
記住我








A challenge in studying bivalent chromatin is that aligning independently generated single H3K4me3 and H3K27me3 datasets in silico is theoretically insufficient to distinguish true bivalency (where both marks are present on the same chromatin fragment) from allelic or cellular heterogeneity (where marks are present on different alleles or in different cells within the population) (Fig. 1A). To address this, reChIP (also known as sequential ChIP or ChIP-reChIP) approaches have been used [13,14,15,16,17,18, 22, 23], however, many limitations exist with current protocols which typically require large (> 10 million cells) amount of starting material per reaction (13,14,15, 22, 23), and consequently are often performed in just one of the two directions [23]. This is a major issue as many false positives can confound the results due to “signal carry-over” whereby enrichment from the first ChIP carries through into the second ChIP. Moreover, variable data quality with low signal to noise has traditionally made downstream bioinformatic analysis of bivalent regions challenging. To address these points, we optimised the reChIP protocol to give a high signal to noise ratio with both qPCR and high-throughput sequencing readouts from just 2 million cells (Fig. 1B). Critically, we advise the reChIP be carried out in both orientations (H3K4me3 followed by H3K27me3 and vice versa). The method was optimised using serum/LIF cultured E14 mouse Embryonic Stem Cells (ESCs) given their well-defined distribution of bivalent chromatin [11, 12, 14, 18]. Importantly our method produces high quality data that can be analysed with commonly-used bioinformatic tools. A full detailed protocol accompanies this paper (Additional file 1).
The 3-day workflow is shown in Fig. 1B. Briefly, cells are treated with formaldehyde to cross-link chromatin, and 2 million cell aliquots can then be stored at − 80 ℃ for up to 6 months. Cells are gently lysed and treated with MNAse to generate predominantly mononucleosomes (Fig. 1C, Additional file 2: Figure S1A) and chromatin pre-cleared by incubating with pre-washed dynabeads for 3 h at 4 ℃ to reduce non-specific binding. Alternatively, sonication can be used to fragment chromatin with similar results (Additional file 2: Figure S1A, B). During the pre-clearing step, the antibody-dynabead complexes are formed for the IgG control, H3K4me3 and H3K27me3 immunoprecipitations. 5% of the precleared chromatin is set aside as an input control and the remainder split across the three tubes of antibody-dynabead complexes for the first overnight immunoprecipitation at 4 ℃.
Following the first immunoprecipitation, the chromatin-antibody-dynabead complexes are thoroughly washed to remove any non-specific binding prior to chromatin elution. Traditionally, reChIP protocols typically use one of two approaches to elute chromatin from beads. DTT- or SDS-based elution buffers function by dissociating the affinity interactions upon which the immunoprecipitation is based but require additional dilution and/or cleanup steps to ensure compatibility with a second immunoprecipitation reaction (14,15,16,17, 22, 23). An alternative is to use high concentration of modified histone tail peptides to compete with antibody binding sites [13]. We compared these two approaches to elute chromatin in single H3K4me3 ChIPs (Fig. 1D). The SDS elution performed well in terms of specificity and signal to noise ratio. The 3 hour peptide competition gave similar results to SDS elution, however, the amount of unspecific background signal increased when incubated overnight (Fig. 1D). After considering costs and availability of commercial peptides, we decided to implement SDS elution in our final protocol. To facilitate subsequent antibody binding events, we diluted the chromatin and performed a buffer exchange using 3 kDa molecular weight filters. From the first immunoprecipitation reaction, 10% of the sample representing in-line total H3K4me3 or total H3K27me3 control can be set aside to aid downstream analysis and bivalent peak classification, although we recommend performing independent total H3K4me3 and H3K27me3 ChIPs when possible. The second immunoprecipitation is then performed overnight using the alternate antibody so that the reChIP is performed in both directions: H3K4me3 followed by H3K27me3 (K4-K27), and H3K27me3 followed by H3K4me3 (K27-K4). As a negative control, IgG followed by IgG (IgG–IgG) is also performed to control for non-specific enrichment during the reChIP assay. Chromatin is then eluted in SDS-elution buffer, formaldehyde crosslinks reversed, RNA and proteins degraded, and enriched DNA fragments purified ready to be processed for qPCR analysis and/or high throughput sequencing.
