
記住我
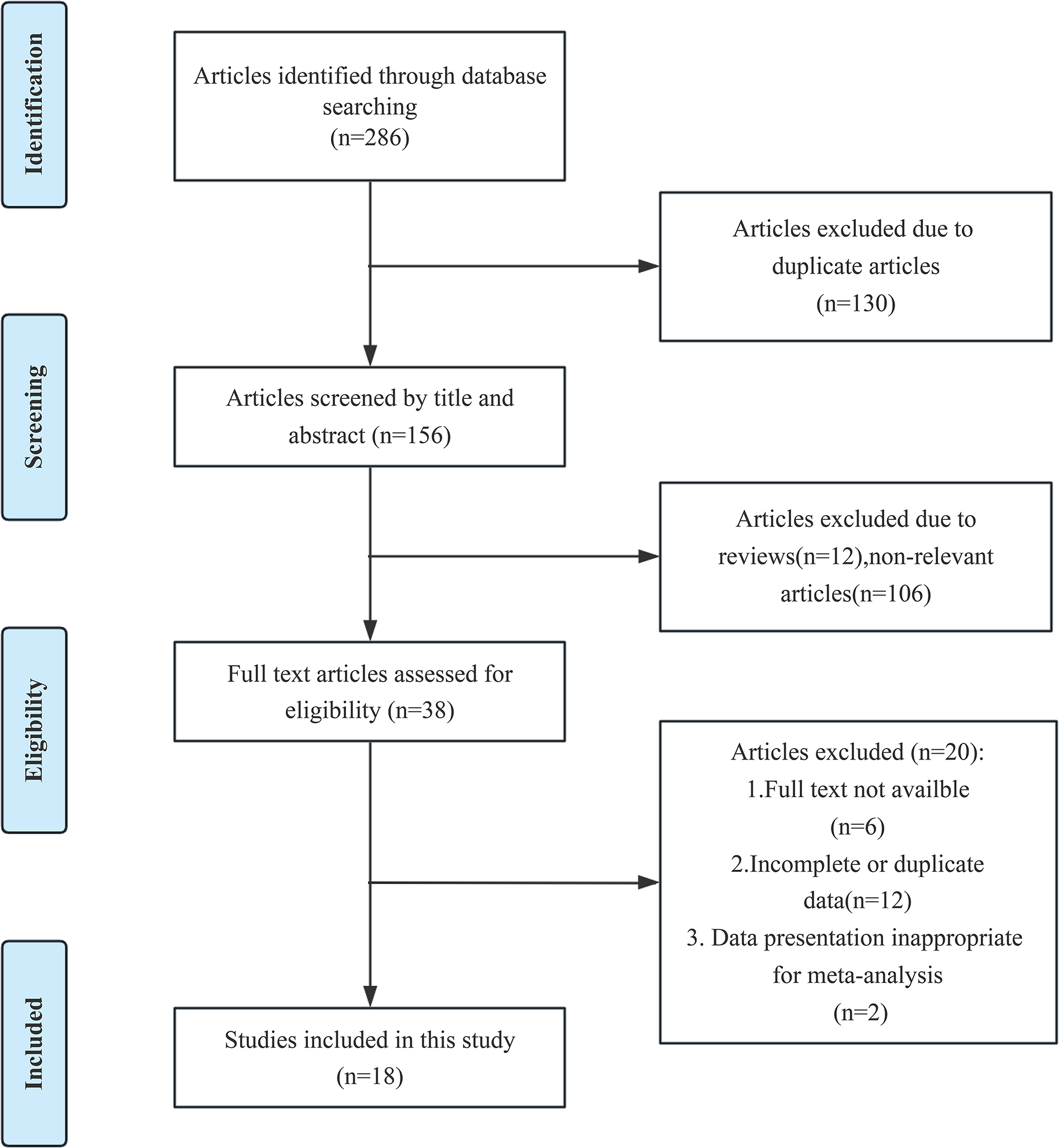

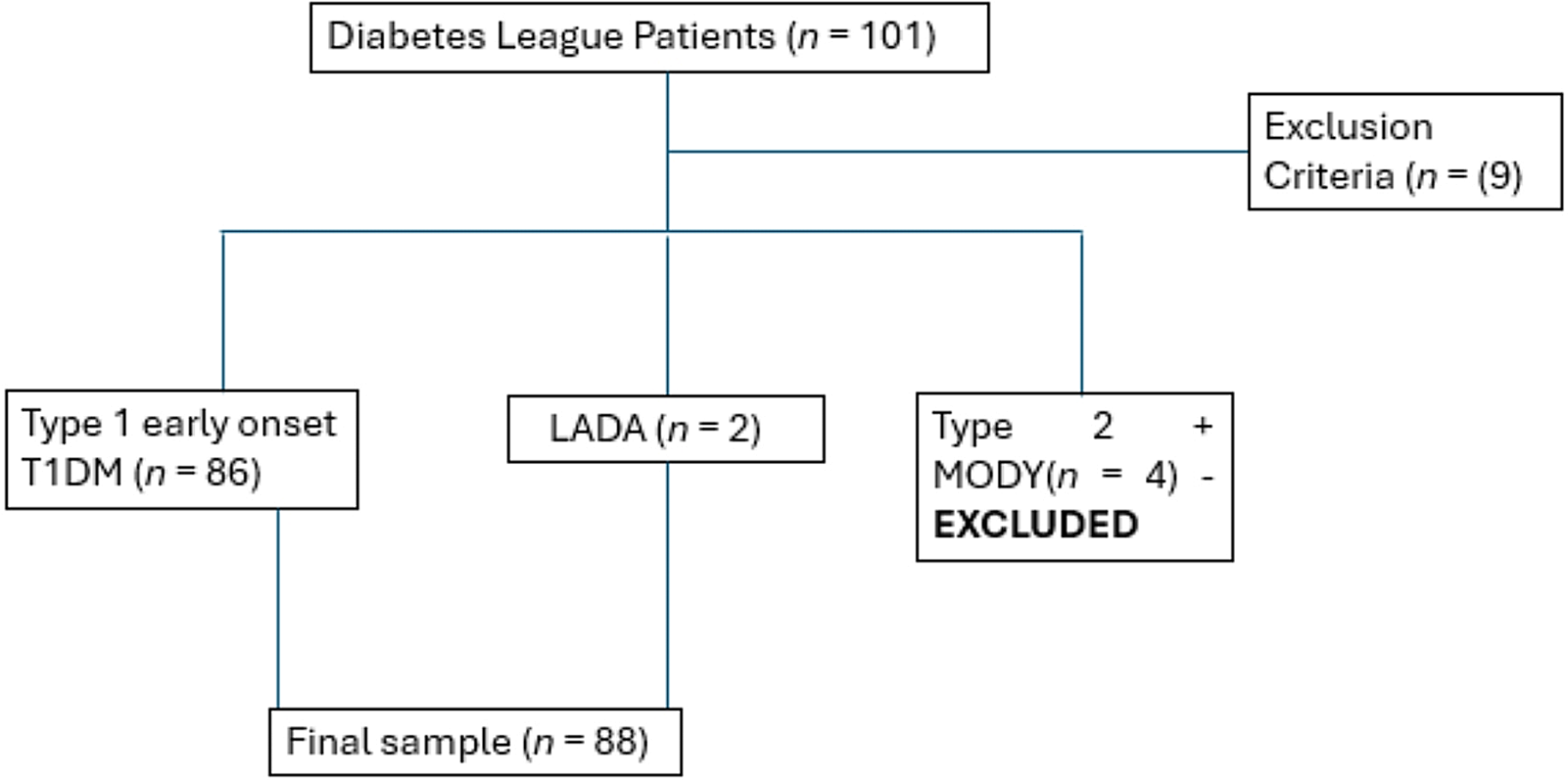
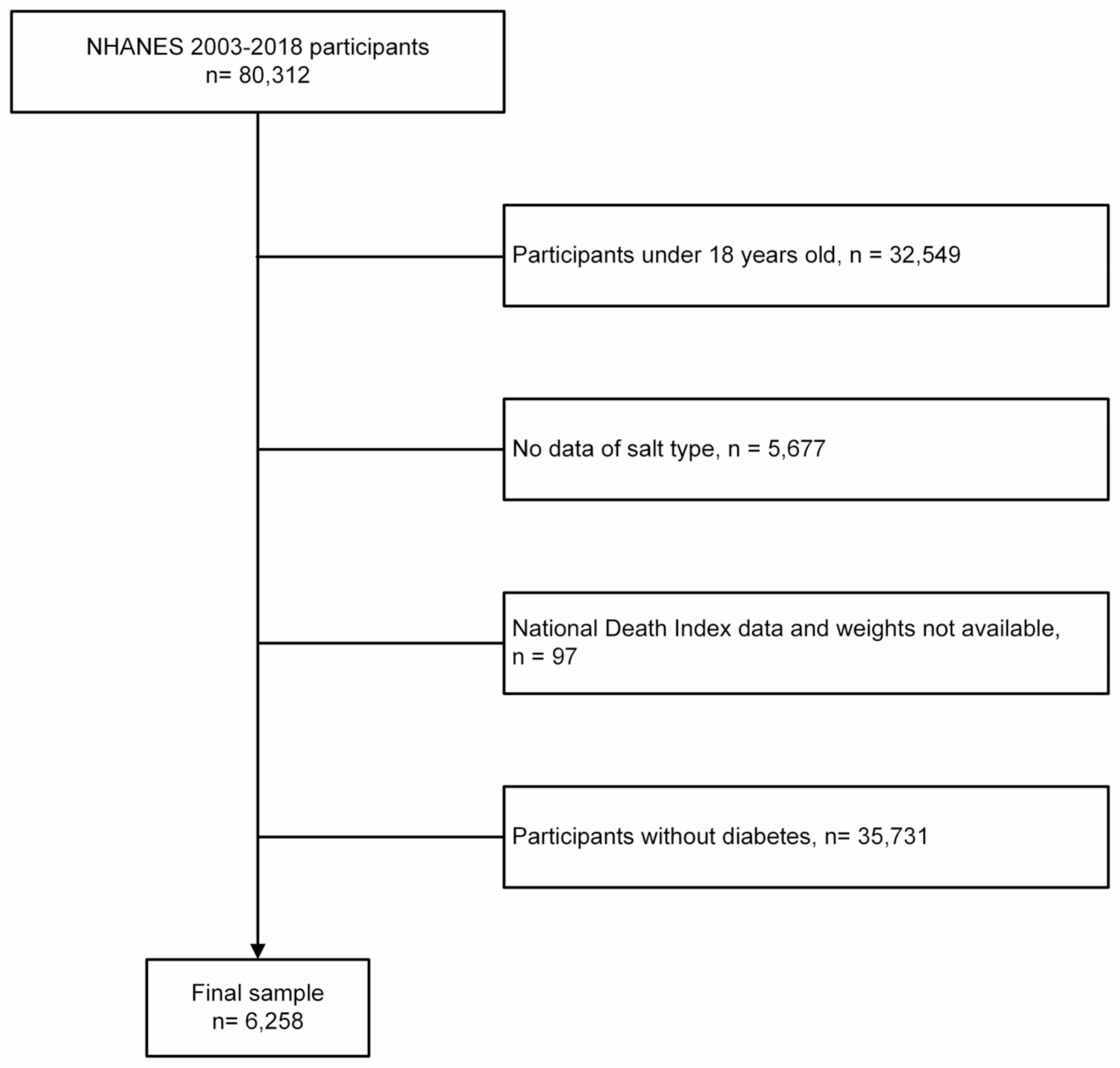
NHANES is a continuous, multistage, nationally representative survey of the noninstitutionalized civilian resident population of the United States. This study included 8 cycles between 2003 and 2004 and 2017–2018. Participants without data of type of table salt used were excluded. Participants aged under 18 years old were excluded. Pregnant women were excluded. Participants without history of diabetes were excluded. Participants not eligible for National Death Index were excluded. Adults with diabetes were defined as meeting one of three criteria: (1) self-reported history of diabetes, (2) receipt of oral glucose-lowering medicines or insulin, or (3) glycated hemoglobin A1c (HbA1c) level of at least 6.5%. After exclusion, a total of 6,278 participants were defined as adults with diabetes (Fig. 1).
Fig. 1
Flow chart of the study. NHANES, the National Health and Nutrition Examination Survey
