
記住我





Artificial intelligence's (AI) use of advanced algorithms and sophisticated neural networks enables the technology to rapidly analyze and interpret vast amounts of data. For example, Chat Generative Pretrained Transformer-4 (ChatGPT-4)—a publicly available, and user-friendly AI chatbot—recently performed near the passing threshold on the United States Medical Licensing Exam, a set of medical license examinations that tests expert-level knowledge, without specialized human input.1 The study suggests that with ChatGPT's clinical reasoning displayed on the United States Medical Licensing Exam, the chatbot could potentially assist in clinical decision-making and diagnosing.1 This has prompted investigations into ChatGPT's potential use as a supplemental tool for the diagnosis of health conditions. One study determined ChatGPT-3's diagnostic accuracy in physician-generated cases for 10 common internal medicine complaints to be 53.3%.2 Another investigation found that ChatGPT-4's diagnostic accuracy in New England Journal of Medicine complex case challenges to be 39%.3
ChatGPT has also been investigated for its ability to provide appropriate treatment recommendations. A recent cross-sectional study found that when licensed health care professionals blindly evaluated ChatGPT versus verified physicians' answers to health-related questions on a social media forum, evaluators preferred ChatGPT's answers in 78.6% of the 585 evaluations.4 This study concluded that AI chatbots can provide quality responses to health questions—indicating that ChatGPT may be more useful for providing potential treatments as opposed to diagnoses.4
While there have been increasingly more studies investigating the use of AI within medicine, little research has focused on the specialty of developmental and behavioral pediatrics (DBP). The few studies that have investigated AI in DBP have focused on risk detection measures, where machine learning techniques are used to analyze sets of “big data” from electronic health records to predict future diagnoses. These studies report encouraging risk prediction performance of AI models with access to data on comorbidities.5 Machine learning techniques can identify autism spectrum disorder risk based on recognizing comorbidity clusters for electronic DBP health records.6,7 Notably, autism spectrum disorder has also been reliably detected by AI through analysis of caregiver questionnaires, home videos of behavior, and physician surveys.8
Despite these past implementations of AI in DBP, no study has yet examined the use of ChatGPT in diagnosis and developing treatment plans for DBP patients. Given ChatGPT's sophistication, accessibility, and ease of use, the AI chatbot may eventually be seen as an attractive tool for primary care physicians and parents alike in seeking advice for children with developmental and behavioral (DB) issues. AI chatbots, while currently available online as either applications or websites, may in the future be implemented into commercial products, making it more accessible for patients. Furthermore, given the national shortage of physicians that is particularly affecting the DBP subspecialty, many parents are facing barriers to accessing care for their children.9 This may spur parents to turn to alternative methods of acquiring medical advice for DB issues, such as ChatGPT.
However, there are indications that ChatGPT may potentially struggle in this regard. While ChatGPT-4 outperformed first- and second-year medical students on free response clinical reasoning examinations,10 indicating that AI is adept at analyzing large pools of data, there are many contexts and nuances to consider for actual patients. As evidenced by the diagnostic accuracy when ChatGPT analyzed complex New England Journal of Medicine case studies (39%) as opposed to common internal medicine cases (53.3%), ChatGPT becomes less accurate in cases that are more challenging.
Therefore, incorporating generative AI in health care is ethically demanding; an investigation published in Nature suggests that the chatbots' responses are not fixed and subject to change.11 ChatGPT is also not a medically trained bot and therefore needs significant oversight from health care professionals. Unique complexities and nuances of developmental medicine may present challenges to a large language-based algorithm, which when examined by a DBP physician may seem quite logical. An example may be pica sequelae from sensory mouthing; while a trained physician may immediately recognize concerns of lead poisoning, ChatGPT may not.
This study investigates how ChatGPT analyzes medical information and subsequently creates recommendations. Cases and treatment plans were sourced from Stanford DBP Training Materials, Journal of Developmental and Behavioral Pediatrics, and Crocker's Developmental and Behavioral Pediatrics (third edition). ChatGPT was prompted to provide a diagnosis and treatment plan for each case, and a panel of physician researchers scored the accuracy ChatGPT's responses, as well as the accuracy and completeness of ChatGPT's treatment plan.
