
記住我

To achieve successful communication, speakers must transform their communicative intentions into coherent utterances through a specific sequence of words. This process involves conceptualization, linguistic encoding (including grammatical and prosodic encoding), and articulation (Ferreira, 1993, 2010; Konopka and Kuchinsky, 2015; Levelt, 1989). Most models of language production assume that message planning and linguistic encoding proceed incrementally (Levelt, 1989). That is, speakers do not need to wait until planning is complete before moving on to the next stage, but only need to plan a fragment of the complete utterance before progressing to subsequent stages. This incremental approach allows speakers to initiate articulation before full planning, with the remaining aspects of the utterance being constructed “on-the-fly” after speech onset (e.g., Brown-Schmidt and Konopka, 2008; Konopka and Kuchinsky, 2015; Levelt, 1989; Smith and Wheeldon, 1999). While considerable research in language production has focused on incremental processing during conceptual and grammatical encoding (e.g., Garrett, 1980; Konopka and Meyer, 2014; Konopka and Kuchinsky, 2015), prosodic encoding remains less investigated. This study aims to explore the incremental processing in conceptualization and prosodic encoding during the production of sentences with focus accentuation. Before presenting our experiment, we review relevant theoretical and empirical studies concerning the incremental processing in conceptual and linguistic encoding as well as the relation between focus and accentuation during speech production.
Conceptualization, or message formulation involves converting a communicative intention into a preverbal semantic representation. This involves gathering information at the message-level, including details about the entities involved in an event, the relationships between these entities (i.e., the gist of event, for example, who-did-what-to-whom), and the overall type of message being conveyed. Linguistic encoding in language production involves both grammatical and prosodic encoding. Grammatical encoding concerns accessing lemmas and constructing of syntactic structure, while prosodic encoding entails generating prosodic constituents such as prosodic words, phonological phrases, and intonational phrases. This is followed by establishing a metrical grid based on the prosodic constituent structure (Ferreira, 1993; Levelt, 1989).
There are two predominant theoretical frameworks concerning the incrementality process about conceptualization and linguistic encoding in sentence production. The first framework, termed linear incrementality (e.g., Brown-Schmidt and Konopka, 2008; Ganushchak et al., 2017; Gleitman et al., 2007; Meyer and Meulen, 2000), assumes that speakers can prepare a sequence of small conceptual and linguistic increments without relying on a complete conceptual framework. Accordingly, the initial increment of conceptual and linguistic encoding may consist of only information pertinent to a single entity, typically the one mentioned first by speakers. In contrast, the second framework, termed hierarchical incrementality (e.g., Bock et al., 2004; Griffin and Bock, 2000; Hwang and Kaiser, 2014; Kuchinsky and Bock, 2010; Lee et al., 2013; Momma et al., 2016), assumes that speakers do not encode concepts and words individually; rather, they initially formulate the gist of an event and establish a conceptual framework during conceptualization. Subsequently, during linguistic encoding, they first construct a syntactic framework to organize the target sentence.
The majority of studies using eye movement technology have consistently shown that speakers preferentially encode the entity mentioned first in the speech, thus providing support for the linear incrementality hypothesis (Ganushchak et al., 2017; Gleitman et al., 2007; Griffin, 2001; Meyer and Meulen, 2000; Konopka and Meyer, 2014; Schlenter et al., 2022). Gleitman et al. (2007) used the attention capture paradigm to manipulate visual salience and found that the most visually salient character was consistently assigned to the initial position of the sentence. Crucially, speakers fixated on this character preferentially within 200 ms of scenario onset and maintained their fixation until speech onset. Similar findings were reported by Ganushchak et al. (2017), who instructed participants to construct active sentences (e.g., “The frog catches the fly.”) during a scenario description task. They manipulated the accessibility of agent and patient words by providing varying levels of semantic context information and related vocabulary. It was observed that speakers prioritized fixating on the agent very rapidly after the presentation of the picture (within 400 ms). Moreover, the availability of agent words was found to influence fixation patterns on the scenario after 400 ms, suggesting that speakers predominantly encode this character rather than formulating a comprehensive conceptual framework encompassing information about both agents and patients.
In contrast, several studies provide empirical support for hierarchical incrementality (e.g., Bock et al., 2004; Griffin and Bock, 2000; Hwang and Kaiser, 2014; Kuchinsky and Bock, 2010; Lee et al., 2013; Momma et al., 2016). Griffin and Bock (2000) conducted a study in which participants were presented with scenarios, and their eye movements were tracked while performing either a linguistic task (describing the scenario) or a non-linguistic task (detecting a patient). The findings revealed intriguing observations: within the initial 300 ms of scenario presentation, participants did not exhibit a fixation preference toward any specific entity, irrespective of the task. However, beyond this initial period, participants exhibited dictinct fixation patterns depending on the task at hand. In the scenario description task, participants predominantly fixated on the subject entity after the initial 300 ms, whereas in the patient detection task, their fixation was directed toward the patient entity. These findings suggest that speakers rapidly grasp the essence of an event, such as who performed an action on whom, and generate a conceptual framework within ~300 ms after scenario onset. Subsequently, they shift their gaze to the entity that is established as the appropriate starting point based on the conceptual framework, thus leading support to hierarchical incrementality during conceptualization.
Additionally, Do and Kaiser (2019) discovered evidence supporting hierarchical incrementality in linguistic encoding. In contrast to the approach taken by Ganushchak et al. (2017), who employed SVO (Subject-Verb-Object) sentences where the hierarchical syntactic structure and the surface linear word order of the utterance are isomorphic, Do and Kaiser (2019) utilized object questions in English to separate the syntactic subject from the linearly initial word. Participants were instructed to produce declarative sentences (e.g., “The nurses tickled the maids.”) and object questions in English (e.g., “Which maids did the nurses tickle?”), with a syntactic subject (i.e., the nurses) placed in the initial or medial position within the sentence. The findings revealed an initial preference for fixations to the subject region ~400 ms after scenario onset, despite the subject not being the linearly initial element in object questions. This suggests that speakers construct a syntactic frame and then assign a concept to serve as the structurally-initial element of the utterance. Notably, speakers shifted their fixation to the object relatively soon after fixating on the subject in object questions, indicating that linear and hierarchical incrementality are distinct yet closely coordinated facets of sentence encoding.
