
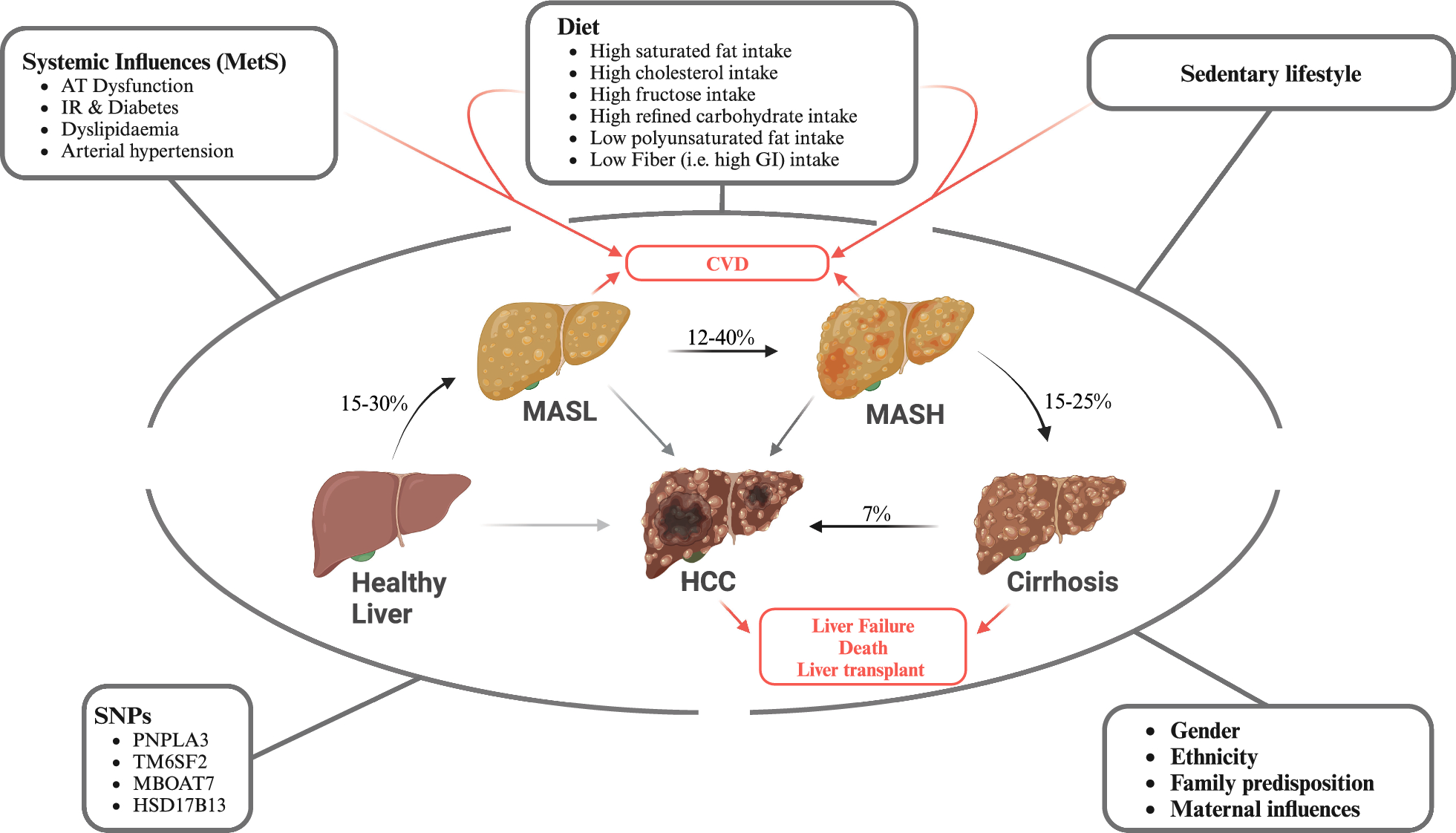
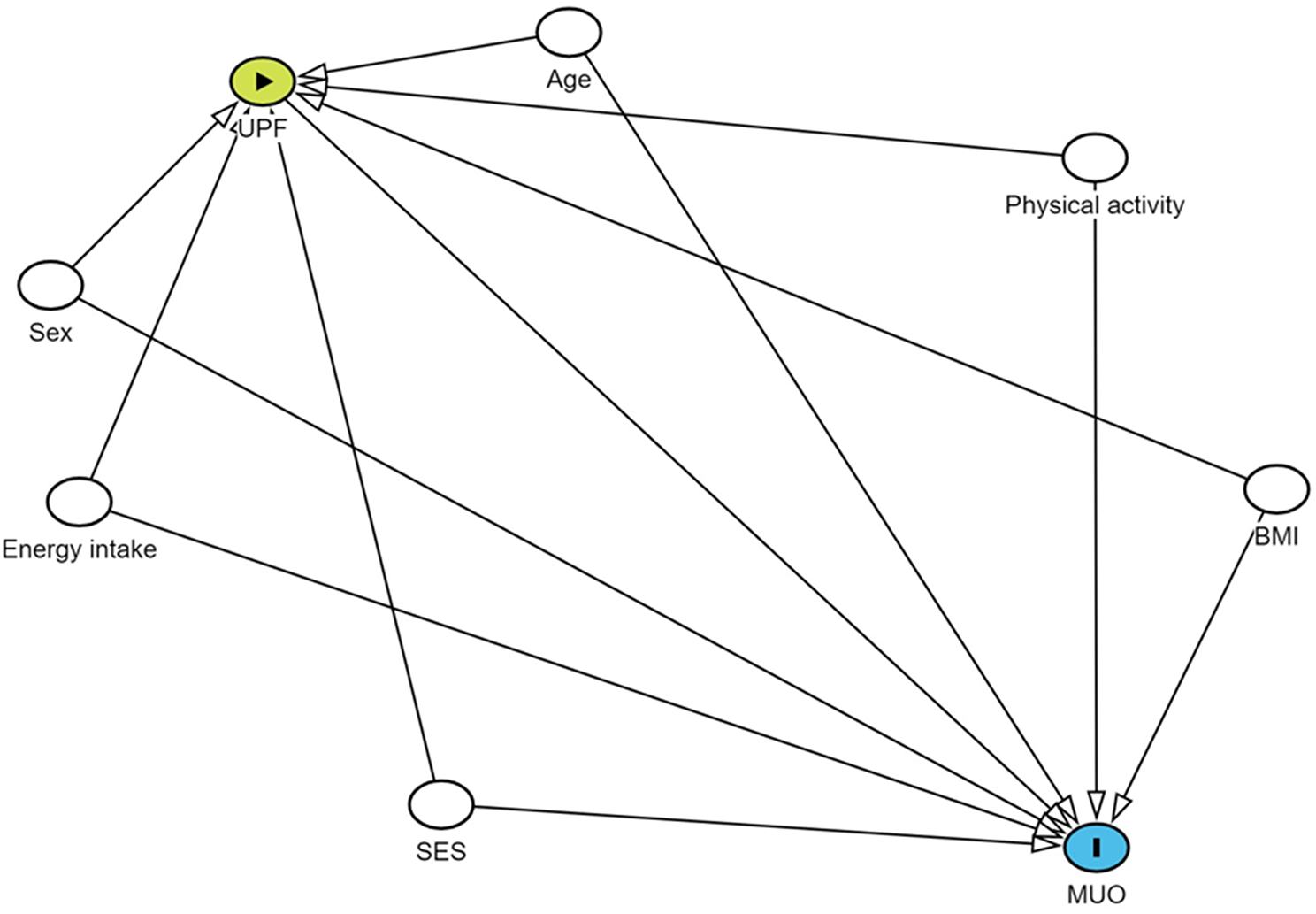
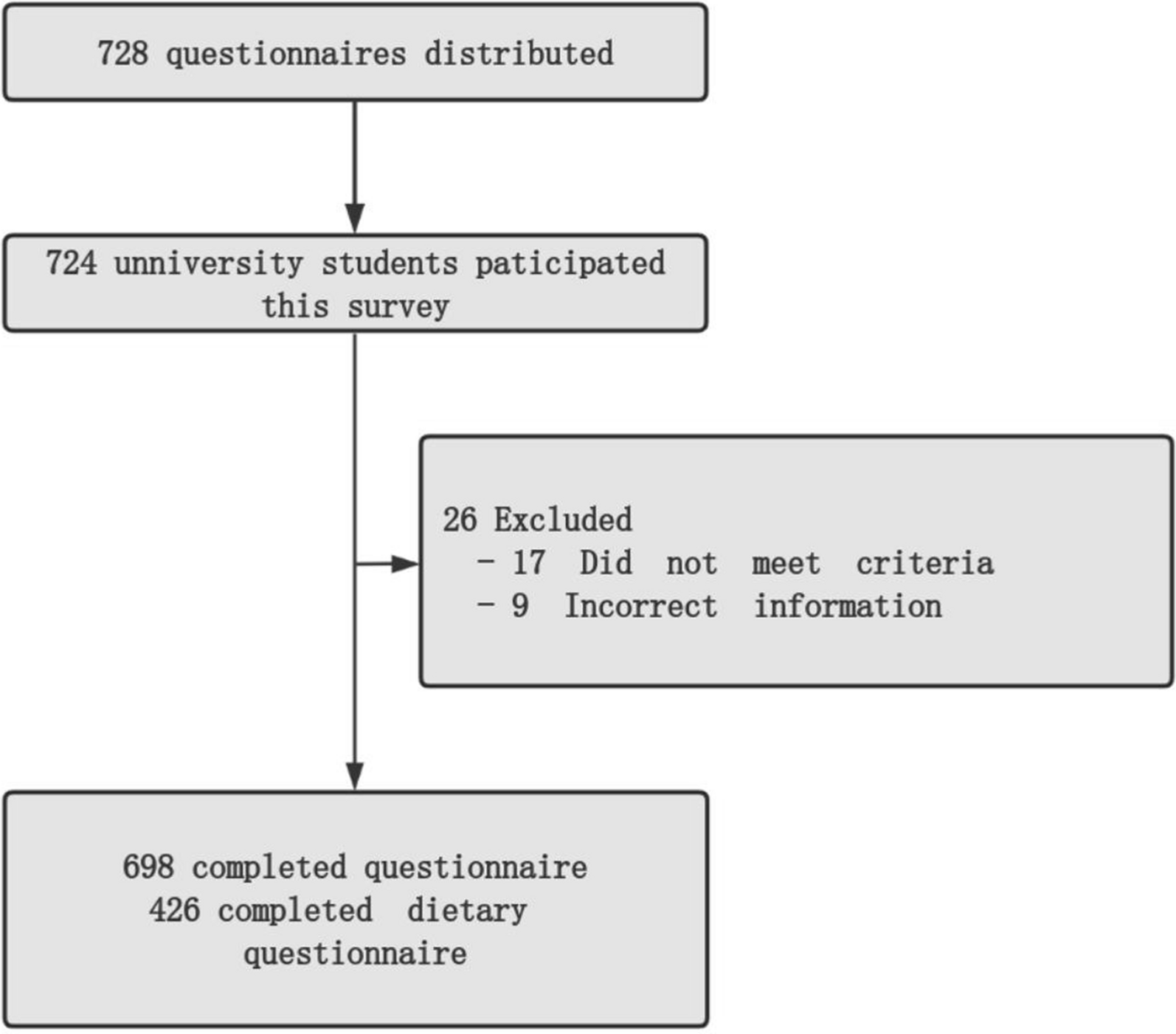
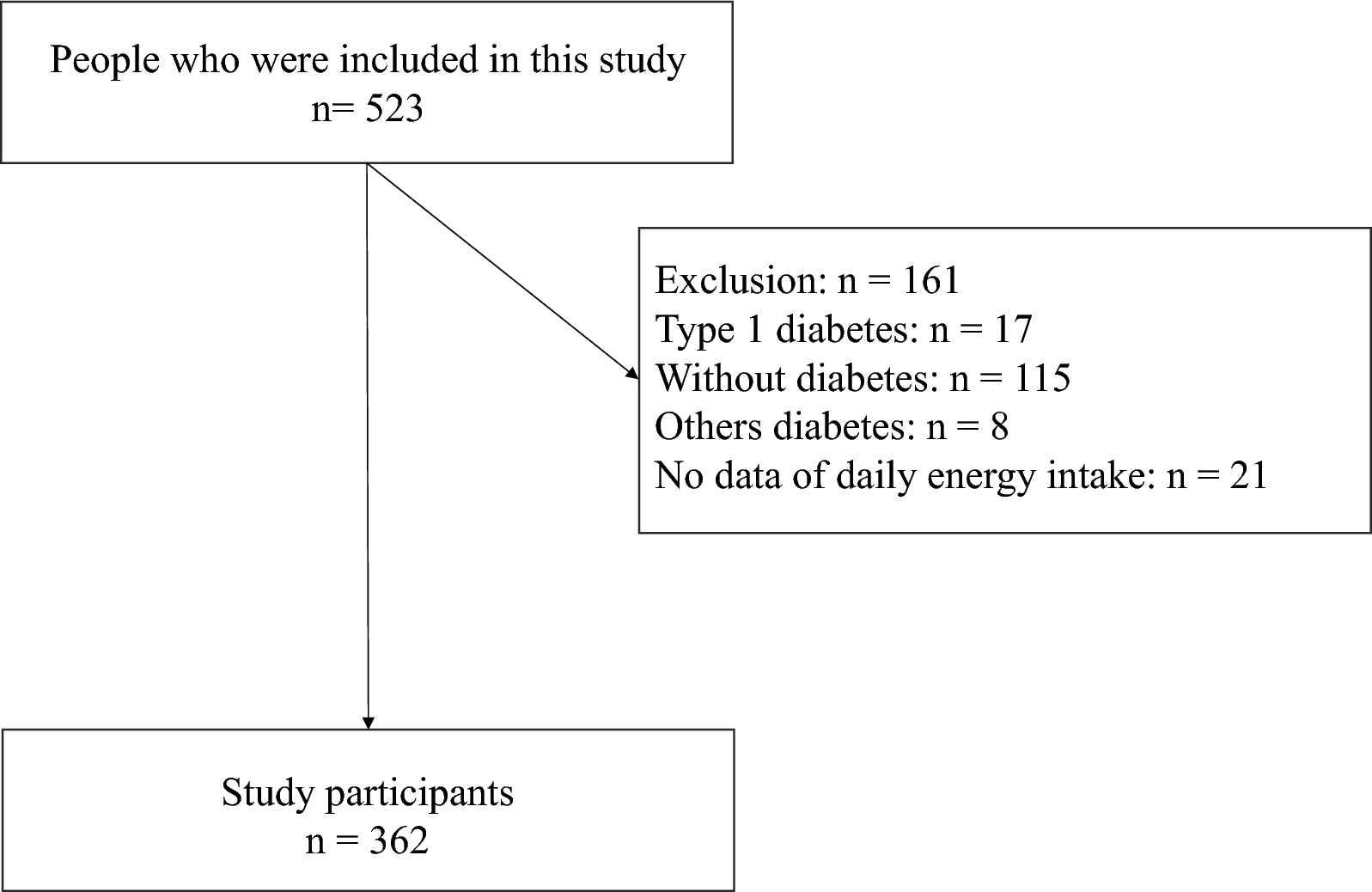
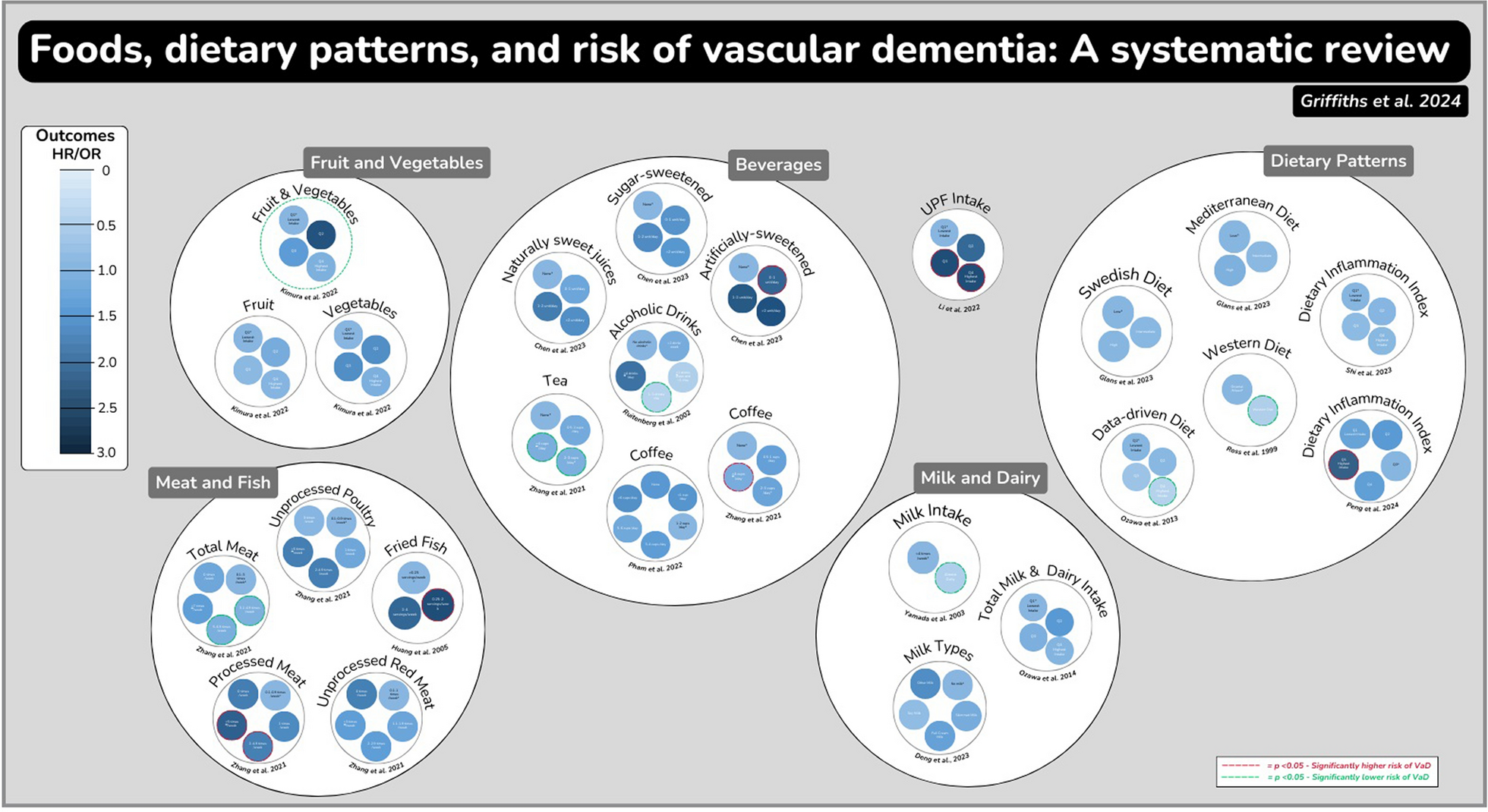
記住我
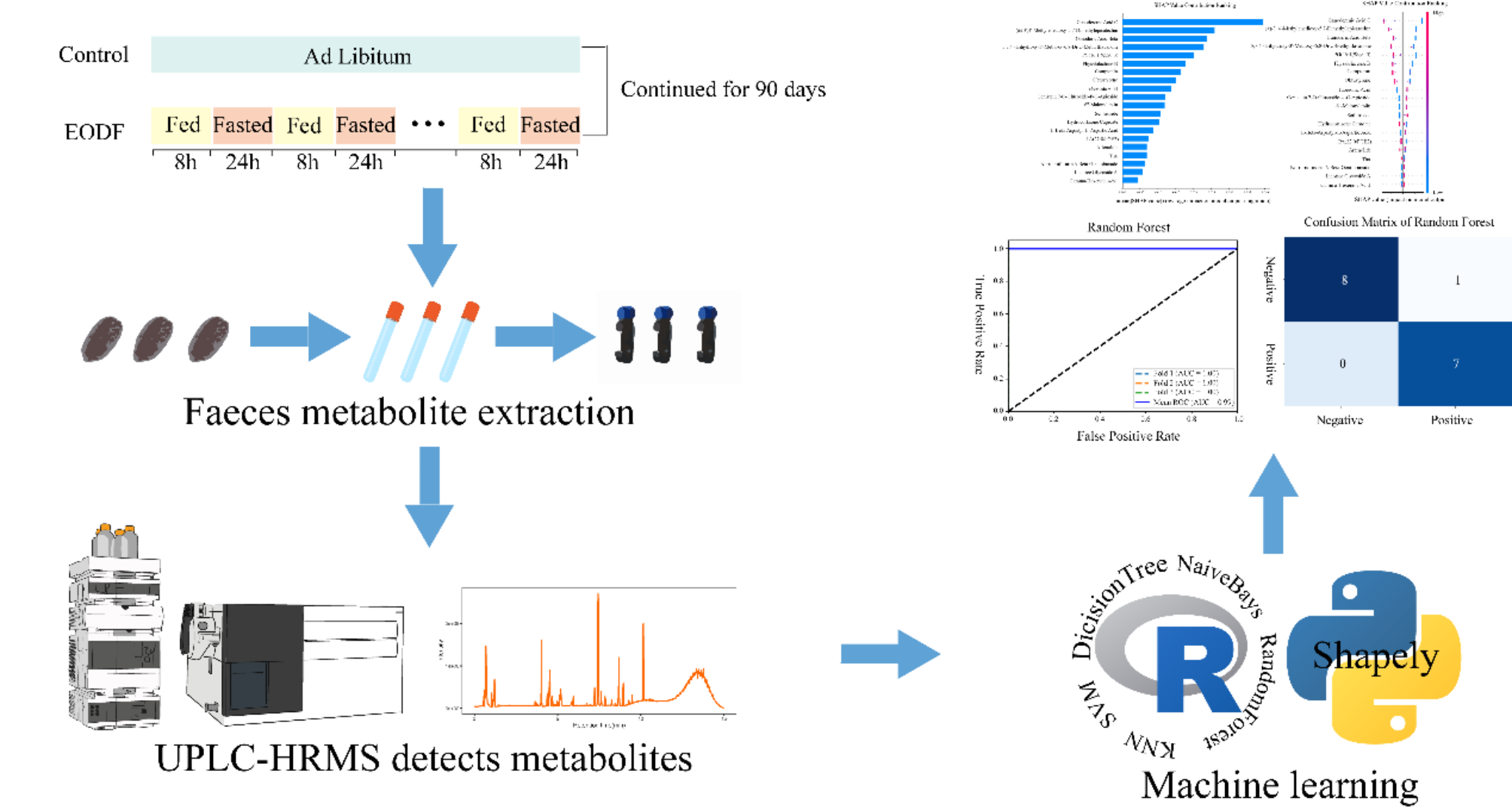

Untargeted metabolomics is often used to identify all metabolites in a sample under two dietary patterns. In this experiment, a total of 7400 differential metabolites (VIP > 1 and p-value < 0.05) were detected in mouse feces using UPLC-HRM, among which 595 differential metabolites with significant changes were selected for subsequent data-mining of