
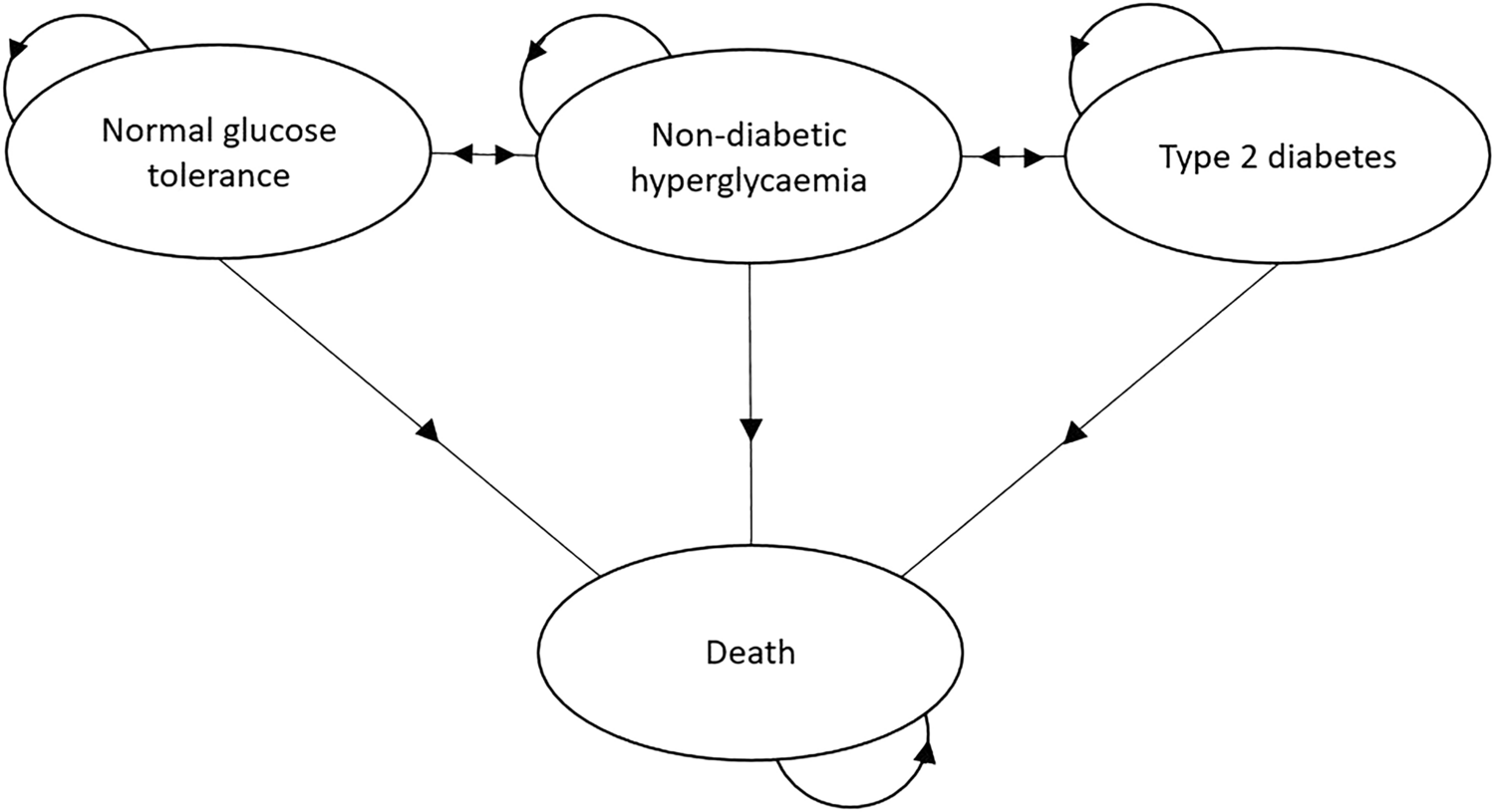
記住我


The ability of the LLM to replicate the results of manually conducted NMAs was tested using four case studies. For each of these case studies, a literature review had been conducted to identify relevant trials, followed by a feasibility analysis to determine which trials were appropriate to include in the NMA, i.e. involving a review of the study design, patient characteristics and outcomes to determine whether the trials were sufficiently similar to include in the NMA [17]. The four case studies spanned two disease areas (hidradenitis suppurativa [HS], which is a chronic, inflammatory skin disorder, and non-small cell lung cancer [NSCLC]) and two types of outcome (binary and time-to-event [survival]). These outcomes were chosen because if a prototype could be shown to work for binary or time-to-event outcomes, then it should be generalisable to other outcome types.
