
記住我
The most commonly used classification system to differentiate ischemic stroke subtypes is the one developed by the Trial of Org 10,172 in Acute Stroke Treatment (TOAST). The different groups are: large-artery atherosclerosis (atherothrombotic), cardioembolic, small vessel occlusion, stroke of other determined etiology, and stroke of undetermined etiology (cryptogenic) (1). The correct diagnosis of ischemic stroke subtype is very important for improving clinical outcomes and preventing new events. Nonetheless, stroke classification sometimes is challenging.
One important problem faced by the neurologists is the correct classification of cryptogenic strokes, due to the unclear thrombus origin (1). Technologies such as artificial intelligence (AI), specifically deep learning (DL), could assist in classifying ischemic strokes, aiding in the development of supplementary tools for physicians (2). AI attempts to replicate human cognitive functions, while DL uses large neural networks to deal with complex regression or classification problems. One example of a deep neural network architecture is the convolutional neural network, which recognizes the visual patterns of an image and retains the main information by applying convolutions (3, 4).
AI has proven to have great applicability to aid in the diagnosis and prognosis of ischemic stroke patients. Radiomic features extracted from brain embolism regions segmented from CTA images of large vessel occlusion (LVO) stroke patients have been used as input of machine learning (ML) models for the classification of stroke subtypes. A four-center retrospective study gathered thrombus-extracted radiomic features and basic information to construct a ML model that could reliably predict cardioembolic stroke, performing better than the routine radiological method (5). In another monocentric study, DL convolutional neural networks were applied for TOAST classification (cardioembolic vs. atherothrombotic) using only radiomic features from clots in brain CTA images (6). In a different approach, a deep neural network developed to diagnose cardioembolic stroke based on chest radiographs demonstrated good classification performance and biological plausibility (7). On the other hand, ML algorithms, including a deep neural network using demographic and clinical variables, have also been created for prediction of long-term functional outcome in stroke (8). Fused imaging (MRI/CTA) and clinical DL models outperformed predictability of good reperfusion after mechanical thrombectomy (MT) (9) and functional outcome (10, 11). Although MRI and CTA medical images have been usually used to build DL models in cerebrovascular disease, a recent study used retinal photographs for screening and staging of Moyamoya disease by a DL algorithm (12).
In 1996, alteplase became the first recanalization therapy for ischemic stroke, aimed at thrombus lysis (13). However, with the advent of endovascular therapies in the last decades, such as MT (14, 15) a different approach is available to treat ischemic stroke, which also enables the study of the biological material responsible for obstructing blood flow. Since Marder’s pioneering study (16), clot composition analysis emerged as a potential diagnostic tool to gain insight into ischemic stroke etiology (17) ML algorithms have been used in the histological (18) and proteomic (19) analysis of thrombi. The largest histological study in patients from the Stroke Thromboembolism Registry of Imaging and Pathology (STRIP) found statistically significant but clinically insignificant differences between clots of cardioembolic and atherothrombotic etiologies (18).
In a study regarding the macroscopic aspect of the clots, photographs were used to visually classify the thrombi as white or red/black, with excellent inter-reader agreement for graded clot color. While white clots were significantly associated with atypical etiologies, in particular with infectious endocarditis, there was no significant difference in typical etiologies (i.e., cardioembolic vs. atherothrombotic) (20). DL can adaptively learn representative information from raw medical imaging without any preconceptions related to the human-involved feature extraction process. In the present study, we propose using DL methods to recognize complex patterns in photographs of the extracted thrombi, together with clinical characteristics of the patients, to produce accurate predictions of atherothrombotic or cardioembolic TOAST classes. For this purpose, two convolutional neural networks were used, first an image segmentation neural network, and later a binary classification neural network. To the best of our knowledge, DL models have never used photographs of retrieved thrombi to predict stroke etiology.
2 Materials and methods 2.1 Study design: patients, data retrieval, biological samples, and image acquisitionThis retrospective study used a prospective registry of consecutive LVO ischemic stroke patients subjected to MT between April 2016 and January 2023 at La Fe University and Polytechnic Hospital in Valencia. The study protocol was approved by the research ethics committee (CEIm, approval #2021–577-1). Informed consent was obtained from all participating patients or their legal representatives. This study follows the Guidelines for Developing and Reporting Machine Learning Predictive Models in Biomedical Research (21).
Vascular neurologists retrieved the demographic and clinical characteristics from the medical history (age, sex, active smoking, and occurrence of diabetes, dyslipidemia, or arterial hypertension). The biological material was cerebral clots retrieved by neurointerventionalists during MT. Depending on the decision of the neurointerventionalist, based on the characteristics of the LVO, different extraction devices were used: (a) distal aspiration catheter with manual syringe, (b) balloon guide catheter plus stent-retriever, or (c) combined stent-retriever with distal aspiration catheter. The retrieved clot was either detached from the extraction device by gentle flushing with saline solution in most cases, or in some cases found in the aspiration syringe, and then preserved in saline solution at 4°C. No distinction was made between the head and tail of the thrombus, or between its shell and core. In the case of fragmented thrombi, the entire set of fragments was collected and treated as a single sample. Digital images of the thrombi were acquired once within 24 h of MT.
All the thrombus images were captured with the same camera (OLYMPUS® CAMEDIA C-5050, Olympus Optical Co., Ltd., Tokyo, Japan), format (TIF) and resolution (640 × 480 pixels) to avoid internal variability. As the camera captured images containing thrombi and non-relevant information, a segmentation process was necessary to focus exclusively on the thrombi for image analysis. The result of this segmentation is a new binary image called mask that contains the relevant information of the original image (i.e., the thrombus; see Figure 1 for representative images of cardioembolic and atherothrombotic thrombi). The manually segmented masks were obtained using the software ITK-SNAP v3.4.0 (22). This set of images/masks was used as a ground truth to train the segmentation neural network.

Figure 1. Representative images of retrieved thrombi. Images of a cardioembolic thrombus (A) and an atherothrombotic thrombus (B) as captured by the camera, and their corresponding manual segmentations, the thrombus masks (C,D).
Convolutional neural network was the modeling technique selected in order to combine thrombus images and patient features as input for DL categorical predictive fused models.
