
記住我







There are mainly four steps in our method: (1) pre-compute non-lattice subgraphs and identify candidate pairs of concepts that are currently not linked by hierarchical relations; (2) given a candidate pair, check if the inferred definition of one concept is more specific than the other’s; (3) compute lexical features for concepts and perform lexical-based subsumption checking; and (4) remove redundant and cycle-causing potentially missing hierarchical relations.
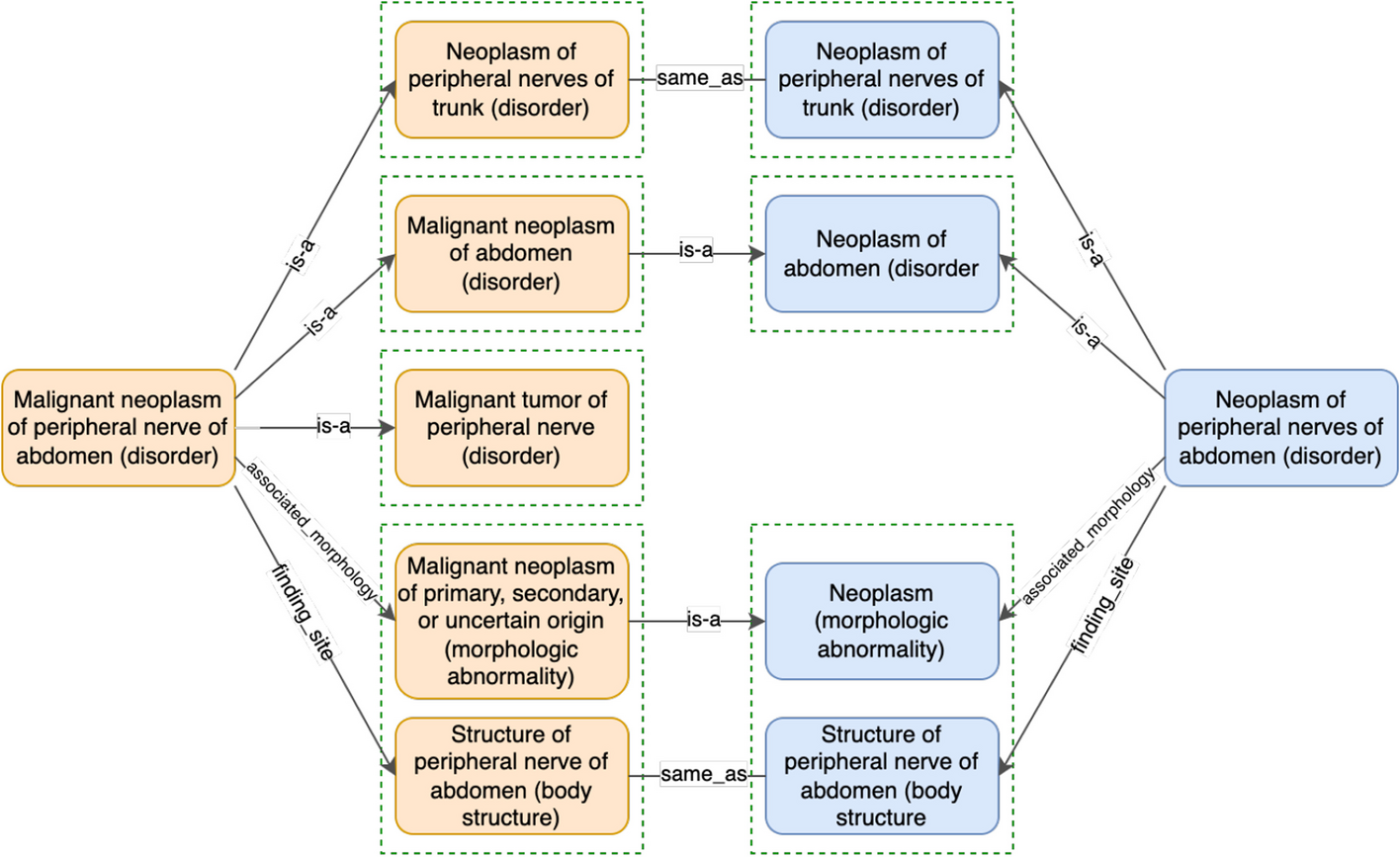
Pre-computing non-lattice subgraphs and generating candidate pairsIn our previous work [23, 30,31,32], we found that non-lattice subgraphs often reveal quality issues such as missing hierarchical relations or missing concepts. Non-lattice subgraphs are graph fragments obtained from hierarchical (or IS-A) relations of an ontology. A pair of concepts is known as a non-lattice pair if they share more than one maximal common descendant. A non-lattice subgraph can be obtained from a non-lattice pair by first reversely computing the minimal common ancestors of the maximal common descendants of the non-lattice pair and then aggregating all the concepts and hierarchical relations between them [30]. Figure 3 shows a non-lattice subgraph in the March 2020 Release of the SNOMED CT (US Edition) obtained from non-lattice pair: (“Neoplasm of peripheral nerves of trunk (disorder),” “Neoplasm of abdomen (disorder)”) with three maximal common descendants “Malignant neoplasm of peripheral nerve of abdomen (disorder),” “Benigh ganglioneuroma of abdomen (disorder),” and “Neoplasm of peripheral nerves of abdomen (disorder).” Similarly, Fig. 4 shows a non-lattice subgraph in the 23.05e release of NCIt that contains the non-lattice pair: (“EGFR-targeting Agent,” “Bispecific Monoclonal Antibody”) and five of its maximal common descendants.
