
記住我
Primary liver cancer remains a global health challenge, leading to 905,677 new cases and 830,180 deaths worldwide in 2020, especially a major threat to Asia and Africa (https://gco.iarc.fr) (1). The majority of primary liver cancers are hepatocellular carcinomas (HCC) (2). The major factors that contribute to the onset and progression of HCC include chronic viral hepatitis, alcohol intake, non-alcoholic fatty liver disease, and exposure to aflatoxins (3, 4). The appropriate therapies for HCC depend on the tumor stage, hepatic functional reserve, and the general condition of the patients. For patients with early-stage HCC, the curative therapies include surgical resection, liver transplantation, or radiofrequency ablation. Intermediate-stage HCC is typically managed with transarterial chemoembolization and radiation therapy, either as monotherapy or in combination with systemic therapies. Advanced-stage HCC requires systemic therapies, including traditional chemotherapy and emerging precision medicine approaches such as immune checkpoint inhibitors or molecular targeted therapies (5, 6). Despite these treatments, HCC remains a highly refractory disease with approximately 70% of the 5-year recurrence rate after curative therapies and a 5-year overall survival (OS) of less than 15% (7, 8).
Given the heterogeneity of HCC, understanding its molecular characteristics and classifications is essential for precise clinical management. So far, several typing schemes for HCC have been proposed, yet they typically rely on specific dimensions (9–12), or are tailored to particular subtypes, such as HBV-related HCC (13). Moreover, few schemes performed validation with external cohorts and provided user-friendly software. These factors restrict their ability to comprehensively capture the complex features of tumors and impede practical implementation in clinical settings.
To make out the molecular features of HCC comprehensively, we conducted evaluations and classifications for HCC based on multidimensional feature scores (FSs). These FSs included 50 hallmark pathways from the Molecular Signatures Database (MSigDB, https://www.gsea-msigdb.org/gsea/msigdb) (14), 7 regulatory cell death pathways (15–20), immune cell infiltration (21), mRNA stemness index (mRNAsi) (22), estimate score (23), stromal score, tumor purity, immune score, immune checkpoint score (24), tumor immune dysfunction and exclusion (TIDE) score (25–27), and a merged metabolic pathway from the MSigDB database. We also systematically characterized the response to anti-PD1 therapy for each subtype, as well as their single nucleotide variation (SNV), tumor immune microenvironment (TIME), drug sensitivity, pseudo-temporal trajectory, intercellular communication, etc. In this study, we also developed practical software for predicting the molecular subtypes and prognosis based on individual transcriptomic data (https://github.com/OliveryYL/oncoClassSurv). In addition, our study identified formiminotransferase cyclodeaminase (FTCD) as a classification-specific prognostic gene with anti-tumor effects in HCC, serving as a potential therapeutic target for specific molecular classifications through bioinformatics screening and experimental evidence.
Therefore, this study provides a comprehensive global landscape of HCC from multiple perspectives, which can provide support to therapeutic decision-making based on classifications, individualized disease evaluation, and further scientific research (Figure 1).
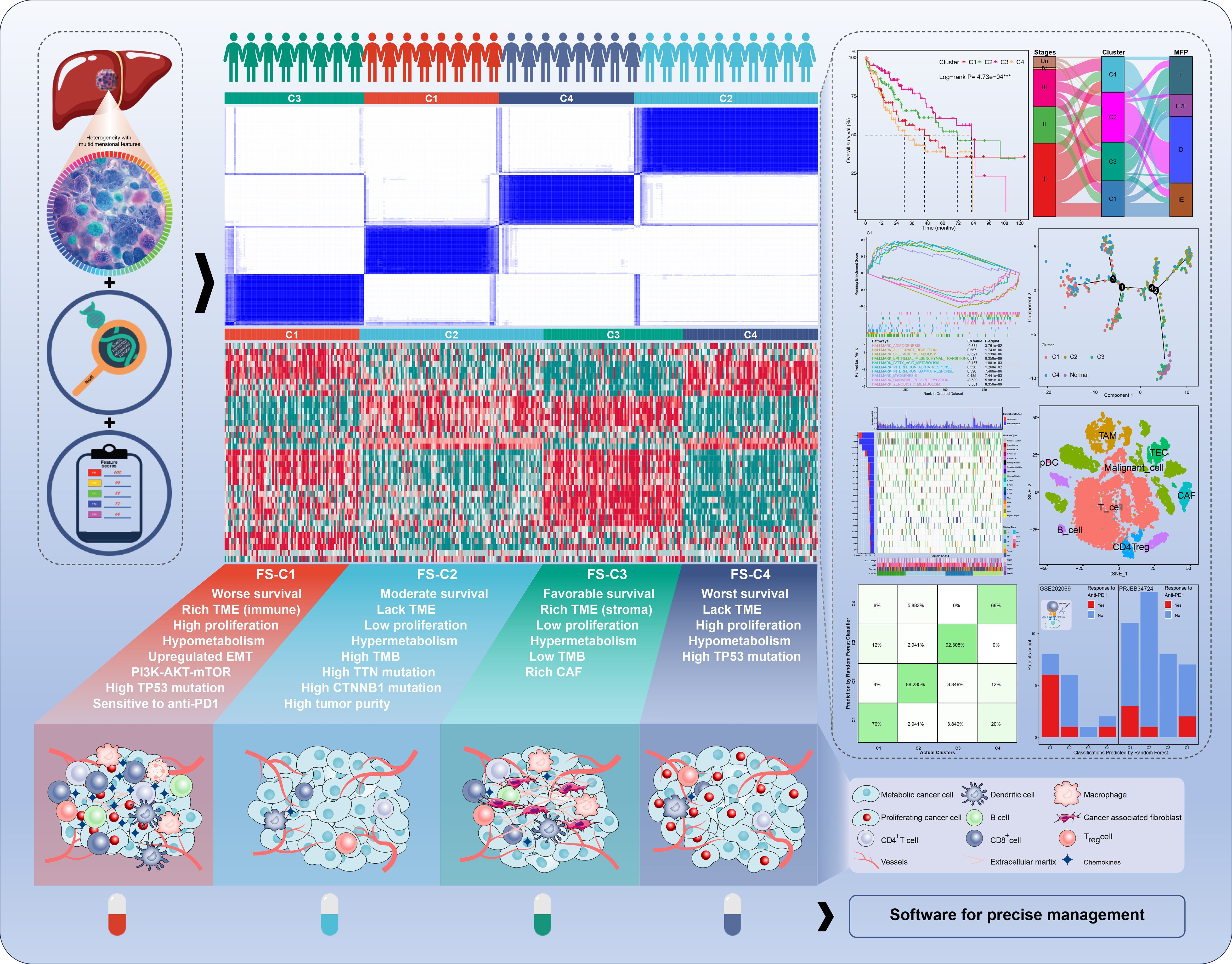
Figure 1. The graphic overview of the molecular classification system in the current study.
2 Materials and methods2.1 Research schemeThe research scheme is illustrated in Figure 2. Further details on analytic processes and experimental methods are provided in the Supplementary Materials.
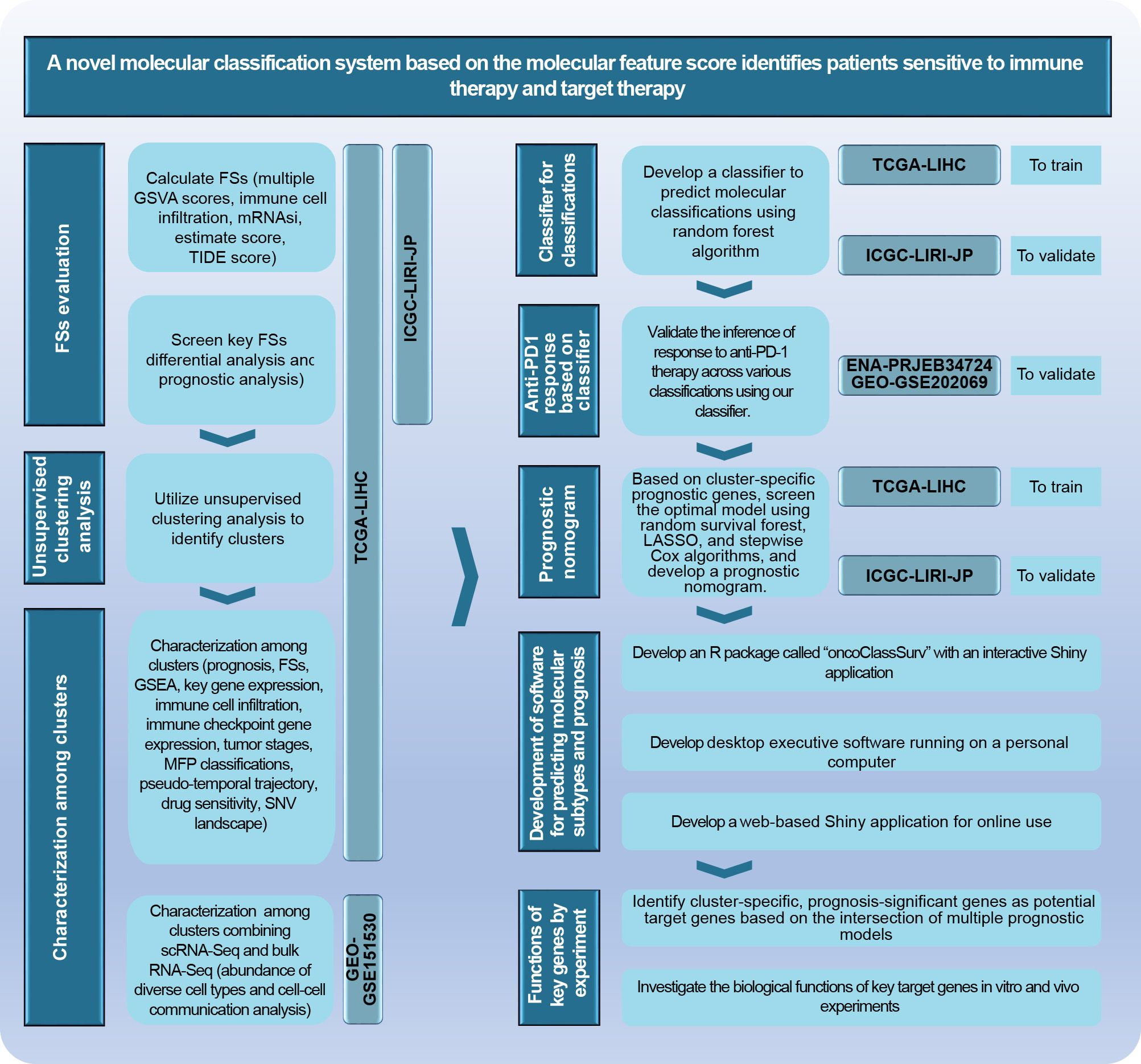
Figure 2. The main analytical scheme of the current study.