2.2 Segmentation neural networkChoosing the architecture of a neural network is crucial when developing a model in DL. We used one of the most widely used networks in biomedical image segmentation, the U-NET network, first developed by Ronneberger et al. (23). The U-NET consists of two parts: an encoder and a decoder which are interconnected with skip connections. The detailed architecture of the segmentation network can be seen in Figure 2. During the encoder phase, 4 blocks of convolutions layers are used, and in each block, different operations are applied such as convolution layers, batch normalization (24) and dropout (25) followed by pooling layers, effectively capturing the image’s contextual information. Batch normalization layers are used to normalize data during training, and dropout was used after pooling layers to avoid overfitting. In our U-NET, the kernel size utilized was 3×3 pixels, the starting number of filters was 64, and it was doubled in each down sampling step. Subsequently, the decoder comprises up-convolution layers and concatenations of the cropped feature maps extracted from the encoder part. Conversely to the encoder, the number of filters is divided in the “up-convolutions” of the decoder (23). All layers were activated with the ReLU function except the output layer, which was activated with the softmax function.
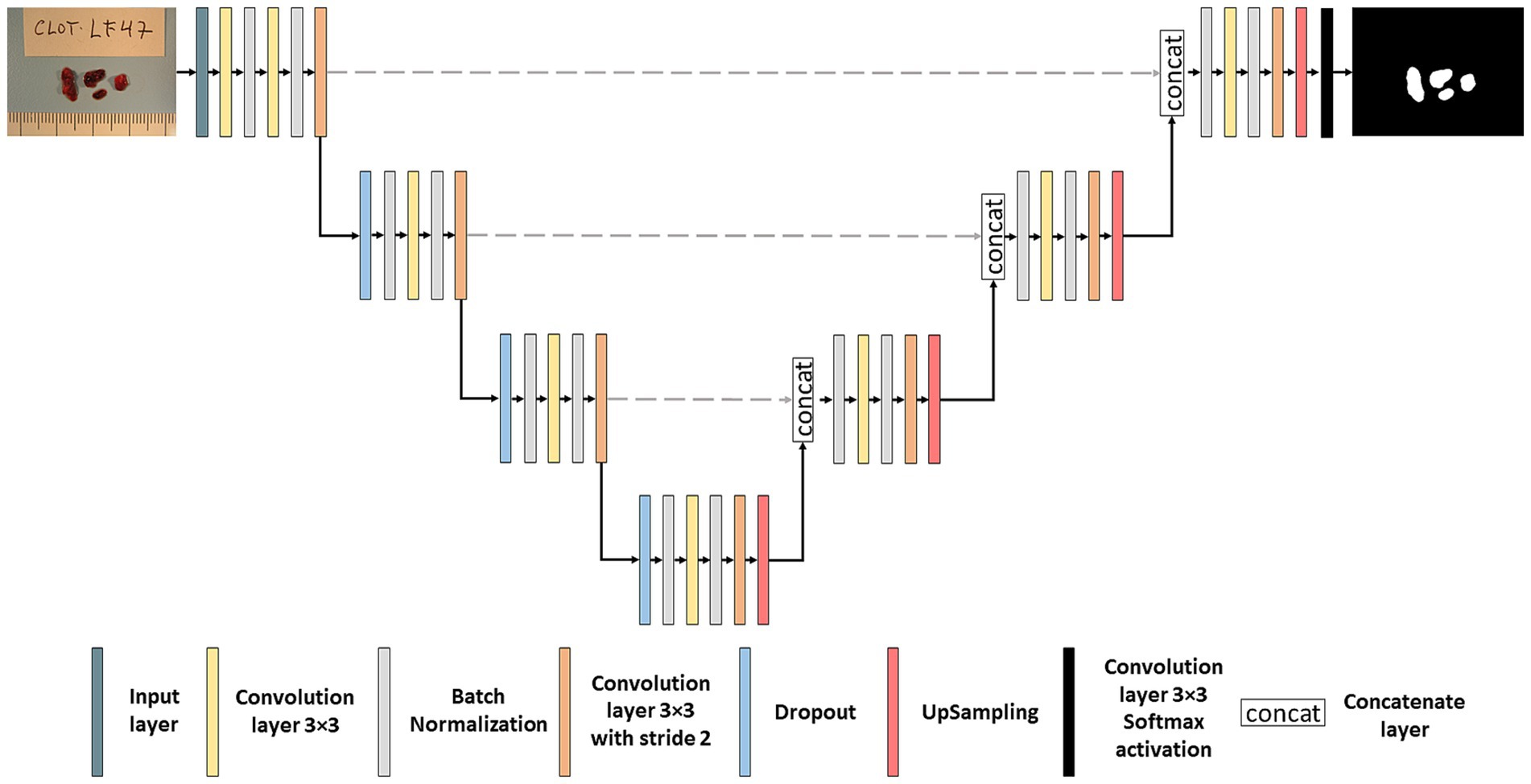
Figure 2. Segmentation neural network. Architecture of the U-NET neural network used for thrombus image segmentation.
2.3 Classification neural networkThe classification network adopts an architecture reminiscent of the LeNet model (26). The input to the classification network results from multiplying the original image by the mask generated in the segmentation network. This approach selectively retains only the pertinent information for thrombus classification, discarding non-relevant details and emphasizing the macroscopic structure. The detailed architecture of the classification network can be seen in Figure 3. The network started with 64 filters, each with 3×3 pixel kernels, and this number of filters was doubled after each pooling layer, culminating in a total of 1,024 filters. Dropout and Convolutional Block Attention Module (CBAM) (27) layers were applied following each fixed resolution block to enhance accuracy. Subsequent to the feature extraction layers, a global average pooling layer consolidates all features, yielding 1,024 values per image. These values are then utilized to input a fully connected subnetwork comprising of dense layers with 128, 32 and lastly 1 neuron (all with ReLU activation, exception for the last layer which used sigmoid activation). The model’s output is a number between 0 and 1, and the image was classified as atherothrombotic or cardioembolic according to a set threshold.
