
記住我
With an estimated 12 million cases each year worldwide, stroke is the second leading cause of death and a major cause of disability (1). Medical imaging is crucial not only for diagnosing and guiding stroke therapy but also for monitoring patients after treatment. The two main imaging modalities for stroke are Magnetic Resonance Imaging (MRI) and Computed Tomography (CT). MRI provides a very accurate image contrast of the brain and the lesion, the latter often provides a lighter or poor image contrast of the brain and the lesion than the surrounding healthy tissue. However, MRI is expensive and requires more time than a CT scan to be performed and is not always available in an emergency. Therefore, in the majority of the cases, CT scan is opted despite its lower contrast; in this modality, the lesion appears darker than the background. The advantage of CT scan is that hemorrhagic transformations are extremely well visible as a light spot in the dark lesion (2).
In recent years, machine learning (ML) has emerged as a powerful tool for segmenting the area of the brain affected by stroke. Despite methodological advances, the subject remains topical, as evidenced by the Ischemic Stroke Lesion Segmentation (ISLES) challenge, which took place annually from 2015 to 2018 and brought together teams from around the world in 2022 (3). As in general medical segmentation, the state-of-the-art architecture in stroke lesion segmentation is the U-Net architecture (4) and its no-new-Net (nnU-Net) variation (5, 6). The nnU-Net, in particular, has led to significant improvements and was the most widely used model in the latest ISLES challenge (7). Reflecting the growing focus on brain lesion segmentation, many alternative architectures have been proposed, utilizing both two-dimensional (2D) and three-dimensional (3D) models and a variety of deep learning techniques. For instance, 3D neural network architectures have been explored in a previous study (8), while other studies leverage multiple imaging modalities (9). Additionally, for improved segmentation accuracy, some studies adopt innovative approaches such as generative adversarial networks (GANs) (10) or employ vision transformers (VIT) (11).
Despite continuous advancements in stroke lesion segmentation, applying ML techniques to CT images remains a significant challenge. Due to the limited availability of large annotated public CT datasets until 2023, majority of the existing research has focused on MRI because of the difficulty that represents this imaging modality. Those inherent difficulties of CT imaging, such as lower contrast resolution compared to MRI, pose unique obstacles for stroke lesion detection. As an example, in a recent brain lesion segmentation challenge on joint segmentation of CT scan or MRI lesions (12), the top-performing team achieved a DSC of 0.67 on MRI, but only 0.20 on CT using the same acute stoke patients' tests. One critical factor is the timing of CT image acquisition, as lesion visibility can change dramatically in the first few hours and days after a stroke (13). Our focus on subacute CT images acquired 24 h after the stroke addresses a crucial window for stroke treatment, yet this phase remains underexplored in current research.
A closer examination of existing CT stroke lesion segmentation datasets reveals several additional challenges. Many datasets consist only of follow-up images, and the populations studied often do not reflect the diverse clinical characteristics of stroke patients. Moreover, much of the research has concentrated on hemorrhagic lesions (14, 15), which are easier to detect on CT due to their hyperdense appearance. Other studies exhibit biases in lesion size; for instance, in one study (16), the median lesion volume in the training set was 48 ml (using follow-up images), while the median lesion volume for MRI in the ISLES 2015 challenge was only 17 ml. However, lesion contrast—rather than size alone—appears to be the more significant challenge (17), as ischemic stroke lesions are often poorly contrasted with surrounding healthy tissue in CT images, making them difficult to distinguish.
Addressing these challenges requires specialized approaches for CT analysis. Techniques, such as window setting, which adjusts the Hounsfield unit (HU) ranges to enhance lesion visibility, have shown potential for improving CT segmentation (18). However, often, these methods fail when distinguishing ischemic lesions from normal tissue, as their intensity ranges can overlap significantly. Moreover, there is no consistent HU threshold that can reliably differentiate between healthy tissue and various types of brain lesions (19). To overcome these obstacles, innovative solutions are needed that account for the unique characteristics of CT imaging and the complexities of stroke lesion segmentation, particularly for subacute ischemic lesions, where lesion contrast and visibility, especially, are challenging.
The contrast issue is well-known among medical images analysis and various techniques have been developed to improve it, including morphological transformations (20) and super-resolution (21). Segmentation algorithms have specifically targeted low-contrast images with attention mechanisms on the objects of interest (22–24) or their contours (25). Although, these methods improve segmentation in specific scenarios, they are generally task-specific and they lack generalizability across other medical imaging challenges. Moreover, automatic quality assessment methods for CT datasets primarily evaluate acquisition-related factors (26), such as motion artifacts or field of view, or the quality of specific image processing steps such as registration (27). However, they do not address how the quality of a dataset impacts its suitability for specific machine learning tasks, particularly segmentation.
