
記住我



Our dataset was built using 13,200 panoramic radiographs acquired from patients who underwent dental imaging at the Seoul National University Dental Hospital between 2017 and 2021 in South Korea. This study was approved by the Institutional Review Board of Seoul National University Dental Hospital (ERI23025). The ethics committee approved the waiver of informed consent because this was a retrospective study. The study was performed following the Declaration of Helsinki. Panoramic radiographs were acquired using OP-100 (Instrumentarium Dental, Tuusula, Finland), Rayscan alpha-P (Ray, Seoul, South Korea), and Rayscan alpha-OCL (Ray, Seoul, South Korea) under conditions of tube energy of 73 kVp and tube current of 10 mA.
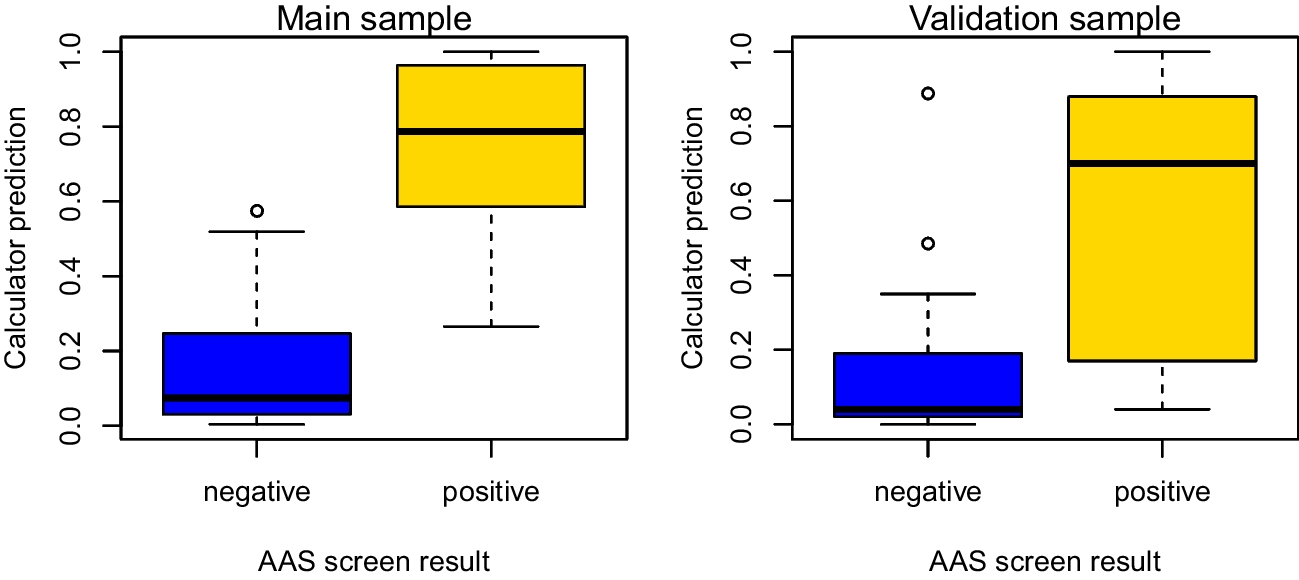
The collected panoramic radiographs were unfiltered real-world data. We excluded only low-quality images caused by artifacts (the patient’s earrings, removable prosthesis, etc.), inadequate anatomical coverage, patient positioning errors, and pre-and post-processing errors (noise, enhancement errors, abnormal density, and contrast) [31]. Representative samples of patients aged 15–80 years from our dataset are shown in Fig. 1. Our dataset included panoramic radiographs acquired from patients with alterations, dental implants, caries, bridges, fillings, retainers, missing teeth, or crowns. However, the exclusion criteria were as follows: edentulous patients, patients undergoing orthodontic treatment, patients undergoing orthognathic surgery, maxillofacial reconstruction patients, and patients with large intraosseous lesions.
Fig. 1
Examples of panoramic radiographs of males or females aged 15–80 years
Each panoramic radiograph was labeled with the specific sex and chronological age of the patient. Our dataset has the same distribution of sex and chronological age, with approximately equal numbers of images for each sex and age group. The datasets were randomly separated into training, validation, and test sets, where each set consisted of the same distribution of sex (male and female) and chronological age (15–80 years old). The splitting ratio was 3:1:1, and each set contained 7920, 2640, and 2640 images [32]. The dataset consists of high-resolution 8-bit panoramic radiographs. The heights of the panoramic radiographs ranged from 976 to 1468 pixels, while the widths ranged from 1976 to 2988 pixels. For the network training, the images were resized to 480 \(\times\) 960 pixels.
