
記住我





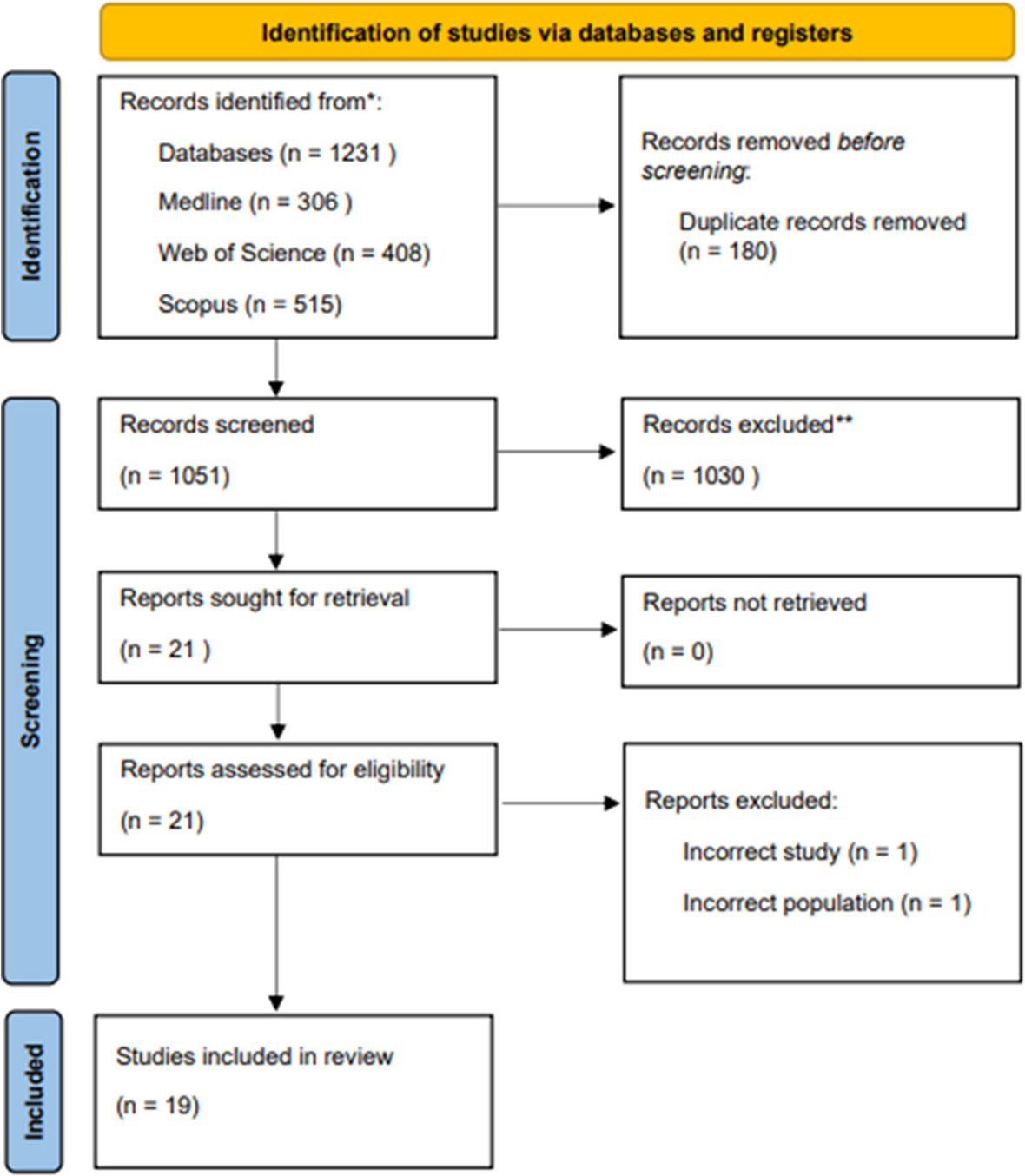
Initially, 1,231 articles were identified, and 180 duplicates were removed. After screening and in-depth review, 19 articles were included in the final analysis (Fig. 1). The main reasons for exclusion were studies with outcomes not directly related to the application of AI in the analysis of human milk consumption and breastfeeding. For instance, some studies have focused on general AI applications in other areas of healthcare rather than on breastfeeding, milk composition, or lactation-related outcomes. ‘Incorrect population’ refers to studies that did not focus on lactating mothers, infants, or populations directly involved in breastfeeding practices, such as studies targeting unrelated age groups or conditions not involving breastfeeding. Additionally, studies with unsuitable designs such as narrative reviews or opinion pieces that did not provide primary data were excluded.
