
記住我



Carbon fiber microelectrodes (CFMs) were fabricated using an established standardized CFM design at Mayo Clinic [16]. A single carbon fiber (AS4, diameter = 7 μm; Hexel, Dublin, CA) was inserted into a silica tube (ID = 20 μm, OD = 90 μm, 10 μm coat with polyimide; Polymicro Technologies, Phoenix, AZ). The connection between the carbon fiber and the silica tubing was sealed with epoxy resin. The silica tubing was then attached to a nitinol (Nitinol #1, an alloy of nickel and titanium; Fort Wayne Metals, IN) extension wire with a silver-based conductive paste. The nitinol wire was then insulated with polyimide tubing (ID = 0.0089″, OD = 0.0134, WT = 0.00225; Vention Medical, Salem, NH) up to the exposed carbon fiber tip. The exposed carbon fiber was then trimmed under a dissecting microscope to a length of 50 μm. An Ag/AgCl reference electrode was prepared from Teflon-coated silver wire (A-M systems, Inc., Sequim, WA) by chlorinating the stripped tip in saline with a 9 V dry cell battery. CFMs were chemically tested in a beaker with TRIS buffer prior to coating with a PEDOT:Nafion deposition solution, which has been shown to minimize the effect of in vivo biofouling and increase sensitivity to electroactive monoamine neurotransmitters [27].
In vitro experimentsFigure 1 outlines the workflow of the in vitro experiments. M-CSWV was performed using a commercial electronic interface (NI USB-6363, National Instruments) with a base-station desktop computer and software written in-house using MATLAB (MathWorks Inc., Natick, MA) [28]. Data, in the form of a sequence of unsigned 2-byte integers, were saved to the base-station computer. Additional processing, including temporal averaging, filtering, and background current simulation were done in MATLAB [28]. A CFM and Ag/AgCl reference electrode were lowered into the monoamine solution. The NI system transmitted the M-CSWV waveform through the CFM, oxidizing and subsequently reducing surrounding species. The resulting current traveled back through the CFM to the base-station computer for analysis (Fig. 1A).
Fig. 1: In vitro workflow.
A The input M-CSWV waveform is transmitted to the CFM, oxidizing and reducing surrounding electrochemical species in the beaker solution. The resulting current data is picked up by the CFM and sent back to the computer for analysis. B Tested single and mixture monoamine solution concentrations (nM). C Artificial intelligence models are used to resolve mixtures of monoamines into their individual components.
The monoamine solutions used in this work are shown in Fig. 1B. These three monoamines were chosen because they are commonly seen in the in vivo environment and are relevant for a variety of neuropsychiatric conditions [29,30,31]. Other potential interferents such as ascorbic acid, DOPAC, and pH changes have already been shown to be excluded by the M-CSWV waveform [32], so were not assessed. All solutions were dissolved in TRIS buffer to the appropriate concentrations. Each solution represents a single dataset per CFM. For each dataset, the CFM was allowed to stabilize in TRIS buffer for 30 minutes. Then, the CFM was inserted into the solution, and was allowed to stabilize for an additional 10 minutes. 50 voltammograms were then recorded (scan repetition rate = 0.1 Hz [32]). In between solutions, the CFM was rinsed with TRIS buffer. A total of 12 CFMs with data collected by 5 different experimenters were used for in vitro data collection.
Voltammogram processing proceeded as described previously [28, 32, 33]. The current data measured by the CFM is sent to the base-station computer for processing. Tonic concentrations are obtained through dynamic background subtraction of the non-Faradaic current. The final background subtracted voltammogram was fed into the artificial intelligence models for neurochemical concentration prediction (Fig. 1C).
