
記住我

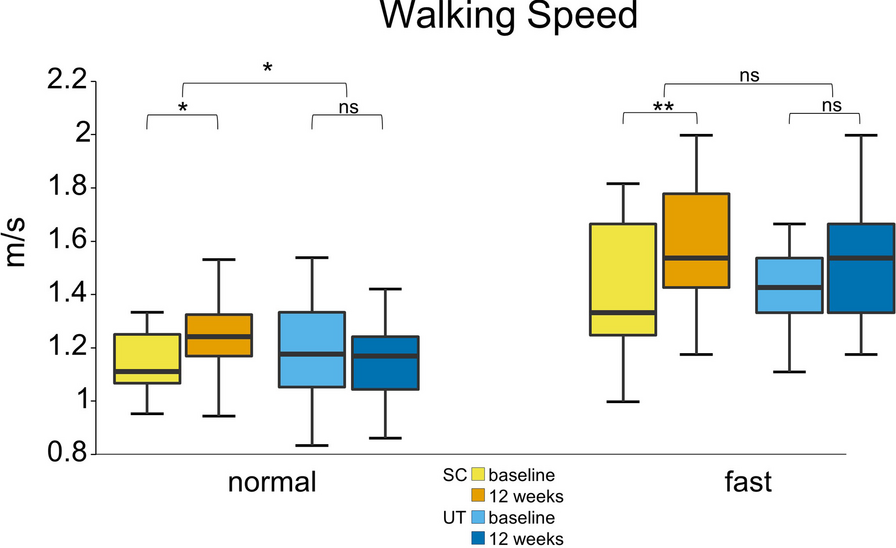


The experiments were conducted with the participation of five healthy subjects who did not report any known diseases or movement impairment and had no prior experience with BMI systems (mean age, 22.6 ± 3.05). Prior to the experiments, the participants were informed about the study and provided written informed consent. All the procedures were approved by the Institutional Review Board of the University of Houston, TX (USA), with study ID: STUDY00003848.
EquipmentDuring the experiments, EEG signals were recorded using 32 wet electrodes positioned over an actiCAP (Brain Products GmbH, Germany). Two additional electrodes, serving as ground and reference, were located on the ear lobes. Electrodes were placed following the 10–10 distribution, with four electrodes used for recording electrooculography (EOG), arranged in a cross shape with respect to the eye with the vertical ones around the left eye. The data were wirelessly transmitted using a WiFi MOVE unit (Brain Products GmbH, Germany) and amplified with BrainAmpDC (Brain Products GmbH, Germany).
The REX exoskeleton (Rex Bionics, New Zealand) was utilized for the experiments. This exoskeleton is capable of independently supporting both itself and the weight of the subject, making it suitable for individuals with complete spinal cord injury. It is comprised of powered hip, knee and ankle joints (bilaterally). This self-standing exoskeleton does not require crutches and can be controlled by high-level commands sent via Bluetooth to initiate or stop the gait. Real-time feedback on the exoskeleton status was also provided during the experiments. Figure 1 shows the equipment employed in the experiments.
Fig. 1
Equipment employed in the experiments
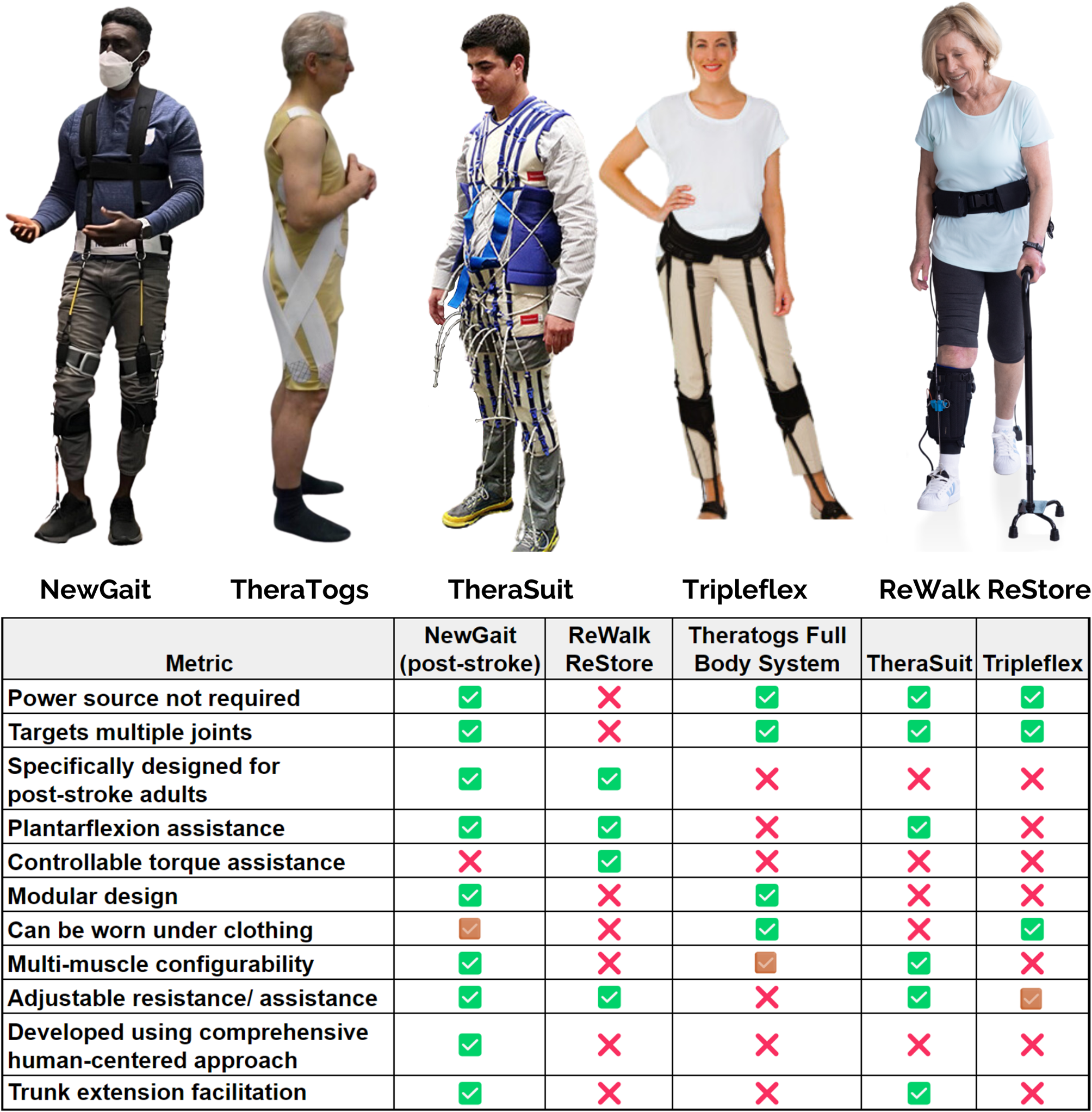
Experimental protocolIn the study, five experimental sessions were conducted by the participants to test a lower-limb exoskeleton (REX) system controlled by a BMI as shown in Fig. 2.
Fig. 2
Five subjects participated in five experimental sessions