The minimum sample size was estimated to detect significant differences in accuracy between ForensicNet and the other networks when both assessed the same subjects (panoramic radiographs). Sample size calculation was designed to capture a mean accuracy difference of 0.05 and a standard deviation of 0.10 between the ForensicNet and other networks. Based on an effect size of 0.25, a significance level of 0.05, and a statistical power of 0.95, a sample size of 305 was obtained by G* Power (Windows 10, version 3.1.9.7; Universität Düsseldorf, Germany). The dataset of panoramic radiographs was split into 7920, 2640, and 2640 images for the training, validation, and test sets, respectively.
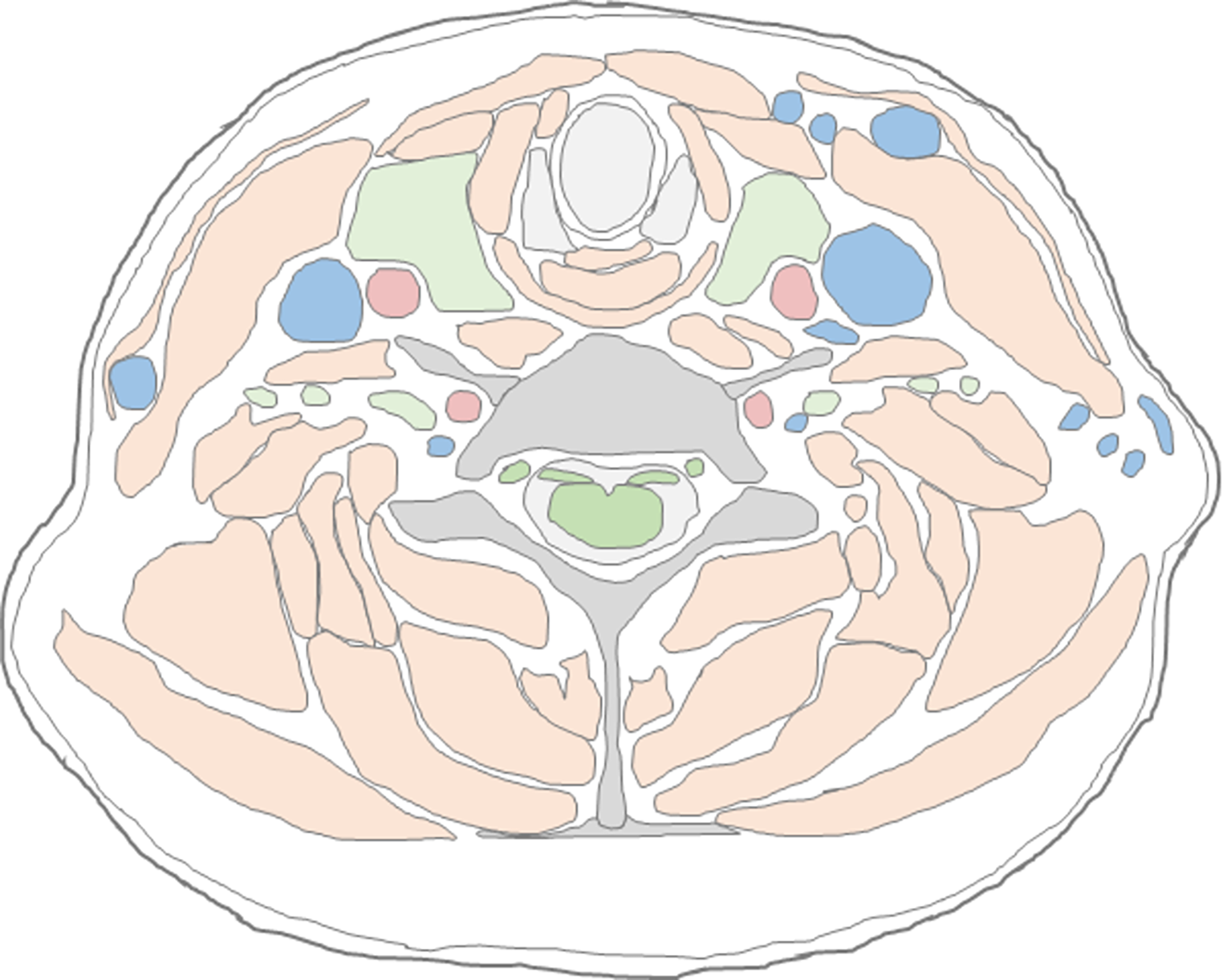
Proposed multi-task deep learning network (ForensicNet)The architecture of the proposed network, ForensicNet, consisted of a backbone, sex, and age attention branches (Fig. 2). Popular feature extraction networks such as VGG16 [33], MobileNet v2 [34], ResNet101 [35], DenseNet121 [36], Vision Transformer [37], Swin Transformer [38], Encoder of TransUNet (TransNet) [39], and EfficientNet-B3 [40] were used as backbones in ForensicNet.
