
記住我







DNA methylation is essential for numerous biological processes and is associated with multiple diseases, particularly cancer (Maegawa et al., 2010; Yehudit and Howard, 2013). Accurately identifying DNA methylation sites is necessary for comprehending gene regulation and the mechanisms of diseases. Deep learning approaches have recently emerged as a significant tool in recognizing DNA methylation sites, demonstrating encouraging outcomes. Presently, three extensively studied DNA methylation types include N6-methyladenine (6mA), 5-hydroxymethylcytosine (5hmC), and N4-methylcytosine (4mC) (Manavalan et al., 2019; Yingying et al., 2021).
The field has recently witnessed notable advancements in integrating deep learning methodologies. Regarding the prediction of DNA methylation sites of 4-mC species, in 2019, introducing two remarkable algorithms, 4mCCNN (Khanal et al., 2019) and 4mCPred-SVM (Leyi et al., 2019), marked a leap in 4-mC prediction capabilities. 4mCCNN used a CNN-based framework, whereas 4mCPred-SVM was developed using support vector machine (SVM) techniques. Additionally, Quanzhong et al. (2020) crafted DeepTorrent, a composite model fusing CNN and BiLSTM, to identify 4-mC sites (Quanzhong et al., 2020). Deep4mC, another innovative algorithm, validated the effectiveness of a CNN-only approach in delivering impressive 4-mC prediction outcomes (Haodong et al., 2020). Hyb4mC introduced a unique approach, integrating an elastic net with a capsule network for smaller datasets while emphasizing the prowess of CNN for larger datasets (Ying et al., 2022). Moreover, Zeng et al. introduced a novel two-layer deep learning structure named Deep4mcPred, based on ResNet with long short-term memory (LSTM) (Rao and Minghong, 2020). Xia et al. (2023) presented the DRSN4mCPred model, a variant based on the deep residual network, and it can enhance the model’s capability to assimilate intricate data characteristics (Xia et al., 2023).
The research focusing specifically on recognizing 5hmC sites is comparatively limited. Tran TA et al. applied a unique feature extraction approach using k-mer embeddings obtained from a pre-trained language model (Duong et al., 2021). The BiLSTM-5mC model leveraged one-hot encoding and nucleotide property and frequency (NPF) techniques for representing nucleotide sequences. It then integrated a bidirectional long short-term memory (BiLSTM) model with a fully connected network to forecast methylation sites (Xin et al., 2021).
The field has seen considerable research in identifying 6-mA methylation sites. For instance, the sNNRice6mA algorithm adopted a two-dimensional one-hot encoding approach for DNA sequences, using a convolutional neural network (CNN) to identify 6-mA sites (Haitao and Zhiming, 2019). Ying et al. (2021) incorporated an attention mechanism into their model, enhancing the identification of critical features for more accurate detection of epigenetic changes in DNA (Ying et al., 2021). Mehedi et al. (2020) developed Meta-i6mA, a cross-species predictive framework for 6-mA sites in plant genomes, leveraging informative features in a comprehensive machine learning methodology (Mehedi et al., 2020). Juntao et al. (2021) introduced DeepM6ASeq-EL, an advanced method combining LSTM with ensemble learning to predict human m6A sites in RNA with high accuracy (Juntao et al., 2021). This fusion of techniques significantly boosts the model’s prediction accuracy, offering a powerful tool for m6A site identification in the human genome. Sho et al. (2022) used word to vector (word2vec) and Bidirectional Encoder Representations from Transformers (BERT) for developing BERT6mA, a deep learning framework that showed exceptional performance in predicting 6-mA modifications (Sho et al., 2022). Ue et al. (2022) proposed a CapsuleNet-based DNA m6A site recognition framework, proving its precision in methylation site prediction (Ur et al., 2022). Sho et al. (2022) demonstrated that BERT-based models could significantly enhance the accuracy of predicting 6-mA sites in DNA, effectively handling interspecies variations and serving as a valuable asset for plant genome studies and epigenetic research (Sho et al., 2022).
Although the methods mentioned earlier have achieved varying degrees of progress, they are all specifically designed to identify one type of DNA methylation. Conversely, there are only a few techniques that address all three previously mentioned methylation categories (Lv et al., 2020; Yingying et al., 2021; Junru et al., 2022), with notable examples being iDNA-ABT (Yingying et al., 2021), iDNA-ABF (Junru et al., 2022), and iDNA-MS (Lv et al., 2020). Typically, DNA methylation datasets appropriate for deep learning contain shorter sequences per sample, with sequences of 41 base pairs (bp) being predominantly prevalent.
Many studies indicate a growing interest in using deep learning to predict DNA methylation, achieving significant progress in enhancing prediction accuracy (Wang et al., 2023). However, current deep learning-based models have not completely exploited the capabilities of learning features. Acknowledging this gap, the genomic sequences can be viewed as biological texts, and the sequences’ bases can be considered biological words (Zou et al., 2019; Dai et al., 2022). Considering this, we propose the iDNA-OpenPrompt model, an OpenPrompt learning approach (Ding et al., 2021) for DNA methylation sequences. The model combines a prompt template, prompt verbalizer, and pre-trained language model (PLM) to construct a prompt learning framework.
Moreover, a DNA vocabulary library, BERT tokenizer, and specific label words are also introduced into the model to enable accurate identification of DNA methylation sites. An extensive analysis is conducted to evaluate the predictive performance, reliability, and consistency of the iDNA-OpenPrompt model. The results, which include 17 benchmark datasets covering a variety of species and three types of DNA methylation modifications (4 mC, 5 hmC, and 6 mA), consistently reveal that our model surpasses other outstanding methods in both performance metrics and overall robustness.
The primary contribution of this article is that the iDNA-OpenPrompt model can learn biological contextual semantics. In contrast to the existing approaches, iDNA-OpenPrompt brings the following contributions:
(1) Our model creates a DNA vocabulary library and integrates it with the BERT tokenizer for DNA methylation sequences to develop the prompt template.
(2) Our model constructs label words specific to DNA methylation sequences and integrates them with the BERT tokenizer to establish a prompt verbalizer.