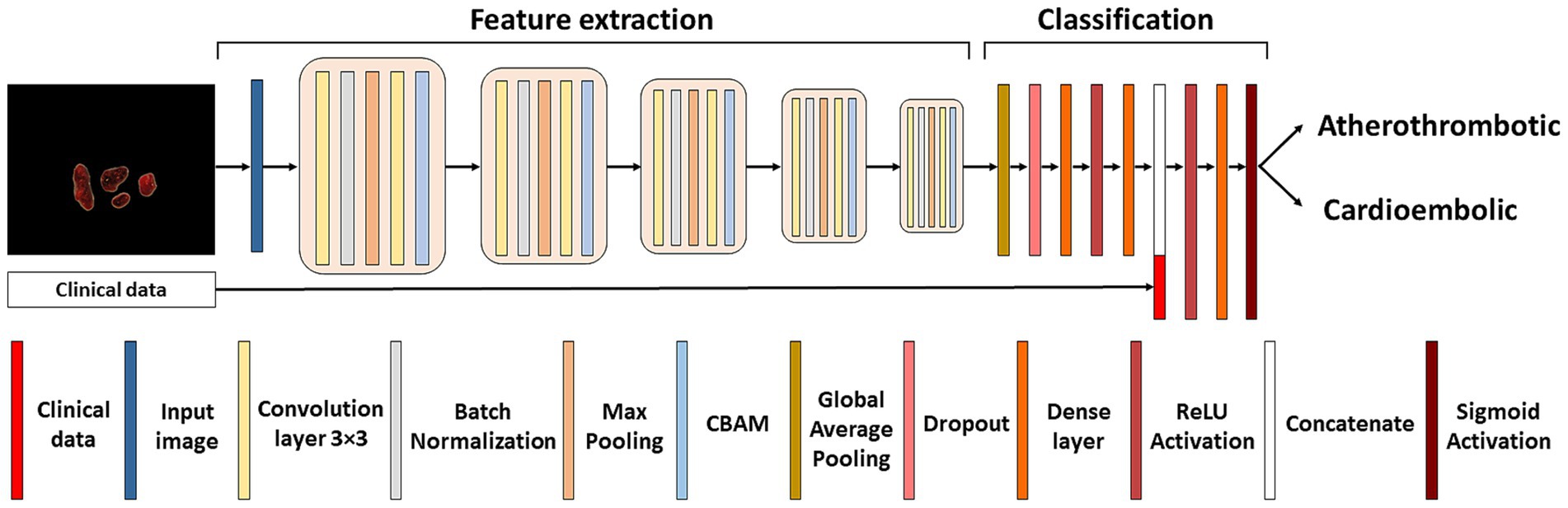
Figure 3. Classification neural network. Architecture of the LeNet neural network used for the etiological classification of thrombus images concatenated with patient’s demographic and clinical characteristics.
Several experiments were conducted to improve the accuracy of the model. The first model exclusively used as input data the thrombus image and the mask. After the creation of this model, the concatenation of the six demographic and clinical characteristics was done. Statistical analysis was performed to find significant differences between atherothrombotic and cardioembolic etiologies regarding patient characteristics. Then, different models were created in order to find the best layer concatenation to the fully connected layer. Once the best model with the best concatenation was obtained, data augmentation techniques such as blurring or sharpening were applied to ameliorate the model’s accuracy.
2.4 k-fold cross-validation strategyA k-fold cross-validation strategy was used to account for the rather small sample size. This involves dividing the dataset into k folds. Each fold will have a training set formed by k-1 folds and a test group which contains the remaining one. This process will be iterated k times so all data will be used as a train and test set (28). We used 5-fold cross-validation in both the segmentation and classification networks. As atherothrombotic and cardioembolic classes were unbalanced, a generator function was used to provide balanced samples to the classification network by randomly sampling the corresponding datasets.
2.5 Training processThe segmentation network was first trained on a subset of original images of the thrombi and their manually generated masks. Then, all the images included in the study were used. The loss function chosen was Dice loss, which employs the DICE coefficient (29). The DICE coefficient measures the overlap between two images. The optimizer utilized was Adam (30), and the number of epochs was established to 500 with 100 steps per epoch.
The classification network was trained with images whose etiology was known (i.e., atherothrombotic or cardioembolic). The loss function chosen in this network was the Binary Cross Entropy because, unlike the segmentation network, the classification operates as a binary classifier. Adamax was the optimizer employed in this network (30). The number of epochs was 1,000 with 100 steps per epoch.
DL algorithms require a substantial amount of training data, yet the disposition of annotated medical images is limited. Data augmentation was used, where some modifications are applied to the original images and improve the network’s performance (31). In our case, the modifications applied were random rotations/flips along the horizontal and vertical axes, and the application of blurring and sharpening, which affect the image edges. This process of data augmentation was applied in both segmentation and classification networks to improve their generalizability and minimize overfitting.
2.6 Test processThe DICE coefficient was employed to assess the performance of the segmentation network. The mask predicted by the model was generated using Test Time Data Augmentation (TTDA) (32), a technique consisting in predicting the output with different input transformations (horizontal and vertical flip in our case) to generate several predictions to later average them (after inverting the transformation). This technique is a simple way to use auto-assembling that generally improves accuracy and robustness of the network at test time.
The classification network underwent the evaluation using also the TTDA approach. The model’s input was the image multiplied by the mask generated in the segmentation network, and the output was the model’s prediction. The image was classified as either atherothrombotic or cardioembolic depending on the average numerical value returned by TTDA. A threshold was set to determine if images were classified as cardioembolic or atherothrombotic. The accuracy estimated from the training data of the model was used to determine the threshold which was stablished to 0.2. The models were evaluated three times and the results represent their average.
Once the classification predictions were obtained, which is the index test of this study, accuracy, precision, sensitivity, specificity and AUC score were used for the evaluation of the model. We used a bootstrapping approach in order to estimate the 95% confident intervals of our predictions. Bootstrap used 1,000 samples of the test set. In order to calculate these metrics, the reference standard was the TOAST classifications provided by clinicians. Performance accuracy was used to select the best model.
2.7 Statistical analysisStatistical analysis was performed with the demographic and clinical characteristics obtained from the patients to observe the existence of significant differences between patients who suffered a stroke of atherothrombotic or cardioembolic etiology. The χ2 test was used for the categorical variables (sex, smoking, hypertension, dyslipidemia, and diabetes) and the Wilcoxon test for the non-normally distributed continuous variables (age and DICE coefficients). R software in version 4.3 was used. p-values <0.05 were considered statistically significant.
3 Results 3.1 Patient characteristicsA flowchart of the study is shown in Figure 4. Out of 290 LVO stroke cases subjected to MT, 166 patients were included (age [mean ± SD] 69.11 ± 13.39 years; 67 [40.36%] female). TOAST etiologies were: 87 cardioembolic, 31 atherothrombotic, and 48 cryptogenic. Demographic and clinical characteristics are detailed in Table 1.
