
記住我


While the materials in Deauvieau et al. (2014) consisted of anonymized individuals, in our study the materials consisted of the names of feminist authors and activists our participants could reasonably be expected to know. To generate the list of names, we used the CaFé corpus (see Section 2), from which we extracted all the occurrences of feminist figures cited by the interviewees, which amounted to 129 occurrences. We then selected all names of feminist figures that were cited more than once by more than one feminist activist. The idea was to obtain a list of names that are sufficiently well-known and salient to members of Parisian feminist communities so that they could be meaningfully categorized by our participants. This left us with 36 names, from which we removed figures that we hypothesized were frequently cited in the corpus because of its particularities. For example, since the corpus was originally constructed as part of a linguistics project, it contains many discussions about language and linguistic practices, so we suspected that linguists were over-represented in our names. This led to a final selection of 31 names of feminist figures which constituted our stimuli. For a list of all names, see the Supplementary Materials (though the names can also be gleaned from Table 4 or Figs. 3 and 5).
The study received approval from the ethics board of Paris Cité University (No 2022-38-bendifallah-burnett), and it was conducted online using the Qualtrics platform. The tasks were the same as in Deauviau et al. (2014)’s study. Specifically, participants were asked to sort as many of the 31 names that they recognized into at most nine groups. They could also make a tenth group for the figures that they did not know. Also as in Deauvieau et al. ’s study, they were asked to give a label to each of the groups and to identify the most representative member of each group. In the last part, we collected data about each participant (age, education, gender, sexuality, racial background) and their activism. We asked them to choose which feminist political identity term(s) they would primarily use to qualify their own feminism: “intersectional,” “materialist,” “queer,” “pro-sex,” “radical,” “decolonial” and/or “other(s).” If they chose “other(s),” they were free to write additional information.
4.1.2 ParticipantsParticipants were recruited via a large French mailing list dedicated to researchers working in gender studies. Participants spent on average 35 minutes on the survey. They were compensated with a gift card worth € 15. A total of 81 participants completed the study. They identified mostly as white (68), under 35 (65), and highly educated (62 had a master’s degree or higher); they were almost all from France (75), with many from the Parisian region (29). Thus, the participants in our study formed a rather homogeneous social group. One area in which they varied concerns gender and sexuality. Most (56) participants identified as some feminine gender identity, but there was a significant number of participants whose gender did not respect the male/female binary (20), and a small number of participants with a masculine gender identity (5). The participants were almost equally divided between identifying as lesbians (26), heterosexual women (20), and bi- or pansexual people (24), with the remaining 11 participants having some other sexual identity, such as asexual or gay man.
4.2 Results and discussionParticipants categorized the 31 feminist figures into at most nine groups. The constitutions of the groups depended first of all on how many of the names participants felt that they knew well enough to judge. Here, we found a fair amount of variation across our stimuli. For example, Simone de Beauvoir and Angela Davis were the only feminists who were known by all 81 participants, although Judith Butler, Olympe de Gouges, and Virginie Despentes were known by 80.Footnote 18 This being said, all but four feminists (Gwenola Ricordeau, Joan Scott, Jules Falquet, and Michelle Perrot) were known by at least two thirds of the participants, and only Scott and Ricordeau were known by fewer than half of the participants (40 and 35, respectively). We therefore consider our technique of using the corpus to generate the stimuli as successful at providing a set of feminists who are relevant and salient to the community that we wanted to study.Footnote 19
Participants varied with respect to how many categories they employed. While the design of our study allowed for nine categories, many participants used fewer. In fact, the average number of categories used in a single categorization schema was 7.5 (SD = 1.6). The fewest number of categories used was three (three participants), and 31 participants used the maximum number of nine. In addition to categorizations based on feminist political identity terms (materialist, queer, intersectional, afrofeminist, decolonial, lesbian feminist, universalist, etc.), participants made categorization schemas based on other kinds of considerations, as indicated by the category labels they used. These included profession (politicians vs. journalists vs. academics), temporality (historical figures vs. contemporary figures), political spectrum (left wing vs. right wing), and nationality (French feminists vs. American feminists). And, although there were some participants who made their groupings strictly according to feminist political identities—for example, participant 38 who proposed the categorization schema in Table 1—the majority proposed categorizations like participant 44, given in Table 2, which mix political identities with professions, temporality, platforms, and so on.
