
記住我
FIGURE 7
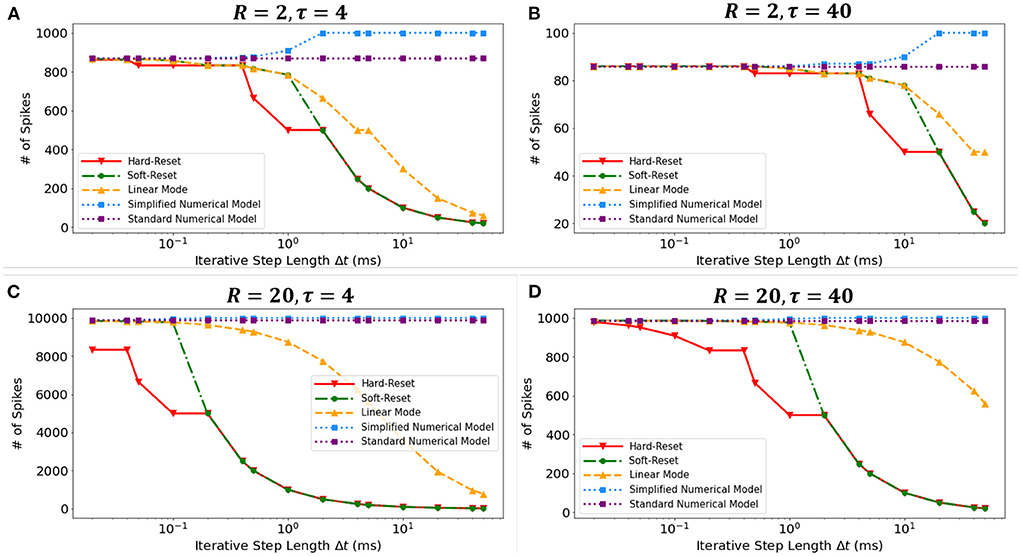
Figure 7. The numbers of spikes via Δt with different discrete models. Four experiments with different τ and R: (A) R = 2Ω, τ = 4ms, (B) R = 2Ω, τ = 40ms, (C) R = 20Ω, τ = 4ms, (D) R = 20Ω, τ = 40ms.
3.2. Classification of neuromorphic datasetsTo demonstrate the reliability of our approaches, we train our SNN models with spike-based datasets for image and sound classification and compare the achieved error rates with related works on SNN algorithms.
3.2.1. Experiment setting and parameters initializationThe proposed model is built on the deep learning framework, PyTorch (Paszke et al., 2019), and the weights are initialed using the default Xavier Normal (Glorot and Bengio, 2010) method. Besides, we use Adam as the optimizer and Cross-Entropy as the criterion during training. Hyperparameters of experimental settings are shown in Table 1. We built fully connected networks for classification as the Multilayer Perceptron (MLP) structure.
TABLE 1
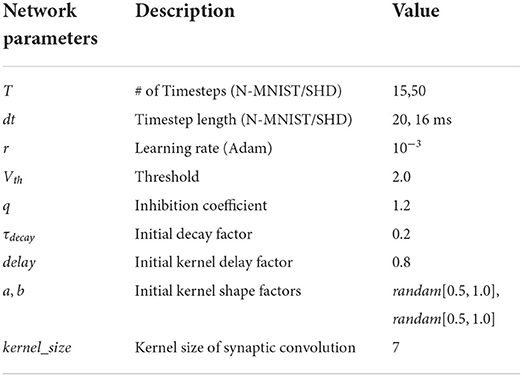
Table 1. Hyperparameters setting.
3.2.2. Neuromorphic image datasetN-MNIST (Orchard et al., 2015) is a neuromorphic version of MNIST digits, which contains 60,000 train samples and 10,000 test samples aligning with MNIST. The samples of N-MNIST are event-based spike signals captured by recording MNIST images displayed on an LCD screen using Dynamic Vision Sensors (DVS) mounted on a moving platform. The N-MNIST images record overall 300ms frames and have two channels that separately record brighter and darker brightness changes. We process the two channels in parallel with two groups of 400 hidden neurons, where the network architecture is (2 × 1156)−(400+400)−10.
