Such hubs are believed to be a critical adaptive mechanism in cancer cells that harbor ecDNA, enabling enhanced transcriptional output and rapid responses to selective pressures. The disruption of these hubs by JQ1 could undermine a key survival strategy in cancers harboring ecDNA, offering an exciting new avenue for drug development targeting these aggressive tumor phenotypes. Furthermore, JQ1’s influence on chromatin accessibility may indirectly impact the segregation and stability of ecDNA during cell division, adding another layer of complexity to its effects.
As a pharmacology application, we leverage our AI-accelerated image annotation platform, using the Microscopy Image Analyzer (MIA), to study changes in ecDNA counts before and after drug treatment across three distinct cancer cell lines: a lung cancer cell line (NCI-H2170), a gastric cancer cell line (SNU16), and a colorectal cancer cell line (COLO320DM). Our goal is to apply our image processing pipeline and MIA to predict ecDNA counts in images from untreated, control (DMSO-only) and drug-treated samples, with a focus on assessing the impact of JQ1 treatment on ecDNA counts after 24 h. This approach aims to provide deeper insights into the effects of JQ1 on ecDNA copy number changes and its potential role in disrupting critical adaptive mechanisms in cancer cells.
Model performance for predicting ecDNA counts in JQ1-treated samplesThe MIA model and the ecSeg model were evaluated for their ability to predict ecDNA counts in both untreated and JQ1-treated samples. Our objective was to determine how accurately each model could quantify the reduction in ecDNA levels induced by JQ1 treatment, a BET inhibitor known to impact chromatin accessibility and gene expression.
The MIA model achieved reasonable accuracy in predicting ecDNA counts across both untreated and treated conditions. For untreated samples, the model obtained an accuracy of 0.719, with precision and recall values of 0.796 and 0.696, respectively, resulting in an F1 score of 0.74. However, when applied to JQ1-treated samples, the model’s performance declined, reflecting the biological complexity of drug-induced changes. In treated samples, the MIA model reported an accuracy of 0.603, with precision at 0.777 and recall at 0.47, yielding an F1 score of 0.579. The drop in recall suggests that the model undercounted ecDNA, possibly due to the altered ecDNA patterns post-treatment.
The ecSeg model exhibited lower overall performance compared to the MIA model. For untreated samples, it achieved an accuracy of 0.413 with a precision of 0.505 and a recall of 0.164, indicating difficulty in detecting the full ecDNA population. In JQ1-treated samples, the ecSeg model’s performance further declined, with an accuracy of 0.375 and a precision of 0.399, while recall dropped to 0.101, resulting in a negative Matthew’s correlation coefficient (MCC) of −0.147. These metrics highlight the ecSeg model’s limitations in adapting to ecDNA changes following drug treatment.
Model comparison and implicationsThe performance of both models underscores the challenges in predicting ecDNA counts under drug treatment conditions. While the MIA model demonstrated moderate generalizability, achieving reasonable performance across untreated and treated samples, the ecSeg model struggled with both untreated and JQ1-treated datasets. The higher precision but lower recall in JQ1-treated samples for both models suggests that while some ecDNA features were accurately identified, a significant portion of ecDNA was missed, possibly reflecting altered ecDNA morphology or reintegration patterns in response to the drug.
These findings indicate that while our models, especially MIA, offer potential for predicting ecDNA behavior, further model refinement is needed to improve recall and robustness under varying biological conditions. The results also demonstrate the need to incorporate additional training data reflecting post-treatment changes to better capture the dynamics of ecDNA in response to drugs like JQ1 (Table 1, Sections A and B).