Table 1 Categorization of participant 38The size of the groups also varied, as Tables 1 and 2 show. Some groups are singletons and others contain many names. The feminist who was most often put in a class of her own is Beyoncé (25 participants), followed by yourself, where 12 participants created special singleton “me” categories (and three considered that their self was unknown).
Table 2 Categorization of participant 44In addition to collecting self-identification data, we also asked participants to put themselves in a group. However, we did not incorporate this data in the construction of our similarity and conceptual spaces. Unlike the self-identification which focused on feminist political identities, participants’ self-categorization took into account various other criteria, including hobbies, temporality, profession, and topics of interest. For instance, participant 2 used a single category to categorize themselves as a “reader,” participant 7 classified themselves as a “contemporary intersectional,” participant 11 labeled themselves as an “academic feminist,” and participant 12 identified as a “thinker.”
4.2.1 Constructing a similarity spaceAs described in the previous section, the first step in constructing a conceptual space is to build a similarity space. Because the yourself item was unlike the others (being a kind of variable and often appearing in its own special “me” group), we discarded it from the analyses. Therefore, in what follows, we construct a similarity space in which we locate the 31 feminist names.
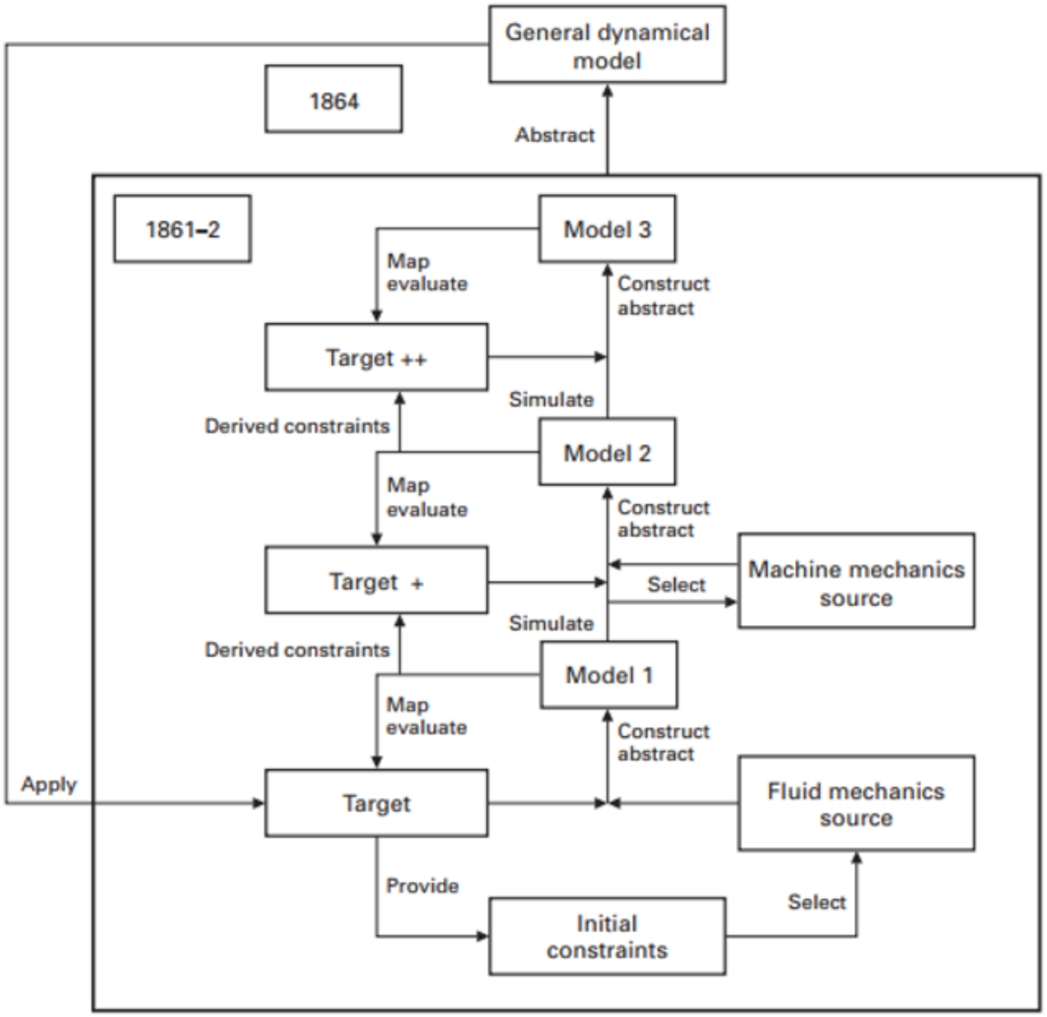
Following Deauvieau et al. (2014), we derive similarities from how often our participants group figures together in some group, which we can represent in a co-occurrence matrix, as shown in Table 3. As this table indicates, Olympe de Gouges and Simone de Beauvoir were grouped together by 53 participants; Gouges and Virginie Despentes were grouped together by 6 participants; and so on. Specifically, we start by calculating the correlation coefficients among the columns of this table (or equivalently, given that it is symmetric, among its rows). These are visually represented in Fig. 1. Next, we use the function \(f(r) = \sqrt\), as for instance implemented by the cor2dist() function in the psych package (Revelle, 2023) for the statistical computing language R, to turn the correlation coefficients into distances.Footnote 20