Fig. 3
An example of non-lattice subgraphs in the March 2020 Release of the SNOMED CT (US Edition). Concepts are connected by hierarchical relations
Fig. 4
An example of non-lattice subgraphs in the 23.05e Release of NCIt. Concepts are connected by hierarchical relations
In this work, we first compute all the non-lattice subgraphs using an efficient non-lattice extraction algorithm [33]. Then we generate a list of candidate concept pairs which are concepts that are currently not linked by hierarchical relations in non-lattice subgraphs. Consider the SNOMED CT non-lattice subgraph shown in Fig. 3. Two example candidate pairs are (“Malignant neoplasm of peripheral nerve of abdomen (disorder),” “Neoplasm of peripheral nerves of abdomen (disorder)”) and (“Benigh ganglioneuroma of abdomen (disorder),” “Neoplasm of peripheral nerves of abdomen (disorder)”). In the NCIt non-lattice subgraph shown in Fig. 4, two example candidate pairs are (“Amivantamab and Recombinant Human Hyaluronidase,” “Amivantamab”) and (“EGFR-targeting Agent,” “Bispecific Monoclonal Antibody”).
Logical definition-based subsumption checkingIn this step, given a candidate pair, we check whether the logical definition of one concept is more general than that of the other. We perform this comparison at the relation group level. Note that some relations such as IS-A relations in Fig. 1, can be ungrouped in SNOMED CT. We consider each of these relations to be in a separate group. In addition, NCIt does not group relations as SNOMED CT does. Therefore, we also consider each relation in NCIt concepts to be in its own relation group to generalize the method’s implementation.
Based on relation groups, given a concept X, we consider its logical definition (inferred) as a set of groups of defining relations, \(I_X=\\), where \(X_n\) is a group of relations in the form of attribute-value pair(s), i.e., \(X_n=\: v_)\mid m=1, \dots , j\}\). For example, the logical definition of the SNOMED CT concept “Neoplasm of peripheral nerves of abdomen (disorder)” in Fig. 1 consists of three relation groups \(\\), where \(X_1=\) , \(X_2=\) , and \(X_3=\) . Note that \(X_3\) contains two relations while \(X_1\) and \(X_2\) contain one relation each.
Given a candidate pair (X, Y), \(I_X\) is considered to be more specific than \(I_Y\) in logical definitions if, for each relation group \(Y_m\) in \(I_Y\), there exists a corresponding group \(X_n\) in \(I_X\) such that \(X_n\) is more specific than \(Y_m\). Given two relation groups, \(X_n\) is considered to be more specific than \(Y_m\), if for each defining relation (\(k_Y\), \(v_Y\)) in \(Y_m\), there exists a corresponding defining relation (\(k_X\), \(v_X\)) in \(X_n\) such that (\(k_X\), \(v_X\)) is more specific than (\(k_Y\), \(v_Y\)). The following two rules are followed to determine whether a defining relation is more specific than another.
The first rule is the inclusion rule which covers most cases. Given two defining relations (\(k_X\), \(v_X\)) and (\(k_Y\), \(v_Y\)), (\(k_X\), \(v_X\)) is more specific than (\(k_Y\), \(v_Y\)) if \(k_X\) is the same as or a subtype (i.e., descendant) of \(k_Y\), and \(v_X\) is the same as or a subtype (i.e., descendant) of \(v_Y\). Consider the candidate pair in Fig. 1. For each relation group in the inferred definition of concept “Neoplasm of peripheral nerves of abdomen (disorder),” we could find a corresponding group in the inferred definition of “Malignant neoplasm of peripheral nerve of abdomen (disorder)” which is more specific. For example, the relation groups at the bottom of Fig. 1 both contain two relations. The relation (Finding site: Structure of peripheral nerve of abdomen (body structure)) exists under both concepts. In the other relation, the attribute type “Associated morphology” is the same for both the concepts while the value concept “Malignant neoplasm of primary, secondary, or uncertain origin (morphologic abnormality)” is a subtype of “Neoplasm (morphologic abnormality).” As a result, based on their logical definitions “Malignant neoplasm of peripheral nerve of abdomen (disorder)” is considered to be more specific than “Neoplasm of peripheral nerves of abdomen (disorder).”