Fig. 2
Overview of the proposed multi-task deep learning network (ForensicNet). ForensicNet consists of a backbone with age and sex attention branches. Each attention branch has a convolutional block attention module (CBAM) composed of channel and spatial attention modules. ForensicNet takes panoramic radiographs as inputs and simultaneously estimates sex and chronological age by each attention branch
VGG16 consists of 16 layers, including 13 convolutional layers with ReLU activation, 5 max-pooling layers, and 3 fully connected layers. VGG16 contains approximately 15.1 million trainable parameters [33]. MobileNet v2 is designed to implement the inference of deep networks with low computing power, such as mobile devices [34]. To design a lightweight model, MobileNet v2 uses depth-wise separable convolutions instead of standard convolutions. MobileNet v2 has approximately 4.7 million trainable parameters. A residual neural network, also called ResNet, adopts a residual learning method that employs the addition of a skip connection between layers [35]. This skip connection is an element-wise addition between the input and output of the residual block, without additional parameters or computational complexity. ResNet101 contained 48.8 million trainable parameters. The densely connected network DenseNet121 uses a cross-layer connection approach in each layer to solve the problem of the vanishing gradient. In the DenseNet121 architecture, the feature maps of each previous layer are used as inputs for all subsequent layers. DenseNet121 contains approximately 8.6 million trainable parameters [36]. Vision Transformer adapts the original Transformer architecture for use in computer vision [37]. It takes an input image by dividing it into non-overlapping patches and generating the linear embedding from these patches based on the linear projection. To include the location information of each patch, positional encodings are appended to this linear embedding. Subsequently, these embedding vectors are fed into a Transformer encoder. Vision Transformer contains approximately 87.0 million trainable parameters [37]. Swin Transformer is a type of Transformer architecture that has been specifically designed for computer vision tasks [38]. Swin Transformer applies shifted local windows in an image across different levels of detail, allowing the model to capture both local details and global context. Swin Transformer contains approximately 89.8 million trainable parameters [38]. TransNet is the encoder of TransUNet which combines the advantages of Transformer and convolutional neural networks (CNN) to improve segmentation performance by capturing both global and local features [39]. In TransNet, ResNet50 is used as a CNN-based encoder to extract high-level features. Then, high-level features are fed to the Transformer with self-attention layers to capture global contextual relationships. TransNet contains approximately 31.5 million trainable parameters [39]. EfficientNet is a state-of-the-art network that significantly outperforms other popular networks in classification tasks with fewer parameters and high model efficiency. EfficientNet employs a compound scaling method to efficiently adjust the width, depth, and resolution of a deep network. EfficientNet-B3 contains approximately 14.3 million trainable parameters [40].
On panoramic radiographs, anatomical structures are typically observed in different sizes and shape variations according to the sex and chronological age of the patients. To learn these features, a deep network must cover different scales of receptive fields to capture long-range relationships between anatomical structures. In this study, a CBAM [41] was embedded before each output layer in the sex and age attention branches of the proposed ForensicNet. The CBAM contained two submodules for channel and spatial attention (Fig. 2). An input feature map \(_\in }^\) are fed to the channel attention module (CAM) to obtain a 1D channel attention map \(_\in }^\) as follows:
$$_=\sigma \left(\text\text\text\right(\text\text\text\text\text\text\text\left(_\right)\left)\right)+\sigma \left(\text\text\text\right(\text\text\text\text\text\text\text\left(_\right)\left)\right)$$
(1)
,
where \(C\), \(H\), and \(W\) indicate channels, height, and width of a feature map, respectively. \(\sigma\), MLP, MaxPool, and AvgPool denote the Sigmoid activation function, shared multi-layer perceptron layers, a global max-pooling layer, and a global average-pooling layer, respectively. Then, a channel-attentive feature map \(_^}\in }^\) is acquired by:
,
where \(\otimes\) denotes element-wise multiplication. To obtain a spatial attention feature map \(_\in }^\), a channel-attentive feature map \(_^}\) is fed to the spatial attention module (SAM) as follows:
$$_=\sigma \left(^\left(\left[\text\text\text\text\text\text\text\left(_^}\right); \text\text\text\text\text\text\text\left(_^}\right)\right]\right)\right)$$
(3)
,
where \(\sigma\), \(^\), MaxPool, and AvgPool denote the Sigmoid activation function, a \(7\times 7\) convolution layer, a 2D max-pooling layer, and a 2D average-pooling layer, respectively. \(\left[\bullet \right]\) indicates channel-wise concatenation operation. Then, a spatial-attentive feature map \(_^}\in }^\) is obtained by:
,
where \(\otimes\) denotes element-wise multiplication. Finally, a spatial-attentive feature map \(_^}\)of CBAM combined with spatial and channel attention were fed to a global average pooling layer. CBAM can promote deep networks to focus on semantic information and effectively refine intermediate features.
