
記住我




Type 2 Diabetes Mellitus (T2DM) constitutes a profound global health dilemma, significantly amplifying the risk of morbidity and mortality related to atherosclerosis cardiovascular disease (ASCVD) (1). This ailment drastically diminishes life expectancy, evidenced by findings that, compared to individuals without diabetes, men and women afflicted by diabetes mellitus experience a reduction in lifespan of approximately 7.5 and 8.2 years, respectively. The anticipated growth of the global diabetic population to approximately 439 million adults by 2030 underscores a 69% increase in developing countries and a 20% increase in developed countries (2).Addressing this imminent crisis necessitates a large-scale, population-based follow-up study vital for prevention, early detection, and the identification of associated risk factors.
T2DM patients represent distinctive cardiovascular profiles marked by elevated atherosclerotic plaque burdens, larger atheromatous plaque volumes, and lipid metabolism dysfunction (3–5). Decades ago, the groundbreaking Framingham Heart Study highlighted the prospective link between diabetes mellitus and an increased prevalence of cardiovascular disease, particularly impactful in women across various age groups (6). Despite the historical recognition of heightened risks, significant progress in improving cardiovascular outcomes through glucose reduction has remained elusive. Hafner and colleagues (7) delved into the mortality landscape within cardiovascular diseases among T2DM patients, revealing a concerning outlook. The mortality rate for T2DM patients without a history of myocardial infarction (MI) is 15.4%. This rate increases dramatically to 42.0% for T2DM patients with a history of MI. In stark contrast, individuals without T2DM face significantly lower risks, with mortality rates from cardiovascular causes at 2.1% and 15.9% for those without and with a history of MI, respectively.
In recent years, the explosion of genomic data availability has elevated bioinformatics analysis methods to indispensable tools in scientific research (8, 9). Bioinformatics analysis plays a pivotal role in deciphering this wealth of information, enabling the identification of Differentially Expressed Genes (DEGs), conducting intricate Gene Ontology (GO) analyses, and performing insightful pathway analyses (10). In our study, we have seamlessly integrated cutting-edge bioinformatics techniques with data sourced from two pivotal databases: the National Health and Nutrition Examination Survey (NHANES) and the Gene Expression Omnibus (GEO) hosted by the National Center for Biotechnology Information (NCBI). The combination of these two databases allows the complex relationship between T2DM and ASCVD to be elucidated at the metabolic and molecular levels. We aim to employ a multifaceted bioinformatics approach to unravel the genetic mechanisms underpinning the comorbidity of T2DM and ASCVD.
Materials and MethodsData CollectionOur study samples and data were sourced from the NHANES (https://wwwn.cdc.gov/nchs/nhanes/) from 2001 to 2018. NHANES is a nationally representative survey of the non-institutionalized civilian population in the US, and the survey involved interviews conducted at participants’ homes and standardized physical examinations, including laboratory tests, performed at mobile screening centers (MEC).
To identify pertinent datasets for our investigation, we conducted a comprehensive search of the NCBI GEO database (https://www.ncbi.nlm.nih.gov/geo/) using specific medical keywords such as “Type 2 diabetes mellitus”, “Atherosclerosis”, “Homo sapiens”, “Expression profiling by array”, and “expression profiling analysis”. The objective was to pinpoint datasets that met stringent criteria: they had to contain archived information on both case and control groups, offer raw data for further analysis, and enable expression analysis using array methods. Additionally, our search was limited to datasets exclusively featuring data from Homo sapiens (Figure 1).
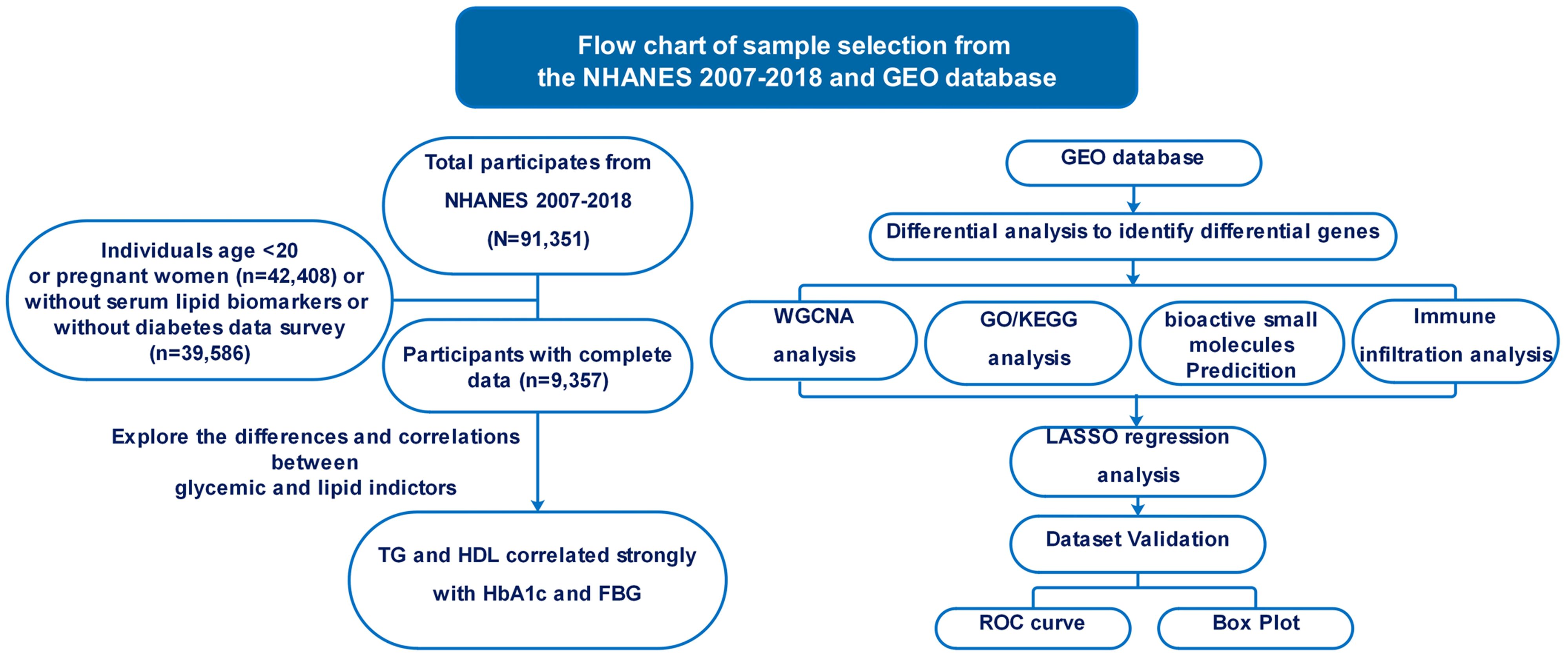
Figure 1 Flowchart illustrating the methodology employed in this study.
Microarray analysis was performed using two different platforms: the GSE40231 dataset employed the GPL570 (Affymetrix Human Genome U133 Plus2 microarrays), whereas the GSE9006 dataset utilized the GPL96 (Illumina HumanHT-12 V4.0 Expression Bead Chip). The T2DM dataset (GSE9006) comprised gene expression data from peripheral blood mononuclear cells (PBMC) collected from 24 healthy people and 12 newly diagnosed with T2DM. We utilized 40 samples of Atherosclerotic Arterial Wall (AAW) and 40 samples of Non-Atherosclerotic Arterial Wall (NAW) from GSE40231 to identify DEGs, including Differentially Expressed mRNAs (DEmRNAs) and Long Non-Coding RNAs (DElncRNAs). Additionally, we validated the diagnostic efficacy of essential genes using datasets from two different platforms: the T2DM (GSE71416) from the GPL570 platform, which included 14 morbidly obese diabetic patients (cases) and six morbidly obese non-diabetic patients, and the AS dataset (GSE43292) utilizing 32 AAW samples and 32 NAW samples.
Study populationIn this cohort study, we selected adult participants from the NHANES spanning from 2001 to 2018, totaling 91,351 individuals. The inclusion criteria mandated participants to be at least 20 years old and not pregnant, narrowing down the cohort to 48,943 participants. Following the exclusion of individuals with missing data on fasting blood glucose (FBG), hemoglobin A1c (HbA1c), triglyceride (TG), total cholesterol, low-density lipoprotein (LDL), and high-density lipoprotein (HDL), the final participant was 9,357.
To identity individuals withT2DM, we adhered to the American Diabetes Association’s diagnostic criteria, which include:(1)a self-reported physician diagnosis of diabetes; (2) the use of oral hypoglycemic agents or insulin for treatment; (3) a fasting plasma glucose level of at least 126 mg/dL; (4) an HbA1c level of at least 6.5%. Following these criteria, 1,829 participants were classified into the diabetes group, whereas 7,528 were allocated to the control group. Our study rigorously followed the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) reporting guidelines to ensure the highest level of clarity, transparency, and rigor in reporting the observational study findings.
