
記住我
The human body relies on the eyes to perceive external information. However, the eyes are easily damaged because of prolonged screen exposure, resulting in frequent vision problems and serious interference with daily life Rauchman et al. (2022). In today’s society, the popularity of electronic devices such as mobile phones and computers makes it almost impossible to work and study without using electronic screens, which undoubtedly poses a direct challenge to vision. Long-term immersion in front of electronic screens often leads to varying degrees of vision damage Lanzani et al. (2024). Due to the large population base and uneven distribution of medical resources, not everyone can receive high-quality medical diagnosis and treatment in time, which increases the risk of delayed illness and makes some patients miss the best time for treatment. According to the World Health Organization, approximately 2.2 billion people in the world have vision problems caused by eye diseases Bashshur and Ross (2020). It is particularly noteworthy that nearly half of these vision impairments could have been avoided or recovered through effective preventive measures or early and timely intervention. Therefore, in the field of clinical research, early detection and accurate diagnosis of eye diseases Xu et al. (2022); Wan et al. (2023b); Wan et al. (2024b) are particularly important. Accurate diagnosis of eye diseases can not only reduce avoidable vision loss, but also improve the quality of patients’ life.
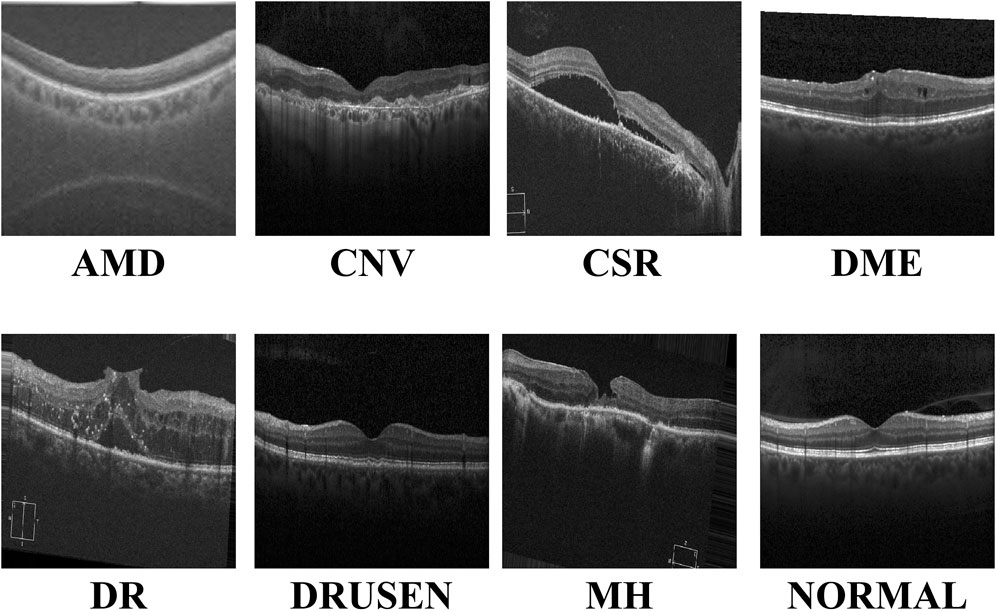
With the continuous advancements in optimal theory and technology Wan et al. (2023a); Wan et al. (2024a); Ji et al. (2024), optical coherence tomography (OCT) technology has emerged and rapidly penetrated into the medical field Bouma et al. (2022). OCT has significant advantages such as high resolution, efficient detection, and non-invasiveness. It can be used for the detection and diagnosis of retinopathy and has now become an indispensable routine method in eye examinations Xu et al. (2023). Figure 1 shows eight examples of retinal disease, namely, age-related macular degeneration (AMD), choroidal neovascularization (CNV), central serous chorioretinopathy (CSR), diabetic macular edema (DME), macular hole (MH), Drusen, diabetic retinopathy (DR), and normal. However, due to hardware and equipment factors, OCT images are often mixed with unavoidable noise during the imaging process, which undoubtedly increases the complexity and challenge of diagnosis for doctors. Moreover, OCT is a grayscale imaging technique. Since the characteristics of small lesions are not clear enough at the grayscale level, these subtle changes are often difficult to detect, which increases the risk of missed diagnosis by doctors. At the same time, although the number of patients with retinal eye diseases increases year by year, the number of doctors with professional diagnostic capabilities is relatively scarce. This contradiction is becoming increasingly prominent, making it difficult to effectively meet the diagnosis and treatment needs of a large patient population Daich Varela et al. (2023). This technology can assist doctors in accurately assessing patients’ conditions, effectively reducing doctors’ workload, while improving the accuracy of eye disease screening and diagnosis. It has far-reaching significance for optimizing the allocation of medical resources and improving the quality of medical services.
