
記住我
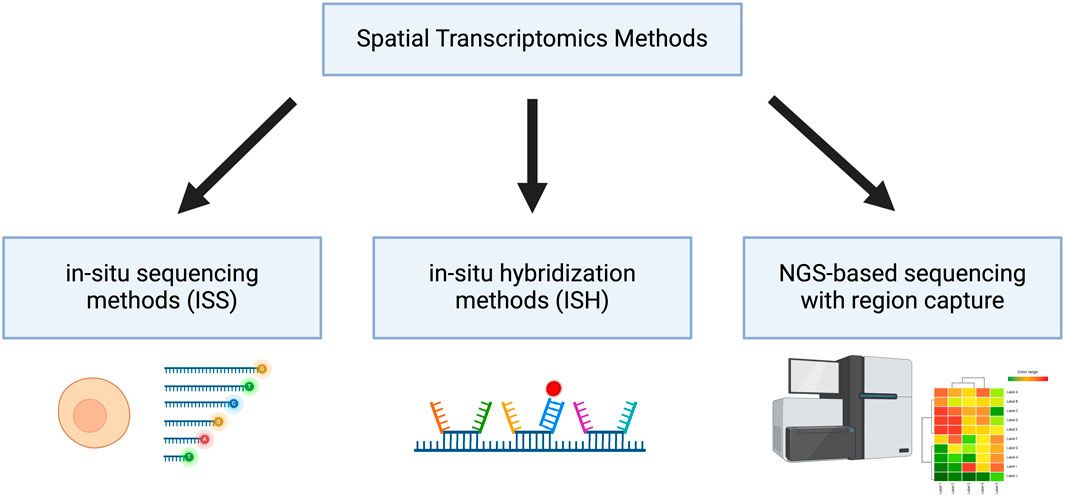



With the advent of omics, we have gained the ability to study cells in a more holistic approach, opening new insights into cellular heterogeneity, cell function, interactions and responses to stimuli (T. Y. Chen et al., 2023; Kolodziejczyk et al., 2015; Patel et al., 2014; Vandereyken et al., 2023). Referring to the Transcriptomics subdiscipline, which studies all the RNA present in a cell at a specific time, great advances have been made to reveal information about the expression levels of genes. Whereas in the past, only standard methods such as Real Time Quantitative PCR (RT-qPCR) and Northern blotting could be used, we can now apply novel transcriptomics techniques. With the help of transcriptomics methods, valuable information about all or most actively expressed genes and their tissue-specific and intercellular variations can be disclosed (Mistry et al., 2020). Furthermore, spatial transcriptomics additionally provides the locations of the certain RNAs detected in the cell. This can be done by using multiplex imaging approaches, i.e., high-throughput imaging of large numbers of RNAs. During the last years, new transcriptomics methods have appeared and have been applied to characterize cells, study the development and the biological basis of diseases. A broad classification of these methods can be made dividing them into in situ sequencing (ISS) methods, in situ hybridization (ISH) technologies and methods combining next-generation sequencing (NGS) with region capture (Figure 1) (Rao et al., 2021). Recently, many reviews have been published that give a great overview over the landscape of spatial transcriptomics methods, e.g., the review from Cheng et al., 2023.
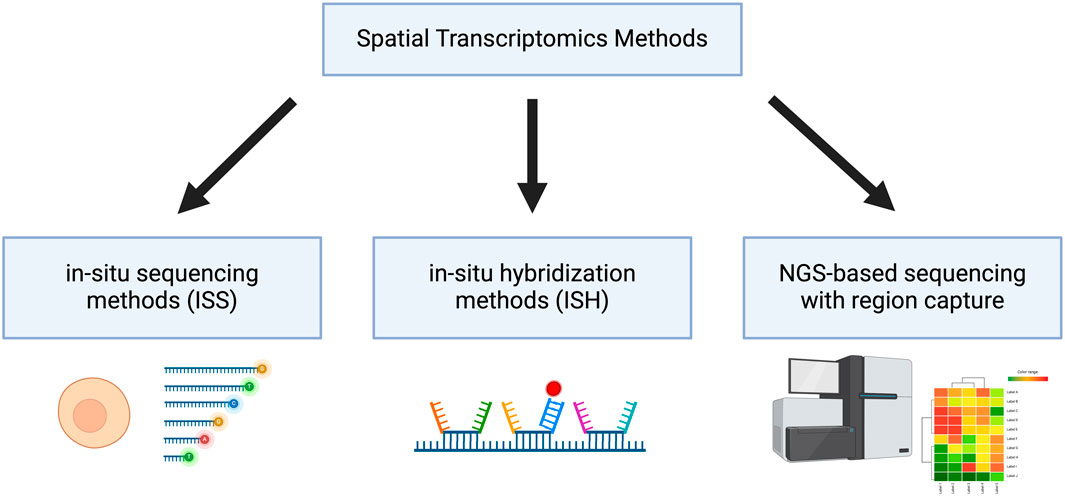
Figure 1. Classification of Spatial Transcriptomics Methods Spatial transcriptomic methods can be categorized into in situ sequencing methods (ISS), in situ hybridization methods (ISH) and next-generation sequencing (NGS)-based sequencing with region capture. Created with BioRender.com.
Expansion Microscopy (ExM) is a super resolution and tissue clearing technique using physical tissue expansion to overcome the resolution limit of the standard light microscope (Tillberg et al., 2019). Whereas the resolution of a light microscope alone is maximum 250 nm, structures as small as 70 nm can be detected using expansion microscopy with the same microscope, after physical expansion (Zhao et al., 2017). The ExM technique has been developed in 2015 by Chen et al. and further optimized for multiple purposes, including for Pathology. Expansion Pathology (ExPath) has been introduced to facilitate the transition of the method into the clinical context (F. Chen et al., 2015; Bucur et al., 2020; Bucur and Zhao, 2018). ExM is based on four essential steps: (1) labeling biomolecules for later crosslinking to the gel (2) polymerization of a gel inside cells (3) the digestion of cellular proteins using Proteinase K to enable (4) expansion of the gel by the addition of water, which swells and thus magnifies space between the cellular compounds.
In this paper, we explore some innovative transcriptomics methods that have been combined with ExM protocols and investigate how these methods have been improved by the use of ExM.
2 Methods in multiplexed spatial transcriptomics2.1 In situ sequencing methodsIn in situ sequencing (ISS) methods sequencing is directly carried out on the single-cell or tissue. In order to perform these methods, complementary DNA (cDNA) first needs to be synthesized from the RNA in situ, which can then be used for the sequencing (Vandereyken et al., 2023). ISS can either target specific RNAs or it can sequence the RNA present in cells in an untargeted approach (Rao et al., 2021; Vandereyken et al., 2023). An advantage of untargeted approaches is that they enable identification of the variability of RNAs depending on their location in the cell and the detection of splicing differences as well as accumulation of excised introns (Morgan et al., 2019; Alon et al., 2021). Since the first use of ISS by Ke et al., in 2013 who examined the expression of target genes in breast cancer, this technology has been adapted and further developed (Ke et al., 2013). Lee et al. (2014) introduced fluorescent in situ RNA sequencing (FISSEQ) being the first untargeted approach to transcriptomics (Lee et al., 2014).
2.1.1 Fluorescent in situ RNA sequencing (FISSEQ)Fluorescent in situ RNA sequencing (FISSEQ) sequences RNAs directly in a cell creating quantitative information about the amount of specific RNAs throughout the cell and qualitative data, i.e., the sequence of the RNAs which can be then used for further analysis.