Indeed, studies examining the online processes of conceptual and linguistic encoding confirm that the incremental processing strategy at both levels may exhibit considerable variability, particularly in response to the ease of conceptual and linguistic encoding (Konopka and Meyer, 2014; Konopka and Kuchinsky, 2015; Konopka, 2012; Kuchinsky and Bock, 2010). Konopka and Meyer (2014), for instance, manipulated the ease of conceptual encoding through character codability (variations in speakers' noun selection) and event codability (variations in verb choice), while also manipulating the ease of linguistic encoding through lexical primes (words semantically or associatively related to a character) and structural primes (active and passive syntax) to investigate sentence production. Their findings indicated that speakers are inclined to encode individual message elements sequentially when one character is easy to identify or when the event is complex to comprehend. Conversely, they are more likely to prioritize encoding information about both characters when employing a more familiar syntactic structure or when the event is straightforward to encode. Similar findings were replicated in the study conducted by Konopka and Kuchinsky (2015), where they observed that speakers exhibited a more consistent allocation of attention to both characters during linguistic encoding in structurally primed sentences compared to unprimed ones. However, they also noted that the priming effects on eye movements were attenuated by conceptual familiarity. This suggests speakers are inclined to prepare larger message increments when the sentence structure is primed, albeit this tendency is constrained by message-level information. The variability in increment size observed during conceptual and linguistic encoding aligns with the claim that incrementality represents an adaptive feature of the production system, allowing speakers to employ diverse planning strategies (Jaeger, 2010).
It is noteworthy that while previous studies have predominantly focused on grammatical encoding in sentence production, empirical investigations into prosodic encoding have been relatively limited. Currently, research has begun to investigate the planning scope of phonological encoding, revealing that it may extend to the first prosodic word (Meyer, 1996; Schriefers, 1999; Jescheniak et al., 2003; Wheeldon and Lahiri, 1997). Phonological encoding includes not only prosodic encoding but also the retrieval of segmental information (Levelt, 1989). Meyer (1996) conducted a study wherein participants were presented with pairs of pictures described by noun phrases (e.g., “the arrow and the bag”) or sentences (e.g., “the arrow is next to the bag”), accompanied by an auditory distractor word phonologically related to either the first or second noun, or unrelated to both. The findings revealed that when the distractor word was phonologically related to the first noun, speech latency was shortened, whereas no such phonological facilitation was observed for the second noun. This suggests that prior to articulation, the form of the first noun is already selected, and the planning scope of phonological encoding may extend to the first prosodic word. A similar conclusion was drawn in the study of Wheeldon and Lahiri (1997). They initially presented participants with a visually displayed noun phrase or adjective phrase, followed by an auditorily presented a question related to that phrase. Participants were then instructed to formulate a sentence in response to the question using the words they had seen as soon as possible. The results revealed that speech latency was contingent upon the complexity of the first prosodic word.
The conventional perspective once held that syntactic structure directly dictates the prosodic features of a sentence (Cooper and Danly, 1981; Klatt, 1975; Selkirk, 1984). However, more recent evidence suggests the presence of prosodic representations that are relatively autonomous from syntactic structure and directly shape prosodic features (e.g., Ferreira, 1993; Jun and Bishop, 2015; Jungers et al., 2016; Tooley et al., 2018; Wheeldon and Lahiri, 1997; Zhang and Zhang, 2019). These studies have revealed that prosodic structures do not align perfectly with syntactic structure (Ferreira, 1993; Gee and Grosjean, 1983; Miyamoto and Johnson, 2002). Additionally, researchers also observed prosodic features such as speech rate, prosodic boundaries, and rhythm, which exhibit priming effects, suggesting the presence of independent representations for these prosodic features (Jun and Bishop, 2015; Jungers et al., 2002; Jungers and Hupp, 2009; Jungers et al., 2016; Tooley et al., 2014, 2018; Zhang and Zhang, 2019). Therefore, it is necessary to investigate the incremental processing strategy in prosodic encoding.
We hypothesize that the incremental processing strategy of prosodic encoding could follow either linear incrementality or hierarchical incrementality. Under the framework of linear incrementality, speakers generate smaller units (e.g., prosodic words) sequentially in the order of mention. In contrast, under the framework of hierarchical incrementality, speakers construct a prosodic frame at the sentence level first, which then guides subsequent production.
The reasons for proposing these two hypotheses are as follows: First, prosody is closely linked to syntax (Cooper and Danly, 1981; Klatt, 1975; Selkirk, 1984) and may directly connect to message-level representations (Levelt, 1989; Tooley et al., 2018). Previous studies have demonstrated that conceptualization and linguistic encoding in sentence production follow either linear or hierarchical incrementality. Thus, it is plausible that prosodic encoding might share similar patterns.
Second, evidence from prior studies supports these two potential strategies. On the one hand, word-level prosodic encoding research supports linear incrementality. That is, speakers access stress on the first syllable before the second (Schiller et al., 2004, 2006; Schiller, 2006). Stress refers to the relative prosodic prominence of one syllable compared to others (Cutler, 1984). Schiller et al. (2004) found that words with initial stress are produced faster than those with final stress. This pattern was further corroborated by lexical stress monitoring tasks and go/no-go decision tasks (Schiller et al., 2006; Schiller, 2006). Additionally, studies have indicated that the planning scope of phonological encoding may extend to the first prosodic word (Meyer, 1996; Jescheniak et al., 2003). These findings suggest that prosodic encoding may align with linear incrementality.
On the other hand, some research findings suggest that prosodic encoding might follow a hierarchical incremental pattern. Speech error studies have shown that the overall accentuation pattern remains stable even when words are swapped during phrase production (Garrett, 1975, 1976). Similarly, acoustic analyses of sentence recall tasks found that while the duration of individual words varied, the overall rhythmic structure of the sentence remained consistent (Ferreira, 1993). Additionally, priming studies have revealed prosodic priming effects at both the word and sentence levels, such as stress, speech rate, prosodic boundaries, and rhythm (e.g., Jungers et al., 2016; Tooley et al., 2014, 2018; Yu et al., 2024; Zhang and Zhang, 2019), supporting the existence of prosodic frames at multiple levels.
In daily communication, speakers often use accentuation, a prosodic feature, to highlight important information (referred to as focus) within an utterance, thereby enhancing the accuracy and effectiveness of information delivery. Focus typically pertains to new or contrasting information at the message-level (Chomsky, 1971; Gundel et al., 1993). Although our current understanding of the role of focus during real-time language production is somewhat limited, it is generally believed that focus is specified in conceptualization (Ferreira, 1993; Ganushchak et al., 2014; Levelt, 1989; Tooley et al., 2018). Previous studies have primarily employed question–answer pairs to establish a focus context, where the interrogative words and key answers corresponding to the questions are focus information (e.g., Chen et al., 2015; Dimitrova et al., 2012; Do and Kaiser, 2019; Ganushchak et al., 2014; Magne et al., 2005).