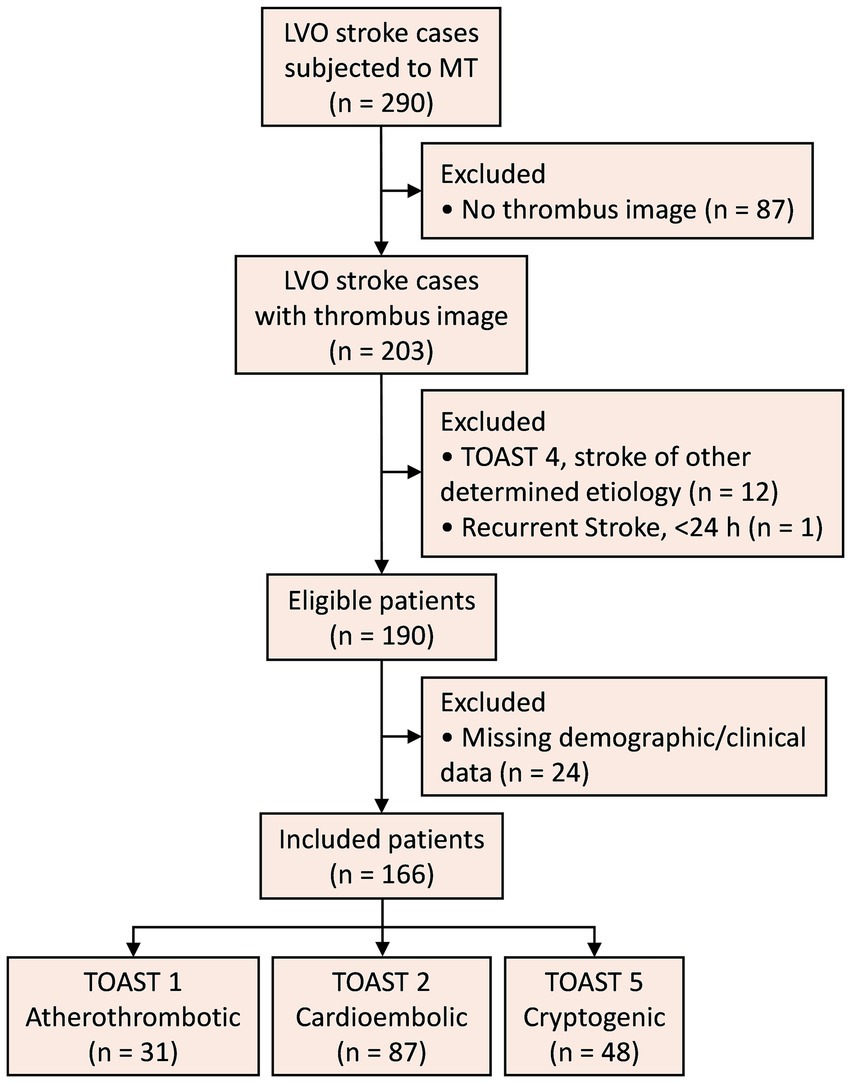
Figure 4. Study flowchart. LVO, large vessel occlusion; MT, mechanical thrombectomy; TOAST, Trial of Org 10,172 in Acute Stroke Treatment.
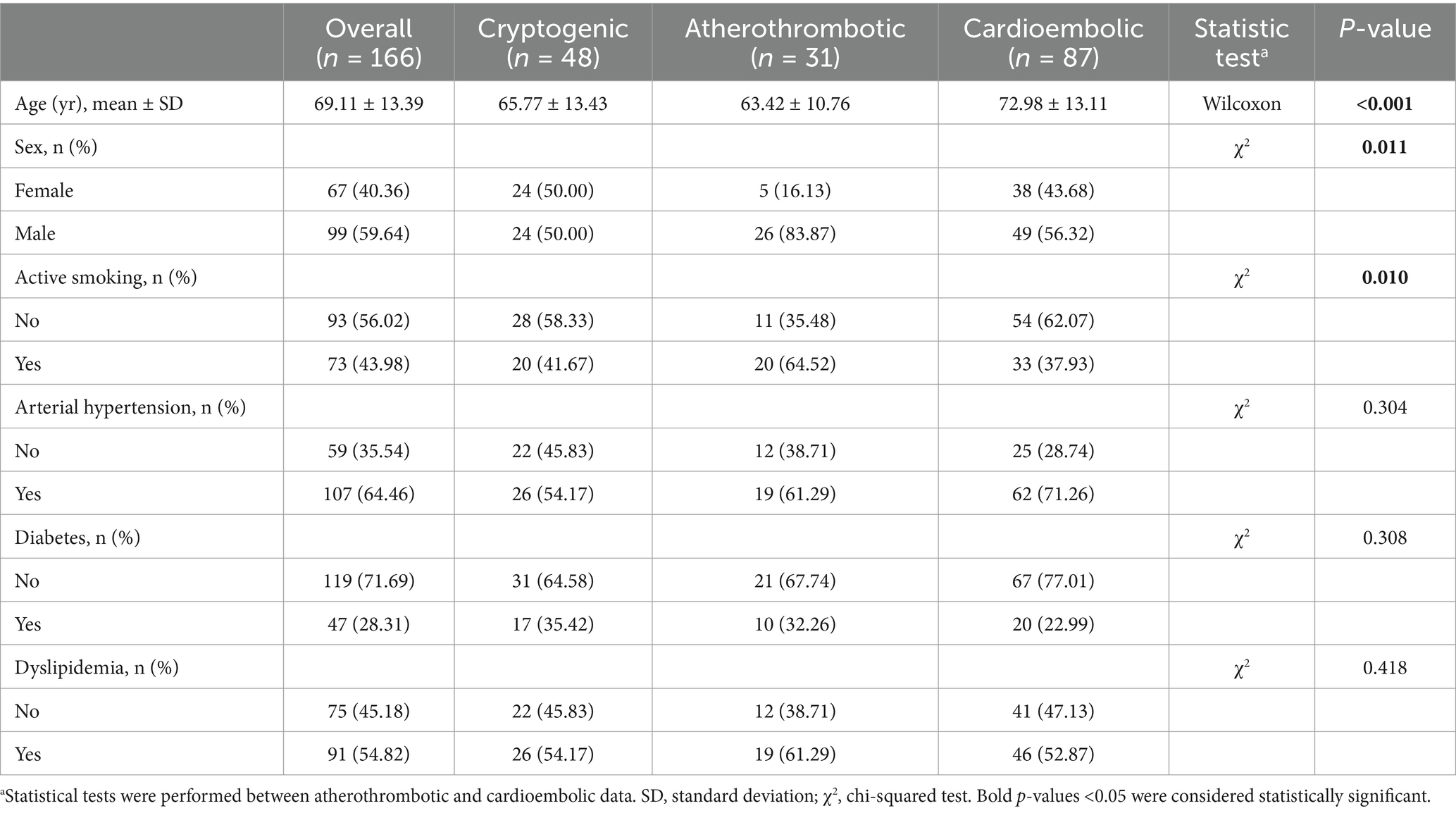
Table 1. Sample description and statistical analysis.