Fig. 1
Flow diagram of study selection
Regarding the study methodologies, seven were observational studies, one was a case report, and the remaining studies focused on evaluating the development and integration of AI (Table 1).
Table 1 Description and characterization of included studiesRisk of bias and quality of studiesRegarding the quality and risk of bias in observational studies, most had a low risk of bias. The main causes of bias were the sample size and generalizability of the results (Fig. 2a). In addition, a low risk of bias was identified in the case reports, with the main factors being the timeline and clinical findings (Fig. 2b).
Fig. 2
Evaluation of the methodological quality of included studies. Assessment using the STROBE checklist. b Assessment using the CARE checklist
Artificial intelligenceThe articles were categorized into five groups: 1. prediction of breastfeeding practices (n = 5); 2. characterization of macronutrients in human milk (n = 3); 3. Education and resolution of doubts and problems regarding breastfeeding (n = 4); 4. Detection of drug concentration and passage in human milk (n = 4), and 5. Detection of environmental contaminants in human milk (N = 3). The most common AI approaches used were machine learning, neural networks, and chatbot development and application (Table 1).
Predicting breastfeeding practicesIn a study by Oliver-Roig et al., machine learning techniques, including XGBoost and a linear support vector machine (SVM), were used to analyze data from 2,042 nursing mothers [23]. The model identified the main individual, clinical, and hospital environmental factors that predicted exclusive breastfeeding, including the mother’s previous experience, admission to the neonatal intensive care unit, and institutional accreditation in breastfeeding [23]. A study conducted by Silva et al. on 1,003 infants and using decision trees to determine factors associated with breastfeeding practices in the first six months revealed that maternal and child characteristics (multiple births, maternal age, and parity), social context, work, inpatient feeding practices, and hospital policies on breastfeeding influenced breastfeeding rates [24]. The length of hospital stay was the most important predictor of feeding practices, both at hospital discharge and at the third and sixth months [24]. Using a decision tree combination algorithm, this study offers a better understanding of the risk predictors of breastfeeding cessation in an environment with a high variability in exposure [24]. Sampieri et al. used machine learning techniques to assess the influence of skin-to-skin contact on breastfeeding [25]. Using selection algorithms generated by supervised learning, this study identified a direct relationship between skin-to-skin contact at birth, prenatal breastfeeding education, initiation and duration of breastfeeding, and mothers’ perceptions of breastfeeding after childbirth [25].
By using machine learning with logistic regression on imputed data, Elgersma et al. examined data from 1,944 newborns with complex single-ventricular congenital heart disease to identify the predictive factors related to breastfeeding and direct breastfeeding at the time of neonatal discharge and after palliative surgical correction [26]. They found that presurgical breastfeeding and private health insurance were associated with an increased likelihood of some types of breastfeeding after surgery [26]. On the other hand, being African American was associated with a decrease in this likelihood [26].
He et al. explored the benefits of applying common data-mining techniques to national breastfeeding surveys, where statistical analyses are common [27]. This study aimed to analyze the factors influencing the decision to breastfeed newborns using a decision tree and regression approach for classification based on selected features [27]. In addition, a risk pattern mining method was employed to identify groups at high risk of not breastfeeding. The results suggest that data mining in national surveys can identify mothers at greater risk of non-breastfeeding, which would allow their inclusion in early care and education programs to increase breastfeeding rates [27].