After fixation and permeabilization of the cells, the method involves reverse transcription of the RNA to cDNA within the cell, accompanied by the addition of aminoallyl dUTP molecules which incorporate into the cDNA (Lee et al., 2015). Subsequently, critical adaptors needed for the later sequencing step are ligated to the ends of the cDNAs. A chemical reaction then cross-links the cDNA template to the protein matrix of the cell to prevent locational change due to diffusion. RNA degradation follows to remove competitive inhibitors of CircLigase, an enzyme catalyzing the ligation of single stranded DNA into circles.
Circularized cDNA serves as a template during rolling circle amplification (RCA), a technique for nucleic acid amplification which in contrast to the widely used polymerase chain reaction (PCR) operates isothermally and uses a circular DNA as a template (Garafutdinov et al., 2021). RCA involves three steps: (1) Annealing of a starting primer to the single-stranded circular DNA template, (2) synthesis of the complementary strand along the circle by a special polymerase with strand displacement activity and (3) displacement of the copy from the circular DNA template as soon as the 5’ end of the primer is reached, while at the same time continuing the synthesis along the circle (Garafutdinov et al., 2021). This procedure thus creates one long single-stranded DNA which can contain between 10 to a few thousand copies of the template (Lee et al., 2015; Garafutdinov et al., 2021). In this experiment aminoallyl dUPTs are also used during RCA and cross-linking is again performed in order to form the long amplified DNA copy into a tuft called the RCA amplicon (Figure 2A). RCA amplicons typically measure around 200–400 nm in diameter (Lee et al., 2014). While this small size allows for dense localization within the cellular context, the high abundance of these amplicons can lead to optical crowding. Optical crowding can potentially impact the accuracy of FISSEQ by making it difficult to resolve closely spaced transcripts. Proper optimization and careful interpretation of the data are essential to mitigate these issues and ensure precise RNA localization and quantification.
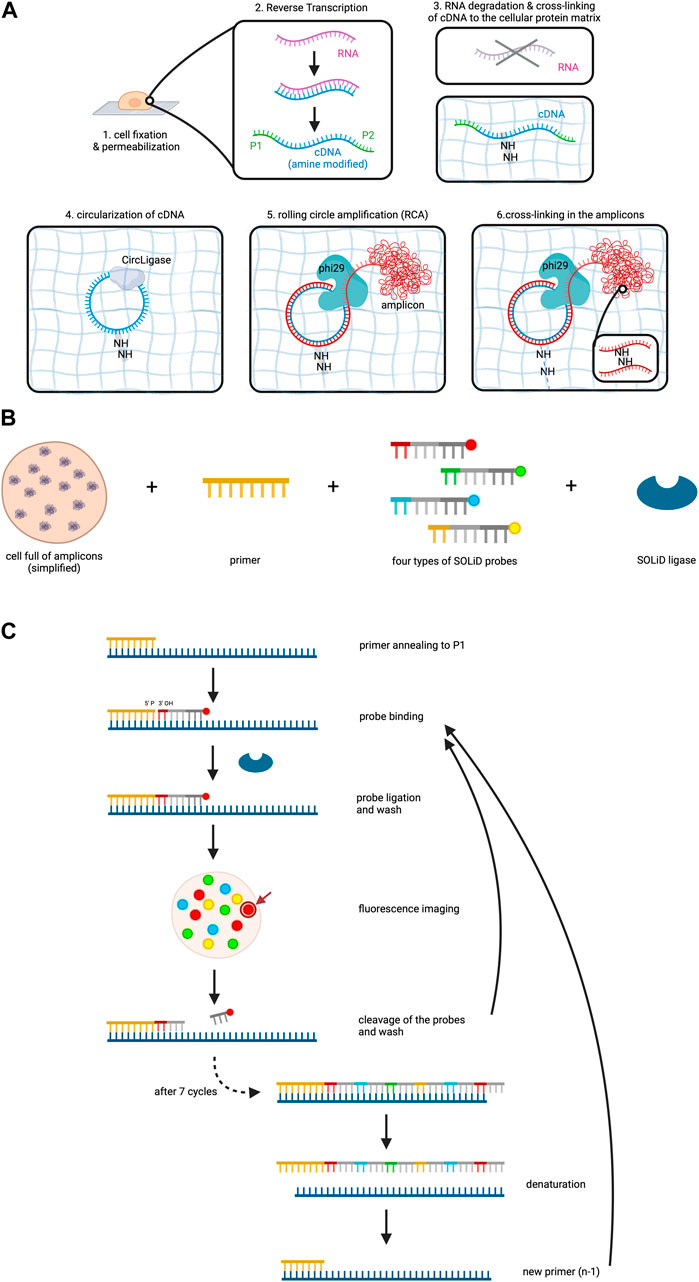
Figure 2. FISSEQ. The figure depicts the FISSEQ method for spatial transcriptomics. (A) library preparation for in situ sequencing. After fixing the cell on a glass slide and making it permeable with Triton X100, reverse transcription of the RNA is performed. A cDNA strand is synthesized from the RNA, which is amine-modified by the addition of aminoallyl dUTP during synthesis. The P1 and P2 adaptors are attached to the respective ends of the cDNA, which is needed for later sequencing steps. The RNA is then degraded and the primary amine groups of the aminoallyl dUTPs are used to anchor the cDNA in place on the cellular protein matrix. The cDNA is circulated by CircLigase in order to perform rolling circle amplification on the cDNA. Thus, a long strand of DNA is created which is called an amplicon and is cross-linked in the next step. (B) key reagents needed for SOLiD sequencing. All RNA in a cell has been prepared and is now available for sequencing. The copies of the initial RNA are bordered by P1 and P2 adaptors as explained above. Furthermore, a primer complementary to the P1 adaptor, four types of probes and the SOLiD ligase are needed. (C) SOLiD sequencing mechanism. After annealing the primer to the DNA template, the fitting probe binds to the template and is ligated to the primer by SOLiD ligase. The color of the fluorescent dye can be detected during imaging at the specific location in the cell. The arrow gives an example of where the fluorescent dye used in this figure may be visualized in the cell under the microscope. This is followed by cleavage to remove the fluorescent probes. The next cycle starts again with the addition of probes. After seven cycles the newly synthesized strand is removed and a new primer that is one base shorter than the first one is added. The whole procedure is repeated until in total five rounds have been completed, i.e. 5 different primers have been used. Created with BioRender.com.
Sequencing utilizes sequencing by oligonucleotide ligation and detection (SOLiD) which is carried out at room temperature under a confocal microscope (Lee et al., 2015). SOLiD, invented at the George Church laboratory at Harvard Medical School in 2005 and subsequently improved and commercialized upon 2 years later by Applied Biosystems necessitates cDNA fragments flanked by P1 and P2 adaptors on opposite ends, a step which has already been addressed during reverse transcription of the RNA (Shendure et al., 2005; Voelkerding et al., 2009). Primers are introduced, annealing to the P1 adaptor and providing a 5′ phosphate group for ligation (Voelkerding et al., 2009; Lee et al., 2015). Next, eight nucleotide long probes are added which are attached to a fluorescent dye. These probes are made up of four distinct parts which from 3′ to 5′ are: (1) a combination of two bases, e.g., AT, CT, GG. As there are four bases, a permutation of 16 bases is possible. (2) three degenerate bases able to bind to any of the four bases A, T, C and G. (3) three inosine bases and (4) a fluorescent dye (Lee et al., 2015; Voelkerding et al., 2009; ATDBio - Next-Generation Sequencing, n.d.).
Four types of probes, each with a unique fluorescent dye color corresponding to specific base combinations, are employed (Voelkerding et al., 2009). SOLiD ligase is then added to initiate sequencing (Figure 2B). The process involves primer binding to P1, complementary probe annealing to the DNA fragment adjacent to the primer, and SOLiD ligase joins the 5′ phosphate group of the primer with the 3′ hydroxyl group of the probe. After a washing step, the fluorescent signal of the probe is measured, which is followed by cleavage of the fluorescent dye including the adjacent three inosine bases of the probe, resulting in a five-base-long remaining probe (Voelkerding et al., 2009; Lee et al., 2015). Seven cycles of probe annealing, ligation, washing, fluorescence measurement and washing are repeated.
