
記住我



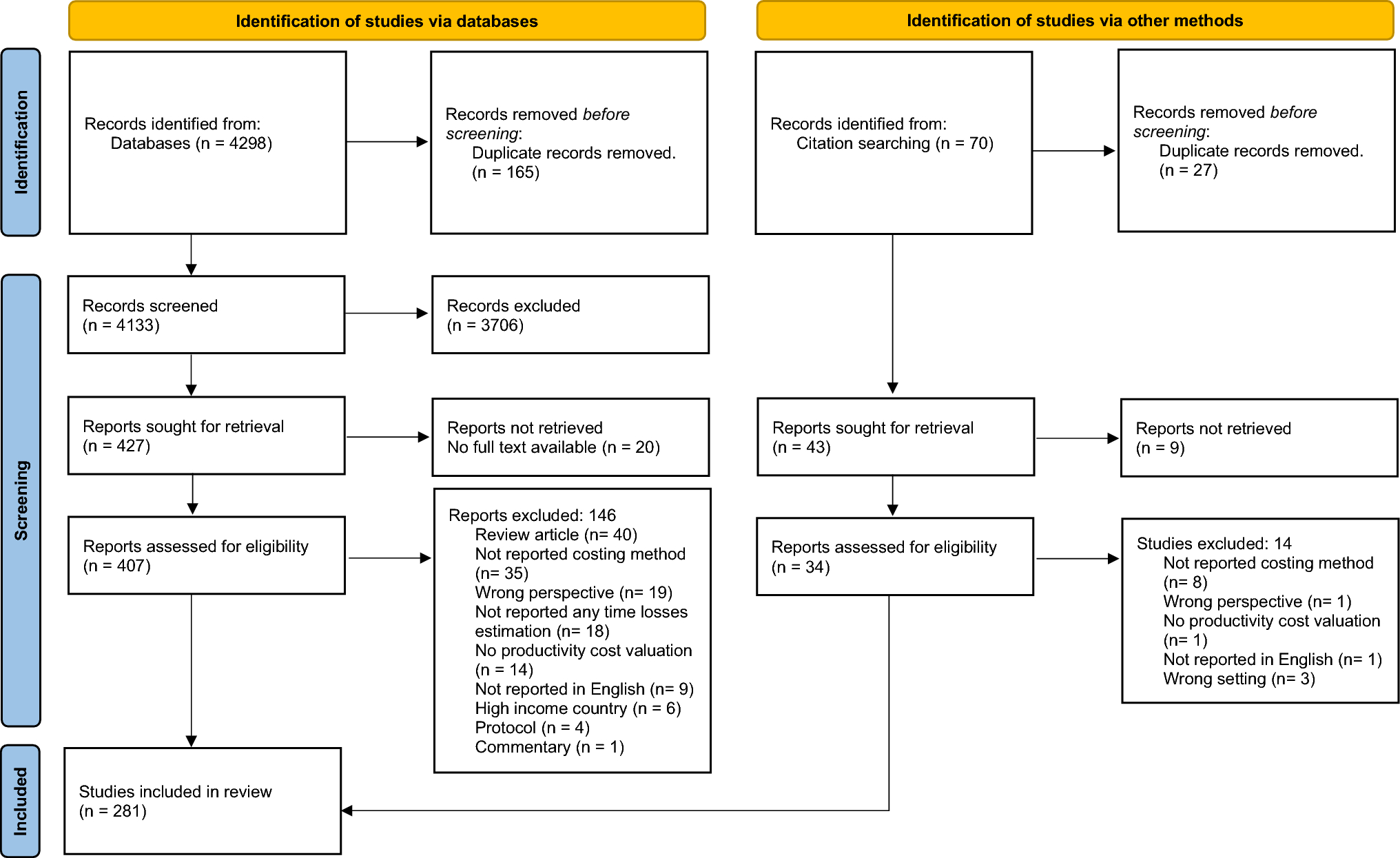
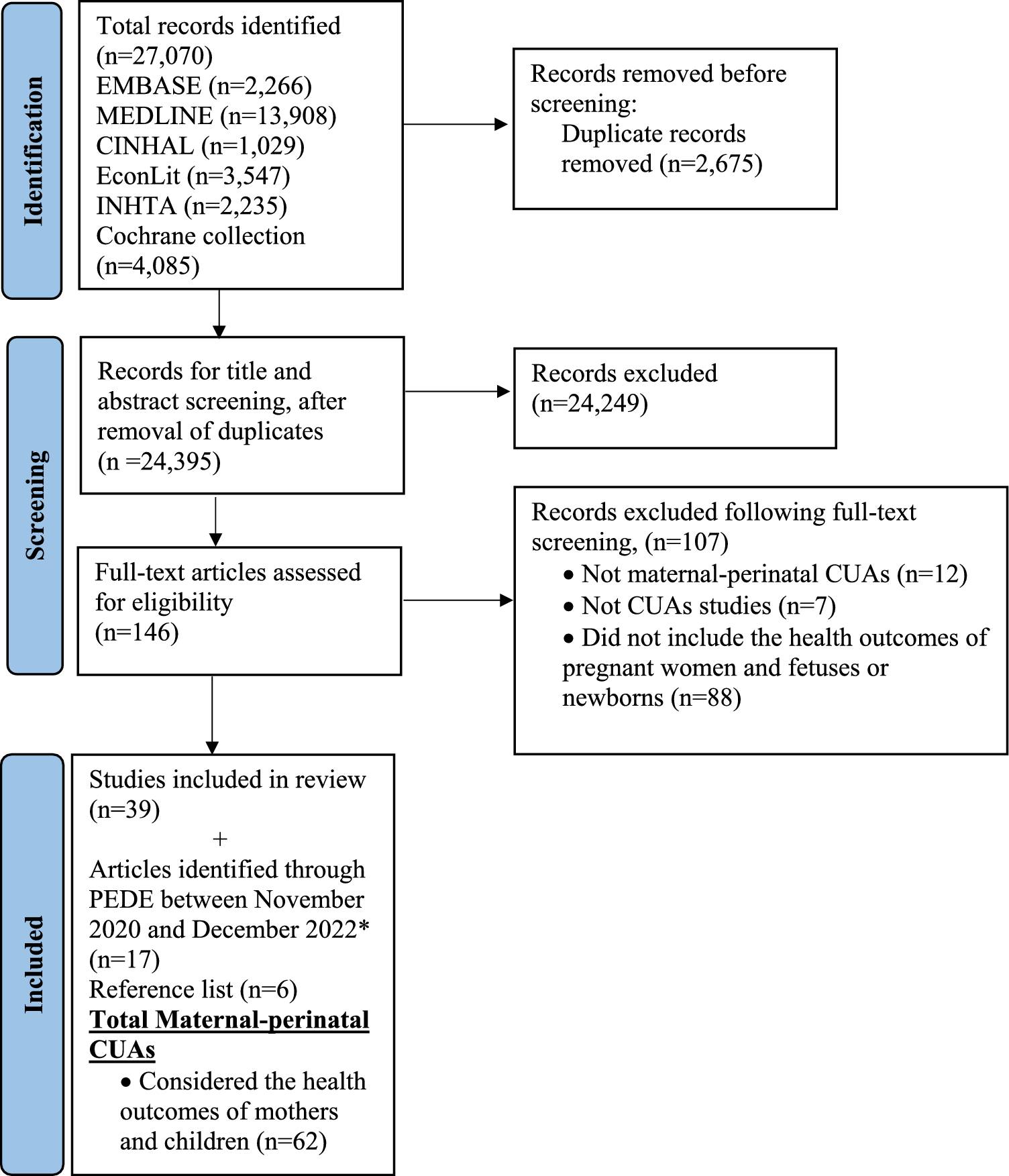
The tutorial adheres to the following structure: (1) set-up the data in R; (2) employ methods to impute missing standard deviations; (3) define the priors; (4) fit the model; (5) diagnose model convergence; (6) interpret the results; and (7) perform sensitivity analyses.
3.1 Set-Up the Data in RAll the packages needed to run our model are loaded using ‘library()’ (Box 1). The brms (Bayesian regression models using Stan) package is used for the implementation of the Bayesian meta-analysis [40]. Stan is a probabilistic programming language for statistical modelling [41], and brms extends the functionality of Stan by offering an interface (similar to the traditional regression modelling syntax in R) to fit Bayesian models. The mfp and mice packages are utilized to impute missing standard deviations through fractional polynomial regression and multiple imputation using chained equations, respectively [42, 43]. Plots are generated either through the built-in functions in the brms package or through the bayesplot [44], shinystan [45], tidybayes [46] or the ggplot2 [47] packages.
Box 1 Set-up the data in R