Differential analysisWe used R software version 4.2.2 and processed raw matrices downloaded from the datasets. Data normalization was performed using the RMA algorithm after preprocessing and converting probe IDs to gene symbols using annotated platform files. Empty probes were removed, and values for genes with multiple probes were averaged to enhance result reliability.
Separate analyses were conducted for AS and T2DM datasets. The limma package was employed with stringent criteria (|logFC| >1 and Padj< 0.05) to identify DEGs. This approach identified genes with significant expression changes between case and control groups. An overlap analysis of DEGs from T2DM and AS datasets was also performed. We identified common DEGs to uncover potential molecular links between T2DM and AS. Venn Analytics was used for this analysis, allowing for a comprehensive evaluation of shared genes (11). These overlapping DEGs form the basis for further exploration into the molecular mechanisms connecting T2DM and AS.
Functional Enrichment AnalysisWe conducted an integrated analysis using Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) to explore biological functions and pathways associated with the identified genes (12–14). Visual representations were generated using the ggplot2 package in R4.2.2, facilitating a clear understanding of enriched pathways and their significance. Pathways with a P-value < 0.05 were considered statistically significant, indicating robust associations between T2DM and AS.
Construction of WGCNA co-expression modules for datasetsWe applied weighted gene co-expression network analysis (WGCNA) to assess gene expression patterns in extensive T2DM and AS datasets (15). Genes with significant Padj values (P <0.05) and absolute logarithmic changes greater than 1 were chosen. Combining the soft thresholding-derived neighbor-joining matrix with a gene-gene correlation matrix,we explored gene connectivity, describing the network’s interconnectedness. Co-expression modules were identified through transformation of the neighbor-joining matrix into a topological overlap matrix, followed by gene hierarchical clustering dendrogram analysis, grouping genes with similar expression patterns and implying potential functional links. To pinpoint clinically relevant modules, we calculated module eigengene sand examined their correlation with clinical features, focusing on modules with positive correlations in both T2DM and AS datasets. Positive correlations between modules and diseases indicated strong associations between module genes and the respective disease.
Identification of critical genesLASSO (Least Absolute Shrinkage and Selection Operator) is a regression-based methodology that accommodates many covariates in the model. Notably, LASSO possesses a distinct feature of penalizing the absolute value of regression coefficients. Our study employed the ‘glmnet’ package in the R software to conduct LASSO analysis on the candidate hub genes and DEGs. This analysis aided in identifying the final hub genes that exhibited strong associations with the studied conditions.
Diagnostic potency assessment of Hub genes and their expression correlationTo assess the potential diagnostic utility of the hub genes, we evaluated performance using the T2DM dataset (GSE9006 and GSE71416) and the AS dataset (GSE40231 and GSE43292). The ROC curves provide a graphical representation of the sensitivity and specificity of the hub genes as diagnostic markers. By analyzing area under curve (AUC), we can measure the accuracy with which central genes classify disease and control groups. The closer the AUC value is to 1, the higher the diagnostic accuracy.
Additionally, to investigate significant differences in gene expression levels between the groups, we employed t-tests. These tests allowed us to compare the expression levels of the hub genes in individuals with T2DM, AS, and controls.
Immune Cell CompositionThe CIBERSORT algorithm was employed to calculate the proportions of various immune cells in the peripheral blood of patients with T2DM and non-T2DM participants and the arterial wall of patients with AS and non-AS participants. Using the R package “CIBERSORT” and the expression matrices, we determined the proportions of 22 immune cell types in the T2DM and AS disease groups and their respective control groups. To visually represent the proportions of the 22 immune cells in the disease and control groups for T2DM and AS, we generated heatmaps using the “corrplot” package. These heat maps provided a comprehensive view of the quantitative correlations between each disease condition’s different immune cell types. Additionally, we employed the “ggplot2” Rpackage to explore potential associations between immune cell proportions and the expression levels of specific diagnostic markers in the context of T2DM and AS.
Target prediction of bioactive small moleculesThe Connectivity Map (cMAP) database provided by the Broad Institute (https://clue.io)consist of drug-like compounds tested for gene expression (16). We uploaded all common DEGs in the GSE9006 and GSE40231 datasets to the cMAP database to screen small molecule candidates. We screened with a score greater than 90, suggesting they potentially have therapeutic effects on T2DM and AS.
Statistical analysisAll statistical analyses were done using R software (R version 4.2.2). Means and confidence intervals for quartile HbA1c and quartile FBG versus lipid indices were calculated by linear regression. Wilcoxon test was used for statistical analysis between diabetic and non-diabetic groups. We used Spearman’s correlation analysis to investigate the relationship between glycemia and lipid indices by calculating the means and confidence intervals of quartile HbA1c and quartile FBG versus lipid indices in the T2DM using multivariate logistic regression modeling. Statistical significance was determined based on P-values less than 0.05, 0.01, or 0.001. These thresholds helped identify genes with statistically significant differences in expression levels between the disease and control groups. By combining ROC curve analysis and t-tests, we can assess the diagnostic performance of the pivotal genes and determine which genes may be promising biomarkers for differentiating between T2DM, AS, and controls. P-values less than 0.05 (P < 0.05) indicate statistical significance. Significance levels are expressed as follows: *P < 0.05, **P < 0.01, ***P < 0.001. ***P < 0.001.
ResultsParticipant CharacteristicsTable 1 shows the demographic characteristics of the 9,357 participants included in the study, segregated into two groups: 1,829 individuals diagnosed with T2DM and 7,528 controls. The prevalence of T2DM was significantly higher in males (P=0.026), and the group of former smokers, hypertensive, alcohol drinkers, and less educated had a higher risk of developing the disease (P < 0.001). Patients with T2DM had a lower BMI than the healthy population (P < 0.001).
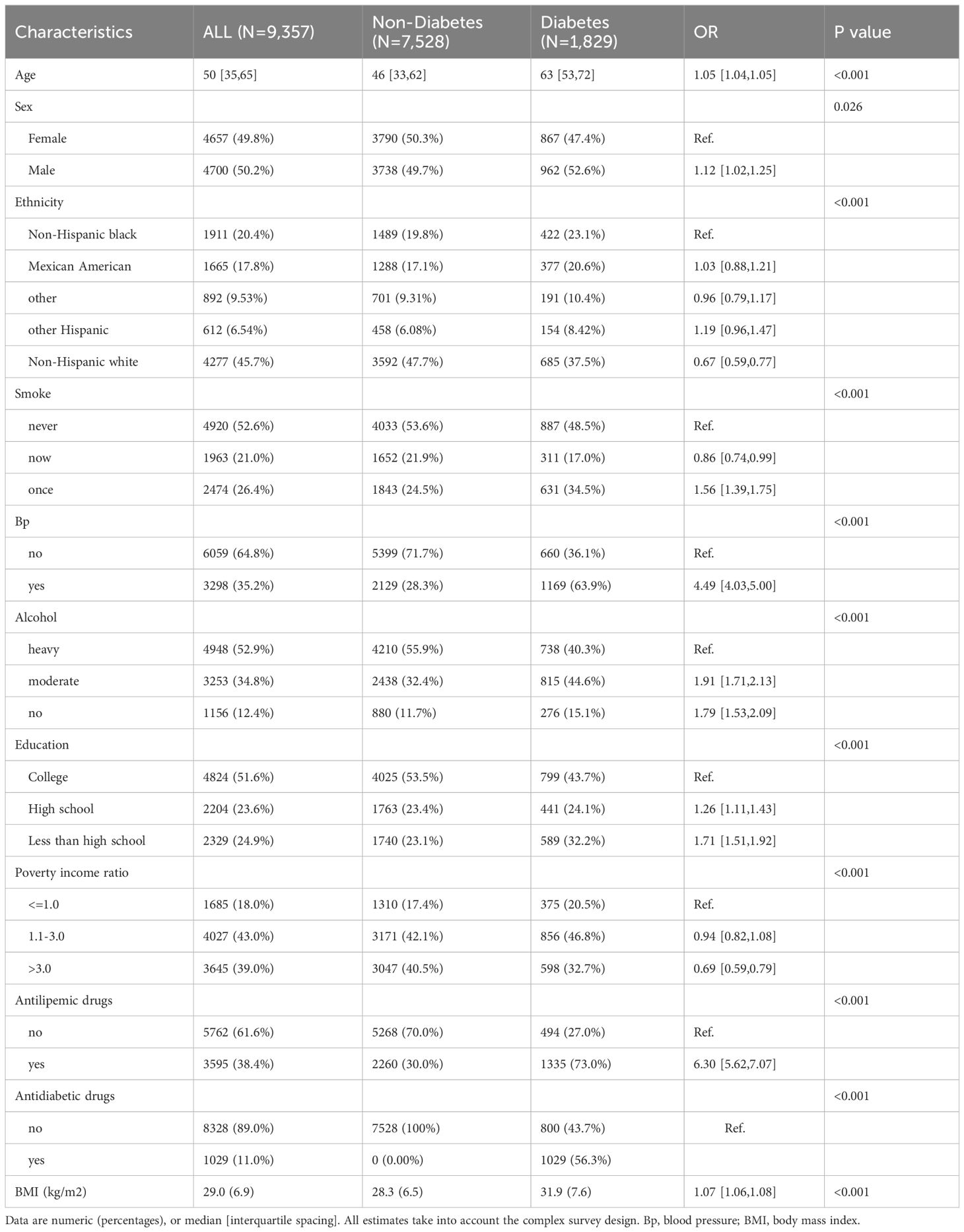
Table 1 Baseline characteristics of study population, NHANES 2001–2018.
