
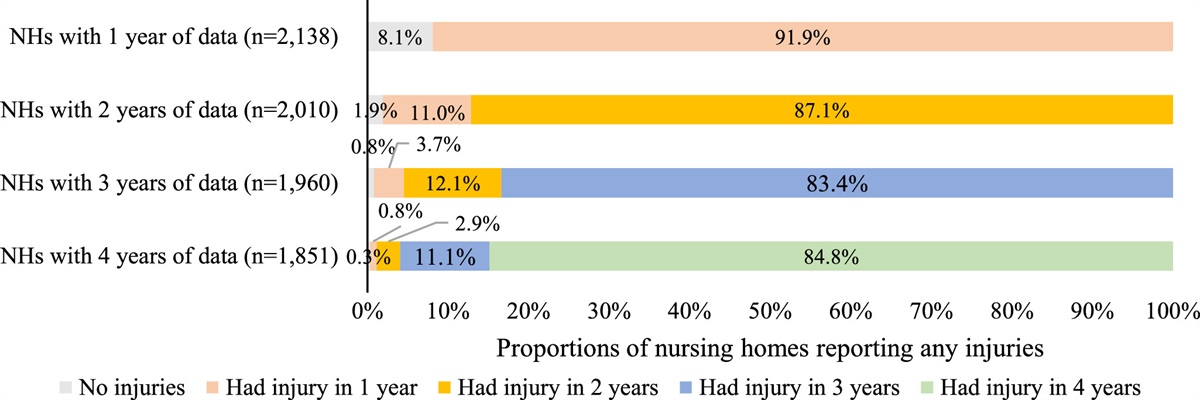
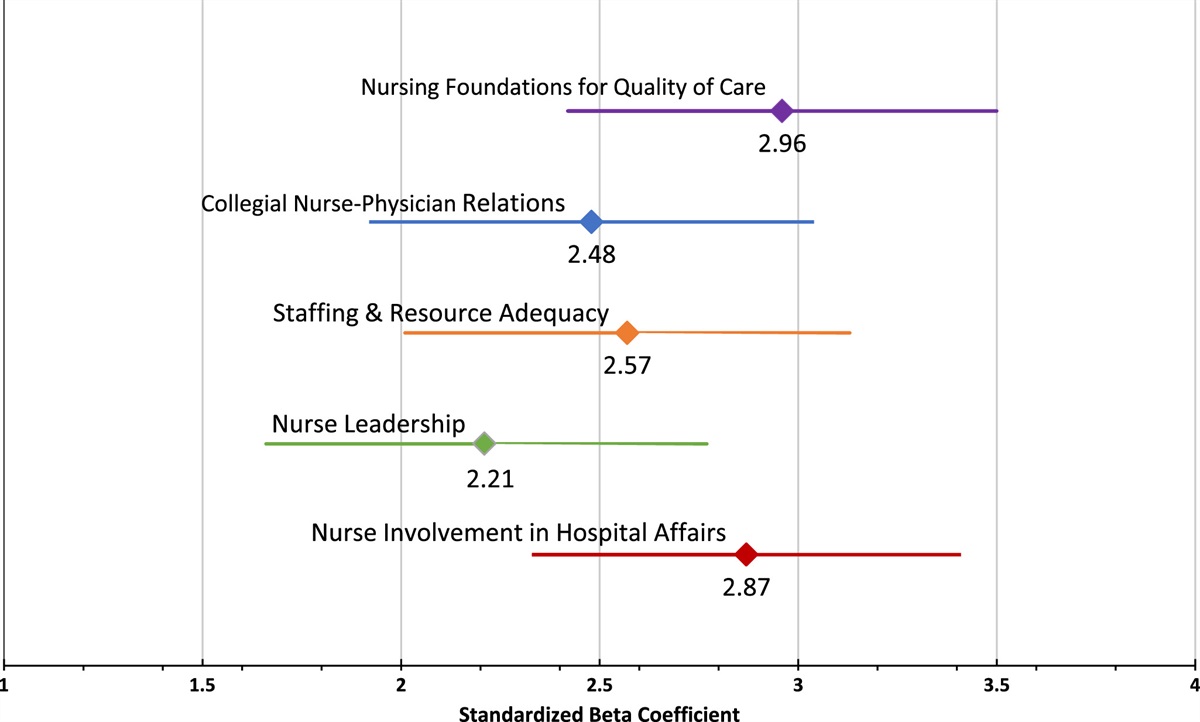
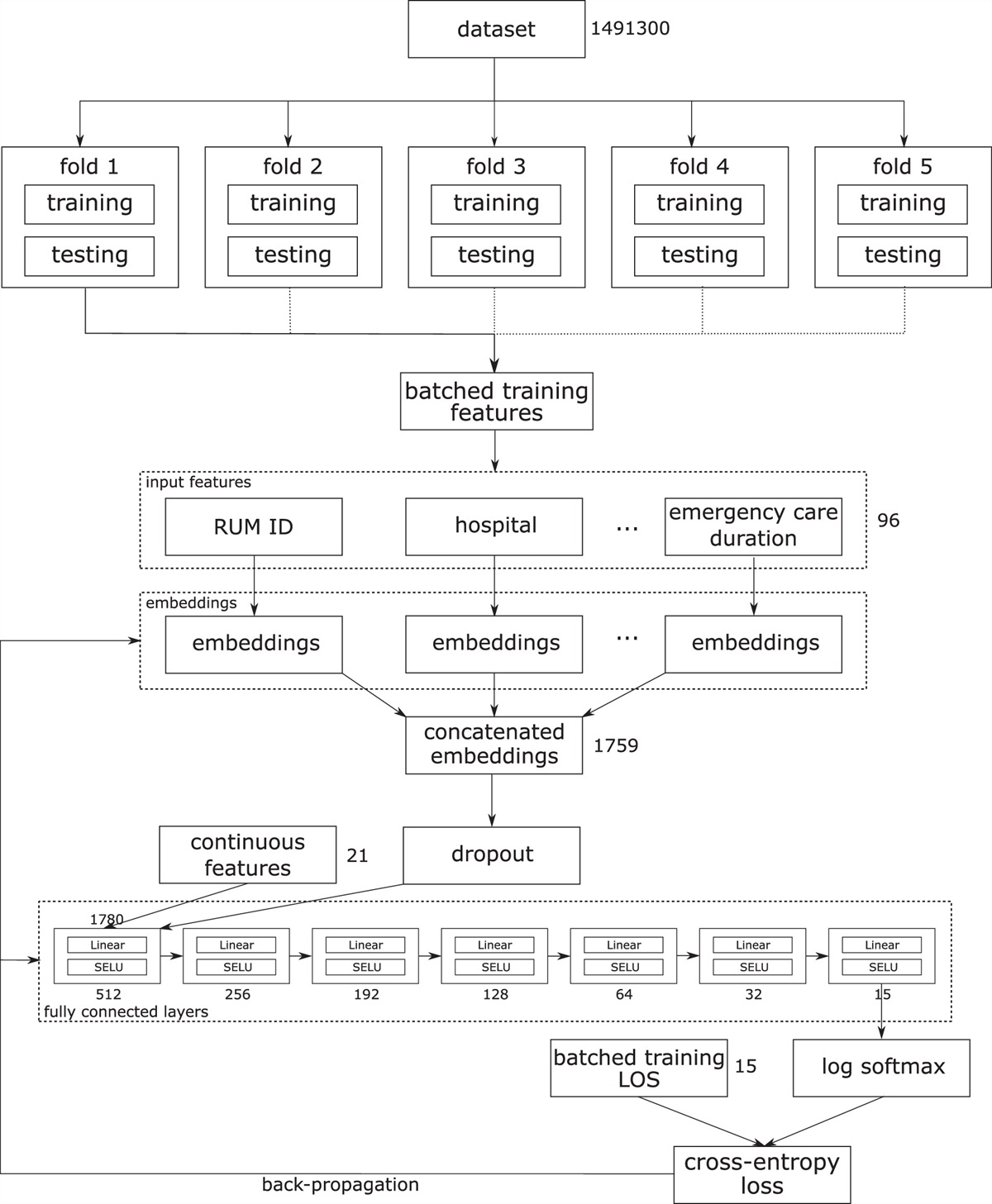
記住我
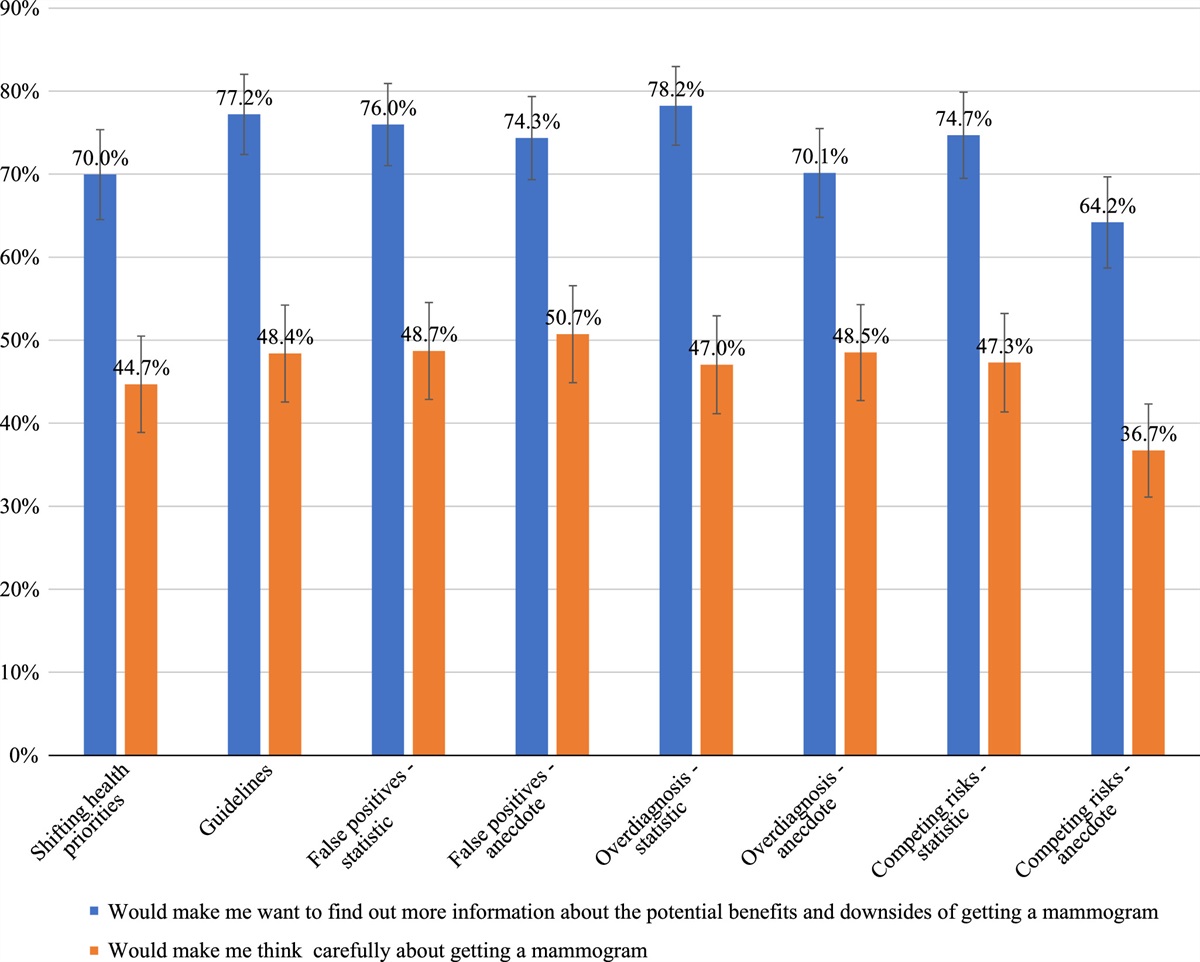



The financial burden associated with illness and medical care in the United States is increasingly well-appreciated, though in many cases patients need to make treatment decisions without comprehensive information about how these choices will impact their economic well-being longer term.1–8 Calculating the full burden of disease is difficult because of the many elements that can contribute, such as lost wages from time out of the workplace or early retirement, out-of-pocket health spending, and modifications to homes or vehicles. Further, many studies have been restricted to studying financial impacts on the individual patient despite evidence that one person’s illness also impacts other members of the household. Family and friends may have to change their own employment status or hours worked to provide informal care or take on debt to pay for medical care for a loved one. In addition, the financial burden may accumulate over time as informal caregivers lose opportunity for promotion and higher salaries at work due to time spent caregiving. Figure 1 demonstrates some of the ways that an illness can impact patients and their families and caregivers over time.
 FIGURE 1:
FIGURE 1: Sample short-term and long-term impact of patient illness on family finances.
Researchers attempting to understand the full financial burden of patients’ illnesses currently face data limitations.9 Administrative data allow large-scale linkages of registry or claims data to information about economic outcomes such as credit report data. This enables us to follow patients for years after disease or injury onset.10,11 However, these studies have generally been restricted to following the patient’s own outcomes, even though we know that other members of the family often need to change their labor supply to accommodate caregiving or ensure access to health insurance.
