
記住我








Let \(}_\) be a time-series of voxel \(v\), which samples the fMRI signal across ~ 20 s (i.e., the length of a BOLD activation in response to a brief stimulus or a quick motor action). The length, \(T\), of the time-series is related to the temporal resolution (i.e., TR of the experiment). Under the assumption that an arbitrary voxel time-series \(\vec_\) either belongs to the “activated” (class 1, \(C_\)) or “non-activated” (class 0, \(C_\)) class, we may define the fMRI dataset, H, to be a union of two mutually exclusive classes,
where \(C_ = \left\_\,\, \textit,v \in H} \right\}\) and \(C_ = \left\_\, \textit,v \in H} \right\}\). The goal is to find a decision function that reliably separates voxels in an fMRI data set into these two classes.
Classification problems are typically supervised—they rely on data with ground-truth labels for training the parameters of the decision function. However, labelling a common fMRI dataset that may include 10’s of thousands of voxels is prohibitively time consuming. Thus, we proceed with a semi-supervised approach, where the initial labelling is automatic and data-driven, while the subsequent training is iteratively improved without supervision.
Initialization (initial label assignments)One obvious difference between the time-series of voxels with and without a BOLD activation is that, while the baseline signal is more or less random, the BOLD signal evolution has a temporal structure (Fig. 1). Therefore, the autocorrelation of the time-series in voxels with a BOLD activation is different from that of voxels with the random background signal. We suggest using this difference to initially label a few voxels by computing the sample autocorrelation [34] of each voxel time-series, \(}_\), repeatedly with increasing lag, and summing the sample autocorrelation [36] across all the lags
$$SA_ = \mathop \sum \limits_^ }} \hat\left( i \right)_$$
(2)
where
$$\hat\left( i \right)_ = \frac_ } \right)\cdot\left( \right)}}\mathop \sum \limits_^ \left( \left[ \right] - \overline_ } \right)\left( \left[ k \right] - \overline_ } \right)$$
(3)
and \(Var\left(}_\right)\) and \(_\) refer to the temporal variance of \(}_\) and the maximal number of computed time-lags, respectively. \(_\) is one of the hyperparameters of the network – here set to 19. Longer lags may be used if needed, but care should be taken that the autocorrelation function remains reliable. An example of the autocorrelation function and its sum across 19 lags are provided in Fig. 1 for two different voxel time-series—one with a clear BOLD activation and another with a random baseline signal.
Fig. 1
Visualization of the automatic and data-driven initialization procedure. Top row: display of the time-series of a voxel featuring a BOLD activation on the left and its computed autocorrelation function on the right. The autocorrelation function was evaluated at 20 time-lags, including the 0th term (always 1), yielding a total sum of the autocorrelations (\(_\)) of 8.24 for voxel 5728. Bottom row: similar plots and calculations but for voxel 31791 with a baseline time-series, yielding a \(_\) that is near 1 (0.24) as expected for a truly random signal. Note that on the y-axis of the sampled time-series are arbitrary intensity units, whereas on the x-axis are sample numbers of the time-series. ACF = autocorrelation function
The initial class labels 0 and 1 are assigned according to the lowest and highest \(\frac }}quantiles \, of \, SA = \left\ } \right\}_\), respectively. For example, if \(_\) is 10% then voxels with \(S_>quantil_(SA)\) and \(S_<quantil_(SA)\) are labelled 1 or 0, respectively (Fig. 2).
