
記住我
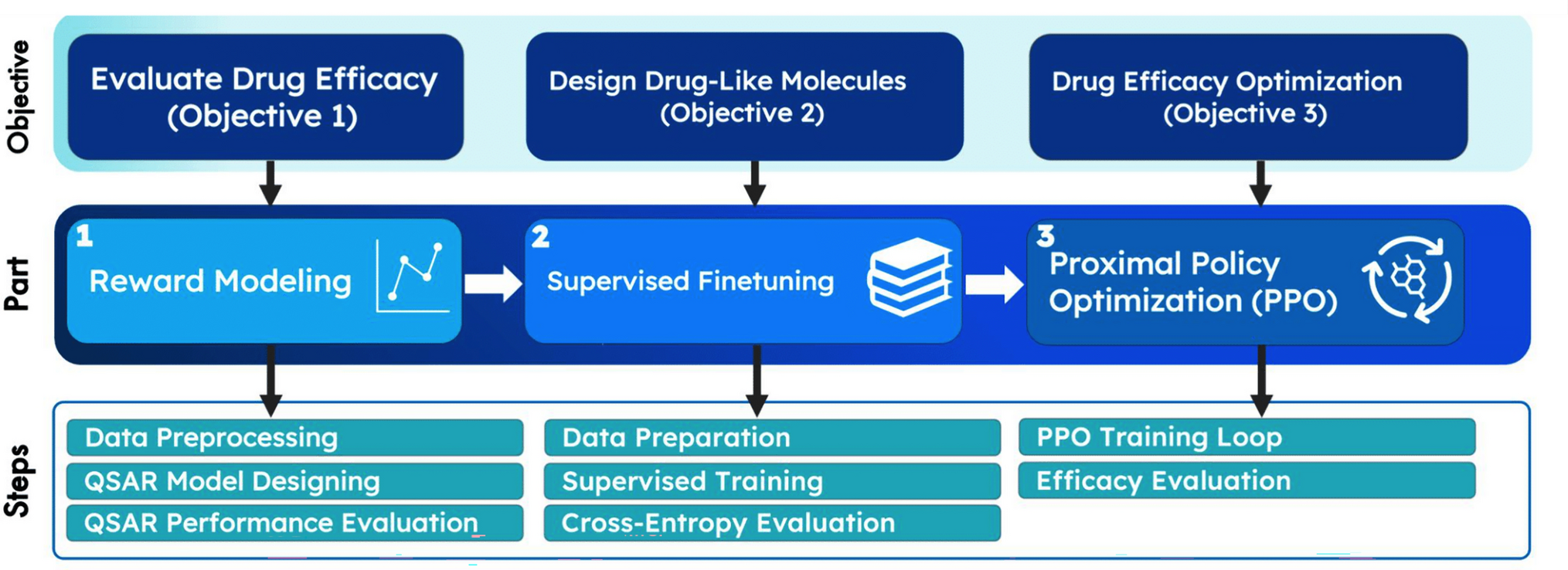

The proposed framework consists of a Generator of molecular structures and a Predictor, which estimates the biological activity of the compounds against the USP7 target. As indicated in Fig. 1, the two DL models are combined to implement a conditioned generation dynamic through RL. The objective is for the Generator to learn how to explore the most promising zones of the chemical space while considering the properties to be optimized. At the end of the process, it will be possible to identify the spatial configuration of the atoms and the most important interaction regions for the best hits generated. Nevertheless, before integrating the RL dynamics, the Generator and the Predictor will be pre-trained. The former is trained to generate chemically valid compounds, i.e., it will acquire knowledge about the vast chemical space, whereas the latter will learn to predict the binding affinity between the sampled molecules and the USP7 target. At the end of the optimization process, we performed docking experiments using the best compounds, i.e., the ones with higher biological affinity against the USP7, to simulate the potential interactions and validate the entire framework.
Fig. 1
General workflow. Implementation steps of the model for generating molecules with desired properties, stereochemical information, and indication of the key active sites
Pretraining of the generatorDatasetThe dataset of chemical information used to train the Generator was obtained from the ChEMBL database. We assembled 1,179,477 SMILES from the ChEMBL22 version. To ensure that the initial chemical space was within the drug-like region, the selected small molecules had a molecular weight ranging from 200 to 600 g/mol and a partition coefficient (logP) ranging from − 2 to 6. Additionally, the input dataset was filtered using the RDKit library, to exclude the molecules that could not be parsed and canonicalized by this tool.