(3) Our model constructs an OpenPrompt learning model that can be used for identifying DNA methylation sites.
2 Materials and methods2.1 DatasetFor the iDNA-OpenPrompt model’s evaluation, the datasets are selected from the iDNA-MS web server (iDNA-MS, 2020), including training and independent testing subsets, as detailed in Table 1. There are 4mC, 5hmC, 6mA methylation sequences, totaling 17 datasets, encompassing 501,200 DNA sequences. The length of each sample in the datasets is 41 base pairs. It is worth mentioning that in the 6mA samples, the methylated adenine (A) is always found in the central position, and similarly, methylated cytosine (C) is prominent in the 5hmC and 4mC samples. Indeed, such central position characteristics are also present in the negative samples.
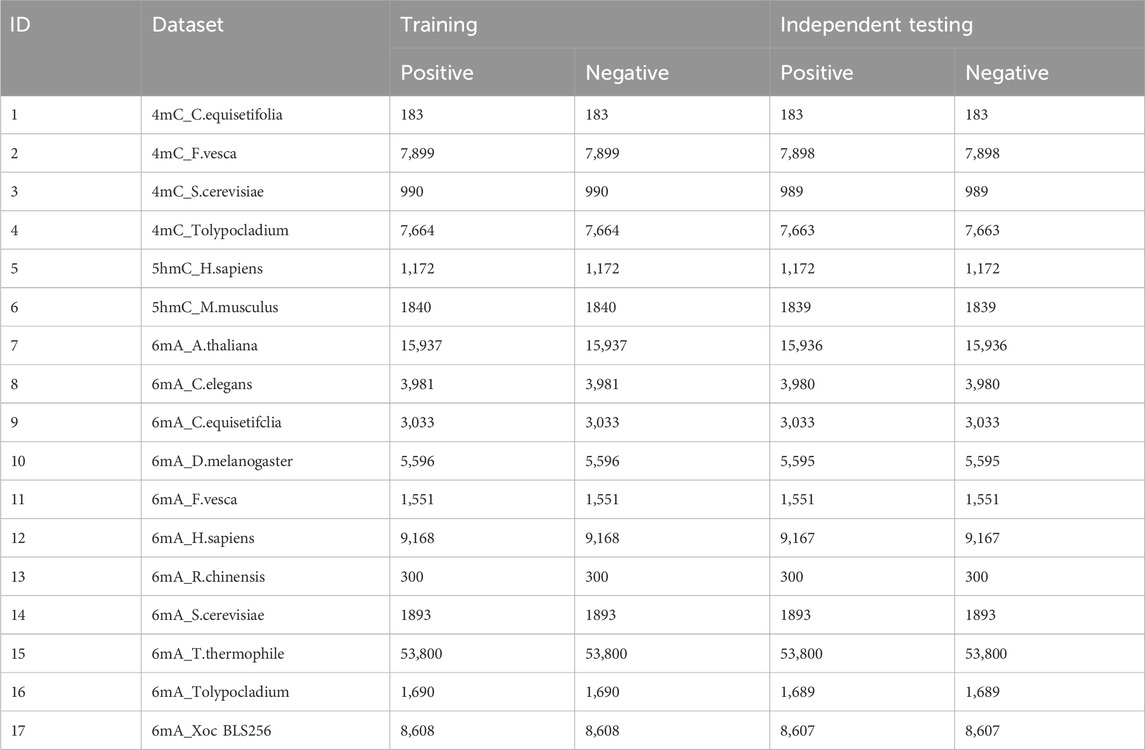
Table 1. Overview of datasets.
Table 1 includes a “dataset” column, which lists the names of the various datasets. Within these names, the part before the “-” separator signifies the methylation modification type, and the segment following the separator denotes the species type. The “training” and “testing” columns provide detailed information about the quantity of positive and negative samples within each dataset.
2.2 Overview of iDNA-OpenPromptFigure 1 displays the overall structure of the iDNA-OpenPrompt model. The core module of the iDNA-OpenPrompt model (prompt model) mainly consists of three parts: the prompt template, prompt verbalizer, and PLM. The prompt template part involves building a DNA vocabulary library and training it in the transformer’s BERT tokenizer to form the prompt template. In the prompt verbalizer part, label words for DNA methylation sequences are created, and the constructed label words, along with the transformer’s BERT tokenizer, are used to build a prompt verbalizer in the manual verbalizer method of OpenPrompt learning. The BERT model, which can capture bidirectional contextual information in the text, is used for the PLM part. Below, the key technologies of the iDNA-OpenPrompt model will be introduced.
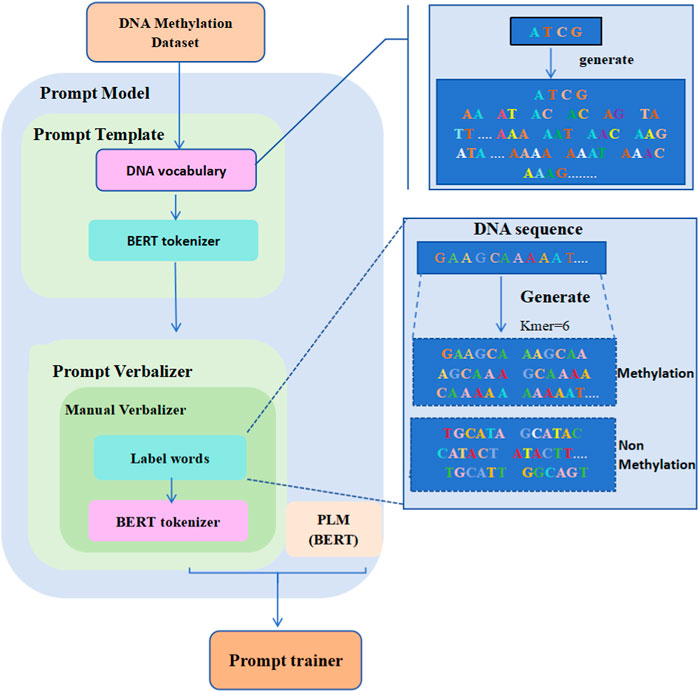
Figure 1. Overall architecture of the iDNA-OpenPrompt Model.