3.2.3. Neuromorphic sound datasetSpiking Heidelberg Digits (SHD) (Cramer et al., 2020) is a spike-based speech dataset consisting of 0–9 spoken digits recordings in both English and German. The audio recordings are converted into spikes using an artificial inner ear model, transforming into temporal structures with 700 input channels. There are 8156 train samples and 2,264 test samples in SHD, and each of them lasts for at most 800 ms. SHD requires multiple layers to fit. Therefore, we built the architecture of 700−400−400−20 with two hidden layers of 400 neurons.
3.2.4. Error rate comparisonWe compare the obtained model performance with state-of-the-art SNN models, The results of N-MNIST are in Table 2 and SHD is in Table 3, including ablation experiments with MSP and SFSRM alone. The experimental results show that MAP-SNN can decrease the error rate by 0.16% on N-MNIST and 1.30% on SHD, which has achieved the highest performance among SNN-based algorithms under the same MLP structure. Furthermore, we observe that MSP and SFSRM can independently improve the model accuracy and be combined for significantly better performance, which supports the complementarity of MAP properties.
TABLE 2
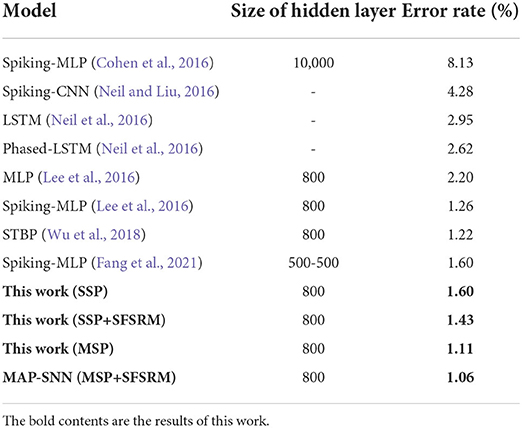
Table 2. Performance of different algorithms on N-MNIST.
TABLE 3
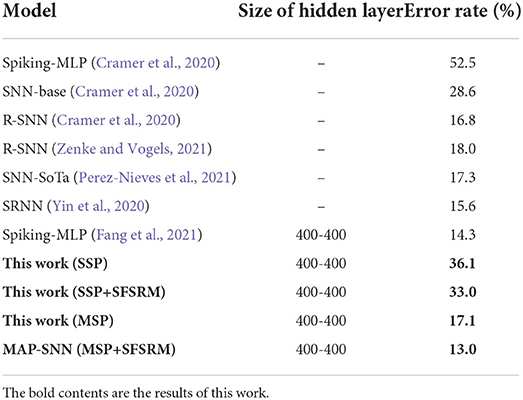
Table 3. Performance of different algorithms on SHD.
3.2.5. Visualization resultsTo help understand the signal transmissions of SNNs and highlight the difference between the MSP and the SSP, we derive the spike raster plot of an SHD sample. The network structure consists of two hidden layers of 700 − 400 − 400 − 20. The plot shows the neural spike activities in layers on the 800-th SHD training sample with label 0 in Figure 8. The horizontal and vertical axes indicate the time interval and the indices of spiking neurons in layers. In detail, we implement the SSP based on STBP (Wu et al., 2018) for comparison with the proposed MSP. In Figure 8B, it is observed under MSP that spike activities are more concentrated in the temporal dimension, while there are fewer nearby sparse spikes in deep layers (Layer 2 and Layer 3). In contrast, Figure 8C shows that the spike channels of Layer 2 are almost full, which is because the neurons under SSP are “encouraged” to keep fire to maintain signal integrity within restricted binary signals.