We load the dataset using the ‘read.csv()’ function. The dataset contains four variables: studyid, which refers to the first author and year of publication; n, the study sample size; utility, the reported or calculated mean health state utility per study; and sd, the standard deviation.
3.2 Employ Methods to Impute Standard DeviationsCommonly, meta-analyses exclude studies that lack a measure of variability. However, there are several approaches to deal with missing standard deviations in meta-analysis [48], and the choice of imputation method usually depends on the nature of the outcome variable or data structures. For the purpose of demonstration, two approaches are shown in this tutorial to impute missing standard deviations of utility values. The first method involves fitting a regression model using fractional polynomials based on the methods of Royston and Altman [49]. This method has been applied in a previous meta-analysis of utilities of chronic kidney disease patients [50]. The second method involves multiple imputation using chained equations. The first approach is applied in the main analysis, while the second approach was used in the sensitivity analysis.
To fit a fractional polynomial regression model of the observed standard deviations against the utility estimates, the mfp function from the mfp package is used [42] (Box 2). The advantage of using fractional polynomial regression is that it allows for non-linear modelling of relationships between variables [49]. Briefly, the mfp package works by fitting several models with different combinations of fractional polynomial transformations of the predictor variable, and then selects the model that best fits the data through a stepwise model selection approach. In our model, sd is the dependent variable, while utility is the predictor. The term ‘fp(utility)’ tells R that we want to investigate different fractional polynomials of utility. The results are stored in an object called sd.model1.
Box 2 Employ methods to impute missing standard deviations