The second rule is the property chains, which include transitive properties. Given attribute types \(k_a\), \(k_b\) and \(k_Y\) with a property chain \(k_a \circ k_b\) is a sub-property of \(k_Y\), defining relation (\(k_X\), \(v_X\)) is more specific than (\(k_Y\), \(v_Y\)) if attribute type \(k_X\) is the same as or a subtype of \(k_a\), and \(v_X\) has a relation to \(v_Y\) via attribute type \(k_b\). Consider the SNOMED CT defining relations (Causative agent: Sodium calcium edetate (substance)) from concept “Sodium calcium edetate adverse reaction (disorder)”and (Causative agent: Edetate (substance)) from concept “Edetate adverse reaction (disorder).” Here, the value concept “Sodium calcium edetate (substance)” is not a subtype of “Edetate (substance)”. However, “Sodium calcium edetate (substance)” has a relation whose attribute type is “Is modification of” to “Edetate (substance),” and property chain of Causative agent \(\circ\) Is modification of is a sub-property of Causative agent. Substituting to the second rule, \(k_a\) and \(k_Y\) equal to “Causative agent,” \(k_b\) equals to “Is modification of.” In this case, \(k_X\) equals to \(k_a\) (i.e., “Causative agent”), and value \(v_X\) “Sodium calcium edetate (substance)” has a relation to \(v_Y\) “Edetate (substance)” via \(k_b\) “Is modification of.” As a result, defining relation (Causative agent: Sodium calcium edetate (substance)) is more specific than relation (Causative agent: Edetate (substance)) even though they do not comply with the first inclusion rule. In the September 2021 Release of the SNOMED CT (US Edition), all the property chains have attribute type “Is modification of” as intermediate property (i.e., \(k_b\) = “Is modification of”).
In some concepts, the inferred definitions may not contain any attribute relations (only containing hierarchical relations). In such cases, we only have limited definitions for the potential supertype, and it could be meaningless to find its potential subtypes considering logical definitions. To improve the quality of suggested missing hierarchical relations, we only consider those candidate pairs where the potential supertype contains at least one attribute relation.
Supplementary lexical-based subsumption checkingIn our previous work [23, 25, 32], we found that lexical features (e.g., words and noun phrases appearing in the concept names) can be used to represent the semantic meaning of concepts. These lexical features may include information that is not conveyed through logical definitions and can be taken as supplementary features in representing the semantic meaning of concepts. In this work, we aggregate three types of lexical features from a concept name to form a lexical feature set for each concept: (1) dependency pairs of two dependencies: object of a preposition “pobj” and direct object “dobj’; (2) base noun phrases; and (3) single words that were not in dependency pairs.
Given a concept name, we first use Spacy [34], a Natural Language Processing (NLP) library, to perform dependency parsing. Figure 5 shows the dependency parse of the SNOMED CT concept “Malignant neoplasm of peripheral nerve of abdomen (disorder).” As shown, the first occurrence of the word “of” and the word “nerve” has “pobj” dependency. Also, the second occurrence of the word “of” and the word “abdomen” also has “pobj” dependency. Therefore, we include “of nerve” and “of abdomen” as dependency pairs in the lexical feature set.
Fig. 5
Dependency parsing result for concpet name “Malignant neoplasm of peripheral nerve of abdomen (disorder).” The semantic tag “(disorder)” is not parsed and will not be included in the lexical feature set of this concept
Afterward, using Spacy, all the base noun phrases existing in a concept name are identified and aggregated to the lexical feature set. For instance, the SNOMED CT concept “Malignant neoplasm of peripheral nerve of abdomen (disorder)” contains base noun phrases: “malignant neoplasm,” “peripheral nerve,” and “abdomen”.
Finally, the rest of the words that are not part of the dependency pairs are aggregated into the lexical feature set. For instance, in the SNOMED CT concept “Malignant neoplasm of peripheral nerve of abdomen (disorder),” the words ‘malignant,’ ‘neoplasm,’ and ‘peripheral’ are not part of the dependency pairs “of nerve” and “of abdomen”. Therefore, these words are aggregated to the lexical feature set.