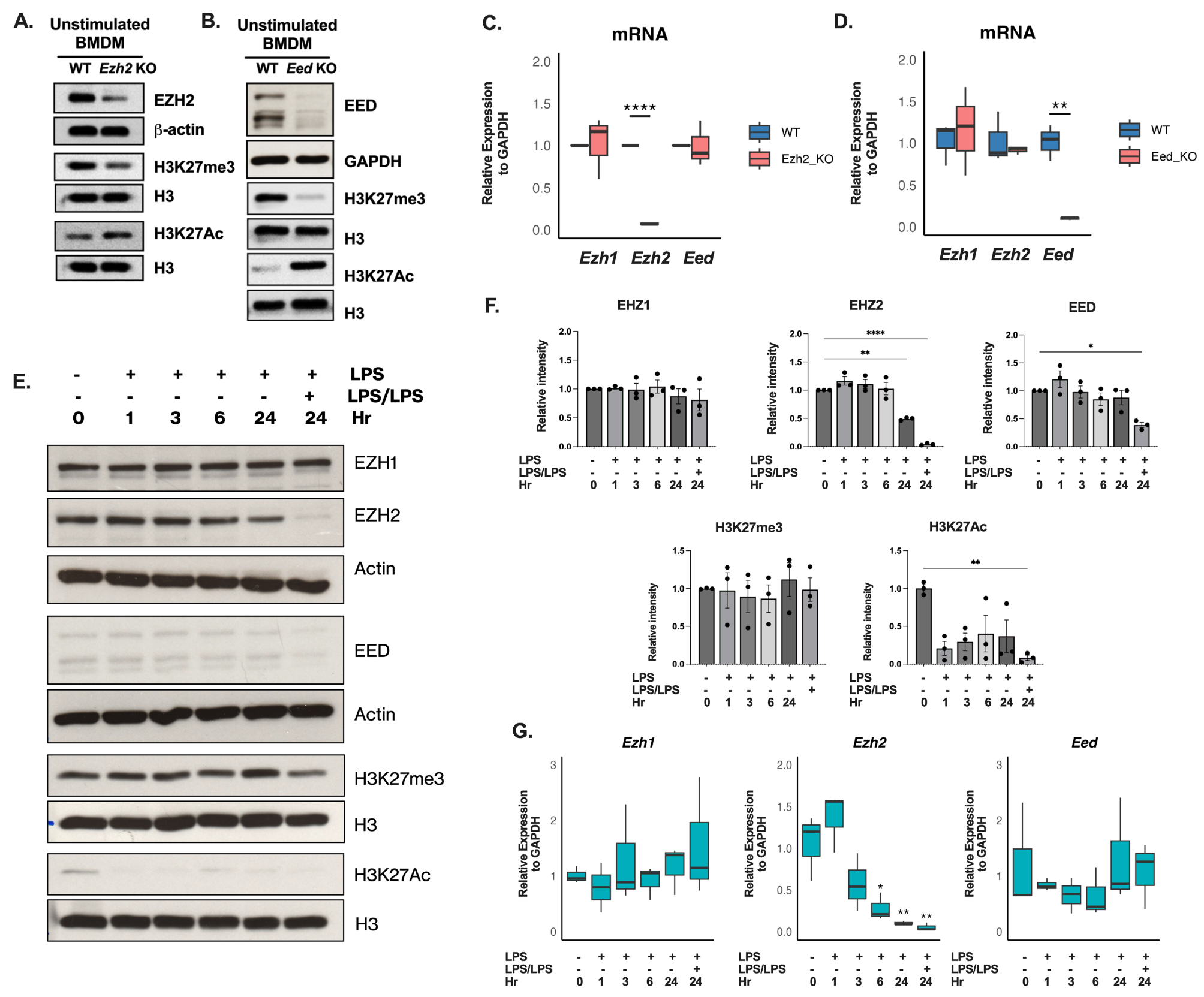
Generating high quality genome-wide bivalent chromatin maps in mouse embryonic stem cellsTo date bivalent chromatin is best understood in mouse ESCs. Therefore, we used this model to test our refined method. In total 9 datasets were generated from two biological replicates (Fig. 2A). These included two in-line H3K4me3 single ChIPs, two in-line H3K27me3 single ChIPs, two each of K4-K27 and K27-K4 reChIPs, and one IgG–IgG replicate. We note that the widely-used commercial ChIP-grade H3K4me3 antibody used predominantly in our manuscript has also been reported to detect H3K4me2 at lower efficiency [24], and so we may also be detecting some H3K4me2-H3K27me3 bivalent nucleosomes. Replicate 2 was sequenced at a higher depth (45–55 million reads per sample) than replicate 1 (9.4–19.6 million reads per sample), to enable us to determine optimal library sequencing depth through downsampling analysis (see below).