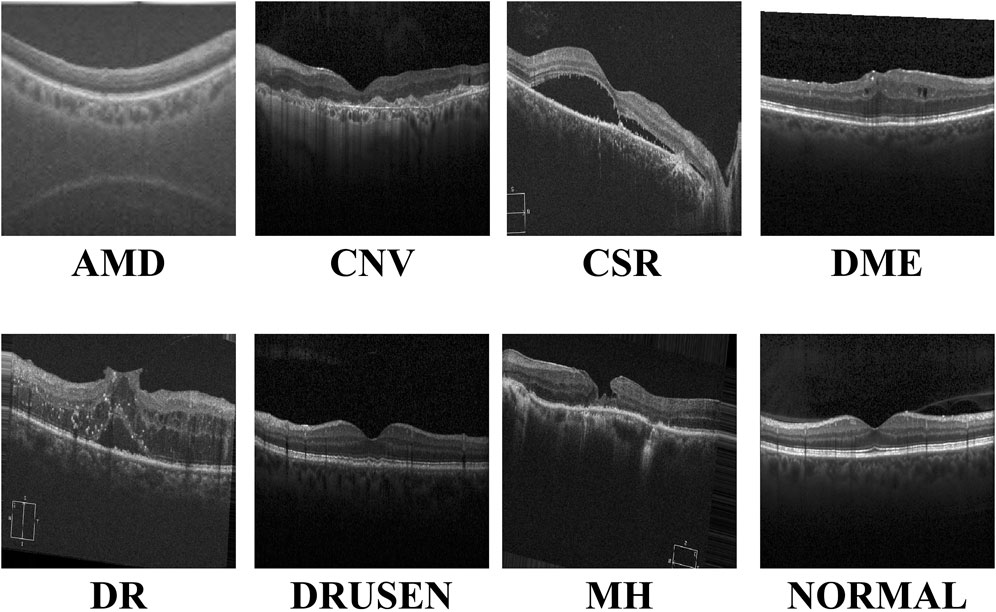
Figure 1. Visualization of the eight retinal diseases.
In the field of medical image processing, convolutional neural networks (CNNs) have performed well in medical image segmentation Li et al. (2024); Hong et al. (2022b); Zhang et al. (2023), image generation You et al. (2022); You et al. (2024), and image classification Yu et al. (2022); Zong et al. (2024); Zuo et al. (2023a). By stacking multiple layers of convolution and pooling layers, CNNs can effectively extract complex features and subtle lesions in images Hong et al. (2022a), such as microaneurysms and exudates, which are key signs of diseases such as diabetic retinopathy. Combined with fully connected layers for feature integration and classification, CNN models can accurately distinguish different types of retinal diseases, providing ophthalmologists with fast and objective preliminary diagnostic references, thereby improving the diagnostic efficiency and accuracy and speeding up patient treatment. However, CNN models have difficulty modeling long-distance dependencies in images and are sensitive to position translation, which limits their application in certain complex retinal disease classification tasks.
Due to its remarkable work in natural language processing, the transformer network is now gradually entering the field of medical image computing Zuo et al. (2024); Zuo et al. (2023b), bringing improvements in performance of the task of retinal disease image classification Parvaiz et al. (2023). Due to the unique self-attention mechanism, the transformer-based network is able to deeply analyze the complex relationship between each pixel and other pixels in the image, thereby capturing small but important pathological features in retinal disease images, such as subtle vascular abnormalities and exudate distribution. This global information integration capability enables the transformer network to more accurately identify different types of retinal diseases during the classification process, providing ophthalmologists with a more reliable and timely diagnostic basis. Since the network does not consider the spatial locality of the image, it may not capture detailed features as finely as CNNs when processing high-resolution medical images and requires larger data sets and computing resources to train, all of which limit the application scenarios of transformer-based models in medical image diagnosis.
