
記住我




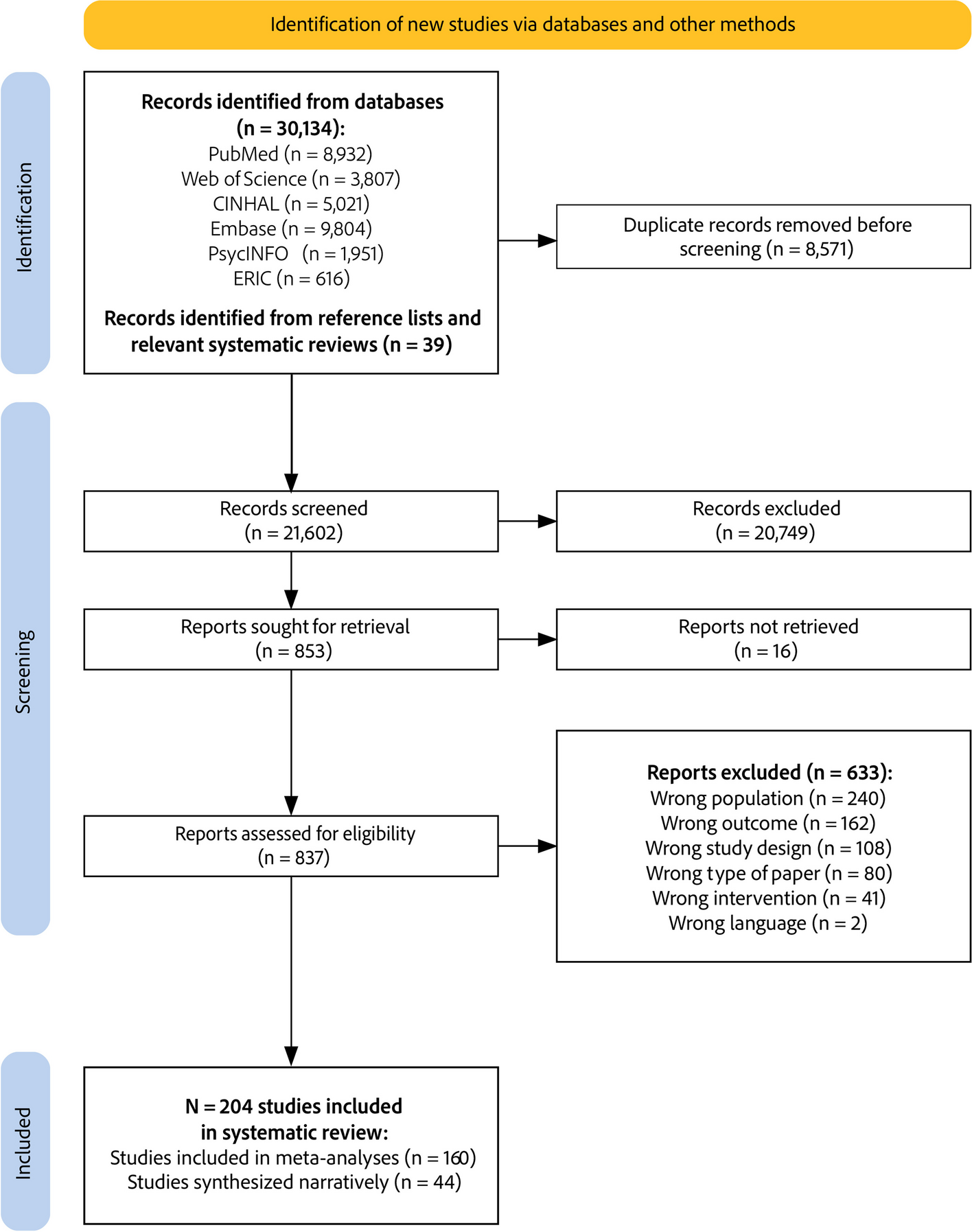



A total of 3195 unique citations were identified. After the title and abstract were screened, 3164 were excluded, leaving 31 that were retrieved for full-text screening. Four of these were deemed eligible for inclusion and a further one was added after a protocol was identified in the 31 papers for which the completed review had been published but had not been identified in the initial searches. Three reviews were discussed with the review panel. Two were included [21, 22] after a discussion regarding the relevance of including reviews considering instruments that measure the implementation outcomes of healthcare policies, as opposed to interventions. One review was excluded as it only focused on the outcome of fidelity and the decision was made that the reviews should consider an implementation outcome framework (for example, Proctor’s taxonomy (2011)) as a whole, rather than a limited Sect. [23] as the frameworks provide a more thorough and rounded view of implementation, rather than a more narrow focus on one aspect. Figure 1 shows the PRISMA flow diagram for the selection process.