Characterization of macronutrients in human milkWong et al. developed a machine learning-based prediction model using donor mother variables, binomial characteristics, and the milk extraction process to estimate the fat and protein contents in collected mixtures of donated human milk [28]. They analyzed samples of human milk donated to a human milk bank in Canada, combining milk from two to five donors into a single bottle, and showed that the most important variables in the prediction of total fat were the body mass index of the donor, whether the neonate was preterm or full-term, and the time of day of milk production (night vs. day) [28]. In contrast, for protein prediction, the most significant variables were the average number of days postpartum, volume of milk expressed in the bank per day, and whether the neonate was preterm or full term [28]. The model was shown to be clinically acceptable for protein-level prediction, whereas fat prediction was more difficult owing to its natural variability and measurement challenges [28].
Jansen et al. proposed a model to optimize the experimental parameters for chromatographic separation of cholesterol esters in breast milk from three samples obtained from donor mothers [29]. Using an artificial neural network-genetic algorithm (ANNGA) approach, factors such as the type of organic component in the mobile phase, column temperature, and flow rate were optimized [29]. This method led to significant improvements in the separation parameters and quality of the chromatographic results, allowing better resolution of the identified analytes [29].
Ruan et al. compared two methods for determining the macronutrient composition in the breast milk of Chinese mothers at all stages of lactation using a mid-infrared analyzer and an ultrasound-based analyzer [30]. Through machine-learning techniques using linear regression algorithms, the ultrasound results were converted to align the results from both methods, making them comparable [30]. The initial compositional results obtained using the two analysis methods differed significantly for all compounds: protein, fat, lactose, and energy [30]. However, after adjusting the values using machine learning, the data exhibited improved consistency. This approach illustrates how AI techniques enhance the accuracy and consistency of breast milk composition measurements, which is clinically important for ensuring adequate nutrition in infants, especially preterm infants [30].
Education and resolution of doubts and problems regarding breastfeedingCorrea et al. described the design process of the Lhia chatbot, a virtual tool aimed at breastfeeding education and recruiting breastfeeding mothers to donate human milk to milk banks, using text and images from Telegram and WhatsApp [31]. They adopted a co-design approach with lactation professionals, who simulated texts from mothers with potential breastfeeding issues, which helped refine the AI-based chatbot [31]. Five deep-learning-based NLP systems were trained to classify the various intentions of user mothers [31]. Throughout the co-design process, improvements were made to the content and structure of the conversation flow based on the data gathered during subsequent training sessions [31]. The final system, with optimal performance and enhanced conversation flow, was implemented in a Lhia chatbot. This tool has demonstrated high accuracy in identifying specific issues related to breastfeeding and human milk donation [31].
Achtaich et al. developed ALMA, a chatbot designed to engage in natural conversations with breastfeeding mothers via WhatsApp, using the Twilio application programming interface (API) [32]. ALMA utilizes natural language understanding and generation to respond to breastfeeding-related needs and to provide relevant information. The chatbot was evaluated by volunteer breastfeeding mothers and the results were validated with lactation consultants [32].
In a related study, Oyedove et al. explored social networks as platforms for expressing both positive and negative opinions about breastfeeding, highlighting the opportunity to analyze these perspectives [33]. They proposed using AI to identify the factors affecting breastfeeding based on an analysis of tweets [33]. Tweets on this topic were collected and analyzed for sentiment using both lexicon-based and machine-learning techniques to classify them as positive or negative [33]. Four lexicon-based sentiment classifiers were evaluated: VADER, TextBlob, Pattern, and VADEREXT. Additionally, supervised machine learning algorithms—multinomial naïve Bayes (MNB), support vector machine (SVM), logistic regression (LR), stochastic gradient descent (SGD), and random forest (RF)— have been applied for text classification. Among these, SVM showed the best performance, whereas RF performed the least [33]. This study identified factors that negatively impact breastfeeding, such as health issues (breastfeeding-related, medical, and nutritional problems), as well as social, psychological, and situational factors [33]. Positive influences included perceived benefits, maternal self-efficacy, social support, and access to educational and training resources [33].