2.2 Data collection and feature score calculationBulk RNA sequencing (RNA-Seq) data were obtained from the Cancer Genome Atlas-Liver Hepatocellular Carcinoma (TCGA-LIHC) and the International Cancer Genome Consortium (ICGC-LIRI-JP) projects. A total of 89 feature scores (FSs) were calculated, including gene set variation analysis (GSVA) scores (28), curated scores, and immune cell infiltration metrics. GSVA scores encompassed 50 hallmark gene sets and another 11 crucial gene sets (Supplementary Table S1). Six curated scores—mRNAsi, TIDE, estimate score, immune score, stromal score, and tumor purity—were calculated based on previous studies (22, 25, 26). Immune cell infiltration was estimated using the R package “immunedeconv”, which involves six algorithms: Cibersort, Quantiseq, Timer, MCPcounter, XCell, and EPIC (21). Specifically, the proportions of 22 immune cell types calculated by the Cibersort algorithm were enrolled in the 89 FSs above.
2.3 Clustering and characterizationDifferential, prognostic, and Venn analyses were performed to identify consistently significant FSs in HCC. These FSs were then used for the unsupervised clustering analysis (29). The characteristics of clusters were analyzed, including key signal pathways, immune evaluation, pseudo-temporal trajectory, single nucleotide variation (SNV), drug sensitivity, and single-cell RNA sequencing (scRNA-Seq). Moreover, to make out the association among diverse classification criteria, we compared the proportion of different stages and MFP subtypes among clusters, respectively (30).
2.4 Classifier development and validationCluster-specific marker genes were identified employing the “FindAllMarkers” function from the “Seurat” package (31). A classifier was developed using the random forest (RF) algorithm based on these marker genes in the TCGA-LIHC training cohort and externally validated with the ICGC-LIRI-JP cohort. To validate the reliability of our classifier, characteristics of the predicted classifications in the external cohort were compared with those of the clusters in the TCGA-LIHC cohort. Additionally, datasets GSE202069 and PRJEB34724 were used to validate the responses to anti-PD1 therapy based on our classifier (12, 32, 33).
2.5 Prognostic nomogramA novel prognostic nomogram was developed using cluster-specific marker genes in the TCGA-LIHC training cohort and externally validated with the ICGC-LIRI-JP cohort.
2.6 Software developmentThe practical software was developed for individualized predictions of molecular classifications and prognoses using external transcriptomic data.
2.7 Classification-related therapeutic target identificationSignificant therapeutic targets were identified through Venn analysis, differential expression analysis, and prognostic analysis of genes from several prognostic models. Lentiviral transduction was used to establish overexpressing Huh7 cell lines for the target gene and its negative control. The biological roles of the gene were evaluated by means of cell proliferation, colony formation, transwell migration, apoptosis, cell cycle assays, and tumorigenicity assays in nude mice.
All animal procedures were approved by the Ethics Committee of Zhejiang Cancer Hospital and conducted in accordance with the ethical guidelines.
3 Results3.1 Identification for critical FSs and unsupervised clustering analysis.After calculating the 89 FSs, differential and prognostic analyses were performed to identify the most critical FSs in the TCGA and the ICGC cohorts. The differential analysis results are presented in the heat maps (Figures 3A, B) and Supplementary Table S2, while the Kaplan-Meier survival analysis results are provided in Supplementary Table S3. The forest plots of the univariable Cox regression analyses are shown in Supplementary Figure S1. The results of the Kaplan-Meier survival analysis were incorporated into the subsequent screening. Finally, Venn analysis for the differential and the prognostic FSs identified 37 critical FSs closely related to HCC biological behavior (Figure 3C).
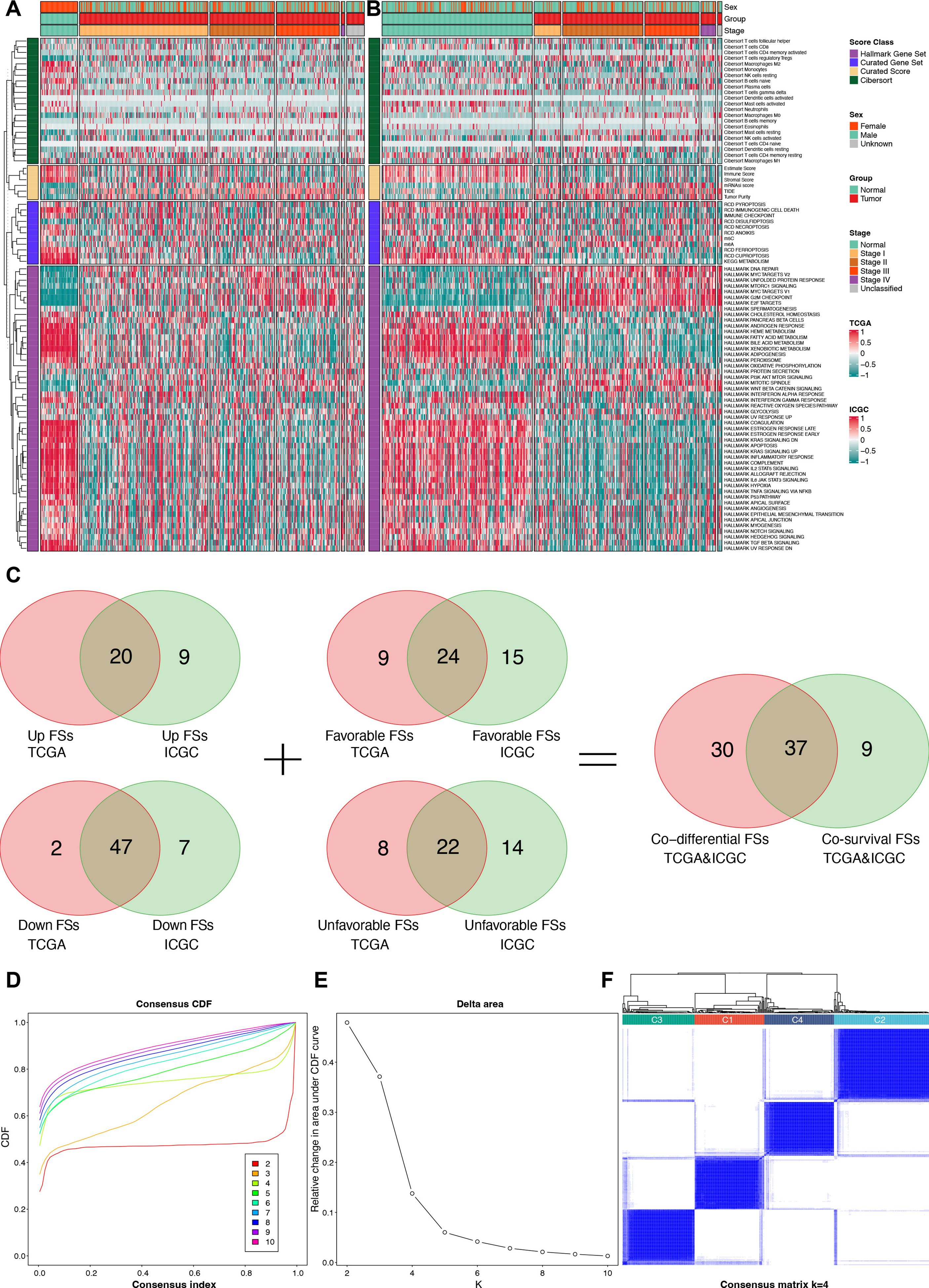
Figure 3. Identification for critical FSs and unsupervised clustering analysis. (A) Differential heat map of FSs in the TCGA cohort. (B) Differential heat map of FSs in the ICGC cohort. (C) Selection of consistently differential and prognostic FSs using Venn analyses. (D) The consensus CDF plot of the unsupervised clustering analysis. (E) The delta area plot of the unsupervised clustering analysis. (F) Consensus matrix plot of the unsupervised clustering analysis when K = 4. FSs, feature scores; TCGA, the Cancer Genome Atlas; ICGC, the International Cancer Genome Consortium; CDF, consensus cumulative distribution function.
Using the 37 critical FSs, we performed unsupervised clustering analysis on 374 tumor samples from the TCGA-LIHC cohort, identifying four clusters: C1, C2, C3, and C4 (Figures 3D–F).
3.2 Prognostic characteristics among clustersSignificant survival differences were observed across the clusters. Patients in C3 had the most favorable prognosis, with a median overall survival (OS) of 81.9 months, followed by C2 (median OS: 71 months), C1 (median OS: 45.7 months), and C4 (median OS: 30 months) (P < 0.001, Figure 4A).