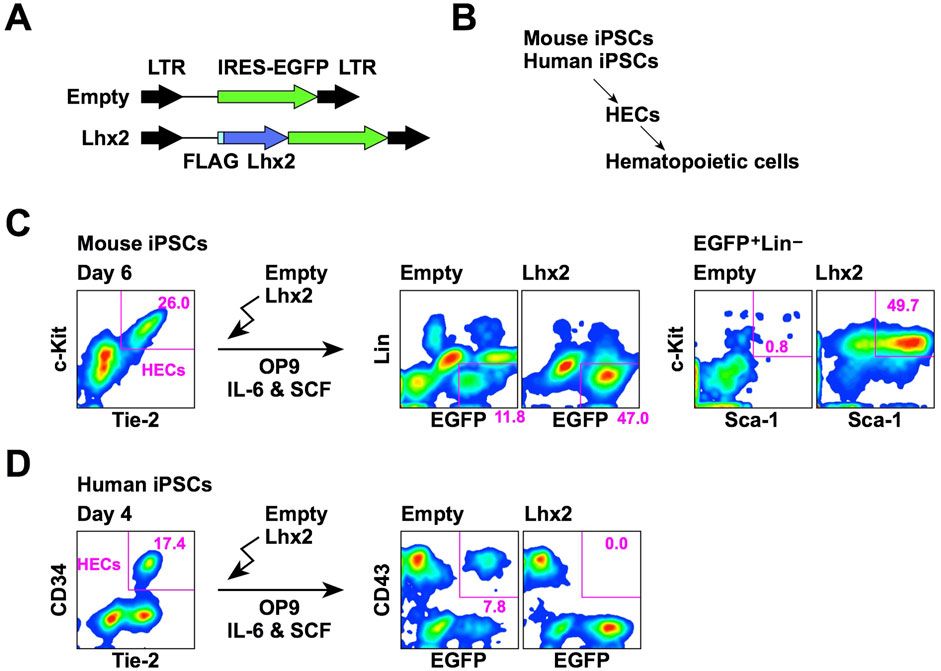
Recently, the Mamba network, an innovative deep learning architecture, has excelled in long-distance relationship modeling Gu and Dao (2023); Zhu et al. (2024). Through its unique selection state mechanism, it effectively captures the spatial dependencies between distant regions in an image and ignores noise interference, thereby improving the learning efficiency and prediction accuracy of the model. Inspired by the above observations, we combined the CNN and Mamba networks and proposed the multi-resolution visual Mamba (MRVM) model for OCT image classification. The MRVM model first extracts local features from OCT images using convolution and then captures global long-range dependencies through the retinal Mamba. Next, by integrating multi-scale global features, the model enhances the classification accuracy and overall performance. The multi-directional selection mechanism (MSM) within the retinal Mamba improves feature extraction by focusing on various directions, thereby boosting the model’s ability to detect complex, orientation-specific retinal patterns. Finally, the fused multi-scale features are sent to the classifier to discriminate disease-related OCT images. The proposed model has the potential to accurately detect retinal diseases and can be extended to other medical image classifications. The main contributions of this work are summarized as follows.
• The proposed MRVM model first extracts local features of OCT images through the convolution module and then extracts global long-range dependent features through the retinal Mamba, significantly improving the performance of image analysis and recognition tasks.
• We devised the MSM in the retinal Mamba to enhance feature extraction by focusing on multiple directions of the local receptive feature map. This enables the model to more effectively capture complex, orientation-specific patterns in retinal images, improving the performance of image classification and retinal disease detection.
• By fusing multi-scale global features, it can capture detailed lesion characteristics of retinal images at different scales, further improving the performance of OCT image classification and making the model more robust and accurate.
The subsequent sections of this work are structured as follows: In Section 2, we review the literature on retinal disease detection. We detail the innovative MRVM model in Section 3 to introduce a novel approach for detecting retinal disease using OCT images. Subsequently, Sections 4 and 5 present the experimental setup alongside comparative prediction outcomes utilizing alternative methods. Lastly, Section 6 delves into the credibility of this work and provides concise key findings.
2 Related worksThe classification performance of retinal OCT images is also constantly improving with the advancement of artificial intelligence. These improved methods mainly focus on local feature learning and global feature learning.