FIGURE 8
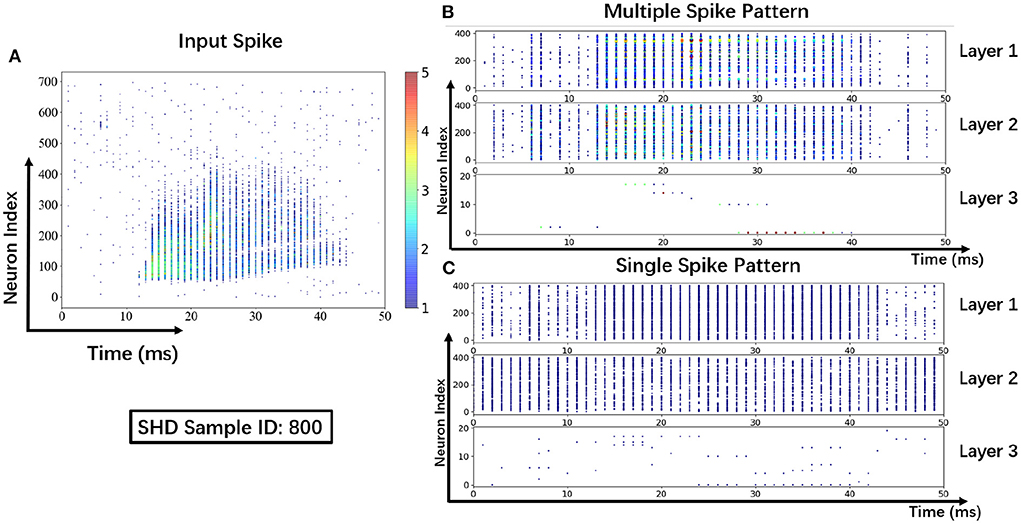
Figure 8. Spike raster plot: Visualization of spike transmission on SHD sample. (A) Input spikes. (B) Spike transmission in multiple spike pattern. (C) Spike transmission in single spike pattern.
3.3. Control experiments and performance analysisTo explore the potentials of the proposed MSP, SFA, and SFSRM, we carry out control experiments on N-MNIST and SHD datasets and discuss the impacts of MAP properties on improving model performance.
3.3.1. The impact of multiplicity on discrete iterationThe selection of minimal iterative step lengths Δt influences model performance in the discrete iterative models. For the sake of completeness of the analysis, we analyze this instability in the ablation experiments by building control experiments under MLP architecture with different iterative step lengths, as shown in Figures 9A,B. The experiments are based on N-MNIST and SHD, respectively, where the unified network structure is (2 × 1156)-200-10 on N-MNIST and 700-400-20 on SHD. With the MAP properties, the error rates of the model have been significantly improved. Compared with benchmark SSP, our MAP-SNN with the combination of MSP and SFSRM reduces error rates among different iterative step lengths by the range of (1.0, 2.8%) on N-MNIST, and (19, 41%) on SHD, which demonstrates the reliability of the proposed methods. Furthermore, the model trained with MSP keeps almost constant error rates across different Δt, supporting that multiplicity alleviates the discretization problem and improves the model stability over time-iteration with different iterative step lengths.
FIGURE 9
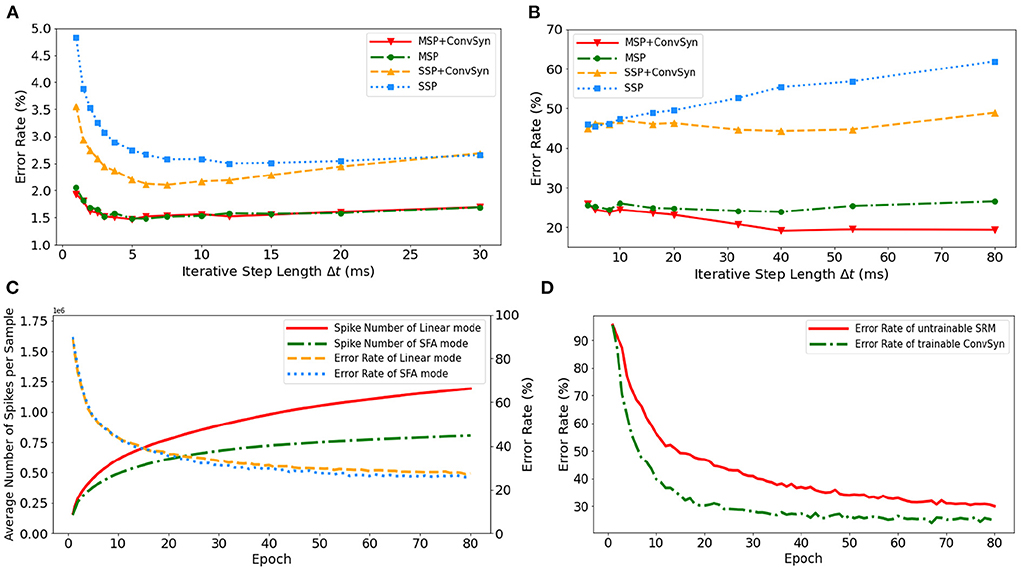
Figure 9. Experimental results. (A) Error rate curves among different iterative step lengths on N-MNIST. (B) Error rate curves among different iterative step lengths on SHD. (C) Control experiment of spike frequencies between SFA and Linear modes on SHD. (D) Control experiment of synaptic plasticity for performance improvement on SHD.