2.3 Prompt learningIn a standard prompt learning setting, like in natural language processing (NLP) tasks, input sentences are structured through a natural language template. This process frames text classification tasks as cloze-style tasks (Zhu et al., 2023). For example, in a task of classification, the goal is to categorize the sentence x into various topics, such as “I must reduce the budget” into the label. y1=BUSINESS or y2=SPORTS, and the template could be expressed as Eq. (1):
xp=CLSx,aMASKquestion.(1)Given an input x=x1,x2,⋯,xn, categorized into a label y from the set of labels Y, the corresponding label word set is represented as Vy=y1,y2,⋯,yn . Here, Vy is a subset of the vocabulary V and associated with the y category. In PLMs, denoted as P, the probability of each word v in Vy being used to fill in the [MASK] is represented by pMASK=v∈Vy|xp. As a result, the text classification task is reformulated by calculating the probabilities of label words. This computation is formulated as Eq. (2):
py∈Y|x=pMASK=v∈Vy|xp.(2)In this example, if the determined probability for V1=business, corresponding to y1=BUSINESS, exceeds that of V2=sports for y2=SPORTS, it suggests that the sentence x belongs to the BUSINESS category.
2.4 OpenPromptOpenPrompt (Ding et al., 2021) is an open-source toolkit designed for prompt learning, offering both ease of use and extensibility. It effectively modularizes the entire prompt learning framework and considers the interactions between various modules. OpenPrompt enables the versatile integration of different task formats, PLMs, and prompting modules. An instance of this flexibility is the straightforward adaptation of prefix-tuning (Li and Liang, 2021) for text classification tasks within OpenPrompt. This capability allows users to evaluate the broad applicability of their prompt learning models across different tasks rather than just focusing on performance in specific tasks.
In OpenPrompt, the template class is specifically used to create or define textual or soft-encoding templates encapsulating the original input. The templates are pivotal in constructing and formatting input data for effective interaction with PLMs (Han et al., 2021). They can wrap original text data into a format that aligns with the structure of PLMs. Templates can add extra contextual information to aid the model in more effectively comprehending and handling the input data. The verbalizer bridges PLMs and specific task requirements, offering a flexible and effective way to customize model outputs.
2.5 Prompt templateThe prompt template is to construct a prompt framework, which involves formatting the original input data (such as sentences or paragraphs) into a specific structure, making it more suitable for understanding and processing by PLMs. One or more mask tokens are often inserted (for example, the [MASK] token used in BERT).
Various studies have explored different types of templates. For instance, there are manually written templates (Schick and Schütze, 2020) and purely soft templates (Lester et al., 2021). Liu et al. (2023) demonstrated effective results by keeping manual tokens unchanged while fine-tuning a smaller portion (Liu et al., 2023). Han et al. (2022) used contextualized templates, necessitating the addition of specific entities to create complete templates. Additionally, their approach to loss calculation involved using outputs from various positions (Han et al., 2022). Logan IV et al. (2021) introduced an empty template, a straightforward combination of the input data, and a subsequent [MASK] token (Logan IV et al., 2021).
Within the iDNA-OpenPrompt model, the manual template, which is trainable using task-specific datasets, is used. This manual template enables the precise construction of templates based on one’s understanding of the task and specific requirements, and it can simplify the model training process and reduce the demand for computational resources. The template mainly consists of two modules: creating a DNA vocabulary library and the BERT tokenizer.
2.5.1 Creation of the DNA vocabularyWhen creating a vocabulary library for DNA methylation sequences, unlike in traditional NLP tasks, the presence of one, two, or even three nucleobases in a sequence does not necessarily indicate a DNA methylation site. Considering the categories of DNA methylation (4 mC, 5 hmC, and 6 mA) and the nucleobase composition for each, we propose using DNA vocabulary for DNA methylation sequences in the prompt template. Here, the length of nucleobase sequences (A, T, G, and C) is defined as kmer = 1, 2, 3, 4, 5, and 6, to form the DNA methylation sequence vocabulary. For example, at kmer = 1, the template includes four nucleobase words: A, T, G, and C. At kmer = 2, there are 16 nucleobase words, such as AA, AT, AG, …, and CC. Similarly, for kmer = 3, there are 64 nucleobase words; for kmer = 4, there are 256 nucleobase words; for kmer = 5, there are 1,024 nucleobase words; and for kmer = 6, there are 4,096 nucleobase words. The maximum k-mer value in this prompt template is set to 6 because, in DNA methylation sequences, 6 mA methylation involves attaching a methyl group to the sixth nitrogen atom of the adenine nucleobase. Therefore, the DNA vocabulary library contains a total of 5,460 nucleobase words. After creating the vocabulary library, the BERT tokenizer is used to generate the tokenizer of the iDNA-OpenPrompt model.
2.5.2 BERT tokenizerBERT tokenizer is designed explicitly for the BERT model and is pivotal in NLP tasks. The DNA vocabulary processed by the BERT tokenizer enables the raw text to be transformed into a format effectively handled by OpenPrompt learning. It breaks down basic text strings into smaller units, tokens, words, subwords, or symbols. To accommodate the needs of the BERT model, the BERT tokenizer automatically adds unique tokens such as the start of the sequence token [CLS], separator token [SEP], and padding token [PAD]. It creates an attention mask to indicate which tokens are meaningful and which are for padding. The BERT tokenizer provides essential text processing capabilities for the use of the iDNA-OpenPrompt model.
2.6 Prompt verbalizerIn OpenPrompt, the verbalizer plays an important role, especially when applying PLMs to downstream tasks. The primary function of the verbalizer is to map labels to the vocabulary; the verbalizer maps task-specific labels (such as category labels in classification tasks) to words within the pre-trained model’s vocabulary. This mapping allows the model to associate its outputs with specific labels.