The first approach focuses on local lesion characteristics. It deeply analyzes the key lesion signs in the image, such as changes in the vascular morphology, edema of the optic disc, and abnormal manifestations of the macular area, and accurately captures the specific characteristics of these lesions to achieve accurate classification of the retinal diseases. Rong et al. (2018) proposed a CNN-based automatic classification method to effectively classify OCT images through image denoising, mask extraction, and proxy image generation. This CNN-based method performs well in evaluation on different databases. Alqudah, (2020) developed a more powerful CNN-based model to classify five types of retinal diseases (including AMD, CNV, DME, Drusen, and normal) with an overall accuracy of 95.3%. Karthik and Mahadevappa (2023) replaced the residual connection with the contrast of derivatives in the standard ResNet model. Experimental results on the two public OCT datasets show at least 1% improvement in the accuracy estimation. To reduce the model size, Sunija et al. (2021) designed only six convolutional blocks with downsampling and weight sharing mechanisms to classify four-label OCT images. Compared with the existing ResNet-50 model, it uses 6.9% of the learnable parameters but has a better classification performance. Considering the previous methods may ignore useful discriminative information at different scales, Wang and Wang (2019) designed a novel CNN-based method to automatically detect AME and AMD, which shows good classification performance in cross-dataset adaptability. In addition, Das et al. (2021) proposed a deep multi-scale fusion convolutional neural network (DMF-CNN) to extract and fuse different scale features for AMD/DME/normal classification. The multi-label classification results show excellent performance and good versatility on the UCSD and NEH datasets.
The second approach is modeling the global diseased areas, which focuses on the overall information of the image, comprehensively considers multiple visual elements and structural features in the image, and does not need to identify specific lesions separately but directly performs intelligent analysis on the entire image so as to determine the label of retinal diseases from a global perspective. Yu et al. (2021) applied the vision transformer (VIT) to the task of retinal disease classification. Their framework outperforms CNN models on two publicly funded image datasets. Shen et al. (2023) incorporated the clinical prior knowledge to guide the transformer-based network for retinal disease prediction and achieved superior classification and good generality on the public nAMD dataset. Hammou et al. (2023) used the pre-trained state-of-the-art models as the prior knowledge and fine-tuned these models to classify OCT videos. This method has potential application in the real-time diagnosis of retinal diseases. To improve the accuracy and interpretability of these classification models, He et al. (2023) proposed a transformer-based model with Swin-poly strategy to classify retinal OCT images. They achieved state-of-the-art performance on the OCT2017 dataset, which is superior to that of both vision transformer (VIT) and convolutional neural network approaches. A similar work is presented in Playout et al. (2022). Wen et al. (2022) combined the transformer and CNN to train this hybrid model for ophthalmic disease classification. This model extracts both local and global contexts for lesion area extraction and understanding with considerable accuracy improvement. In addition, they Laouarem et al. (2024) designed a hybrid model to classify seven retinal diseases by combining visual transformers and CNN. They extracted multi-scale local features from OCT images by a hierarchical CNN and achieved good results on three public datasets. Hemalakshmi et al. (2024) proposed a SqueezeNet-Vit model to extract local and global features for more accurate OCT classification.
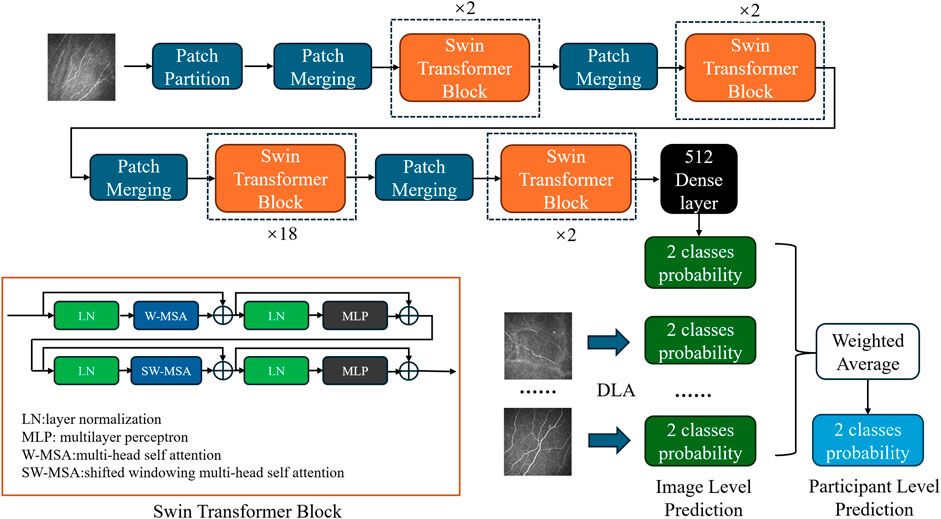
3 MethodsThe proposed MVRM model is illustrated in Figure 2. The input is an image with the size S×S, and the output is the retinal disease label. There are three main blocks: the convolutional block, the retinal Mamba block, and the classifier block. The convolutional block is used to extract local structures buried in the image by using local receptive fields and parameter sharing. The local receptive field allows the convolution kernel to focus on only a small area, thereby capturing local features. The retinal Mamba focuses on the long-range dependencies and mines the overall lesion area association in OCT images. Through the resampling modules, the three retinal Mamba modules can generate multi-scale global–local features for capturing the characteristics of the lesion area from all directions. By cleverly integrating global features and local features, the proposed model not only fully retains disease-related global information but also significantly enhances its ability to keenly capture local subtle differences. This fusion strategy effectively improves the accuracy and robustness of classification tasks. Furthermore, by using the category loss function to optimize and calculate these fused multi-scale features, the model can generate more refined and representative representations for each retinal disease category. These representations accurately reflect the core characteristics of retinal diseases and can be used for analysis and decision-making on other downstream tasks. The details of these blocks are described in the following sections.