First sessionIn the first session, participants were given an overview of the experimental protocol and asked to complete a consent form. An initial assessment was conducted to ensure that participants met the inclusion/exclusion criteria, see Additional file 1. They were also asked general questions about their current physical state. If they were eligible to participate, baseline measurements were taken to properly set up the brain cap and exoskeleton, including foot length and width, weight, height, lower limb lengths, and head size. Participants had the opportunity to gain some experience with the exoskeleton. No EEG recordings were accomplished during this first session.
Afterwards, the concept of kinesthesic and visual motor imagery were explained [28]. In addition, they received the Motor Imagery Questionnaire-3 (MIQ-3) to complete at home. Two different versions, Spanish or English, were provided depending on the subjects’ mother tongue [29, 30]. The MIQ-3 is a 12-item questionnaire designed to evaluate the individual’s capacity to mentally visualize four specific movements using internal visual imagery, external visual imagery, and kinesthetic imagery. Kinesthetic motor imagery refers to the cognitive capacity to mentally simulate the execution of a physical action by generating a vivid perception of the muscular contractions and sensations that accompany the actual movement. In contrast, visual motor imagery involves the ability to create a mental representation of the desired movement. During the following sessions, participants were instructed to perform only kinesthetic motor imagery since it produces more similar brain patterns as motor execution and therefore, it promotes mechanisms of neuroplasticity that induces motor rehabilitation [31].
Second and third sessionIn the second and third session, participants wore the EEG equipment and lower-limb exoskeleton and walked with it for 30 min while being commanded by an external operator/researcher before the real experiment began. This preliminary phase aimed to acquaint participants with the device prior to commencing the actual experimental tasks. The operator sent commands from a computer to the exoskeleton via Bluetooth to start or stop the gait at certain periods, with participants being given an acoustic cue beforehand.