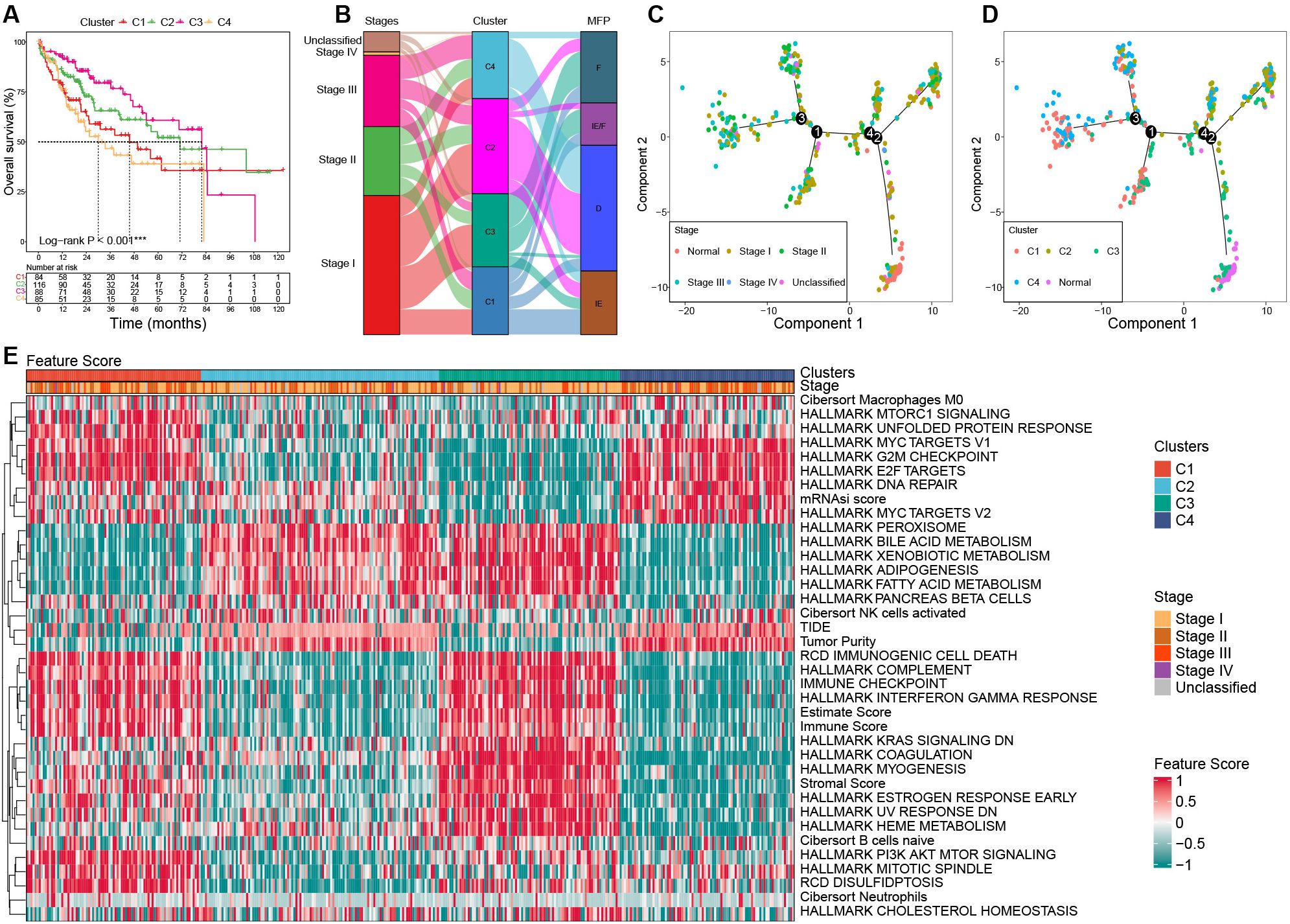
Figure 4. Characterization among clusters based on bulk RNA-seq in the TCGA cohort. (A) Survival curves among clusters. (B) Association among clusters, stages, and MFP classifications using Sanky plot. (C) Pseudo-temporal trajectory analyses by tumor stages. (D) Pseudo-temporal trajectory analyses by clusters. (E) Heat map of the key FSs enrolled in the unsupervised clustering analysis among clusters in the TCGA cohort. TCGA, the Cancer Genome Atlas; MFP, molecular functional portrait.
3.3 Association among clusters, tumor stages, and MFP classificationsThe results showed that C3 had the highest proportion of stage I tumors (58.14%) and the lowest proportion of stage III (12.79%), while C4 had the highest proportion of stage III tumors (35.44%) and the lowest proportion of stage I (31.65%). C1 was predominantly MFP-IE (37.50%), whereas C2 and C4 were mainly MFP-D (64.29% and 72.15%, respectively). C3 showed the highest frequency of MFP-F (47.67%) (Figure 4B).
3.4 Pseudo-temporal trajectory analysisTo investigate the evolutionary relationships among clusters, we performed a pseudo-temporal trajectory analysis. As illustrated in Figure 4C, the lower-right subpopulation, representing normal samples, was designated as the starting point, while the top-left subpopulation marked the endpoint. The analysis revealed that cluster C3 was closest to normal tissue, followed by C2, C1, and C4, which aligns closely with their prognostic characteristics (Figure 4D).
3.5 Characteristics of key gene expression and FSs among clustersSignificant differences in gene expression and FSs were observed among clusters. The expression of MKI67 and AFP was significantly upregulated in C1 and C4 than that of C2 and C3. Compared to the normal samples, samples with upregulated AFP in HCC tumors mostly occurred in C1 and C4, not C2 and C3 (Supplementary Figure S2; Supplementary Table S4). The significant feature scores (FSs) in the heat map can be mainly categorized into three parts: stemness proliferation, microenvironment (immune/stroma), and metabolism. In terms of stemness proliferation, notable FSs include the mRNAsi score, MYC targets, E2F targets, G2M checkpoint, PI3K AKT mTOR pathway, and DNA repair activity. The microenvironment category encompasses the estimate score, stromal score, immune checkpoint score, immune score, complement score, immunogenic cell death score, tumor purity, and TIDE score. The metabolism category includes various metabolic-related pathway scores. These categories help to delineate the roles and impacts of FSs within the context of tumor biology.
C1 was characterized by upregulated activities in MYC targets, E2F targets, G2M checkpoint, and PI3K AKT mTOR. In addition, C1 had a high estimate score, hot immunity (such as immune checkpoint score, immune score, complement score, and immunogenic cell death score), and high disulfidptosis, while its tumor purity and TIDE score were low, as well as hypometabolism; C2 was characterized by downregulated PI3K AKT mTOR activity, cold immunity, high tumor purity, and hypermetabolism; C3 exhibited the lowest stemness, high estimate score and stromal score, hot immunity, low tumor purity, low DNA repair activity, and hypermetabolism; C4 showed the highest stemness, high G2M, high DNA repair, but low PI3K AKT mTOR activity, cold immunity, low estimate score and stromal score, high tumor purity, and hypometabolism (Figure 4E; Supplementary Table S5).
3.6 Gene set enrichment analysisGSEA revealed significant pathway alterations among the clusters. In C1, there was upregulation in pathways such as epithelial-mesenchymal transition (EMT), interferon response, and antigen processing, while pathways like adipogenesis, fatty acid metabolism, and oxidative phosphorylation were downregulated. Conversely, C2 exhibited the opposite trends in these pathways compared to C1. C3 showed upregulation in EMT, interferon response, coagulation, and complement pathways, with downregulation observed in the unfolded protein response, G2M checkpoint, E2F targets, and MYC targets. In C4, significant upregulation was observed in the G2M checkpoint, E2F targets, ribosome, and oxidative phosphorylation pathways, while its peroxisome, immune, and metabolic pathways were significantly downregulated (Supplementary Figure S3; Supplementary Table S6).
3.7 Characteristics of immune microenvironment among clustersWe characterized the immune landscape among the four clusters to infer their responses to immunotherapy. Immune and stromal cell infiltration was evaluated using six computational methods: XCell, MCPcounter, Timer, Quantiseq, EPIC, and Cibersort (Supplementary Figure S4A). Overall, clusters C1 and C3 had higher levels of immune and stromal cells compared to C2 and C4. Notably, C1 exhibited the highest abundance of CD8+ T cells and the highest cytotoxicity score, indicating a strong anti-tumor immune response. C3 showed the highest abundance of cancer-associated fibroblasts (CAF) and endothelial cells, suggesting a tumor-promoting microenvironment. In addition, C1 and C3 had the highest abundance of myeloid dendritic cells and macrophages, which have complex roles in antigen presentation and tumor progression.
Further investigation into the expression of human leukocyte antigen (HLA) genes and immune checkpoint genes (ICGs) revealed significant upregulation of multiple HLA genes and ICGs in C1, including HLA-A, HLA-B, HLA-C, PDCD1, CD274, CTLA-4, HAVCR2, LAG3, CD80, CD86, TIGIT, etc. In contrast, although C3 had upregulated expression of HLA genes, its ICGs expression was weak (Supplementary Figure S4B).
These findings indicate that C1 is in an immunosuppressive state, potentially making it more responsive to immune checkpoint blockade (ICB) therapies by alleviating this inhibition and thereby inducing an immune response.
3.8 Single nucleotide variation landscape among clustersConsidering that SNV can drive tumor progression by altering the structure of encoded proteins or regulating gene expression, therefore, we investigated the SNV landscape among clusters.