The generator architectureThe Generator is built with recurrent architectures due to their ability to operate with sequential inputs, as is the case of the SMILES notation [23]. The pre-processing steps required for this input include tokenization and padding of each sequence. The training compounds are then encoded using an embedding layer and processed by a set of two long short-term memory (LSTM) layers. After the extraction of the main features by these layers, the next token of the sequence is predicted based on the output of a softmax-activated dense layer. Hence, the sequence analysis is performed token-by-token, which means that the model should learn how to maximize the probability of the true token given the preceding context. The optimal implementation parameters of the Generator are indicated in Table S1 of the Supporting Information. As shown in Eq. 1, the loss function is the categorical cross-entropy since we intend to minimize the distance between the distribution predicted by the model (\(\hat_\)) and the true output (\(y_\)).
$$\begin J(\theta )=-\frac \sum _^\left[ y_ \log \hat_+\left( 1-y_\right) \log \left( 1-\hat_\right) \right] \end$$
(1)
The model’s performance is evaluated through its capacity to generate syntactically valid molecules, that is, molecules that respect the SMILES notation rules for considering a molecule as synthesizable. This evaluation is performed using the RDKit tool after generating each instance. In addition to validity, it is important to assess whether the model can generate unique and novel instances compared to the training dataset. Furthermore, we employed the Tanimoto diversity metric to evaluate the molecular similarity in the set of generated molecules (internal) and in the training set (external). This metric involves obtaining the extended connected fingerprints (ECFP) of the molecules, which are bit vectors that contain structural and functional information about the compounds. To obtain these descriptors, the neighbourhood of each non-hydrogen atom of the molecule is analyzed up to a user-defined radius and mapped into integer codes using a hashing procedure [24].
Pretraining of the biological affinity predictorDatasets and preprocessingThe dataset used to train the Predictor includes the SMILES of the compounds and their corresponding biological affinity for the USP7 target. The parameter that measured the biological affinity was the negative logarithm of the half-maximal inhibitory concentration (\(pIC_\)). Nevertheless, one of the problems related to the USP7 target is the scarcity of biological affinity information to train DL models properly. As a result, as the existing datasets contain few examples, it is challenging to implement robust models with generalization capability. In this case, the following approach was to add novel instances to the USP7 dataset. However, these novel instances relate compounds with the biological affinity for other targets that are similar to the USP7. In this sense, several targets were selected based on their catalytic domain similarity with the USP7. We assembled a final dataset containing 1453 molecules (see Table S2 of the Supporting Information for more details). The reasoning behind augmenting the dataset is that if the catalytic domains of two targets are similar, then the active groups of two molecules interacting with each target will also be similar. Still, despite the model being trained with the assembled dataset, we performed a fine-tuning step with the compounds especially related to the USP7 target after the initial training step. The objective was to achieve a valid training process and to create a model that could provide meaningful predictions for the USP7 target.
ModelWe aim to obtain a model that learns to establish the relationship between chemical structures and their corresponding \(pIC_\) values. Therefore, it was analyzed the best approach to implement this model regarding the molecular descriptor and DL architecture. The studied combinations are summarized in Table 1. Following that, we have designed reward functions for each objective in order to map each predicted property to the respective reward based on how the property should be optimized (see Fig. S1 of the Supporting Information). Hence, it will be possible to explore the chemical space and identify the molecules with the highest potential to interact with the target.
Table 1 Tested models for the Predictor implementationAs previously stated, ECFPs are molecular descriptors that represent the structural features of molecules. Hence, these descriptors allow us to verify the presence or absence of substructures in molecules, making ECFPs well-suited for problems of biological activity prediction [25]. The radius used to analyze the neighbourhood of each atom can be adjusted, and, in this work, we tested ECFP4 and ECFP6 that apply radii of 2 and 3 atoms, respectively. Additionally, the RDKFingerprint implemented by the RDKit tool (http://www.rdkit.org/http://www.rdkit.org/) was also tested as the molecular descriptor. This algorithm starts by identifying all subgraphs in a molecule containing a number of bonds within a predefined range, then it applies a hashing procedure to the subgraphs and finally transforms it to generate a bit vector of fixed length.
One of the aspects that we aim to study in this model is the effect of attention mechanisms on the Predictor performance. Attention mechanisms were initially used in encoder-decoder models with recurrent architectures. The rationale associated with the application of attention is to be able to analyze a sequence and ensure that the output of this analysis has a direct influence on all elements of that sequence [26]. Without attention, the output is just the result of the last hidden state of the RNN, that is, all intermediate hidden states would be ignored. Although LSTM layers are able to capture long-range dependencies, for longer inputs, important parts may be overlooked using this architecture. Attention mechanisms were designed to address this problem since they manage to keep all the relevant information of the input in the context vector by assigning different relative importance to each processed element [26].