Fig. 2
A Summary table of samples sequenced in E14 mouse embryonic stem cells indicating replicate (Rep), ChIP, total aligned reads, percentage duplication and number of peaks. B Analysis pipeline for calling bivalent peaks. C Genome browser view of reChIP datasets including IgG–IgG reChIP control (grey), in-line total H3K4me3 (green, rows 2 and 3), in-line total H3K27me3 (red, rows 4 and 5) and bivalent reChIP for H3K4me3 followed by H3K27me3 (K4-K27, purple, rows 6 and 7) or vice-versa (K27-K4, blue, row 8 and 9). Two biological duplicates (R1 and R2) are shown for all but IgG–IgG libraries. CpG islands are denoted by orange bars. Bivalent regions are highlighted in yellow. D FRiP scores showing proportion of reads within peaks for each individual sample. IgG–IgG (grey) is shown for each set of peaks to get background levels. E Comparison of peaks called using our reChIP method compared to in silico overlap of independently derived total ChIP-seq datasets F Single ChIP-qPCR for H3K4me3 (green) or H3K27me3 (red) at a H3K4me3 region (Gapdh1) or three bivalent regions (Tlx1, Pou4f1, Dlx3). Bottom panel shows corresponding reChIP controls: IgG–IgG (black), H3K4me3-IgG (light green), H3K27me3-IgG (light red). G Schematic of enrichment of first IP into the second IP when IgG antibody is used as the second IP in reChIP experiments. H reChIP-qPCR analysis of a H3K4me3-only region (Gapdh1) and three bivalent regions (Tlx1, Pou4f1 and Dlx3) in control (dark bars) versus cells treated with Tazemetostat (Taz) to reduce global H3K27me3 levels (light bars)
The bioinformatic workflow for calling bivalent peaks is outlined in Fig. 2B. Initial data inspection of our reChIP datasets revealed strong peak distribution of reads for the K4-K27 and K27-K4 reChIP samples at known bivalent regions with low intervening background signal (Fig. 2C). Furthermore, peaks were observed in the in-line total H3K4me3 and total H3K27me3 samples, albeit these signals were noisier. This is likely due to the lower starting material for library preparation of these samples which only correspond to approximately 60,000 cells. This is near the lower limit for achieving clear signal over background for single ChIPs in our laboratory (Additional file 2: Figure S1C).
We sequenced the two biological replicates at different depths ranging from approximately 10 million through to 55 million aligned reads (Fig. 2A). From the higher coverage replicate 2, we performed in silico downsampling analysis from which we concluded that 15–20 million reads was a good compromise between number of high-confidence bivalent peaks and promoters detected (see below) versus sequencing cost (Additional file 2: Figure S1D, E). Supporting this, even with approximately 10 million mapped reads in replicate 1 there were clear peaks in the reChIP samples (Fig. 2C). Moreover, downsampling independently derived total H3K4me3 and H3K27me3 datasets generated from approximately 10 million cells had no negligible effect on the number of peaks called (Additional file 2: Figure S1F, G), suggesting it is the starting cell number, not the sequencing depth, that dictates data quality.
To get a measure of the specificity of our assay, we calculated the fraction of reads in called peak regions (FRiP score) which is commonly used in ATAC-seq analysis to determine library quality. Notably, all reChIP samples had very high FRiP scores, while the corresponding IgG–IgG scores for each of the peak sets were all less than 0.1 (Fig. 2D). This indicates a very high and specific enrichment and low background of these reChIP libraries.