Studies have shown that focus may influence sentence production. Ganushchak et al. (2014) used the visual world eye-tracking paradigm to investigate the fixation patterns during the production of declarative sentences under contexts with varying focus positions in Dutch and Chinese. They used questions to create a focus context, and after hearing a question, participants were instructed to answer questions with complete declaratives according to scenarios. This is exemplified in the following examples:
Neutral-focused: “What is happening here?” (in Dutch, “Wat gebeurt hier?”; in Chinese, “发生了什么?”).
Subject-focused: “Who is stopping the truck?” (in Dutch, “Wat stopt de politieman?”; in Chinese, “谁在停止卡车?”).
Object-focused: “What is the policeman stopping?” (in Dutch, “Wie stopt de vrachtauto?”; in Chinese, “警察在停止什么?”).
Answer: “The policeman is stopping the truck.” (in Dutch, “De politieman laat een vrachtauto stoppen.”; in Chinese, “警察在停止卡车。”).
The findings revealed that in both languages, after 400 ms of scenarios onset, speakers exhibited increased fixation on the focus information, and this fixation lasted longer when producing subject-focused or object-focused sentence compared to neutral-focused ones. This suggests that the focus context influences subsequent sentence production, facilitating speakers in rapidly and concurrently encoding focus information in various positions. In contrast, Do and Kaiser (2019) did not find evidence for the role of focus in speech production. In their study, participants were first provided with a letter cue and then asked to produce a sentence in Chinese based on a given scenario. If the cue was “s,” participants would describe the scenario with a declarative sentence (e.g., “The chefs shot the nurses.”), while a “q” cue would prompt the production of an object question (e.g., “The chefs shot which nurses?”). There is no significant difference in fixation patterns during the production of declarative sentences and object questions. The divergent findings might stem from differences in processing mechanisms and processing costs between questions and declaratives (Aoshima et al., 2004; Sussman and Sedivy, 2003), as proposed by Do and Kaiser (2019). Unlike the production of questions in Do and Kaiser (2019), the production of declarative sentences in Ganushchak et al. (2014) may also involve comprehending (or recalling) the question being answered. Additionally, the processing cost for declarative sentence production in Ganushchak et al. (2014) is likely lower than for question production in Do and Kaiser (2019), as participants in the former had already been provided with most of the relevant information in the question.
Focus is intricately linked to accentuation, a term that broadly describes the presence of prosodic prominence on a specific element within a sentence (Li et al., 2018). As a crucial prosodic feature, accentuation primarily undergoes processing during prosodic encoding (Ferreira, 1993; Levelt, 1989). In Chinese, as a tonal language, accentuation is realized through pitch maximum raising, duration lengthening or intensity increasing (Li et al., 2008; Li and Yang, 2013; Liu and Xu, 2005; Xu, 1999). Numerous studies have found that focus is often marked with accentuation, while non-focus elements tend to be deaccented, as evidenced through phonetic analysis of spoken dialogues (Chen et al., 2015; Eady and Cooper, 1986; Patil et al., 2008; Pierrehumbert, 1993; Xu et al., 2012). Consequently, focus can be prosodically distinguished by accentuation across languages, including German (Burght et al., 2021), Mandarin (Chen et al., 2015), Dutch (Dimitrova et al., 2012), English (Dahan et al., 2002), French (Magne et al., 2005), and Japanese (Ito and Garnsey, 2004). Tooley et al. (2018) employed a priming paradigm to investigate whether accentuation operates an independent representation. In their experiment, participants were presented with a prime sentence featuring a specific accentuation pattern auditorily, followed by the visually presented target sentences. Subsequently, the target sentence disappeared, and participants were asked to recall it. Interestingly, the results indicated that the accentuation of prime sentences did not affect target sentences. Tooley et al. (2018) proposed that despite the absence of an accentuation priming effect, accentuation is widely assumed to be independently represented (Gussenhoven, 1983; Selkirk, 1995). They suggested that the absence of a priming effect could be attributed to accentuation encoding having direct communication with message-level representations, such as focus. Consequently, any priming effect might not be robust enough to survive the linguistic planning for subsequent target sentences. Notably, focus and accentuation are not always strictly on a one-to-one basis. The determination of focus position is constrained by contextual factors, but once the focus position is determined, the distribution of accentuation is constrained by the specific structural rules of the language (Gussenhoven, 1983; Ladd, 2008; Selkirk, 1995).
Although focus with accentuation is a prevalent part of naturalistic communication, it has received limited attention in the realm of real-time language production, leaving us uncertain about how to process focus and accentuation during speech production. Levelt (1989) proposed that speakers mark focus during the conceptualization, with this marking subsequently transforming into accentuation during prosodic encoding, potentially influencing the intonation of the eventual utterance. Furthermore, he posited that accentuation can proceed incrementally from left to right. However, the question of how focus information is processed remain unspecified, and these views lack empirical support until now. According to the principle of incrementality for sentence production, we hypothesize that the process of conceptualization and prosodic encoding generally adheres to this incremental principle.
According to the framework of linear incrementality, we assume that speakers can prepare a sequence of small conceptual and accentuation pattern increments. That is, speakers sequentially encode the conceptual and accentuation features of a single entity, following the order in which entities are expressed. Consequently, speakers are expected to prioritize processing the earlier mentioned focus and accentuation. According to the framework of hierarchical incrementality, we assume that speakers generate an overall conceptual framework along with a corresponding sentence-level accentuation pattern. Therefore, speakers should simultaneously process focus and accentuation regardless of its position in the mention sequence. These two frameworks primarily diverge in their views on the increment size of focus and accentuation processing. The former suggests that the increment size of focus and accentuation processing is small, such as the prosodic word, while the latter proposes that it extends to the overall sentence.
Given that focus can be specified during conceptualization and accentuation is processed during prosodic encoding (Ferreira, 1993; Ganushchak et al., 2014; Levelt, 1989; Tooley et al., 2018), we manipulated the position of focus and accentuation to investigate the interplay between conceptualization and prosodic encoding in sentence production. To investigate the incremental framework (linear incrementality vs. hierarchical incrementality) employed in focus and accentuation processing, we compared speech latencies and fixation patterns in sentences with different positions of accentuation. Previous studies typically employed question–answer pairs to induce focus accentuation (Chen et al., 2015; Xu et al., 2012). However, and this method may introduce a preview effect, potentially confounding the results of speech latencies (Allum and Wheeldon, 2009). This confusion is evident in the study of Ganushchak et al. (2014), which reported that speech latency in the medial focus is shorter than that in the initial focus. To address this, we employed the visual world paradigm, allowing speakers to spontaneously produce sentences with varying positions of focus with accentuation without the preview of information (see method section for further details) in the current study.