Association between Baseline glycemic and lipid markersSignificant differences in HDL, LDL, TG, total cholesterol, FPG, and HbA1c levels between the two groups of patients were analyzed by comprehensive generalized linear regression (Figures 2A-F). FBG, HbA1c, and TG levels were significantly higher in diabetic patients than in non-diabetic patients (P < 0.001) (Figures 2A, B, D). In addition, total cholesterol, LDL, and HDL levels were significantly lower in diabetic patients than non-diabetic patients(Figures 2C, E, F). In Figure 3, our analysis showed a significant positive correlation (P < 0.01) between FBG, HbA1c, and TG (Figures 3B, F). In contrast, there was a significant negative correlation (P < 0.01) between FBG, HbA1c, and HDL levels (Figures 3D, H). There was also a low positive correlation (P < 0.01) between HbA1c and total cholesterol, LDL (Figures 3E, G). Meanwhile, FBG also showed a lower positive correlation with total cholesterol and LDL as well (Figures 3A, C). These findings highlight the unique lipid profile of diabetic patients and emphasize the intricate relationship between glycemic control and lipid metabolism.
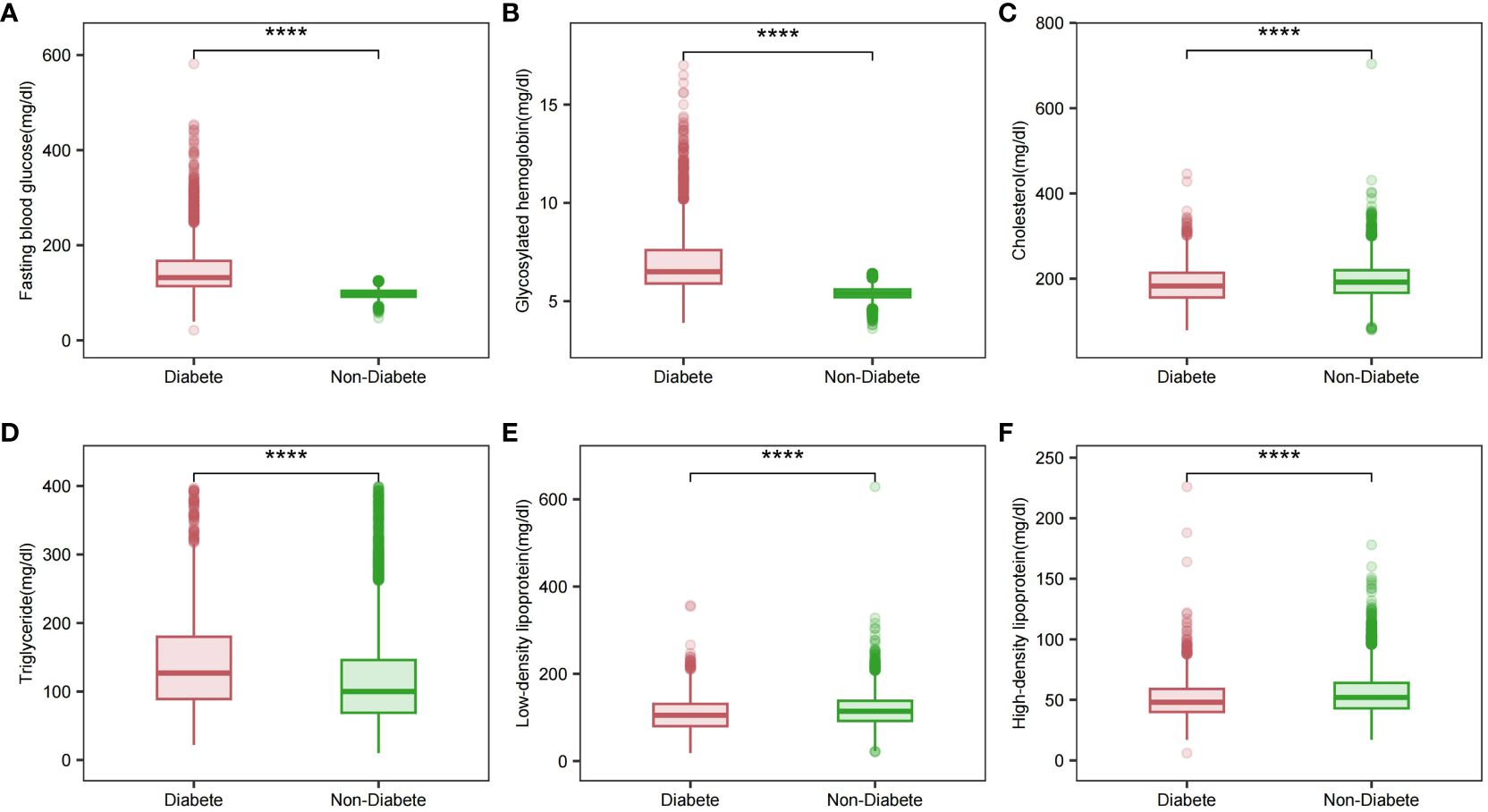
Figure 2 Glycemic and lipid profiles in different diabetic states. (A) Fasting glucose profile in different diabetic states; (B) Glycosylated hemoglobin profile in different diabetic states; (C) Total cholesterol profile in different diabetic states; (D) Triglyceride profile in different diabetic states; (E) LDL profile in different diabetic states; (F) HDL profile in different diabetic states. Comparison of means between groups performed by wilcox test (****P <0.0001).
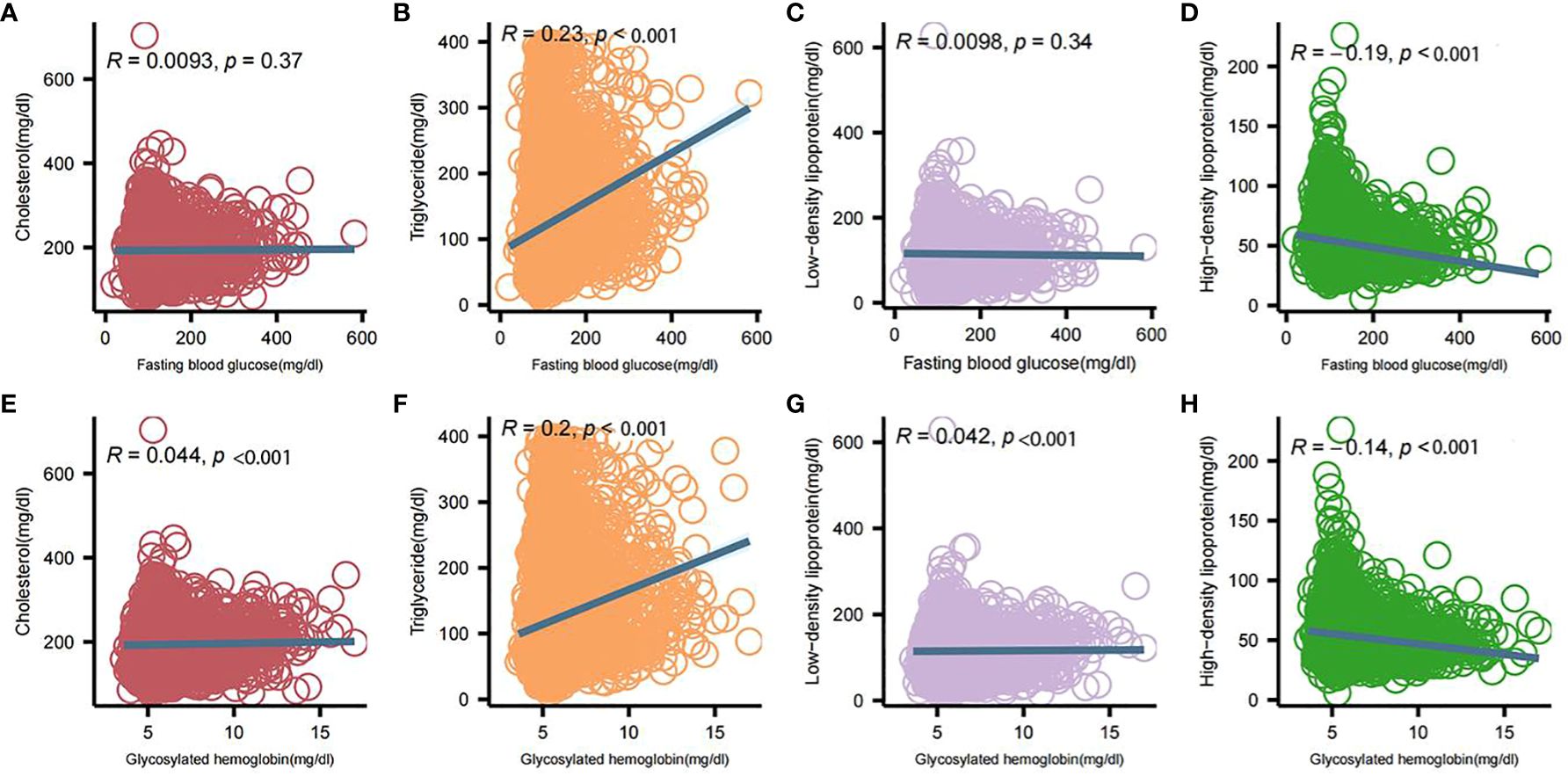
Figure 3 Correlation analysis between blood glucose and lipid profile components. (A) Correlation of fasting glucose and total cholesterol; (B) Correlation of fasting glucose and triglycerides; (C) Correlation of fasting glucose and low-density lipoproteins; (D) Correlation of fasting glucose and high-density lipoproteins; (E) Correlation of glycosylated hemoglobin and total cholesterol; (F) Correlation of glycosylated hemoglobin and triglycerides; (G) Correlation of glycosylated hemoglobin and low-density lipoproteins; (H) Correlation between glycosylated hemoglobin and high-density lipoprotein. Intergroup correlations were determined using spearman.
