
記住我
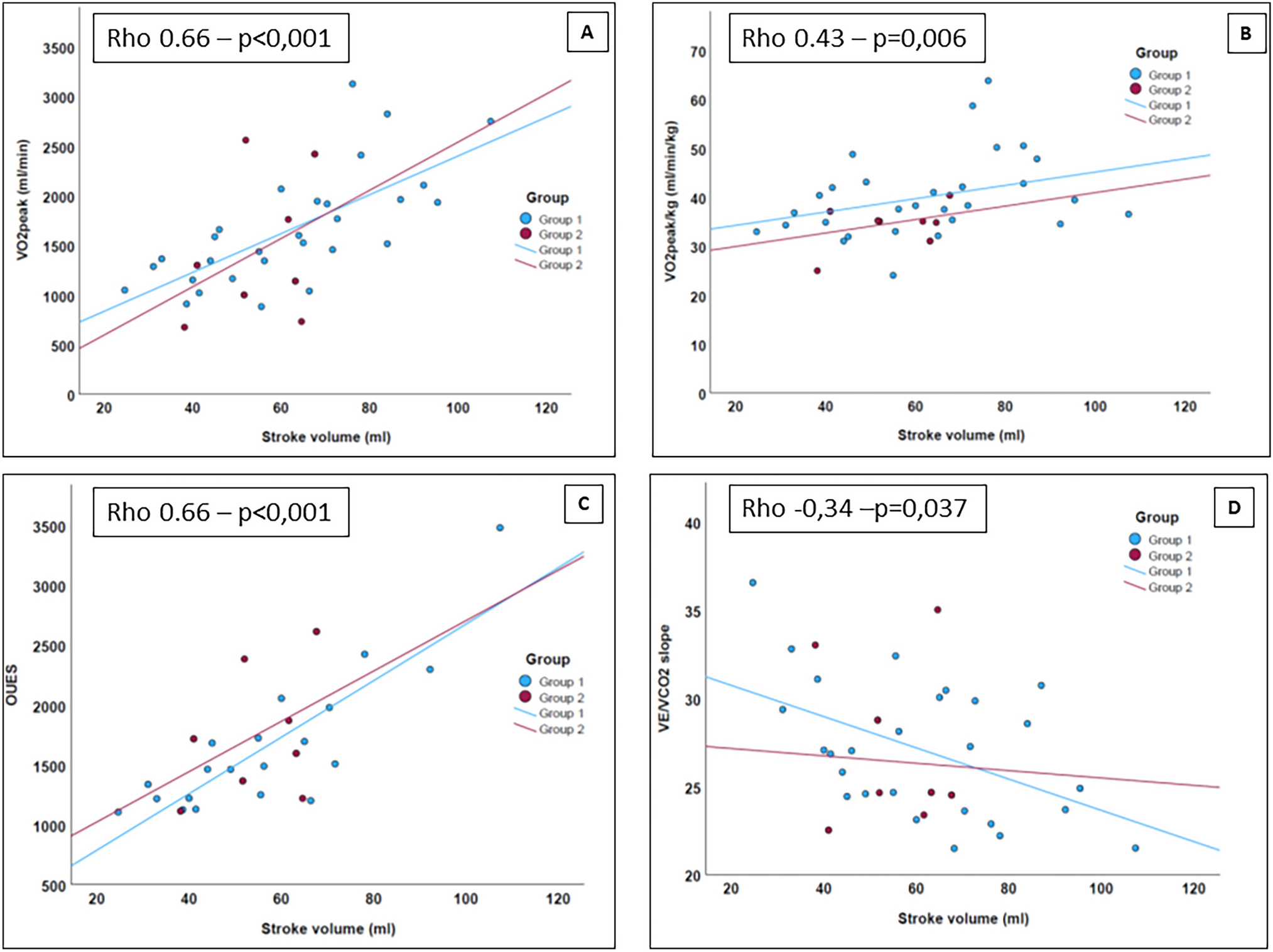

Through a rigorous variable selection process, a total of 1,474 cases were ultimately included after patients with incomplete feature information were excluded. This dataset comprises 992 cases of complete KD and 482 cases of incomplete KD, each characterized by 24 informative features, as presented in Table 1, including both binary and continuous variables. A comparison of the data between the KD and KD + CAL groups revealed that patients with KD + CAL were younger and had higher absolute platelet counts, NT-proBNP levels, and alanine aminotransferase levels (p < 0.05).
Table 1 Demographic and clinical characteristics of patients treated at Shanghai Children’s Medical CenterModel ResultsSince this study applied a fivefold cross-validation scheme to train and test the models, there were 5 outcomes. Each subset included 1180 or 1179 cases for training and contained 294 or 295 cases for testing. Furthermore, 24 informative features were selected as inputs to the machine learning model after excluding those with a missing data rate greater than 10%, with inputs involving both continuous variables and discrete variables. Specifically, since continuous and discrete variables may contribute different levels of impact to the assessment results of the machine learning model, three distinct sets of experiments were conducted for this study. Experiment A employs all 24 informative features (including 17 continuous features and 7 discrete features). However, Experiments B and C use only 17 continuous or 7 discrete features to train and test the models, respectively (Tables 2 and 3 and Figs. 2, 3, 4).