Unlabeled in vivo dataThe second branch of our model learns salient features from unlabeled in vivo data. This data was collated from prior in vivo experiments performed in our laboratory. These experiments were all performed on male urethane-anesthetized Sprague-Dawley rats (150–200 g). For each experiment, using M-CSWV, 50 voltammograms were selected randomly from a portion of the experiment after the CFM was electrochemically stabilized but before any experimental manipulations, such as electrical stimulation or drug of abuse administration, were performed. The voltammograms were preprocessed in the same way as the in vitro data. Overall, 20 experiments conducted by 3 different investigators were used, for a total of 500 in vivo voltammograms. The brain regions targeted by these experiments include the nucleus accumbens (n = 13), the dorsal hippocampus CA1 region (n = 3), and the medial prefrontal cortex (n = 4). Of note, the electrodes used within these in vivo experiments are distinct from those used to collect the in vitro data.
Shallow learning algorithm modelingAll shallow learning modeling was performed in MATLAB. The following artificial intelligence algorithms were assessed based on their previous use in the electrochemical literature for discriminating similar appearing monoamines: Support vector regression (SVR), principal components regression (PCR), partial least squares linear regression (PLSR), lasso regression, ridge regression, and elastic net regression [14, 22, 23, 34, 35]. The 50 voltammograms and the associated concentration labels from each in vitro experiment were compiled and shuffled. Prior literature utilizing artificial intelligence for concentration resolution from mixtures has used the same electrodes to construct the training and test sets. We follow this approach for our “within electrode” training branch. In general, this decision makes sense, as electrochemical data arising from different electrodes can be quite variable, due to different electrode surface characteristics, lengths, etc. These differences lead to differing voltammograms for solutions containing the same concentrations of monoamines, which can disrupt artificial intelligence model training. However, the decision to use the same electrodes for training and testing also presents several problems. When future data is collected with new electrodes, it will mean the model will have to be retrained with data from these new electrodes. Further, this prevents extension to the in vivo environment, as ground truth labeling of in vivo data is difficult to obtain. Therefore, we also included an “across electrode” training branch, in which validation and testing voltammograms were allowed to come from electrodes entirely unseen during model training. This tests the electrode-wise generalizability of each model. Having a model that performs well across-electrodes would be beneficial, as it would mean that data from future electrodes could simply be fed back into the model without the need for retraining. Such generalizability would bode well for generalizing to the in vivo environment. Indeed, our unlabeled in vivo data was collected with an entirely separate set of electrodes from the in vitro data.
For the “within electrode” branch, the shuffled voltammogram dataset was split randomly into training and test sets (80% training) for evaluation (Fig. 2A). In total, there were 11350 voltammograms, yielding 9080 voltammograms for training and 2270 for testing. To maximize the generalizability of the models, each model was programmed to output a predicted concentration for each monoamine (DA, NE, 5-HT) regardless of whether the monoamine was present in the mixture. Model performance was evaluated with root mean square error (RMSE) between the predicted and true test concentrations.
Fig. 2: DiscrimNet architecture and artificial intelligence algorithm flowcharts.
A Shallow learning algorithm evaluation flowchart. The evaluation of each model is handled differently depending on the availability of tunable hyperparameters. All models were evaluated on the same training and test sets. B Deep learning algorithm evaluation flowchart. Voltammogram processing proceeds similarly to Fig. 2A. C DiscrimNet is a convolutional autoencoder consisting of 2D convolution and MaxPooling blocks in the encoder branch, and 2D convolution and upsampling blocks in the decoder branch.
For support vector regression, the box constraint, epsilon, and kernel scale hyperparameters were optimized using five-fold cross validation on the training set using the L1QP solver. A total of 30 optimization iterations were performed on the training set before the final concentration predictions on the test set. For PCR and PLSR, a total of 7 principal components were used in the regression, as 7 principal components explained 99% of the variance.
For lasso, ridge, and elastic net regression, Principal Component Analysis (PCA) was performed on the training and test datasets, and the first 100 principal components of the training set were kept for regression. This was to reduce the program execution time and make the regression problem tractable. 20-fold cross validation was used to estimate the coefficients of each regression model. The largest lambda value (retained regularization coefficients) was used such that the cross-validated mean squared error was within 1 standard error of the minimum mean squared error.