The SNV analysis showed that C1 exhibited high-frequency TP53 missense mutations (29.58%), low frequencies of TTN (15.49%) and CTNNB1 (15.49%) missense mutations; C2 harbored multiple high-frequency mutations, especially TTN (28.00% missense mutations and 13.00% silent mutations) and CTNNB1 (43.00% of missense mutations), with moderate TP53 mutations (13.00% of missense mutations); Notably, C3 had the lowest overall mutations among the four clusters; C4 was mainly characterized by high frequencies of TP53 (33.78% missense mutations) and TTN (25.68% missense mutations) mutations, while the frequency of CTNNB1 mutations was not significantly increased (27.03% missense mutations) (Figure 5).
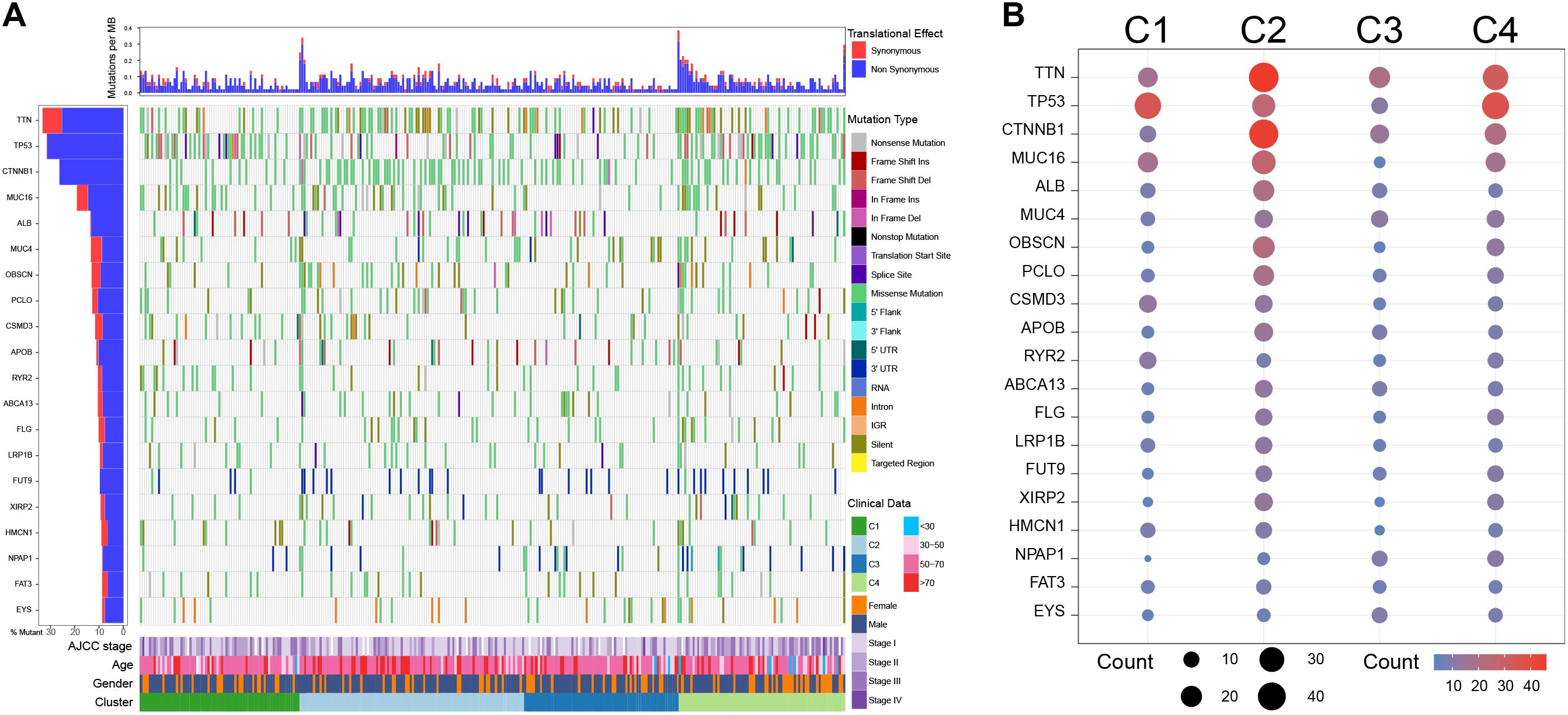
Figure 5. Single nucleotide variation analysis among clusters in the TCGA cohort. (A) Single nucleotide variation landscape among clusters. (B) Single nucleotide variation frequency among clusters.
3.9 Drug sensitivity evaluation among clustersTo evaluate the differences in drug sensitivity among clusters, we calculated the half-maximal inhibitory concentration values for 198 drugs. The results revealed distinct drug sensitivities for each cluster. C1 exhibited increased sensitivity to several drugs: gemcitabine, which interferes with DNA synthesis; cisplatin, which induces DNA cross-linking and damage; irinotecan, which inhibits topoisomerase I; and talazoparib, which inhibits poly ADP ribose polymerase (PARP). C2 was primarily sensitive to TAF1 inhibitor TAF1_5496_1732, which inhibits transcription; MCL-1 inhibitor AZD5991_1720, which promotes apoptosis; and mitochondrial inhibitor Dihydrorotenone_1827. C3 showed heightened sensitivity to nutlin-3a, which inhibits MDM2; selumetinib, which inhibits MEK1/2; mitoxantrone, which inhibits topoisomerase II, and gemcitabine. C4 was sensitive to Sepatronium bromide_1941, which inhibits survivin; Daporinad_1248, which inhibits nicotinamide phosphoribosyltransferase (NAMPT); and MK−1775_1179, which inhibits WEE1 and PLK1 in the cell cycle pathway (Supplementary Figure S5A; Supplementary Table S7).
We further investigated the correlation between drug sensitivity and TP53 mutations. The results showed that the expression of TP53 and MDM2 was higher in wild-type TP53 patients compared to those with TP53 mutations. Most patients in the C3 subtypes met the conditions of wild-type TP53 and high expression of MDM2, which could explain the sensitivity of nutlin-3a in C3 patients (Supplementary Figures S5B, C).
3.10 Single-cell analysis for characterization among clustersTo gain deeper insights into clusters at the cell-subpopulation level, we performed single-cell analyses. Following quality control, dimensionality reduction, clustering, and cell annotation, we identified eight distinct cell subpopulations (Supplementary Figure S6; Figures 6A, B).
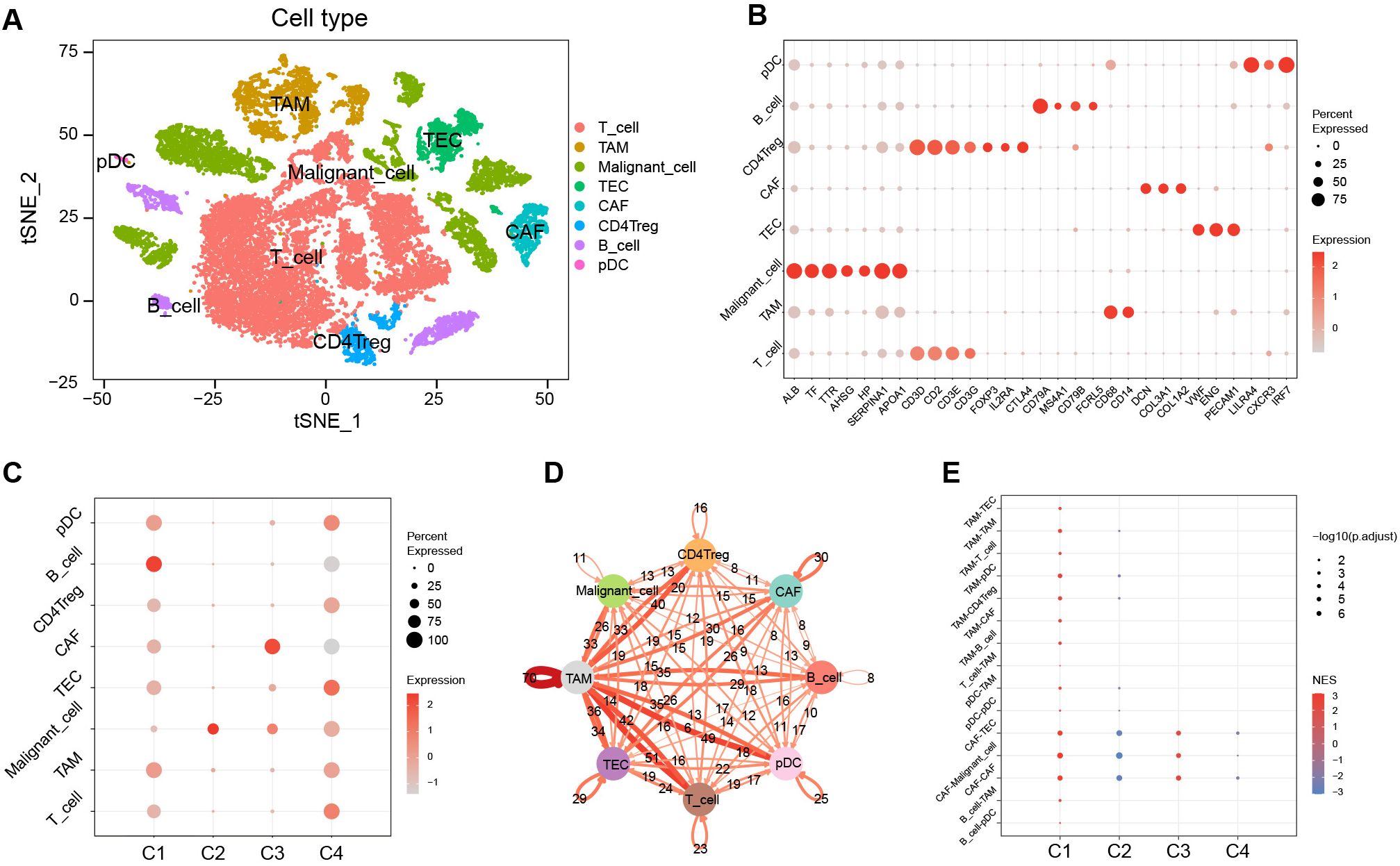
Figure 6. Characterization among clusters using scRNA-Seq data. (A) The tSNE plots of cell annotation for single-cell clusters. (B) Single-cell subpopulations and their annotation genes. (C) GSVA scores of upregulated marker gene sets of C1–C4 among the single-cell subpopulations. (D) Network of intercellular communication among single-cell subpopulations. (E) The activation level of intercellular communications among clusters in the TCGA cohort using the GSEA algorithm. tSNE, t-distributed stochastic neighbor embedding; GSVA, gene set variation analysis; TCGA, the Cancer Genome Atlas; GSEA, gene set enrichment analysis; NES, normalized enrichment score.