Fig. 1
PRISMA flow diagram for database search
Characteristics of included reviewsSee Table 2 for a summary of findings. Of the five included SRs, three were conducted in the USA [13, 21, 22], one in the UK [12] and one in Australia [24]. Regarding the identified instruments, all stated that the highest percentage of instruments were developed in the USA, with the others from high-income countries such as Canada, Australia and throughout Europe. Each review provided a breakdown of the setting of the included instruments (for example, outpatient, school or pharmacy based) apart from Khadjesari et al. [12].
Table 2 Summary of findings from included papersFour of the SRs used specific implementation outcome frameworks to search for and categorise the instruments [12, 13, 21, 22]. Two SRs solely used Proctor’s Taxonomy of Outcomes (2011) [12, 13]. The authors stated that the taxonomy was applied to ensure that all instruments fit the inclusion criteria of assessing an implementation outcome. The second two SRs [21, 22] also use the taxonomy for the same purpose but also use the CFIR and the Policy Implementation Determinants Framework [25]. The final SR [24] solely uses the constructs from the CFIR [20], which whilst also widely used within implementation research, does not focus on specific outcomes. A CFIR outcomes addendum is in the process of being developed [26] but the SR predates this.
Methodological strengthAll five reviews used similar search strategies and had clear and justifiable eligibility criteria (Table 5). Two SRs published the protocols for the reviews before completion, providing further transparency of the process [27, 28]. A further two SRs were both undertaken by members of the same research team and stated that they based their review procedures on the method listed in the protocol of the Mettert et al. [13] review [28]. The Mettert et al. SR [13] yielded significantly more eligible instruments than the other reviews, 150, and 102 of which were eligible for psychometric rating. No explanation is provided for this but the combination of behavioural and mental health settings may have provided a broader search strategy thus yielding more results.
In the five included reviews, three different methods were used to assess the quality of the included papers. Mettert et al. [13] used a self-developed Psychometric and Pragmatic Evidence Rating Scales (PAPERS) [29], developed in response to a perceived gap in the literature in that no measures existed that were able to support the evaluation of the more specific and nuanced properties that fit the complexities of implementation science evaluations. Two further SRs identified also use this scale [21, 22]. Khadjesari et al. [12] also identified the same gap in the literature regarding psychometric measures. Firstly, they used the COSMIN checklist to assess methodological quality, specifically validity, reliability and responsiveness [30]. Secondly, they developed a contemporary psychometrics checklist (ConPsy) to assess psychometric strength more accurately. This aims to complement the COSMIN checklist and its psychometric strength is currently being evaluated as part of a separate study. Clinton-McHarg et al. [24] used the guidelines from the Standards for Educational and Psychological Testing [31] to assess methodological quality. PAPERS, COSMIN and ConPsy all provided a score for each instrument, the guidelines from Clinton-Mcharg et al. [24] provided a pass/fail mark.
Psychometric scoresEach review reported that the majority of instruments analysed had poor or inadequate psychometric scores. Khadjesari et al. [12]reported that of the scales reported reliability, only 8/62 scored a rating of excellent or good on the COSMIN checklist and only 11/63 which reported validity scored excellent or good. The ConPsy results were also low, out of a maximum score of 22, only 12 studies scored over seven, with the highest score recorded as nine. The Mettert et al. [13] review reported that out of 102 eligible instruments, 33 had no recorded psychometric properties and a further 39/102 scored between -1 to 2 out of a maximum of 36 on PAPERS. The highest recorded score was 12 and norms and internal consistency were the properties most likely to be measured. In the McLoughlin et al. [22] review, the instruments were split into two groups, those designed for large-scale purposes (e.g. regionally or nationally) and those designed as a unique tool for a specific policy. They found the large-scale tools showed marginally better psychometric scores due to high internal consistency and validity, however, the median PAPERS score across all measures was 0/36 due to the majority not providing psychometric information. In the Allen et al. [21] review, only 38/66 instruments that were assessed as being transferable to other settings were scored. The median PAPERS score was 5/36, with norms and internal consistency the most likely to be measured. Finally, in the Clinton-Mcharg et al. SR [24], of the 51 instruments, most demonstrated face/content and construct validity and internal consistency but only 3/51 achieved for test-rest reliability and 8/51 achieved for responsiveness.