METHODSThe Journal of Developmental & Behavioral Pediatrics, Stanford Department Developmental-Behavioral Pediatrics,12 and Crocker's Developmental & Behavioral Pediatrics (third edition) were sourced for pediatric case studies (n = 100). Of the 100 cases reviewed, 3 cases were excluded (n = 97) because ChatGPT was unable to process some cases that involved blocked topics (i.e., sexual assault) or they were not substantial enough to provide a diagnosis or list of recommendations as deemed by the physicians.
To determine whether ChatGPT was trained on any of the case studies, researchers asked the chatbot if it had access to the 3 sources stated above; the chatbot responded that it did not have any access to specific journals, training materials, and books.
Researchers entered the information in each case study into ChatGPT-3.5 with the prompt: Please provide a diagnosis (if not stated otherwise) and a plan/recommendations for this patient. The prompt was also not derived from any previous studies because this investigation uniquely examines both diagnoses and treatment recommendations. The researchers have not found other studies that analyze both of these elements of a ChatGPT response. Based on the prompt and case, ChatGPT provided a diagnosis (or multiple diagnoses if applicable) as well as a complete treatment plan for the patient in the case study (Table 1). The response generated by ChatGPT was then provided to a panel of 3 dually boarded physicians (pediatrics and developmental and behavioral pediatrics—each with over 10 years of clinical experience). The physicians evaluated the diagnoses individually and reached a consensus afterward; ChatGPT's diagnoses were labeled as Correct, Incorrect, Overdiagnosed, or Did Not Fully Capture the Diagnosis. If a diagnosis was already provided in the case study, the case was excluded when analyzing ChatGPT's diagnostic accuracy.
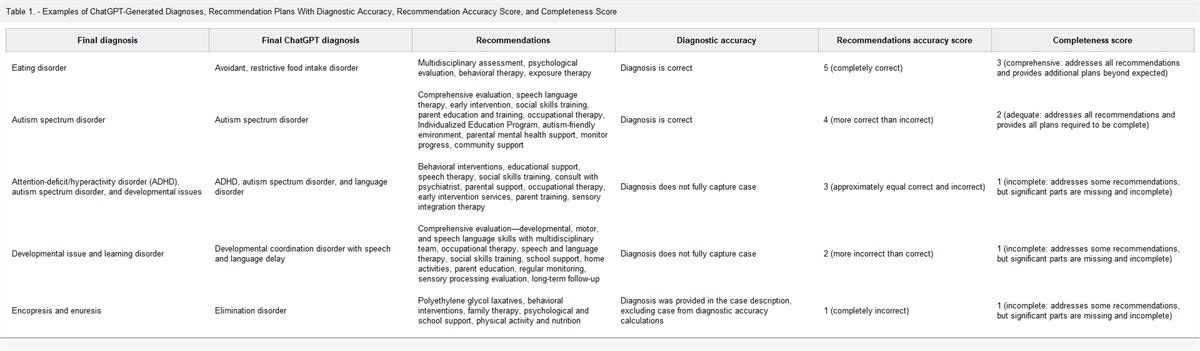
Table 1. - Examples of ChatGPT-Generated Diagnoses, Recommendation Plans With Diagnostic Accuracy, Recommendation Accuracy Score, and Completeness Score Final diagnosis Final ChatGPT diagnosis Recommendations Diagnostic accuracy Recommendations accuracy score Completeness score Eating disorder Avoidant, restrictive food intake disorder Multidisciplinary assessment, psychological evaluation, behavioral therapy, exposure therapy Diagnosis is correct 5 (completely correct) 3 (comprehensive: addresses all recommendations and provides additional plans beyond expected) Autism spectrum disorder Autism spectrum disorder Comprehensive evaluation, speech language therapy, early intervention, social skills training, parent education and training, occupational therapy, Individualized Education Program, autism-friendly environment, parental mental health support, monitor progress, community support Diagnosis is correct 4 (more correct than incorrect) 2 (adequate: addresses all recommendations and provides all plans required to be complete) Attention-deficit/hyperactivity disorder (ADHD), autism spectrum disorder, and developmental issues ADHD, autism spectrum disorder, and language disorder Behavioral interventions, educational support, speech therapy, social skills training, consult with psychiatrist, parental support, occupational therapy, early intervention services, parent training, sensory integration therapy Diagnosis does not fully capture case 3 (approximately equal correct and incorrect) 1 (incomplete: addresses some recommendations, but significant parts are missing and incomplete) Developmental issue and learning disorder Developmental coordination disorder with speech and language delay