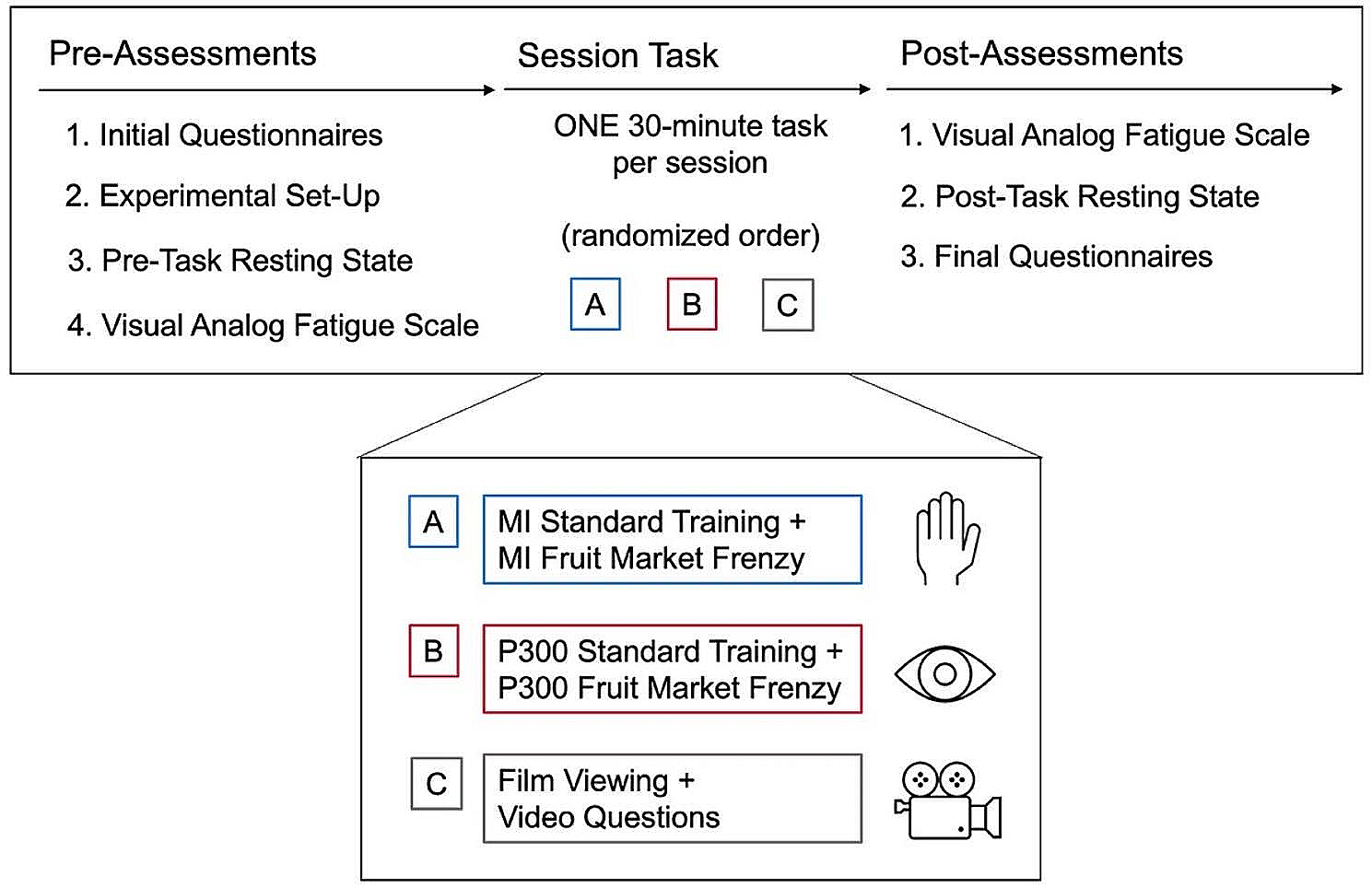
After becoming familiar with the device, training with the BMI and the lower-limb exoskeleton began, which is also referred as calibration. Participants performed 14 trials with the exoskeleton in open-loop control, during which they engaged in a series of mental practices including idle state and kinesthetic motor imagery. The sequence of tasks is shown in Fig. 3.