Fig. 2
Initial label assignment. The histogram represents the empirical distribution of \(_\) (i.e., sum of autocorrelation of voxel time-series across the computed lags). \(_\) for each voxel, v, is computed using Eqs. (2) and (3). The blue demarcation line serves as the upper threshold for classifying voxel time-series as belonging to \(_\). Similarly, a red demarcation line is the lower threshold for the value of \(_\) above which a voxel time-series is classified as part of \(_\). The first training pool consists of the same number of samples in each class. A training sample is a combination of fMRI time-series and its automatically assigned label, i.e., \(\left( _ ,label} \right).\)
\(_\) is another hyperparameter and is computed according to an optimization problem
$$\arg \min_ \right]}} \left\}} \left( \right)} \right] - E\left[ }} \left( \right)} \right]} \right) \cdot \frac \right\} - \min \left\ \right\}}} + \alpha } \right\},$$
(4)
where the two summands are decreasing and increasing with \(\alpha\), respectively, and thus provide a trade-off between the number of training samples and the difference of mean \(SA\) among the voxels belonging to the sets of the two classes, \(_\) and \(_\). In other words, we desire a large initial training pool, in which the time-series belonging to the two classes differ as much as possible in their temporal autocorrelation structure. Note that \(E\left[SA | SA\ge _}\left(SA\right)\right]\) is also known as the tail-value-at-risk, a quantity often used in extreme value theory [35]. The voxels thus labelled will be called the initialization pool and are used in the first iteration of training the neural network.
Iterative neural network trainingAfter the initialization, a neural network (Fig. 3) that consists Bi-LSTM [32, 36] blocks, batch normalization [36] and a fully connected layer with sigmoid activation functions is trained by minimizing the cross-entropy loss in an iterative scheme (Fig. 4):
1.At the first iteration, the neural network is trained with the automatically labelled initialization pool.
2.After the first training period, pseudo-labels [37] are created for all voxels that did not belong to the initialization pool with the model trained in Step 1. To identify and use only the most confident predictions, a voxel \(v\) is assigned with label 0 and 1 if \(_\left(}_\right)<1-c\) and \(_\left(}_\right)>c\), respectively, where \(c\) is a hyperparameter called the confidence level that was set to 0.98. At each iteration, the 500 voxels with the most extreme \(_\) in each class are added to the initialization pool, thereby creating the expanded training pool for the next iteration. The function \(_(\cdot )\) consists of the network output, \(_\left(\cdot \right)\) (see Fig. 4) times an additional function based on \(S_\): \(_\left(}_\right):= \frac_(}_)}(-S_)}\). The denominator acts as a regulatory factor, increasing the difficulty for samples in subsequent iterations to be categorized into \(C_\), which helps reduce the class imbalance that would otherwise occur because in any given fMRI experiment voxels without a BOLD activation outnumber those with an activation.