Comprehensive evaluation—developmental, motor, and speech language skills with multidisciplinary team, occupational therapy, speech and language therapy, social skills training, school support, home activities, parent education, regular monitoring, sensory processing evaluation, long-term follow-up Diagnosis does not fully capture case 2 (more incorrect than correct) 1 (incomplete: addresses some recommendations, but significant parts are missing and incomplete) Encopresis and enuresis Elimination disorder Polyethylene glycol laxatives, behavioral interventions, family therapy, psychological and school support, physical activity and nutrition Diagnosis was provided in the case description, excluding case from diagnostic accuracy calculations 1 (completely incorrect) 1 (incomplete: addresses some recommendations, but significant parts are missing and incomplete)The panel of physicians also evaluated ChatGPT treatment recommendations on 2 predefined Likert scales for accuracy and completeness. Each physician provided an individual score, and the average score across the panel was computed. These scales were derived from a previous study13 with modifications. While the original study used a six-point Likert scale for accuracy and a three-point Likert scale for completeness,13 this study assessed accuracy on a condensed five-point scale (Table 2). Completeness, on the other hand, was evaluated on a three-point Likert scale (Table 3). In cases where the panel rated ChatGPT's treatment recommendations as comprehensive (a value of 3 on the completeness Likert scale), the panel was also asked whether ChatGPT's recommendations were excessive and included unnecessary treatments or recommendations.
Table 2. - Likert Scales for Accuracy Used by a Panel of Physicians to Score ChatGPT Treatment Recommendations Score Accuracy description 1 Completely incorrect 2 More incorrect than correct 3 Approximately equal correct and incorrect 4 More correct than incorrect 5 Completely correctAmong the 97 cases, there were 11 cases that the panel of physicians determined to be culturally sensitive. For such cases, the physicians agreed that the patients' cultural backgrounds must be considered because of religious or cultural beliefs. Physicians assessed ChatGPT's treatment plan on whether it correctly addressed these culturally sensitive issues. The physicians also found a specific case requiring ethical considerations and assessed whether ChatGPT addressed the ethical issue.
Mean, median, interquartile range, and SD were computed for the Likert scale scores for accuracy and completeness using Python. Diagnostic accuracy was calculated as a percentage.
RESULTSOf the 65 case studies with no diagnosis in the case study description, the panel agreed with ChatGPT's diagnosis for 66.2% of those case reports. The panel of physicians also agreed that in 21.5% of the case reports, ChatGPT did not fully capture the correct set of diagnoses. The panel deemed that ChatGPT overdiagnosed for 3.1% of the cases and disagreed with ChatGPT's diagnosis for 9.2% of the cases.
Across the 97 case studies, the panel of physicians rated ChatGPT's treatment plans with a mean accuracy score of 4.6 (median 5, SD 0.8, inter-quartile range [IQR] 0.0) and a mean completeness score of 2.6 (median 3, SD 0.7, IQR 0.5). The panel of physicians rated 77.3% (n = 75) of ChatGPT's treatment plans as entirely correct (accuracy score of 5) and 1.0% (n = 1) as entirely incorrect (accuracy score of 1). Regarding completeness, 72.2% (n = 70) of cases were rated as comprehensive (completeness score of 3), and 13.4% (n = 13) were rated as incomplete (completeness score of 1).