Survey data have helped us to understand some of the costs of family caregiving and employment consequences for spouses, parents, and children. However, use of survey data generally means either focusing on a convenience sample at a single or a few institutions, data from a single point in time, or relying on small and nongranular samples from a nationally representative survey, such as pooling all cancers in the Health and Retirement Study (HRS). Pooling recent waves of common survey datasets generated only 675 of 27,803 HRS interviews in 2016 and 2018 with new cancer diagnoses and 421 of 28,834 Panel Study of Income Dynamics (PSID) 2017 and 2019 interviews. Each diagnosis impacted an average of 2.16 householders in the HRS, which is representative of adults 50 and above, and 2.56 householders in the nationally representative PSID. Nationally representative surveys that include economic outcomes are simply too small to study most diseases. However, this information is critical to improve patient outcomes by mitigating economic harms, informing public policies and service delivery, and supporting treatment choice comparisons conditional on disease.
The current lack of a large household dataset for health research is a surmountable barrier. Linking household members based on exact addresses provides an opportunity to link household health and economic outcomes. This would be particularly useful for understanding the impacts of pediatric diseases on parents and studying long-term economic consequences of illness. These data currently exist, and could vastly expand our knowledge of the financial burden of illness at the household level, but are currently extremely difficult to access. For example, Matta et al12 identify couples in Medicare claims data who share an exact address and zip code history. This process took >4 years to complete between negotiating data use agreements, using geographic information systems to clean text-based address fields that were not designed for research use, and developing the couple algorithm. This timetable is unlikely to be feasible for many research teams, especially those led by junior investigators. Further, exact address data are highly identifiable and require secure computing environments that many researchers lack.
Using address data as an intermediate step to creating a household roster dataset that researchers can access through appropriate secure computing environments would be a boon to researchers interested in the financial burden of disease, as well as other topics important for patient care, such as whether the presence of other adults in the household reduces readmission risk. A sharable data file could be used across multiple environments or many candidate datasets could be submitted to a single source for aggregating. To date, we know of 3 possible approaches for researchers to access household composition. Table 1 summarizes these options. The Census Bureau’s Master Address File (MAF), which synthesizes address data from multiple sources is likely most comprehensive. This file, along with the MAF-Auxiliary Reference File, which provides streamlined information in the form of a household identifier and identifiers of all individuals living at that household, can be accessed through Census Restricted Data Centers only and have seen little health research use thus far.13
TABLE 1 - Currently Available Address Data Sources Data source Strengths and weaknesses Census Bureau’s Master Address File/MAF-Auxiliary Reference File Synthesizes multiple sources of address dataA second strategy relies on addresses from a single provider, such as the Centers for Medicare and Medicaid Services or the Social Security Administration. These addresses would have to be harmonized to ensure that households are correctly enumerated. This approach can be challenging when respondents live in apartment buildings and other larger dwellings, especially if apartment numbers are not consistently recorded. Matta and colleagues were able to identify some but not all of the expected number of couples using Medicare claims data alone, suggesting that this application could work well for some research designs, particularly those that would not be limited by a nonrandom sample of couples. Finally, credit bureaus themselves do address-based householding using proprietary methodology that may be similar to other models described above, but challenging for researchers to review or verify.
Given the extreme sensitivity of exact address data and time cost of processing, we recommend that researchers use existing household rosters whenever possible. A single, standardized file, possibly a random sample of the MAF-Auxiliary Reference File, would be a good tool for reducing effort in recreating household rosters and limiting the need for exact address access. This type of approach can currently be used to link to datasets with Census identifiers within the Census RDC environment. However, many datasets that are important for health research in general and the economic burden of illness, in particular, are not Census data products and are not currently available in Census RDCs.
One of the biggest challenges that will need to be overcome to maximize the utility of a new household roster dataset is facilitating Personally Identifying Information (PII) based crosswalks such as Social Security Numbers (SSN), full names, and dates of birth so that a researcher could, for example, connect a hospitalized child in state all-payer data with their parents’ Social Security earnings or Experian credit report. Many agencies do not release SSNs and other PII to preserve confidentiality. It is possible to generate a random sample of SSNs and submit this file, possibly with an anonymous study ID for merging, to request data from multiple sources. However, the odds of generating pairs of random SSNs that could map to couples or parents/children are implausibly slim. Thus, federal agencies and other data providers would need to find secure ways of facilitating the transfer of identifiable household rosters. This process could be overseen by an agency with fewer restrictions on information transfer in order to accommodate multiple modes of data sharing. Some providers, like the Centers for Medicare and Medicaid Services, only transfer data using encrypted hard drives, while the credit bureaus can only send or receive data via secure FTP. In the short term, sending additional datasets with PII to the Census Research Data Centers could expand health research that can use the household as the unit of analysis.