3.3.2. The impact of adaptability on spike efficiencyTo demonstrate the effectiveness of SFA in spike reduction, we establish a set of controlled experiments on the SHD dataset with the 700-400-20 MLP structure. Figure 9C shows the error rates and spike numbers in the training process of models in both SFA mode and Linear mode. The experimental results show that SFA effectively suppresses spike activities by 1.48 × times while slightly improving model accuracy by 1.52%. In this case, the reduced signal transmissions helpfully decrease the amount of computation in synapses, which will help save the power consumption of neuromorphic hardware based on spike transmissions.
3.3.3. The impact of plasticity on feature extractionTo highlight the importance of plasticity for feature extraction, we set up a control experiment to compare the SRM with and without the plasticity, as shown in Figure 9D. The untrainable SRM refers to the fixed SRM (the parameters fixed after initialization) and the trainable SFSRM refers to our proposed method in Section 2.4. The experiment is set on the SHD with the 700-400-20 MLP structure, where the SRM or SFSRM is inserted on 400 hidden neurons. Figure 9D shows the changes in model error rate and loss during the training epoch. The experimental results show that the plasticity allows the model to converge faster by 4.2% and reduces the error rate by 15.6% during epoch [10, 80]. This demonstrates the advantage of SFSRM in temporal feature extraction. We conclude that plasticity helps shorten the training process of models and improve the model's performance.
4. DiscussionIn this work, we refer to the Multiplicity, Adaptability, and Plasticity (MAP) properties and model spike activities with Multiple-Spike Pattern (MSP), Spike Frequency Adaption (SFA), and State-Free Synaptic Response Model (SFSRM) that improve BP-based methods with better performance. For the spiking neural models, the existing methods rely on the neurons with the single-spike pattern (SSP) that only outputs the binary events (Lee et al., 2016; Wu et al., 2018; Cheng et al., 2020), introducing discrepancies between the discrete iterative simulation and biological network. To mitigate this discrepancy due to time discretization, we propose an MSP spiking neural model that supports the neurons to output the number of spike events. We set up the control experiments on neuromorphic datasets and tested SSP and MSP in the same MLP architecture. The results demonstrate that the SSP is sensitive to the selection of iterative time step Δt, while the MSP is more robust under different time steps Δt compared with the SSP, as shown in Figures 9A,B. Considering the smaller number of simulation timesteps and lower inference latency, the spiking neurons with multiple thresholds are proposed in recent works (Chowdhury et al., 2021; Xu et al., 2021), which refer to the linear mode of MSP implementation. The spike activity increases linearly as the increase of input currents in such linear mode MSP. More spike activities require more energy for spike transmission and subsequent operations. While a biological neuron fires with a reduced frequency over time under a constant stimuli (Benda and Herz, 2003). Therefore, the SFA mode was implemented under the MSP to reduce spike activities while keeping on the model accuracy shown in Figure 9C. Some published works have applied the SRM model in SNNs to capture the spike temporal information and thus achieved high performance (Jin et al., 2018; Shrestha and Orchard, 2018). However, they restrict the shape parameters inside the kernel function and need to expand the kernel among temporal domains to do the calculation step by step. In order to enrich the model representation power and make the SRM more compatible in deep frameworks, we propose to substitute the iterative calculation with convolution operations and allow all parameters inside the kernel to be learned for plastic synapses.