3.2 Image segmentation performanceIn the segmentation network, the images of all 166 patients were used, regardless of stroke etiology. The proposed segmentation network had a total of 1,963,202 parameters (1,959,938 trainable) and obtained a DICE coefficient of 0.95551 ± 0.12996 without TTDA and 0.95553 ± 0.13037 using it. As can be noticed, TTDA improved results (although not statistically significant, p = 0.744, W = 0.310, Wilcoxon test). The average processing time of the segmentation network was 0.5 s per image.
3.3 Etiology classification performanceIn the classification network, the images of 118 patients with known etiology were used (31 atherothrombotic and 87 cardioembolic). Three consecutive models were developed to optimize accuracy, precision, sensitivity, specificity, and area under the curve (AUC). Cardioembolic etiology was considered the positive class. Table 2 summarizes input data, data augmentation, and performance metrics (mean [95% CI]) for each model.
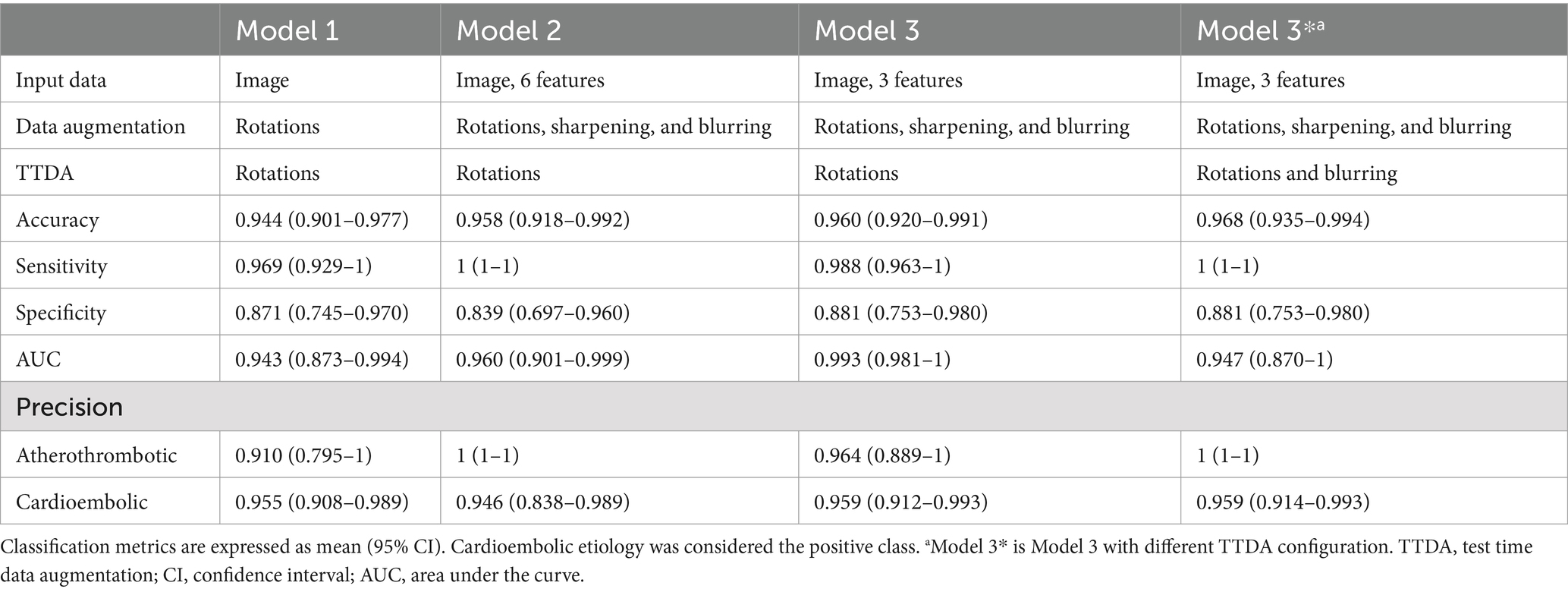
Table 2. Summary of input data, data augmentation, and performance metrics of the classification models.
Model 1 exclusively used the original image multiplied by the mask as input. The accuracy of the model was 0.944, and the precisions were 0.910 and 0.955 for atherothrombotic and cardioembolic etiologies, respectively.
Given the possibility of accessing demographic and clinical data associated with the thrombus image, Model 2 concatenated all the six characteristics (age, sex, active smoking, diabetes, dyslipidemia, and arterial hypertension occurrence) in the dense layer with 128 neurons to the fully connected layer of the classification model. In addition, image sharpening and blurring operations were applied in the data augmentation process. The accuracy of the model increased to 0.958, and the precisions were 1 and 0.946 for atherothrombotic and cardioembolic etiologies, respectively.
Given that the addition of demographic and clinical characteristics improved the accuracy of Model 2, we decided to perform a statistical analysis of these characteristics to find out statistically significant differences between patients who suffered from a stroke of cardioembolic or atherothrombotic etiology (Table 1, characteristics with a p-value <0.05 have been highlighted). In the light of the statistical analysis results, only the 3 significantly different characteristics (age, sex, and active smoking) were included in Model 3, and they were concatenated in the same layer that Model 2. The model increased its accuracy from 0.958 to 0.960. The precisions were 0.964 and 0.959 for atherothrombotic and cardioembolic etiologies, respectively.
Finally, we tested Model 3 with a different TTDA configuration consisting of blurring the images to see its effect not only in the training process, but also in the test. The accuracy of this optimal Model 3* increased to 0.968, and the precisions for atherothrombotic and cardioembolic etiologies were 1 and 0.959, respectively. AUC for cardioembolic (positive) prediction was 0.947. As can be noticed, the blurring at TTDA improved the accuracy metrics, thus suggesting that color information was more relevant for classification that texture information. The concatenation of the 3 patient characteristics in Model 3* was performed in the dense layer with 32 neurons. The parameters for this model were 4,874,922 (4,872,938 of them were trainable).
3.4 Classification of cryptogenic thrombiUsing Model 3*, the best performing classification network for atherothrombotic and cardioembolic thrombi, we conducted a preliminary experiment to evaluate the 48 images of thrombi with cryptogenic etiology (together with age, sex, and active smoking data) and predict their classification. Cryptogenic thrombi were evaluated by the 5 folds of the model and the final result was the vote of the majority of the folds. The network classified 46 images as cardioembolic and 2 images as atherothrombotic (Figure 5). This suggests that cryptogenic thrombi are more similar to cardioembolic thrombi (95.83%) than atherothrombotic thrombi (4.17%), which is in good agreement with the higher incidence of cardioembolic etiology. In 36 out of 46 cases (78.26%) the prediction of cardioembolic origin was unanimous. After further diagnostic workup, 5 out of the 36 unanimous predictions were clinically confirmed as cardioembolic etiology (Figure 5).