Among the 70 case studies where the panel of physicians rated ChatGPT's treatment plan as complete, 11.4% (n = 8) were rated as excessive and included unnecessary treatments or recommendations.
Of the 11 culturally sensitive cases, the physicians agreed that ChatGPT adequately addressed the cultural issues in 10 cases (90.9%). For the 1 case that the physicians deemed ethically challenging, ChatGPT suggested ethically appropriate suggestions.
DISCUSSIONAccess to powerful AI has markedly grown with the release of ChatGPT, increasing the likelihood that users will access the technology to seek medical advice. As such, many studies have investigated the accuracy of diagnosis and treatment recommendations of ChatGPT in medicine. However, few have focused specifically on the chatbot's utilization in DBP. Our study tested ChatGPT's diagnostic accuracy, treatment recommendation accuracy, and treatment recommendation completeness for DBP case studies.
The national shortage of physicians is especially being felt by those seeking pediatric subspecialties.9 In 2018, nearly 50% of children's hospitals had vacancies for the DBP subspecialty.14 There are currently only 709 actively certified DBP physicians nationwide for an estimated 17 million children with DB health problems; 68% of children with DB issues have not received developmental services.15 In response, parents and caregivers may begin to turn to alternative methods of acquiring medical advice online, as they have been doing since the advent of the internet. One recent estimate reported that Google receives as many as 1 billion health questions per day,16 and at least 66% of Americans report using the internet for medical information.17
For pediatrics in particular, a 2015 study revealed that 98% of parents report using the Internet to search for information regarding their children’s health. Despite 80% of respondents using public search engines for information rather than verified university/hospital-based websites, 74% trusted such unverified websites—and only 50% of parents fact-checked information found on the Internet with a physician.18 With most parents turning to the Internet for medical suggestions, it is imperative to understand what quality of advice they will be receiving.
While ChatGPT's diagnosis accuracy of 66.2% falls relatively short to the national physicians' accuracy of 84.3%,19 it was higher than the rates found in previous ChatGPT studies, including the 39% accuracy for case challenges from the New England Journal of Medicine.3 This may indicate that ChatGPT fares better at specifically diagnosing DBP cases as opposed to complex cases that are overwhelmingly not related to DBP. However the AI chatbot still falls short of actual physician diagnostic rates, which highlights the continued need for physician involvement in DBP cases.
Regarding providing recommendations, ChatGPT had a mean accuracy of 4.6 (4 being more correct than incorrect, 5 being completely correct) as determined by a panel of DBP physicians, demonstrating that chatbot can generate relevant medical suggestions. This result is similar to previous work performed on ChatGPT's accuracy for medical queries (4.8 on a 1–6 scale; between mostly and almost completely correct).13 In addition, the DBP physician panel rated ChatGPT's completeness of recommendations as a mean of 2.6 (between adequate and comprehensive), suggesting that ChatGPT's output often matches many of the recommendations that physicians would also suggest. This result also mirrors work previously performed by Johnson et al,13 who found a mean completeness score of 2.5 out of a 1 to 3 Likert scale.
ChatGPT was also found to not solely focus on the symptoms of the case study patient. Physicians noted that ChatGPT advice seemed empathetic. For example, when ChatGPT was given a DBP case in which a mother had postpartum depression, the chatbot suggested treatment for the mother in addition to the child. This included joining local parenting groups and learning proper maternal coping skills. This sensitivity of ChatGPT aligns well with previous research; one study found that ChatGPT explicitly considered social factors such as race or insurance status in 55% of the cases studied, indicating that ChatGPT analyzes beyond clinical data.20 This empathy may be an emulation of how DBP physicians would consult patients and parents. Parental support groups, for example, are often recommended by DBP physicians for mothers with postpartum depression, and ChatGPT detected the patterns of such conditions it was trained on.