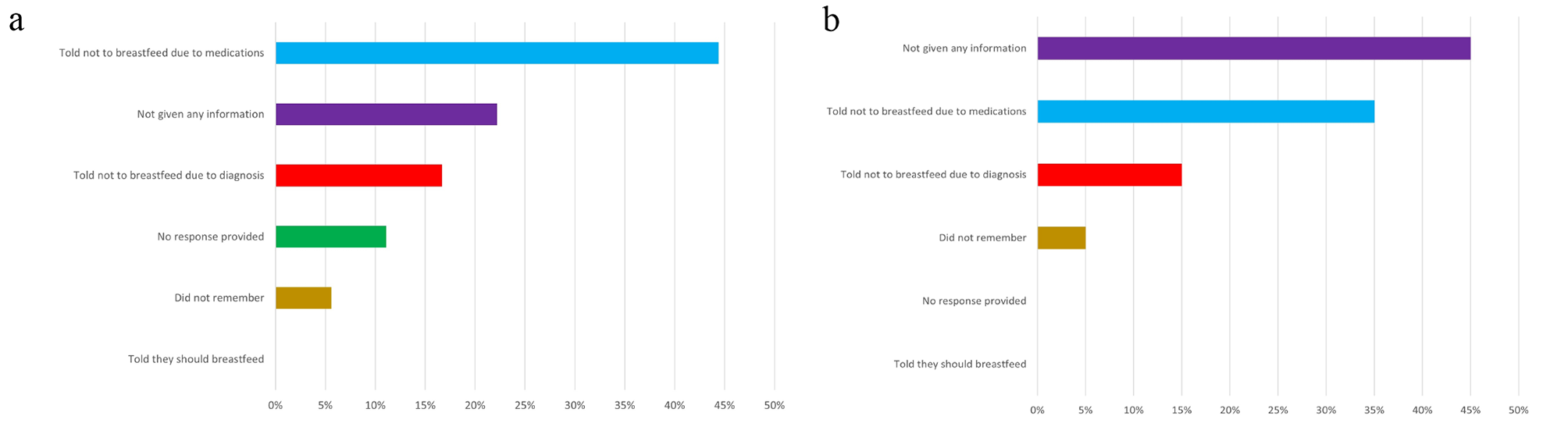
In India, Yadav et al. evaluated the impact of chatbots on breastfeeding among mothers living in slums [34]. Initially, they developed a question-and-answer prototype by analyzing interaction patterns, perceptions, and usage contexts. The results showed that most of the nursing mothers’ questions could be effectively answered using the app [34]. Additionally, the study highlighted that many of the queries made to the chatbot were influenced by beliefs and myths held by breastfeeding mothers and their families [34].
Detection of drug concentrations and transfer in human milkAgatonovic-Kustrin et al. applied artificial neural networks to preestablished data on milk plasma concentrations and molecular structure characteristics of 123 drugs, aiming to identify factors that predict drug concentrations in human milk [35]. They used genetic algorithms to select the most relevant features describing drug transfer into breast milk, and subsequently applied an artificial neural network (ANN) to correlate these selected features with the milk/plasma ratio, developing a quantitative structure–activity relationship (QSAR) regression model [35]. This model includes nine features that predict the milk/plasma ratio of the studied drugs, considering characteristics such as molecular size, shape, and electronic properties, without requiring additional experimental data [35].