To this point, the data collected only comprises the fluorescent measurement for each fifth base on the DNA fragment. In order to identify the bases that lie in between, denaturation is performed to remove the newly synthesized strand, followed by the addition of a new primer off-set by one base (n-1) (ATDBio - Next-Generation Sequencing, n.d.; Lee et al., 2015; Voelkerding et al., 2009). In total, five cycles are performed (n, n-1, n-2, n-3, n-4), ensuring data collection for each base on the DNA fragment and even more so, it means that each base of the DNA fragment has been read out twice (Figure 2C).
The data generated by SOLiD sequencing is next interpreted by analyzing the colors emitted in the five rounds. Therefore, the 3D cell images are processed by 3D deconvolution techniques and MATLAB to precisely overlay colors and convert those into TIFF images. Thus, pixel colors are analyzed to deduce the base sequence using Python. This base sequence is then compared to the reference transcriptome (Lee et al., 2015). In the Python sequence analysis, it is taken into consideration that each color corresponds to four distinct base combinations. By integrating information about the base’s position on the sequenced DNA inferred from the round and cycle the color reading had been obtained in, and an algorithmical decoding of the color’s bases, the sequence of the DNA template and thus of the initial RNA can be determined (Valouev et al., 2008; Voelkerding et al., 2009). Ultimately, the parameters obtained by data analysis encompass various aspects such as “the number of individual pixels per object, gene ID, consensus sequence, x and y centroid positions, number of mismatches, base call quality and alignment quality” (Lee et al., 2015).
2.1.2 Expansion sequencing (ExSEQ)Alon et al. have combined in situ sequencing with the method of expansion microscopy (ExM) to enable high-resolution imaging of RNA in the subcellular compartments (Alon et al., 2021). Expansion sequencing (ExSEQ) is based on FISSEQ but offers better accessibility to the RNA inside the cell as the amplicons become less dense, and more precise spatial mapping (Wassie et al., 2019; Alon et al., 2021). The experiment starts with tissue fixation and permeabilization, followed by RNA anchoring and the alkylation of RNA bases with LabelX to anchor RNAs to the cellular matrix (Alon et al., 2021).
This is a critical step to prepare the biomaterial ensuring even distribution of the cross-linked RNAs along with cell matrix molecules during the later expansion step. Subsequently, cells are put into a gelling solution and then transferred into a gel chamber where radical polymerization takes place (Alon et al., 2021). This is followed by digestion carried out in overnight incubation with Proteinase K which is responsible for protein cleavage and release of nucleic acids (Alon et al., 2021). Lastly, expansion is performed by incubation of the cells in double-distilled water (ddH2O) (Alon et al., 2021). The purpose of digestion is to prepare the cells for expansion as it enables the cleaved proteins, especially structural proteins, to spread in an isotropic way during expansion. At this point, an expansion of approximately 3.3x of the cells can be obtained (Figure 3) (Alon et al., 2021).
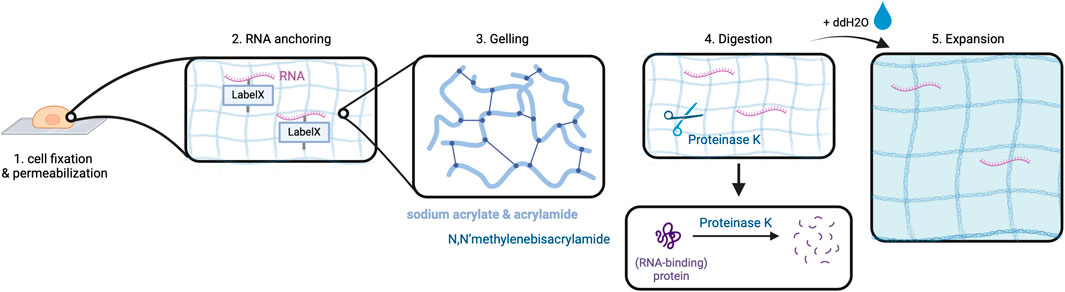
Figure 3. Expansion in ExSEQ. After fixing and permeabilizing the cell (1) RNA anchoring: cellular biomolecules including RNA are labeled for later anchoring to the gel, which is achieved by covalently binding the LabelX to the RNA and the protein matrix (2). The cell is placed in a gel chamber, in order for the gelling solution to polymerize (3). Proteinase K cleaves the protein matrix of the cell into pieces (4) that can then spread isotropically after the addition of water, depicted as a light blue background in (6). Created with BioRender.com.
The next step is re-embedding, i.e., the expanded gel is placed into a polyacrylamide gel that does not expand (Alon et al., 2021). This step is necessary to ensure that the expanded gel does not change its conformation further, because it would falsify the results during RNA sequencing (Alon et al., 2021). Because of an inhibition of enzymes needed for later sequencing by carboxylic acid groups of sodium acrylate in the expansion gel, passivation is required (Alon et al., 2021). During passivation, ethanolamine forms a covalent bond to the carboxylic groups which results in a chargeless amide (Alon et al., 2021).
From here, the experiment continues with the FISSEQ procedure. More precisely, the RNA is reverse transcribed and then removed, cDNA is circularized and RCA is performed (Alon et al., 2021). Prior to these steps, the cell’s genome is digested by DNAse I to avoid contamination of the cDNA (Alon et al., 2021). As the ExM protocol is conducted before the RCA step, the size and density of RCA amplicons remain unchanged when compared to the standard FISSEQ procedure. However, the increased distance between neighboring replicons enhances RNA resolution. Lastly, SOLiD sequencing using confocal microscopy can be carried out to obtain the data, which can then be interpreted (Alon et al., 2021).
2.1.3 Other in situ sequencing approachesExamples of other ISS methods are ISS using padlock probes (Ke et al., 2013) and STARmap (spatially resolved transcript amplicon readout mapping) (X. Wang et al., 2018), which are both targeted approaches for ISS. FISSEQ in contrast to these other two methods is untargeted and does not use padlock probes. Padlock probes are DNA oligonucleotides whose ends are complementary to two adjacent parts of a targeted RNA or DNA sequence. The padlock probes’ 5′ and 3′ end sequences are designed in a way, so that the padlock probe oligonucleotide forms into a circle when those end sequences bind to the targeted RNA or DNA respectively. The padlock probe is then used to perform RCA on the target sequence to create the amplicons needed for sequencing. Additional to the untargeted ExSEQ method described above, Alon et al. also presented a targeted approach of ExSEQ which is based on barcoded padlock probes that hybridize to the target RNAs. RNA detection then occurs by sequencing the barcodes (Alon et al., 2021).
Although STARmap also embeds the tissue in a hydrogel, it does not do that with the purpose of performing expansion on the tissue, but rather to optimize imaging conditions, as the induction of the gel into the tissue ameliorates transparency and decreases background noise. Hence, tissue expansion by ExM technology has not yet been used on these ISS approaches which is why we do not go into further detail here.
2.2 In situ hybridization methodsFluorescence in situ hybridization (FISH) is a widely used method with many applications in molecular biology and diagnostics. By delivering fluorescent labeled probes into a cell which hybridize to a complementary target sequence, the detection of specific DNA or RNA sequences in cells is made possible (Bayani and Squire, 2004). This procedure has been adapted to enable transcriptome-wide analyses. Firstly, single-molecule FISH (smFISH) methods have emerged visualizing and quantifying RNA in fixed cells by hybridization of cellular RNA to a number of different FISH probes containing colored fluorescent dyes (J. Chen et al., 2018; Lubeck et al., 2014; Lubeck and Cai, 2012; Raj et al., 2008). However, only a limited number of RNAs (ca. 30) could be studied by these methods at a time because of the restricted number of fluorescence channels for the fluorophores (Zhuang, 2021). Recently, advances have been made to increase throughput of ISH methods and lead to the development of the methods MERFISH and RNA seqFISH. The main difference between these methods lies in the barcoding to infer RNA identity: While MERFISH uses a binary barcode to identify RNA types, RNA seqFISH encodes RNAs through color-schemed barcodes.