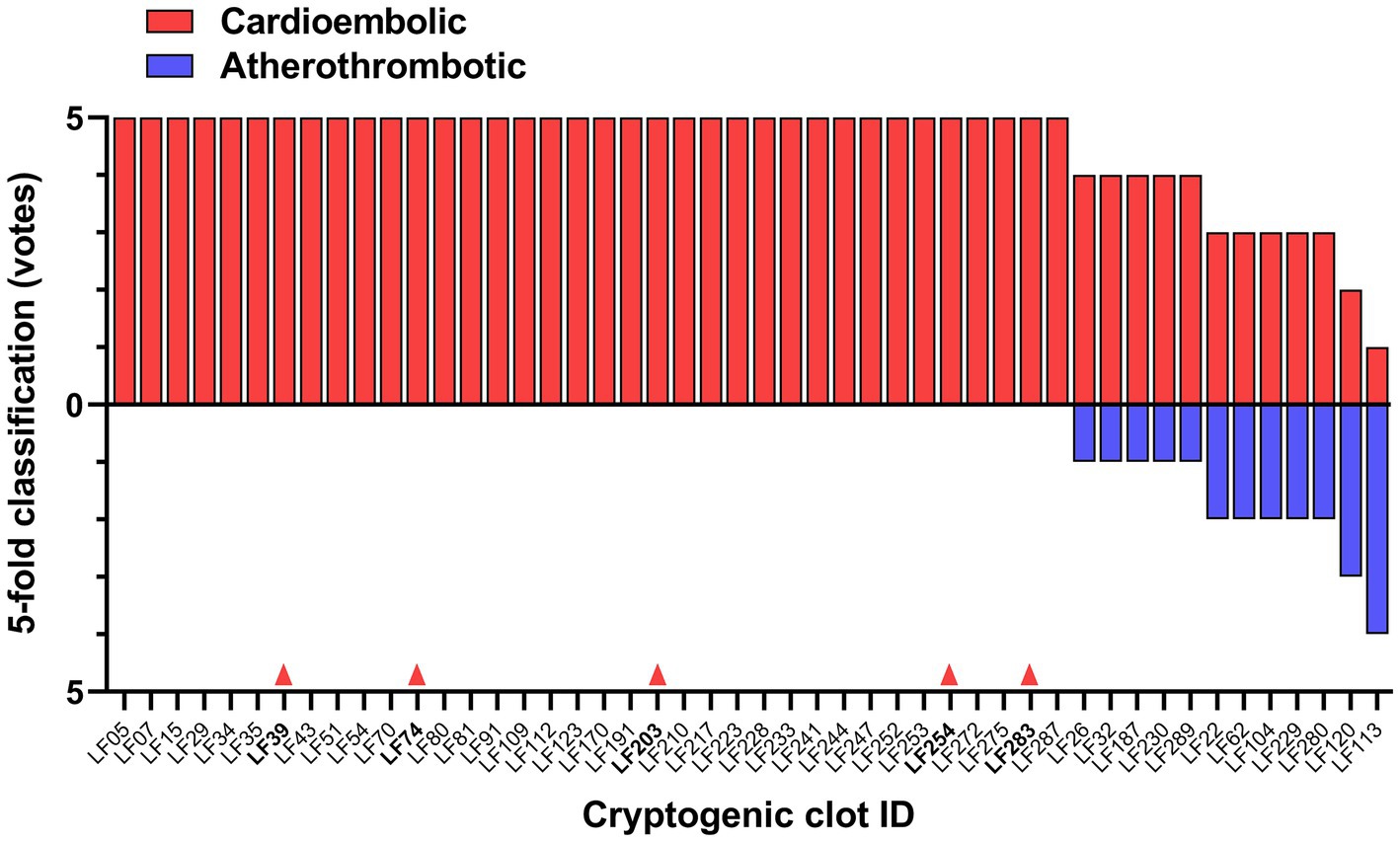
Figure 5. DL-model classification of cryptogenic thrombi into cardioembolic or atherothrombotic. The votes of the 5-fold model for each clot are shown. Red arrows indicate 5 cases clinically confirmed as cardioembolic stroke by further diagnostic workup.
4 DiscussionIn this study, we have developed and optimized a method to automatically segment stroke thrombus images from digital photographs and to accurately classify them, together with clinical characteristics, into atherothrombotic and cardioembolic categories. Our results show the usefulness of using DL on thrombus photographs for typical etiology classification, when compared to visual classification by expert interventional neuroradiologists (20). High accuracy of our best model (0.968) outperformed accuracies reported in previous studies using AI to predict cardioembolic or atherothrombotic origins based on different clot features. Combination of DL convolutional neural network and radiomics of brain embolism regions segmented from the CTA images predicted stroke subtype with 0.8929 accuracy (6). A ML model using thrombus-extracted radiomic features from CTA images and basic information predicted cardioembolic stroke with 0.904 accuracy (5). With regard to retrieved thrombi, ML models classified cardioembolic versus atherothrombotic with 0.77 accuracy on the basis of clot histomics (33), 0.883 accuracy based on clot proteomics (19), and 0.889 accuracy when metabolomics features were used as etiology predictors (34). On the other hand, classification of cardioembolic stroke based on a DL neural network using chest radiographs showed 0.844 accuracy (7).
The segmentation network with the U-NET architecture has demonstrated high performance in various medical imaging tasks, such as segmentation of brain tumors or skin lesions (35, 36). The average DICE coefficient obtained in our case was 0.955, proving its good performance. This allowed reliable automatic segmentation of the thrombus from the whole photograph, in contrast to time-consuming and less accurate manual segmentation carried out to delineate the cerebral embolism region in the CTA image on the patient’s head before extracting radiomic features for etiology prediction (6).
Regarding the classification neural network, our best model achieved not only a high accuracy of 0.968, but also high precisions of 1 for atherothrombotic and 0.959 for cardioembolic cases. These results suggest that the proposed method can effectively classify thrombi as either atherothrombotic or cardioembolic. The architecture of the model was inspired in the well-known architecture proposed by LeCun et al. (26). The main difference in the present study was the application of dropout, Adamax optimizer, convolutional block attention module (CBAM) (27), and the change of the activation function in the last layer from softmax to sigmoid due to our approach, which is a binary classification.