We evaluated the significantly upregulated marker gene sets of C1–C4 using the GSVA algorithm in single cells (Figure 6C). The results showed that the activity of the characteristic gene set of C1 was upregulated in various immune cell types, yet exhibited downregulated activity in malignant cells. In contrast, the activity of the characteristic gene set of C2 was significantly upregulated in malignant cells. The characteristic gene set of C3 showed pronounced activation in CAF, whereas the C4 characteristic gene set displayed activation across various cell types, predominantly in TEC, but showed diminished activity in B cells and CAF.
Cell-cell communication analysis revealed that tumor-associated macrophages (TAM) played a pivotal role in intercellular interactions within HCC (Figure 6D). The intercellular-interaction gene sets were used as reference gene sets for the GSEA enrichment analysis of C1–C4 based on bulk RNA-seq clustering (Figure 6E). The results showed upregulations of TAM-mediated and CAF-mediated intercellular communication in C1, a downregulation of CAF-mediated intercellular communication in C2, and an upregulation of intercellular communication mediated by CAF in C3 (P < 0.05). However, there was no significant enrichment of intercellular communication observed in C4.
3.11 Development of the classifier and validation for response to anti-PD1 therapyTo efficiently identify the molecular subtypes of patients in real-world settings, we developed a classifier using the random forest (RF) algorithm (Figure 7A).
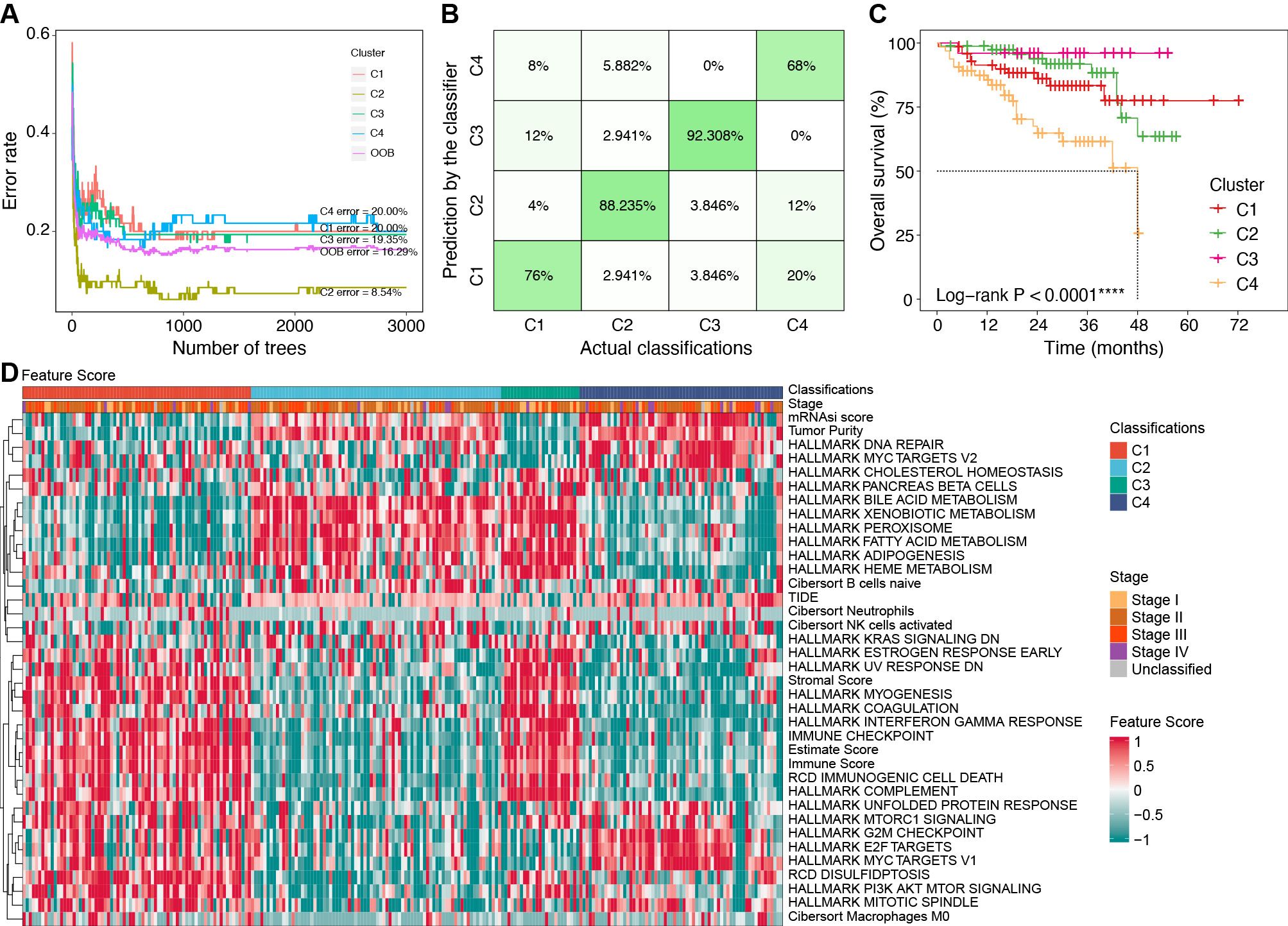
Figure 7. Construction of classifier using the RF algorithm. (A) Error rates of the RF model using the 521 cluster-specific marker genes. (B) The accuracy in the TCGA internal validation cohort by the RF classifier. (C) Survival curves by the RF classifier in the ICGC external validation cohort. (D) Characteristics of key feature scores among classifications predicted by the RF classifier in the ICGC external validation cohort. ****P < 0.0001. RF, random forest; TCGA, the Cancer Genome Atlas; ICGC, the International Cancer Genome Consortium.
We identified 521 cluster-specific marker genes using the “FindAllMarkers” function (Supplementary Table S8). Based on these marker genes, the RF classifier achieved an overall prediction accuracy of 81.82% with a 95% confidence interval (CI) of 73.33%–88.53% in the TCGA internal validation cohort. The prediction accuracy for each subtype by the RF classifier is presented in Figure 7B.
In the ICGC external validation cohort, the molecular classifications were predicted using the RF classifier. Compared to the TCGA cohort, the predicted classifications in the ICGC cohort exhibited consistent prognostic characteristics (median OS: C3 > C2 > C1 > C4, P < 0.001, Figure 7C). We also evaluated the characteristics of FSs (Figure 7D), immune cell infiltration (Supplementary Figure S7A), and immune genes (Supplementary Figure S7B) in the ICGC cohort. These validation results were consistent with the characteristics in the TCGA cohort, which further confirmed the robustness and reliability of our classifier.
Using our classifier, we further tested the hypothesis that C1 is more sensitive to anti-PD1 therapy in two external cohorts including 81 patients. Among them, the PRJEB34724 cohort enrolled 40 patients (6 responders and 34 non-responders), and the GSE202069 cohort enrolled 17 patients (8 responders and 9 non-responders).
The results showed that the immune cell infiltration and ICG expression profiles among the four subtypes were highly similar to the corresponding subtypes in the TCGA cohort (Figure 8A). Notably, we confirmed that patients in the C1 subgroup had a higher anti-PD1 response rate of 47.37% (9/19, P = 0.01), especially in the GSE202069 cohort with a response rate of 75% (6/8). Moreover, none of the C3-subtype responders were found in either of the two cohorts (Figures 8B, C).