Maeshima et al. developed a prediction model for the ratio between drug concentration in breast milk and plasma concentration (M/PAUC) using the area under the curve (AUC) as a basis [36]. They also applied a quantitative structure–activity/property relationship (QSAR/QSPR) approach to predict the compounds involved in active transport during breast milk transfer [36]. Artificial intelligence (AI) tools were used to construct binary classification models, and data on the milk-to-plasma concentration ratio (M/P ratio) were collected from the existing literature [36]. Two binary classification models were developed: artificial neural network (ANN) and support vector machine (SVM). The sensitivity of the ANN model was 0.969 for the training set and 0.833 for the test set, whereas that of the SVM model was 0.971 for the training set and 0.667 for the test set [36]. These findings suggest that AI models can identify compounds with M/P ratios greater than or equal to 1 [36]. It is important to note that while these results are useful in risk assessment, alongside infants’ responses, they are not sufficient to determine the safety of breastfeeding during pharmacological treatment based solely on M/P ratio [36].
Zhao et al. developed computational models to predict and classify the milk-to-plasma concentration ratio (M/P ratio) of 123 pharmacological compounds that are commonly used by lactating mothers [37]. They employed the support vector machine (SVM) method to assess the potential risks of these drugs to infants. Each drug was included in the model with a range of characteristics to determine the best predictive model and ultimately identify five key factors for its construction [37]. Two classification models were developed: linear discriminant analysis (LDA) and SVM with bootstrap validation based on selected molecular descriptors [37]. The results showed that the classification accuracies of the SVM method were 90.63% for the training set and 90.00% for the test set [37]. The overall accuracy of SVM was 90.48%, which was significantly higher than that of LDA (77.78%) [37]. This comparison suggests that SVM performed better than LDA in classifying the risks associated with drugs when experimental M/P ratio data were unavailable [37]. Additionally, steric and electronic factors appear to be important components of the drug transfer process, along with other physical descriptors that influence the ability of drugs to transfer between breast milk and blood plasma [37].
On the other hand, Ye et al. developed a process that combined colorimetric methods with artificial intelligence image preprocessing and backpropagation artificial neural network (BP-ANN) analysis to detect amoxicillin in breast milk [38]. This technique involves the coupling of gold nanoparticles (AuNPs) with aptamers (ssDNA) at various amoxicillin concentrations, producing distinct color results [38]. An image of the color was captured using a portable image acquisition device, followed by image pre-processing [38]. These findings suggest that the colorimetric process, combined with AI-based image preprocessing and BP-ANN, provides an accurate and rapid method for detecting amoxicillin in breast milk [38].
Detection of environmental contaminants in human milkKowalski et al. collected human milk samples from 193 mothers across different regions of Brazil to identify patterns that could predict the presence of polychlorinated biphenyls (PCBs) in milk [39]. They used high-resolution omics and separation technologies to analyze compounds, considering mothers’ social, environmental, clinical, and lactational factors [39]. For the data analysis, non-automated learning techniques were applied to discover patterns and relationships, generating self-organizing maps using Kohonen neural networks [39]. The key variables predicting the presence of PCBs in breast milk included the mother’s region of residence, proximity to industrial areas or contaminated rivers, lactation phase (colostrum, early milk, or late lactation), and number of previous pregnancies [39].
In a related study, Nadal et al. used Kohonen neural networks to assess the relationship between the concentrations of polychlorinated dibenzo-p-dioxins (PCDDs) and polychlorinated dibenzofurans (PCDFs) in breast milk and dietary habits across various countries [40]. Their findings indicated higher concentrations of PCDDs/PCDFs in human milk in countries with high fish consumption [40].
Using machine learning methods and the Guided Regularized Random Forest (GRRF) algorithm, Jovanovic et al. aimed to identify persistent organic compounds such as organochlorine pesticides and polychlorinated biphenyls in human milk [41]. The study included samples from seventy-nine healthy mothers along with data on their social, environmental, and occupational backgrounds [41]. The levels of organic contaminants varied between the milks of primiparous and multiparous mothers [41]. The developed model demonstrated a high capacity to reliably predict contaminants in human milk based on selected variables [41]. The primary factor influencing the model’s predictions of contaminant concentrations was the chemical structure of each contaminant, particularly the number and position of the chlorine atoms [41].
留言 (0)