Fig. 3
BMI calibration. It involved the training phase, during which participants completed a total of 14 trials involving specific mental tasks. Half of these trials were conducted under full static conditions (blue), where participants stood still with the exoskeleton, while the other half involved walking assisted by the exoskeleton during the whole trial (orange). The trials conducted under static and motion conditions followed a similar structure. Each trial started with a 15-s period to allow the convergence of the denoising algorithms. Subsequently, an acoustic cue signaled the initiation of the idle state, during which participants were instructed to relax. Following this, another cue indicated the onset of the motor imagery period. Notably, the motor imagery task differed between static and motion trials. In the static trials, participants were instructed to imagine the act of walking, whereas in the motion trials, the task involved imagining the action of stopping the gait. Specifically, this stopping action was defined as bringing the legs together after completing a step
During half of the trials, participants stood still with the exoskeleton, and during the other half, they walked. The lower-limb exoskeleton was controlled the whole time by the predefined open-loop controlled periods. These procedural steps were implemented to facilitate the development of a dual-state BMI, specifically comprising two distinct models: Static and Motion, which were then used in the closed-loop control phase.
Fourth and fifth sessionIn the fourth and fifth sessions, participants were first fitted with EEG equipment and lower-limb exoskeleton. They then walked with the exoskeleton for a period of 30 min, which was controlled by an external operator/researcher before the actual experiment began.
Following this, the participants underwent training with a BMI in the same manner as in the second and third sessions. However, after the training, the BMI was updated with data specific to each participant and session, and it was then tested in closed-loop control as shown in Fig. 2.
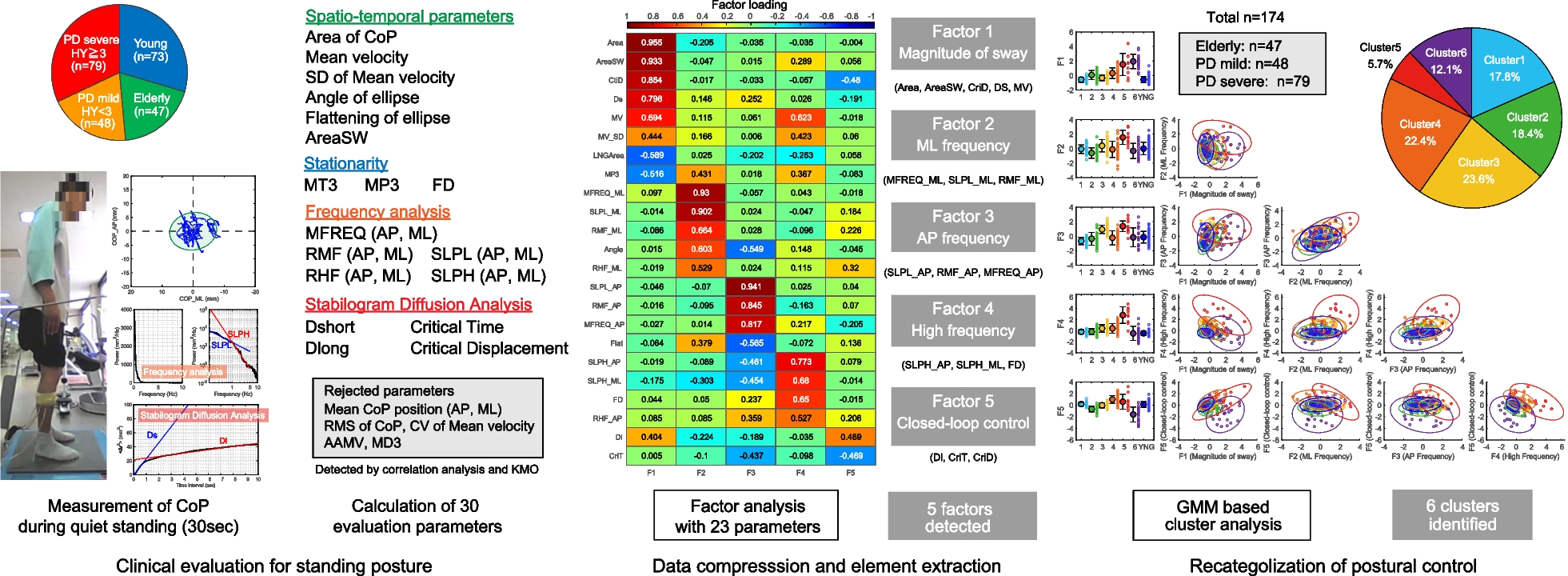
To test the BMI, participants walked along a straight path that had five lines marked on the floor. The yellow lines marked the areas in which the subject should begin walking, while the red lines marked the areas in which they should stop. Participants had to perform various mental tasks to make the exoskeleton move or stop. They were trained during the previous sessions to imagine themselves during two different classes (MI and idle state) and in two different states (Static and Motion): static motor imagination for starting the gait vs. static in an idle state to remain standing still; and motion in an idle state to continue walking vs. motion motor imagination for stopping the gait. A diagram of the path is shown in Fig. 4. They performed five test trials and in each of them they had to go through the whole move/stop areas path. This protocol was designed as an asynchronous control, so subjects decided when to begin each mental task trying to reach the different stop areas keeping the exoskeleton in motion up to them.