The output shows that given our data, the best model for predicting the standard deviation of a utility estimate is a simple linear model with the following equation: sd = 0.558 − 0.474 × utility. We also calculate the standard error of each utility estimate since this is required as an input for fitting the Bayesian meta-analysis model using the brms package in the subsequent step.
3.3 Define the PriorsOne of the advantages of employing Bayesian methods lies in their capacity to integrate prior knowledge or beliefs into the analytical process, and combine this prior knowledge with the observed data to update parameter estimates. Prior distributions are specified for each parameter in the model, and in the context of Bayesian meta-analysis, this means that we can directly model our assumptions about two parameters of interest: (1) the effect size (i.e. mean health state utility) and (2) the between-study heterogeneity tau. The inclusion of prior information for these parameters can help improve the precision of the estimates, particularly when dealing with a limited number of studies or highly variable data, by shrinking estimates towards more plausible values [51].
In general, priors can be classified into three types: flat, informative and weakly informative. Flat priors are typically used when one wants to input as little information as possible about the parameters of interest, thus assigning equal probability to all possible parameter values. In contrast, informative priors incorporate specific prior knowledge, for instance, from previous research or literature, which can influence the plausibility of some parameter values. Lastly, weakly informative priors fall between flat and informative priors, and provide some information to guide the analysis without strongly influencing the results. These are usually employed when there is some prior knowledge about the parameters of interest, but not strong enough to justify a more constrained prior [11]. While Bayesian meta-analysis offers flexibility in including priors in the model, it is important to carry out sensitivity analysis to assess if specifying different prior information affect the results.
We define the priors using the ‘prior()’ function from the brms package (Box 3). This function takes two arguments, the prior distribution and the class. For illustration purposes, we use a Normal prior centred at 0.5 with a standard deviation of 0.05 for the mean health state utility, but other priors can be used [7, 8]. We set the class as intercept since it is a fixed population-level effect. For the between-study heterogeneity, we use a half-Cauchy prior to restrict values to positive numbers (since standard deviations cannot be negative), with a peak of 0 and a scale of 0.5. We set the class as sd since it is a measure of variability. The priors are saved into an object called priors.model1.
Box 3 Define the priors and perform prior predictive check