Furthermore, ChatGPT displayed a substantial level of cultural sensitivity. For instance, one case report featured a Japanese family that was resistant to using medication or cognitive behavioral therapy for their child's anxiety because these treatments were not aligned with their cultural beliefs centered on mental health. ChatGPT acknowledges this point by including in its recommendation that physicians must “respect [their] cultural beliefs” and “consider alternative therapies in line with [the family's] cultural beliefs.” In another case report with similar cultural issues, the chatbot stressed “patience and empathy” for the patient's “religious beliefs.” The physician panel confirmed that ChatGPT's cultural recommendations were clinically appropriate, which is encouraging because there has been little previous research on ChatGPT's cultural competencies.
Despite ChatGPT's encouraging performance in treatment suggestions, the chatbot did make consistent errors. For example, although each case report explicitly indicated the age of the patient, the chatbot often recommended “early intervention”—a service that many times the patient had already aged out of and was thus ineligible for. In addition, physician researchers also noted that AI chatbot underused social support services that the case study child would be eligible for, although this may be because ChatGPT did not have access to the patient's geographic location and cannot determine what services would be available. The chatbot also had a tendency to report an oversized plan with unnecessary suggestions, such as “comprehensive reevaluation” (i.e., medical tests or psychiatric reevaluations) that were often deemed unnecessary by the physician panel. This may also be due to ChatGPT emulating DBP physicians' knowledge, similar to empathy. Early intervention and reevaluations are often recommended by the physicians for DBP cases; therefore, ChatGPT is able to recognize the patterns and often over suggests often-used DBP recommendations. While diagnosing rate falls short because of the patients' contexts and nuances that ChatGPT cannot account for, ChatGPT, through machine learning, has acquired the skills to realize the patient's symptoms and output a series of recommendations that are largely appropriate in accuracy and completeness.
LimitationsThere are limitations to this study. While this study had a significant number of cases, additional cases with more variety (mental health, behavioral issue, developmental issue, genetics, etc.) could have led to a more comprehensive analysis of ChatGPT's capabilities. Researchers only studied ChatGPT, but there are medical AI chatbots that may provide different results. Future studies should use different chatbots and analyze case studies from other specialties.
Furthermore, the physician panel consists of 3 physicians from a singular medical institution, which may not be representative of all specialists. However, it should be noted even physicians within the same practice may vary widely in their clinical opinions, and therefore, the authors believe that the study continues to have merit. This study was not blinded, and respondent bias or social desirability may be a factor in the physician panel's ratings.
From the cases analyzed, researchers only found 1 ethically challenging case, which may be insufficient to conclude ChatGPT as empathetic. In addition, the tested cases contain medical jargon and phrasing; this may not be reflective of the accuracy rates when parents and guardians input their DBP concerns into ChatGPT. Future studies should test ChatGPT's abilities based on patient inputs and examine ethically challenging cases.
CONCLUSIONThis study shows that while ChatGPT displays a high level of accuracy and completeness in clinical treatments and recommendations for challenging DBP cases, it still lacks in regards to diagnostic accuracy. With a large proportion of the general patient population willing to use ChatGPT for self-diagnosis,21 Large-language models (LLMs) must be verified through real-world testing. Professionals should provide the right data and algorithmic guidelines to develop these tools further.22 Although ChatGPT is still imperfect for use in clinical settings, its ability to generate comprehensive and adequate medical recommendations in a matter of seconds is impressive. There is a possibility that, with guidance and improvements from medical professionals, the chatbot can eventually generate a more complete and accurate list of next steps that patients can refer to. The implications of this study have the potential to be far-reaching—while parents and patients may eventually have the ability to access ready information on what they can do to help their child as they wait for physician confirmation of a diagnosis, ChatGPT is still in its infancy. Despite this, many ChatGPT users can easily consult the LLM with their concerns and receive very variable inputs, perhaps alleviating or heightening parental concerns. DBP physicians must be aware of the emergence of LLMs in medical settings and should address the precautions of using online chatbots to parents and patients.