Cells rapidly eliminate ecDNA after 24 h of JQ1 treatmentComparing ecDNA counts before and after 24 h of JQ1 treatment, we observe that cells rapidly eliminate their ecDNAs. In NCI-H2170 cells, the mean ecDNA count in untreated wild-type cells is 330 ± 167, while after JQ1 treatment, the mean ecDNA count drops to 220 ± 132 (Figure 3D). Similarly, in COLO320 cells, the mean ecDNA count decreases from 50 ± 37 in wild-type cells to 45 ± 30 post-treatment. In SNU16 cells, the mean ecDNA count shifts from 370 ± 203 in wild-type cells to 298 ± 156 following JQ1 exposure. Using a Wilcoxon rank-sum test, we find that the difference in ecDNA counts between untreated and JQ1-treated populations is highly significant across all 3 cell lines. We see a similar trend between DMSO (vehicle-only control) and JQ1-treated (Supplementary Figure 6). This suggests that JQ1 induces a similar drug response mechanism as other chemotherapeutic agents, where cells rapidly eliminate their ecDNA, possibly through the selection of less sensitive clones, cells with fewer ecDNAs, or active elimination processes. Remarkably, the distributions of all ecDNA species—whether containing only MYC, only ERBB2, or both MYC and ERBB2—show significant differences before and after drug treatment (Supplementary Figures 7–10).
Cells reintegrate ecDNAs into chromosomal homogeneous staining regions (HSRs)During drug treatment, cells reintegrate ecDNA into chromosomes, forming HSRs, or regions of highly amplified genes within chromosomes (Figure 3E). In this way, ecDNA, which is extrachromosomal and independent of chromosomes, shapeshifts into chromosomal DNA. As a field, we still do not definitively understand how this phenomena increases cell fitness or survival during drug treatment. The overarching opinion is that cells “hide” and “store” their ecDNA in HSRs when it will serve them better in future conditions. Furthermore, ecDNAs form higher-order structures in which it appears that they multimerize and combine into larger ecDNA entities (Figure 3F). Multimerization may occur prior to reintegration; however, we currently lack sufficient evidence to confirm this process definitively (Figure 3G).
Comparing the number of HSR counts in NCI-H2170 cells before and after JQ1 treatment, we find that cells reintegrate ecDNAs at a rate of approximately 5% during drug exposure (Figure 3H). In this cell line, no HSRs are observed in untreated cells that contain the same set of genes as the ecDNAs, indicating that any HSR detected in the drug-treated samples containing MYC or ERBB2 represents a reintegrated ecDNA. After 24 h of drug treatment, we observe 18 reintegration events across 450 cells (Figure 3I), confirming that ecDNA reintegration occurs as part of the cellular response to the drug.
ecDNA reintegration mostly occurs in cells with fewer ecDNA countsReintegration events are more likely to occur in cells that have lower numbers of ecDNA. Analysis of over 600 metaphase FISH images from NCI-H2170 cells showed that DMs reintegrate into HSRs more frequently in cells with fewer DMs (p = 0.027, chi-squared test), consistent with findings from previous studies (Haque et al., 2001) (Figure 3J). One possible explanation for this observation is that cells with fewer ecDNAs may face lower cellular allocation costs, allowing them to invest more resources into processes such as reintegration. Alternatively, these cells may have different cell cycle distributions, potentially spending more time in specific phases that favor reintegration events. This could enable a higher frequency of HSR formation in cells with fewer ecDNAs, offering them a survival advantage under drug treatment conditions.
This analysis provides a powerful framework for quantifying how JQ1 influences ecDNA elimination and reintegration, opening new avenues to explore whether its effects are mediated through direct disruption of ecDNA hubs, transcriptional regulation, or broader processes like cell cycle dynamics. By systematically measuring changes in ecDNA, this work lays the foundation for future studies to unravel the complex mechanisms underlying JQ1’s impact on ecDNA behavior.
Model limitationsWhile the Microscopy Image Analyzer (MIA) offers significant advantages in automating the detection of ecDNA in metaphase FISH images, it has several limitations that users should consider.