Glycemic and Lipid Indices Correlation in a Diabetic CohortTable 2 stratifies FBG into quartiles, revealing a progressive increase in TG with higher FBG levels, indicating a heightened risk (OR 1.4, 95% CI [1.3-1.5]). Concurrently, HDL levels inversely correlate with FBG (P < 0.001). Similarly, Table 3 categorizes HbA1c into intervals, demonstrating significant TG elevation with increased HbA1c (OR 1.3, 95% CI [1.2-1.4]), alongside a decline in HDL with rising HbA1c levels (P < 0.001). Elevated FBG and HbA1c are associated with higher total cholesterol and LDL levels.
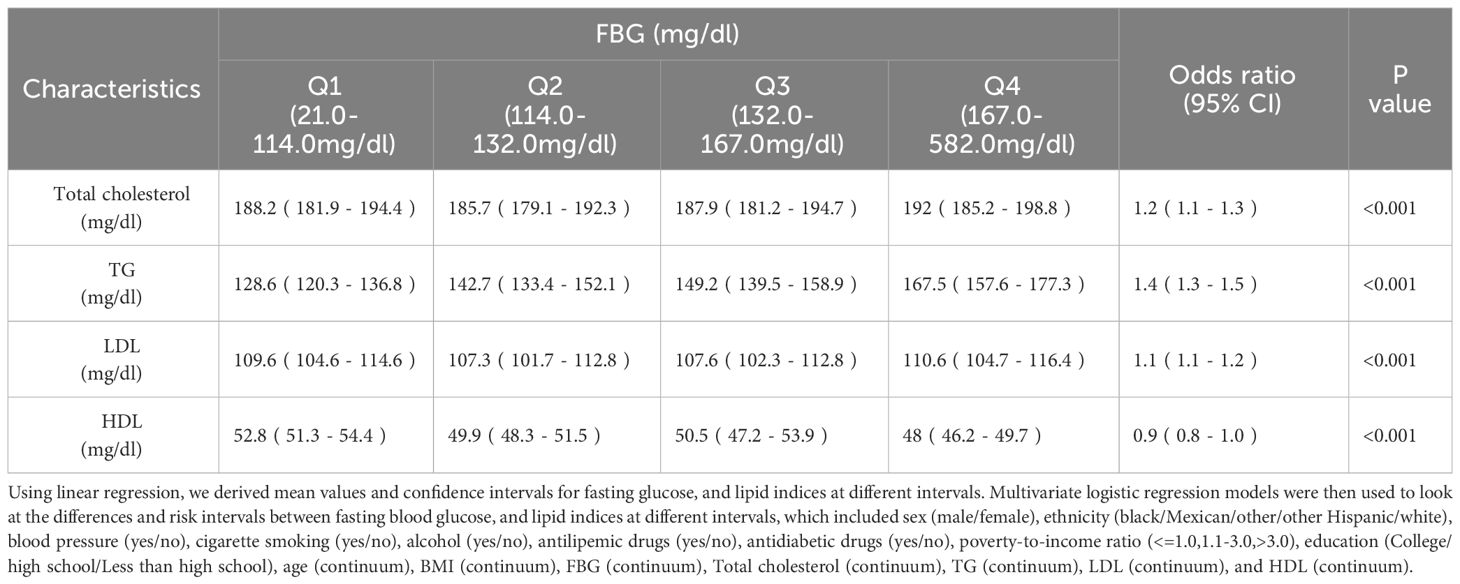
Table 2 Lipid profile in people with different levels of FBG.
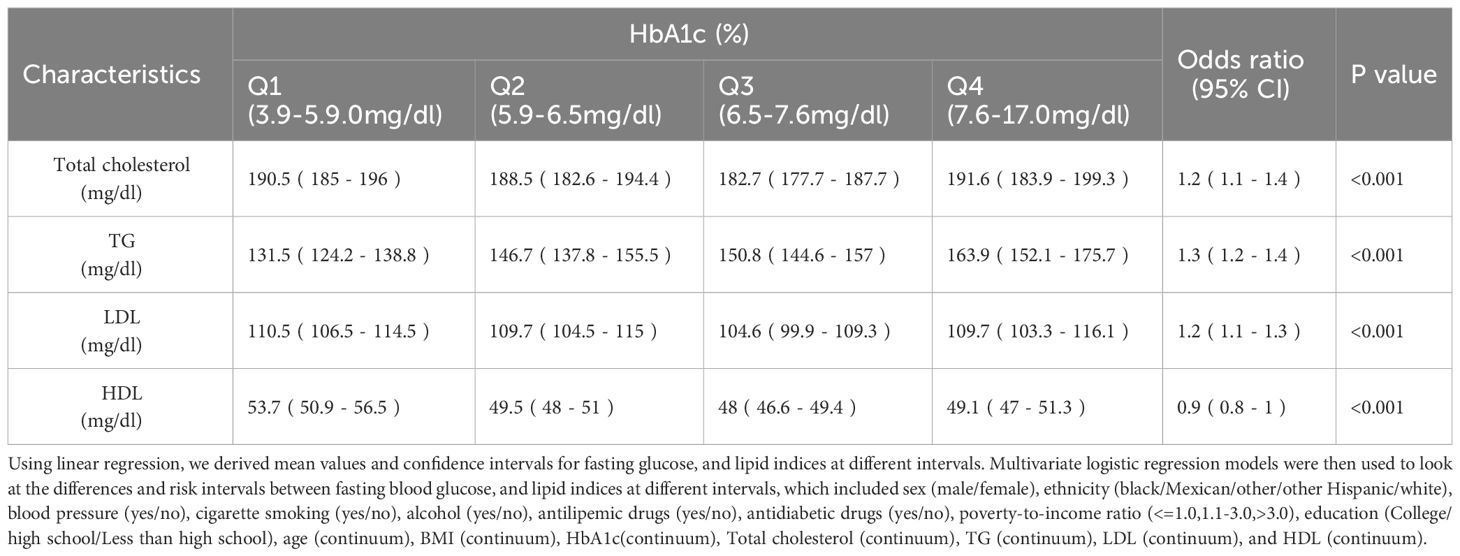
Table 3 Lipid profile in people with different levels of HbA1c.