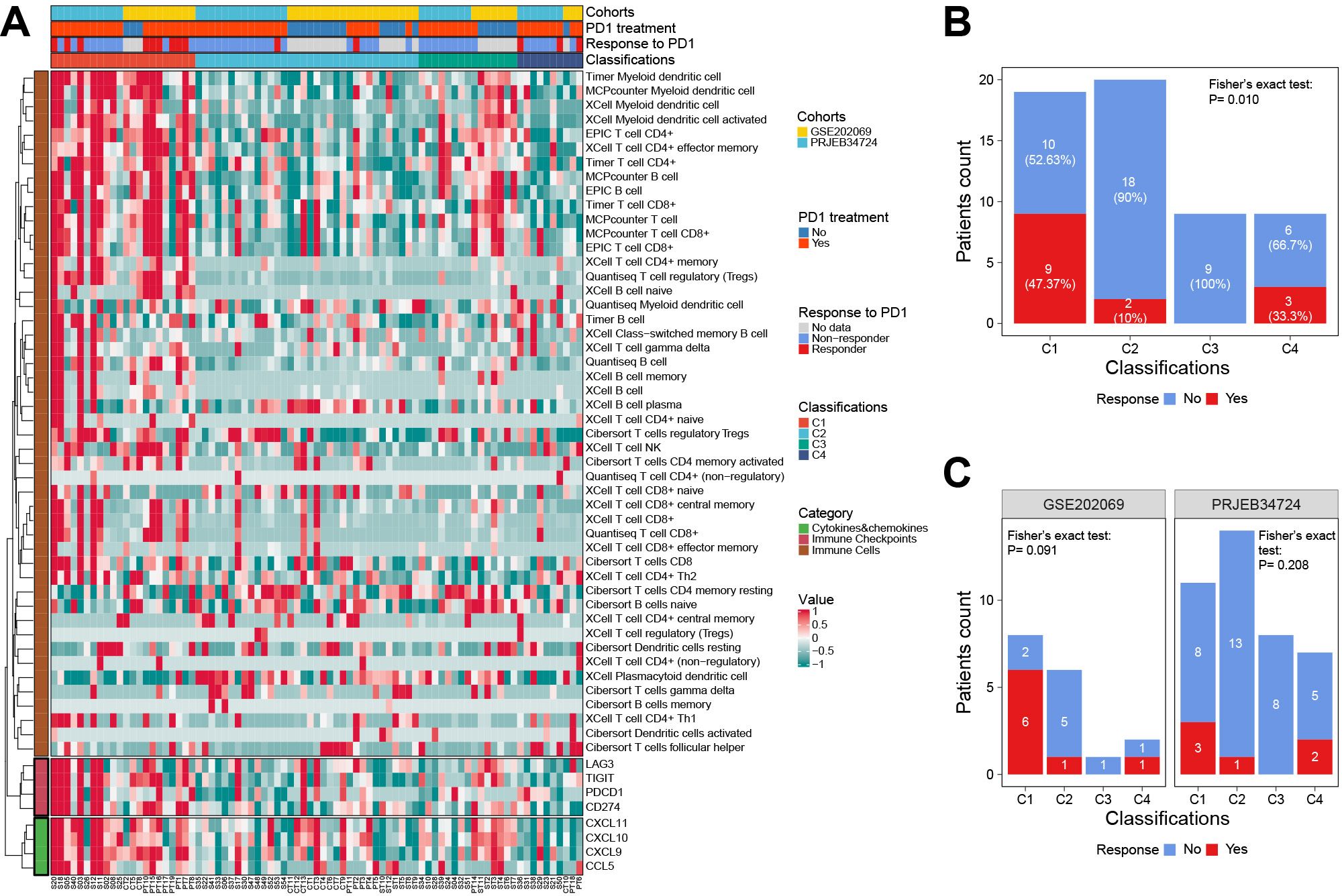
Figure 8. The response to anti-PD1 therapy among classifications in two external validation cohorts. (A) The heat map showed the classifications predicted by the RF classifier and the details of response to anti-PD1 therapy. (B) The correlation between the response to anti-PD1 therapy and classifications predicted by the RF classifier. (C) Subgroup analysis showed the response to anti-PD1 therapy in each cohort. RF, random forest.
3.12 Development of the prognostic nomogramTo develop the prognostic nomogram, we identified 70 genes based on the intersection of cluster-specific marker genes and HCCDB prognostic genes. Then seven models were evaluated using the random survival forest (RSF) (Supplementary Figures S8A–C), the least absolute shrinkage and selection operator (LASSO) combining 10-fold cross-validation (Supplementary Figures S8D, E), and stepwise Cox regression. The details of covariables included in the seven models are shown in Supplementary Table S9.
Using the 3-fold 1000-time-repeation cross-validation, the median concordance index (C-index) of the LASSO combined with stepwise Cox regression and tumor staging (LASSO-Stage) model achieved 0.770 in the training cohort and 0.810 in the TCGA inner validation cohort (Supplementary Figure S8F). In addition, we compared the time-dependent receiver operating characteristic curves and found that the LASSO-Stage model had higher values of area under curves at different time points (Supplementary Figures S8G–J). Therefore, the 9-variable LASSO-Stage model was relatively simple and accurate, and accordingly was used to develop the prognostic nomogram (Figure 9A). The C-index of the nomogram was 0.782 (95% CI, 0.709–0.855) in the external ICGC validation cohort. The calibration curves demonstrated good consistency between the nomogram predictions and actual outcomes (Figures 9B–E).
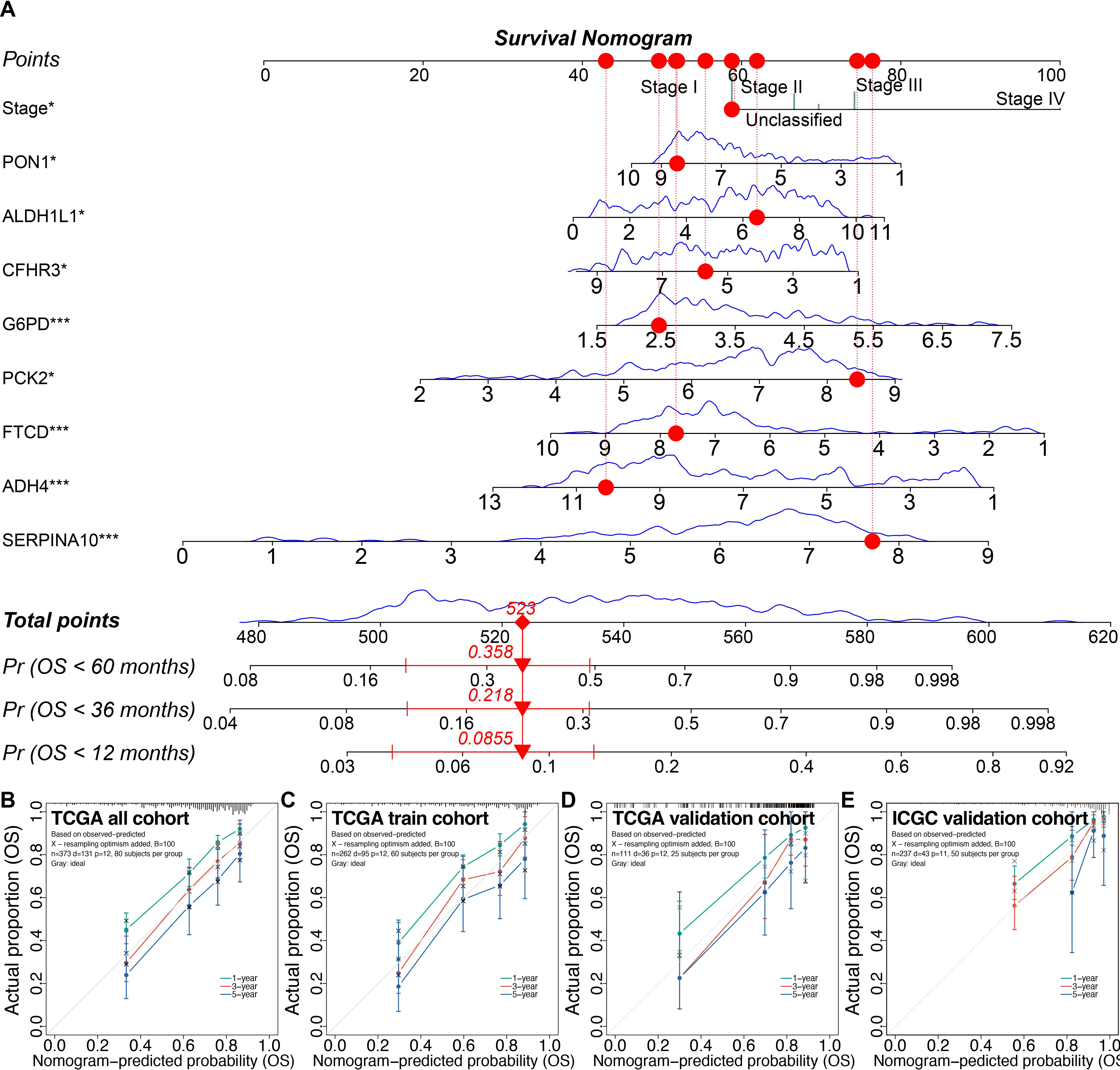
Figure 9. Prognostic nomogram and calibrations in the training and validation cohorts. (A) The prognostic nomogram. (B–E) The calibration plots of the nomogram in the TCGA all cohort (B), the TCGA training cohort (C), the TCGA inner validation cohort (D), and the ICGC external validation cohort (E). *P < 0.05, ***P < 0.001. TCGA, the Cancer Genome Atlas; ICGC, the International Cancer Genome Consortium.
Decision curve analysis indicated that the 9-variable nomogram model was almost as effective as the 26-variable Step-Cox model. Patients could benefit from the nomogram when the risk thresholds range from 0.036 to 0.66 (Supplementary Figures S9A, B).
Using the nomogram, the risk scores were calculated for all patients, and the iterative stratification method was used to divide the training cohort into three stratifications (P < 0.001). Using the thresholds of the training cohort, patients in the validation cohorts could be divided into significant prognostic stratifications (P < 0.01) (Supplementary Figures S10A–C). The risk curves and survival status demonstrated that the risk scores of patients predicted by the nomogram were positively related to their death risk (Supplementary Figures S10D–F).
To facilitate classification and prognosis prediction, we developed an R package called “oncoClassSurv” (https://github.com/OliveryYL/oncoClassSurv), which has a corresponding desktop executable version (https://github.com/OliveryYL/oncoClassSurv_Expansion/) and a web-based Shiny calculator (https://oncomanager.shinyapps.io/oncoClassSurv/).