Like prompt templates, prompt verbalizer classes derive from a shared base class featuring necessary attributes and essential abstract methods. Beyond the manually defined verbalizer, OpenPrompt includes automated options like the automatic verbalizer and knowledgeable verbalizer (Hu et al., 2021). Critical processes such as calibrations (Zhao et al., 2021) are also incorporated in OpenPrompt. In the iDNA-OpenPrompt model, a manual verbalizer is chosen for the prompt verbalizer; the manual verbalizer mainly consists of two modules: label words and BERT tokenizer.
2.6.1 Label wordsLabeling words is a crucial attribute in the manual verbalizer component within the OpenPrompt framework. These words or phrases are labeled words to interpret and transform the model’s output.
In this study, the method for constructing label words is as follows: for DNA methylation sequences and non-methylation sequences, centering around the 21st nucleobase of the sequences, kmer = 6 encoding is performed on the nucleobase sequences on both sides of the central nucleobase and the encoded words as label words. In all 4-mC sequences (including positive and negative samples), the 21st nucleobase is always C; in all 5-hmC sequences, it is C, and in all 6-mA sequences, it is A.
The words encoded from the positive samples in the DNA methylation sequence dataset are used as positive-sample label words. In contrast, those encoded from the negative samples are used as negative-sample label words.
For example, it is taking a positive sample from the 4-mC category of the 4 mC_F.vesca species, “GAAGCAAAAATCGGAAAACCCA … CTTTTGGTT”: the possible positive sample label words that can be constructed are as follows: “GAAGCA, AAGCAA, AGCAAA, GCAAAA, …, AAAACC, AGAAAA, GAAAAT, AAAATT, …, TTGGTT”. Similarly, a negative sample was taken from the 4-mC category of the 4 mC_F.vesca species, “TGCATACTTTCAGTAGTTTTCAAT … ATGGCAGT”: the negative sample label words that can be constructed are as follows: “TGCATA, GCATAC, CATACT, ATACTT, …, AGTTTT, AATGCA, ATGCAT, TGCATT, …, GGCAGT”. To understand the process of constructing label_words for DNA methylation sequences, Figure 2 illustrates its schematic diagram.
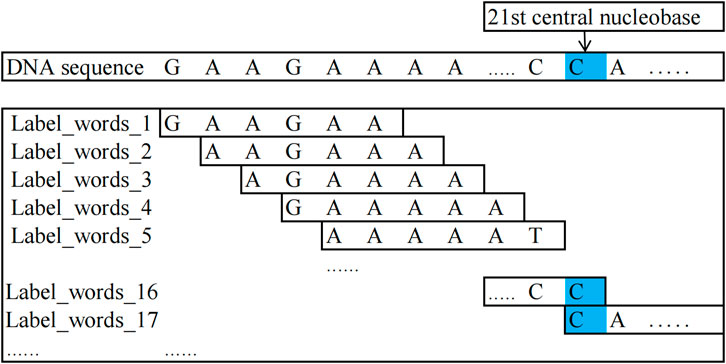
Figure 2. Schematic diagram of label_words for DNA methylation sequences.
2.7 PLMThe PLM of iDNA-OpenPrompt is the BERT model. The application of the BERT model in OpenPrompt follows the fundamental principles and structure of the BERT model (Devlin et al., 2018) while adapting and extending it within the framework of prompt learning. The core of the BERT model is the encoder part of the transformer, which comprises multiple encoder layers, each containing self-attention mechanisms and feed-forward neural networks. One of the primary attributes of BERT is its ability to generate bidirectional contextualized word embeddings, signifying that it considers the context of the entire sentence when processing each word. To learn deep language representations, the BERT model undergoes pre-training on an extensive corpus, including tasks like the masked language model (MLM) and next sentence prediction (NSP).
2.7.1 Attention calculationThe scalar product between the query vector (Q) and key vector (K) is computed, followed by scaling down of the result to prevent overly large attention scores, while a scaling factor (commonly the inverse square root of the key vectors’ dimension) is also factored in. The attention scores are then subjected to a softmax operation for normalization into attention weights. A weighted sum over the value vectors (V) is then performed using these weights, resulting in the final attention representation. The formulaic representation of self-attention is expressed as Eq. (3) and (4):
Self−attentionQ,K,V=softmaxQKTdkV.(4)In this context, X∈RL*dm symbolizes the embedding output obtained from the embedding module, where dm indicates the embedding dimension and L represents the input sequence’s length. Q, K, and V∈RL×dk correspond to the matrices of the query, key, and value, respectively. These matrices are derived from X through a linear transformation using WQ, WK, and WV, each existing in the real space Rdm*dk. Here, dk denotes the size of the query, key, and value vectors. dm and dk are both regarded as hyperparameters.
2.7.2 Multi-head attentionThe computation of the attention head specified by index “i” is as shown in Eq. (5), (6) and (7):
Qi=XWiQ,Ki=XWiK,Vi=XWiV,i=1,⋯,h,(5)Headi=Self−attentionQi,Ki,Vi(6)MultiHead−AttentionQ,K,V=ConcactHead1,Head2,⋯,HeadhWO.(7)WiQ, WiK, and WiV∈Rdm×dk are the query, key, and value matrices for the i-th head, respectively. The parameter ‘h’ denotes the count of heads. The multi-head attention is used for Q, K, and V by concatenating ‘h’ individual heads, with each performing self-attention relevant to the input sequence. Furthermore, Wo∈Rdm×dk acts as a linear transformation matrix, adjusting the dimensions of the multi-head attention’s output to align with the input dimensions of the encoder block. This enables a skip connection, where the input for the encoder block is linked to the output from the multi-head attention mechanism.
In OpenPrompt, the BERT model is commonly used with templates and verbalizers. Prompt templates are designed to construct input formats suitable for processing by BERT. In contrast, prompt verbalizers are used to map the output of models to specific task labels by leveraging the advanced language understanding capabilities of the BERT model, which can strengthen the function of OpenPrompt models within a variety of NLP tasks.