The implementability of the proposed MAP-SNN is a major concern. State-of-the-art neuromorphic chips, such as Tianjic (Pei et al., 2019), Darwin (Ma et al., 2017), and Loihi (Davies et al., 2018), support the single-spike pattern directly. The MAP-SNN model with a generalized definition is feasible to perform the on-chip inference on Tianjic Chip with proper hardware configuration. In detail, the neural models of multiple-spike patterns with SFA mode can be simplified at the hardware level by pre-setting a lookup table to determine the number of spike activities based on the value of the current membrane potential. Besides, in the axonal process of spike traveling, the Tianjic chip with ANN-SNN hybrid design can compatibly perform the integer transmission, supportive of the multiple-spike pattern. Further, at the axonal terminal, the state-free synapses are implemented by the low-pass filters, which transform the spike activities into synaptic currents. We believe that algorithms and hardware can be developed in tandem. The improvements in algorithms may also inspire the hardware design. The feasibility of MAP-SNN on Tianjic provides a potential development perspective for both spike-based algorithms and neuromorphic hardware.
The aforementioned discrete models (Figure 3) have great numerical calculation accuracy in simulation and inference, which may be used in the ANN-SNN conversion approach to narrow the gap between analytical and numerical solutions, as well as reduce network latency through time compression; this is an area worthy of further exploration in the future.
In conclusion, this work demonstrates the potency of effectively modeling spike activities, revealing a unique perspective for researchers to re-examine the significance of biological facts.
Data availability statementPublicly available datasets were analyzed in this study. This data can be found here: the datasets SHD/N-MNIST for this study can be found in the https://zenkelab.org/resources/spiking-heidelberg-datasets-shd/ (Spiking Heidelberg Datasets), and https://www.garrickorchard.com/datasets/n-mnist (Neuromorphic-MNIST).
Code availability statementThe source code of MAP-SNN can be found in the Github repository https://github.com/Tab-ct/MAP-SNN.
Author contributionsCY proposed the idea. CY and YD designed and did the experiments. CY, MC, and AW wrote the manuscript, then GW, AW, and EL revised it. AW directed the projects and provided overall guidance. All authors contributed to the article and approved the submitted version.
FundingThis work was supported in part by the Fundamental Research Funds for the Central Universities under Grant 2-2050205-21-688 and in part by the Zhejiang Provincial Natural Science Foundation Exploration Youth Program under Grant LQ22F010011.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesAdibi, M., Clifford, C. W. G., and Arabzadeh, E. (2013). Informational basis of sensory adaptation: entropy and single-spike efficiency in rat barrel cortex. J. Neurosci. 33, 14921–14926. doi: 10.1523/JNEUROSCI.1313-13.2013
PubMed Abstract | CrossRef Full Text | Google Scholar
Bellec, G., Salaj, D., Subramoney, A., Legenstein, R., and Maass, W. (2018). “Long short-term memory and learning-to-learn in networks of spiking neurons,” in Advances in Neural Information Processing Systems 31, eds S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Curran Associates, Inc.). Available online at: https://proceedings.neurips.cc/paper/2018/file/c203d8a151612acf12457e4d67635a95-Paper.pdf
Bellec, G., Scherr, F., Subramoney, A., Hajek, E., Salaj, D., Legenstein, R., et al. (2020). A solution to the learning dilemma for recurrent networks of spiking neurons. Nat. Commun. 11, 3625. doi: 10.1038/s41467-020-17236-y
PubMed Abstract | CrossRef Full Text | Google Scholar
Cheng, X., Hao, Y., Xu, J., and Xu, B. (2020). “LISNN: improving spiking neural networks with lateral interactions for robust object recognition,” in IJCAI, 1519–1525. doi: 10.24963/ijcai.2020/211
CrossRef Full Text | Google Scholar
Chowdhury, S. S., Rathi, N., and Roy, K. (2021). One timestep is all you need: training spiking neural networks with ultra low latency. arXiv preprint arXiv:2110.05929. doi: 10.48550/arXiv.2110.05929
CrossRef Full Text | Google Scholar
Cohen, G. K., Orchard, G., Leng, S.-H., Tapson, J., Benosman, R. B., and van Schaik, A. (2016). Skimming digits: neuromorphic classification of spike-encoded images. Front. Neurosci. 10, 184. doi: 10.3389/fnins.2016.00184
PubMed Abstract | CrossRef Full Text | Google Scholar
Cramer, B., Stradmann, Y., Schemmel, J., and Zenke, F. (2020). “The Heidelberg spiking data sets for the systematic evaluation of spiking neural networks,” in IEEE Transactions on Neural Networks and Learning Systems, 1–14. doi: 10.1109/TNNLS.2020.3044364
PubMed Abstract | CrossRef Full Text | Google Scholar
Davies, M., Srinivasa, N., Lin, T.-H., Chinya, G., Cao, Y., Choday, S. H., et al. (2018). Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99. doi: 10.1109/MM.2018.112130359
CrossRef Full Text | Google Scholar
Dayan, P., and Abbott, L. F. (2005). Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems. MIT Press.