3.13 Target gene screen and characterization of biological functionsWe identified four crucial prognostic genes through Venn analysis of multiple models (Figure 10A). Protein expression profiling and immune fluorescence indicated that FTCD was significantly downregulated in HCC (P < 0.001, Figures 10B, C). Survival analysis revealed that patients with elevated FTCD expression had a significantly improved prognosis compared to those with diminished expression in the TCGA cohort (P < 0.001, Figure 10D). FTCD expression was relatively upregulated in C2 and C3 with a favorable prognosis, while it was downregulated in C1 and C4 with a poorer prognosis (Supplementary Figure S11).
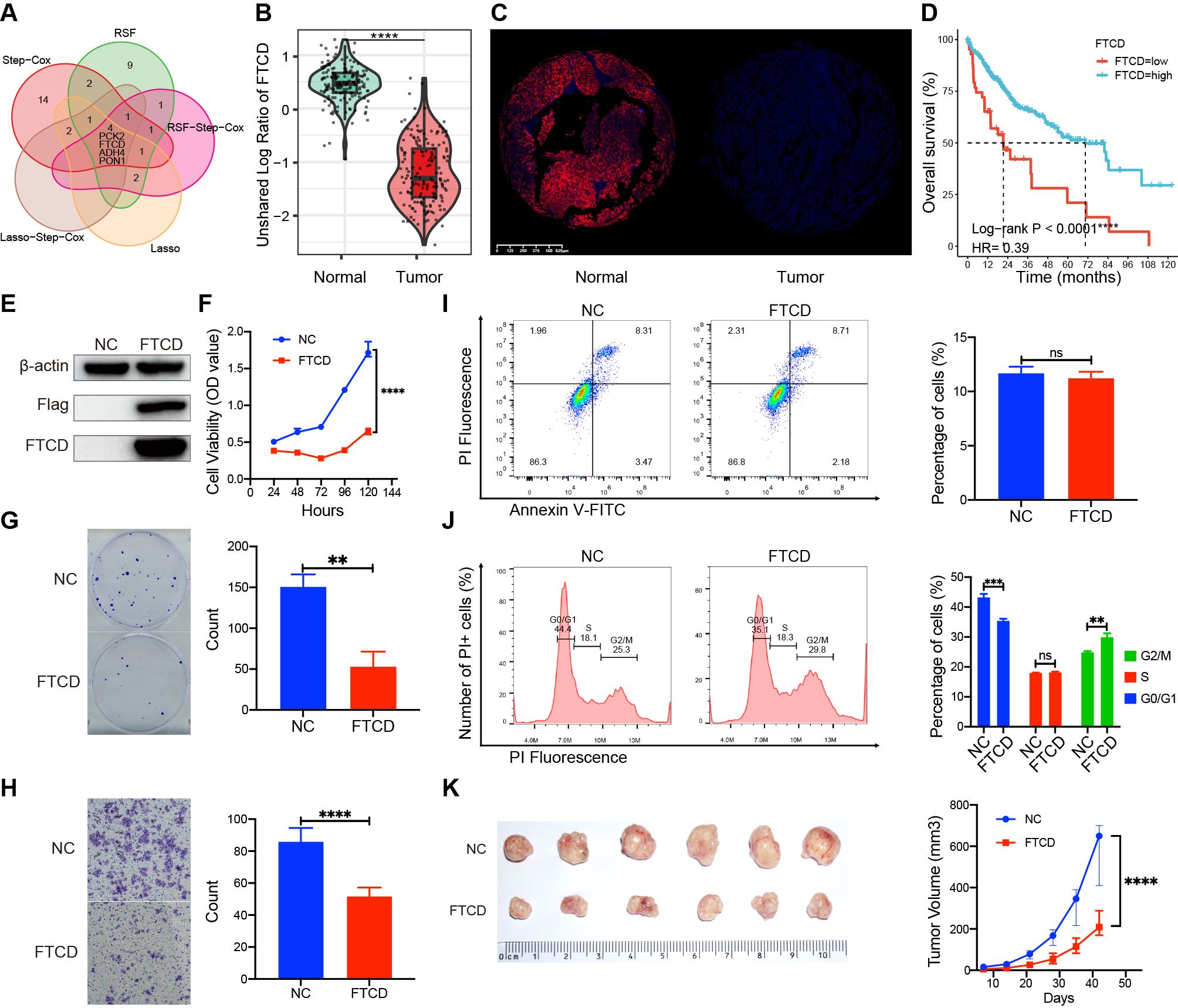
Figure 10. Expression differences, prognostic roles, and biological functions of FTCD. (A) Identification of prognostic key genes through Venn analysis. (B) The protein expression difference in FTCD was assessed by the CTPAC proteomic database. (C) The protein expression difference in FTCD was assessed by the immunofluorescence experiment. (D) Survival curves of FTCD expression levels in the TCGA database. (E) Protein expression of FTCD-overexpressing Huh7 cell lines by Western blot. (F) The Cell Counting Kit-8 (CCK-8) assay assesses the cell viability. (G) Colony formation assay assesses the clonogenic ability of cells. (H) The transwell assay was used to evaluate the cell migration ability. (I) Flow cytometry was used to evaluate changes in cell apoptosis. (J) Flow cytometry was used to assess alterations in the cell cycle. (K) Subcutaneous tumorigenicity assay in nude mice was used to evaluate the impact on the progression of tumors. **P < 0.01, ***P < 0.001, ****P < 0.0001, ns, not significant.
We established FTCD-overexpressing Huh7 cell lines (Huh7-FTCD) and negative control (Huh7-NC) via lentiviral transduction (Figure 10E). Cell proliferation assays indicated that FTCD overexpression significantly inhibited the viability of Huh7 cells (Figure 10F). Colony formation assays demonstrated a reduced clonogenic ability in Huh7-FTCD cells (Figure 10G); Transwell assays revealed a significantly decreased migration ability in Huh7-FTCD cells (Figure 10H). Apoptosis assays showed no significant difference between Huh7-FTCD and Huh7-NC cells (Figure 10I), while the Huh7-FTCD cells exhibited G2/M cell cycle arrest compared to Huh7-NC cells (Figure 10J). Subcutaneous tumorigenicity assay in nude mice indicated that tumor progression originating from the Huh7-FTCD cells was significantly slower than that from the Huh7-NC cells (Figure 10K).
4 DiscussionHCC is a highly heterogeneous disease with complex biological characteristics. In the emerging era of precision medicine, it is essential to identify the classifications based on their molecular characteristics. Although several schemes for HCC have been proposed, they often have some limitations. These include a narrow focus on specific dimensions, a lack of validation with external cohorts, and impracticality due to the absence of user-friendly software or overly complex metrics. Thus, the current study was mainly designed to comprehensively characterize HCC heterogeneity across multiple dimensions, develop practical predictive software, and explore the potential therapeutic strategies customized for different subtypes.
Previous studies have proposed several molecular classifications of HCC. A proteogenomic study conducted by Qiang Gao and Jia Fan, et al., categorized hepatitis B virus-associated HCC patients into three distinct subgroups: the metabolic subgroup (S-Mb), the microenvironment dysregulation subgroup (S-Me), and the proliferative subgroup. S-Mb showed enrichment in cancer metabolism and had a favorable prognosis. In contrast, S-Me exhibited enrichment in immunity-related features, with a worse prognosis compared to S-Mb (13). Other classifications mainly focused on a few certain pathways, such as immune or metabolic-related pathways. Chen Yang et al. proposed a three-layered classifier based on the metabolic gene sets (9), while Binghua Li et al. developed a three-layered classifier based on the fatty acid degradation pathway (12); Additionally, Jiao Gong et al. developed a three-layered classifier based on the immunologic and hallmark gene sets (10). Montironi et al. described the immune genome background of HCC, dividing it into inflammatory and non-inflammatory tumors (11). Recently, the study by Shimada S et al. summarized the past development of molecular classifications of HCC, highlighting the importance of characterizing HCC subtypes (34). Our study contributes to this field by developing a molecular typing system with four subtypes based on proliferation, microenvironment (immune/stromal), and metabolic activity. We compared our subtypes with previously identified subtypes and found interesting overlaps. For instance, our C1 subtype shares similarities with previously reported subtypes like MFP-IE, inflammatory, or FAD-F1 subtype, while C2, with its CTNNB1 mutations and immune therapy response patterns, is consistent with previous findings. This comparison helps explain our classification system and provides insights into HCC heterogeneity.
We appreciate their groundbreaking studies. However, these schemes also have acknowledged limitations, as mentioned previously. To characterize the complex heterogeneity of HCC, we conducted comprehensive analyses across multiple FSs dimensions. In addition, we integrated single-cell data analysis and combined the TIME-MFP typing system to scrutinize the characteristics of subtypes. Among the initial 89 FSs, the selected signal pathways act as significant roles across various malignancies (35–40); mRNAsi can represent the stemness characteristics closely related to tumor proliferation and progression (41, 42); Metrics such as TIDE score, MFP typing, immune score, immune checkpoint, and immune cell infiltration can reflect the TIME and contribute to clarifying the relationship between subtypes and immune response (25–27, 30). The integrated tumor metabolic score can reflect the metabolic reprogramming characteristics of HCC, and the m6A and m5C gene sets are hot fields involving RNA modification (43–45). The 37 key FSs were rigorously selected from the initial FSs through differential expression and survival analyses to ensure their relevance to HCC’s biological characteristics. Therefore, our classification system encompasses multiple critical dimensions, providing robust evidence for precise management and research.