3 Performance metricsThe performance of the iDNA-OpenPrompt model, along with other DNA methylation recognition models (Zeng and Liao, 2021; Li F. et al., 2023; Li Q. et al., 2023), is evaluated using the following five commonly used metrics: accuracy (ACC), sensitivity (SN), specificity (SP), Matthews’ correlation coefficient (MCC), and area under curve (AUC). The equations for these measurements are expressed below Eq. 8 to Eq. 12:
MCC=TP×TN−FP×FNTP+FNTP+FPTN+FPTN+FN,(11)AUC=∑i∈posranki−numposnumpos+12numposnumneg.(12)Here, TP, FN, TN, and FP denote the counts of true positive, false negative, true negative, and false positive instances, respectively. ACC and MCC are both used for gauging the model’s comprehensive performance. SN pertains to the ratio of accurately predicted samples correctly identified as methylated with the predictor, while SP quantifies the proportion of accurately predicted non-methylated samples with the predictor. The AUC is determined as the region enclosed between the receiver operating characteristic (ROC) curve and the coordinate plane, where the false positive rate (FPR) is plotted on the x-axis, and the true positive rate (TPR) is plotted on the y-axis. In total, an increase in these metrics signifies an improved model performance.
4 Results4.1 The visualization of UMAP for samples of iDNA-OpenPromptTo visually demonstrate the iDNA-OpenPrompt’s performance, Uniform Manifold Approximation and Projection (UMAP) (Junru et al., 2022) displays the distribution of samples with and without methylation sites. UMAP is a sophisticated non-linear method for reducing dimensionality that effectively maps high-dimensional data into a more manageable two-dimensional space, preserving local and global data point structures.
As seen in Figure 3, blue corresponds to non-DNA methylation (negatives), while red corresponds to DNA methylation (positives). The figures of (a-1) and (b-1) display the visualization of DNA methylation and non-methylation sequence samples without model processing; positive and negative samples appear mixed. The figures of (a-2) and (b-2) exhibit the visualization of DNA methylation and non-methylation sequence samples after iDNA-OpenPrompt model processing; and the positive and negative samples distinctly separate into well-defined groups. This separation visually confirms the model’s capacity to differentiate between DNA methylation and non-DNA methylation samples effectively.
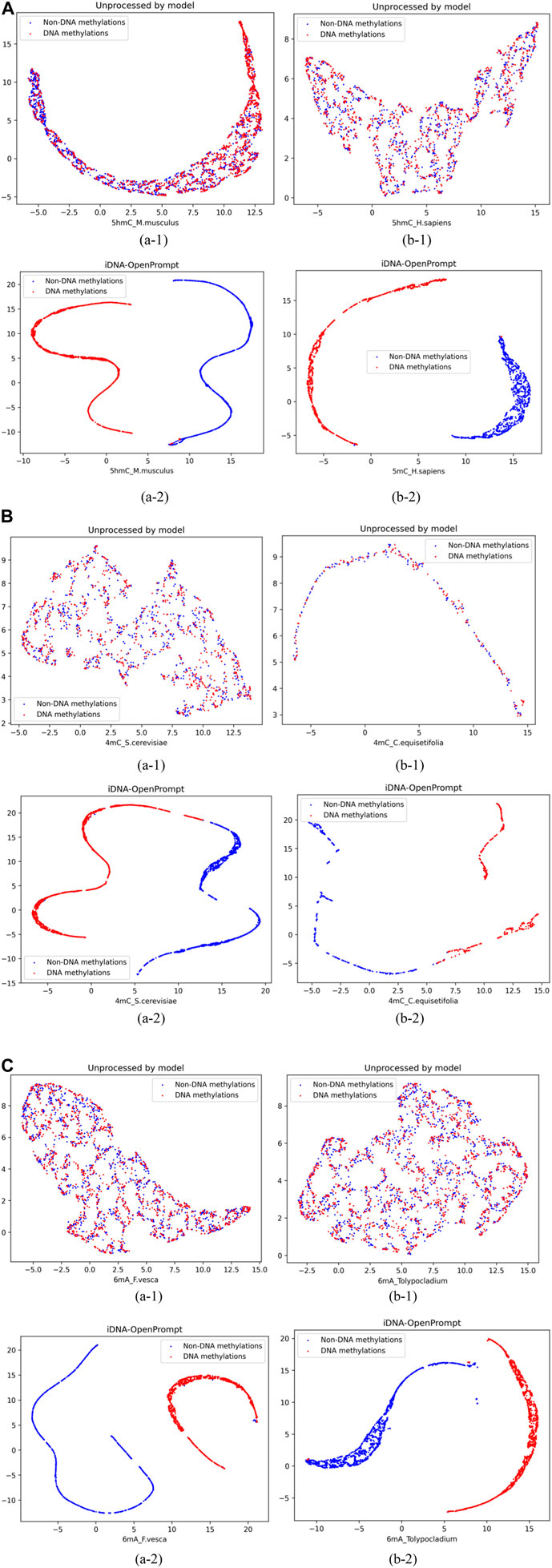
Figure 3. Representing samples before and after using the iDNA-OpenPrompt model with UMAP. (A) UMAP visualization of samples before and after processing with the iDNA-OpenPrompt model for the species 5hmC_M.musculus and 5hmC_H.sapiens. (B) UMAP visualization of samples before and after processing with the iDNA-OpenPrompt model for the species 4mC_cerevisiae and 4mC_C.equisetifolia. (C) UMAP visualization of samples before and after processing with the iDNA-OpenPrompt model for the species 6mA_F.vesca and 6mA_Tolypocladium. In Panels (A–C) (a-1) and (b-1) show the samples before processing with the model, while (a-2) and (b-2) show the samples after processing with the model.