We aimed to develop a method for assessing the quality of CT datasets, specifically addressing the challenges posed by low contrast in CT scans. Unlike existing methods, our approach evaluates dataset quality in the context of a specific ML task. Our goal is to determine the minimum contrast value required for an ML model to successfully segment a stroke lesion on CT images. By exploring the constraints of low-contrast data, we seek to deepen the understanding of how contrast impacts segmentation performance. To achieve this, we developed a methodology based on performance, graphical, and clustering analysis that can be applied to any medical segmentation task using deep learning architectures. Our approach automates the quality control process, enabling efficient training of segmentation models by ensuring that only the most relevant data is used. This study provides a new tool for assessing dataset quality and addresses one of the main obstacles to CT segmentation of brain lesions.
2 Material and methods 2.1 MaterialWe used two independent databases, one for training the ML model and other for testing, to guarantee the generalizability of our results.
2.1.1 Training data: HIBISCUS-STROKE datasetWe included patients from the HIBISCUS-STROKE cohort. The design and methods of this cohort have been published in Debs et al. (28). Briefly, stroke patients with an anterior circulation stroke threated by thrombectomy underwent a baseline MRI and both CT and MRI follow-up scans, respectively, 24 h and 6 days after the treatment. This day-6 MRI is segmented to have a final lesion mask. The work is based on the hypothesis that the lesion is stabilized 24 h after treatment, and so the segmentation obtained on fluid-attenuated inversion recovery (FLAIR MRI) is used as reference for the CT scan.
A total of 108 patients are included in the study. All patients gave their informed consent and the imaging protocol was approved by the regional ethics committee.
2.1.2 Test data: RELATE dataset and APIS datasetRELATE is a monocentric prospective database of all consecutive patients treated by intravenous thrombolysis and/or thrombectomy, from the same center as for the HIBISCUS-STROKE cohort. The patients were selected with additional criteria compared to the HISBISCUS-STROKE dataset, specifically considering stroke severity scores: Alberta Stroke Program Early Computed Tomography Score (ASPECTS) < 6 and National Institutes of Health Stroke Scale (NIHSS) >7, resulting in the inclusion of only more severe patients. In these RELATE patients, the final stroke lesion was segmented on day 1 CT images, with an additional selection based on the ability of the annotators to accurately segment the images due to the difficulty that the manual CT scans segmentation represents, as day-6 MRI is not part of standard clinical practice. In total, 125 patients were included from this dataset. Due to the selection bias resulting from the severity scores and the ability of the annotators to accurately segment the images, the fact that the reference does not come from the same modality and that the RELATE dataset does not provide day-6 MRI, we could not fuse the two datasets, even though the images come from the same center.
A Paired CT-MRI Dataset for Ischemic Stroke Segmentation (APIS) Challenge, is the only stroke lesion segmentation challenge based on CT images (12). The dataset includes CT images from 60 patients in the acute phase, along with corresponding lesion masks derived from acute-phase ADC MRI scans. Since our work focuses on subacute images, we did not merge this dataset with ours. However, we still found it valuable to use the APIS dataset for testing to assess how our models perform on a different set of images.
2.1.3 PreprocessingBefore training and testing the models, some preprocessing steps specific to stroke lesion segmentation task were performed: (1) skull stripping with FMRIB Software Library (FSL), optimized for CT images (29, 30); (2) non-linear registration of images onto DWI MRI as a reference frame using ANTs (31); (3) separation of 3D volumes into 2D slices, with only slices containing lesions according to the reference being retained; (4) selection of slices containing lesions with an area >1cm2, as smaller lesions cannot be reliably segmented on CT; (5) selective horizontal flipping to place all lesions in the same hemisphere and provide a consistent lesion position prior; and (6) resizing of images to 192 × 192 pixels. Steps 3 and 4 assume that a rough location of the lesion is known from preliminary clinical examinations. Ultimately, the 108 patients included in the HIBISCUS-STROKE dataset represent 3,772 slices used for training the model. Treated the same way, the patients in the RELATE database represent 4,327 samples, and the APIS database contains 259 images, on which models are tested to test their transferability.
2.2 MethodsUsing the HIBISCUS-STROKE database, we identified the minimal image contrast for an ML model to successfully segment a subacute stroke lesion. The proposed method is summarized in Figure 1 and detailed in the following subsections.

Figure 1. Graphical representation of the methodology steps. The performance analysis are performed on results of models trained on raw dataset or dataset with data augmentation.
2.2.1 Contrast evaluationThe key element of our study is the evaluation of the contrast of the stroke lesion in the CT images. We used Fisher's ratio that is well-adapted to evaluate the contrast between an object of interest and the background. It is defined as follows:
F=(μobject-μbackground)2σobject2+σbackground2where μobject represents the mean of the values within the object of interest according to a ground truth, μbackground represents the mean of the values in the background tissue, and σobject2 and σbackground2 are the standard deviations squared in these respective regions. The Fisher's ratio assumes normally distributed data within each group and approximately equal variances across different groups.
