
記住我



Social network analysis seeks to characterize the interrelationships between individuals (or other social entities) and can serve both to identify the network structure linking individuals as well as to examine how particular behaviors or health outcomes may be impacted by social ties. Social network analyses, long a staple in the fields of anthropology and sociology, are becoming more popular among health service researchers, given growing appreciation of the role that social context plays in shaping health-related behaviors and outcomes (O’Malley and Marsden 2008). Key mechanisms through which social relationships are hypothesized to impact health include: providing direct support and resources (including tangible resources, emotional support, information sharing); and shaping behavioral norms (Berkman and Glass 2000). In the health services context, one area of research interest is examining how social network connections between healthcare providers impact provider behavior and health outcomes. Specifically, it is hypothesized that providers who work together and share patients may influence each other through the transmission of information or development of mutually recognized norms of practice (Brunson and Laubenbacher 2018; Barnett et al. 2011; Breslau et al. 2021; Stein et al. 2017; Pollack et al. 2012a; Manchanda et al. 2008). For instance, if one provider adopts non-opioid treatment alternatives for pain disorders, closely linked colleagues may similarly alter their clinical practice. Other recent applications of social network analysis in the health context include: assessing the impact of provider team structure on health outcome and cost among Medicare patients (Kuo et al. 2020), examining the relationship between social network characteristics and living donor kidney transplantation (Gillespie et al. 2020), examining the impact of peer and family social network structure on adolescent drinking (McCann et al. 2019), and characterizing social transmission of positive and negative sentiment towards COVID-19 responses (Hung et al. 2020).
Unlike in many contexts where the analytic sample comprises individuals who are assumed to be an independent sample of the population, individuals constituting a social network do not reflect an independent sample. Indeed, the statistical independence of observed data points is a foundational assumption of most statistical techniques, including regression, comparisons of means, difference-in-differences approaches, instrumental variables, and many more (Naroll 1961a; Grafen and Hamilton 1989; Felsenstein 1985; Rohlf 2006). However, network data have long been known to violate the independence assumption because each data point (i.e., each “node,” often an individual) has a relational connection to other nodes within the social network structure. If a given observed characteristic (i.e., trait) of one node is potentially impacted by the corresponding characteristic of connected nodes in the network—e.g., through the process of social influence—then nodes cannot be assumed to be statistically independent (Leenders 2002). Rather, one individual’s trait value will directly impact the trait values of connected individuals via the social influence process. For example, while physician opioid prescribing behaviors and statin prescribing behaviors may be assumed to be independent, they both may be affected by information diffusion and social influence processes within physician social networks (O’Malley and Marsden 2008; Leenders 2002).
We note that a different problem of statistical nonindependence occurs when the traits of nodes induce connections to form between them, creating a higher likelihood of social ties between similar individuals (referred to as homophily). Although homophily and influence are not fully distinguishable in empirical data, they are conceptually distinct (Shalizi and Thomas 2011). Furthermore, nonindependence of nodes induced by processes acting across network connections (including social influence and homophily) is not the same as confounding that arises from unmeasured traits of nodes. The relationships that induce nonindependence are not features of the nodes themselves, but rather reflect relational connections linking nodes. In the case of social influence, the outcome of interest then influences itself based on the relationship structure amongst the nodes. Unmeasured confounding, in contrast, occurs when an observed association of variable Y with variable X in fact is due to by both Y and X being caused by a third unmeasured variable. Unmeasured confounding is well-known to cause biased estimates for slope coefficients in linear regression leading to statistical inconsistency, meaning that as more data are added to a regression, the model becomes more certain about a spurious association between measured variables when this association is, in fact, driven by the unmeasured variable(s) (Rohlf 2006; Lee 2021; Dow 1984; Naorli 1961).