Measurement of usage of table salt usedThe usage of salt used in the diet was the primary focus of interest. Trained interviewers conducted in-home interviews to collect dietary intake data from participants. Participants were asked to participate in two 24-hour total nutrient recall interviews. The data on the type of salt used was collected from the first 24-hour recall. Four types of table salt were reported in the interview: ordinary salt, lite salt, salt substitutes, and not using or adding salt products at the table.
However, due to the limited sample size of lite salt and salt substitutes (246 and 155 participants, respectively), the participants were divided into two groups based on the type of table salt used: Group 1 consisted of individuals who either consumed ordinary salt, lite salt, or salt substitute, while Group 2 consisted of individuals who didn’t use or add salt products at the table.
CovariatesThe data set included sociodemographic variables, including age, sex, race, and ethnicity, which were collected using a standardized questionnaire. Self-reported race was in 6 categories, and we grouped participants into 4 mutually exclusive racial and ethnic categories: non-Hispanic Black, Hispanic, non-Hispanic White, and other (includes races other than non-Hispanic white, non-Hispanic black, or Hispanic, including multiracial). In addition, family income-poverty ratio and educational attainment were also assessed as demographic variables in the interview. The family income-to-poverty ratio, which varies depending on the size and composition of the family, was employed to ascertain the poverty status of individuals and categorize them as having an income below 1.5, between 1.5 and 3.5, or above 3.5 [15]. The participants’ educational attainment was determined by their self-reported highest grade or level of education completed and categorized as having completed less than a high school graduated, high school graduated, or higher than high school graduated.