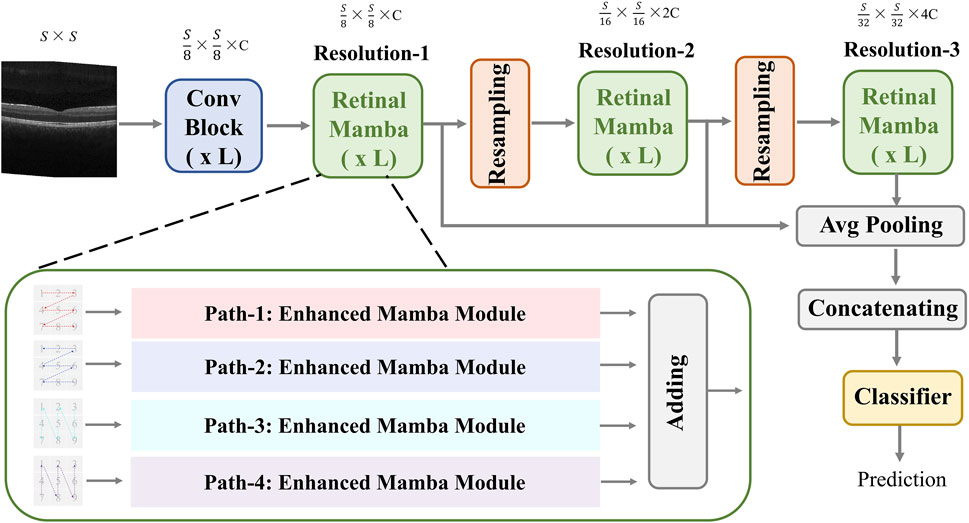
Figure 2. Architecture of the proposed MVRM model, consisting of the Conv block, retinal Mamba module, sampling module, and classifier. The input is a two-dimensional image, and the output is a vector representing the retinal disease label.
3.1 Convolutional blockIn the convolution module, we designed three residual layers, and the output sizes of these three residual layers are as follows: (S/2)×(S/2)×C1, (S/4)×(S/4)×C2, and (S/8)×(S/8)×C3. Adjacent residual layers are connected with 1 × 1 convolution kernels with a sliding step of 2. After the third residual layer, a 1 × 1 convolution kernel is used to change the number of channels from C3 to C. The input image size is S×S, and the output size is (S/8)×(S/8)×C. The calculation formula can be expressed as follows:
I3=Conv1×1ResidualI2.(3)Residual=Conv3×3,BN,ReLU,AvgPool,Conv1×1,BN,ReLU,AvgPool+shortcutConv1×1.(4)where, Equations 1–3 are based on the Equation 4. In Equation 4, it contains 2 sub-convolution layers. The first sub-convolution layer contains a 3 × 3 convolution (Conv) kernel with a step size of 2, a batch normalization layer (BN), a ReLU activation layer, and an average pooling layer (AvgPool); the second sub-convolution layer contains a 3 × 3 convolution kernel with a step size of 1, a normalization layer, a ReLu activation layer, and a flat pooling layer.
3.2 Retinal MambaThis module extracts global disease-related patterns by selectively modeling different parts of the OCT image. To capture multi-scale patterns, we designed two resampling modules to obtain multi-resolution feature maps and utilize the retinal Mamba (RM) to learn the global lesion area relations from multi-scale perspectives. The resampling module between retinal Mamba modules consists of a batch-normalized 3×3 CNN layer with a stride of 2 to halve the image resolution and double the channel dimension. The multi-scale feature maps can be computed by the following formula:
where R1, R2, and R3 are the output of Equations 5–7, representing feature maps at three different multi-resolutions. The feature map sizes are S/8×S/8×C, S/16×S/16×2C, and S/32×S/32×4C, respectively. Next, we use the average pooling to normalize the three multi-resolution maps and concatenate these maps to fuse multi-scale features. The fused feature Rf can be expressed by the following:
Rf=AvgPoolR1‖AvgPoolR2‖AvgPoolR3.(8)The fused feature Rf in Equation 8 has the size 1×7C.