Table 3 Initial rows and columns of the co-occurrence matrixFig. 1
Plot of correlation coefficients among columns (or equivalently, rows) of Table 3
To obtain the actual space, then, we apply an MDS procedure to these distances. More exactly, we used the SMACOF algorithm, implemented in the smacof package (Mair et al. , 2022) for R, to construct spaces with numbers of dimensions ranging from 1 to 6. As already briefly mentioned in Section 3.1, goodness of fit for MDS output is commonly measured in terms of stress, where the stress value indicates how closely the distances between objects in the configuration resulting from the MDS procedure match the similarities between the items underlying the distance matrix. The left panel of Fig. 2 shows the stress values for the results of the various MDS solutions we obtained. The figure also allows us to compare these values, for each relevant number of dimensions, with the stress values associated with 250 other MDS solutions with the same number of dimensions, where these other solutions were based on random similarity matrices. According to some authors (e.g., Dexter et al. 2018), this gives a better indication of how good an MDS solution is than its associated stress value considered in isolation. In the figure, it is seen that stress diminishes sharply (and thus goodness of fit increases sharply) when we move from one to two dimensions, and then substantially from two to three dimensions, but less so when we move to higher dimensions. Also, we see that the three-dimensional model has a stress value of .1, which is considered good. The right panel of Fig. 2 shows specifically for this model that its fit is significantly better than what could be expected by chance. We thus decided to go with the three-dimensional model, which is visualized in Fig. 3.Footnote 21
As a quick sanity check, one can observe that, for instance, Olympe de Gouges, the 18th century feminist author and revolutionary, is much closer to Simone de Beauvoir, whose foundational work laid the groundwork for second wave feminism, than to Sam Bourcier, the contemporary queer scholar and transfeminist activist. Likewise, Bourcier is much closer to Judith Butler, with whom he shares a political orientation, than Butler, American queer academic, is to Elisabeth Badinter, one of the main figures of French universalism. This is all exactly as should be.