Pragmatic strengthWhilst the PAPERS score was created by the team who undertook the Mettert et al. [13], they state in the protocol that they would not be applying the pragmatic rating scale as it was in the process of development. However, two other SRs use it [21, 22]. The scale uses the same scoring system as the psychometric scale and covers brevity, language simplicity, cost to use, training ease and analysis ease with a maximum score available of 20. Khadjesari et al. [12] also referenced PAPERS for their pragmatic scoring, however, they only score for brevity (referred to as usability) scoring it from minimal (over 100 items in the instrument) to excellent (under ten items). This is the only review to undertake further statistical analysis, using Spearman’s correlation to examine the relationship between the COSMIN and ConPsy scores and usability. Clinton-McHarg et al. [24] use the guidelines listed above to measure acceptability, feasibility and potential for cross cultural adaption, using a pass or fail score.
Pragmatic scoringThe Khadjesari et al. review looked solely at usability, i.e. number of items in an instrument. The number of items in each instrument ranged from 4- 68. 6/65 contained fewer than 10 (scored as excellent) and 55/65 contained between 10 and 49 items (scored as good). No correlation was found between usability and either COSMIN scale, and a small negative correlation was found between usability and ConPsy scores. Mettert et al. [13] did not use the pragmatic section of PAPERS but did report a number of items, ranking them in categories of 1–5 items (10/102) 6–10 items (10/102) or 11 or more items (82/102). No further analysis is provided. McLoughlin et al. [22] used PAPERS and found a median score of 10/20, the large-scale instruments and the unique instruments scored the same overall but had different areas of benefit, the large-scale ones were more likely to have training provided but were also much longer with an average of 150 items per instrument as opposed to an average of 73 items for the unique instruments. Allen et al. [21] also used PAPERS, again, analysing only the 38 instruments identified as transferrable to other settings. These had a median score of 11/20, averaging 4/4 for cost and 3/4 for brevity and language. Clinton-McHarg et al. [24] did not analyse the length of the instrument, instead assessed whether any papers reported the acceptability or feasibility of the instrument, 17/51 reported elements of these, with 5/51 reporting on length of time taken to complete the measure and 6/51 reporting the proportion of missing items. No other pragmatic data was reported.
Phase twoEligibility criteria for selecting instrumentsEach review was assessed to establish that the instruments that they had reviewed were eligible for potential adaption to an acute healthcare setting such as the PICU. Three reviews were excluded [13, 22, 24] from phase two. All three provided a clear breakdown of the settings in that the instruments had been used, highlighting that they were predominantly outpatient, community, workplace or school-based, and for specific interventions, for example, smoking cessation or physical activity. This suggests that adaptability to an acute healthcare setting would be limited. Furthermore, all three reported the poorest psychometric results, and two lacked any pragmatic scoring [13, 24].
Instruments from the Allen et al. SR [21] were deemed acceptable for potential inclusion as the authors had undertaken analysis on each instrument to ascertain whether they could be transferable to different settings or contexts. Due to this, the 38 instruments that were assessed as fully or partially transferable were considered as they had the potential to be adapted to an acute healthcare setting. The Khadjesari et al. SR [12] provides some of the most detailed methodological and psychometric testing due to its use of both COSMIN and ConPsy scoring. Furthermore, the review specifically focused on instruments used in the physical healthcare setting and as this is inclusive of the PICU setting, suggests that instruments in this review were more likely to be appropriate for adaption. However, key contextual information is lacking in this review regarding the type of healthcare setting and as it is stated that most of the instruments were formed for a specific intervention [12], it is difficult to identify which may be adaptable for use with the PICU environment. As such, instruments in this review were considered for inclusion alongside those in the Allen et al. (2020) review, however, it was necessary to develop further inclusion/exclusion criteria (shown in Table 3) to narrow down the options and identify suitable options. The aim was to find an instrument that has been built for use, is adaptable to use in an acute clinical area, and has minimal or no cost involved with its use, as well as best scores on the COSMIN, ConPsy and usability and PAPERS scales. In recognition that both reviews highlighted that few instruments scored highly throughout, it was agreed by the co-authors that compromises could be made if an instrument fits the majority of the criteria but has one low score.
Table 3 Eligibility criteria for implementation outcome measurement instrumentsAs both the ConPsy and PAPERS are newly developed scales, and due to the novel nature of this review, there is no established guide to determine what scores should be considered acceptable. Thus, the cut-offs were decided by considering the median scores in each review and giving in-depth consideration to scoring guidance for each scale. Any deviation from these criteria was discussed on a case-by-case basis. These decisions were all agreed upon by the full review panel.