Classification metrics were improved in the present study by combining imaging and selected clinical data in the DL model. This kind of fused DL models have not been previously used for stroke etiology prediction, but outperformed separate imaging or clinical models (and traditional risk-scoring by expert neurologists) when used in the prediction of functional ischemic stroke outcome (10, 11, 37) and good reperfusion after endovascular treatment (9). Performance of more complex neuronal networks combining clot macroscopic imaging, omics features and patient clinical characteristics deserves further research.
Different data augmentation options were used. We included rotations as the orientation of the clots was somewhat random at the moment of image acquisition. Blurriness is also a realistic artifact as sometimes the camera can be not totally focused. Of note, our best performing model applied blurring after the process of data augmentation. The improved performance by application of blurring may indicate that the network is using mainly color information from the image rather than texture information. Previous studies have compared the proportions of fibrin and cellular components (i.e., chromatic aspect) in atherothrombotic and cardioembolic thrombi, but there is no consensus. Some studies report that cardioembolic thrombi contain more red blood cells (red thrombus) than atherothrombotic thrombi (38, 39), while others conclude the opposite (40, 41). Of note, a recent meta-analysis including 21 studies found that fibrin composition is significantly higher (white thrombus) in strokes of cardioembolic and cryptogenic origin than in strokes of non-cardioembolic origin (42).
Cryptogenic thrombus and their clinical characteristics were introduced as input data into the classification network as a proof-of-concept for the classification of thrombi with unknown origin. The findings of this experiment indicate that the classification network tends to unanimously categorize in most cases cryptogenic thrombi as cardioembolic rather than atherothrombotic. A previous study also more likely predicted a cardioembolic origin in cryptogenic thrombi by applying a histomics-based ML model (33). These results are in line with similarities in thrombus histology, interventional and clinical outcome parameters previously observed between cryptogenic and cardioembolic thrombi, when compared to non-cardioembolic thrombi (43), thus supporting the hypothesis that the majority of cryptogenic strokes are actually cardioembolic. However, this should be taken with caution, as bioinformatic analysis of clot transcriptomes from different TOAST etiologies showed that gene expression of cryptogenic thrombi was not clustered toward only one group, but showed expression patterns related to both atherothrombotic and cardioembolic etiologies (44). The use of DL offers a new research avenue for uncovering cryptogenic stroke. The next step in this process should be to ensure that cryptogenic strokes, which were initially classified as a cardioembolic stroke by the model, are clinically re-evaluated to detect any underlying cause of cardioembolic stroke and thus confirm the diagnosis. Interestingly, at present 5 out of the 36 cryptogenic thrombi unanimously predicted as cardioembolic by the model have been clinically confirmed after further diagnostic workup. This supports the need to maintain the diagnostic workup effort in the remaining 31 patients.
Regarding atherothrombotic strokes, there has been in recent years an increasing interest in the application of AI in carotid plaque detection using ultrasound, CT scans, and MRI. Deep learning models based in CNNs have been demonstrated to be a valid help in identifying the characteristics of vulnerable and potentially symptomatic plaques, increasing the accuracy of imaging detection, or simply speeding up the diagnostic process, in order to prevent future cerebral ischemic events (45).
Although this study provides a DL classification model that shows translational promise in stroke diagnosis, it has limitations. Regarding the handling of thrombotic material, different MT devices and techniques were used to obtain clot samples with different degrees of fragmentation, which were stored in cold saline solution for different periods of time until image acquisition within 24 h, potentially affecting the morphological characteristics of the thrombi. It is a monocentric study with a limited sample size, although higher than in other studies using ML and clot histomics (33), proteomics (19), or radiomics (6). Some patients who underwent MT during the recruitment period were excluded because thrombus image or demographic/clinical data were not available, which may have introduced selection bias. However, the proportions of cardioembolic, atherothrombotic and cryptogenic etiologies in the patients finally included were quite similar to those expected in the TOAST stroke subtype classification in clinical practice (46). Data augmentation (image modification) techniques and a k-fold cross-validation strategy were used to account for the limited number of images available and to minimize overfitting. These methods proved useful in improving the performance of algorithms for classifying stroke subtypes (33) or predicting stroke functional outcome (37). Another limitation is the representativeness of the sample. The limited sample size has the potential to complicate the generalizability of the model, even with the use of techniques such as data augmentation and k-fold cross validation, given their dependence on the original dataset. To overcome this problem, a highly standardized protocol was developed to augment the dataset not only in our center, but also in different centers. Therefore, the present results should be extended in a multicentric study to increase the sample size and perform external validation of the model. For this purpose, it would be important to standardize data acquisition in all centers of a collaborative network. Finally, this DL model can only be used for patients from which a clot is retrieved. However, the estimated population eligible for endovascular treatment is ∼10% of stroke admissions (47).
5 ConclusionIn conclusion, two convolutional neural networks have been built for the automatic segmentation and highly accurate and precise etiological classification of thrombus images from patients with LVO acute ischemic stroke. This innovative approach should be validated in a multicentric study with a larger sample size. It has translational potential to serve as a complementary diagnostic support tool for vascular neurologists, thereby improving patient classification and enhancing decision making, particularly for secondary prevention of new events.
Data availability statementThe raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statementThe studies involving humans were approved by the Research Ethics Committee (CEIm) of La Fe University and Polytechnic Hospital in Valencia. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributionsÁL-G: Data curation, Formal analysis, Investigation, Methodology, Resources, Software, Visualization, Writing – original draft, Writing – review & editing. AA-V: Data curation, Resources, Writing – review & editing. IV-G: Data curation, Resources, Writing – review & editing. IE-M: Resources, Writing – review & editing. LM-C: Resources, Writing – review & editing. FA-R: Resources, Writing – review & editing. DLTH: Data curation, Resources, Writing – review & editing. GF: Resources, Writing – review & editing. JIT: Resources, Writing – review & editing. JBS: Conceptualization, Funding acquisition, Project administration, Resources, Supervision, Visualization, Writing – original draft, Writing – review & editing. JVM: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Writing – original draft, Writing – review & editing.