Diehl, P. U., Zarrella, G., Cassidy, A., Pedroni, B. U., and Neftci, E. (2016). “Conversion of artificial recurrent neural networks to spiking neural networks for low-power neuromorphic hardware,” in 2016 IEEE International Conference on Rebooting Computing (ICRC), 1–8. doi: 10.1109/ICRC.2016.7738691
CrossRef Full Text | Google Scholar
Eshraghian, J. K., Ward, M., Neftci, E., Wang, X., Lenz, G., Dwivedi, G., et al. (2021). Training spiking neural networks using lessons from deep learning. arXiv preprint arXiv:2109.12894.
Fang, H., Shrestha, A., Zhao, Z., and Qiu, Q. (2020). Exploiting neuron and synapse filter dynamics in spatial temporal learning of deep spiking neural network. arXiv preprint arXiv: 2003.02944. doi: 10.24963/ijcai.2020/388
CrossRef Full Text | Google Scholar
Fang, H., Taylor, B., Li, Z., Mei, Z., Li, H. H., and Qiu, Q. (2021). “Neuromorphic algorithm-hardware codesign for temporal pattern learning,” in DAC, 361–366. doi: 10.1109/DAC18074.2021.9586133
CrossRef Full Text | Google Scholar
Gerstner, W., and Kistler, W. M. (2002). Spiking Neuron Models: Single Neurons, Populations, Plasticity. Cambridge University Press. doi: 10.1017/CBO9780511815706
CrossRef Full Text | Google Scholar
Glorot, X., and Bengio, Y. (2010). “Understanding the difficulty of training deep feedforward neural networks,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–256. Available online at: https://proceedings.mlr.press/v9/glorot10a.html
Gu, P., Xiao, R., Pan, G., and Tang, H. (2019). “STCA: spatio-temporal credit assignment with delayed feedback in deep spiking neural networks,” in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (Macao), 1366–1372. doi: 10.24963/ijcai.2019/189
CrossRef Full Text | Google Scholar
Han, B., Srinivasan, G., and Roy, K. (2020). “RMP-SNN: residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network,” in ICCV, 13558–13567. doi: 10.1109/CVPR42600.2020.01357
CrossRef Full Text | Google Scholar
Hodgkin, A. L., Huxley, A. F., and Eccles, J. C. (1952). Propagation of electrical signals along giant nerve fibres. Proc. R. Soc. Lond. Ser. B Biol. Sci. 140, 177–183. doi: 10.1098/rspb.1952.0054
PubMed Abstract | CrossRef Full Text | Google Scholar
Hunsberger, E., and Eliasmith, C. (2016). Training spiking deep networks for neuromorphic hardware. arXiv preprint arXiv: 1611.05141. doi: 10.13140/RG.2.2.10967.06566
CrossRef Full Text | Google Scholar
Jin, Y., Zhang, W., and Li, P. (2018). “Hybrid macro/micro level backpropagation for training deep spiking neural networks,” in Advances in Neural Information Processing Systems 31, eds S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Curran Associates, Inc.). Available online at: https://proceedings.neurips.cc/paper/2018/file/3fb04953d95a94367bb133f862402bce-Paper.pdf
Lechner, M., Hasani, R., Amini, A., Henzinger, T. A., Rus, D., and Grosu, R. (2020). Neural circuit policies enabling auditable autonomy. Nat. Mach. Intell. 2, 642–652. doi: 10.1038/s42256-020-00237-3
CrossRef Full Text | Google Scholar
Ma, D., Shen, J., Gu, Z., Zhang, M., Zhu, X., Xu, X., et al. (2017). Darwin: a neuromorphic hardware co-processor based on spiking neural networks. J. Syst. Arch. 77, 43–51. doi: 10.1016/j.sysarc.2017.01.003
CrossRef Full Text | Google Scholar