In addition, we used eye movement technology to capture fixation information on different entities displayed simultaneously on the same screen. This allowed us to examine the time-course of speech planning and assess how focus with accentuation at different positions affects the production of target sentences. More importantly, we aimed to distinguish between conceptualization and prosodic encoding based on the time course. The early time window (within about 400 ms) after the scenario onset corresponds to conceptualization, whereas the later time window (about 400 ms to speech onset) encompasses linguistic encoding, including grammatical and prosodic encoding (Ganushchak et al., 2014; Griffin and Bock, 2000; Schlenter et al., 2022; van de Velde et al., 2014; Konopka and Meyer, 2014). Given the lack of clarity regarding the timing of various processes involved in sentence production research, we adopted a data-driven approach to select time windows for analysis, aiming to provide more precise timing data.
Sentences with identical structures but differing accentuation positions (e.g., “The turtle is above the frog, not the peacock”; “The turtle is above the frog, not the peacock.” The underlined is the focus with accentuation), provide an ideal experimental setup for examining the mechanism employed in focus and accentuation processing. According to the linear incrementality, speakers are expected to prioritize encoding focus and accentuation occurring earlier in the mentioned positions, whereas the hierarchical incrementality predicts that speakers should simultaneously encode focus and accentuation in different mentioned positions.
We hypothesized that if the production of focus accentuation sentences follows linear incrementality, the speech latencies for sentences with initial focus accentuation will be significantly shorter than those with medial focus accentuation. Furthermore, participants in both conditions are expected to initially fixate on the information at the beginning of the sentence, followed by fixation on the information in the middle of the sentence. More importantly, we expect that the effect of initial focus accentuation will occur earlier in time compared to the effect of medial focus accentuation effect. At both positions, the presence of focus accentuation effect is expected to result in a greater proportion of fixation on the accented pictures compared to the deaccented pictures.
If the production of focus accentuation sentences follows hierarchical incrementality, we expect that there will be no difference in speech latencies between sentences with initial and medial focus accentuation. Furthermore, participants in both conditions are expected to initially exhibit no clear fixation preference toward any entity in scenario after its presentation, followed by rapidly fixate on the accented pictures. Critically, there should be no differences in the timing of the focus accentuation effect between initial and medial positions.
2 Method 2.1 ParticipantsThirty-eight native Mandarin speakers (15 males, mean age = 23.50 ± 2.61, range = 19–29 years) with normal or corrected-to-normal vision participated in the experiment, and they were paid for their participation. We used the software G*Power 3.1 (Faul et al., 2009) to conduct the power analysis, which revealed that a sample size of 34 participants would be required to detect an effect size (dz) of 0.5 with an α of 0.05 and power of 0.80. Ethics approval for the study was obtained from the ethics review board of Department of Psychology, Renmin University of China (the approval number 22-025). All participants gave written informed consent before the experimental session and received payment for their participation.
2.2 MaterialsOne hundred and twenty-nine black-and-white pictures with disyllabic names were selected from the database established by Zhang and Yang (2003). Among them, 120 pictures were used for the experiment and nine for practice sessions. The target trials comprised two types of scenarios, each consisting of four pictures. Participants were asked to describe the scenarios using a fixed syntactic structure, which was a vague ellipsis sentence (i.e., the target sentence) with two potential interpretations when presented visually. This is illustrated in the following examples:
Target sentence: “乌龟在青蛙的上面,不是孔雀。” (in English, “The turtle is above the frog, not the peacock.”).
One interpretation: “乌龟在青蛙的上面,不是孔雀在青蛙的上面。” (in English, “The turtle is above the frog, not the peacock is above the frog.”).
The other interpretation: “乌龟在青蛙的上面,不是乌龟在孔雀的上面。” (in English, “The turtle is above the frog, not the turtle is above the peacock.”).
In both interpretations, the first clause serves as the positive statement (e.g., “乌龟在青蛙的上面”, in English: “The turtle is above the frog”), and the second clause functions at the negative statement (e.g., “不是孔雀在青蛙的上面,” in English: “not the peacock is above the frog”). The key distinction between the positive and negative clauses lies in the focus (e.g., “乌龟,” in English: “the turtle”). Each type of scenarios corresponds to one interpretation, corresponding to initial and medial focus, respectively (see Tables 1a, b). Participants would accentuate the focus in the target sentence to accurately describe the scenario, which only represents one interpretation (Burght et al., 2021; Winkler, 2019). There are two positions of focus with accentuation (initial vs. medial, hereinafter “initial focus accentuation” and “medial focus accentuation” respectively).
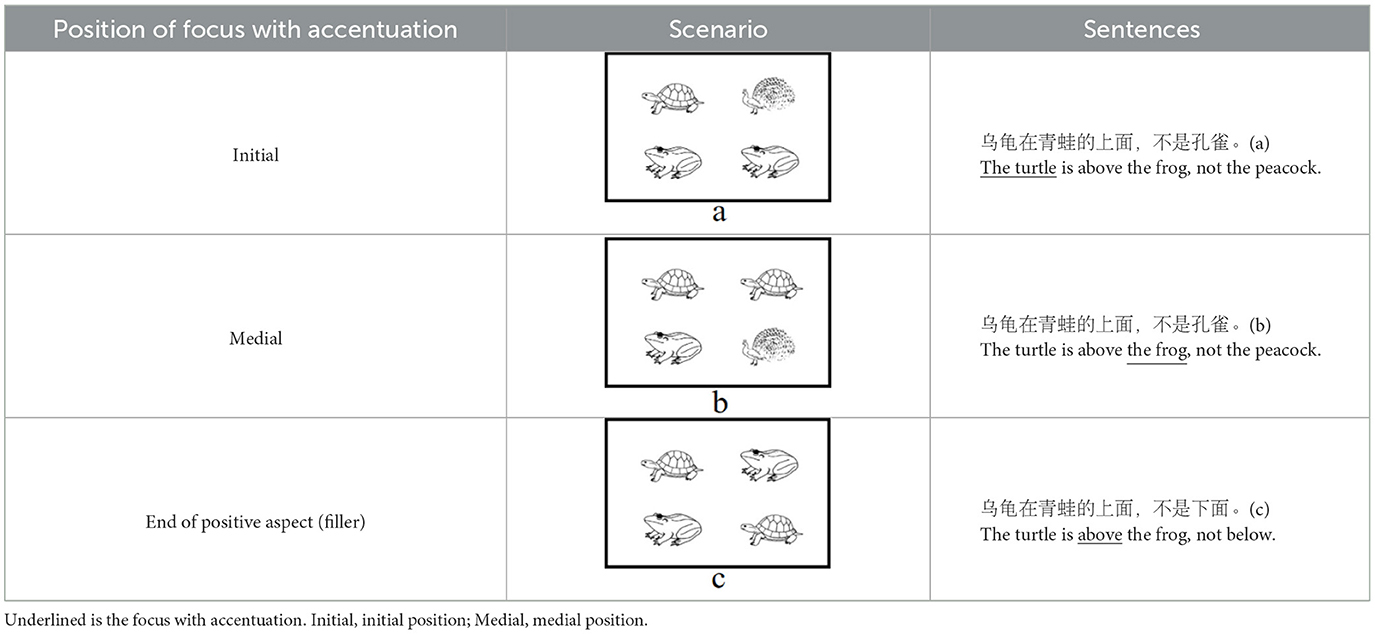
Table 1. Example of three type of scenarios.