Fig. 4
Asynchronous closed-loop control. During this phase, participants engaged in five trials where they utilized their thoughts to control the lower-limb exoskeleton. The experimental setup involved navigating through a pathway that was divided into distinct regions: MOVE areas marked by yellow lines and STOP areas demarcated by red lines. Within the MOVE areas, participants were required to engage in motor imagery of the gait until a command was sent to the exoskeleton, initiating the walking motion. To maintain the gait, participants were instructed to maintain an idle state until they reached the STOP area. Upon entering the STOP area, participants were tasked with performing a single stop. This involved mentally imagining the movement of stopping the gait. Participants were required to sustain this mental task until a command was issued to the device or until they exited the STOP area and reentered a MOVE area. Failure to execute a stop within the designated STOP area constituted an unsuccessful attempt
As mentioned above, two models were trained with data from training phase: Static model was trained only with the trials in which subjects were standing still, and Motion model was trained only with trials in which subjects were walking assisted by the exoskeleton. They were utilized for the control process as a dual-state machine. The Static model had the purpose of preserving the exoskeleton in a stationary position and detecting the initiation of gait. However, once the exoskeleton started its movement, the control mechanism of BMI shifted to the Motion model. This model effectively controlled the continuous motion of the exoskeleton until a desire to halt its progression was detected. Upon such detection, the control model was switched to the Static model again. Figure 4 shows a schema of this dual-state control.
Brain–machine interfaceDeep learningEEGNet [32] was used in the experiments. This network combines the principles of temporal, frequency and spatial features that were manually computed in traditional approaches. This framework starts with a temporal convolution to learn specific frequency filters that highlight relevant brain rhythms. It is followed by a depthwise convolution in spatial dimension that learns a spatial filter for each filtered signal from the previous layer. Finally, the separable convolution is a combination of a depthwise convolution that learns a temporal summary from each spatially filtered signal from the previous step, and a pointwise convolution that combines all features in the most discriminant way. This network was preferred for this experiment due to its relatively low number of trainable parameters as compared to other frameworks present in the literature, such as DeepConvnet [18]. The network hyper-parameters are shown in Table 1.
Table 1 EEGNet hyper-parametersTwo networks were trained, one with static trials (Static model) and one with trials in motion (Motion model). The Static model’s input data consisted of 2 s epochs of the pre-processed EEG signals of 27 channels sampled at 200 Hz. Each epoch was shifted at a 0.5 s pace, so they were overlapped 1.5 s. Pre-processing involved applying a Notch filter at 60 Hz to remove the contribution of the power line and a high-pass filter at 0.1 Hz to reduce DC offset. A denoising algorithm was employed using the four EOG channels to estimate the contribution to each EEG channel and mitigate the artifact contribution [33]. The following step was to apply a common average reference (CAR) spatial filter [34], to enhance the activity of each electrode by subtracting the mean from all of them for every time point. Finally, a band-pass filter was applied between 8 and 40 Hz to focus on alpha, beta and low gamma rhythms [19].
For the Motion model, input data were pre-processed in the same window size and sliding window, but with a slightly different method. The first steps till CAR spatial filter were the same. However, the following steps were a band-pass filter between 1 and 100 Hz [17], and signals were normalized [14]. The selection of pre-processing approaches was guided by the findings of our prior research [35], which identified the approach that yielded the most favorable outcomes.
In this study, we conducted a comparative analysis of three distinct training sub-approaches for both static and motion networks. The selection of the optimal approach for closed-loop control was based on the results obtained from an open-loop evaluation pseudo-online, which means they were evaluated post hoc after the completion of all the sessions simulating a real-time prediction system. The three sub-approaches investigated were: (1) a generic model, (2) a generic model fine-tuned to individual subject and session data, and (3) a generic model fine-tuned to individual subject and session data with a focus on the last three layers.