FundingThe author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was funded in part by the INBIO Program (Universitat Politècnica de València -Hospital Universitari i Politècnic La Fe/Instituto de Investigación Sanitaria La Fe) through grants AP2021-01 and PI2023-12. The funders were not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statementThe authors declare that no Gen AI was used in the creation of this manuscript.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes References1. Adams, HP, Bendixen, BH, Kappelle, LJ, Biller, J, Love, BB, Gordon, DL, et al. Classification of subtype of acute ischemic stroke. Stroke. (1993) 24:35–41. doi: 10.1161/01.STR.24.1.35
Crossref Full Text | Google Scholar
2. Miceli, G, Basso, MG, Rizzo, G, Pintus, C, Cocciola, E, Pennacchio, AR, et al. Artificial intelligence in acute ischemic stroke subtypes according to toast classification: a comprehensive narrative review. Biomedicines. (2023) 11:1138. doi: 10.3390/biomedicines11041138
Crossref Full Text | Google Scholar
3. Greener, JG, Kandathil, SM, Moffat, L, and Jones, DT. A guide to machine learning for biologists. Nat Rev Mol Cell Biol. (2022) 23:40–55. doi: 10.1038/s41580-021-00407-0
Crossref Full Text | Google Scholar
4. Jiang, F, Jiang, Y, Zhi, H, Dong, Y, Li, H, Ma, S, et al. Artificial intelligence in healthcare: past, present and future. Stroke Vasc Neurol. (2017) 2:230–43. doi: 10.1136/svn-2017-000101
Crossref Full Text | Google Scholar
5. Jiang, J, Wei, J, Zhu, Y, Wei, L, Wei, X, Tian, H, et al. Clot-based radiomics model for cardioembolic stroke prediction with CT imaging before recanalization: a multicenter study. Eur Radiol. (2023) 33:970–80. doi: 10.1007/s00330-022-09116-4
Crossref Full Text | Google Scholar
6. Chen, Y, He, Y, Jiang, Z, Xie, Y, and Nie, S. Ischemic stroke subtyping method combining convolutional neural network and radiomics. J Xray Sci Technol. (2023) 31:223–35. doi: 10.3233/XST-221284
Crossref Full Text | Google Scholar
7. Jeong, HG, Kim, BJ, Kim, T, Kang, J, Kim, JY, Kim, J, et al. Classification of cardioembolic stroke based on a deep neural network using chest radiographs. EBioMedicine. (2021) 69:103466. doi: 10.1016/j.ebiom.2021.103466
Crossref Full Text | Google Scholar
8. Heo, JN, Yoon, JG, Park, H, Kim, YD, Nam, HS, and Heo, JH. Machine learning-based model for prediction of outcomes in acute stroke. Stroke. (2019) 50:1263–5. doi: 10.1161/STROKEAHA.118.024293
Crossref Full Text | Google Scholar
9. Ramos, LA, Van, OH, Hilbert, A, Olabarriaga, SD, Van Der, LA, Roos, YBWEM, et al. Combination of radiological and clinical baseline data for outcome prediction of patients with an acute ischemic stroke. Front Neurol. (2022) 13:809343. doi: 10.3389/fneur.2022.809343
Crossref Full Text | Google Scholar
10. Liu, Y, Yu, Y, Ouyang, J, Jiang, B, Yang, G, Ostmeier, S, et al. Functional outcome prediction in acute ischemic stroke using a fused imaging and clinical deep learning model. Stroke. (2023) 54:2316–27. doi: 10.1161/STROKEAHA.123.044072
Crossref Full Text | Google Scholar
11. Jo, H, Kim, C, Gwon, D, Lee, J, Lee, J, Park, KM, et al. Combining clinical and imaging data for predicting functional outcomes after acute ischemic stroke: an automated machine learning approach. Sci Rep. (2023) 13:16926. doi: 10.1038/s41598-023-44201-8
Crossref Full Text | Google Scholar
12. Hong, J, Yoon, S, Shim, KW, and Park, YR. Screening of moyamoya disease from retinal photographs: development and validation of deep learning algorithms. Stroke. (2024) 55:715–24. doi: 10.1161/STROKEAHA.123.044026
Crossref Full Text | Google Scholar
13. The National Institute of Neurological Disorders and Stroke rt-PA Stroke Study Group . Tissue plasminogen activator for acute ischemic stroke. N Engl J Med. (1995) 333:1581–8. doi: 10.1056/NEJM199512143332401
Crossref Full Text | Google Scholar
14. Goyal, M, Demchuk, AM, Menon, BK, Eesa, M, Rempel, JL, Thornton, J, et al. Randomized assessment of rapid endovascular treatment of ischemic stroke. N Engl J Med. (2015) 372:1019–30. doi: 10.1056/NEJMoa1414905
Crossref Full Text | Google Scholar
15. Campbell, BCV, Mitchell, PJ, Kleinig, TJ, Dewey, HM, Churilov, L, Yassi, N, et al. Endovascular therapy for ischemic stroke with perfusion-imaging selection. N Engl J Med. (2015) 372:1009–18. doi: 10.1056/NEJMoa1414792
Crossref Full Text | Google Scholar
16. Marder, VJ, Chute, DJ, Starkman, S, Abolian, AM, Kidwell, C, Liebeskind, D, et al. Analysis of thrombi retrieved from cerebral arteries of patients with acute ischemic stroke. Stroke. (2006) 37:2086–93. doi: 10.1161/01.STR.0000230307.03438.94
Crossref Full Text | Google Scholar
17. Aliena-Valero, A, Baixauli-Martín, J, Torregrosa, G, Tembl, JI, and Salom, JB. Clot composition analysis as a diagnostic tool to gain insight into ischemic stroke etiology: a systematic review. J Stroke. (2021) 23:327–42. doi: 10.5853/jos.2021.02306
Crossref Full Text | Google Scholar
18. Brinjikji, W, Nogueira, RG, Kvamme, P, Layton, KF, Almandoz, JED, Hanel, RA, et al. Association between clot composition and stroke origin in mechanical thrombectomy patients: analysis of the stroke thromboembolism registry of imaging and pathology. J Neurointerv Surg. (2021) 13:594–8. doi: 10.1136/neurintsurg-2020-017167
Crossref Full Text | Google Scholar
19. Dargazanli, C, Zub, E, Deverdun, J, Decourcelle, M, de Bock, F, Labreuche, J, et al. Machine learning analysis of the cerebrovascular thrombi proteome in human ischemic stroke: an exploratory study. Front Neurol. (2020) 11:575376. doi: 10.3389/fneur.2020.575376
Crossref Full Text | Google Scholar
20. Sgreccia, A, Duchmann, Z, Desilles, JP, Lapergue, B, Labreuche, J, Kyheng, M, et al. Association between acute ischemic stroke etiology and macroscopic aspect of retrieved clots: is a clot’s color a warning light for underlying pathologies? J Neurointerv Surg. (2019) 11:1197–200. doi: 10.1136/neurintsurg-2019-014905
Crossref Full Text | Google Scholar
21. Luo, W, Phung, D, Tran, T, Gupta, S, Rana, S, Karmakar, C, et al. Guidelines for developing and reporting machine learning predictive models in biomedical research: a multidisciplinary view. J Med Internet Res. (2016) 18:e323. doi: 10.2196/jmir.5870
留言 (0)