3.Repeat step 2 and keep adding newly labelled voxels into the training pool unless the new iteration adds less than 500 \(C_\) labels or a prior set number of iterations is reached.
Fig. 3
Neural network structure. To begin, a batch of size of \(B\) fMRI time-series of length \(T\) are fed into the first Bi-LSTM [32] block. Via the LSTM equations, forward and reverse states denoted as \(o\) of size \(_\) (first hidden dimensions) are computed at all times, \(T\). The subsequent output, denoted here as \(y\), of the Bi-LSTM block is then the mean of the computed forward and reverse states. Next, the output \(y\) undergoes a batch normalization [36] (output \(y\)) before it is entered into the second Bi-LSTM block with hidden dimension \(_\) (ouput \(z\)). In the last Bi-LSTM block (output \(w\)), the last forward and first reverse hidden states are averaged out and enter a fully connected layer, FC, with sigmoid activation function (denoted as \(\sigma\)), which finally maps the output of each sample in the batch into the interval \([\text]\), resulting in vector \(p\) of size \(B\) with values in \([\text]\)
Fig. 4
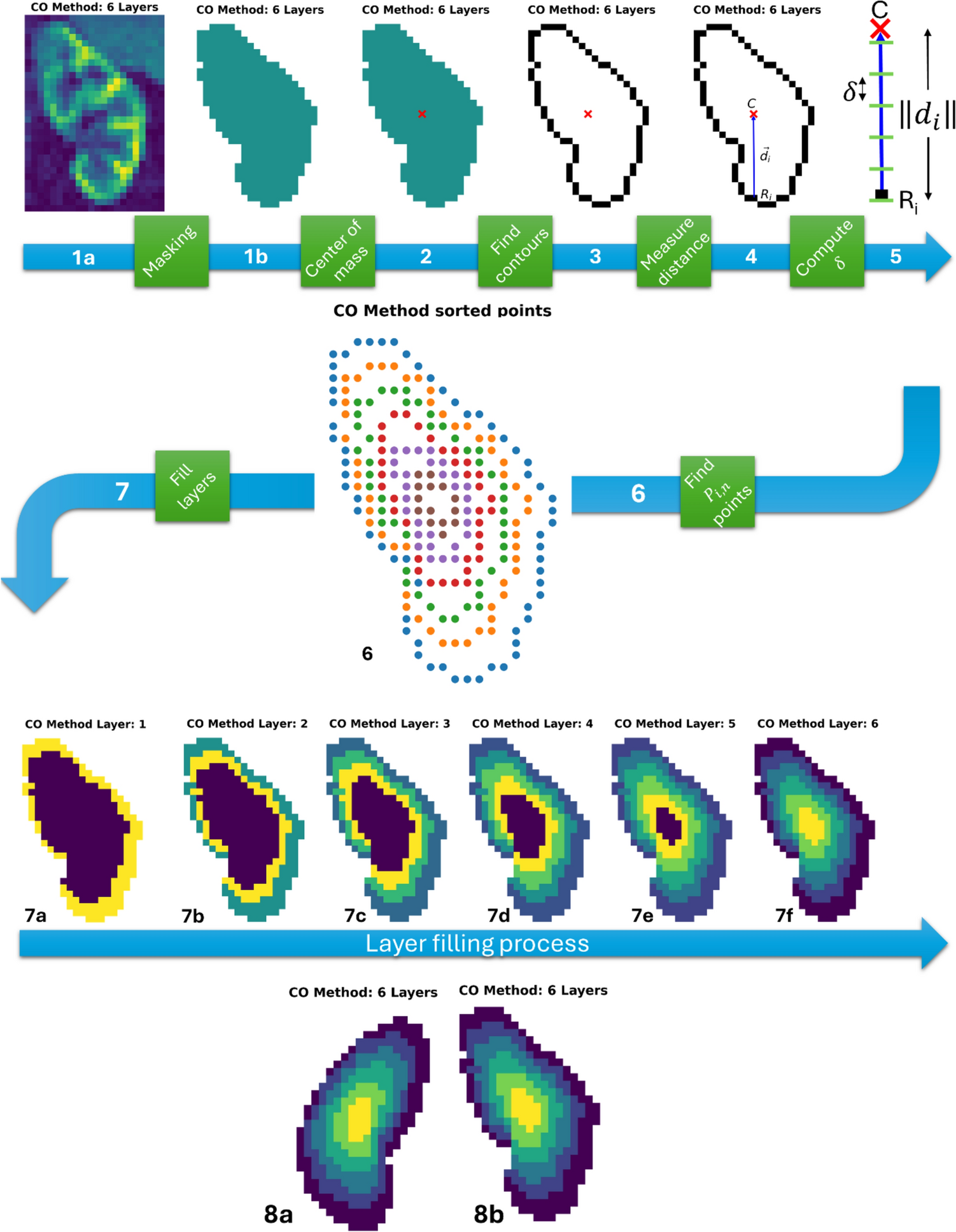
Flowchart of SAD. Initially, we compute the sum of autocorrelation of each voxel time-series (\(S_\)) across 20 time-lags (see also Fig. 1 and 2). Subsequently, using Eq. (4) (highlighted in red), \(_\) is computed and voxel time-series, \(}_\), with \(S_\) below \(\frac_}\) and above \(1-\frac_}\) are assigned with label 0 and 1, respectively to create the initialization pool. After first training the neural network with the initialization pool, class probabilities are predicted via \(_\left(}_\right)= \frac_(}_)}_)}\) for all unseen voxels and thresholded with high confidence level \(c\). Pseudo-labels 0 and 1 are assigned to the bottom and top 500 samples. For example, a sample is assigned with label 1 if \(_>c\) and it is entered into the set if it has one of the 500 highest \(_\). Finally, the training pool and the neural network are updated with the newly assigned samples. The updating procedure is stopped when either less than 500 samples are found or another stopping criterion such as the total number of iterations is met. At each iteration the newly added samples are split 70% vs 30% into further training and validation sets, respectively
Step 2 requires choosing the hyperparameter \(c\), defined by
$$- \log \left( - 1} \right) \le quantile_ }}}} \left( \right)$$
(5)
where \(\text(\cdot )\) denotes the natural logarithm and, similarly to \(_\) above, ensures that only voxels whose labels can be assigned confidently will be added to the training pool. Like setting hyperparameters in general, determining the optimal confidence level is an empirical problem. We have settled on \(c=0.98\) which fulfills Eq. (5) and provided reliable results.