4.2 Comparison of iDNA-OpenPrompt’s performance with other outstanding methodsTo evaluate the performance of iDNA-OpenPrompt, the comparative study is conducted against four outstanding predictors, including iDNA-ABT (Yingying et al., 2021), iDNA-ABF (Junru et al., 2022), iDNA-MS (Lv et al., 2020), and MM-6mAPred (Pian et al., 2020). iDNA-ABT, iDNA-ABF, and iDNA-MS are designed for various methylation prediction tasks, whereas MM-6mAPred was initially tailored for 6-mA site prediction. This comparison highlights iDNA-OpenPrompt’s adaptability and its capability, not just limited to 6 mA but also extending to 5hmC and 4 mC. Each of these predictors is independently trained on 17 distinct training datasets encompassing three methylation types, and then, its corresponding test dataset is evaluated (details are provided in Table 1). The outcomes, encompassing metrics such as ACC, SN, SP, AUC, and MCC, are depicted in Figure 4A–E. The data clearly show that the proposed model consistently surpasses the performance of four other exceptional predictors across all 17 datasets. The effectiveness of the proposed model can be attributed to its utilization of the OpenPrompt learning framework, which has proven to be highly effective in enhancing its performance, along with the outstanding performance of the prompt template and prompt verbalizer specifically designed for DNA methylation sequences.
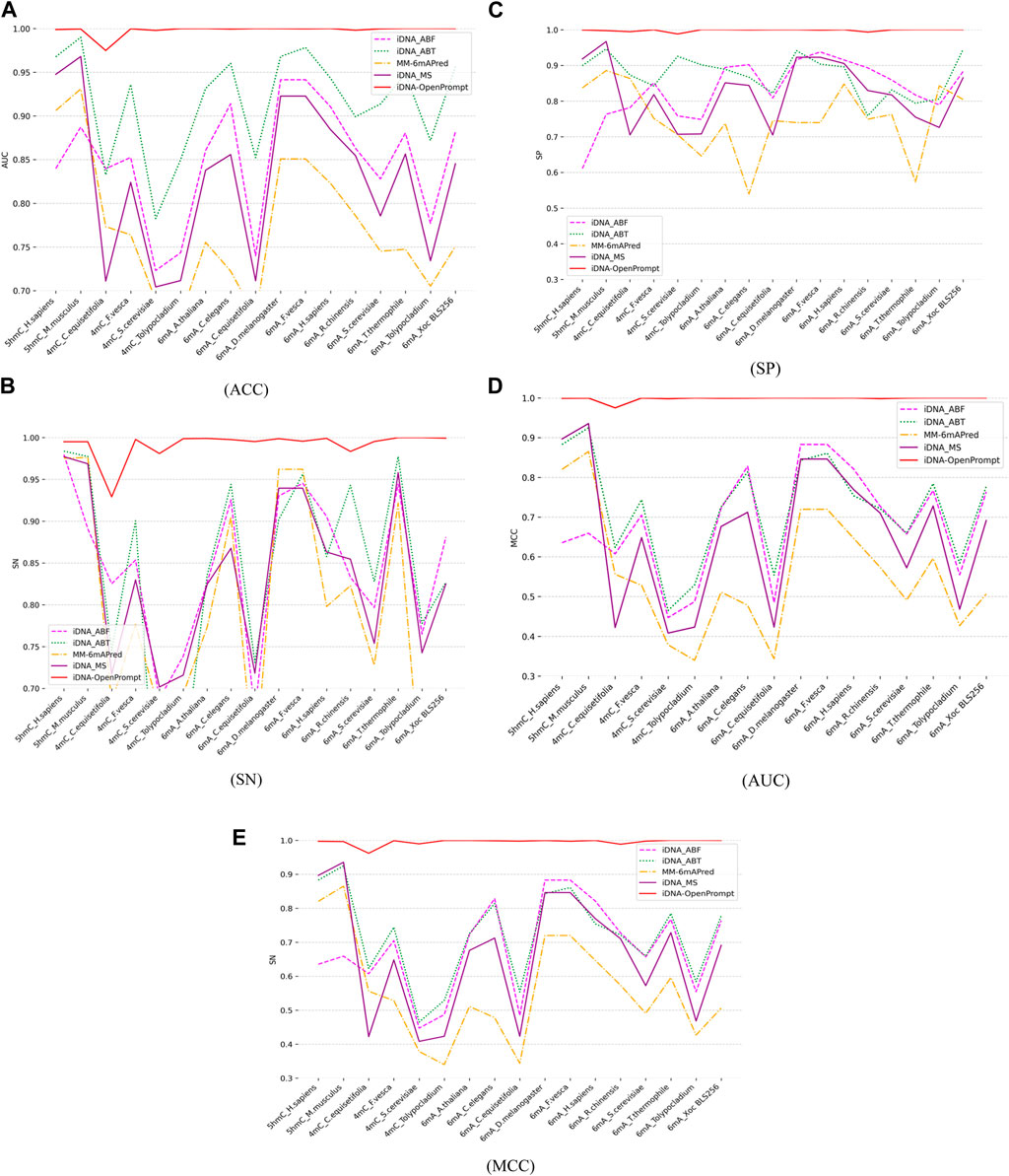
Figure 4. Comparing Performance of iDNA-OpenPrompt with other outstanding methods. (A) the ACC of iDNA-OpenPrompt with other outstanding methods, (B) the SN of iDNA-OpenPrompt with other outstanding methods, (C) the SP of iDNA-OpenPrompt with other outstanding methods, (D) the AUC of iDNA-OpenPrompt with other outstanding methods, (E) the MCC of iDNA-OpenPrompt with other outstanding methods. The evaluation metrics displayed above (ACC, SN, SP, AUC, MCC) are the results of testing the iDNA-OpenPrompt, iDNA-ABT, iDNA-ABF, iDNA-MS, and MM-6mAPred models on datasets of 17 species.
4.3 Successful cross-species validation resultsTo assess the proposed model’s adaptability across different species, it is imperative to gauge a model’s ability to be trained on data from one species and then used to detect modification sites in others. With this goal in mind, we have developed distinct models, each customized for a specific species; the effectiveness of these models is ascertained by applying them to other species for 4mC, 5hmC, 6mA modification. The outcomes of this validation procedure across different species are visually represented in Figure 5.