Maass, W. (1997). Networks of spiking neurons: the third generation of neural network models. Neural Netw. 10, 1659–1671. doi: 10.1016/S0893-6080(97)00011-7
CrossRef Full Text | Google Scholar
Masquelier, T., and Kheradpisheh, S. R. (2018). Optimal localist and distributed coding of spatiotemporal spike patterns through STDP and coincidence detection. Front. Comput. Neurosci. 12, 74. doi: 10.3389/fncom.2018.00074
PubMed Abstract | CrossRef Full Text | Google Scholar
Muratore, P., Capone, C., and Paolucci, P. S. (2021). Target spike patterns enable efficient and biologically plausible learning for complex temporal tasks. PLoS ONE 16, e0247014. doi: 10.1371/journal.pone.0247014
PubMed Abstract | CrossRef Full Text | Google Scholar
Neftci, E. O., Mostafa, H., and Zenke, F. (2019). Surrogate gradient learning in spiking neural networks: bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 36, 51–63. doi: 10.1109/MSP.2019.2931595
CrossRef Full Text | Google Scholar
Neil, D., and Liu, S.-C. (2016). “Effective sensor fusion with event-based sensors and deep network architectures,” in ISCAS, 2282–2285. doi: 10.1109/ISCAS.2016.7539039
CrossRef Full Text | Google Scholar
Nessler, B., Pfeiffer, M., and Maass, W. (2009). “STDP enables spiking neurons to detect hidden causes of their inputs,” in Advances in Neural Information Processing Systems 22, eds Y. Bengio, D. Schuurmans, J. Lafferty, C. Williams, A. Culotta (Curran Associates, Inc.). Available online at: https://proceedings.neurips.cc/paper/2009/file/a5cdd4aa0048b187f7182f1b9ce7a6a7-Paper.pdf
Orchard, G., Jayawant, A., Cohen, G. K., and Thakor, N. (2015). Converting static image datasets to spiking neuromorphic datasets using saccades. Front. Neurosci. 9, 437. doi: 10.3389/fnins.2015.00437
PubMed Abstract | CrossRef Full Text | Google Scholar
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). “PyTorch: an imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems, eds H. Wallach, H. Larochelle, A. Beygelzimer, F. d' Alché-Buc, E. Fox, and R. Garnett (Curran Associates, Inc.). Available online at: https://proceedings.neurips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf
Payeur, A., Guerguiev, J., Zenke, F., Richards, B. A., and Naud, R. (2021). Burst-dependent synaptic plasticity can coordinate learning in hierarchical circuits. Nat. Neurosci. 24, 1010–1019. doi: 10.1038/s41593-021-00857-x
PubMed Abstract | CrossRef Full Text | Google Scholar
Pei, J., Deng, L., Song, S., Zhao, M., Zhang, Y., Wu, S., et al. (2019). Towards artificial general intelligence with hybrid Tianjic chip architecture. Nature 572, 106–111. doi: 10.1038/s41586-019-1424-8
PubMed Abstract | CrossRef Full Text | Google Scholar
Perez-Nieves, N., Leung, V. C. H., Dragotti, P. L., and Goodman, D. F. M. (2021). Neural heterogeneity promotes robust learning. Nat. Commun. 12, 1–9. doi: 10.1101/2020.12.18.423468
PubMed Abstract | CrossRef Full Text | Google Scholar
Rothman, J. S. (2013). “Modeling synapses,” in Encyclopedia of Computational Neuroscience, eds D. Jaeger and R. Jung (New York, NY: Springer), 1–15. doi: 10.1007/978-1-4614-7320-6_240-1
CrossRef Full Text | Google Scholar
Rueckauer, B., Lungu, I.-A., Hu, Y., Pfeiffer, M., and Liu, S.-C. (2017). Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 11, 682. doi: 10.3389/fnins.2017.00682