We have implicitly assumed that all studies included in the analyses were sufficiently homogeneous to be combined based on a previous publication [18] (NSCLC) and from a topline manual check of study design and characteristics (HS).
Case study 1 involved an indirect comparison of the efficacy of treatments for patients with moderate-to-severe hidradenitis suppurativa (unpublished literature review and analysis). The literature review had identified six relevant trials evaluating the clinical response to different treatments (adalimumab, secukinumab and bimekizumab) in this patient population, and the feasibility analysis determined that all six trials were suitable to include in the NMA. The network diagram for the analysis is shown in Fig. S1 and the trials and clinical response data are summarised in Table S1 (Online Resource).
Case studies 2, 3 and 4 concerned the efficacy of second-line treatments for patients with NSCLC. The SLR was originally conducted in 2018 and updated in 2021 [18]. Case study 2 involved treatments and outcome data (overall survival [OS]), which were used in the primary analysis (base case) of an economic model. The feasibility analysis identified five trials reporting on OS across relevant treatments (nivolumab, pembrolizumab and atezolizumab, with docetaxel as the common comparator treatment) that were appropriate for inclusion in the NMA (Fig. S2 and Table S2 [Online Resource]). Case study 3 involved an extra seven trials reporting OS for three additional treatments (nintedanib + docetaxel, pemetrexed and ramucirumab + docetaxel) that had been used in a sensitivity analysis of an economic model (Fig. S3 and Table S3 [Online Resource]). Case study 4 concerned the efficacy outcome of progression-free survival (PFS), and the feasibility analysis determined that the same five trials used in Case study 2 were appropriate for the NMA for this outcome (Fig. S4 and Table S4 [Online Resource]).
2.2 Overview of the LLM-Based Process for Automating the NMAGPT-4 (Generative Pre-trained Transformer 4, developed by OpenAI [14]) was selected as the LLM engine for this study, as it was considered superior to other publicly available LLMs at the time of study. However, the method developed for interacting with GPT-4 in this study can, in theory, use different LLMs.
To allow the LLM to generate text to specify an NMA, it was decided to choose a programming language whereby the analysis and the data could be contained within one script. R was chosen as the software in which the AI-generated analysis would be built, as it is freeware and platform (operating system) independent. To implement an NMA in R, the ‘multinma’ package was used, which implements network meta-analysis, network meta-regression and multilevel network meta-regression models [19]. Models were estimated in a Bayesian framework using Stan [20].
LLMs require the user to provide ‘prompts’, i.e. instructions stating what the user wants the LLM to do and the output required. Interaction with the LLM was achieved through application programming interface (API) calls (a way for two or more computer programs to communicate with each other) written in a Python script. The outline of the process, as shown in Fig. 2a, is as follows:
For data extraction from the publications, a prompt including text from the publication and requesting extraction of all relevant data from the supplied publication text was sent via an API call to the LLM for each publication needed for the NMA.
To produce an R script with code to run the NMA, a prompt requesting generation of an R script was passed to the LLM via an API call, along with the data from all publications and an example R script (sourced from the Vignettes for the ‘multinma’ package) [19].
To produce a small report containing a description of the disease, a description of the analysis conducted, the results of the analysis and an interpretation of the results, the LLM-generated R script was called from the Python script and the results of the NMA, along with a prompt requesting generation of a small report, were sent via an API call to the LLM.
Fig. 2
a LLM-based process for automating the NMA. b Chunking approach to data extraction. API application programming interface, LLM large language model, NMA network meta-analysis
Example prompts are provided in the Online Resource.
2.3 Prompts Used to Instruct the LLM and HyperparametersPrompts were developed that were used to instruct the LLM to:
Extract the required data for the analysis from the abstracts of the publications.
Determine if all data required was contained in the abstract and, if not, extract any missing data from the full publication.
Infer missing data from other information, e.g. the number of patients affected from the proportion of patients affected and the number at risk as well as the number of patients at risk from total trial size and randomisation ratio.
Transform extracted data to the correct format for inclusion into the model for analysis (number affected for binary outcomes and log scale for time-to-event outcomes).