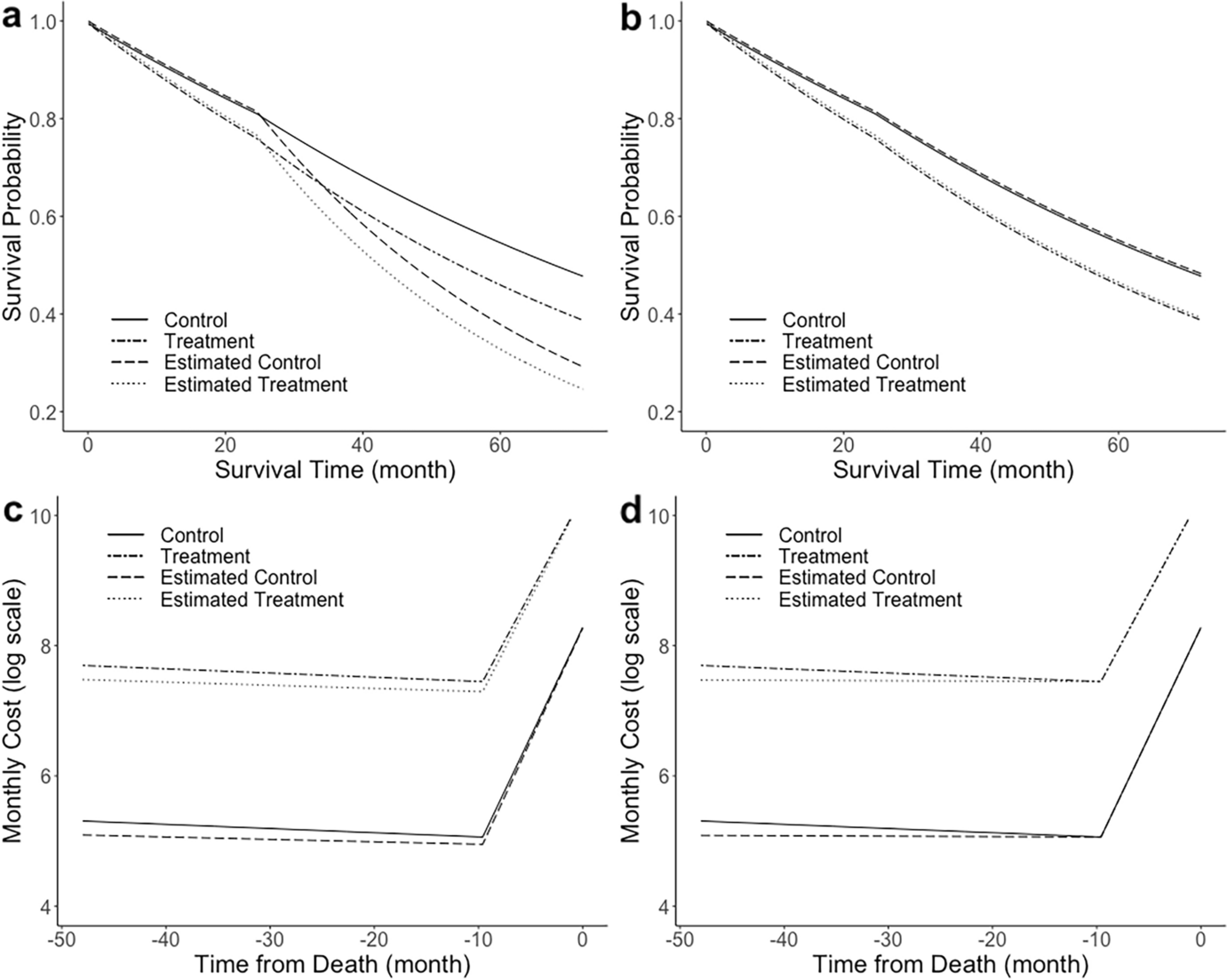
In the presence of network nonindependence, increased sample size does not yield biased slope estimates that are more consistent around an underlying value (unlike for confounding), leading some to the erroneous conclusion that nonindependence is therefore relatively unimportant. Rather, adding more complete data in the context of nonindependence results in a different form of statistical inconsistency in which the model is more likely to find a significant result with a randomly positive or negative slope (Rohlf 2006). Somewhat paradoxically, reducing the sample size relative to the total population through sampling may in fact improve statistical performance for networked (nonindependent) data, because a randomly sampled subset may comprise nodes that are (generally) not directly linked together, and hence are statistically more independent (Fig. 1).