The left and right parts of each scenario can represent the positive and negative aspects of the sentence. Prior to each block, participants will receive information regarding the position of the positive aspect (left or right) within the scenarios and the orientation of the description (“above” or “below”) in the target sentence. In Table 1, the positive aspect in all scenarios was positioned on the left and the description orientation was “above.” Participants used the same sentence to describe scenarios a or b, albeit with different positions of focus with accentuation. The sentence describing scenario a is “乌龟在青蛙的上面,不是孔雀” (in English: “The turtle is above the frog, not the peacock,” featuring initial focus accentuation. The underlined is the focus with accentuation). This sentence conveys “the turtle is above the frog, not the peacock is above the frog.” The sentence describing scenario b is “乌龟在青蛙的上面,不是孔雀” (in English: “The turtle is above the frog, not the peacock.”), with medial focus accentuation, conveying “the turtle is above the frog, not the turtle is above the peacock.”
For filler trials, in order to prevent participants from anticipating only two positions of focus with accentuation (initial, medial), a third type of scenario was introduced (see Table 1c). Participants described scenario c using the sentence “乌龟在青蛙的上面,不是下面” (in English: “The turtle is above the frog, not below”), with focus accentuation at the final position of the positive aspect.
Among the 120 pictures, 24 were of animals, while the remaining 96 depicted non-animal objects, including artifacts, body organ, natural phenomena and foods. A scenario consists of four object pictures, and two of them are identical. Thus, 120 experimental pictures were divided into 40 sets. To prevent potential confounding due to differences in animacy among pictures, the three pictures within a scenario are selected exclusively from either animal or non-animal pictures. To ensure consistency across experimental conditions and avoid potential differences arising from varying experimental materials, both initial and medial accentuation conditions utilized the same set of pictures. As shown in scenarios a and b, the combination of “turtle,” “frog” and “peacock” appeared in both conditions. Additionally, to avoid the potential confounding stemming from differences in semantic categories between accented and deaccented pictures within a sentence, we interchanged the pictures in the positive aspect of a set to generate new scenarios. Notably, the tones of the keywords (i.e., the picture names in the positive aspect) within each set were not entirely uniform. The procedure described above ensured that the tones of the keywords at critical positions (i.e., initial and medial) were evenly distributed across conditions, thereby reducing the impact of tone on the results. The arrangement of three pictures within each set generated 6 scenarios, including 2 fillers and 4 experimental trials. With a total of 40 sets employed in the current study, the overall number scenarios amounted to 240. Furthermore, the positions of accented and deaccented pictures on the screen were evenly distributed, ensuring an equal frequency of appearances across four screen locations.
2.3 DesignThe experiment was a single factor design with two levels (position of focus with accentuation: initial and medial focus accentuation). Each level comprised of 80 trials, resulting in 160 target trials. The total experiment consisted of 240 trials, including 160 targets and 80 fillers. The trials were subdivided into 8 blocks, with each containing 30 trials: 20 targets and 10 fillers. Within each block, the position of the positive aspect and the description orientation were consistent. Across the blocks, two versions of the experiment were administered: In the first version, the position of positive aspect alternated between the left and right sides, and the description orientation followed a balanced “ABBABAAB” pattern (where A represented “above” and B represented “below”). In the second version, the position of positive aspect was consistent with s that of version 1, but the description direction was reversed. Each participant was assigned only one version of the experiment. A break was provided between two blocks to ensure participant comfort and to minimize fatigue.
2.4 Procedures and apparatusBefore the main experiment, participants were instructed to familiarize themselves with all pictures and associated names by viewing them on a computer screen. Following this, participants underwent the practice trials for familiarizing themselves with experimental procedures. They were then asked to comfortably position their heads on the bracket, with the task involving describing scenarios using fixed ellipsis sentence. The stimuli were presented on a 19-inch DELL monitor with a resolution of 1920 × 1,080 pixels and a refresh rate of 60 Hz). Participants were seated 70 cm away from the monitor. Speech responses were recorded via a microphone connected to the YAMAHA Steinberg CI1 (Germany). Presentation of stimulus presentation was managed using Experiment Builder 2.3.1 software. Eye movements were tracked using an Eyelink Portable Duo eye tracker (SR Research, Canada) with a sampling rate of 1,000 Hz.
To improve the probability of participants accurately accentuating focus information, they were informed beforehand that their produced sentences would be recorded and played to others, who were required to select the scenario seen by participants among multiple scenarios. Prior to each block, the eye tracker was calibrated to the screen using a built-in 9-point calibration protocol. The eye tracker was recalibrated when the calibration accuracy exceeded a mean threshold of 0.5° and a maximum threshold of 1° visual angle. Subsequently, the instruction regarding the position of positive aspect in scenarios and the describe orientation were presented in the middle of the screen. The experimental session proceeded until participants could accurately accentuate the focus.
During both the practice and experimental sessions, each trial involved the following sequences. Initially, a drift calibration to the center (black dots located at 960, 540) was presented, which was followed by the target scenario with each picture having a resolution of 200 × 200 pixels. The upper left picture was positioned at 560, 300, the upper right picture at 1,360, 300, the lower left picture at 560, 780, and the lower right picture at 1,360, 780. Participants were asked to describe the scenarios as accurately as possible. The scenario remained on the computer screen while participants were speaking. However, if participants did not utter any speech within 10 s after the scenario onset, it would disappear automatically. Participants were then requited to press the space bar to indicate that they had finished speaking. The next trial was started after a 1,000 ms blank screen (see Figure 1).