Algorithm-specific limitationsOne key limitation is that the algorithm has been trained exclusively on metaphase FISH images. As such, applying MIA to other types of images (e.g., interphase cells or tissue sections) would likely require retraining the model on an appropriate dataset. Additionally, the detection of ecDNA is dependent on size thresholds inherent to the algorithm’s training. While it is difficult to provide an exact size threshold in terms of spatial resolution, the ecDNA analyzed in the training dataset typically ranged from 1 to 4 Mb in DNA content or approximately 0.25 µm in size (Supplementary Figure 2). Further research is needed to clarify the minimum detectable size for ecDNA and how this correlates with biological and technical resolution limits. Finally, MIA was trained on metaphase FISH images captured at ×60 magnification, and its performance is optimal with images of similar resolution. Deviations in magnification (e.g., ×20, ×40, or ×100) or image resolution may reduce accuracy or limit the ability to analyze full metaphase spreads efficiently.
Biological considerationsThe necessity for metaphase spreads limits the application of this algorithm to cell line models and samples where such spreads can be reliably generated. This may preclude its immediate use in primary patient samples or tissues that cannot be processed into metaphase spreads. Additionally, the interpretation of ecDNA distributions under JQ1 treatment warrants careful consideration. While our data suggest that JQ1 influences the population of ecDNA-positive cells entering metaphase, it is possible that JQ1 does not directly alter ecDNA itself but rather affects the subset of cells capable of entering mitosis or the chromosomal context of ecDNA and HSRs. This underscores the need for further studies to disentangle direct effects on ecDNA from secondary effects mediated through cell cycle regulation.
Technical limitationsFrom a software perspective, MIA is restricted to a graphical user interface (GUI) and lacks command-line functionality, preventing it from running in a “headless” mode. This limits its integration into larger, script-based workflows for high-throughput analyses. The software also requires substantial memory resources, which can be a constraint when analyzing large datasets or using less powerful machines. Additionally, MIA does not allow direct processing from master folders, requiring manual file management and input, which can be cumbersome for large-scale analyses.
A detailed guide on preparing, ranking, and analyzing metaphase FISH images with MIA is provided in the Supplementary Material. This documentation includes step-by-step instructions on image preparation, ranking criteria, and running the software for optimal results. These limitations highlight opportunities for future improvement in both the biological scope and technical functionality of MIA to enhance its applicability in ecDNA research.
ConclusionIn this study, we successfully automated the detection of extrachromosomal DNA (ecDNA) using the Microscopy Image Analyzer (MIA), providing a robust and accurate framework for analyzing metaphase FISH images. Through the development and application of our custom pipeline, we enhanced MIA’s capabilities specifically for ecDNA detection and quantification, establishing it as a powerful tool for investigating the effects of pharmacological treatments on cancer cells.
Our approach has yielded new insights into cellular responses during JQ1 treatment, revealing significant shifts in ecDNA counts, patterns of ecDNA reintegration into chromosomes, and the tendency of certain cells within the population to favor ecDNA reintegration. These findings underscore the potential of MIA-based analysis to advance our understanding of how cancer cells adapt to therapeutic pressures, offering valuable perspectives for drug discovery and cancer treatment strategies.
Additionally, we observed promising signs of generalizability. Models trained primarily on images from 1 cell line could predict ecDNA patterns in another cell line with moderate success, indicating that the framework holds potential for cross-cell-line applications. Similarly, models trained on images of untreated cells were able to predict ecDNA behavior in drug-treated cells with reasonable accuracy, demonstrating that the training process is sufficiently robust to generalize across treatment conditions. These findings suggest that the system is flexible and capable of adapting to varying biological contexts, though further validation will be needed to fully assess the extent of this generalizability.
MethodsPrimary cell cultureNCI-H2170, SNU16, and COLO320DM and NCIH716 cells were purchased from ATCC and were grown in RPMI media (Gibco) supplemented with 10% heat-inactivated fetal bovine serum (Gibco) in a humidified incubator with 5% CO2. SUM159PT cells were given as a gift from Gary Johnson’s laboratory (UNC
留言 (0)