ncRNA, Vol. 8, Pages 70: Flnc: Machine Learning Improves the Identification of Novel Long Noncoding RNAs from Stand-Alone RNA-Seq Data
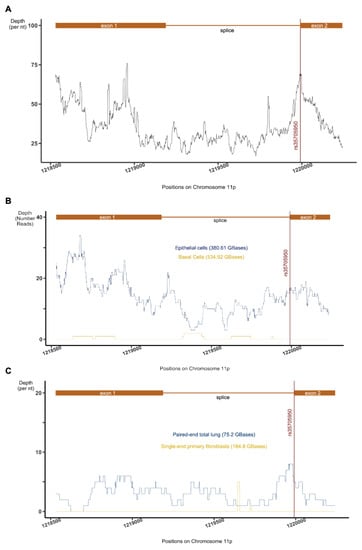
Long noncoding RNAs (lncRNAs) play critical regulatory roles in human development and disease. Although there are over 100,000 samples with available RNA sequencing (RNA-seq) data, many lncRNAs have yet to be annotated. The conventional approach to identifying novel lncRNAs from RNA-seq data is to find transcripts without coding potential but this approach has a false discovery rate of 30–75%. Other existing methods either identify only multi-exon lncRNAs, missing single-exon lncRNAs, or require transcriptional initiation profiling data (such as H3K4me3 ChIP-seq data), which is unavailable for many samples with RNA-seq data. Because of these limitations, current methods cannot accurately identify novel lncRNAs from existing RNA-seq data. To address this problem, we have developed software, Flnc, to accurately identify both novel and annotated full-length lncRNAs, including single-exon lncRNAs, directly from RNA-seq data without requiring transcriptional initiation profiles. Flnc integrates machine learning models built by incorporating four types of features: transcript length, promoter signature, multiple exons, and genomic location. Flnc achieves state-of-the-art prediction power with an AUROC score over 0.92. Flnc significantly improves the prediction accuracy from less than 50% using the conventional approach to over 85%. Flnc is available via GitHub platform.
View Full-Text
►▼
Show Figures
This is an open access article distributed under the
Creative Commons Attribution License which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.








留言 (0)