2.2.1 Multiplexed error-robust fluorescence in situ hybridization (MERFISH)MERFISH is an innovative method employing combinatorial labeling with high throughput imaging and error-robust barcoding. When it was first introduced by Chen et al., in 2015 it enabled the simultaneous analysis of about 1,000 genes (K. H. Chen et al., 2015). This capacity has been enhanced by integrating MERFISH with ExM to address more than 10.000 genes in one single MERFISH experiment (see 2.2.2). However, in contrast to ISS methods, ISH technology can only be performed in a targeted approach because knowledge about the RNA types in a cell to be identified in the ISH method is a prerequisite to encode the FISH probes. MERFISH enables location, identification and quantification of RNA types of the transcriptome. To avoid misunderstandings, it should be clarified that the terms “RNA type” and “gene” are used synonymously in this article. However, we more frequently use the term “RNA type” as it emphasizes the RNA nature of the molecules under consideration.
The key aspect of MERFISH lies in the assignment of each targeted cellular RNA type to a specific binary barcode composed of the digits (bits) 0 and 1. These digits indicate if the specific RNA type emits a fluorescent color during the respective imaging round corresponding to the bit one in the code, or if no color will be measured by the fluorescence microscope which is encoded as the bit 0. For example, the barcode 100 means that in the one particular spot on the images, i.e., the same location within the cell, a fluorescence signal will be measured in the first imaging round, but in round two and three the spot will remain dark. In order to achieve this alternating light emission for a specific RNA type in the different imaging cycles, the design of so-called encoding probes is essential. These encoding probes hybridize with high specificity to the RNA type which they have been designed for. Additionally to the RNA type specific sequence, the encoding probes contain certain sequences which serve as binding spots for oligonucleotides linked to a fluorescent dye. The color emission observed under the microscope is then achieved by the addition and removal of the fluorescent dye-linked oligonucleotides in each round which can either bind to the encoding probe of a specific RNA type or not.
However, one aspect that has to be considered is the proneness to error: a misreading of 1 bit alone produces a falsified binary barcode that matches to a different RNA type (K. H. Chen et al., 2015). Thus, the RNA type that is actually located in a particular spot would be mistaken for another RNA type just because of an error in one imaging cycle. This also clarifies that the risk of error increases with the amount of MERFISH cycles carried out (K. H. Chen et al., 2015). To address this, smartly designed, so-called error-robust barcodes can be generated by introducing a Hamming distance for all the barcodes (K. H. Chen et al., 2015). Hamming distance is a concept in informatics which describes the number of positions within a string that differ to all the other strings in the same data set. For instance, at a Hamming distance of 4, 4 bits can be changed by errors without resulting in a barcode that encodes another RNA type. Instead, the error in the barcode can be detected and changed by the programme to enable correct RNA type identification (K. H. Chen et al., 2015).
Thus, to start the experiment, the data on RNA types/genes to be targeted in the MERFISH experiment including their sequences are retrieved from databases, in order to assign each gene to their respective error-robust barcode and to generate specific encoding probes (K. H. Chen et al., 2015; Moffitt et al., 2016). Each encoding probe consists of the following components: (1) a target-binding region in the center for hybridization to the specific RNA type, (2) different readout sequences bordering the target-binding region for fluorescent dye binding, (3) primers framing the readout sequences to both sides to enable encoding probe amplification. The number of encoding probes depends on the number of RNA types to be sequenced. Generally, the more encoding probes per RNA type are used, the stronger is the potential fluorescence signal under the microscope.
Referring to the readout sequences on the encoding probes, homology to cellular RNA has to be avoided in order to prevent errors during hybridization (K. H. Chen et al., 2015). Each specific readout sequence corresponds to one cycle of hybridization and imaging, and is complementary to a readout probe, which is composed of an oligonucleotide attached to the fluorescent dye. Following synthesis of the encoding probes and readout probes, cells are immobilized on a coverglass and permeabilized before exposure to encoding wash buffer (K. H. Chen et al., 2015; Lee et al., 2014). Encoding probes in a hybridization buffer are then pipetted on a microscopic slide which is next covered with the cell-coated coverglass (K. H. Chen et al., 2015; Moffitt et al., 2016). The cells are then incubated to enable hybridization (Figure 4A). Subsequent steps involve washing, incubation with fluorescent beads for later image alignment and fixation of the sample with paraformaldehyde (K. H. Chen et al., 2015).
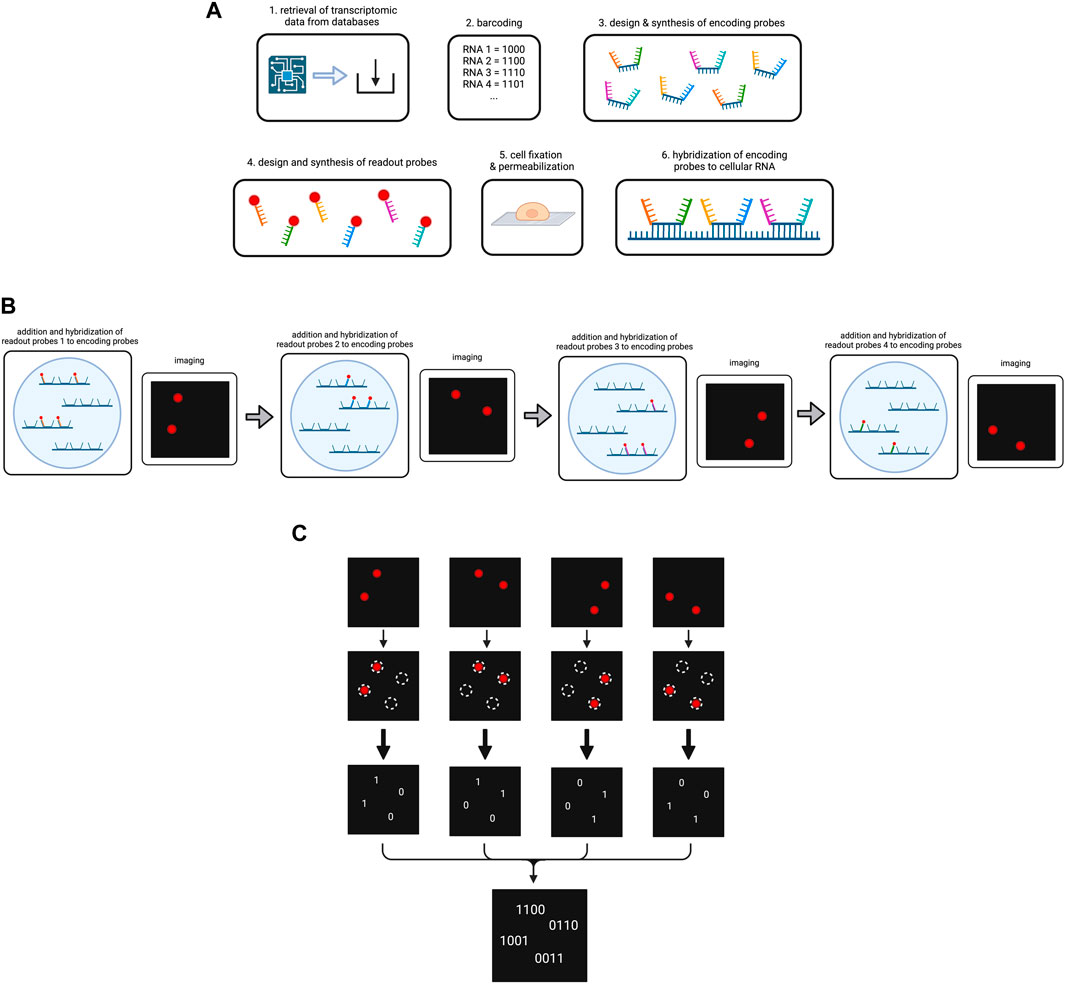
Figure 4. Overview on the MERFISH method. (A) Preparation of the cellular RNA library. Targeted RNA types are determined and encoded by a barcode each. The encoding probes and readout probes are designed and synthesized. After cell fixation and permeabilization encoding probes are added to the cells, so they hybridize to the cellular RNA. (B) Simplified scheme of the operating principle of MERFISH cycles. For the purpose of simplification, our cell contains four RNAs that have been hybridized to encoding probes. We use four different readout probes in four MERFISH cycles. In each cycle a different type of readout probe is added which hybridizes to the respective readout sequences on the encoding probes. After hybridization, imaging occurs and shows the RNAs that have bound to the respective readout probe. The fluorescence is then removed for the next cycle to start. (C) Decoding of the MERFISH images. The single images from each MERFISH cycle are analyzed to determine the spots in which targeted RNAs are located. A present or lacking fluorescent signal in the respective spot is transformed into the bits 1 or 0. Combining the bits from each MERFISH cycle, the binary code is obtained that indicates which RNA type is located in the respective spot. Created with BioRender.com.