Fig. 2
Left panel showing stress values of n-dimensional MDS models based on our data, for \(n = 1,\ldots , 6\) (in blue), plotted together with stress values of 250 n-dimensional MDS models based on random similarity matrices (in purple); right panel showing stress values for the specific case of \(n=3\)
Fig. 3
Pairs of dimensions of the three-dimensional similarity space based on the co-occurrence matrix partially shown in Table 3
More importantly, however, we explained in Section 3.1 that, in an MDS analysis, one not only aims at a low-dimensional and well-fitting representation of the input data, the dimensions of the space in which the data are represented should also be interpretable. For the space that came out as best of the MDS procedure, the interpretation of the dimensions seems rather straightforward. The first dimension has the politicians Anne Hidalgo, Marlène Schiappa, and Christiane Taubira, along with the politically active writers Elisabeth Badinter and the activist Caroline de Haas, on one end, and the academics, such as bell hooks, Kimberlé Crenshaw, Jules Falquet, Judith Butler, Sam Bourcier, and Paul Preciado, on the other end. In the middle, we find authors, journalists, and artists, such as Beyoncé, Victoire Tuaillon, and Virginie Despentes. Thus, a plausible interpretation of the first dimension is that it is “profession” related, plausibly indicating degree of (explicit) political engagement, with the two extremes being “politician” and “academic.” Another plausible interpretation concerns radicality ranging from institutional feminism to a more revisionary kind of feminism. Institutional feminism focuses on creating change within existing institutions and systems. Politicians would be good representatives of this kind of feminism but this interpretation would also allow Beyoncé and Chollet, who are not politicians but are closer to this group, to be interpreted on this continuum. On the other hand, revisionary feminism seeks to challenge power dynamics by incorporating intersectionality and a more nuanced understanding of gender identity. This includes intersectional, materialist, and queer figures that can be found on the other end of the dimension.
The second dimension depicts scholars who work on sexuality (and gender), particularly in queer studies (Butler, Preciado, Bourcier, Wittig) on one end, and scholars whose work investigates questions related to race and gender (hooks, Davis, Crenshaw, Vergès) on the other. The politicians, artists and journalists are in the middle, as are the lesser known academics (Ricordeau, Scott, Perrot, Falquet) and major figures of French materialist feminism such as Christine Delphy and Colette Guillaumin. Note however, that Dorlin, Guillaumin and Ricordeay are closer to Vergès, Crenshaw, Davis, and hooks, than Delphy is, possibly reflecting their focus on race. Thus, we consider that dimension 2 can be described as representing a focus on sexuality–focus on race continuum.
The third dimension is a bit harder to interpret. It is characterized by a large separation between Olympe de Gouges, Simone de Beauvoir and the early 20th century writer Virginia Woolf on one end, and all the other feminists on the other. Given that Gouges, Beauvoir, and Woolf are the only figures in our stimuli whose most famous activities took place before the 1960s, we suggest that dimension 3 corresponds to some kind of “temporality” scale. Interestingly, there do not appear to be clear temporal distinctions within the large cluster of contemporary feminists. Within this large group, the feminists do not appear to be ordered by age: Joan Scott and Michelle Perrot are from an older generation than Beyoncé and Mona Chollet, yet they appear further away from Beauvoir, Gouges, and Woolf on the third dimension. More generally, the participants in our study do not seem to be distinguishing between different “waves” of feminism: Judith Butler, Monique Wittig, and Virginie Despentes are all practically at the same point on dimension 3, yet Wittig is generally considered to be a “second wave” feminist, while Butler and Despentes are important figures of the “third wave” in France and abroad (Schaal , 2017). Thus, the relevant temporal distinction to our participants appears to be something like historical figures (mid 20th century or before) versus contemporary figure (late 20th/early 21st century).
In short, the above considerations suggest that our best space has a politicians–academics dimension, a sexuality–race dimension, and a historical–contemporary dimension.
4.2.2 Partitioning the spaceRecall that a conceptual space consists of both a similarity space and a partition of that space into cells, which are supposed to represent a family of concepts. As previously explained, the most common way to partition a space is through first identifying a relevant set of prototypes and then letting those generate a Voronoi tessellation. In our study, as a way of trying to obtain prototypes, we asked participants to indicate which feminist they considered to be the most representative of the group, for each group that they constructed. But this procedure failed to yield useful results, possibly because participants used different categorization strategies but possibly also because we are dealing with a conceptual domain for which the notion of prototype is unhelpful (see note 14).Footnote 22
Thus, instead of using prototypes to define the concepts in the similarity space (i.e., going “top down”), we decided to go “bottom up” and use the clustering approach also mentioned in Section 3.1 to identify which feminists are to fall under the same concept. In particular, we used the PAM clustering algorithm, implemented in R in the cluster package (Maechler et al. , 2022), which, as previously said, is a more robust version of the older k-means clustering and, like it, aims to partition a number of items into k clusters in such a way that, broadly speaking, within-cluster similarity and across-cluster dissimilarity are jointly maximized.