Overlapping total H3K4me3 and total H3K27me3 peaks in silico is often used as a proxy to define bivalent chromatin (Fig. 1A). Using this approach with the independent 10 million cell datasets gives 7,188 putative bivalent regions, of which 5,299 (73.7%) overlapped a peak in both reChIP datasets (Fig. 2E). Crucially, 1,889 in silico called peaks are not validated in both reChIP directions indicating a high false-positive rate of 26.3% (Fig. 2E). This may be explained by allelic or cellular heterogeneity in mouse embryonic stem cells and highlights the importance of performing reChIP experiments to accurately measure bivalent chromatin.
A frequently used control in sequential ChIP experiments is to use IgG as a second antibody [14, 22]. The rational for this is that the IgG should not enrich for any chromatin regions and thus the H3K4me3-IgG and/or H3K27me3-IgG reChIPs can be used to estimate non-specific enrichment levels and control for signal carry-through from the first ChIP into the second. To test the utility of these controls we performed H3K4me3-IgG and H3K27me3-IgG reChIP-qPCRs in mESCs (Fig. 2F). However, these reChIPs still showed substantial enrichment at bivalent regions, while the IgG–IgG reChIPs did not enrich at any region (Fig. 2F). The enrichment at H3K4me3-IgG and H3K27me3-IgG reChIPs had a near identical enrichment pattern to the corresponding total H3K4me3 or H3K27me3 single ChIPs. Consistently, reanalysis of published reChIP data in mESCs [14] showed near identical enrichment between total H3K4me3 and H3K4me3-IgG reChIP datasets (Additional file 2: Figure S1H). This suggests that the use of IgG as a secondary ChIP is subsampling the first enrichment (Fig. 2G), and so not a useful negative control.
As an alternative control for signal carry-over from the first ChIP into the second, we treated mESCs with the Ezh2 inhibitor Tazemetostat to deplete global levels of H3K27me3 [25, 26]. As expected, single ChIP-qPCR revealed total H3K27me3 at these regions was completely lost in the Tazemetostat-treated cells, while total H3K4me3 was unaffected (Fig. 2H). Importantly, in Tazemetostat-treated cells, the reChIP signal in both orientations was also depleted. This indicates that our reChIP protocol is specific for detecting bone fide bivalent chromatin and not affected by signal from the first ChIP carrying through into the second.
Identification of 8,789 bivalent peaks in mESCsIn our mESC datasets, we revealed 9,202 K4-K27 and 16,400 K27-K4 reChIP peaks of which 8,789 were shared (Fig. 3A). We first investigated whether these peaks were similarly shared in total H3K4me3 and/or total H3K27me3 datasets. We initially stratified bivalent peaks using our in-line total H3K4me3 and H3K27me3 single ChIPs. We were unable to call many peaks using these in-line controls (Additional file 2: Figure S2A), although enrichment for total H3K4me3 and total H3K27me3 at bivalent regions was still observed (Fig. 3B). This is likely due to the low signal- to-noise seen in these datasets that correspond to approximately 60,000 cells (Fig. 2D). Therefore, as an alternative we stratified the reChIP peaks using independent total ChIPs from approximately 10 million cells we previously generated using the same cell line [7]. When using these independently derived total ChIP-seq datasets, 5,299 of the 8,789 peaks (60%) overlapped peaks in both the total H3K4me3 and H3K27me3 datasets (Fig. 3A). We termed these high-confidence promoters to distinguish them from K4-biased (peak shared only in total H3K4me3, n = 855), K27-biased (peaks shared only in total H3K27me3, n = 2,240) or low confidence (did not share a peak in either total H3K4me3 or H3K27me3, n = 395) bivalent regions. As expected, high confidence bivalent regions had the highest enrichment in reChIP datasets (Fig. 3B, C). Representative H3K4me3-only, high-confidence, K4-biased, K27-biased and low-confidence bivalent regions are shown in Additional file 2: Figure S2B-F.