The adequacy of the priors can be checked by performing prior predictive checks [44]. A prior predictive check involves generating simulated data based on the chosen prior distribution and comparing it to the observed data. In brms, this is carried out by fitting the model (the arguments of the brm function are explained in the next section) and including the ‘sample_prior = “only”’ argument [40]. The ‘pp_check()’ function is used to plot the simulated data points and the observed data. In our example, the prior predictive check showed that the simulated data aligns with our expectation (that the utility value is around 0.5 and has a standard deviation drawn from the half-Cauchy prior) and covers the range of the observed data (Fig. 1). It is to note that if the simulated data from the prior predictive distribution consistently diverge from the observed data, it implies that the suggested priors are at odds with the data and likely need to be reconsidered.
Fig. 1
Prior predictive check. The black line represents the observed data, while the blue lines represent the simulated data based on the prior distributions specified for the model parameters.
3.4 Fit the ModelThe brm function from the brms package is used to fit the Bayesian meta-analysis model. The brms package uses the No-U-Turn sampler (NUTS) to find and draw samples from the posterior distribution [40, 52]. The NUTS algorithm is considered better than traditional Markov Chain Monte Carlo (MCMC) in terms of efficiency, adaptability and scalability [11, 52]. The NUTS algorithm is packaged into Stan [11], which the brms package applies for fitting Bayesian multilevel models.
For our example, we define the model for our meta-analysis by specifying the formula, data, prior and iter (Box 4). The formula argument follows the standard regression notation, with some modifications since we are doing a meta-analysis. The part ‘utility | se(se.imp1) ~ 1’ indicates that our outcome is the utility value weighted according to the standard error of each study and that we do not have any predictors in the model. However, if one wishes to perform a meta-regression to account for factors that could potentially influence the pooled utility value (for instance, the year of study, study design, or the instrument used to elicit utility), then the syntax would be replaced by ‘utility | se(se.imp1) ~ covariates’. It is worthy to note that inclusion of covariates into the model requires specifying priors for those parameters as well. The part ‘+ (1 | studyid)’ indicates that the utility values are assumed to be nested within studies and as such we want to use a random-effects model. We specify our dataset in the data argument, the priors for the effect size and between-study heterogeneity in the prior argument (which we have already set in the previous step), and the number of iterations per chain in the iter argument. By default, the brm function runs four chains. We save the fitted model into an object called fit.model1.
Box 4 Fit the model
 3.5 Diagnose Model Convergence
3.5 Diagnose Model ConvergenceSeveral tools are available to evaluate model convergence. By default, the brm output offers two convergence metrics: the Gelman–Rubin convergence diagnostic (i.e. Rhat) [53] and the number of effective sample size (i.e. bulk_ESS and tail_ESS). Rhat serves as a numerical summary for evaluating convergence. In practical applications, many researchers employ a threshold value greater than 1.1 to indicate non-convergence [54]. The effective sample size refers to the number of independent samples from the posterior distribution after taking into account autocorrelation of chains [11]. A low effective sample size indicates high autocorrelation, which means that the sequential samples are closely related to the previous one, rendering the chains inefficient. As a rough guide, both bulk_ESS and tail_ESS should be at least 100 per chain to be able to consider the estimates reliable [55]. Additionally, graphical diagnostics can also be used to assess model convergence, for example, using a trace plot and a posterior predictive check plot. If the model has converged well, we can expect a trace plot with a stable path and good mixing, and a posterior predictive check plot where the density of the generated effect size aligns with the observed data.
We evaluate the Rhat, bulk_ESS and tail_ESS using the ‘summary()’ function (Box 5). The ‘plot()’ function from the brms package displays both the density and trace plots for the parameters of interest (in our case, the effect size and between-study heterogeneity), whereas the ‘mcmc_trace()’ function from the bayesplot package displays just the trace plot. The ‘pp_check()’ function is used to display the posterior predictive check plot. This function works by drawing samples of model parameters from the posterior distribution and generating simulated data points that match the structure of the observed data. Lastly, the ‘launch_shinystan()’ function from the shinystan package opens an interactive window where we can further examine diagnostic plots and assess the performance of the model.
Box 5 Diagnose model convergence

Model diagnostics showed that our model achieved convergence. No parameter had an Rhat above 1.1 or bulk_ESS and tail_ESS of less than 400 (100 × 4 chains) for both effect size and between-study heterogeneity parameters. There were no divergent transitions recorded. The trace plot showed stationarity and good mixing (see Figure S1 in the electronic supplementary material). The posterior predictive check plot showed that the simulated effect sizes aligned with the observed effect size, particularly at the tails of the distribution (Fig. 2).
Fig. 2
Posterior predictive check. The black line represents the observed data, while the blue lines show the simulated data based on the posterior distribution of utility (which takes into account both the observed data and the prior distributions of the model parameters).
3.6 Interpret the ResultsGuidance about interpreting the results from Bayesian analysis is available [11, 56]. In our example, we interpret the results by looking at the pooled effect size and between-study heterogeneity in the summary output (Box 6). The pooled effect size, in our case the pooled utility value, is 0.66 with a 95% credible interval (CrI) of 0.60–0.70, given the data, priors and model used. The between-study heterogeneity tau is 0.12 (95% CrI 0.08–0.18). Since we fitted a random-effects model under the assumption that each study has its unique effect size, we can also look at the study-specific effect sizes (by summing up the pooled effect size and the deviations from each study) using the ‘ranef()’ function.
Box 6 Interpret the results

Bayesian meta-analysis naturally provides the posterior distribution of the pooled effect, which we can examine and use to make explicit probability statements regarding our parameters of interest [10]. We can extract the parameters of interest from the fitted model using the ‘posterior_samples()’ function, and then perform manual calculations or use the ‘ecdf()’ function to calculate posterior probabilities (Box 7). The ecdf function takes a value or set of values as input and returns the cumulative probabilities associated with those values. In our example, the probability that the pooled utility value is less than 0.80 is 100.00%, while the probability that it is less than 0.70 is 96.06%. Figure S2 displays the cumulative posterior distribution plot, which shows the cumulative probability associated with values less than or equal to each utility value on the x-axis (see the electronic supplementary material).
Box 7 Calculate posterior probabilities