In this study, we performed unsupervised clustering analysis on the FSs derived from TCGA-LIHC and generated a clustering heatmap of the FSs (Figure 4E). After predicting molecular classifications on the ICGC-LIRI-JP dataset using our tool, we generated another clustering heatmap (Figure 7D). According to the FSs clustering heatmaps, HCC exhibited complex heterogeneity and could be stratified into four subtypes (C1–C4) from the three major fields: stemness proliferation, metabolism, and microenvironment (stroma-riched or immunity-riched). Stemness-proliferation-related FSs include G2M, MYC, E2F, PI3K AKT mTOR, mRNAsi, and DNA repair activity, etc. From the perspective of stemness proliferation, both C1 and C4 exhibited high G2M, MYC, E2F activities, and MKI67 expression levels. Besides, C1 had high PI3K AKT mTOR activity, while C4 had high mRNAsi and DNA repair activity. Therefore, both C1 and C4 exhibited high stemness-proliferation characteristics. In contrast, C2 and C3 had lower levels of MKI67, mRNAsi, G2M, MYC, and E2F, indicating a low proliferative phenotype. Metabolism-related FSs include HALLMARK BILE ACID METABOLISM, HALLMARK XENOBIOTIC METABOLISM, HALLMARK ADIPOGENESIS, and HALLMARK FATTY ACID METABOLISM, etc. From the perspective of metabolism, C1 and C4 were hypometabolic, while C2 and C3 were hypermetabolic. Microenvironment-related FSs can be divided into two subcategories: immune-related FSs and stroma-related FSs. Immune-related FSs include immune cell infiltration proportions, immune score, TIDE, RCD immunogenic cell death, HALLMARK COMPLEMENT, immune checkpoint, and HALLMARK INTERFERON GAMMA RESPONSE. Stroma-related FSs include stromal score, estimate score, and tumor purity. From the perspective of microenvironment, both C1 and C3 exhibited rich microenvironment phenotypes. C1 was particularly immune-rich with high lymphocyte infiltration and overexpression of multiple HLA genes and suppressive immune checkpoint genes. Most of C1 belonged to the MFP-IE subtype (37.50%) with a high potential for response to anti-PD1 therapy (30); C3 was mainly a stroma-rich subtype, rich in CAF, with overexpression of HLA genes, and diminished expression of suppressive immune checkpoint genes. Most patients of C3 were MFP-F subtype (47.67%) and MFP-IE subtype (32.56%). C2 and C4 were stroma-desert, immune-desert, and highly tumor-purity subtypes, with most of C2 (64.29%) and C4 (72.15%) belonging to the MFP-D subtype. Thus, considering the correlation with immune and MFP classifications, it can be inferred that C1 may be more suitable for anti-PD1 treatment.
Considering the characteristics of pseudo-temporal trajectory, staging, and prognosis, C3 was the closest subtype to normal tissue and in the early phase of the disease, with the most favorable prognosis. C2 was in the middle phase of the disease with a good prognosis, only inferior to C3. C1 was in the middle or late phase of the disease with a poor prognosis. C4 was in the late phase of the disease with the worst prognosis.
Gene mutations are known to drive various tumors (46). Multiple studies have indicated that TP53 mutation is an important tumor driver associated with poor prognosis (47–49). In the current study, the mutation frequency of TP53 (C4 > C1 > C2 > C3) was closely correlated with the prognosis of different subtypes (median OS: C4 < C1 < C2 < C3). Previous studies suggested that patients with wild-type TP53 and high expression of MDM2 would be more sensitive to MDM2 inhibitors (50). Interestingly, most C3 patients fit this condition, which accounted for their high sensitivity to nutlin-3a (Supplementary Figure S5); In addition, the mutation rates of CTNNB1 were higher in C2, while they were both lower in C1 and C3. CTNNB1 encodes β-catenin, and the previous study suggested its mutations can activate the WNT/β-catenin signaling pathway, which is commonly found in immunotherapy-unresponsive individuals (32). Accordingly, we made the following inference that C2 is relatively not suitable for anti-PD1 therapy due to their immune-desert characteristics and higher CTNNB1 mutations. This inference can be verified by external cohorts experiencing anti-PD1 therapy in the following analysis. Moreover, we identified the most sensitive drugs for each subtype, which could provide references for further research.
We further investigated the cluster characteristics at the single-cell level. The results of the single-cell analysis exhibited high consistency among clusters with the immune-related findings from the bulk RNA-Seq data in the TCGA cohort. For instance, C1 is enriched in immune cells, while C3 is enriched in CAF. C2 is predominantly composed of malignant cells with a lack of immune cells. These findings provide insights into the varied responses to anti-PD1 therapy among clusters from the single-cell perspective.
To verify our inference of sensitivity to immune therapy in external cohorts, we first needed to accurately predict their classifications. To achieve this, we constructed a four-layer classifier based on the TCGA cohort using the RF algorithm, which performed well in the external ICGC cohort. The predicted classifications of the external ICGC cohort showed consistent characteristics, including prognostic outcomes and FSs among distinct classifications, compared to the TCGA cohort. Using the robust classifier, we further conducted another external validation in two datasets experiencing anti-PD1 therapies to evaluate the response to anti-PD1 therapy. The encouraging results confirmed our inference that the C1 subtype has the highest response to anti-PD1 therapy.
We conducted multivariate analyses to assess the prognostic values of the selected genes using machine learning algorithms. The critical classification-specific prognostic genes were selected and used to develop a prognostic nomogram. This nomogram has excellent prediction ability and can provide personalized prognostic evaluations.
Based on the above investigations, we further developed practical prediction software that can be applied to evaluate the classifications and prognosis of HCC, including three versions: local R program, desktop executable software, and web-based application. These tools can also utilize customized expression profiles and classification-specific marker genes to expand to other diseases.
Furthermore, we propose that the functional characterization for molecular typing marker genes can serve as a novel anti-tumor target screening approach. This screening strategy holds promise for precise patient screening and decision-making based on molecular classifications in the future. To explore targets with high potential therapeutic values, we performed Venn analysis and expression profiling differential analysis for the prognostic genes, and identified FTCD as a critical prognostic gene with significant expression differences.
In the clinical cohort, FTCD expression is downregulated in C1 and C4 subtypes, which is correlated with increased tumor malignancy and poorer patient outcomes. In contrast, C2 and C3 subtypes exhibit FTCD overexpression with more favorable prognoses.
A previous study indicated that hepatocyte-specific knockout of FTCD can promote chronic diethylnitrosamine-induced and spontaneous HCC in mice. The Loss of FTCD upregulated peroxisome proliferator-activated receptor (PPAR)γ and sterol regulatory element-binding protein 2 (SREBP2) by regulating the PTEN/Akt/mTOR signaling axis, leading to lipid accumulation and hepatocarcinogenesis (51).
Our investigation into FTCD’s biological roles further revealed its tumor-suppressive function. A series of cell and animal experiments suggested that FTCD overexpression can significantly inhibit the progression both in vitro and in vivo (Figure 10). Thus, diminished FTCD expression is a key driver of disease progression in C1 and C4 subtypes. Enhancing FTCD expression in these patients may lead to substantial therapeutic gains. In future scientific research and clinical management, we may refine tumor biological behavior and patient outcomes through targeted delivery methods, such as mRNA-liposome nanomedicine, to boost FTCD expression levels in HCC tissues. Accordingly, the FTCD gene emerges as a viable therapeutic target for C1 and C4 patients. Certainly, these findings warrant further investigation for validation.
5 ConclusionsIn summary, we proposed a novel molecular classification scheme for HCC based on the multidimensional FSs. The four-layer classification scheme reveals the complex heterogeneity of HCC through comprehensive characterization. We also developed and validated predictive software. Notably, our research confirmed that the C1 subtype is more responsive to anti-PD1 treatment, and identified FTCD as a promising therapeutic target, particularly for C1 and C4. These findings provide robust evidence for individualized disease evaluation, decision-making, and further scientific research.
Data availability statementThe original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
Ethics statementThe animal study was approved by Ethics Committee of Zhejiang Cancer Hospital. The study was conducted in accordance with the local legislation and institutional requirements.
Author contributionsYL: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft. YD: Writing – review & editing. JW: Writing – review & editing. XW: Writing – review & editing. DZ: Writing – review & editing. HZ: Writing – review & editing. PZ: Conceptualization, Funding acquisition, Supervision, Writing – review & editing. GS: Resources, Supervision, Writing – review & editing.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study was supported by the National Natural Science Foundation of China (No. 82202274), the Science and Technology Development Program of Hangzhou (No. 202204B04), and the Projects from China Postdoctoral Science Foundation (No. 2021T140646).
AcknowledgmentsWe are grateful to Prof. Kai Gao from Hangzhou Institute of Medicine (HIM), Chinese Academy of Sciences for her advice on our work.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fimmu.2024.1466069/full#supplementary-material
AbbreviationsHCC, hepatocellular carcinoma; FSs, feature scores; OS, overall survival; mRNAsi, mRNA stemness index; TIDE, tumor immune dysfunction and exclusion; SNV, single nucleotide variation; TIME, tumor immune microenvironment; RNA-Seq, RNA sequencing; TCGA, the Cancer Genome Atlas; ICGC, the International Cancer Genome Consortium; GSVA, gene set variation analysis; scRNA-Seq, single-cell RNA sequencing; RF, random forest; MFP, molecular functional portrait; CAF, cancer-associated fibroblasts; HLA, human leukocyte antigen; ICGs, immune checkpoint genes; ICB, immune checkpoint blockade; KEGG, Kyoto Encyclopedia of Genes and Genomes; GSEA, gene set enrichment analysis; EMT, epithelial-mesenchymal transition; PCA, principal component analysis; TEC, tumor endothelial cell; TAM, tumor-associated macrophage; CI, confidence interval; RSF, random survival forest; LASSO, least absolute shrinkage and selection operator; C-index, concordance index; CDF, consensus cumulative distribution function; tSNE, t-distributed stochastic neighbor embedding; ES, enrichment score; AUC, area under curve; DCA, decision curve analysis.
References1. Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, et al. Global Cancer Statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. (2021) 71:209
留言 (0)