Fig. 3
Identification of 8,789 bivalent regions in mouse embryonic stem cells. A Overlap between K27-K4 (blue) and K4-K27 (purple) reChIP datasets. The 8,789 overlapping peaks were classified as high confidence (overlap peak in both total H3K4me3 and total H3K27me3, blue), K4-biased (overlap peak in only total H3K4me3, green), K27-biased (overlap peak in only H3K27me3, orange) or low confidence (does not overlap peak in either H3K4me3 or H3K27me3, brown) using independent total H3K4me3 and H3K27me3 single ChIPs from approximately 10 million cells from GSE135841 [7]. B Box-whisker plots (line shows median and box denotes 25th and 75th percentile, whiskers shown interquartile range multiplied by 2) showing log2CPM/bp values for high confidence (top left), K4-biased (top right), K27-biased (bottom left) and low confidence (bottom right) peaks in independent total H3K4me3 and total H3K27me3 datasets from GSE135841 [7] (denoted by * and shaded grey background) or the in-line total and reChIP datasets generated in this study. C Scatter plot showing log2CPM/bp values for bivalent K4-K27 (x-axis) and bivalent K27-K4 (y-axis) datasets for all bivalent peaks highlighting high confidence (blue), K4-biased (green), K27-biased (orange) and low confidence (brown) peaks. D Relative distribution plot (each probe is weighted equally in final profile) of reads across peaks showing broader peak width for H3K27me3 peaks compared to H3K4me3 and reChIP peaks E 5-state chromHMM models using pooled replicates for in-line total H3K4me3, in-line total H3K27me3 and K4-K27 and K27-K4 reChIP datasets showing emission (left) and transmission (second from left) parameters, enrichment across TSS ± 2kb and overlap with high confidence (blue), K4-biased (green), K27-biased (orange) and low-confidence (brown) bivalent regions (right). F Genomic features associated with the bivalent regions. G, H Violin plots showing GC fraction G and GC-CG dinucleotide frequency H within regions compared to random subset (width and GC-content matched) of 8,789 genomic regions. All comparisons are statistically significant after multiple testing (Benjamini–Hochberg correction). I Motif enrichment for the four classes of bivalent peaks compared to the same background set used in G, H. Those with log2enrichment over random sequences > 1 are shown, along with their enrichment scores and -log10Adjusted p-value
The bivalent reChIP peaks were sharp and narrow (Fig. 3D), demonstrating the specificity of our approach in enriching for chromatin fragments containing both modifications of interest, and the absence of carry-over of the broader H3K27me3 signal, particularly in the K27-K4 reChIP dataset. Orthogonal unbiased Hidden Markov Model approaches [27] using in-line totals and reChIPs identified chromatin states that matched our peak-centric classifications (Fig. 3E). From the 5-state chromatin model we observed that state 3 and state 5 were characterised by high signal in both K4-K27 and K27-K4 datasets, as well as in-line controls. Both these states were enriched for our bivalent promoters, confirming the validity of these bivalent peak subclasses.
Consistent with previous studies [4, 5, 11], bivalent peaks were predominantly located at promoters or transcription start sites (TSS) (80%) (Fig. 3F) which contained CpG islands (Additional file 2: Figure S2G). Sequence analysis revealed that bivalent regions had a higher GC content (Fig. 3G) and CpG dinucleotide frequency (Fig. 3H) than size and GC-content matched random set of genomic regions. Motif analysis revealed a strong enrichment for motifs associated with developmental regulation including ZSCAN4, HOX(A1,A6,A9,B7), PROX1, TGIF1, PAX4/9 and ZIC1/4/5 (Fig. 3I) in the high confidence bivalent regions. Approximately half (51.8%) of non-promoter bivalent peaks predominantly overlapped candidate enhancer elements (Additional file 2: Figure S2H), suggesting a potential regulatory role for this chromatin state at enhancer elements.