Lastly, we can also generate a forest plot by following the step-by-step guide from the tidybayes package [46] (Fig. 3). Note that this requires installation of other packages. The full code is provided in the script.
Fig. 3
Forest plot showing the posterior distribution of effect sizes for each study and the pooled effect size
3.7 Perform Sensitivity AnalysisFor this tutorial, we explored the results of using a more informative prior for the mean health state utility, employing multiple imputation using chained equations to impute missing standard deviations, and excluding studies with missing standard deviations. For the first sensitivity analysis, a Normal prior centred at 0.6 with a standard deviation of 0.03 is used (Box 8). This is regarded as being more informative than the prior used in the main analysis since it is above the midpoint of possible utility values with a smaller standard deviation. Given that mean utility values are generally bounded between 0 and 1 (although, at the individual participant level, they may occasionally take negative values), it is important to choose a prior distribution that will not violate these bounds. When the number of observations is large, the likelihood will be more important than the prior, and the posterior distribution will approach a normal distribution. In such scenarios, the normal distribution is a justifiable choice for the prior, and is easy for non-statistical collaborators to understand. However, when utility values are likely to be close to the boundaries of possible values (0 or 1), skewness will be introduced that only an extremely large number of observations will overcome. In these cases, a different prior distribution is justified. Options include a truncated normal distribution, a truncated log-normal distribution (which is skewed and has a lower limit) or truncated log-normal distribution reversed to have an upper limit. Using a beta prior distribution might also be an appropriate choice, as it aligns well with the above constraint and could potentially reflect the uncertainty around utility values better [57]. For example, in the script, this could be implemented by using ‘prior(beta(1,1), class = Intercept)’ rather than ‘prior(normal(0.5,0.05)’. Lastly, if the analysis conceives of the possibility of negative utilities, has relatively small number of observations and anticipates results around zero, it may be necessary to define a lower boundary to the utilities. The prior for the between-study heterogeneity can also be changed, but is kept the same as the main analysis in this example for simplicity. Guidance on the selection of prior distributions for the between-study heterogeneity parameter is available [58, 59].
Box 8 Sensitivity analysis 1: using a more informative prior

For the second sensitivity analysis, we use the ‘mice()’ function from the mice package. Multiple imputation using chained equations involves generating several datasets with imputed values for the missing data. Within each dataset, missing values are filled in one at a time, using the observed values and other variables in the dataset. The process iterates, refining the imputed values based on the results of the previous round, until all missing data have been imputed. In our example, we generate five sets of imputed standard errors (Box 9). We use the brm_multiple function (rather than the brm function) from the brms package to fit the model since it is compatible with fitting multiple imputed datasets generated by mice and pooling the posterior distributions of those imputed datasets [40].
Box 9 Sensitivity analysis 2: using multiple imputation using chained equations

For the last sensitivity analysis, only studies with available standard deviations were included (Box 10). The results are summarized in Table 2. The sensitivity analyses conducted did not materially change the pooled utility value and the 95% CrI. The model excluding the studies with missing SDs (model 4) generated less precise estimates compared to the other models, while the model with more informative priors for the effect size (model 2) yielded slightly narrower CrIs. All models achieved convergence. Model 3 has the highest bulk_ESS and tail_ESS since five imputed datasets were used and pooled to produce the estimates.
Table 2 Summary of results and convergence diagnosticsBox 10 Sensitivity analysis 3: excluding studies with missing SDs
 3.8 Comparison to Frequentist Approach
3.8 Comparison to Frequentist ApproachRandom-effects meta-analysis using the DerSimonian and Laird method were also carried out using the metafor package [60] to compare the results between the frequentist and Bayesian approaches. The codes for the frequentist meta-analysis are included in the script. The three frequentist models (i.e. with imputed SDs using fractional polynomial regression, with imputed SDs using mice, and excluding studies with missing SDs) produced identical pooled utility values (0.70), which were slightly higher than the values from their Bayesian counterparts (Table 3). As expected, the confidence interval widths were narrower than the CrIs, and the taus were lower in the frequentist models than in the Bayesian models. Lastly, all p values produced from the frequentist models were statistically significant (p < 0.05).
Table 3 Comparison between Bayesian and frequentist meta-analysis results
留言 (0)