Hence, the attention capabilities can be applied to the Predictor implementation. In this scenario, rather than analyzing the significance of each word in the sentence, we aim to assess the relative importance of each molecular token to the \(pIC_\) value associated with the molecule. In practice, the RNN context vector for the molecule m (\(C_m\)) will be calculated as a weighted average of all preceding hidden states (\(h_\)), as indicated in Eq. 2.
$$\begin \begin&C_=\sum _^ \alpha _ h_ \\&\alpha _=} \Big [ }\Big ( e (O_,h_) \Big ) \Big ] \end \end$$
(2)
The weights \(\alpha _\) are the score calculated by a feedforward neural network (e) that extracts the alignment between the input token and the output (\(O_m\)). A hyperbolic tangent transformation, followed by a softmax activation, is applied to this score so that the values can be normalized between 0 and 1. Thus, the score has a dimension (T,1), and each element represents the importance of the token for the output.
Conditioned molecular generation dynamics through RLAfter pre-training the Generator and the Predictor, both models will be integrated into an iterative process comprising the generation and evaluation of compounds to identify an interesting set of hit compounds. Throughout this process, the Generator will be trained with RL using the reward assigned by the Predictor. The Predictor should indicate to the Generator the regions of the chemical space that have a higher probability of interacting with the USP7 target and adequate physicochemical properties.
Formally, the implementation of this method is based on the Markov Decision Problem (MDP) setting. In this work, the MDP setup was adapted to the molecular generative dynamics. The actions selected by the agent will be the sampling of new molecules by the Generator. Then, the external environment evaluating the actions will coincide with the Predictor’s evaluation of the molecular properties. The Generator will learn by experience throughout the process and the RL setting implemented in this work was the REINFORCE algorithm [27]. As a result, the policy used to select the actions corresponded directly to the weights of the Generator, which are updated through the gradient descent algorithm. The ultimate goal of this policy-gradient algorithm is to select the actions that maximize the scalar reward assigned to the agent, as stated in Eq. 3.
$$\begin R_=\sum _^ \gamma ^ r_ \end$$
(3)
where \(R_\) is the reward, t is the time step, T is the final time step, and \(\gamma\) is a parameter ranging from 0 to 1, denoting how much the future reward is worth in the present. This methodology allows the Generator to learn the more appropriate behaviour through trial and error, that is, without applying supervised learning. In practice, the policy (\(\pi\)) will choose the next action based on the distribution of probabilities derived from the previous context. The objective of the RL training is to improve the policy successively, i.e., the parameters of the Generator.
The Generator starts the dynamics by sampling a batch of molecules. Afterwards, we analyze each molecule by disassembling it into its separate tokens. Each token represents a taken action, and the loss function evaluates the probability of choosing each action. At each step, the cumulative loss is calculated by summing the probability analysis for the batch of molecules. As described in Eq. 4, \(R_t\) is the reward assigned to the Generator by selecting the action \(A_t\) when it was in the state \(S_t\), following the policy parameters \(\theta _t\), where \(\alpha\) is the learning rate. This reward value is multiplied by the natural logarithm of the corresponding probability of taking that action, allowing the agent to learn which actions should be chosen more or less frequently in future similar situations. Thus, whenever the agent returns to the same state throughout the generation process, it will select the actions that previously brought it more reward and avoid the others. After following this procedure for the batch of molecules, the gradient of the loss function is computed, and the weights of the Generator are updated accordingly to minimize the loss function.
$$\begin \theta _=\theta _+\alpha \gamma ^ R_ \nabla \ln \pi \left( A_ \mid S_, \theta _\right) \end$$
(4)
Self-adaptive molecular optimization strategyUSP7 is a cysteine protease that is involved in several signalling pathways. Its substrates and binding partners influence functions such as cell cycle regulation (e.g. cyclins), transcription factors (e.g. c-jun, NF-KB), immunological response, tumour suppression, epigenetic control, and DNA repair [28]. Therefore, this protein plays an important role in crucial post-translational mechanisms for cell dynamics, specifically through ubiquitination/deubiquitination in the p53-MDM2 pathway, which has been linked to cancer-protection mechanisms [29, 30]. Furthermore, the USP7 gene was found to be overexpressed in various cancers, which generally indicates poor tumour prognosis [28]. For this reason, small molecules that can inhibit the USP7 target may function as anticancer agents with significant therapeutic potential. Despite this possible impact, it has not yet been possible to identify a sufficiently effective and selective USP7 inhibitor capable of reaching the late phase of clinical trials.
In this work, it is expected that the generated molecules have the potential to inhibit USP7. Therefore, the objective is to maximize the \(pIC_\) of the generated molecules and to promote the inhibitory interaction between the sampled molecule and the catalytic domain of the USP7 target. Nonetheless, during the generation of the molecules, another property will be considered to ensure that the identified hits are drug-like and synthesizable in the laboratory. In other words, we intend to optimize a property that considers factors such as large rings, non-standard ring fusions, stereocomplexity, and molecule size throughout the synthesis process. This property is the synthetic accessibility score (SAS), and it condenses the evaluation of the mentioned properties into a single scalar ranging from 1 (easy to synthesize) to 10 (impossible to synthesize) [31].