To obtain a broader view of the semantics of a concept, we further construct an enriched set of lexical features by leveraging its ancestors. The lexical features for each ancestor is computed and aggregated to the concept’s lexical feature set to generate the enriched lexical feature set. Table 1 shows the initial lexical feature set and the enriched lexical feature set for the SNOMED CT concept “Malignant neoplasm of peripheral nerve of abdomen (disorder).”
Table 1 The initial and enriched sets of lexical features of concept “Malignant neoplasm of peripheral nerve of abdomen (disorder)”. Noun phrases and dependency pairs are underlinedGiven a candidate pair (X, Y), if X is more specific than Y in terms of logical definitions, we further check whether the enriched lexical feature set of X is a superset of Y’s (i.e. if concept X is also lexical-wise more specific than Y). If so, a potentially missing hierarchical relation X IS-A Y is discovered. Consider the candidate pair (“Malignant neoplasm of peripheral nerve of abdomen (disorder),” “Neoplasm of peripheral nerves of abdomen (disorder)”) in the SNOMED CT non-lattice subgraph in Fig. 3 as an example. “Malignant neoplasm of peripheral nerve of abdomen (disorder)” is more specific than “Neoplasm of peripheral nerve of abdomen (disorder)” both in logical definitions and lexical features, and therefore, a potentially missing hierarchical relation “Malignant neoplasm of peripheral nerve of abdomen (disorder)” IS-A “Neoplasm of peripheral nerve of abdomen (disorder)” is suggested by our method. Note that our approach also found another missing IS-A relation in this particular non-lattice subgraph: “Benign ganglioneuroma of abdomen (disorder) IS-A Neoplasm of peripheral nerves of abdomen (disorder).” Both the missing IS-A relations are shown in Fig. 6. Similarly, the NCIt candidate-pair (“Amivantamab and Recombinant Human Hyaluronidase,” “Amivantamab”) in the NCIt non-lattice subgraph in Fig. 4 satisfies both these logical and lexical conditions. Therefore, a potential missing IS-A relation “Amivantamab and Recombinant Human Hyaluronidase” IS-A “Amivantamab” is suggested between these two concepts. This missing IS-A relation is shown in Fig. 7.
Fig. 6
Two potentially missing hierarchical relations identified (marked red) by our methods in the SNOMED non-lattice subgraph shown in Fig. 3. Note that the original direct hierarchical relation between “Malignant neoplasm of peripheral nerve of abdomen (disorder)” and “Neoplasm of peripheral nerves of trunk (disorder)” is removed because it can now be transitively inferred by the potential missing hierarchical relation and the existing hierarchical relation
Fig. 7
A potentially missing hierarchical relations identified (marked red) by our methods in the NCIt non-lattice subgraph shown in Fig. 4. Note that the two original direct hierarchical relations from the concept “Amivantamab and Recombinant Human Hyaluronidase,” to the concepts “Bispecific Monoclonal Antibody” and “Anti-EGFR Monoclonal Antibody” are removed because they can now be transitively inferred by the potential missing hierarchical relation and the existing hierarchical relations
Redundancy and cycle removalSome of the potential missing IS-A suggested by our method might be implied by other potential missing IS-A relations and existing IS-A relations. For example, our approach may suggest two potentially missing hierarchical relations A IS-A B and A IS-A C. If C is an ancestor of B in the original concept hierarchy of SNOMED CT, A IS-A C will be considered redundant as it can be implied transitively by potentially missing hierarchical relation A IS-A B and existing IS-A relation B IS-A C. Such redundant potential missing IS-A relations are removed from the list of discovered potential missing IS-A relations. For each potential missing IS-A relation, we combine the rest of the potential missing IS-A relations together with all the existing IS-A relations to check whether it can be inferred.
In addition, we further remove any potential missing IS-A relations that may cause cycles in the ontology. For instance, if our method suggests two potentially missing IS-A relations X IS-A Y and Y IS-A X, then both of these would be removed as they cause a cycle. A potential missing IS-A relation could cause a cycle together with existing IS-A relations in the ontology. For example, if the method suggests X IS-A Y, while Y IS-A X already exists in the ontology, then, X IS-A Y will be removed.
EvaluationTo evaluate the efficacy of our method in identifying accurate missing IS-A relations, we leveraged the support of domain experts (authors JS and SL) to review a sample of potential missing IS-A discovered by the method. The experts evaluated potential missing IS-A relations in terms of their validity and provided comments where necessary indicating why a certain case is valid or not. For SNOMED CT, we randomly picked potential missing IS-A relations from “Clinical Findings” and “Procedure” subhierarchies, and both the domain experts individually reviewed each case. We consider a particular potential missing IS-A relation to be valid if both reviewers agree with it. For NCIt, we picked all the potential missing IS-A relations from the “Drug, Food, Chemical or Biomedical Material” subhierarchy which were each manually reviewed by the author JS.
留言 (0)