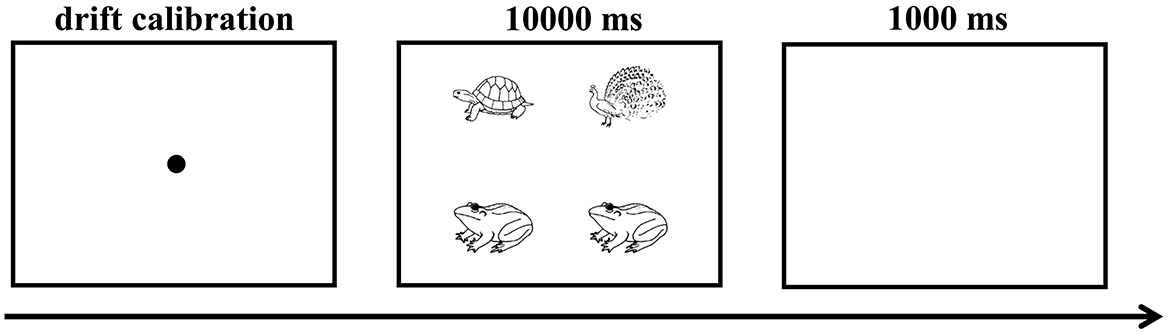
Figure 1. Visualization of the experimental trial.
3 ResultsAll incorrect (where participants named pictures incorrectly), disfluent responses and data beyond three standard deviations of the mean value in the speech latency (5.28% of original data) were excluded from the acoustic, speech latency, and the eye-tracking analyses.
3.1 Acoustic analyses of accentuationWe conducted acoustic analyses to confirm that participants spontaneously accented the focus. Praat software was used to segment the sentences generated by each subject into seven segments. Below is an example illustrating the segmentation, with the symbol | indicating the position of audio segmentation:
乌龟|在|青蛙|的|上面|,|不是|孔雀。
(In English: The turtle | is | above | the frog |, | not | the peacock.)
(Pinyin: Wu1gui1 | zai4 | qing1wa1 | de | shang4mian4 |, | bu2shi4 | kong2que4.)
The script developed by Xu (1999) was used to extract the duration (in milliseconds), maximum pitch (in hertz), and mean intensity (in decibels) for each audio segment. With the exception of fillers, each acoustic parameter of the focused segment was compared with other non-focused segments. When a spoken sentence where the acoustic parameters of the intended focus segment were significantly higher than those of the other six segments, indicating that the focus segment was accented successfully. The average proportion of such trials in all participants was 92.00% (SD = 7.92%), indicating that the participants spontaneously accented the focus in most trials. Paired sample t-tests were performed on the acoustic data from correctly accentuated trials, comparing the focused segments to non-focused segments. As the number of syllables varied across segments, duration analysis was performed on segments with equal syllable counts (i.e., segments 1, 3, 5, 6, and 7). Results showed that the duration, maximum pitch, and mean intensity of the focused segments were significantly greater than those of the other segments (ps < 0.001) (see Table 2), indicating that participants accented the focus as expected. The results of the acoustic parameter are illustrated in Figure 2.
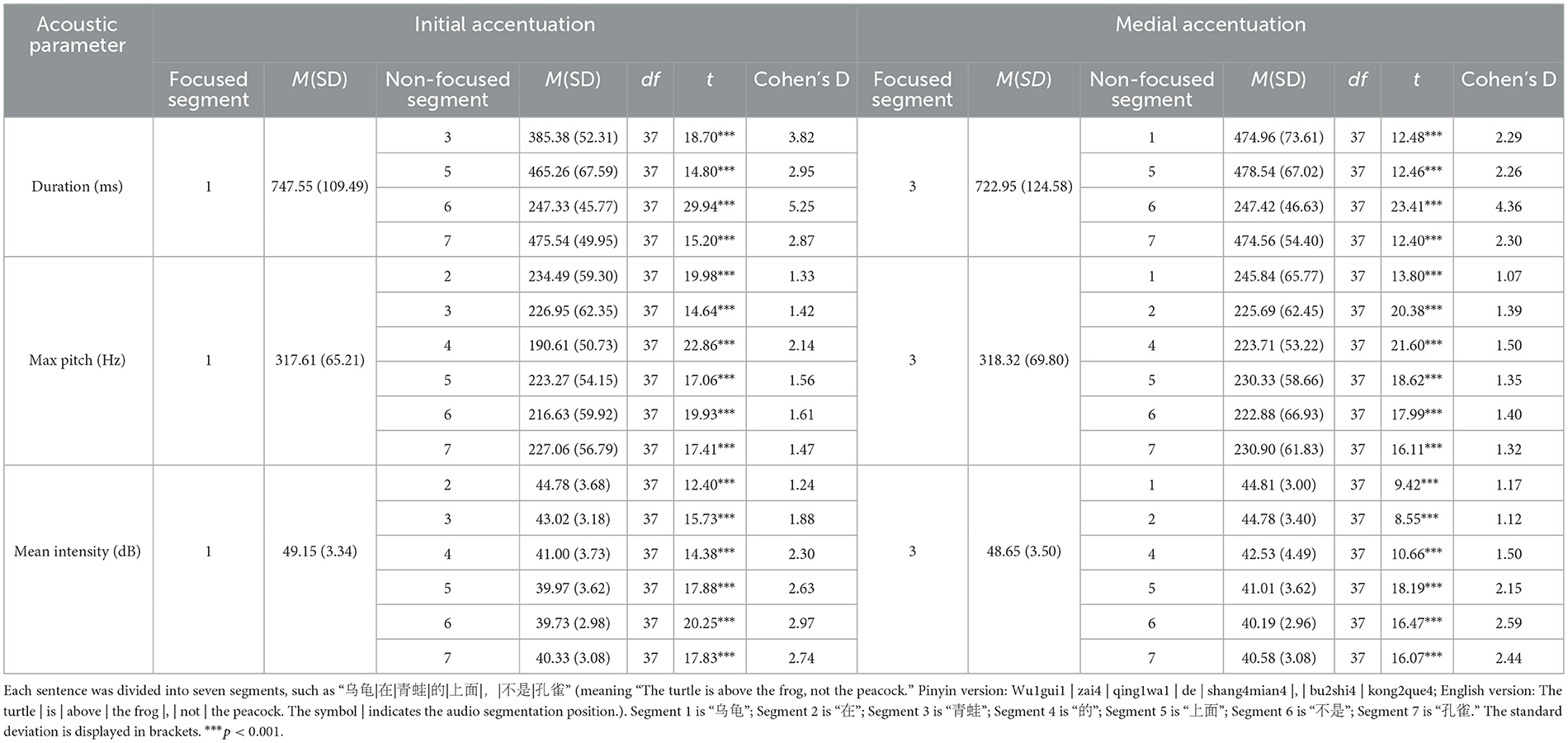
Table 2. Acoustic parameters and t-test results for the focused and non-focused segments in sentences with initial and medial focus.