Behavioral and metabolic variables including smoking status, body mass index, and level of HbA1c were included. Individuals who had smoked more than 100 cigarettes in their lifetime were classified as smokers, while others were defined as non-smokers. Smokers were further classified as either ever smokers or current smokers. The body mass index (BMI) was calculated as weight in kilograms divided by height in meters squared. The BMI was subsequently categorized as lower than 25, 25 to 30, or 30 or higher. Individuals were divided into two groups based on HbA1c data, with a cutoff value of 6.5%. The data of serum alanine aminotransferase (ALT), aspartate aminotransferase (AST), gamma-glutamyl transferase (GGT), lactate dehydrogenase (LDH), total bilirubin, triglycerides, and creatinine were collected as continuous variables. Strict protocols were followed during blood collection and analysis, as outlined in the NHANES Laboratory/Medical Technician Protocols Manual [16]. The estimated glomerular filtration rate (eGFR) is calculated using the serum creatinine concentration [17].
Dietary data on sodium intake, potassium intake, and total energy intake were collected on the first and second days of dietary recall. The mean of the two-day data was utilized for subsequent analysis. To assess the quality of the diet, data on the Healthy Eating Index-2020 (HEI-2020) were calculated [18]. However, as the equations of the HEI were revised after 2005, only the HEI data from that point onwards were included in the analysis.
Comorbid conditions were also collected, including hypertension, cardiovascular disease, and cancer. Participants were asked if they had a history of hypertension, and if they answered “Yes,” they were defined as having a history of hypertension. Participants with a self-reported history of congestive heart failure, coronary heart disease, angina, myocardial infarction, or stroke were defined as CVD survivors. Participants with a self-reported history of cancer were defined as cancer survivors.
Furthermore, data were collected on the treatment of diabetes. The participants were divided into two groups based on whether they were treated with insulin or oral medication. The number and weighted percentage of covariates were presented in Table S1.
Ascertainment of deathThe National Death Index was referred to determine all-cause and CVD mortality until December 31, 2019. The causes of death were identified using ICD-10 codes [19].
Statistical analysisAll analyses were conducted following the NHIS and NHANES analytic guidelines. The data analysis took into account the major sampling units, sample weights, and strata to provide credible national estimates [20].
To determine the association between salt usage and dietary sodium intake, we employed weighted linear regression analyses to investigate the relationship between the usage of table salt and total sodium intake. Subsequently, weighted multivariable Cox proportional hazards regression models were employed to investigate the associations between the usage of table salt consumed and the risks of all-cause and CVD mortality. Schoenfeld residuals were used to test the proportional hazards assumption, and no violation was observed. Covariates with concerning collinearity observed were excluded. Two multivariable models were constructed. In Model 1, we adjusted for age, gender, and race/ethnicity. In Model 2, we additionally adjusted for educational level, BMI, family ratio of income to poverty, smoking status, treatment of diabetes, HbA1c level, and self-reported history of hypertension, CVD, and cancer. In the event of missing values, the multiple imputation method was employed to impute the variables. The Kaplan-Meier (KM) curve was utilized to visualize the relationship between the usage of table salt and all-cause and CVD mortality. Cumulative mortality rates were compared by log-rank analysis.
Further subgroup analyses were conducted according to age, gender, race/ethnicity, smoking status, BMI, HbA1c, hypertension, CVD, and cancer. A likelihood ratio test was conducted to assess the interaction between subgroups and usage of table salt used.
Various sensitivity analyses were also conducted. (1) To mitigate the potential impact of reverse causation, participants who died in the first two years of their follow-up were excluded. (2) Analyses were repeated only for participants with complete data. (3) To investigate a potential role of blood lipid levels, liver and kidney indices, or total dietary sodium, potassium, and energy intake with any of the observed associations, we further adjusted for lipid profile (including total bilirubin and triglycerides), an indicator of kidney function (eGFR), an indicator of liver function (ALT, AST, GGT, and LDH), and total dietary sodium, potassium, and energy intake. (4) In order to ascertain the potential role of specific salt types in relation to any observed associations, we repeated the main analysis on initial four groups (using ordinary salt, lite salt, salt substitutes, and not using or adding salt products at the table). (5) To ascertain the potential role of dietary quality in any observed associations, we proceeded to adjust for HEI-2020. A two-sided P-values less than 0.05 were considered statistically significant. All analyses were performed with R, version 4.3 (R Foundation for Statistical Computing) and Stata version 18.0 (Stata Corp).
留言 (0)