At this point, MERFISH cycles can start, which are carried out in a flow chamber under the fluorescence microscope. In each round, the sample is hybridized with readout probes, imaged for fluorescent light emission and decolorized by removal of the fluorescent dye (Figure 4B). In more detail, one type of readout probes per MERFISH cycle dissolved in a hybridization buffer is infused into the chamber. During incubation the readout probes hybridize to the corresponding readout sequences on some of the encoding probes. The flow chamber then washes the sample and imaging occurs for two color channels: one for the readout probes and one for the beads (X. Chen et al., 2019). In order to remove the fluorescent light emission, either photobleaching or cleavage of the fluorescent dye, e.g., by TCEP (tris(2-carboxyethyl)phosphine) can be performed, and the samples are imaged again to check if the decolorization was successful (K. H. Chen et al., 2015; Moffitt et al., 2016). The number of cycles has been determined during the barcoding of the RNA types as it corresponds to the numbers of bits in the codes.
Upon completion of all cycles, image alignment is performed with the help of the fluorescence signals by the small fluorescent beads in each image and a coordinate system is established for data analysis (K. H. Chen et al., 2015). A multi-Gaussian-fitting algorithm is used to identify RNA location from fluorescence signals (K. H. Chen et al., 2015). For instance, it can detect overlapping readings in a pixel and correctly assign them to two different individual RNA. Each image is analyzed for whether a fluorescence is measured at a specific location (1) or not (0) and the bits are noted to obtain the final binary code for the respective RNAs (Figure 4C) (K. H. Chen et al., 2015). From the obtained binary codes, the RNA type in each of the locations can be concluded. The MERFISH procedure is depicted in Figure 4.
The MERFISH method can be further enhanced to study a broader range of genes simultaneously firstly by increasing barcode length and thus number of readout probes and hybridization rounds, and secondly by using more fluorescent colors channels per hybridization cycle (Moffitt et al., 2016). Hence, the total number of possible RNA types that can be studied in a MERFISH experiment can be theoretically calculated by multiplying the number of hybridization rounds (N) which equals the numbers of digits per barcode, with two because each digit has two possible outcomes (1 or 0) which in turn is multiplied with the amount of colors used (C): 2NC = number of RNA types distinguishable in the MERFISH experiment (Zhuang, 2021).
2.2.2 Application of expansion in MERFISHRecently, performance of the MERFISH method has been improved by combination with ExM (Wang et al., 2018; Xia et al., 2019). Application of the ExM technology decreases RNA density which significantly improves resolution, allowing for more genes to be studied in a MERFISH experiment. Hence, in 2019, Xia et al. demonstrated the detection and identification of 10.050 genes using a total of 69 readout probes and three fluorescent dyes across 23 hybridization cycles performed (Xia et al., 2019).
The procedure is very similar to the MERFISH method by Chen et al. and starts with the creation of error-robust barcodes, design and synthesis of encoding probes and readout probes similarly as described above (Xia et al., 2019). Besides, labeling of cellular structures, e.g., the nucleus and endoplasmic reticulum (ER) can be carried out to better characterize the location of RNA spots in the cell (Xia et al., 2019). To do so, the stain DAPI can be used for nuclear visualization, while KDEL can be used to label the ER. Cells are immunostained after cell fixation and permeabilization to a coverglass (Xia et al., 2019). Immunostaining includes a primary antibody binding to subcellular structures and a secondary antibody which is conjugated with oligonucleotides that can later hybridize to fluorescent complementary probes that can be visualized in an imaging round before the start of the MERFISH cycles (Xia et al., 2019). The antibody labeling is fixed with PFA to avoid their detachment in the further procedure. The experiment continues with hybridizing the encoding probes to the cellular RNA. However, to prepare the cellular RNA for expansion, acrydite-modified poly(dT) locked nucleic acid (LNA) probes are added into the hybridization solution, where they hybridize to the poly(A) tails of mRNAs which enables anchoring to the expansion gel (Wang et al., 2018; Xia et al., 2019). This is followed by incubation with small beads that are to be used for location reference to align multiplexed images in a later step as previously described (Figure 3).
For ExM, the cells are firstly incubated with a gel solution and polymerization is started. Digestion is carried out by placing the sample into a solution of sodium dodecyl sulfate (SDS), Triton X-100, Proteinase K and SSC overnight (Xia et al., 2019). Then, isotropic expansion is performed in saline sodium citrate (SSC) buffer, followed by re-embedding of the gel in a polyacrylamide gel to prevent conformational changes of the expanded gel (Xia et al., 2019).
The MERFISH cycles take place in a flow chamber and consist of the three procedures mentioned above: readout probe hybridization, imaging and fluorescence removal. In more detail the steps as described by Xia et al. are: (1) addition and hybridization of three encoding probes per cycle to the cellular RNA, (2) washing, (3) imaging, (4) removal of the fluorescent dye and (5) washing (Xia et al., 2019). Imaging is carried out at wavelengths corresponding to the three fluorescent dyes used, revealing three digits of the individual barcodes per cycle (Xia et al., 2019).
Once the data has been obtained image analysis is performed by aligning the images with the help of the signals from the beads, identifying fluorescence spots that indicate RNA location and transforming the light signals into bits to obtain the barcodes by a voxel-based decoding algorithm (Xia et al., 2019). Hence, the RNAs detected can be identified and counted to compare the amount of each RNA type. Additionally, as spatial relations are preserved the accumulation of RNA types in certain subcellular compartments can be examined.
2.3 NGS sequencing with region captureIn contrast to ISS and ISH technologies, RNA in NGS-based transcriptomic methods is physically extracted from the cells. After reverse transcription of the RNA into cDNA next-generation sequencing is performed to discover the identity of the RNA while the location can be traced back by the individually assigned barcode of the respective RNA. Hence, NGS-based sequences are not carried out in situ but require region capture and reconstruction of the spatial data after sequencing.