Identification of DEGs and Functional Enrichment AnalysisAmong the 76 common DEGs, 21 were upregulated, an increased expression level, while 21 were down-regulated, indicating a decreased expression level (Supplementary Figures 1A-C). GO and KEGG enrichment analyses showed that lipid metabolism-related pathways significantly enriched the differential genes in both diseases. The results of GO analysis showed that the differential genes in both diseases were increased dramatically in response to fatty acid, long-chain fatty acid transport, lipid storage, triglyceride metabolic process, positive regulation of LDL receptor activity, fatty acid transmembrane transport, regulation of LDL particle clearance, LDL particle clearance, negative regulation of LDL particle receptor catabolic process and positive regulation of receptor-mediated endocytosis involved in cholesterol transport. KEGG analysis of differential genes was mainly enriched in the Adipocytokine signaling pathway, Glucagon signaling pathway, Insulin resistance, Insulin signaling pathway, Phospholipase D signaling pathway, Fatty acid degradation, Carbohydrate digestion and absorption, Fatty acid metabolism, regulation of lipolysis in adipocytes and VEGF signaling pathway (Figure 4D).
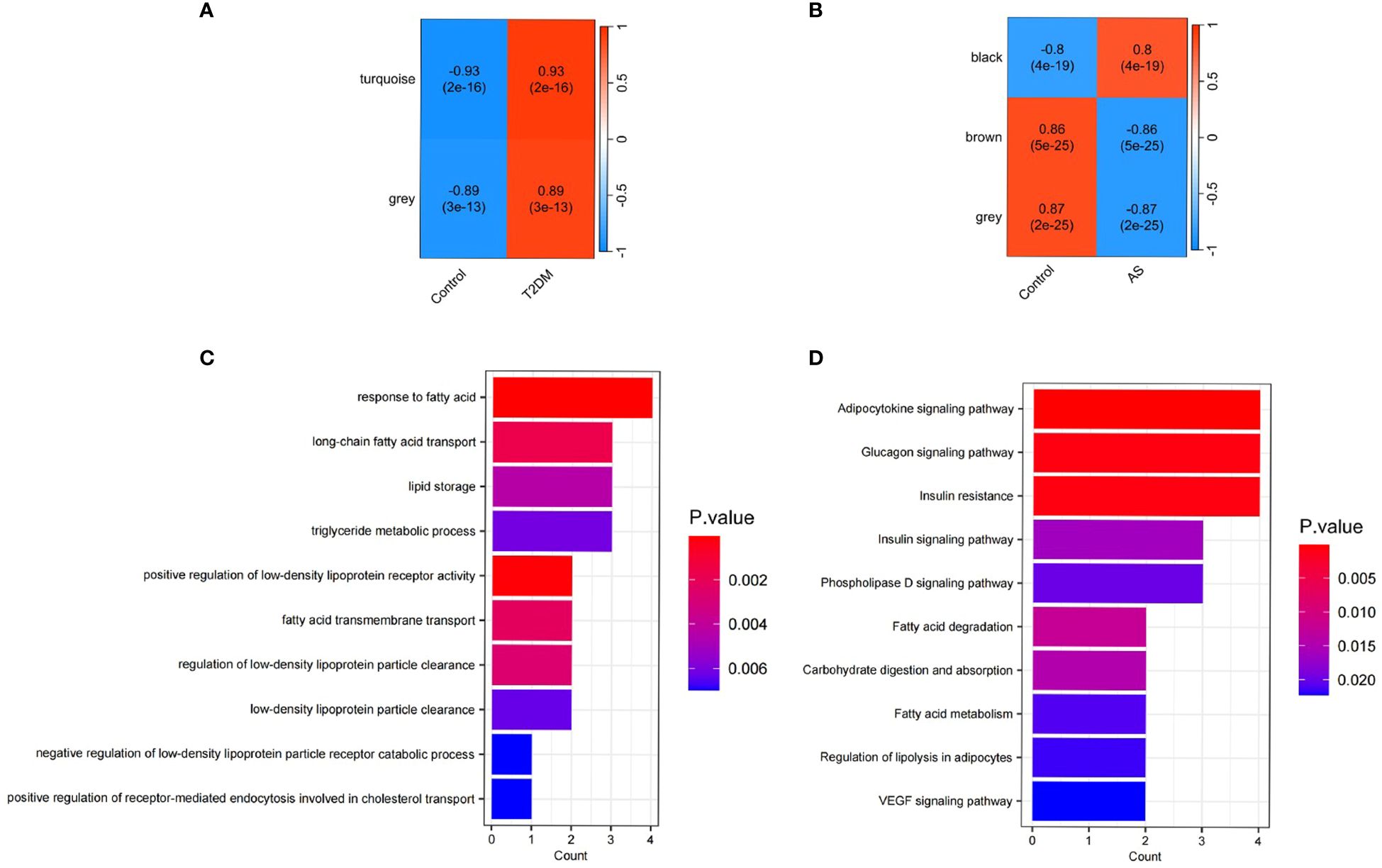
Figure 4 Functional enrichment analysis and WGCNA. (A) Correlation between modules and T2DM traits heatmap; (B) Correlation between modules and AS traits heatmap; (C) Enriched Gene Ontology (GO) terms; (D) Kyoto Gene and Genome Encyclopedia (KEGG) pathway.
Co-expression modules of T2DM and AS analyzed by WGCNATo construct a scale-free topological model, we chose a soft threshold β of 14 for the GSE40231 dataset and a soft threshold β of 9 for the GSE9006 dataset (Supplementary Figures 2A-D). These thresholds were instrumental in identifying gene modules that displayed positive associations with AS and T2DM. By applying hierarchical clustering and Spearman correlation analysis, we successfully identified three gene modules exhibiting positive associations with T2DM, encompassing 439 T2DM-related genes (Figure 4A). Likewise, we identified three gene modules that demonstrated positive associations with AS, encompassing 3084 AS-related genes (Figure 4B). Importantly, we observed 32 overlapping genes within the modules detected by the GSE40231 and GSE9006 datasets(Supplementary Figure 1D). These shared genes are fascinating as they may be crucial in developing AS and T2DM.
Screening for Hub GenesBy LASSO regression analysis, 15 genes were selected as candidate genes for each of the two diseases (Figures 5A-D). Among them, there were six overlapping genes in both diseases. To further explore the association between these two diseases, we first tested the diagnostic effect of critical genes and whether they were differentially expressed. After removing the mismatched genes, the results showed that two genes (ABCC5 and WDR7) were significantly upregulated in T2DM and AS samples compared with standard samples (Figures 6A, B), and the AUC values of these two genes were more outstanding than 0.6, which provided better diagnostic effects (Figures 6C, D). In addition, we validated the diagnostic efficiency and expression levels of these two critical genes in validation datasets (GSE71416 and GSE43292) (Figures 6E-H). The results suggest that upregulation of these essential genes may lead to T2DM and induce AS.
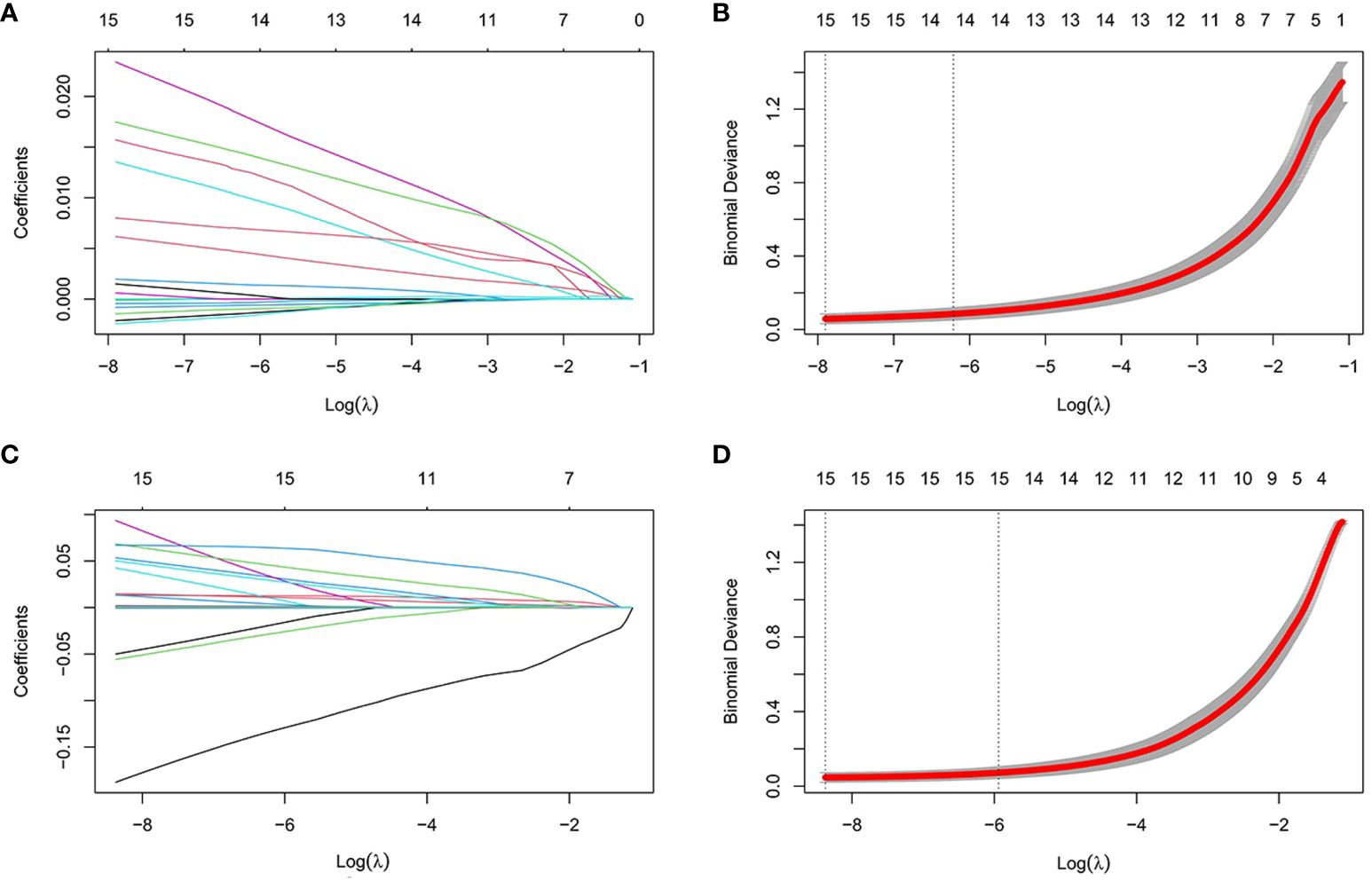
Figure 5 Establishment of diagnostic biomarkers by LASSO regression analysis. (A) LASSO coefficient profiles in T2DM; (B) Log (lambda) sequence used to construct a coefficient profile diagram in T2DM; (C) LASSO coefficient profiles in AS; (D) Log (lambda) sequence used to construct a coefficient profile diagram in AS.