Figure 2. Mean measurements of the (A) duration, (B) max pitch, and (C) mean intensity of each sentence segment, broken down by positions of focus with accentuation. The abscissa is the segment number. For example, in “乌龟|在|青蛙|的|上面|, |不是|孔雀”, segment 1 is “乌龟”, segment 2 is “在”, segment 3 is “青蛙”, segment 4 is “的”, segment 5 is “上面”, segment 6 is “不是”, segment 7 is “孔雀”. Note that only durations of segment 1, 3, 5, 6, and 7, which have the same number of syllables, were compared.
3.2 Speech latenciesSpeech latencies refer to the duration between the onset of scenario presentation and when participants start speaking. Figure 3 shows the latencies of spoken sentences with two positions of focus with accentuation (initial vs. medial). These speech latencies were analyzed using a linear mixed-effects model (LMM) analysis with the package lmerTest (Kuznetsova et al., 2017) in R (version 4.1.2). We initially constructed a model including position of focus with accentuation as a fixed effect, picture position as a covariate, and random intercepts for participants and items with by-participant as well as by-item random slopes for position of focus with accentuation (Baayen et al., 2008). However, this fully specified random effects structure failed to converge, we removed random slopes for items, given that in researcher-designed experiments, the variance for items typically tends to be smaller than that for participants (Segaert et al., 2016), leading to convergence. The best-fitting model included position of focus with accentuation as a fixed effect, picture position as a covariate, random intercepts for participants and items, and by-participant random slopes for position of focus with accentuation. Result showed that speech latencies in sentences with medial focus accentuation were significantly longer than those in sentences with initial focus accentuation (β = 206.38, p = 0.001). To assess the reliability of the main effect of position of focus with accentuation, we performed a Bayesian factor analysis using the lmBF program from the BayesFactor package (Morey et al., 2022) in R software, and the results revealed that the Bayes factor of BF10 was 79.60, providing a robust support for the main effect of position of focus accentuation (Jeffreys, 1961) (see Figure 3 and Table 3).
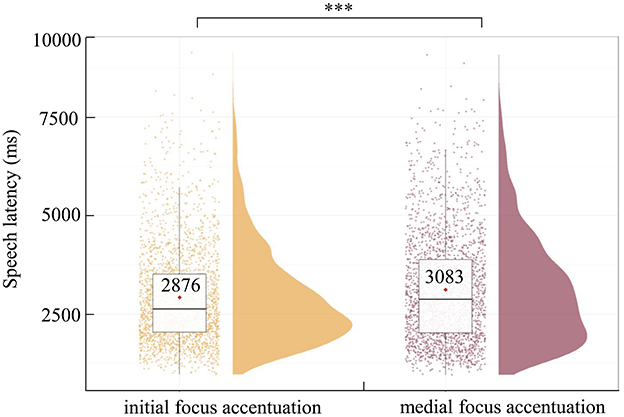
Figure 3. Speech latencies in sentence with initial (left) and medial (right) focus accentuation. The thin horizontal black line represents the median. The violin plot outline shows the density of data points for different dependent variables, and the boxplot shows the interquartile range with the 95% confidence interval represented by the thin vertical black line. The red diamonds in the boxplot denote the mean per condition, above which is written the mean value. The full dots represent individual data points. ***p < 0.001.
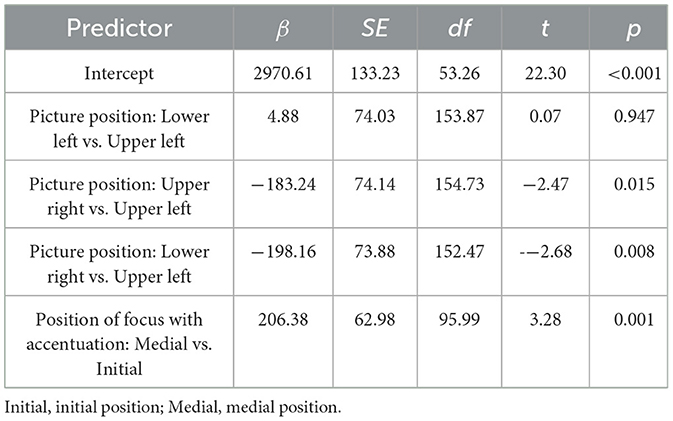
Table 3. Fixed effects of a linear mixed effects model with speech latencies as the dependent variable.
3.3 Proportion of fixation duration before articulationProportion of fixation duration refers to the ratio of total fixation time for a specific ROI to the total fixation time within the period of interest. In each scenario, the positive aspect consisted of two ROIs: one defined as the accented picture, and the other as the deaccented picture. The period on interest spanned from the onset of the scenario to the onset of speech. To compare the accented and deaccented segments during the interested period, trials where participants fixated solely on one picture were excluded from all analyses. Among the 38 participants, the percentage of trials wherein only one picture was fixated upon before articulation ranged from a minimum of 0.00% and a maximum of 33.13% (M = 9.13%, SD = 8.19%). There were 2,406 trials involving sentences with initial focus accentuation and 2,386 trials involving sentences with medial focus accentuation.
To investigate the presence of a focus accentuation effect in different position, we compared the proportion of fixation duration on accented and deaccented picture within the same sentence positions (see Figure 4). Similar to analyses conducted by Ganushchak et al. (2014, 2017), we transformed the single factor design with two levels (position of focus with accentuation: initial and medial focus accentuation) into a 2 × 2 design, incorporating word position (initial, medial) and accented state (accented, deaccented) as factors for LMM analysis. Fixed effects included accented state (accented, deaccented), word position (initial, medial), and their interaction. The picture position was added as a covariate, and random effects included random intercepts for participants and items, by-participant as well as by-item random slopes for accented state, word position, and their interaction. When the model did not converge with the maximal random effects structure, we simplified the random slopes, first removing the interactions and then removing the main effects in the order of least variance explained until the model converged (Barr et al., 2013).