2.3.1 VISIUMThe VISIUM platform stems from the works of Ståhl et al., in 2016 (Ståhl et al., 2016). They introduced the first NGS-based transcriptomic method for transcriptome-wide analysis which they named “Spatial Transcriptomics” and was later commercialized by 10x Genomics to create the VISIUM platform. VISIUM transfers mRNAs from tissue sections onto a microarray with the help of capture probes and assigns each well to a specific barcode. A capture area (microarray of 6.5 × 6.5 mm) in VISIUM contains 5,000 spots. Each spot contains multiple fixed capture probes on the bottom that consist of Illumina TruSeq Read one at the 5’ (a sequencing primer for Illumina), a spatial barcode for tracing back the well-location of an mRNA, a unique molecular identifier (UMI) for tracing back the exact location of the mRNA inside the well and a poly(dT) primer for binding and thus capturing poly-adenylated mRNA (Hudson and Sudmeier, 2022) (Figure 5).
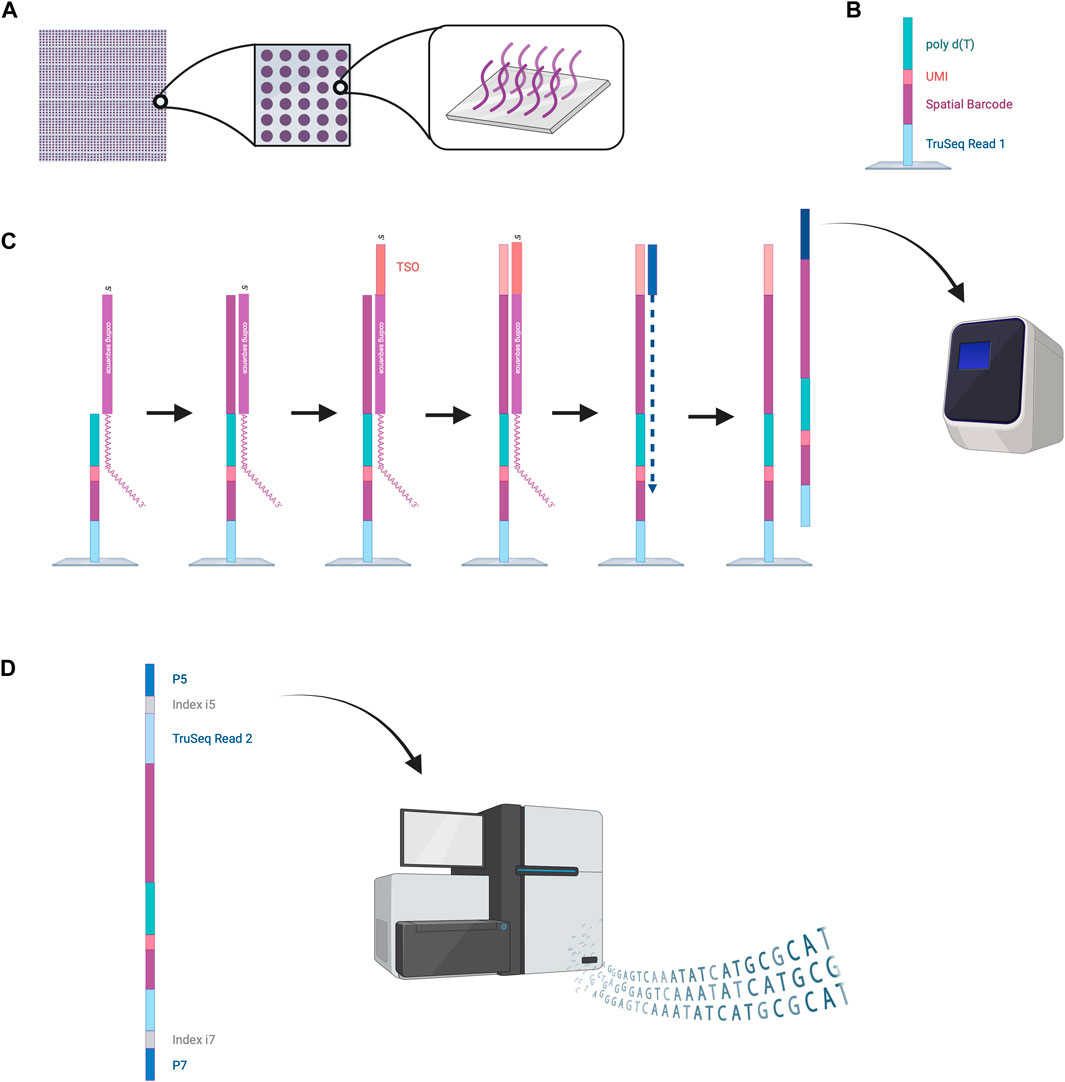
Figure 5. NGS-based sequencing with region capture by the VISIUM platform. (A) A capture area consists of 5,000 small spots in which capture probes are fixed to the bottom of the wells. (B) Structure of the capture probes. (C) mRNAs are captured inside the spots by the capture probes. Reverse transcription is performed, and second strand synthesis provides cDNA that is then amplified by PCR. (D) Amplified oligonucleotides are prepared for Illumina sequencing by the attachment of various oligonucleotides (TruSeq Read two sequence, indices, P5 and P7). These can be processed by the Illumina sequencer to read out the spatial barcode and UMI for spatial mapping and the RNA coding sequences for RNA identification. This data enables reconstruction of the cellular RNA map. Created with BioRender.com.
To start the experiment, a tissue slice is fixed on the microarray, stained with hematoxylin and eosin (HE) and an image is taken under a microscope (Hudson and Sudmeier, 2022). Cells are permeabilized to enable mRNA diffusion into the wells where mRNA is captured by the fixed capture probes. Inside these spots, reverse transcription is performed to obtain a cDNA oligonucleotide containing the illumina TruSeq 1 read, the spatial barcode, the UMI and the RNA-specific sequence (Hudson and Sudmeier, 2022). More precisely, the capture probe is firstly elongated with the RNA-specific complementary sequence and the 5′ end of the mRNA is extended with a template switch oligo (TSO) primer to prevent loss of information at the 5′ end. The TSO is then hybridized to a primer for complementary strand synthesis. After denaturation, cDNAs from each spot are transferred into separate tubes, amplified by PCR and prepared for sequencing (Hudson and Sudmeier, 2022). Preparation steps include the removal of the TSO, attachment of the TruSeq Read 2, and flanking with index regions. Lastly the cDNAs are flanked with P5 and P7 sequences, which will hybridize to the flow cell’s oligonucleotides during Illumina sequencing. The Truseq Read one and two are sequencing primer binding sites needed to perform sequencing-by-synthesis. The indexes work as identifiers to allow sequencing of multiple cDNA libraries. The last step is sequencing. Sequencing cycles reading Truseq Read one sequence the spatial barcode and UMI, whereas sequencing cycles reading Truseq Read two produce the data of the cDNA sequence (Hudson and Sudmeier, 2022). Utilizing the spatial barcode sequences, RNA locations in the tissue can be reconstructed providing valuable information about local gene expression patterns.
2.3.2 Expansion spatial transcriptomics (Ex-ST)A big disadvantage of VISIUM is the inability of obtaining single-cell transcriptomic resolution as the spots on the capture area each have a diameter of 55 μm, thus fitting more than 1 cell per spot and eventually mixing RNA data from different cell types (Fan et al., 2023). In 2023, Fan et al. combined the VISIUM platform with expansion to address this challenge and named this method “Expansion spatial transcriptomics” (Ex-ST). As expansion technology enables physical magnification of the tissue, cell size increases and mRNA availability is enhanced for region capture. It has been shown that when VISIUM is combined with ExM the cell number per spot is significantly decreased and resolution of VISIUM can be lowered from only 55 μm to 20 µm (Fan et al., 2023). Furthermore, the combination of these methods allows for more transcripts to be detected per normalized tissue area and conclusions about subcellular location of transcripts in certain types of cells, e.g., neurons, can be drawn (Fan et al., 2023). This brings valuable data to better characterize cell types and explore functional heterogeneity in tissues.