biomarkers. A good case in point, non- targeted metabolomic analysis of plasma metabolites was performed in imiquimod-induced mice, and the results showed that 37 amino acids and 40 carnitines were significantly differential metabolites, which were the potential biomarkers of psoriasis [3]. In the current study, the metabolites with significant differences were mostly lipids and lipid-like molecules and organic acids and derivatives (described in Table S4 in the Supporting Information). This indicates that lipids and lipid-like molecules and organic acids and derivatives are closely related to the dietary diet in mice. Lipids and lipid-like molecules and organic acids are involved in obesity-related metabolic pathways [16].
Alterations in fecal metabolic markers and metabolic pathways induced by intermittent fasting in miceIn this experiment, sixteen mice were randomly divided into control group and EODF group, with 8 mice in each group. The top 30 metabolites with significant difference were selected for hierarchical clustering based on the untargeted metabolomics data. As shown in Fig. 2A, significant differences in fecal metabolites between intermittent fasting and normal feeding dietary styles were observed. Subsequently, KEGG metabolic pathway enrichment analysis was performed based on the differential metabolites in mouse feces. The detailed information for top 20 metabolic pathways was presented in supplementary information Table S5 and illustrated in Fig. 2B in the form of bubble plots. Riboflavin Metabolis, also known as vitamin B2, is a flavin-like compound that provides energy to the body by participating in the metabolism of sugars, fats and proteins. Several articles have shown that Riboflavin Metabolism contributes to ATP synthesis by participating in major metabolic pathways such as the tricarboxylic acid cycle and the electron transport chain. Histidine metabolism is a compound closely related to energy metabolism, which is mainly mediated by the condensation of ATP and PRPP (Ribose Phosphate Pyrophosphate) to form N-5-Ribose Phosphate. Histidine metabolism is a compound closely related to the energy metabolism of the body, which is mainly formed through the condensation of ATP and PRPP (ribulose phosphate pyrophosphate) to form N-5-phosphate ribulose 1-pyrophosphate (ribulose phosphate-ATP), which can be further synthesized. In addition to this, Histidine metabolism has a close relationship with the secretion of gastric acid, which is facilitated through the binding of the H2 receptor on the cells of gastric lining, thus helping digestion. In this study, a total of 595 metabolites with significant differences were screened from 7400 metabolites based on the parameters of p-value < 0.05 and VIP > 1. The up-regulated metabolites and down-regulated metabolites were then categorized based on log2 FoldChange and presented as volcano plots in Fig. 2C. Among the 595 significant metabolites, 324 down-regulated and 271 up-regulated metabolites were identified.