Fig. 1
Illustration of how random sampling can select nodes that are relatively disconnected in a network and hence more statistically independent (relative to the complete network). Note: Dark gray nodes indicate those selected via random sampling
To our knowledge, the performance of random subsampling of network data has not been explored extensively in the social network analysis literature or in health policy research. It has been developed in the context of more hierarchical cross-cultural networks. Murdock and White’s seminal work creating the Standard Cross-Cultural Sample expressly used this approach to nonindependence to generate a dataset of relatively independent cultures that cross-cultural researchers could use for statistical analyses (Murdock and White 1969). The random sampling approach likely is ineffective specifically for highly hierarchical (tree-like) networks (Mace et al. 1994) but, hypothesizing that it may be effective for some social network contexts, we included it among others as a candidate method in our study.
Although the statistical problem of nonindependence in network data has been known for years, it never has been fully resolved. While there is an extensive methodological literature on the exponential random graph model (ERGM) that deals with the formation and dissolution of network connections in the context of homophily, there has been comparatively less methodological development to resolve pure cases of social influence. In the applied literature, studies employ a variety of methods—including the network autoregressive model, phylogenetic autoregression, robust standard errors, dyadic regression, and principal component analysis—that purport to solve the nonindependence problem (detailed below). Although the network autoregressive model is a primary approach used to address social influence, it is well-known to exhibit systematic biases regarding estimation of key parameters and has never been shown via simulation to produce acceptable statistical properties for Type I error (i.e., false findings of statistical significance) (Mizruchi and Neuman 2008; Neuman and Mizruchi 2010; Dittrich et al. 2017). To date, it is unclear which of these methods perform best, as their relative performance has not been directly evaluated in simulation studies.
To address this gap in the literature, we evaluate the relative performance of numerous analytic methods that have been used in the applied literature to correct for nonindependence arising from network social influence. We conducted a simulation study using simulated network data reflecting social influence processes occurring independently across multiple traits. While traits (and their diffusion) were simulated to be independent, the simulated social influence processes acting on traits means that nodes are not independent. Our simulation study compares various analytic methods for estimating the relationship between traits; methods that correct adequately for node nonindependence (either via a “robust” estimator or by transforming the network structure of the data) should infer no significant correlation between traits (estimating significant associations no more frequently than nominal significance level). To isolate the issue of nonindependence induced by network influence, our simulation assumed that the correct network structure was known with complete accuracy and that there was no confounding or homophily. If available statistical methods cannot correct for nonindependence under these conditions, they are very unlikely to perform well under real-world conditions in which these additional complexities like measurement inaccuracies, confounding, and homophily are common.
1.1 Statistical corrections for network nonindependenceWe will focus on the context of estimating the association between outcome trait Y and predictor trait X. In simplest form, this could be assessed with a regression model of the form \(y=X\beta +e\), in which the estimated coefficient \(\widehat\) quantifies the association of interest. Interrelated network data violates the assumption of independence of observations (and in turn the \(e\) terms) underlying many regression methods such as ordinary least squares. Many statistical methods to account for nonindependence of network data have been proposed. Some methods attempt to correct the variance of regression coefficients (i.e., slopes or betas) for nonindependence, but they do so in different ways. Other methods correct the standard error of the slopes so as to obtain correct p-values for the slope (that may or may not be estimated correctly in terms of magnitude). Herein we briefly characterize each method that we tested, all of which have received full treatments in articles we cite. Table 1 shows a compact overview and comparison of the methods and is followed by brief descriptions of each.