DiscrimNet architectureM-CSWV-derived voltammograms can be reshaped into 2D heatmaps, which effectively can be fed as images to a deep learning algorithm. Therefore, deep learning network layers which operate on images, such as 2D convolutional layers, can be used on our voltammograms. Such layers offer an advantage over equivalent layers which operate on 1D time series (e.g., 1D convolutional layers, recurrent layers, etc.) because of their ability to encode multi-dimensional spatial information in the data, and to use this encoding to discriminate between similar-appearing voltammograms.
One of the major limitations of in vivo use of voltammetric methods such as M-CSWV is that labeling the concentrations of in vivo voltammograms is difficult, as there is currently no way to accurately determine the concentrations of each neurotransmitter present in a certain brain region. One could use in vivo microdialysis, but this method is unsuitable for future clinical use, due to its propensity for tissue damage, low sampling rate, and need for external laboratory identification [2, 36]. To circumvent these concerns, we have developed a semi-supervised learning algorithm which is trained on labeled in vitro voltammograms, allowed to encode features of unlabeled in vivo voltammograms, and finally can predict concentrations from unseen in vivo data.
DiscrimNet was built as a convolutional autoencoder (Fig. 2C) using the Keras library [37] in Python. Autoencoders, which consist of an encoding (learning) branch and a decoding (reconstruction) branch, are typically used in an unsupervised manner to learn the salient features of the input data and attempt to reconstruct it. Autoencoders have been used for anomaly detection, noise suppression, data augmentation, etc. [38] However, we use it in a semi-supervised manner for both concentration prediction and voltammogram reconstruction.
First, voltammogram pre-processing proceeds by normalizing all pixel values to be between 0 and 1 (as recommended for stable training of deep learning networks) [39]. The autoencoder is trained on the same labeled in vitro data as the shallow learning algorithms were trained on. As before, training proceeded in either a “within electrode” or “across electrode” manner (Fig. 2B).
The output of the encoding pathway consists of three concentrations, the predictions for DA, NE, and 5-HT, respectively (Fig. 3). The output of the decoding pathway is an attempted reconstruction of the input voltammogram. There are thus 2 losses that the training process attempts to minimize: regression loss, which is the root mean square error between the predicted concentrations and actual concentration, and the reconstruction loss, which is the binary cross-entropy between the input and output voltammograms. By minimizing both, the network is forced to learn the salient features within the voltammogram and allow these features to inform the concentration prediction process.
Fig. 3: Autoencoder training iterations.
First, the full autoencoder is used to both predict concentrations and reconstruct the input voltammogram, while simultaneously minimizing regression and reconstruction loss. Next, both the encoder and decoder weights are transferred to a new autoencoder, which is trained to reconstruct unseen in vivo data. Finally, the fully-trained encoder weights are used to predict concentrations on unseen in vivo data.
Second, an identical autoencoder is built, but without the dense blocks that lead to concentration prediction. This autoencoder is only designed for reconstruction. Following the principles of transfer learning, the trained layers from the first autoencoder are transferred to this one, and then this second network is fed unlabeled in vivo voltammograms. Now, the layer weights will be modified to incorporate salient features of in vivo voltammograms.
Finally, an encoder is built, identical to the encoding branch of the first network. The encoding layer weights of the second network, which contains information from labeled in vitro data as well as unlabeled in vivo data, are transferred to this one. Unseen in vivo data can then be fed into this encoder, which will output predicted concentrations for DA, NE, and 5-HT in vivo.