Fig. 2
Differences in fecal metabolites caused by intermittent fasting and normal feeding. (A) The heatmap shows top 30 representative metabolites calculated based on the correlation coefficients in the 16 groups of samples, hierarchically clustering each mouse according to the two dietary patterns. (B) KEGG enrichment pathway analysis of the top 20 metabolites. (C) Intermittent fasting-induced changes in differential metabolites, variable importance in projection (VIP) > 1, p-value < 0.05
Predicting metabolites in intermittent fasting based on machine learningIn recent years, machine learning has been widely used in the fields of biomedicine and food chemistry, and has attracted a great deal of attention. In the field of biomedicine, machine learning is often used for disease prediction as well as antibiotic screening and prediction. Deep learning model has been applied to identify a novel type of antibiotic effective in killing Methicillin-Resistant Staphylococcus Aureus (MRSA) from over 12 million compounds [26]. Moreover, machine learning has been widely accepted in the many other fields, such as food chemistry for composition identification or origin traceability [22]. Somaieh Soltani et al. predicted the bitterness of 229 peptides by establishing three machine learning models [24]. The application of machine learning methods in various fields has remarkably enhanced the efficiency of data analysis and offered more novel ideas for scientific research to solve the practical dilemma.
In this experiment, 595 metabolites were screened based on p-value < 0.05 and VIP > 1. However, since the number of 595metabolites was much larger than the number of samples, which would lead to overfitting of the data and make the predictions of the model meaningless, we used several feature screening methods to reduce the number of features from 595 to 21, and performed standardized scaling to avoid certain features that were too large or too small from affecting the stability of the model. In this experiment, due to limited sample data, in order to prevent the model from overfitting, the three cross-validation method was used to establish the model, where the sixteen samples were divided into three groups that do not overlap each other, and two of them were used as the training set and the other as the test set. Three consecutive iterations were performed to build the three-group model, and the performance metrics (e.g., accuracy, mean squared error, etc.) evaluated in all three folds were averaged, and the ROC curves and average ROC curves of each group were plotted to obtain the overall performance evaluation of the model. Due to the limited sample data, the use of overly complex machine learning models may lead to over-fitting of the model.
In this experiment, the Random Forest (Mean AUC = 0.99, Mean Accuracy = 0.94) (Fig. 3A) and the Support Vector Machine (Mean AUC = 0.99, Mean Accuracy = 0.94) (Fig. 3B) models have the highest area under the curve, i.e., AUC. AUC is an important parameter for judging the prediction rate of machine learning, the larger the AUC, the higher the prediction rate of the model. In machine learning models, Precision, Recall, Accuracy, and f1-source are four important metrics for evaluating models. In general, when all four metrics are high and remain in equilibrium, this model will be considered to be ideal. In this experiment, all the five machine learning models we selected have better performance, while the Random Forest and the Support Vector Machine have higher AUC. Thus, the Random Forest and the Support Vector Machine are the best two out of the five machine learning models (Table 1). Since the Random Forest is obtained by integrating multiple Decision Trees, we believe that the Random Forest has better generalization under the same parameters. In summary, we chose the Random Forest as the most ideal machine learning model for the next step of the analysis. However, among the five machine models selected for this experiment, all of them had an AUC value of greater than 0.5, which indicated that the prediction rate of mildly fasted mice versus normally fed mice is higher than random prediction. In this experiment, all models were modeled using default parameters.