Table 1 Comparison of Methods to Correct for Nonindependence in Network DataNetwork autoregression models were developed specifically to deal with nonindependence in network data. They keep the relationship data in their natural dyadic form (i.e., connections from node A to B, A to C, etc.) and specify an autoregressive structure for the error term \(e.\) This approach divides the residual variation into a portion that is correlated across the network ties and then an uncorrelated residual as would be typical of any regression model (O’Malley 2008; Leenders 2002; Grafen 1989; Pagel 1999). We implemented this method using the lnam function in the “sna” R package (Butts 2020). Specifically, lnam fits the following linear network autocorrelation model: \(y=X\beta +e,\) with \(e=\sigma We+\upsilon\). In this model, \(y\) denotes a vector of the outcome trait, \(X\) is a covariate trait matrix, \(W\) is the adjacency matrix (with multiplicative factor \(\sigma )\), and the uncorrelated residual \(\upsilon \sim N(0,^)\). \(W\) parameterizes the autocorrelation of each disturbance in \(y\) on its neighbors.
Phylogenetic autoregression applies the same general statistical approach as does network regression, but it first simplifies the network structure into a best-fitting bifurcating tree structure (Mathew and Perreault 2015a). The advantage of this approach is it greatly reduces the mathematical complexity and circularity of the original network. Prior simulation work has shown this method to be generally valid when the network is very close to a bifurcating tree structure (Matthews 2019), but this method presents a clear disadvantage if the network is not treelike and hence the phylogeny fails to represent aspects of the full network structure. We implemented this approach using the hclust function in R to perform hierarchical cluster analysis to identify the closest fitting tree for the network structure. We then used the corPagel function in the “ape” R package (Paradis and Schliep 2019) to estimate Pagel's lambda correlation structure (\(\lambda )\) from a phylogenetic representation of the estimated tree. Again, the underlying model is \(y=X\beta +e,\) with \(e=\lambda We+\upsilon\) but now \(\lambda\) is used as the scaling factor \(\sigma\) and \(W\) reflects the closest fitting tree. Finally, we regressed \(y\) on \(X\) using the the gls function in the R package “nlme” (Pinheiro et al. 2022), specifying the correlation structure as our estimated \(\lambda\).
Conley standard errors is a method derived from spatial statistics that has been applied to deal with social influence on social networks (Schulz et al. 2019). Specifically, this method uses a Generalized Method of Moments approach and computes a variance–covariance matrix with spatial weights. While typically applied to geographic spatial data, this method can be applied in the context of social network data using spatial weights that represent the network distance between nodes as physical distances (e.g., pretending as if the social network space existed in a physical geographic space). In order to implement this method, one must transform the social network data into a two-dimensional array (e.g., representing latitude and longitude of nodes); we used principal component analysis to estimate 2 components from each network using the isoMDS function in the “MASS” R package (Venables and Ripley 2002). We then used the “conleyreg” R package (Düben et al. 2022) to estimating a regression model of the form \(y=X\beta +e\), specifying the 2 estimated components as the “latitude” and “longitude” used to calculate the spatial weights.
Random effects for network communities model also adjusts the residual variation with a simplification, but it does this by first breaking up the network into a set of network communities. Membership in a network community then is assigned as a nominal variable to each individual, and this variable is entered into the model as a random effect; in other words, this approach fits a hierarchical linear model with network community as the grouping variable (Landon et al. 2018). In the literature this model also is known as a “clustered error” model or “mixed hierarchical” model. We inferred network communities with the cluster walktrap function in the “igraph” R package (Csardi and Nepusz 2005) and then used the lmer function in the “lme4” R package (Bates et al. 2015) to estimate a regression model of the form \(y=X\beta +u+e,\) where \(u\) denotes the network community random effect. Once again, while this simplifies the mathematical work needed to fit the regression, it may fail to account for important structural features of any given social network.