PubMed Abstract | CrossRef Full Text | Google Scholar
Salaj, D., Subramoney, A., Kraisnikovic, C., Bellec, G., Legenstein, R., and Maass, W. (2021). Spike frequency adaptation supports network computations on temporally dispersed information. eLife 10, e65459. doi: 10.7554/eLife.65459
PubMed Abstract | CrossRef Full Text | Google Scholar
Sengupta, A., Ye, Y., Wang, R., Liu, C., and Roy, K. (2019). Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 13, 95. doi: 10.3389/fnins.2019.00095
PubMed Abstract | CrossRef Full Text | Google Scholar
Tavanaei, A., Ghodrati, M., Kheradpisheh, S. R., Masquelier, T., and Maida, A. (2019). Deep learning in spiking neural networks. Neural Netw. 111, 47–63. doi: 10.1016/j.neunet.2018.12.002
PubMed Abstract | CrossRef Full Text | Google Scholar
Tavanaei, A., Masquelier, T., and Maida, A. S. (2016). “Acquisition of visual features through probabilistic spike-timing-dependent plasticity,” in 2016 International Joint Conference on Neural Networks (IJCNN), 307–314. doi: 10.1109/IJCNN.2016.7727213
CrossRef Full Text | Google Scholar
Vanarse, A., Osseiran, A., and Rassau, A. (2016). A review of current neuromorphic approaches for vision, auditory, and olfactory sensors. Front. Neurosci. 10, 115. doi: 10.3389/fnins.2016.00115
PubMed Abstract | CrossRef Full Text | Google Scholar
Woźniak, S., Pantazi, A., Bohnstingl, T., and Eleftheriou, E. (2020). Deep learning incorporating biologically inspired neural dynamics and in-memory computing. Nat. Mach. Intell. 2, 325–336. doi: 10.1038/s42256-020-0187-0
CrossRef Full Text | Google Scholar
Wu, Y., Deng, L., Li, G., Zhu, J., and Shi, L. (2018). Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 12, 331. doi: 10.3389/fnins.2018.00331
PubMed Abstract | CrossRef Full Text | Google Scholar
Wu, Y., Deng, L., Li, G., Zhu, J., Xie, Y., and Shi, L. (2019). “Direct training for spiking neural networks: faster, larger, better,” in AAAI, 1311–1318. doi: 10.1609/aaai.v33i01.33011311
CrossRef Full Text | Google Scholar
Xu, C., Liu, Y., and Yang, Y. (2021). Direct training via backpropagation for ultra-low latency spiking neural networks with multi-threshold. arXiv preprint arXiv: 2112.07426. doi: 10.48550/arXiv.2112.07426
CrossRef Full Text | Google Scholar
Xu, C., Zhang, W., Liu, Y., and Li, P. (2020). Boosting throughput and efficiency of hardware spiking neural accelerators using time compression supporting multiple spike codes. Front. Neurosci. 14, 104. doi: 10.3389/fnins.2020.00104
PubMed Abstract | CrossRef Full Text | Google Scholar
Yin, B., Corradi, F., and Bohte, S. M. (2020). “Effective and efficient computation with multiple-timescale spiking recurrent neural networks,” in ICONS, 1–8. doi: 10.1145/3407197.3407225
CrossRef Full Text | Google Scholar
Zenke, F., and Vogels, T. P. (2021). The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks. Neural Comput. 33, 899–925. doi: 10.1162/neco_a_01367
PubMed Abstract | CrossRef Full Text | Google Scholar
Zhang, T., Zeng, Y., Zhang, Y., Zhang, X., Shi, M., Tang, L., et al. (2021). Neuron type classification in rat brain based on integrative convolutional and tree-based recurrent neural networks. Sci. Rep. 11, 7291. doi: 10.1038/s41598-021-86780-4
留言 (0)