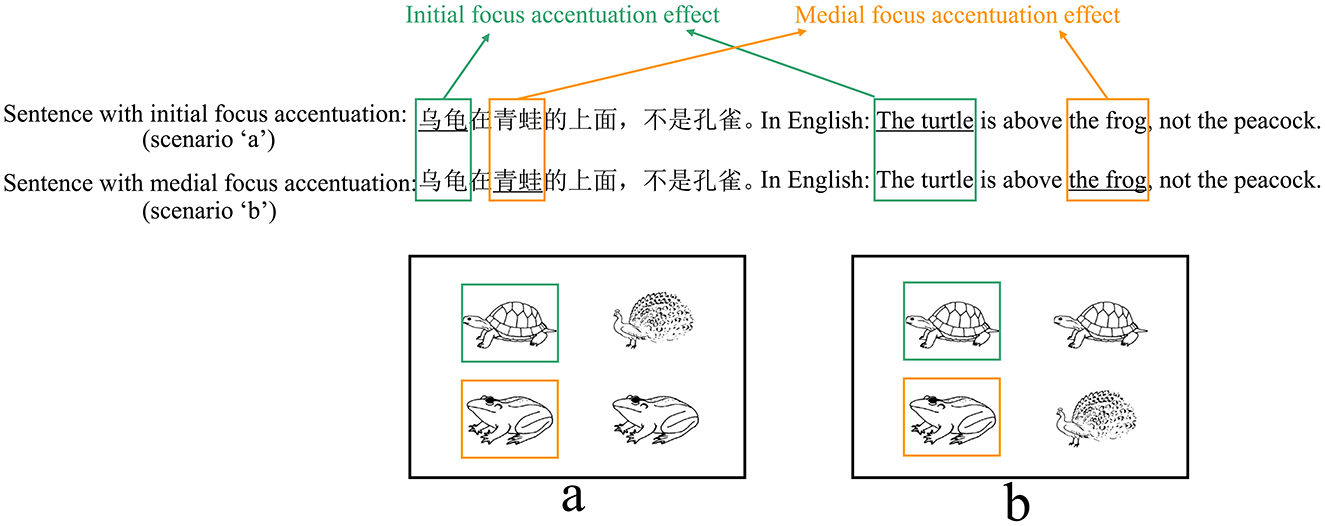
Figure 4. Focus accentuation effect at initial and medial position in eye movement analysis. The positive part in all scenarios were on the left and the orientation of description were “above.” Underlined is the focus with accentuation. Green for initial focus accentuation effect. Yellow for medial focus accentuation effect.
The best-fitting model included accented state, word position, and their interaction as fixed effects, the picture position as a covariate. Random intercepts for participants and items, by-participant random slopes for accented state, word position, and their interaction, as well as by-item random slopes for accented state were included as random effects. The best fitting model did not differ significantly from the full model (full model: Akaike information criterion [AIC] = −12013, Bayesian information criterion [BIC] = −11812; best-fitting model: AIC = −12019, BIC = −11869, p = 0.343). The results showed an interaction between accented state and word position is significant (β = −0.04, p < 0.001). Further simple effects analysis showed that in two positions, the proportion of fixation duration on accented pictures was significantly higher than that on deaccented pictures (initial position: β = 0.09, p < 0.001; medial position: β = 0.13, p < 0.001) (see Table 4 and Figure 5). To assess the reliability of this interaction, we performed a Bayesian factor analysis, and the results showed that the Bayes factor of BF10 was 806.74, providing an extremely robust support for the interaction.
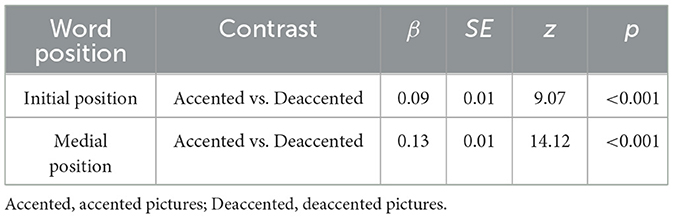
Table 4. Simple effects of the interaction between accented state and word position with the proportion of fixation duration as the dependent variable before articulation.
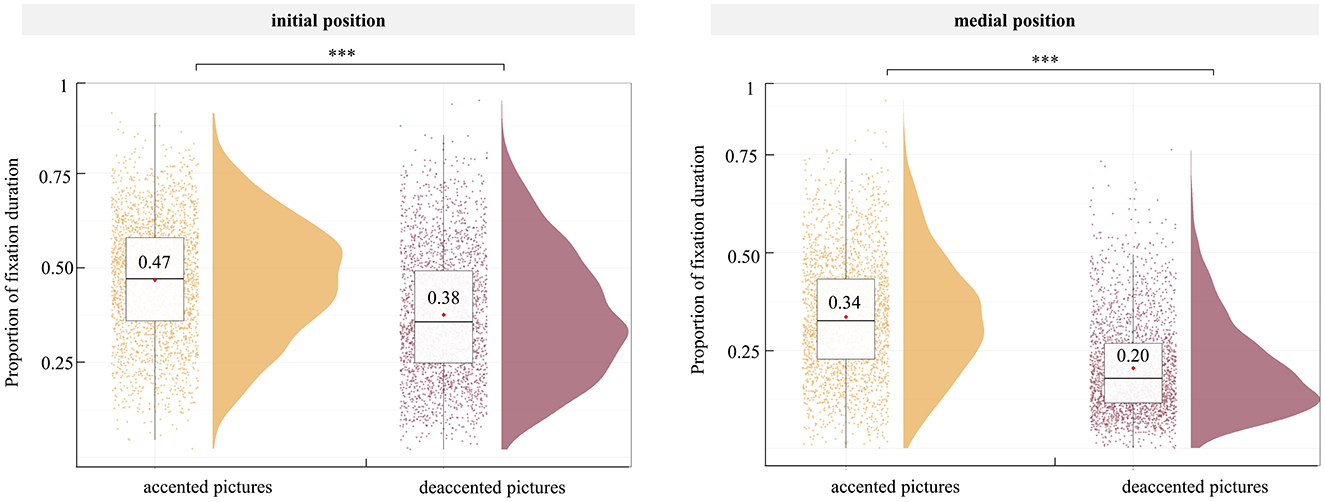
Figure 5. Proportion of fixation duration in sentence with initial (left) and medial (right) pos
留言 (0)