Table 1 Performance parameters of five machine learning modelsWhere, TP is the true positive which were predicted to be positive and actually were positive; FP is the False positive which were predicted to be positive but actually negative; True Negative (TN) was samples that were predicted to be negative and actually were negative; False Negative (FN) was samples that were predicted to be negative but actually positive; Precision, reflects the proportion of correct classification among the number of positive samples classified by the model; Recall, proportion of positive samples among correctly classified samples; Accuracy, proportion of correctly classified samples; F1-score, the average of Precision and Recall; AUC, area under ROC, the larger the AUC, the better the model.
Fig. 3
Five machine learning models were established to predict metabolic biomarkers between intermittent fasting and normal feeding in mice based on 595 significant differential metabolites. The machine learning modes are Decision Tree (A), Random Forest (B), K-Nearest Neighbors (C), Naive Bays (D), Support Vector Machine (E), respectively. (F) is the confusion matrix of Random Forest (Color depth represents the number of samples). The model uses three-fold cross validation and plots the receiver operating characteristic (ROC) curves, the blue line represents the mean of each ROC curve, representing the overall performance of the model
SHAP analysis to identify key metabolites as biomarkers in distinguishing patterns of the two dietary patternsSHAP analysis is a commonly used machine learning interpretable model that calculates the contribution value of each feature to that modeling. The lack of transparency due to the black-box nature of the machine learning model makes the results presented by the machine learning model unconvincing, and the use of SHAP analysis allows for an interpretable analysis of the machine learning model and assigns a certain level of contribution to each feature value [15]. In this experiment, depending on the size of the contribution value, the biomarkers can be identified for both dietary models. The Random Forest model was selected as the most desirable model and further analyzed the interpretability using SHAP analysis. Twenty metabolites with the highest mean contribution was selected to plot a bar chart, and the magnitude of the SHAP value is the contribution of the feature to the model (Fig. 4A), i.e., the extent to which the metabolite is influential in distinguishing between the two dietary approaches. The top 20 differential metabolites between 2 dietary patterns were described in supplementary information Tables S6. It can be seen that the metabolites Ganoderenic Acid C, (±)-3’,4’-Methylenedioxy-5,7-Dimethylepicatechin, Ganoderic Acid Beta contribute to the differentiation between the two dietary patterns in mice. In addition, combining the SHAP values as well as the feature values, potential explanations for the dependence of each trait on the model can be calculated (Fig. 4B). In this figure, red color indicates higher Feature value while blue color indicates lower Feature value, and the higher the Feature value, the better the metabolite’s classification prediction for distinguishing between the two dietary styles. It can be seen that Ganoderenic Acid C, (±)-3’,4’-Methylenedioxy-5,7-Dimethylepicatechin, Ganoderic Acid Beta has a negetive correlation in terms of contribution to SHAP and they were more likely to be present in the Control group. Tuberonic Acid, Genistein 7-O-Glucoside-4’-O-Apioside had a positive correlation for the contribution of SHAP to that and they were more likely to be present in EODF group mice.
Fig. 4
The contribution of each metabolite was calculated through SHAP analysis. (A) The metabolites in feces were ranked according to their SHAP value, and the top 20 were extracted as biomarkers that distinguished mice between intermittent fasting and normal feeding. (B) The fecal metabolite trends of mice under two dietary modes through SHAP value and feature value
Collectively, 595 metabolites with significant difference were discovered between two dietary patterns, which play critical roles in butanoate metabolism, alanine, aspartate and glutamate metabolism, phenylalanine, tyrosine and tryptophan biosynthesis, riboflavin metabolism, D-Glutamine and D-glutamate metabolism, and nitrogen metabolism. After further screening and standardized scaling of 595 metabolites, 21 metabolites from the screening process were used to characterize the five machine learning models were established, and eventually Random Forest was optimal to conduct further interpretation using SHAP analysis for the prediction of metabolites biomarker. Consequently, the metabolites Ganoderenic Acid C showed more contribution to differentiate between normal diet and intermitten fasting dietary in mice. Overall, machine learning can effectively mine data from a large number of metabolites and identify potential biomarkers. Our work provides new insights for metabolic biomarker analysis and lay theoretical foundation for the selection of healthier dietary lifestyle.
留言 (0)