REFERENCES 1. Kung TH, Cheatham M, Medenilla A, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digit Health. 2023;2:e0000198. 2. Hirosawa T, Harada Y, Yokose M, et al. Diagnostic accuracy of differential-diagnosis lists generated by generative pretrained transformer 3 chatbot for clinical vignettes with common chief complaints: a pilot study. Int J Environ Res Public Health. 2023;20:3378. 3. Kanjee Z, Crowe B, Rodman A. Accuracy of a generative artificial intelligence model in a complex diagnostic challenge. JAMA. 2023;330:78–80. 4. Ayers JW, Poliak A, Dredze M, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med. 2023;183:589–596. 5. Aylward BS, Abbas H, Taraman S, et al. An introduction to artificial intelligence in developmental and behavioral pediatrics. J Dev Behav Pediatr. 2023;44:e126–e134. 6. Movaghar A, Page D, Scholze D, et al. Artificial intelligence–assisted phenotype discovery of fragile X syndrome in a population-based sample. Genet Med. 2021;23:1273–1280. 7. Lingren T, Chen P, Bochenek J, et al. Electronic health record based algorithm to identify patients with autism spectrum disorder. PLoS One. 2016;11:e0159621. 8. Megerian JT, Dey S, Melmed RD, et al. Evaluation of an artificial intelligence-based medical device for diagnosis of autism spectrum disorder. NPJ Digit Med. 2022;5:57. 9. Plumley DA. Pediatric subspecialty shortage: a looming crisis. Pediatr Health. 2010;4:365–366. 10. Strong E, DiGiammarino A, Weng Y, et al. Chatbot vs medical student performance on free-response clinical reasoning examinations. JAMA Intern Med. 2023;183:1028–1030. 11. Meskó B, Topol EJ. The imperative for regulatory oversight of large language models (or generative AI) in healthcare. Npj Digit Med. 2023;6:120. 12. Developmental-Behavioral Pediatrics. Case Studies. (n.d.). Available at: https://dbpeds.stanford.edu/education/dbp-resident-training/case-studies.html. 13. Johnson D, Goodman R, Patrinely J, et al. Assessing the accuracy and reliability of AI-generated medical responses: an evaluation of the Chat-GPT model. Res Sq. 2023. Preprint. doi:10.21203/rs.3.rs-2566942/v1. 14. Vinci RJ. The pediatric workforce: recent data trends, questions, and challenges for the future. Pediatrics. 2021;147:e2020013292. 15. Froehlich TE, Spinks-Franklin A, Christakis DA. Ending developmental-behavioral pediatrics faculty requirement for pediatric residency programs—desperate times do not justify desperate actions. JAMA Pediatr. 2023;177:999–1000. 16. Drees J. Google receives more than 1 billion health questions every day. In: Becker's Health It; 2019. Available at: https://www.beckershospitalreview.com/healthcare-information-technology/google-receives-more-than-1-billion-health-questions-every-day.html. Accessed August 14, 2023. 17. Health Topics. Pew Research Center; 2011. Available at: https://www.pewresearch.org/internet/2011/02/01/health-topics-4/. Accessed August 14, 2023. 18. Pehora C, Gajaria N, Stoute M, et al. Are parents getting it right? A survey of parents' internet use for children's health care information. Interactive J Med Res. 2015;4:e12. 19. Semigran HL, Levine DM, Nundy S, et al. Comparison of physician and computer diagnostic accuracy. JAMA Intern Med. 2016;176:1860–1861. 20. Nastasi AJ, Courtright KR, Halpern SD, et al. Does ChatGPT provide appropriate and equitable medical advice?: a vignette-based, clinical evaluation across care contexts. medRxiv. 2023. Preprint. Available at: https://doi.org/10.1101/2023.02.25.23286451. 21. Shahsavar Y, Choudhury A. User intentions to use ChatGPT for self-diagnosis and health-related purposes: cross-sectional survey study. JMIR Hum Factors. 2023;10:e47564. 22. Shah NH, Entwistle D, Pfeffer MA. Creation and adoption of large language models in medicine. JAMA. 2023;330:866–869.
留言 (0)