Catalogue of 3,918 high-confidence bivalent gene promoters in mouse embryonic stem cellsGiven the strong overlap between high confidence bivalent regions and gene promoters, we next analysed gene promoters specifically and found a total of 5,104 bivalent gene promoters in mESCs (Fig. 4A). As some promoters contained more than one bivalent peak, to classify the promoters, we used a hierarchical classification approach whereby promoters were first classed as high confidence if there were any high confidence peaks, then K4-biased followed by K27-biased and lastly low confidence (Fig. 4A). The majority of bivalent promoters were high confidence using the independent 10 million cell totals for classification. To directly compare our list of bivalent promoters with previous studies [14], we re-processed and classified the previous datasets using our pipeline (Additional file 2: Figure S3A), identifying 4,661 bivalent promoters. Importantly, our method detected 3,593 (77%) of these previously annotated bivalent genes (Fig. 4B). Closer examination of the novel bivalent promoters captured with our improved method saw an enrichment of signal in previous reChIP datasets at these loci (Additional file 2: Figure S3B), suggesting that these bivalent regions are real and that the increased signal to noise with our method enables these novel bivalent promoters to be captured. Of note, however, is our improved sensitivity in detecting high-confidence bivalent gene promoters. With the previous dataset, only 397 bivalent promoters were classified as high confidence in contrast to the 3,918 in our study, highlighting the increased sensitivity of our method.
Fig. 4
Catalogue of 5,104 bivalent gene promoters in mouse embryonic stem cells. A Schematic outlining classification strategy for bivalent promoters. Full list of bivalent promoter classifications is available in Additional file 3: Table S3. B Overlap of all bivalent promoters (top) and high-confidence bivalent promoters (bottom) between those identified in this study compared to previously published reChIP data (reanalyzed from [14]). C Enrichment heatmaps showing CPM/bp normalised read densities for high confidence (top row), K4-biased (second row), K27-biased (third row) and low confidence (bottom row) bivalent promoters after scaling for all datasets analysed. Peaks were extended to 5kb upstream and downstream of the peak centre. Values surpassing the 99th percentile have been masked for visualisation. 107 samples refers to independent total H3K4me3 and total H3K27me3 datasets from GSE135841 [7] D, E Scatterplot showing log2enrichment (CPM/bp) of D in-line total H3K4me3 (x-axis) and in-line total H3K27me3 (y-axis) or E bivalent K4-K27 (x-axis) and K27-K4 (y-axis) reChIP datasets for all promoters highlighting those that overlap different classes of bivalent peaks defined using independent 10 million cell total H3K4me3 and total H3K27me3. F Box plot showing log2 RPKM gene expression levels in mouse embryonic stem cells for four different classes of bivalent genes and those redefined from previous data (14). Expression of the bottom 20% and top 20% is shown as a comparison. Gene expression data reanalyzed from GSE135841. G Gene Ontology analysis showing overlap of representative enriched terms in the four classes of bivalent genes (top) and gene ratios and adjusted P-value of selected terms (bottom). The full list of enriched terms is available in Additional file 3: Table S4. H log2 fold change in gene expression levels for different classes of bivalent genes across 9 days of embryoid body differentiation. Each gene has been normalised separately across the time series, genes are grouped using correlation based clustering. Gene expression data reanalyzed from (GSE135841)
The high confidence bivalent gene promoters had the highest levels of total H3K4me3 and total H3K27me3 (Fig. 4C, D) and bivalent K4-K27 and K27-K4 reChIP enrichment (Fig. 4C, E). As expected, the high confidence bivalent genes were expressed at low yet detectable levels in pluripotent mouse embryonic stem cells (Fig. 4F). In contrast the K4-biased bivalent genes had higher expression values, consistent with their enrichment for total H3K4me3 but not total H3K27me3. The high confidence bivalent genes were enriched in developmental biological processes (Fig. 4G) of which many were shared with the K4-biased or K27-biased classes. In line with current models [4, 5, 28], high confidence bivalent genes were dynamically expressed upon differentiation resolving to either an active or repressed state (Fig. 4H, Additional file 2: Figure S3C). Therefore, our data support the current model of bivalent chromatin marking developmental genes in embryonic stem cells, that are poised for future activation or repression.