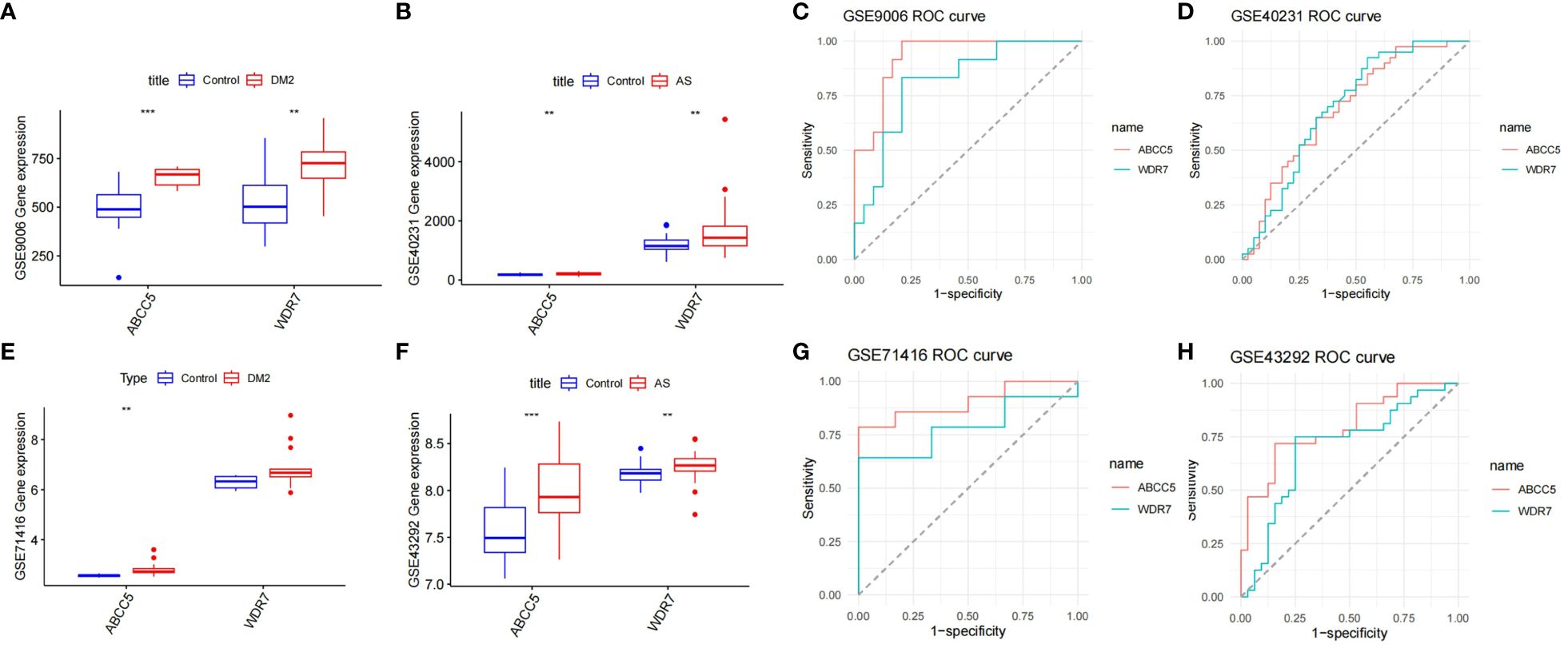
Figure 6 Diagnosis of genetic value. (A) Expression levels of the two key genes in GSE9006 in normal and T2DM patients; (B) Expression levels of two key genes in GSE40231 in normal and AS patients; (C) ROC curves of two key genes in T2DM dataset GSE9006; (D) ROC curves of two key genes in AS dataset GSE40231; (E) Expression levels of two key genes in GSE71416 in normal and T2DM patients; (F) Expression levels of two key genes in GSE43292 in normal subjects and AS. (G) ROC curves of two key genes in T2DM dataset GSE71416; (H) ROC curves of two key genes in AS dataset GSE43292; Box plots: X-axis represents genes, Y-axis represents expression levels. Comparison of means between groups performed by t-test (** P <0.01, *** P <0.001).
Changes in the proportions of immune cells in T2DM and ASWe performed an in-depth analysis of the proportions of 22 immune cell types using the CIBERSORT algorithm. We included 12 patients with T2DM and 24 control samples, which showed a high percentage of infiltration of CD4 native T cells, resting NK cells, CD8 T cells, and monocytes. Notably, patients with T2DM demonstrated increased proportions of CD4 native T cells, gamma delta T cells, and neutrophils compared to the control group. Conversely, the proportions of CD8 T cells, resting NK cells, monocytes were decreased (Figures 7A, C).