Generate an R script for NMA using generic script from the R ‘multinma’ package.
Interpret the results of the analysis and write a small NMA report.
The Python script was used to pass the output of each prompt to the next, with the prompts loaded into Python as strings. Almost identical prompts were used for the four analyses conducted, with the following differences: use of relevant disease name (HS and NSCLC) and relevant outcome name (clinical response, OS and PFS); different R script examples were provided for binary and time-to-event outcomes [19], and additional contextual information was required for R script production for time-to-event outcomes (see Methods Sect. 2.4.3 below).
In addition to developing prompts, there was also a requirement to adjust some of the LLM’s hyperparameters, including role and temperature.
2.4 Prompt Development and Key LearningsThe prompts used have a significant impact on the output quality of the LLM. To evaluate the LLM’s capability to perform the required tasks, it was essential to create prompts of sufficient quality to obtain the required responses. Therefore, the following prompt creation process was followed: for each outcome type, initial prompts were generated and given to the LLM. The returned output was evaluated and, based on the contents, adjustments were made to the prompts. The adjusted prompts were then sent back to the LLM for further testing and evaluation. This process of output evaluation and prompt adjustment continued until no further improvements could be made and final prompts were reached. An example of the development of the OS data extraction prompt is given in Fig. S5 (Online Resource).
Several key learnings were uncovered through the prompt development process, which shaped the form of the final prompts. These were: using an iterative approach to data extraction, using multiple prompts and providing contextual information, as discussed in more detail below.
2.4.1 Chunking Approach to Data ExtractionA token is a chunk of text that an LLM reads or generates. At the time of the study, GPT-4 had a token limit of 8192 (approximately 6000 words), which restricted the amount of text that could be passed to, and be generated from, a single prompt. Since all the publications used for this study exceeded this limit, there was a need to cut publications into chunks before passing them to the LLM for data extraction. As shown in Fig. 2b, we asked the LLM to screen overlapping chunks of text from the main publication (e.g. pages 1–3, 3–5, 5–7, 7–9, etc.) to ensure that all text reviewed was in context and then asked the LLM to assess whether it had obtained all data required, before providing additional text for screening. It was possible for the LLM to get to the end of the publication without extracting all required data if it failed to identify that data.
2.4.2 Multiple PromptsThe first approach for creating an R script was to ask the LLM to write an initial R script using data from the first study, and then to ask it to add data from more trials. This approach worked well for the binary outcome, where the data required for the analysis in R is number at risk and number of patients affected in each arm. However, for the time-to-event outcomes (OS and PFS), the input is a hazard ratio and standard error for each treatment comparison, and the initial approach used did not produce the right format for this input, leading to incorrect results. Thus, for the time-to-event outcomes, we asked the LLM to gather the required data (hazard ratios, error measures, etc.) from all trials before writing the R script. For consistency, this approach was also used for the binary outcome. For the analysis input, different treatments were given numbers in the R script (Fig. S7 [Online Resource]) but the LLM did not always use the same numbering for the same treatment. Therefore, it was necessary to prompt the LLM to fix this in the initial script, to match the numbers with the names and doses of the treatments. Thus, multiple prompts were used to generate the required R script:
2.4.3 Contextual InformationFor some tasks, the LLM was frequently observed to make general errors, such as not understanding statistical significance. These were not related to the content (disease and treatment) or language used in the included studies. Addressing these errors required the provision of contextual information in addition to the instructions. The contextual information was developed iteratively in the same manner as the prompts.
The LLM was initially not very successful at writing an executable R script or choosing the correct model to use for the analysis, for either outcome type. For example, the LLM sometimes invented R packages and functions that it included in the script. Including worked examples has previously been shown to improve the performance of LLMs in multi-step reasoning tasks [21]. Therefore, we provided an example script appropriate for the type of analysis needed, as contextual information for the LLM. The example scripts used were sourced from the online vignette of the ‘multinma’ package [19] (Fig. S6 [Online Resource]).