Profiling bivalent chromatin dynamics in DPPA2/4 knockout mouse embryonic stem cellsLastly, we confirmed the sensitivity of our method to detect changes in bivalent chromatin by profiling mouse embryonic stem cells deficient for the epigenetic priming factors DPPA2 and DPPA4 [7]. We and others recently reported that DPPA2/4 are required to maintain bivalent chromatin at a subset of bivalent genes which were termed Dppa2/4-dependent [6, 7] (Fig. 5A). To test the dynamic sensitivity of our method, we profiled two wild-type (WT) and two DPPA2/4 double knockout (DKO) clones using our refined method. Our reChIP datasets recapitulated previous observations where total H3K4me3 and total H3K27me3 signals were lost at Dppa2/4-dependent bivalent genes yet retained at Dppa2/4-independent (stable) genes in the DPPA2/4 knockout cells (Fig. 5B). Importantly, this was also observed in the both bivalent K4-K27 and K27-K4 reChIP directions, highlighting the ability of our improved method to detect dynamics of bivalent chromatin between different conditions.
Fig. 5
Profiling bivalent chromatin dynamics in DPPA2/4 knockout mouse embryonic stem cells. A Schematic depicting how DPPA2/4 maintain both H3K4me3 and H3K27me3 at a subset of bivalent genes, priming them for future activation. Loss of DPPA2/4 leads results in loss of both H3K4me3 and H3K27me3 and gain of repressive DNA methylation (black circles). B Genome browser view of wild type (WT, dark) and DPPA2/4 double knockout (DKO, light) embryonic stem cell clones. Two clones of each genotype are shown. In-line total H3K4me3 (green), in-line total H3K27me3 (red) and bivalent K4-K27 (purple) and K27-K4 (blue) reChIP data tracks are shown. Dppa2/4-dependent promoters (lose bivalency when DPPA2/4 absent) are denoted by orange bars. Stable promoters are denoted by blue bars. C Scatterplots showing enrichment (log2 CPM/bp) for K4-K27 (top) and K27-K4 (bottom) reChIPs between wild type (x-axis) and Dppa2/4 double knockout (DKO) (y-axis) across all bivalent peaks (grey). Highlighted are those differentially enriched in the K4-K27 (purple), K27-K4 (blue) or both (orange) reChIP datasets. D box plot showing normalised enrichment (CPM/bp) of previously annotated Dppa2/4-dependent gene promoters (light orange) and novel Dppa2/4-dependent gene promoters (dark orange) across the different datasets and clones. As a comparison a subset of stable Dppa2/4-independent gene promoters (bivalent promoters that do not change) are shown (blue). E Enrichment heatmaps showing normalised enrichment of previously annotated Dppa2/4-dependent genes (top, light orange) and novel DPPA2/4-dependent genes (middle, dark orange) across the different datasets averaging across clones. As a comparison a subset of Dppa2/4-independent genes (bivalent promoters that do not change) are shown (bottom, blue). F Log2 RPKM expression levels of original (light orange), novel (dark orange) Dppa2/4-dependent genes and high confidence but not differentially enriched (blue) genes across the different datasets between wild type (WT) and DPPA2/4 double knockout (DKO) cells. As a comparison the bottom 20% (light grey) and top 20% (dark grey) expressed genes are shown. G log2 normalised expression levels of previously annotated (light orange, top), novel (dark orange, middle) Dppa2/4-dependent genes compared to stable bivalent genes (blue, bottom) during 9 days of mouse embryoid body differentiation in wild type cells (left) and DPPA2/4 double knockout cells (right). Each gene has been normalized separately across the time series to aid visualisation of expression patterns, genes are grouped using correlation based clustering
Given the improved sensitivity of our method we next sought to determine whether there may be more widespread changes in chromatin bivalency in DPPA2/4 knockout ESCs compared to what had been previously reported [6, 7]. Firstly, we called peaks for the reChIP samples. This revealed 9,225 peaks that were bivalently marked in either wild-type and/or DPPA2/4 DKO cells in both reChIP directions (Additional file 2: Figure S4A) of which 5,713 were high-confidence in either WT and/or Dppa2/4 DKO cells. To determine if any peaks were gained or lost specifically in Dppa2/4 DKO cells, we performed differential enrichment test using EdgeR (Additional file
留言 (0)