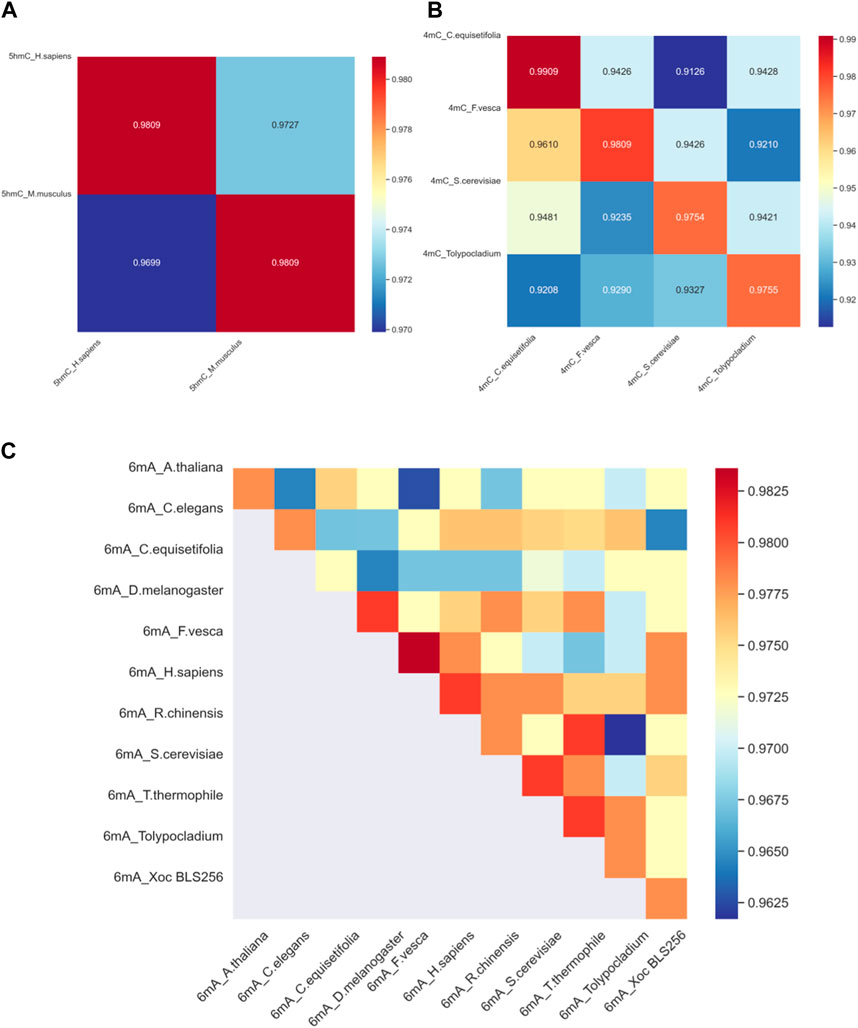
Figure 5. The heat map of cross-validation. (A) The cross-validation accuracy results for DNA methylation 5hmC in two species. (B) The cross-validation accuracy results for DNA methylation 4mC in four species. (C) The cross-validation accuracy results for DNA methylation 6mA in eleven species. In the figures, the species datasets indicated on the horizontal axis are used for training, and the species datasets indicated on the vertical axis are used for testing.
Considering the significant discrepancy in the quantity of training and testing samples for various species, with some species having only a few hundred samples and others reaching over a hundred thousand, we aim for fairness in cross-validation. Therefore, from the datasets of all species, we randomly selected 365 samples for the model’s cross-validation. This selection comprised 183 positive samples and 182 negative samples. The cross-validation outcomes are depicted in Figure 5.
Figure 5A reveals the results of cross-species validation of 5hmC_H. sapiens and 5hmC_M. musculus. Specifically, the accuracy rate attained for 5hmC_H: sapiens and 5hmC_M. musculus is 98.09%, underscoring the success of the proposed method. Figure 5C reveals that in the 6mA_R.chinensis model’s cross-validation, the accuracy for 6mA_R.chinensis is less than that for 6mA_T.thermophile indicates suboptimal results. However, the cross-validation of other species was performed satisfactorily. We can confidently deploy the proposed model, assuring its high-quality performance in identifying DNA methylation sites across different species, indicating that the proposed model has strong cross-validation performance.
4.4 The impact of the DNA vocabulary and label_words on model accuracyTo verify the algorithm’s effectiveness proposed in this article, the length of the DNA vocabulary library in the prompt template and the nucleotide length of the words in the label_words of the prompt verbalizer are changed to test their impact on the proposed model. In the following experiments, the nucleotide length in the DNA vocabulary refers to the length, encompassing all possible combinations of nucleotides ranging from 1, 2, …, up to that maximum length. For instance, if the nucleotide length is 6, then the DNA vocabulary includes nucleotide words that contain all combinations of nucleotides with lengths of 1, 2, 3, 4, 5, and 6.
4.4.1 The impact of the number (length) of nucleotides in the DNA vocabulary library on the modelBy changing the length of the nucleotide vocabulary in the DNA vocabulary while keeping the nucleotide length of the words in the label_words of the prompt verbalizer at 6, tests are conducted on all species across three categories (4mC, 5hmC, 6mA) with the nucleotide numbers (lengths) of individual words in the DNA vocabulary library being 2, 3, 4, 5, 6, 7, and 8. The test results show that, with the nucleotide length of the words in the label_words of the prompt verbalizer unchanged, the highest model accuracy is achieved when the number of nucleotides of individual words in the DNA vocabulary is 6. Taking the 4mC species as an example, the model’s accuracy is illustrated in Figure 6.
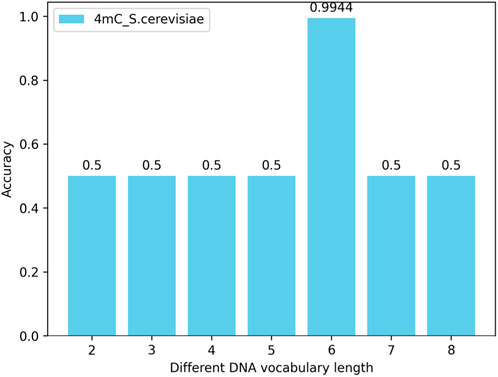
Figure 6. Impact of the number (length) of nucleotides in the DNA vocabulary library on the iDNA-OpenPrompt model.