3.2.1 Enhanced MambaIn the retinal Mamba, four paths are used to extract different direction features from the retinal OCT image. Considering the rich pattern correlations in different directions of time series and the complexity of spatial location dependencies, the output of each enhanced Mamba is added to fuse different directional features. The structure of each enhanced Mamba is shown in Figure 3.
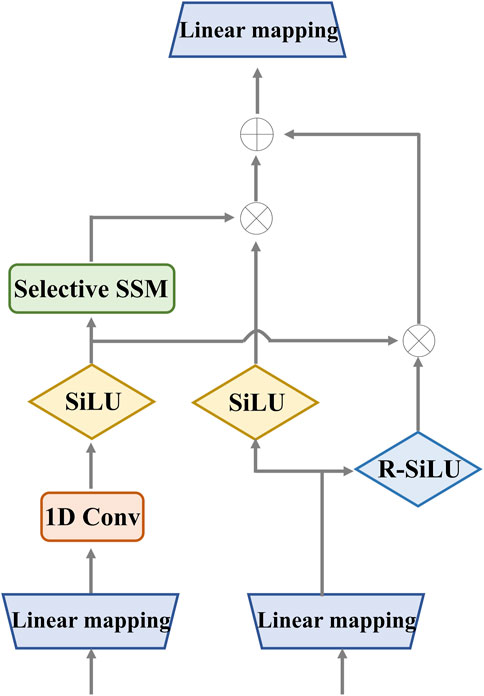
Figure 3. Detailed structure of the enhanced Mamba. It utilizes two gates to capture sequence dependencies for global complementary information. The input and output have the same dimension.
We designed the enhanced Mamba with two pathways. The first pathway leverages a linear mapping (LM), a 1-D convolutional module, and a selective state-space model (SSM) to learn long-range sequence dependencies. The selective SSM can memorize long-term historical information in the HIPPO matrix. The second pathway generates two gates: the sigmoid-weighted linear unit (SiLU) and the reversed SiLU (R-SiLU). The SiLU gate processes the longer-term historical context, and the R-SiLU gate filters the complementary historical information to more comprehensively preserve the valuable long-term information. This designed enhanced Mamba facilitates a more nuanced and effective handling of long-term sequence modeling tasks. The computation process is illustrated in the Algorithm 1.
Algorithm 1.Computation process of enhanced Mamba.
Input: Batch(R0): (b,l,d)
Output: Batch(R1): (b,l,d)
1: x11: (b,l,d)←LM11(R0)
2: x21: (b,l,d)←LM21(R0)
3: x12: (b,l,d)←SiLU(Conv1D(x11))
4: A: (d,q)←ParameterA
6: C: (b,l,q)←LMC(x12)
7: Δ: (b,l,d)←log(1+exp(LMΔ(x12)))+ParameterΔ
8: Ā,B̄: (b,l,d,q)← discretize(Δ, A, B)
9: y1: (b,l,d)←SSM(Ā,B̄,C)(x12)
10: y2: (b,l,d)←y1⋅SiLU(x21)+x12⋅(1−σ(x21))
11: R1: (b,l,d)←LMy2(y2)
12: Return R1
3.2.2 Selective state-space modelThe selective SSM can help the retinal Mamba to capture global dependencies in OCT images, capturing rich semantic disease-related information. The structure of the selective SSM is shown in Figure 4; it is a discretized version of the SSM, where the input is xk and the output is yk. Both of them are the features at the k-th time point. For the continuous condition, we map the one-dimensional sequence x(t)∈RC to the output sequence y(t)∈RC through latent historical representation h(t). The continuous SSM is expressed as follows:
Here, A∈RC×C represents the state matrix, which memorizes the history information of latent representations. B and C project the input sequence and the latent representation into the output sequence. The problem of Equations 9, 10 lies in the unsuitable adaptation for deep learning. To solve this problem, we discretize it by introducing the time-scale factor Δ. The projection matrix B and the state matrix A can be transformed into B̄ and Ā, respectively. The zero-order hold strategy is used to complete this task:
B̄=ΔA−1Ā−I⋅ΔB.(12)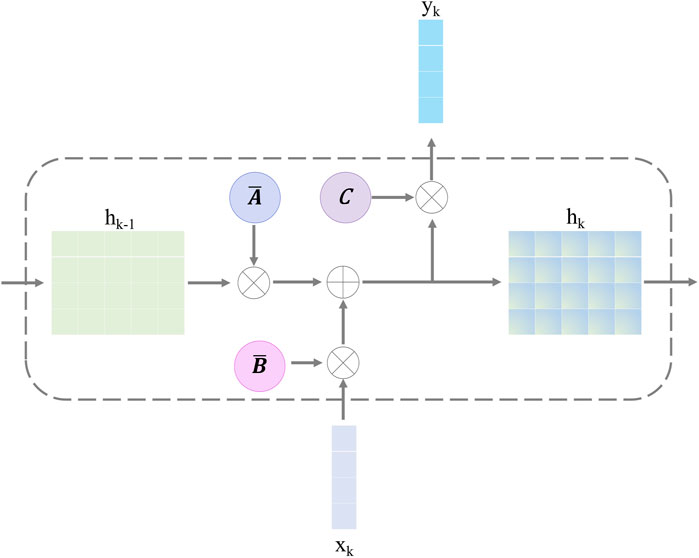
Figure 4. Structure of the selective state-space model.