Principal components from networks first passes the network structure through a dimension reduction procedure to extract out several continuously varying variables. These are intended to recapitulate individuals’ positions in the network through a set of variables, which then are entered into the regression model as fixed effects (Mathew and Perreault 2015b). We used principal component analysis to estimate 5 components from each network using the isoMDS function in the “MASS” R package (Venables and Ripley 2002) and then estimated a linear regression model of the following form: \(y=X\beta +__+_C}_+_C}_+_C}_+_C}_+ e,\) in which \(_\), …, \(_\) denote the 5 components.
Robust standard errors are an approach to estimate unbiased standard errors of OLS coefficients under certain violations the standard OLS assumption of independent and identically distributed (i.i.d.) error terms. In particular, robust standard errors can address heteroscedasticity (i.e., heterogenous variance of the error terms). Notably, robust standard errors do not require specifying the functional form of the underlying covariance matrix, unlike a weighted least squares approach. Although robust standard errors (and weighted least squares) were only ever designed to correct for the identically distributed assumption of i.i.d. (and not the independence assumption), we included it as a candidate method because robust standard errors have seen wide application in the literature far beyond their original intent (King and Roberts 2015). We implemented robust standard error estimation in R with the “sandwich” (Zeileis et al. 2020) and “lmtest” packages (Zeileis and Hothorn 2002), using the coeftest command (and specifying the “HC1” option) when estimating a regression model of the form \(y=X\beta +e\).
Dyadic regression with network covariates is a technique we developed as part of this research that is based on prior network studies (Nooy 2011; O'Malley and Christakis 2011; Matthews et al. 2013). In this approach we first convert the traits into pairwise distances. We then regress these distance values, one for each pair of data points \(_\) and \(_\), against one another, while including a binary indicator term for the presence of a network tie between a pair (denoted \(Z)\). We also include two random effect terms corresponding to the two nodes comprising a given dyad. We fitted this model of the form \(_=\left(_\right)\beta +_Z+_+_+e\) with the lmer function in the lme4 package, where \(_\) and \(_\) denote node random effects.
Random subsampling of network nodes relies on the property that as fewer nodes are sampled from a complete network it becomes less likely the sampled nodes are connected. If all the sampled nodes are sufficiently distant from each other, i.e., separated by at least one intermediary node, then they can be treated as independent data points in statistical models. Even in large samples of the U.S. population like the General Social Survey, node independence can be assumed because the sample is far less than even 1% of the total population. Physician networks, however, have often been analyzed for nearly complete sets of physicians in entire markets (Brunson et al. 2018). Random subsampling may be viable in very large markets, but in smaller markets it may be intractable due to the obvious loss of statistical power this method entails. We implemented random subsampling by first selecting either a 10%, 30%, or 50% random sample of nodes and then estimating a standard ordinary least squares regression model of the form \(y=X\beta +e\).
It is worth noting at this point that Matthews (2019) tested many of these same statistical corrections via simulation for highly hierarchical network structures derived from language trees (Matthews et al. 2019). That study found that random effects for network communities, principal components from networks, and phylogenetic autoregression all performed at acceptable levels for false positive rates when traits were simulated to diffuse via social influence across network ties that were tree-like. However, when the traits were inherited longitudinally down the branches of the tree, and without horizontal diffusion, only the autoregression method performed acceptably. In both forms of trait simulation, the network autoregression method had false positive rates at least 3 times greater than what they should have been. Thus, we acknowledge that network structural characteristics can matter a great deal to the performance of statistical models to deal with network data. In this current paper we are seeking to examine the types of social networks most commonly encountered in health policy research. For hierarchical (tree-like) networks, readers are recommended to consult Matthews (2019). Further research is needed to identify the effects of other types of network structures on model performance.
留言 (0)