It was also noted that the number of clusters needs to be pre-specified, which is to say that the algorithm will not pick that number for us. The standard way to determine the optimal number of clusters is to run the algorithm for a range of numbers of clusters and then compare the goodness of fit of the various resulting solutions, which in the case of the present algorithm can be done by considering how similar the items in each of the clusters are to the medoid of that cluster, which measures the within-cluster similarity (as explained in Section 3) as well as by considering the minimal dissimilarity between items in different cluster, which measures the across-cluster dissimilarity. Figure 4 plots both the within-cluster similarity and across-cluster dissimilarity for PAM applied to the coordinates of the feminist figures in our best similarity space, fitted on the basis of the responses from our participants, for number of clusters going from 3 to 8. In general, increasing the number of clusters yields better fit, which could suggest putting each item in its own cluster. However, that would yield a completely uninformative clustering. Ideally, then, what one finds in the kind of plot shown in Fig. 4—a so-called scree plot—is a discernible “elbow,” indicating that, for some given n, by going from n clusters to \(n+1\) clusters we obtain a notable improvement in fit but then by going from \(n+1\) clusters to \(n+2\) clusters, much less improvement is achieved, in which case we would go with \(n+1\) clusters. We do find this in Fig. 4, at least for across-cluster dissimilarity, where we get a big improvement by going from 3 to 4 cluster and then again by going from 4 to 5 cluster, but then going to 6 or more clusters hardly improves the across-cluster dissimilarity. We thus decided to to go with a partition into five clusters. The result is shown in Table 4, along with the list of the labels that were most often used to the members of these groups. Figure 5 depicts the conceptual space this clustering gives rise to.Footnote 23
Fig. 4
Average dissimilarity within a cluster (blue) and minimal dissimilarity between clusters (purple) for PAM solutions, with number of clusters going from 3 to 8
We see that the first cluster consists of Sam Bourcier, Judith Butler, Alice Coffin, Virginie Despentes, Paul Preciado, Victoire Tuaillon, and Monique Wittig. As mentioned above, Butler, Boucier, and Preciado are the main representatives of queer feminism in France, and so, unsurprisingly, the most commonly used label for the members of this group was queer (156 times). Queer was actually the clear winner for this category, with the next most frequent label being lesbian with only 68 occurrences for the members of this cluster.
The second cluster consists of the politicians Elisabeth Badinter, Caroline Fourest, Anne Hidalgo, Marlène Schiappa, Christiane Taubira, the activist and consultant Caroline de Haas and the journalist Mona Chollet who is primarly known for her books exploring feminist perspectives. Interestingly, the most common label applied to members of this group is not (really) feminist (101 times), but this is closely followed by the profession politician (91 times). The third most common label is racist, but this is less common (only 56 occurrences).
Table 4 Clusters of feminist figures resulting from applying PAM, with five clusters, to the distances derived from the co-occurrence matrix shown in Table 3Fig. 5
Pairs of dimensions of the conceptual space of French feminism
The third cluster consists of the three figures who were distinguished by the third dimension of our space, Simone de Beauvoir, Olympe de Gouges, Virginia Woolf, along with Beyoncé. By far, the most common label for this group is historical figures (125 occurrences), followed by mainstream feminists (35) and then authors (26). At first, it looks like we have the same situation as with Group 2: the same group of feminists is labelled differently by different participants. However, the situation with Group 3 is actually quite different: all the occurrences of the label historical figures are applied to Beauvoir, Gouges, or Woolf, and almost all the occurrences of the label mainstream feminists are applied to Beyoncé (26/35). As just explained, this is due to the “granularity” of our clustering: in the clustering solution for \(k=6\), we find that Beauvoir, Gouges, and Woolf form a separate cluster, with Beyoncé and Chollet ending up in a cluster with Coffin, Despentes, and Tuaillon.