Table 2 Diagnostic performance of machine learning algorithms for all variables (continuous and discrete variables)Table 3 Diagnostic performance of machine learning algorithms for continuous variablesFig. 2
ROC curve showing the performance of the machine learning models in predicting CALs in KD patients using both continuous and discrete features. This curve highlights the balance between sensitivity and specificity for each model
Fig. 3
ROC curve showing the performance of the machine learning models in predicting CALs in KD patients, with only continuous features used. This curve highlights the balance between sensitivity and specificity for each model.Fig. 4: Receiver operating characteristic (ROC) – Discrete variables only
Fig. 4
ROC curve showing the performance of the machine learning models in predicting CALs in KD patients, with only discrete features used. This curve highlights the balance between sensitivity and specificity for each model
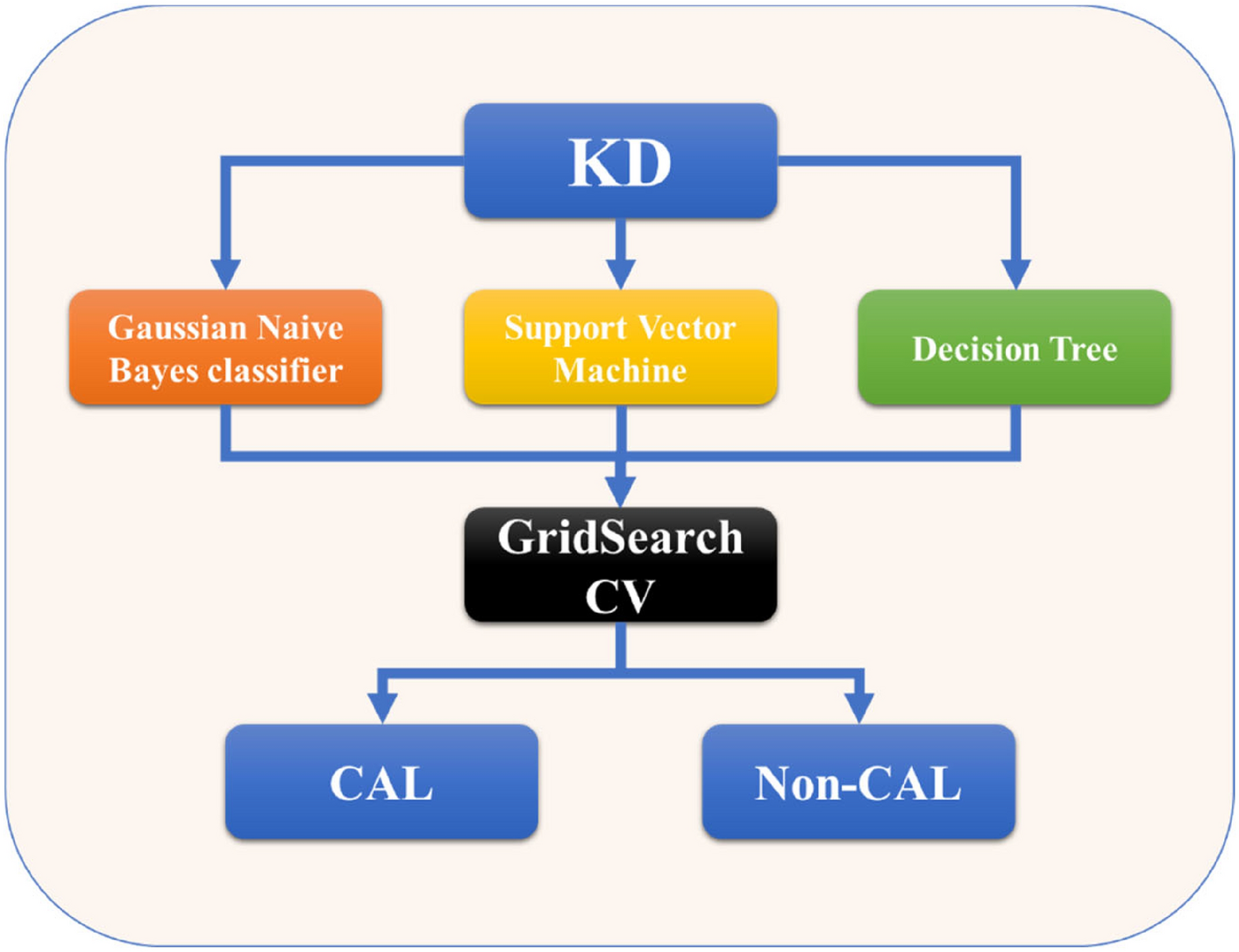
This study assessed the performance of machine learning models, including Gaussian naive Bayes, SVM, and decision tree, using five key criteria: accuracy, precision, recall, specificity, and F1 score. These models were evaluated to predict the likelihood of CALs in children with KD.