Additional analytic work will be needed to crosswalk co-residence at a point in time to family and household structure. In 2022, 35.7% of American households were comprised of nonfamily members.14 Family and household composition can change over time and these outcomes themselves can be important consequences of health events or treatment choices. While linking family economic outcomes to patient illness and treatment represents an important step forward, this method will not help us to see things like informal caregiving or financial contributions from friends and family who do not reside with the focal patient. Companion research to determine what share of costs are typically shouldered by coresidents versus non-coresidents and how this varies with demographics such as age, sex, and race/ethnicity would help the generalizability of address-based research.
Creating data resources to track households across datasets has the potential to vastly increase what we know about the financial burden of disease and the economic tradeoffs associated with alternative treatment regimes. These strengths can justify investment in a household roster crosswalk. Recognizing the sensitivity of the roster itself along with datasets that it would support implies that datasets should be used in very restricted environments such as the Census RDCs, with trusted data brokers available to provide matching information across data providers. We recommend a coordinated, Federal investment in these data to bolster research progress while minimizing duplicative researcher efforts and ensuring high levels of data security and privacy protection.
ACKNOWLEDGMENTSThe author acknowledge funding from the Office of the Assistant Secretary for Planning and Evaluation (ASPE) to support travel to the Symposium on Building Data Capacity to Study Economic Outcomes for Patient-Centered Outcomes Research that was held on December 5, 2022 and provided an opportunity for the authors to present their work and receive feedback from attendees. Philip Pendergast from the Rocky Mountain Federal Statistical Research Data Center provided helpful comments on an earlier draft.
REFERENCES 1. Donley G, Danis M. Making the case for talking to patients about the costs of end-of-life care. J Law Med Ethics. 2011;39:183–193. 2. Hanly P, Ceilleachair AO, Skally M, et al. Time costs associated with informal care for colorectal cancer: an investigation of the impact of alternative valuation methods. Appl Health Econ Health Policy. 2013;11:193–203. 3. Zafar SY, Peppercorn JM, Schrag D, et al. The financial toxicity of cancer treatment: a pilot study assessing out-of-pocket expenses and the insured cancer patient’s experience. Oncologist. 2013;18:381–390. 4. Dobkin C, Finkelstein A, Kluender R, et al. The economic consequences of hospital admissions. Am Econ Rev. 2018;108:308–352. 5. Nicholas LH, Langa KM, Bynum JPW, et al. Financial presentation of Alzheimer disease and related dementias. JAMA Intern Med. 2021;181:220–227. 6. Bradley CJ, Bednarek HL. Employment patterns of long-term cancer survivors. Psychooncology. 2002;11:188–198. 7. Oberst K, Bradley CJ, Gardiner JC, et al. Work task disability in employed breast and prostate cancer patients. J Cancer Surviv. 2010;4:322–330. 8. Yabroff KR, Bradley C, Shih Y. Understanding financial hardship among cancer survivors in the United States: strategies for prevention and mitigation. J Clin Oncol. 2019;38:292–301. 9. Nicholas LH, Davidoff AJ, Howard DH, et al. Cancer survivorship and supportive care economics research: current challenges and next steps. J Natl Cancer Inst Monogr. 2022;2022:57–63. 10. Scott JW, Scott KW, Moniz M, et al. Financial outcomes after traumatic injury among working-age US adults with commercial insurance. JAMA Health Forum. 2022;3:e224105. 11. Dean LT, Nicholas LH. Using credit scores to understand predictors and consequences of disease. Am J Public Health. 2018;108:1503–1505. 12. Matta S, Hsu JW, Iwashyna TJ, et al. Identifying cohabiting couples in administrative data: evidence from Medicare address data. Health Serv Outcomes Res Methodol. 2021;21:238–247. 13. Genadek K, Sullivan J. Using the Census Bureau’s Master Address File for Migration Research; 2022. 14. US Census Bureau. America’s Families and Living Arrangements: 2022. 2023.
留言 (0)