After discretizing with the step size Δ in Equations 11, 12, the SSM is defined with Equations 13, 14:
Finally, we employ a convolution operation for convenient optimization of the proposed model. The SSM computation is expressed as follows:
K̄=CB̄,CAB̄,…,CĀl−1B̄.(15)where, in Equation 15, K̄ indicates a dynamic convolutional kernel, and l denotes the sequence length. In Equation 16, x and y are matrices that share the same size l×d.
3.3 ClassifierThe classifier is a five-layer perceptron network, including the three hidden layers. The input layer receives the fused feature Rf∈R1×7C. The three hidden layers have 5C, 3C, and C neurons, respectively. The output layer contains m neurons corresponding to retinal disease labels, and a softmax activation function is used to convert the output into a probability distribution, representing the predicted probability of each category. This network is trained using a back-propagation algorithm, adjusting weights and biases to reduce the error between the predicted category and the actual category. During the training process, the model learns to map the features of the input data to the corresponding category labels, thereby achieving classification. We utilized the cross-entropy objective to optimize the proposed MVRM model.
L=−1N∑i=1NYi′⋅logYi,(18)where, in Equation 17, Y′ is a m-length vector, the largest value index of Y′ is the predicted label; Y is a one-hot vector representing the actual label. In Equation 18, L is the loss function, and N is the training image number.
4 Experimental configuration4.1 Dataset descriptionDue to the confidentiality and sensitivity of medical data, as well as the high expertise and time costs required for medical image annotation, the use of public datasets has become a common and effective practice in the field of medical image analysis research. Public datasets, such as OCT (optical coherence tomography) image datasets, have been carefully collected and annotated by professional teams to ensure the quality and accuracy of the data. To evaluate our model’s effectiveness, we selected the two public OCT datasets: the OCT-2017 and the OCT-C8. The OCT-2017 dataset1 covers four types of retinal disease images: age-related wet maculopathy (CNV), diabetic macular edema (DME), age-related dry maculopathy (DRUSEN), and normal retinal images (NORMAL). The dataset comes from 4,686 patients with different eye diseases and contains a total of 84,484 images. There are 37,205 CNV images, 8,616 DRUSEN images, 11,348 DME images, and 26,315 NORMAL images in the training set. The testing set contains 1,000 images, with 250 each of various lesions and normal images, which are used to evaluate model performance. The OCT-C8 dataset2 contains a total of 24,000 images with eight categories. Each category has 2,300, 350, and 350 images for training, validation, and testing, respectively. The largest resolution of the OCT image is 384×496, and the smallest resolution of the OCT image is 1536×496.
In order to develop a unified model framework, we resize every OCT image into the same size: 512×512 pixels. The number of images in the original dataset is too different. During the training process, the accuracy of the category with the largest number will greatly affect the overall accuracy of the model. To solve this problem, this paper randomly selects an equal number from each category and determines the ratio of training, validating, and testing be 8:1:1. For the OCT-2017 dataset, we select 8,800 images for each category, including the 7,040 training images, 880 validating images, and 880 testing images. For the OCT-C8 dataset, we partitioned the dataset into the 8:1:1 ratio. The training, validating, and testing image numbers for each category are 2,400, 300, and 300, respectively. The datasets used for this study are summarized in Table 1. To accelerate the training speed and enhance the model’s ability to converge toward optimal weights, we normalize the image’s pixel values across its channels to a uniform range [0, 1]. This process ensures that the eigenvalues of the image data are within a comparable range, facilitating a more stable and efficient training process for neural networks. We also apply the image augmentation techniques (i.e., random shuffling, crop, and rotate) to enhance the generalization of the model’s performance.