Implementation outcome instrument selectionInitially, the instruments from the Allen et al. [21] and the Khadjesari et al. [12] SRs were screened by the psychometric and pragmatic eligibility criteria alone, yielding 21 results out of a potential 93. The title, scores and document characteristics available for each instrument in the reviews were then read in more detail and as a result, a further four were added for consideration. Three of these were from the same study [32] to be used together to cover three domains of the taxonomy so were considered for this purpose despite low COSMIN scores. A fourth was added as it scored highly for validity and usability in the Khadjesari et al. SR but had not assessed reliability [33], however, an older iteration of the same instrument had been identified in the Allen et al. SR [34] which met the PAPERS eligibility criteria. Both scores are included in the instrument characteristics table for reference (Table 4) however, only the most recent iteration was fully analysed, and the older paper was excluded as a duplicate. Finally, the full text of the paper associated with each instrument was read and the remaining eligibility criteria were applied. The process is detailed in Fig. 2 with explanations of exclusions. This left nine instruments for further analysis. However, as the three instruments by Weiner et al. [35] were designed to be used together, they will be considered as one instrument henceforth, so seven instruments will be discussed rather than nine.
Table 4 Summary of the implementation outcome measurement instrumentsFig. 2
PRISMA Flow diagram for implementation outcome instrument selection
Instrument analysisThe included instruments were then read in greater detail, considering all the instruments item by item and considering any relevant supplementary material linked to them. Data was extracted from each of the instruments into a document characteristics table (Table 4).
After this further analysis, one of the seven was not adaptable to a PICU context [38] as it focused on the concept of evidence-based practice (EBP) rather than the implementation of EBP interventions and was therefore excluded.
Of the remaining six, two were formulated for specific populations/interventions [36, 37] but at least half of the questions in each fit the proposed topic and setting well, for example, ‘I feel that I work as part of a team with a recognised and valued contribution’ [36] and both scored highly for methodological and psychometric strength. However, both would require reasonable adaption and there is the potential that the level of adaption would reduce the methodological quality of them. Thus, the remaining instruments were mapped to the CFIR domains to provide insight into the extent each instrument considers different aspects of implementation (Table 5).
Table 5 Instruments mapped to the CFIR domains and constructsResults from mapping to the CFIROn analysing the mapped CFIR (Table 5), the majority of the instruments focus predominately on the ‘inner setting’ and ‘characteristics of the individuals’ domains with limited focus outside of these two domains. In particular, the PCHCOA survey [36] and the I-HIT scale [37] have minimal reach outside of these domains. The PCHCOA survey [36] was validated in Australia and has the highest psychometric score [12]. However, it focuses on the provision of good quality care rather than the implementation of an intervention. Whilst this is a beneficial area to measure, it does not fit the required purpose of measuring staff's understanding and attitudes towards a complex intervention. The I-HIT scale [37] was validated in the United States with strong psychometric scores [12] and is aimed at an acute healthcare setting which would be a better fit with PICU, particularly as PICU is a high-technology environment. However, the focus is clearly on a specific type of information technology that may not be found in every healthcare setting and as such would potentially require significant adaption. The level of adaption that both these instruments would require has the potential to reduce their reliability. Furthermore, they are the two longest scales, and neither consider aspects such as the process of the intervention or understanding of the evidence base. As such, they were excluded.
Of the remaining four, the combined scales by Weiner et al. (2016) have the lowest psychometric scores and do not cover either the ‘outer setting’ or ‘process of intervention’ domains. Furthermore, it was only tested by implementation science researchers and psychologists who had implementation research experience in the United States. There is no evidence of testing by staff from any other healthcare profession or who work in acute healthcare settings. On reading the measures, the statements in each (that are measured using the Likert scale) could seem similar to each other if presented to a healthcare professional with no experience in implementation science. For example, in the Feasibility of Intervention Measure, two of the four statements are ‘Intervention seems doable’ and ‘Intervention seems possible’. This could run the risk of respondents not recognising the intended difference between the statements and giving an answer that is not representative of their true opinion of the intervention. The combination of these factors and the low COSMIN score means that these instruments will be excluded from the shortlist.
Of the three remaining scales, only the EBPAS [33] covered all five domains. Whilst neither the PCIS scale [40] nor the NoMAD questionnaire [39] covered the outer setting, they both provided a much more thorough coverage of the ‘process of intervention’ domain, including questions on reflection and evaluation which would be very beneficial for the required purpose as it is recognised that successful adoption of an intervention is more likely if adequate feedback is provided and the benefits can be seen [41]. EBPAS would require some adaption as it was written in the United States utilising more American terminology. This combined with the poorer psychometric scores means that it will be excluded from the shortlist. The NoMAD was validated in the UK using a wide range of healthcare professionals from different healthcare settings and as such would require minimal adaption for use in a PICU setting. Whilst the PCIS was developed in the USA, using mental health professionals, it was specifically designed to be adaptable to any evidence-based intervention and would also require minimal adaption. Both of these instruments have the potential to be further developed and validated for an acute healthcare setting.
留言 (0)