Thus, the computational task is to maximize the \(pIC_\) while minimizing the SAS of the generated molecules. In the RL setting, this scenario can be seen as the optimization of two potentially competing reward values, i.e., the Generator should learn how to select actions that assure the optimization of both properties at the same time. The followed approach was to design a single reward function composed of these two terms. Therefore, the multi-objective formulation of the problem is transformed into a single-objective optimization task by constructing a single, scalar, additive reward function that considers the influence of both parameters. In this scenario, each objective is associated with a weight (w) that indicates the relative importance attributed by the RL agent. This numerical weight is assigned beforehand, and it can be arbitrarily selected as long as each weight ranges between 0 and 1 and the sum of all assigned weights equal 1. There are several strategies to implement this method that vary according to the specific problem and user’s preferences. This work provides an intuitive method for determining these preferences based on the individual rewards obtained during the optimization process. The first step is to normalize the rewards associated with each property between 0 and 1 to compare each objective’s optimization level. We then determine the initial weight assignment according to the desired preference. From this starting point, the weights are updated, taking into account the rewards registered for each property: if one objective becomes more favoured by the Generator than the other, the algorithm will adjust its weights to reverse this tendency and preserve the fair balance between the two. This self-adaptive method is based on the analysis of the last reward (f) and also on the variation ratio of the reward in a five-batch window (VR(f)). Pseudocode 5 describes the rationale for updating the preference weights throughout the optimization method.
$$\begin \begin&\textrm(x)= w_\mathrm }(x)+w_ \mathrm }(x)\\&\,\,\texttt \,\, (w_ \cdot \mathrm }(x)>w_ \cdot \mathrm }(x)) \,\, \texttt \,\, VR(f_)<0.05 \\&\qquad w_=w_-0.1; \quad w_=w_+0.1; \\&\,\,\texttt \,\,(w_ \cdot \mathrm }(x)<w_ \cdot \mathrm }(x)) \,\, \texttt \,\, VR(f_)<0.05\\&\qquad w_=w_+0.1; \quad w_=w_-0.1; \end \end$$
(5)
It should be stressed that in real-world problems with competing objectives to consider, it is impossible to find an ideal solution that optimizes both. Hence, it is necessary to determine a compromise that meets the demands of the task. In this context, the solutions obtained in the optimization process correspond to molecules. We employed the Pareto diagram visualization tool to visualize and help identify the most promising molecules. It is a method for representing a set of solutions that describes the trade-off between competing objectives [32]. This diagram distinguishes between non-dominated and dominated solutions. The former solutions have all the objectives better optimized than any dominated solution, i.e., all dominated solutions are worse than the non-dominated ones considering each objective. After identifying the non-dominated solutions, a comparative analysis will be performed to determine the most promising molecular hits based on the biological affinity for the target and its synthesizability.
Molecular docking calculationsThe crystal structure of the human USP7 was retrieved from the Research Collaboratory for Structural Bioinformatics (RCSB) Protein Data Bank (PDB) database (PDB ID: 5NGF) with a resolution of 2.33 Å elucidated through X-ray crystallography. Employing Molecular Operating Environment (MOE) software package (v. 2022.02) [33], chain B, the respective crystallographic ligand, 1,2-ethanediol and water molecules were removed from the system. The receptor structure (chain A) was protonated (at pH 7.4 and 310.15 K) using the Protonate 3D tool, and hydrogen atoms were added. Amber10:EHT forcefield was used to assign atom types in the receptor structure, which was further energy minimized using the same forcefield. Using the triangle matcher method in the placement phase and rigid receptor for refinement, self-docking experiments were conducted to predict the best scoring functions from all the available scoring functions in MOE. The best self-docking results were achieved for the GBVI/WSA dG scoring function in both the placement and refinement stages. These settings reproduce the binding pose of the co-crystallized ligand (8wn) in the USP7 crystal structure with a root-mean-square deviation (RMSD) of 1187 Å. Non-docking calculations of the dataset were performed. The ligands were prepared using Amber10:EHT forcefield to assign atom types and protonated at pH 7.4 and 310.15 K with the Protonate 3D tool, followed by energy minimization. The prepared dataset was docked into the catalytic domain of USP7, directing the docking for the crystallographic ligand atoms site. Thirty poses were generated for each molecule using the triangle matcher method in the placement stage and scored by the GBVI/WSA dG scoring function. Subsequently, the five best-scored poses were submitted to rigid receptor refinement using GBVI/WSA dG scoring function. After the docking simulations, the compounds were sorted according to their docking scores. The binding poses and the protein-ligand interactions of the top-ranked compounds were visually inspected. Images of the compound’s interactions with USP7 and surrounding residues were produced using MOE (v. 2022.02) software.
留言 (0)