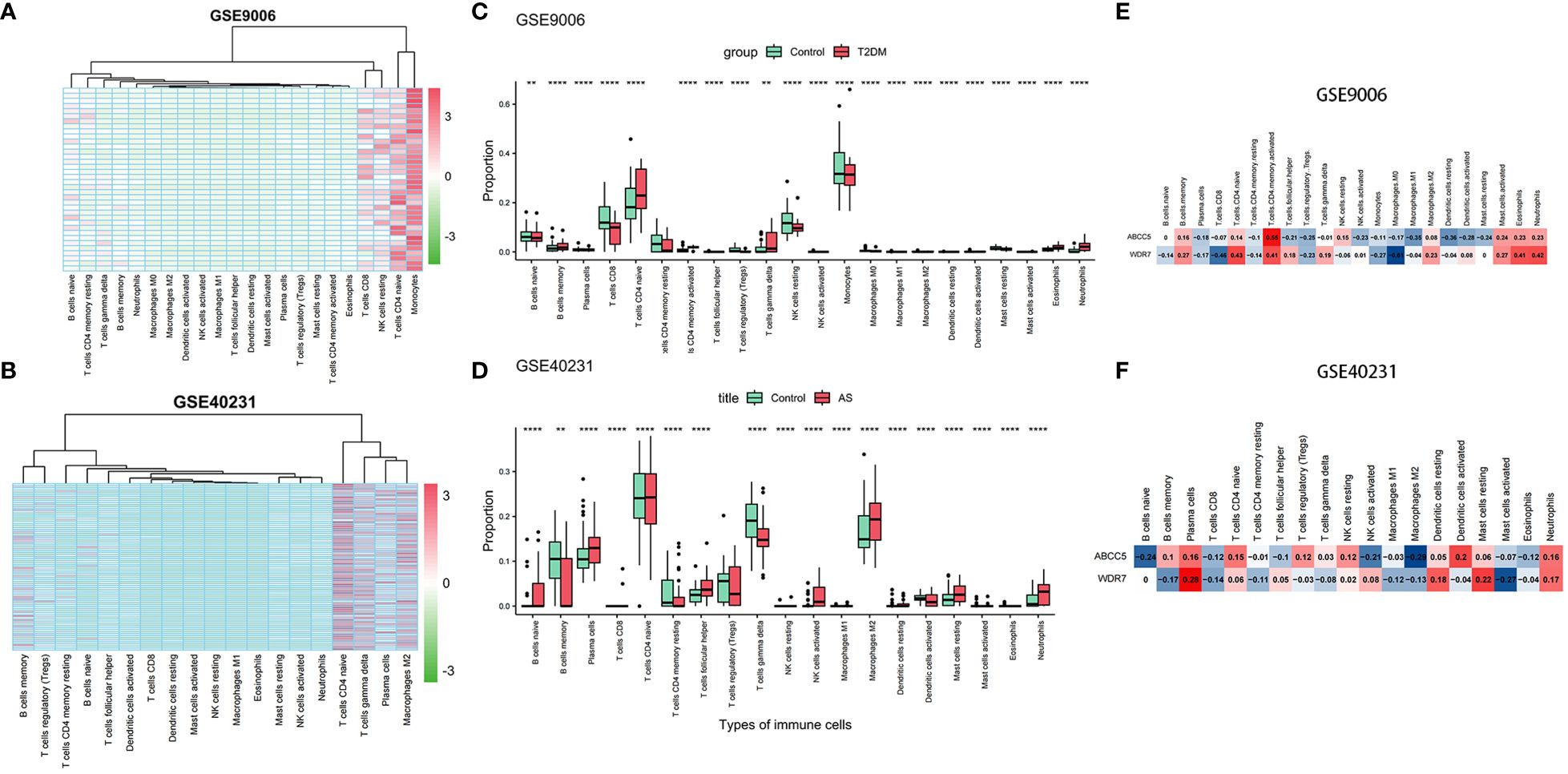
Figure 7 Immune infiltration analysis. (A) Heatmap of samples in GSE9006 dataset with immune cells; (B) Heatmap of samples in GSE40231 dataset with immune cells; (C) Infiltration in immune cells in normal and T2DM groups in GSE9006 dataset; (D) Infiltration in immune cells in normal and AS groups in GSE40231 dataset; (E) Expression of two hub genes in immune cells of GSE9006 dataset; (F) Expression of two hub genes in immune cells of GSE40231 dataset. (** P <0.01,**** P <0.0001).
Subsequently, we extended our analysis to 40 patients with AS and 40 control samples. The results demonstrated higher infiltration percentages of naive T cells,gamma delta T cells, plasma cells, and M2 macrophages among the 22 immune cell types in patients with AS. Compared to the control group, patients with AS exhibited elevated proportions of naive B cells, plasma cells, follicular helper T cells, Tregs, activated NK cells, M2 macrophages, and resting mast cells and neutrophils. In contrast, the proportions of memory B cells, resting CD4 memory T cells, and gamma delta T cells were decreased (Figures 7B, D). In addition, we found that two hub genes, ABCC5 and WDR7, were positively correlated with Neutrophil native cells CD4 naive, and negatively correlated with Macrophages M1 in AS and T2DM (Figures 7E, F).
Identification of Therapeutic Small Molecular Agents Based on the DEGsBased on the results obtained from the cMap database, we have identified potential small molecular agents with therapeutic implications based on the upregulated genes. Among them, the top small molecules with the highest absolute enrichment values are presented in Table 4, including RITA, ON-01910, doxercalciferol, topiramate. These findings provide valuable insights into the potential therapeutic options for AS and T2DM.
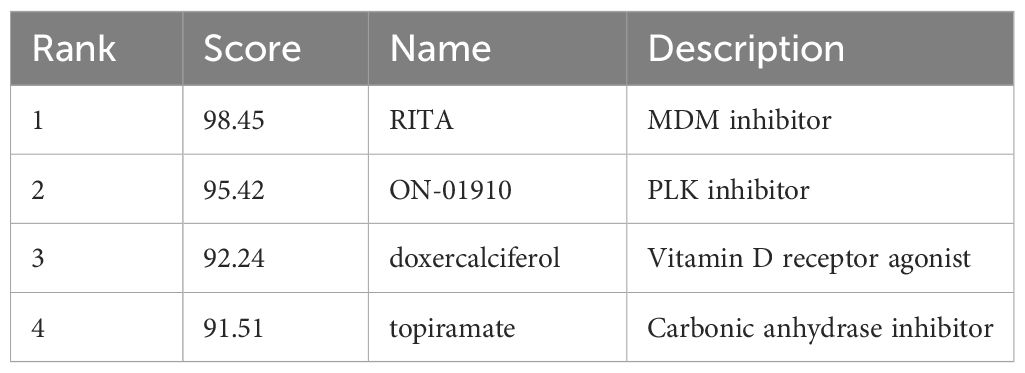
Table 4 Small molecules predicted with the common shared DEGs.
DiscussionDespite available interventions, ASCVD remains a significant cause of morbidity and mortality in individuals with T2DM (17, 18). In this study, we employed an interdisciplinary approach integrating bioinformatics, molecular biology, and clinical epidemiology to comprehensively explore the relationship between T2DM and ASCVD. In the NHANES database, we found that increases in FBG and HbA1c significantly increased the risk of elevated TG, and Ye et al. found that in patients with T2DM, elevated triglyceride levels tended to be associated with an increased risk of CVD, which may suggest that blood glucose levels play a significant role in the development of ASCVD (19) (Tables 2, 3). However, the role of TG in ASCVD was not widely accepted initially, but they are now recognized as necessary (20–22).
Our identification of 76 common DEGs in both T2DM and AS patients revealed genes with abnormal expression patterns(Supplementary Figure 1A). Functional enrichment analysis revealed that the DEGsare significantly engaged in crucial signaling pathways governing lipid metabolism. These pathways encompass fatty acid response, long-chain fatty acid transport, lipid storage, and triglyceride metabolism, alongside the modulation of LDL receptor activity, including its positive regulation and transmembrane transport of fatty acids (Figures 4A, B). Moreover, our findings highlight the intricate regulation of LDL particle clearance, encompassing both its enhancement and the suppression of the receptor’s catabolic processes, as well as the facilitation of cholesterol transport via receptor-mediated endocytosis. This aligns with and substantiates the findings reported in existing literature (23, 24). This suggests that lipid metabolism plays a crucial role in the process of elevated cardiovascular disease risk in people with T2DM.
WGCNA analysis revealed ABCC5 and WDR7 as potential target genes that may play pivotal roles in the pathogenesis of both T2DM and ASCVD. Recent investigations have illuminated the pivotal role of WDR7, identified within the V-type ATPase interactome, as a crucial co-factor influencing the assembly and functional integrity of the V-type ATPase complex, essential for cellular proton (H+) regulation (25). Li et al (26). demonstrated that WDR7 is instrumental in modulating the assembly of the V-type ATPase. A deficiency in WDR7 triggers a compensatory expansion and subsequent over-acidification of endo-lysosomal compartments. Aberrant endo-lysosomal function could exacerbate the cellular stress response, influencing insulin signaling pathways and glucose metabolism during diabetes. Similarly, the altered intracellular trafficking and acidification may contribute to the accumulation of lipid-laden macrophages, a hallmark of atherosclerotic plaque development.
ABCC5, also known as Multidrug Resistance Protein 5 (MRP5), has been molecularly identified as the first ATP-dependent cyclic nucleotide export pump (27–29). Notably, ABCC5 mRNA is more abundant in the human heart than in other organs (30). Studies have confirmed the expression of ABCC5 at the protein level in human atrial and ventricular samples, primarily localized in vascular endothelial cells and smooth muscle cells (31). Furthermore, due to ischemic conditions, ABCC5 protein levels were upregulated in ventricular samples from patients with end-stage heart failure.ABCC5 polymorphisms have been associated with T2DM, insulin resistance, and visceral fat accumulation, indicating its potential role in damaging endothelial cells through lipid metabolic pathways (27).
Recent advancements underscore the therapeutic potential of targeted molecular interventions in addressing the complex interplay between diabetes, atherosclerosis, and their underlying mechanisms. Therefore, we screened the cMAP database for predicted small-molecule compounds (Table 4). RITA activates p53, thereby modulating key molecules such as HIF-1α and vascular endothelial growth factor, unveiling a new pathway that could impact metabolic diseases with pathological characteristics similar to diabetes (32). Concurrently, ON-01910inhibits Polo-like kinase 1 (Plk1), engaging in the shared molecular mechanisms of cell proliferation and inflammation, thus paving a new route for the treatment of diabetes and atherosclerosis (33). Doxercalciferol, a vitamin D receptor agonist, highlights the close association between vitamin D deficiency and conditions such as diabetes, arterial hypertension, and chronic kidney disease (34, 35). The detection of nuclear vitamin D receptors (VDRs) in vascular endothelial cells and cardiomyocytes indicates that vitamin D is directly involved in the development and progression of cardiovascular diseases (36, 37). Topiramate, promotes insulin secretion and enhances insulin sensitivity, offering an effective solution for the critical challenges of β-cell dysfunction and insulin resistance in T2DM (38).