The experiment starts with fixation of cryosectioned tissue on a glass slide, which in contrast to the original VISIUM is followed by expansion. Before beginning the expansion procedure RNAs need to be anchored which is achieved by adding LNA to the hybridization buffer (Fan et al., 2023). The cells are gelled in the next step. Therefore the tissue is first incubated at low temperature in a monomer solution (PBS, NaCl, sodium acrylate, acrylamide, N,N′-methylenebisacrylamide) which is followed by radical polymerization upon the addition of APS along with TEMPO, tetramethylethylenediamine and 4-hydroxy-2,2,6,6,-tetramethylpiperidin-1-oxyl, a hindered amine light stabilizer used to stabilize the resulting polymer (Fan et al., 2023). Digestion is then performed overnight by Proteinase K diluted in digestion buffer, followed by gel expansion in SSC (Fan et al., 2023). At this point, the gel can be transferred onto the capture area of the VISIUM platform. Optionally, nuclei can be stained with DAPI before the transfer and imaged on the VISIUM microarray. Subsequent steps align with the standard VISIUM protocol, encompassing RNA release and capture by the capture probes, reverse transcription, second strand synthesis, cDNA amplification by PCR, cDNA processing for Illumina sequencing, and the placement of the VISIUM arrays into the Illumina sequencer for NGS to be performed (Fan et al., 2023). Modifications to the standard protocol were proposed by Fan et al. include adjustments to, e.g., reverse transcription temperature and the number of PCR cycles. The data obtained is processed by space ranger software from 10x Genomics where RNA transcripts are compared to the reference genome. The data can then be analyzed in Python and R to recreate spatial gene expression maps (Fan et al., 2023).
2.3.3 Other NGS-based methods with region captureSince the introduction of NGS-based approaches with region capture for spatial transcriptomics by Ståhl et al. many more similar methods have been developed to increase RNA detection yield. However, none of these methods except VISIUM have been previously combined with ExM protocols. Thus, the application of ExM on NGS-based methods with region capture offer a highly interesting research field with the potential of commercialization, given by its compatibility with next-generation sequencing technologies, which have become integral components of laboratory instrumentation in genetic research settings. Some examples for other NGS-based technologies with region capture include Slide-seq, Slide-seqV2, Stereo-seq and Seq-Scope.
Slide-seq (Rodriques et al., 2019) and Slide-seqV2 (Stickels et al., 2021) use arrays with adjacently positioned barcoded beads. After mRNA capture from the sliced tissue on the barcoded beads, the library is amplified and sequenced via NGS. The location of the transcripts can then be inferred from the barcodes. Slide-seq achieves a spatial resolution of 10 μm, which is significantly higher than the resolution of VISIUM (55 µm) and even than the combined method of VISIUM and ExM (20 µm). An optimized version of Slide-seq, Slide-seqV2 yields a nearly 10-fold increase in transcript detection per bead compared to the original version (Stickels et al., 2021) (Figure 6; Table 1). Thus, it becomes compelling to consider the implementation of ExM protocols within the framework of Slide-seq methodology, with the potential to surpass existing resolution limitations and enhance the efficacy of RNA detection.
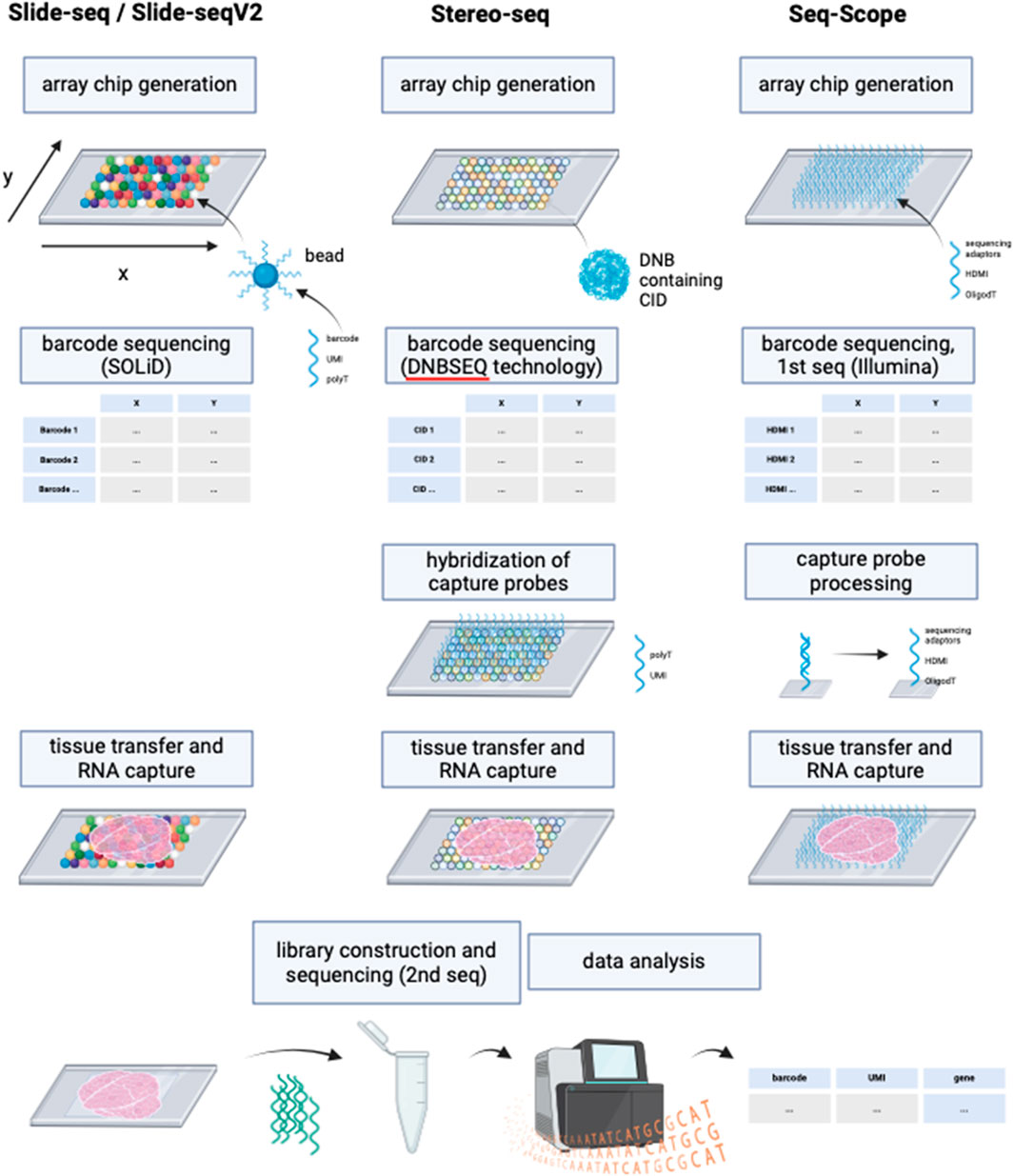
Figure 6. Schematic representation of the working principles of Slide-seq/Slide-seqV2, Stereo-seq and Seq-Scope. Although deploying different technologies, these NGS-based methods with region capture share resembling steps. While Slide-seq/Slide-seqV2 uses DNA-barcoded beads for RNA capture from tissue, Stereo-seq utilizes DNA balls (DNB) containing the barcode called coordinate identity (CID). Hybridization of oligonucleotides to the DNBs is then required for the following RNA capture from tissue. Seq-scope by contrast generates an array chip by high-definition map coordinate identifier (HDMI)-containing oligonucleotide amplification on a flow cell surface. All three methods have in common the barcode sequencing step after array chip generation to obtain coordinates for the barcodes’ location. In Seq-scope, processing is a required step before tissue transfer, to reveal sequences for RNA capture that have been hidden by sequencing-by-synthesis during first seq. Tissue is transferred onto the slides to enable RNA capture, followed by library construction to prepare for NGS (called 2nd seq in Seq-scope) and data analysis to infer RNA identity. Created with BioRender.com.