Similarly, when asked to write the R script for the time-to-event outcomes, the LLM did not always construct the input for the analysis in the correct way nor maintain the order of the treatment comparison. For instance, the LLM would try to construct a dataframe for the input data that had a row per treatment arm in the treatment names and number-at-risk columns but then would only include one row per study for the hazard ratios. It was therefore necessary to provide context to the LLM, which was achieved by including contextual statements within the code-writing prompt. For example, including the text “The order of the treatment comparison is important” ensured that the LLM maintained the treatment comparison order for each hazard ratio. Some of the trials included in the analyses treated patients with a combination of treatment plus placebo, e.g. treatment X plus placebo. Usually, when conducting an NMA, we would consider the treatment effects for these patients to be equivalent to patients treated only with treatment X. For the LLM to consistently make this assumption, and to therefore number the treatments correctly, we needed to provide contextual information, such as adding the statement, “We consider patients treated with ‘treatment X plus placebo’ to be treated with ‘treatment X’”, to the prompt asking the LLM to tidy the R script.
The LLM also required context for interpretation of the NMA results. The LLM reliably identified when a treatment outperformed the comparator, for both the binary and the time-to-event outcomes. However, we noticed that the LLM sometimes claimed that either all or none of the comparisons reached statistical significance, when in fact some did and some did not. Therefore, contextual statements, such as “A result is statistically significant if the lower and upper bound for the credible interval are either both greater than 1 or both less than 1”, were included.
To summarise, the following contextual information was provided to the LLM: example R scripts for the analysis, the importance of the order of the treatment comparison when considering a hazard ratio, the assumptions generally made when considering equivalence of treatments and the definition of statistical significance.
2.5 Non-text-Based PublicationsFor all case studies considered, some of the publications needed for the case study were text-based, whilst some were photographs of presentations, or posters, or contained data within figures. Whilst it is now possible to ask an LLM to receive images as input (e.g. with GPT-4 Vision, Gemini), at the time of the study, GPT-4 was not able to receive images as input and thus was not able to extract any data for these publications. The trials that had image-based publications and the approach taken to obtain data are listed in Table 1.
Table 1 Non-text-based publications and approach to data extraction2.6 LLM Hyperparameters‘Role’ and ‘temperature’ are some of the hyperparameters that can be used to control the behaviour of GPT-4. Assigning a role to the LLM is a simple way to add context to a prompt, for example if you assign it a role of ‘a poet’, the style, and possibly the content, of the response will be different from that obtained if the role assigned is ‘a surly teenager’ [22]. Thus, there was a need to assign an appropriate role to GPT-4. We found that by telling GPT that it is a statistician and a medical researcher, we obtained the type and quality of responses that we needed.
The temperature parameter of GPT-4 is a number between 0 and 2 that determines the randomness of the generated output. A lower value for the temperature parameter will lead to a less random response, whilst a higher value will produce a more creative and/or surprising output. We wanted the responses to be as deterministic as possible, so we set the temperature to be 0.
Default values were used for all other hyperparameters.
2.7 Output Generation and AssessmentFor each case study, a single Python script included the final set of prompts for interaction with the LLM and commands for the generated R script to run and to obtain the results of the analysis (Fig. 2a). Each Python script was run end to end, without human intervention, and produced an R script and a short report describing the disease area and method of analysis, presenting the NMA results and providing an interpretation of the results.
Reproducing results with LLMs can be difficult because of random elements at play that vary outputs over time [23], i.e. LLMs do not produce deterministic results. As previously mentioned (Sect. 2.6), temperature is one of several hyperparameters that control the behaviour of GPT-4. Despite setting the temperature of GPT-4 to 0 (least random), outputs were observed to vary when the same prompt set was used on multiple occasions. Therefore, we ran the Python script end to end 20 times for each analysis (80 runs in total) to capture variation in performance.
The performance of the LLM was assessed in three stages:
Assessment of data extraction: for each run, did the LLM correctly extract all required data from each trial? This was evaluated by comparing outputs from the LLM with data extracted/checked by two of the investigators (SLR and NMA experts).
Assessment of R script (evaluated by one of the investigators, an NMA expert familiar with R and who wrote the R script for the manually conducted NMAs):
oDid the LLM produce an R script that contained all relevant extracted data and the correct functions to conduct an NMA?
oCould the script be run without human intervention? If not, was minor (less than 2 minutes of work) or major (more than 2 minutes of work) editing required to enable this?
oDid the script produce results that matched the same NMA conducted by a human?
Assessment of the NMA report (qualitatively assessed by one of the investigators, familiar with the disease area):
oWas a reasonable description of the disease area provided?
oWas the methodological description of the analysis correct?
oWere correct results presented?
oWas the interpretation of the results correct and informative?
留言 (0)