4.4.2 The impact of the number (length) of nucleotides in the label_words of the prompt verbalizer on the modelIn this experiment, by changing the length of the nucleotide vocabulary in the label_words of the prompt verbalizer while keeping the nucleotide length of the words in the DNA vocabulary of prompt template at 6, tests are conducted on all species across three categories (4mC, 5hmC, 6mA) with the nucleotide numbers (lengths) of individual words in the label_words being 2, 3, 4, 5, 6, 7, and 8. The test results indicate that, with the nucleotide length of the words in the DNA vocabulary of the prompt template unchanged, the highest model accuracy is achieved when the number of nucleotides of individual words in the label_words of the prompt marker is 6. Taking the 6mA_F.vesca species as an example, the model accuracy is illustrated in Figure 7.
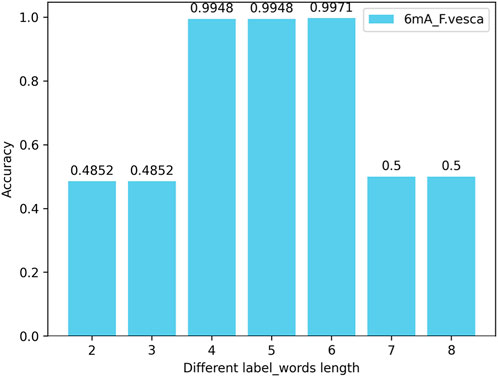
Figure 7. Accuracy of the number (length) of nucleotides in the label_words of the prompt verbalizer on the iDNA-OpenPrompt model.
4.4.3 The accuracy of simultaneously changing the DNA vocabulary library and label_words of the iDNA-OpenPrompt modelIn this experiment, the extent of their impact on model performance is assessed by modifying the length of nucleotide vocabularies in both the DNA vocabulary of the prompt template and within the label_words of the prompt verbalizer. When the maximum length of nucleotide vocabularies in the DNA vocabulary and within the label_words is set to 2, 3, 4, 5, 6, and 7 for testing across multiple species within three methylation categories, the results reveal that the model’s accuracy peaked when both the maximum nucleotide vocabulary length in the DNA vocabulary and the nucleotide length within the label_words are 6. The performance does not improve further when the lengths are extended to 7, and the risk of overfitting the model increases when both lengths reach 8. Taking the 6mA species as an example, the model’s accuracy across various maximum lengths of nucleotide vocabularies in the DNA vocabulary and within the label_words of the prompt marker is illustrated in Figure 8.
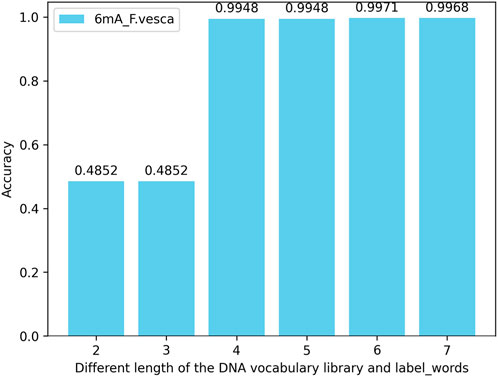
Figure 8. Accuracy of simultaneously changing the DNA vocabulary library and label_words of the iDNA-OpenPrompt model.
5 ConclusionThe proposed iDNA-OpenPrompt model used the innovative OpenPrompt learning approach and combines a prompt template, prompt verbalizer, and PLM to construct the prompt learning framework. Moreover, a DNA vocabulary library, BERT tokenizer, and specific label words are also introduced into the model to enable accurate identification of DNA methylation sites. An extensive analysis is conducted to evaluate the model’s predictive capability, reliability, and consistency of the iDNA-OpenPrompt model. The experimental outcomes, covering 17 benchmark datasets that include various species and three distinct DNA methylation modifications, namely, 4mC, 5hmC, 6mA, consistently indicate that our model surpasses existing outstanding approaches regarding performance and robustness. The limitation to this model lies in that the DNA vocabulary in the prompt template is manually generated, and applying bioinformatics to other RNA sequences or other biological information sequences requires manual generation of their vocabularies anew. In future work, making vocabulary generation automatic and adaptable to other biological information sequences is one of the future research directions.
Data availability statementPublicly available datasets were analyzed in this study. These data can be found at: https://github.com/Yyxx-1987/iDNA-OpenPrompt/tree/master/iDNA-OpenPrompt.
Author contributionsXY: methodology, software, validation, visualization, and writing–original draft. JR: formal analysis, investigation, resources, writing–review and editing, and conceptualization. HL: funding acquisition, methodology, validation, writing–review and editing, and visualization. RZ: data curation, methodology, and writing–review and editing. GZ: investigation, visualization, and writing–review and editing. AB: writing–review and editing. YC: data curation, investigation, methodology, and writing–review and editing.
FundingThe author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work is supported by the National Natural Science Foundation of China (No. 62302132, No. 62262016, No. 61961160706, No. 62262018, No. 62262019), 14th Five-Year Plan Civil Aerospace Technology Preliminary Research Project (D040405), the Hainan Provincial Natural Science Foundation of China (No. 823RC488, No. 623RC481, No. 620RC603, No. 721QN0890, No. 621MS038), the Program of Hainan Association for Science and Technology Plans to Youth R & D Innovation (QCQTXM202209), the Project supported by the Education Department of Hainan Province (Hnky2024-18).
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesDai, C., Jiang, Y., Yin, C., Su, R., Zeng, X., Zou, Q., et al. (2022). scIMC: a platform for benchmarking comparison and visualization analysis of scRNA-seq data imputation methods. Nucleic Acids Res. 50 (9), 4877–4899. doi:10.1093/nar/gkac317
PubMed Abstract | CrossRef Full Text | Google Scholar
Ding, N., Hu, S., Zhao, W., Chen, Y., Ding, Z., Zheng, H. -T., et al. (2021). Openprompt: an open-source framework for prompt-learning. Available at: https://arxiv.org/abs/2111.01998. doi:10.48550/arXiv.2111.01998
留言 (0)