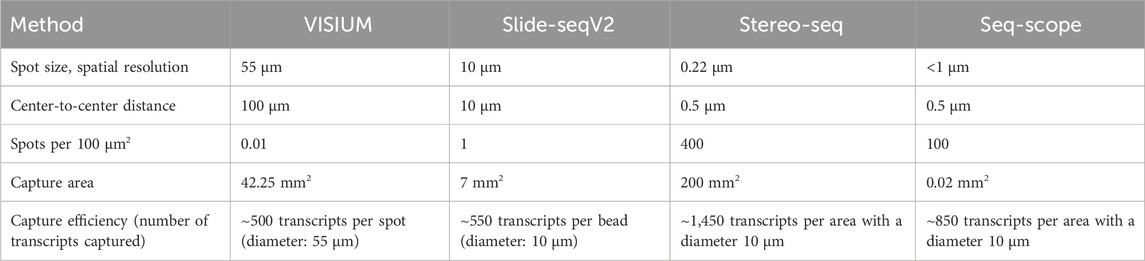
Table 1. Comparison of VISIUM, Slide-seqVs, stereo-seq and seq-scope.
Similarly, the potential application of ExM on spatiotemporal enhanced resolution omics sequencing (Stereo-seq) could be explored. Developed to enable precise spatial transcriptomics on larger tissue sections e.g., for embryological research using a whole mouse embryo, Stereo-seq chips offer a field of view from 1 cm × 1 cm up to 13.2 cm x 13.x cm and provide nanoscale resolution of transcripts (Chen et al., 2022). The method deploys DNA nanoballs (DNBs) containing barcodes and capture probes, situated in the spots of the silicon chip. RNAs are captured onto the DNBs, followed by library construction and NGS (Chen et al., 2022).
Another highly interesting method is Seq-Scope which is based on two rounds of sequencing (Cho et al., 2021). First-Seq reads the barcode sequence of clusters of randomly barcoded oligonucleotides which are fixed on a solid surface, thus mapping the barcodes to their location. The oligonucleotides are then processed to enable RNA capture and 2nd-Seq takes place to return a dataset of the mRNA reads which can be traced back to their location by the barcode sequence. Seq-Scope can detect cellular compartments based on the detection of mitochondrial transcripts and on the amount of intronic sequences in the RNAs, which can indicate unspliced, nuclear RNA.
The major differences between the NGS-based methods with region capture lies in their resolution capacity based on spot sizes, center-to-center distances on the microarray and the total field of view, i.e., the size of the tissue that can be studied. Theoretical compatibility of these methods with ExM requires proper fixation and permeabilization of the tissue, ensuring that spatial relationships can be maintained during expansion and RNA accessibility for subsequent RNA capture. Although these methods’ chemistries might be compatible with ExM in theory, further research is needed to validate the combination with ExM experimentally. The integration of ExM with these methods holds the promise of surpassing existing resolution limitations and enhancing RNA detection efficacy, warranting further research and development (Rodriques et al., 2019; Cho et al., 2021; Stickels et al., 2021; Chen et al., 2022).
3 ApplicationsDespite the high complexity of transcriptomics methods, they have been applied to tackle a great number of research questions in recent years. Their ability to enable the study of cell identity, function and interaction in tissues renders them very valuable. Recently, the development of transcriptomic methods has been advanced to maintain spatial information of the registered gene expression, which can further be enhanced by combining spatial transcriptomics methods with the ExM technology. Until today, these new methods have not been widely-used yet but they have great potential to be put into practice, encouraging discoveries to be made in a variety of different research fields.
Here, we want to give some examples of how spatial transcriptomics in general has advanced our knowledge in some research fields over the last years.
3.1 Identification of cell typesStudying the gene expression patterns received from transcriptomic data enables more precise characterization of cells, the detection of rare cells, as well as cellular subpopulations (Ke et al., 2016). Moreover, cell atlases can be constructed, providing information about gene expression patterns in, e.g., human or mouse cells (Zhuang, 2021; Moffitt et al., 2022; Vu et al., 2022). For instance, whole mouse brain atlases were created from spatial transcriptomic analysis by MERFISH and single-cell RNA sequencing (scRNA-seq) of approximately 7-8 million cells (Yao et al., 2023; Zhang et al., 2023). Similarly, a human cell atlas of the middle and superior temporal gyrus has been reported (Fang et al., 2022).
3.2 Examining the spatial distribution of cell types in a specific tissueCells can be grouped into clusters, thus providing information about regional distribution of cells as well as cell activity and state. Such studies have especially been carried out in various regions of the brain, e.g., the primary motor cortex, the visual cortex or the hippocampus, but they have also been used to study other tissues such as the embryonic heart and neural crest (Zhuang, 2021).
3.3 Insights into cellular function based on the intracellular spatial distribution of transcriptsOn a single-cell level, valuable information can be obtained, e.g., about the underlying mechanisms of cell motility, cell function, cell survival, lineage and development (Zhuang, 2021; Tian et al., 2022; Vu et al., 2022; Williams et al., 2022). Spatial location of RNAs can efficiently be detected in the subcellular compartments using transcriptomic methods, and as RNA location serves as a post-transcriptional regulation mechanism, the data obtained enables insights into the cellular processes and activities taking place (Zhuang, 2021). For instance, differences in the mRNA types present in the neuronal soma, apical and basal dendrites have been observed by the use of targeted ExSeq, with the expression of structural genes enriched in the dendrites and spines (Alon et al., 2021). Furthermore, neuronal circuits can be studied in the brain by high-throughput transcriptomic methods (X. Chen et al., 2019). Moreover, transcriptomic methods can be used to identify somatic mutations in order to determine cell lineage (Frieda et al., 2017). Transcriptomics techniques such as MERFISH have also been used to target DNA, thus enabling the study of the genome. For instance, the chromatin can be imaged in a 3-dimensional manner (Su et al., 2020). Su et al. targeted >1,000 genetic loci and nascent RNAs, and nuclear structures simultaneously to obtain spatial information on the chromatin interactions and the transcriptional process (Su et al., 2020). Such experiments have the potential to further reveal the role of chromatin organization, gene expression and gene regulation in governing cell functions (Ke et al., 2016).
3.4 Unveiling cellular and intercellular changes in the development of diseasesSpatial transcriptomics methods offer a powerful toolset for uncovering cellular and intercellular changes critical to understanding the development and progression of diseases. By providing spatially resolved gene expression data within tissue samples, these methodologies enable researchers to explore how specific genes are expressed and regulated in different cell types and their microenvironment (Cheng et al., 2023). This spatial context is invaluable for dissecting complex disease mechanisms, such as tumor heterogeneity, immune cell infiltration, and tissue remodeling (Tian et al., 2022; Williams et al., 2022). Additionally, spatial transcriptomics facilitates the identification of spatially localized molecular signatures associated with disease states, enabling the discovery of novel biomarkers and therapeutic targets. Furthermore, these methods can elucidate the spatial organization of cellular interactions and communication networks within diseased tissues, shedding light on the underlying biological processes driving disease progression (Cheng et al., 2023). Overall, the application of spatial transcriptomics in disease research holds potential for advancing our understanding of disease pathogenesis and for guiding the development of more effective diagnostic and therapeutic strategies tailored to individual patients.
Spatial transcriptomics methods have been utilized to gain insights into diverse pathomechanisms of diseases, as Table 2 shows. However, it can be observed that
留言 (0)