Tables 2–4 present the diagnostic performance of these models. Table 2 focuses on all variables, including both continuous and discrete variables, whereas Table 3 and Table 4 show continuous and discrete variables, respectively. The results highlight the best-performing model for each criterion, with the corresponding values in bold. In addition, the results from all three experiments are visually depicted via receiver operating characteristic (ROC) curves, which are shown in Figs. 2, 3, 4.
Table 4 Diagnostic performance of machine learning algorithms on discrete variablesIn the context of predicting the likelihood of CALs in children with KD, the inclusion of all available diagnostic features in the dataset clearly yields a substantial increase in overall prediction performance. In the full feature experiment, which employed all the informative features, the accuracies of the Gaussian naive Bayes, SVM, and decision tree methods were 58.55%, 91.72%, and 95.42%, respectively. The corresponding precision values were 73.08%, 93.24%, and 98.83%, the recalls were 50.44%, 93.14%, and 93.58%, the F1 scores were 59.68%, 93.19%, and 96.14%, and the specificities were 71.13%, 89.52%, and 98.28%, respectively. The area under the ROC curve (AUROC) values were 66.00%, 96.00%, and 96.00% for Gaussian naive Bayes, SVM, and decision trees, respectively. The comprehensive set of 24 informative features employed here, referred to as the "Full Feature Experiment," was not only exhaustively analyzed but also considered benchmarks by seasoned medical professionals in their clinical diagnoses.
In contrast, when focusing solely on continuous features and omitting the 7 discrete features, i.e., the "Continuous Feature Experiment," only marginal decreases in prediction performance were observed for the Gaussian naive Bayes, SVM, and decision tree models compared with that of the full feature experiment. This phenomenon can be attributed to the relatively low correlations between these 7 discrete features and the target variable, namely, the broadening of coronary arteries. Consequently, it is imperative to acknowledge that models constructed using only these 7 discrete features, as in what we shall now term the "Discrete Feature Experiment," are bound to exhibit notably inferior prediction performance compared with that of both the Full and Continuous Feature Experiments. It is therefore rational to conclude that the utilization of the 24 diagnostic features is the optimal choice for predicting CALs in children with KD.
Furthermore, we employed a fivefold cross-validation strategy for model training and evaluation, utilizing all 24 variables as inputs in the prediction process. This experiment, referred to as the "Full Feature Experiment," considers all the informative features (both continuous and discrete). The key performance metrics, such as accuracy, precision, recall, F1 score, and AUC, were calculated for each of the machine learning models: Gaussian naive Bayes, SVM, and decision tree. These metrics are summarized in Table 2 and Figs. 2–4.
In the subsequent analysis, we further explored how KCPREDICT distinguishes between complete KD and incomplete KD, as well as its predictive performance for complete KD. After data cleaning, the dataset consisted of 992 cases of complete KD with 24 variables and 482 of incomplete KD with the same 24 variables, including both continuous and categorical features. These variables were input into the KCPREDICT to predict the likelihood of complete KD.
From the results, we observe that the machine learning models achieved varying levels of performance when predicting the likelihood of complete KD. The gradient boosting model achieved the highest accuracy (96.72%), a precision of 88.89%, a recall of 100%, an F1 score of 94.12%, and an AUC of 100%. This finding indicates that the gradient boosting model is highly effective at identifying cases of complete KD, with no false positives and an excellent true-positive rate. The SVM model achieved an accuracy of 95.08%, a precision of 88.24%, a recall of 93.75%, an F1 score of 90.91%, and an AUC of 99.17%. While this model yielded slightly lower accuracy and AUC than did gradient boosting, it still demonstrated strong performance, especially in terms of recall. The decision tree model, with an accuracy of 95.08%, achieved a precision of 88.24%, a recall of 93.75%, an F1 score of 90.91%, and an AUC of 96.67%. This model is also effective at balancing precision and recall, although it was slightly less capable than both the gradient boosting and SVM models were in terms of overall accuracy and AUC. These metrics are summarized in Table 5 and Fig. 5.
Table 5 Diagnostic performance of machine learning algorithms that use all variables to predict complete KD statusFig. 5
ROC curve showing the performance of machine learning models in predicting complete KD status using both continuous and discrete features. This curve highlights the balance between sensitivity and specificity for each model
Prospective ValidationA total of 52 patients with KD were included in this study, among whom 7 (13.5%) had confirmed CALs. The model successfully predicted all 7 cases of CALs, with no missed diagnoses. No additional patients in the study developed CALs. The model demonstrated a predictive sensitivity of 100% (7/7) for CALs and an overall accuracy of approximately 100%, indicating excellent reliability in assessing CAL risk.
留言 (0)