Overall, this convolutional autoencoder derives inspiration from Xue et al., 2021 [40], who utilized a similar autoencoder and transfer learning scheme to predict phasic concentration changes of several monoamines. However, our model possesses some key differences. First, the model of Xue et al. utilized 1D convolution blocks, and reconstructed the voltammogram directly from the concentration predictions. In contrast, our model uses 2D convolution blocks, and reconstructs the voltammogram from a low-dimensional 2D layer, which is near the bottom of the encoding branch. Because our voltammograms possess significantly higher dimensions than theirs (128 × 45,000) vs. (1 × 200), it is impossible to reconstruct the voltammogram from just 3 concentration values. Various additional adjustments are made, such as the addition of batch normalization blocks, the use of Separable convolution blocks rather than simple convolution blocks, and the use of 2D convolution and Upsampling blocks rather than transposed convolution blocks. Finally, the biggest difference is that Xue et al.’s in vitro test set as well as their in vivo set came from the same electrodes used for the training set, while our “across electrode” branch has test sets that consist of voltammograms from electrodes never seen during training. Further, our in vivo dataset comes from an entirely different set of electrodes. Additionally, our model aims to predict tonic concentrations of neurotransmitters, while Xue et al.’s model predicts phasic changes in concentrations.
For all phases of DiscrimNet training, the Adam optimizer was used with random initial hyperparameters. After 3 epochs of no validation loss reduction, learning rate was reduced by 10-fold, with a minimum possible learning rate of 1×10-6. Training continued for a maximum of 50 epochs but was programmed to stop after 20 epochs of no reduction in validation loss. For training on labeled in vitro data, the loss functions were root mean square error for the monoamine concentration predictions and binary cross-entropy for voltammogram reconstruction. For training on unlabeled in vivo data, the loss function was binary cross-entropy for voltammogram reconstruction.
In vitro validation experimentsTo validate DiscrimNet’s ability to characterize individual concentrations of DA, NE, and 5-HT, a new set of in vitro solutions were made that contain all three monoamines (Table 1). These mixtures are entirely different from the initial in vitro mixtures used to create the training set, as those mixtures contained either one or two monoamines each. The mixtures here contained three monoamines and would serve purely as a test set (no iteration of the model would be trained on this set of mixtures). A similar procedure was used to construct this test set and pre-process it (Fig. 2). Three CFMs were used to record 20 voltammograms from each of these mixtures. DiscrimNet and SVR were then used to predict the concentrations of DA, NE, and 5-HT of each voltammogram.
Table 1 In vitro validation solution concentrations. Each mixture consisted of all three monoamines.Selectivity validation experimentsPrior work has shown that the voltammograms recorded by M-CSWV are not affected by other common electroactive interferents in the brain, including adenosine, ascorbic acid, DOPAC, pH changes, homovanillic acid (HVA), and uric acid. [32] However, to further confirm that DiscrimNet’s concentration prediction performance would not be affected by these electroactive interferents, we performed two separate in vitro validation experiments across 3 CFMs.
In the first experiment, 20 in vitro voltammograms were collected from solutions that contained 500 nM DA by itself or in the presence of physiologic concentrations of other possible in vivo interferents. Each solution contained 500 nM DA in addition to one of adenosine (1 μM), ascorbic acid (200 μM), HVA (20 μM), DOPAC (20 μM), uric acid (100 μM), or pH change (-0.2). DiscrimNet was then assessed on its ability to predict the correct DA concentration based on the voltammograms. DiscrimNet was not retrained using voltammograms collected with these other interferents.
In the second experiment, 20 in vitro voltammograms were collected from solutions that contained all three analytes of interest (DA, NE, and 5-HT) in various concentrations (Fig. 4I) and in the presence of physiologic concentrations of one other possible in vivo interferent (adenosine, pH change, DOPAC, and uric acid). DiscrimNet was then assessed on its ability to predict the correct analyte concentrations based on the voltammograms. DiscrimNet was not retrained using voltammograms collected with these other interferents.