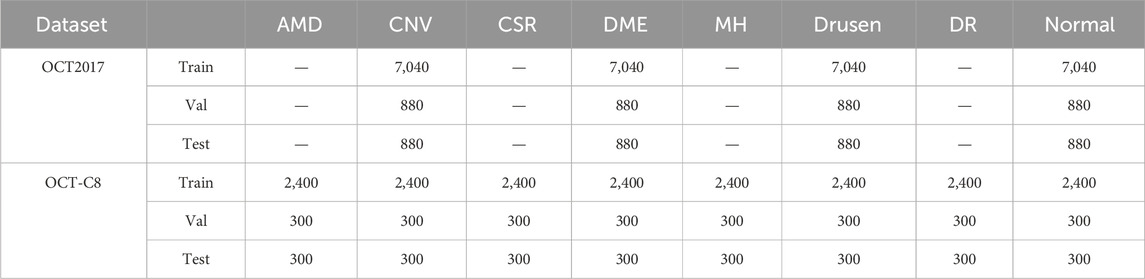
Table 1. Experimental data details used in this study.
4.2 Model training detailsIn the Conv block, S=512, and C1=4,C2=8,C3=C=16, there are L=3 retinal Mamba modules. Our model was trained using the TensorFlow framework on the Nvidia RTX4090 GPU. The Adam optimizer was selected for its adaptive learning rate adjustment capability, and the initial learning rate was set to 0.001 to promote rapid convergence while avoiding overfitting. The batch size is set at 64 to balance memory usage and training efficiency. The number of epochs was set to 150. After each round of dataset training, the model performance was evaluated through the validation set, and the learning rate or model structure was adjusted in time to optimize the results. During the training process, TensorBoard was used to monitor the changes in loss and accuracy to ensure that the training process was stable and effective. The trained model is evaluated on the testing set for comparison and analysis.
4.3 Evaluation metricsIn the multi-category classification task, we use the mean accuracy (mACC), mean sensitivity (mSEN), mean specificity (mSPE), mean precision (mPRE), mean F1-score (mF1), and overall accuracy (OACC). First, we compute the ACC, SEN, SPE, and PRE for each category and then average them for all the categories. During the evaluation, for each category, we treat it as a binary classification, where the positive label is itself and the negative label is the remaining categories. Therefore, TP represents the count of samples that are correctly identified as belonging to the positive category by the network’s predictions, matching their true-positive labels. FP denotes the number of samples that are incorrectly labeled as positive by the network’s predictions, despite their true labels being negative. TN stands for the count of samples that are accurately classified as negative by the network’s predictions, aligning with their genuine negative labels. FN signifies the number of samples that are erroneously classified as negative by the network, whereas their true labels are positive.
mACC=1m∑i=1mACCi=1m∑i=1mTPi+TNiN,(19)mSEN=1m∑i=1mSENi=1m∑i=1mTPiTPi+FNi.(20)mSPE=1m∑i=1mSPEi=1m∑i=1mTNiTNi+FPi.(21)mPRE=1m∑i=1mPREi=1m∑i=1mTPiTPi+FPi.(22)mF1=1m∑i=1mF1i=1m∑i=1m2⋅PREi⋅SENiPREi+SENi.(23)where N is the testing image number and ACCi means the accuracy for the i-th category. Another OACC evaluates the overall performance for all categories. In the confusion matrix, we define TL as the diagonal of the matrix, and the OACC is expressed by
Equations 19–24 are used to evaluate the diagnosis performance of different methods on the ADNI and ABIDE datasets.
5 Results5.1 Prediction resultsFigure 5 shows the details during the training. The left graph shows the curve of loss changing with epochs, and the right subfigure shows the curve of overall accuracy changing with the epochs. Both the training and validating losses show a stable trend. The little gap between them indicates that our model is a good fit model. The confusion matrix of the classification results is shown in Figure 6. Our model shows accurate classification performance on the OCT2017 dataset, with almost no errors in each category. In the OCT-C8 dataset, our model also performs well on most categories, except the CNV and DME categories. Table 2 shows the classification perfor
留言 (0)