Group 4 consists of five feminists whose work often focuses on gender and racial issues: Kimberlé Crenshaw, Angela Davis, Amandine Gay, bell hooks, and Françoise Vergès. By far, the most common label for the members of this group is intersectional (153 occurrences). This being said, this group is also frequently described as afrofeminist (79 times) and decolonial (66 times). Again we see a multitude of terms applied to the same group of people (like Group 2), and this result provides insight into the source of the conflict described in (8). Recall that, in that passage, two feminists disagreed whether the label intersectional is synonymous with afrofeminist. Our results show that for many people, it is not, but for some, it is.
Finally, Group 5 consists of the feminist academics Christine Delphy, Elsa Dorlin, Jules Falquet, Colette Guillaumin, Michelle Perrot, Gwenola Ricordeau, and Joan Scott. Unsurprisingly, the most common label is academics (90 times), but this is followed closely by materialists (74 times). Once more we see participants using multiple labels applying to the same figures. In this case, it is a more similar situation to Group 2, where participants varied between a “profession” based categorization and a “political identity” based categorization of the same figures, rather than to Group 3 where the two labels applied principally to different subgroups.
Note that studying the labels given to the categories by our participants suggests somewhat alternative interpretations of the first two dimensions of our similarity space. Specifically, based on the labels, it would also be reasonable to interpret the politicians–academics dimension as a non-feminists versus feminists dimension and to interpret the sexuality–race dimension as a queer versus intersectional dimension, with the materialist feminists forming a sort of midpoint on that dimension.
4.2.3 DiscussionThe results of our conceptual spaces analysis give us a new understanding of how feminism in France is structured, at least in the minds of our participants. Using the CSF, we have discovered that, in the minds of feminists on an academic mailing list, there is a strong relationship between being an academic and being considered a (real) feminist. We also discovered that, within the feminist academic space, the salient oppositions are intersectional/focusing on race versus queer/focusing on sexuality. We observe that this opposition does not correspond to ones that are generally identified in the feminist domain (including by speakers in the CaFé corpus): intersectional versus universalist; anti-racist versus racist; queer versus materialist; and so on. This is an interesting finding, because these conflicts do appear in the language found in the group labels: members of the politicians/not feminists group are sometimes referred to as racists and universalists by participants. But, when the general patterns of categorization are taken into account, the polar opposite of bell hooks turns out not to be Marlène Schiappa, but Judith Butler. Likewise, the polar opposite of Butler is hooks, not the materialist Christine Delphy (who occupies a “neutral” middle position on the relevant dimension). Finally, we also discovered that, at least with this particular set of stimuli, the pertinent temporal distinction is between feminists who were active before the 1960s and those who made their most notable contributions afterwards. The third dimension thus defines an age of “contemporary feminism” for our participants, most of whom are under 35. Because of these new insights, we argue that our application of the CSF to this complex social domain has been enlightening, and we believe that this opens the door to more investigations of social concepts using this methodology in the future.
With respect to conceptual engineering: we saw that, using PAM clustering to partition the three-dimensional Euclidean similarity space into five categories leads to a plausible explication of the meanings of feminist political identity terms. In this approach, using the term queer as an identity term—as in Elle est queer (“She is a queer feminist”)—involves locating a person in the region of our conceptual space where Judith Butler, Sam Bourcier, Monique Wittig, and Paul Preciado are also located, or, alternatively, communicating that they have a high value on the feminism dimension, and a low value on the queer–intersectional dimension. Saying that someone is a matérialiste communicates that they are located in the same region of conceptual space as Christine Delphy, Colette Guillaumin, Adrienne Rich, Jules Falquet, among other people: they have a high value on the feminism dimension, and no extreme value on the queer–intersectional dimension. Identifying someone as intersectionnelle locates them in the same part of the space as Kimberlé Crenshaw, Angela Davis, bell hooks, Amandine Gay, and Françoise Vergès, specifically in an area with a high value on both the feminism and queer–intersectional dimensions. Finally, identifying someone as a féministe (tout court) involves placing them in a space that has a high value on the feminism dimension, a space that is devoid of politicians.
留言 (0)