At each iteration, the neural network is trained using the Adam optimizer [38], batch size of 32, 50 epochs, 0.001 learning rate and hidden dimensions of 15, 10 and 3 (correspond to \(_,_\) and \(_\) in Fig. 3). In total, the network has 4734 parameters.
Additionally, in each iteration, the sample pool undergoes a pseudo-random split, with 70% allocated to the training set and 30% to the validation set, where cross-entropy losses are then computed.
The neural network is programmed in Python (version 3.9.12) with PyTorch (version 2.0.1).
After the neural network is trained, class probabilities are predicted using the trained model across either all voxel time-series of the same data set or approximately 12,000 manually labelled voxels of an independent 2nd data set (further details below).
Motor and visual taskThe stimulus paradigm was previously reported in Schmidt et al. [26]. Briefly, the visual stimuli were created using nordicAktiva (Nordic NeuroLab, Bergen, Norway) software and presented on an MRI-compatible screen measuring 40 inches in diameter with a resolution of 3840 × 2160 pixels. The participant was instructed to focus on a small white cross situated at the center of a uniform gray (R/G/B-127/127/127) background.
The visual stimulus was a flickering (8 Hz for 375-ms) black and white checkerboard whose appearance also served as a cue for the participant to squeeze a response grip with the dominant hand. These motor responses were slightly delayed relative to the visual stimulus.
The paradigm encompassed 20 visual stimuli, which were slightly and progressively shifted relative to the acquisition repetition time (TR) to coincide with the time of acquisition of one of the 20 slices on consecutive trials. The 20 stimuli were repeated 5 times, but pseudo randomly on one of the 5 repetitions the visual stimulus (and hence the motor response) was omitted for each of the 20 slices.
Data acquisitionParticipantsThe Cantonal Ethics Committee of Zurich (2020-00208_TS12) approved the study, which involved one right-handed male adult participant, who signed a written informed consents prior to scanning. The participant was scanned twice on two different days with the same stimulus paradigm and imaging protocol. The first dataset was used for training and validation of the SAD method, while the second dataset was manually labelled and used as a test set for the trained model. Henceforth, the set of gray matter voxels extracted from the first fMRI dataset will be denoted as STrain, while that from the second data set will be denoted as STest.
Imaging protocolThe imaging protocol was previously reported in Schmidt et al. [26]. Briefly, the data were collected on a 7T MAGNETOM Terra scanner (Siemens Healthineers, Erlangen, Germany) equipped with a single-channel transmit and 32-channel receive head coil (Nova Medical Inc., MA, United States). The acquisition utilized a 2D EPI sequence [39] with a multiband acceleration factor of 3 [23, 25] to collect 60 slices and provide full brain coverage. Further sequence parameters can be found in Table 1. Additionally, a 3D T1-weighted MP2RAGE [40] image with 1-mm isotropic resolution was collected for anatomical guidance and extracting the gray matter segment from the EPI images.
Table 1 Acquisition sequence parameters
留言 (0)