To elucidate the training and evaluation procedures, Fig. 5 provides a visual representation of the following:
1.Deep learning with generic model:
2.Deep learning with generic model and fine-tuning:
The generic model was initially trained with data from sessions 2 and 3 from all subjects.
In session 4, fine-tuning involved 12 training trials and 2 evaluation trials. This process was iterated, with each trial serving as evaluation once and remaining ones for fine-tuning parameters (static model: 6 fine-tuning and 1 evaluation, motion model: 6 fine-tuning and 1 evaluation).
Similar procedures were applied in session 5. Therefore, the generic model was adapted to each subject and session.
3.Deep learning with generic model and fine-tuning last three layers only:
Similar to the previous model, training and evaluation were conducted using data from sessions 2, 3, 4, and 5.
However, fine-tuning focused exclusively on the last three layers of the generic model.
Fig. 5
Visual representation of the training and evaluation procedures
The second alternative showed the highest results (it can be seen in “Results”), and thus these models were used in the closed-loop evaluation during the fourth and fifth sessions.
Features-based approachThe three deep learning sub-approaches aforementioned were compared against a baseline approach that is feature-based and commonly used for BMI [36,37,38]. Pre-processing of signals was performed differently for the features-based approach than for neural networks. Firstly, a Notch filter was applied at 60 Hz to remove power line noise, followed by a high-pass filter at 0.1 Hz to reduce the DC offset. The same EOG denoising algorithm employed in deep learning was then applied, as previously described [33]. Subsequently, four band-pass filters were applied at 5–10, 10–15, 15–20 and 20–25 Hz, consistent with our previous works [36, 37]. The next step involved computing CSP for each frequency band. The goal of CSP was to calculate spatial filters that linearly transform the signal from each channel to maximize differences between two mental tasks, in this case, between MI of gait and idle state for both models, static and motion. The signals from 27 electrodes were filtered, and only the eight most discriminant new components were selected as features. The log-variance was computed for all of them, resulting in a vector of 32 features (8 × 4 frequency bands). Linear discriminant analysis (LDA) was trained with these features to distinguish between the two classes: MI and idle state.
The training and evaluation of this approach are illustrated in Fig. 5. In session 4, 12 trials were used to train the model and 2 for evaluation. This process was repeated, using all trials for evaluation once (static model: 6 training and 1 evaluation, motion model: 6 training and 1 evaluation). The same procedure was applied in session 5. Data from sessions 2 and 3 were not included in training the model because CSP has previously shown poor generalization and higher performance when trained with each subject and session’s data [38, 39].
EvaluationThe efficacy of the BMI was evaluated using a set of defined metrics. The evaluation encompassed both training data and closed-loop trials, providing a comprehensive assessment of the system capabilities. The following metrics were employed:
1.Evaluation of training data (open-loop pseudo-online): cross-validation was performed and the accuracy was measured as the percentage of epochs with correct classification during trials, both in static and motion conditions.
2.Evaluation of closed-loop trials:
Average time to Start: This metric quantified the duration, measured in seconds, that subjects required to send a START command to the exoskeleton while in a static state and performing MI. Notice that as the starting moment of the imagination is marked by the subject will, a high value does not mean a bad evaluation. However, an excessive time could be considered as a timeout.
Average time to Stop: This metric measures the time, in seconds, participants took to issue a STOP command to the exoskeleton while in motion, providing insights into the promptness of their response.
Timeout: In cases where participants were unable to send a START command within 60 s, the trial was considered a timeout. Additionally, if the subject made eight attempts to activate the exoskeleton but failed to reach the end of the path, it was also categorized as a timeout. This metric captured the number of trials that resulted in a timeout.
Accuracy to Start (%): This percentage reflected the frequency at which subjects successfully sent a START command without experiencing a timeout. It indicated the proficiency of subjects in initiating the desired actions within the given time-frame.
Accuracy to Stop (%): This metric measured the success rate of subjects in stopping the exoskeleton within the designated STOP areas along the five testing trials. The presence of two STOP areas allowed for the calculation of a percentage. If subjects managed to make a stop in both areas, it would be considered 100% accuracy, while a single stop corresponded to a 50% accuracy for the trial. A value of 0% indicated that the exoskeleton failed to stop at all.
Ratio of Stops (%): This ratio provided insights into the quality of the stops made by the device. It measured the proportion of successful stops with respect to the total number of stops performed.
留言 (0)