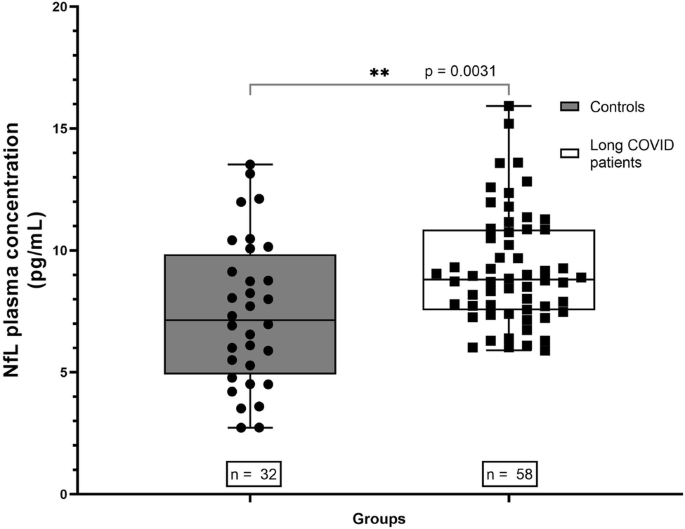
Fig. 4: Model output, performance, and validation.
A 500 nM dopamine. B 500 nM norepinephrine. C 100 nM serotonin. The voltammograms for DA and NE are very similar due to their structural similarity. D Root Mean Square Errors (RMSEs) between actual and predicted monoamine concentrations. The test set consisted of voltammograms obtained using the same electrodes (within) as the training set voltammograms. E Same as (A), but the test set consisted of voltammograms obtained using different electrodes (across) as those from the training set. F Training and validation loss curves for DiscrimNet phase 1, training on labeled in vitro data. G Training and validation loss curves for DiscrimNet phase 2, training on unlabeled in vivo data. H DiscrimNet and SVR are used to predict concentrations from in vitro mixtures containing all three monoamines. Error bars indicated standard deviation across CFMs. I Solutions used for the second selectivity validation experiment. All 4 solutions were measured across 3 CFMs. Monoamine concentrations are in nM. J DiscrimNet performance for both selectivity validation experiments, as well as its performance from monoamine mixtures without interferent (same data as (H), left). Error bars indicate standard deviation across CFMs.
In vivo validation experimentsMale Sprague-Dawley rats (n = 8; 200 g; Envigo, United States) were used for in vivo validation studies. Rats were kept in social housing in an Association for Assessment and Accreditation of Laboratory Animal Care International (AAALAC) accredited vivarium following a standard 12-h light/dark cycle at constant temperature (21 °C) and humidity (45%) with ad libitum food and water. The present studies were approved by the Institutional Animal Care and Use Committee (IACUC), Mayo Clinic, Rochester, MN. The NIH Guide for the Care and Use of Laboratory Animals guidelines (Department of Health and Human Services, NIH publication No. 86-23, revised 1985) were followed for all aspects of animal care. As animals were not allocated to separate experimental groups, randomization and blinding were not needed.
Rats were anesthetized with urethane (1.5 g/kg, i.p., Sigma-Aldrich, St. Louis, MO, USA). After depth of anesthesia was confirmed with loss of hind limb nociceptive withdrawal response, rats were fixed to a stereotactic surgical frame (David Kopf Instruments, Tujunga, CA, USA). A burr hole was drilled over the right nucleus accumbens core (Coordinates from bregma [41]: AP: +1.2, ML: +1.4, DV: -6.5 to -7.5) for placement of the CFM. Another burr hole was drilled on the contralateral side for placement of the Ag/AgCl reference electrode. The CFM was lowered to the target location, and the M-CSWV signal was allowed to stabilize for 60 minutes. Then, cocaine (2 mg/kg, i.v., n = 4) [17] or oxycodone (2.5 mg/kg, i.v., n = 4) [42] was administered, and the resulting effects on monoamine concentrations were recorded with M-CSWV.
After the experiment, DiscrimNet was used to predict concentrations for the three monoamines over the course of each in vivo experiment. Each model was evaluated on its ability to track the expected changes in the monoamines in response to cocaine and oxycodone based on their mechanisms of action.
留言 (0)