To output multi-task classes for both sex and chronological age estimation in an end-to-end manner, sex and age attention branches were designed, where each branch comprised a CBAM, a global average pooling layer, and an output layer (Fig. 2). In the age attention branch, high-level feature maps from the backbone were fed to the CBAM to extract channel and spatial attentive feature maps. The channel and spatial attentive feature maps were then reduced to a one-dimensional vector using a global average pooling layer, and the vector was fed to an output layer with a linear activation function to estimate a continuous age value. The sex attention branch had the same structure as the attention branch, except for the activation function of the output layer, where sigmoid activation was used to classify a categorical sex value, such as male or female.
Weighted multi-task loss functionFor network training, a weighted multi-task loss (WML) function combined with MAE and binary cross-entropy (BCE) was proposed. The MAE measures the mean of the absolute difference between the ground truth and the estimated chronological age. The MAE is defined as
$$MAE\left(y,\widehat\right)=\frac_^\left|_-}_\right|}$$
(5)
,
where \(y\) and \(\widehat\) are the ground truth and estimated chronological ages, respectively. The \(N\) is the number of panoramic radiographs. The BCE measures the average probability error between the ground truth and the estimated sex. The BCE is defined as follows:
$$BCE\left(p, \widehat\right)=-_^_\left(}_\right)$$
(6)
,
where \(p\) and \(\widehat\) are the ground truth and estimated sex, respectively. \(N\) is the number of panoramic radiographs. The MAE was more difficult to minimize than the BCE for multi-task learning. Therefore, asymmetric weights \(\alpha\) and \(\beta\) for MAE and BCE were set in WML, respectively. Finally, the WML is defined as
$$WML=MAE\left(y,\widehat\right)+ \beta BCE\left(p, \widehat\right),$$
(7)
where \(\alpha\) and \(\beta\) are weight constants for MSE and BCE, respectively, and the \(\beta\)is calculated as \(\left(1-\alpha \right)\). Empirically, \(\alpha\) and \(\beta\) were set to 0.7 and 0.3 (Table 1), respectively.
Table 1 Performance comparison of sex and chronological age estimation by changing backbones in ForensicNetTraining environmentThe deep networks were trained for 200 epochs with a mini-batch size of 16. Data augmentation was performed with rotation (ranging from − 10° to 10°) and width and height shifts (ranging from − 10 to 10% of the image size) in the horizontal and vertical axes. Adam optimizer was used with \(_=0.9\) and \(_=0.999\), and a learning rate was initially set to 10−3, which was reduced by half up to 10−6 when the validation loss saturated for 25 epochs. The deep networks were implemented using Python3 based on Keras with a TensorFlow backend, using an NVIDIA TITAN RTX GPU of 24GB.
Evaluation metricsTo evaluate the estimation performance for sex and chronological age, the MAE, coefficient of determination (R2), maximum deviation (MD), successful estimation rate (SER), sensitivity (SEN), specificity (SPE), and accuracy (ACC) were used. The MAE is the mean of the absolute difference between the estimated and actual ages of a sample. R2 is a statistical measure of the fit of a regression model (measures the variations in the data explained by the model). Maximum Deviation (MD) is the highest deviation of the absolute difference between the estimated and actual ages, compared to their mean. SER is the percentage of successfully estimated ages in the ranges of 1-, 3-, 5-, 8-, and 10-year errors, and SEN is a metric that evaluates the ability of a model to estimate the true positives of each available category of sex. SPE is a metric that evaluates the ability of a model to estimate the true negatives of each available category of sex. ACC is the ratio of the number of correct sex estimations to the total number of input samples.
The impact of dataset size on the estimation of sex and chronological age was also evaluated. The training sets were expanded to include 2640, 5260, and 7920 images, respectively, while the validation and test sets were fixed. An analysis of variance test was performed to compare the estimation performances between the backbones in ForensicNet (PSS Statistics for Windows 10, Version 26.0; IBM, Armonk, New York, USA), and the statistical significance level (p-value) was set to 0.05.
To interpret the decision-making processes of a deep network, gradient-weighted class activation mapping (Grad-CAM) was used [42]. Grad-CAM is used to visualize the heatmap of the regions that the deep network focuses on when making an estimation. This method calculates the gradients of the target (here, an output layer to estimate sex and chronological age) and plugs them into a previous convolutional layer to provide a heatmap of the regions that contribute the most to the output decision.
留言 (0)