Most of the current intractable human diseases are associated with immune system disorders, which significantly impact metabolic diseases by altering metabolism, making metabolic immunology a critical emerging discipline today. We found that the proportion of T-cell CD4 native infiltration was significantly elevated in both T2DM and AS compared to controls (P<0.001) (Figures 7C, D). In addition, we found that two central genes, ABCC5 and WDR7, were positively correlated with neutrophils, T cell CD4 naive, and negatively correlated with macrophage M1 (Figures 7E, F).
LimitationFirstly, the sample size and coverage of our study, although substantial, might not adequately represent the broader population affected by T2DM and ASCVD. Therefore, our sample may not capture the full spectrum of demographic and clinical variability, including age, gender, ethnicity, and comorbid conditions, which could significantly influence the disease mechanisms and outcomes. Therefore, future studies should prioritize expanding the sample size and ensuring a more diverse and representative population to enhance the external validity of the findings. the observational nature of our study inherently limits our ability to establish causal relationships between the observed variables. While we have identified correlations that suggest potential mechanisms linking T2DM and ASCVD, these associations do not imply causality. The reliance on observational data, without the ability to control for all potential confounding variables, underscores the need for cautious interpretation of the results. Experimental studies, particularly randomized controlled trials, are essential to confirm the causal links between T2DM and ASCVD and to understand the underlying biological processes.
Lastly, our research did not encompass functional experimental validation of the specific genes implicated in our findings. This limitation highlights a gap in our study, as experimental validation is crucial for verifying the biological relevance and mechanistic role of these genes in the context of T2DM and ASCVD.
Future studies should leverage more comprehensive datasets, employ methodologies that enhance data quality and representation, and incorporate experimental validations. Such endeavors will undoubtedly enrich our understanding and contribute to developing more effective strategies for the prevention, management, and treatment of T2DM and ASCVD.
ConclusionWe identified new target genes ABCC5 and WDR7, which provide valuable avenues and directions for precision medicine and molecular mechanisms of T2DM and AS. We also proposed the potential of RITA, ON-01910, doxercalciferol, and topiramate as targeted small-molecule drugs, which marks our significant progress in precision medicine for T2DM and ASCVD.
Data availability statementThe datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary Material.
Ethics statementEthical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent from the patients/participants or patients/participants’ legal guardian/next of kin was not required to participate in this study in accordance with the national legislation and the institutional requirements.
Author contributionsYZ: Methodology, Formal analysis, Writing – review & editing, Visualization, Validation, Software, Data curation, Writing – original draft. LJ: Supervision, Writing – original draft, Writing – review & editing, Data curation. DY: Writing – review & editing, Methodology. JW: Writing – review & editing, Methodology, Investigation. FY: Writing – review & editing, Funding acquisition, Writing – original draft.
FundingThe author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This study received supports from the National Natural Science Foundation of China (Grant No. 81901853 to YF),the Foundation of State Key Laboratory of Component-based Chinese Medicine (Grant No. CBCM2023107 to FY) and foundation of 2nd affiliated hospital of Harbin medical university (PYMS2023-12 to FY).
AcknowledgmentsThe authors express their gratitude to the generous contributors of the GEO database and NHANES database for sharing their valuable data, also express their sincere gratitude to Professor Bo Yu for his invaluable contributions through fruitful discussions and technical assistance. Furthermore, the authors extend their heartfelt appreciation to Ms. Wang Lin for her exceptional passion and unwavering dedication, as well as for her remarkable warmth, charm, humor, and compassion.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fendo.2024.1383772/full#supplementary-material
AbbreviationsT2DM, Type 2 Diabetes Mellitus; ASCVD, Atherosclerotic Cardiovascular Disease; DEGs, Differentially Expressed Genes; GO, Gene Ontology; KEGG, Kyoto Encyclopedia of Genes and Genomes; GEO, Gene Expression Omnibus; WGCNA, Weighted Gene Co-Expression Network Analysis; MEs, Module Eigengenes; TOM, Topological Overlap Matrix; LASSO, Least Absolute Shrinkage and Selection Operator; ROC, Receiver Operating Characteristic; cMAP, Connectivity Map.
References1. Rawshani A, Franzen S, Sattar N, Eliasson B, Svensson A-M, et al. Risk factors, mortality, and cardiovascular outcomes in patients with type 2 diabetes. N Engl J Med. (2018) 379:633–44. doi: 10.1056/NEJMoa1800256
PubMed Abstract | CrossRef Full Text | Google Scholar
2. Williams R, Karuranga S, Malanda B, Saeedi P, Basit A, Besançon S, et al. Global and regional estimates and projections of diabetes-related health expenditure: Results from the International Diabetes Federation Diabetes Atlas, 9th edition. Diabetes Res Clin Pract. (2020) 162:108072. doi: 10.1016/j.diabres.2020.108072
PubMed Abstract | CrossRef Full Text | Google Scholar
4. Chu X, Feng B, Ge J, Guo L, Huo Y, Ji L, et al. Chinese expert consensus on the risk assessment and management of panvascular disease in patients with type 2 diabetes mellitus (2022 edition). Cardiol Plus. (2022) 7:162–77. doi: 10.1097/CP9.0000000000000029
CrossRef Full Text | Google Scholar
5. Wu J, Zhang Y, Ji L, Zhao S, Han Y, Zou X, et al. Associations among microvascular dysfunction, fatty acid metabolism, and diabetes. Cardiovasc Innov Appl. (2023) 8:941. doi: 10.15212/CVIA.2023.0076
CrossRef Full Text | Google Scholar
6. Chan JC, Lim L-L, Wareham NJ, Shaw JE, Orchard TJ, Zhang P, et al. The Lancet Commission on diabetes: using data to transform diabetes care and patient lives. Lancet. (2020) 396:2019–82. doi: 10.1016/S0140-6736(20)32374-6
PubMed Abstract | CrossRef Full Text | Google Scholar
7. Haffner SM, Lehto S, Ronnemaa T, Pyörälä K, Laakso M. Mortality from coronary heart disease in subjects with type 2 diabetes and in nondiabetic subjects with and without prior myocardial infarction. N Engl J Med. (1998) 339:229–34. doi: 10.1056/NEJM199807233390404
PubMed Abstract | CrossRef Full Text | Google Scholar
8. Guo S, Zhang H, Chu Y, Jiang Q, Ma Y. A neural network-based framework to understand the type 2 diabetes-related alteration of the human gut microbiome. iMeta. (2022) 1:e20. doi: 10.1002/imt2.20
CrossRef Full Text | Google Scholar
9. Zhao C, Zhang Z, Sun L, Bai R, Wang L, Chen S. Genome sequencing provides potential strategies for drug discovery and synthesis. Acupuncture Herbal Med. (2023) 3:244–55. doi: 10.1097/HM9.0000000000000076
CrossRef Full Text | Google Scholar
10. Libuit KG, Doughty EL, Otieno JR, Ambrosio F, Kapsak CJ, Smith EA, et al. Accelerating bioinformatics implementation in public health. Microbial Genomics. (2023) 9:001051. doi: 10.1099/mgen.0.001051
CrossRef Full Text | Google Scholar
11. Szklarczyk D, Franceschini A, Wyder S, Forslund K, Heller D, Huerta-Cepas J, et al. STRING v10: protein–protein interaction networks, integrated over the tree of life. Nucleic Acids Res. (2015) 43:D447–52. doi: 10.1093/nar/gku1003
PubMed Abstract | CrossRef Full Text | Google Scholar
13. Reimand J, Isserlin R, Voisin V, Kucera M, Tannus-Lopes C, Rostamianfar A, et al. Pathway enrichment analysis and visualization of omics data using g:Profiler, GSEA, Cytoscape and Enrichment Map. Nat Protoc. (2019) 14:482–517. doi: 10.1038/s41596-018-0103-9
PubMed Abstract | CrossRef Full Text | Google Scholar
15. Langfelder P, Horvath S. WGCNA: an R package for weighted correlation network analysis. BMC Bioinf. (2008) 9:1–13. doi: 10.1186/1471-2105-9-559
CrossRef Full Text | Google Scholar
16. Musa A, Ghoraie LS, Zhang S-D, Glazko G, Yli-Harja O, Dehmer M, et al. A review of connectivity map and computational approaches in pharmacogenomics. Briefings Bioinf. (2018) 19:506–23. doi: 10.1093/bib/bbw112
留言 (0)