2.2.2 Data augmentationThe training dataset underwent data augmentation (DA) to balance the distribution based on CT image contrast. This augmentation process occurs in two steps, each tailored to address specific aspects of the image data.
Initially, the lesion pixel density were systematically reduced by two HU, iteratively over three rounds, while preserving a border row of pixels unchanged to prevent the emergence of artifacts. This progressive reduction aims to create a smooth gradient within the lesion and mitigate the appearance of outlines resulting from drastic value modifications.
In a second step, applied selectively to slices exhibiting a higher standard deviation of lesion intensity than the background, further modifications were made to pixels falling below or above the median of the lesion's pixel values. Specifically, a modification of two units was applied to these pixels to equalize the appearance of inhomogeneous lesions. Subsequently, a selection process guided by the Fisher's ratio of the augmented images was employed, ensuring that the contrast remains within the range observed in the original dataset. Slices with overly low contrast were excluded, as they were already well-represented in the dataset.
For a detailed outline of this heuristic process, Supplementary Algorithm 1 provides a concise pseudocode overview.
2.2.3 Model training and testingThe U-Net (4) architecture was used to segment the stroke lesions in the CT images. It consists of a contractive path with 3*3 convolutional layers followed by a rectified linear unit (ReLU) activation function (32) and a 2 × max pooling operation. On the other side, there is an expansive path including an upsampling of the feature map, followed by a 2 × 2 convolution and concatenation with the corresponding feature map from the contractive path called skip connection, and two 3 × 3 convolutions, each followed by a ReLU. The training was done with Adam optimizer (33) and the sum of the Dice loss, based on the Dice coefficient, and the binary cross-entropy:
L=2×y×py+p-(ylog(p)+(1-y)log(1-p))where y is the ground truth and p is the prediction made by the model.
The U-net parameters were optimized by grid search, which consists of training several models with different sets of hyperparameters and selecting the one that performed best on the validation data. The parameters of the optimizer were thus set to β1 = 0.5 and β2 = 0.999 and the learning rate at lr = 0.0005. For the final models with both raw data and DA, a five-folds cross validation was performed. A maximum of 200 epochs were done and early-stopping was applied to the validation set to avoid overfitting. Only around 30 epochs were needed to complete model convergence. The final performances were computed from the test set.
The models were tested on a separate group of patients, who were not used during training. Only 5% of the patients in the original dataset were selected for testing. This selection process operates at patient level, preserving the independence of the test set. Data augmentation (DA) was deployed on the remaining 95% of patients, representing 3,527 training slices. With DA, this number rose to 14,415 slices, while 245 slices were reserved for testing without generating augmented data. The test subset was deliberately balanced to ensure a fair representation of slices across all contrast ranges, as shown in Figure 2. By comparing models trained with and without data augmentation, we checked whether uneven distribution influences poor performance in specific contrast scenarios.
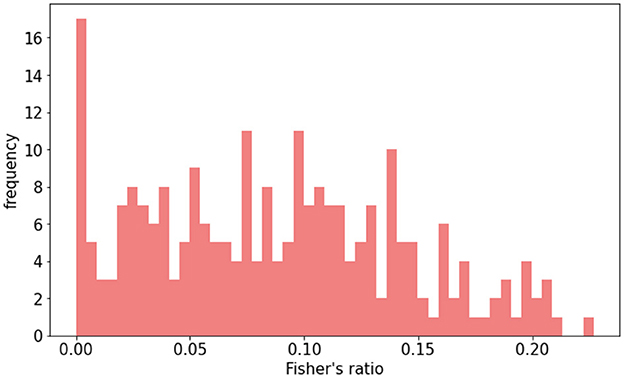
Figure 2. Distribution of Fisher's ratio in HIBISCUS-STROKE test set. Patients are selected, so the distribution is uniform in order to be able to compare the performance between different contrast ranges.
2.2.4 Evaluation metricsFour evaluation metrics were used to assess segmentation performance:
• Detection, determines if a lesion is present in a slice. It is binary, where 0 denotes the model's failure to segment a lesion where one exists according to the reference, and 1 signifies successful segmentation.
• Dice similarity coefficient (DSC), represents the superposition of the segmentation made by the model and the reference:
where TP are the true positives, FN the false negatives, and FP the false positives. Unsatisfactory results yield a DSC of 0. A value below 0.1 (10% overlap) is deemed unacceptable, although this threshold may vary depending on the task.
• Hausdorff distance (HD) between the segmentation (A) and the ground truth (B) is expressed as
HD=max(h(A,B),h(B,A)) where h(A,B)=maxmina∈A,b∈B||A-B||.It calculates maximum distance, in pixels, between segmentation and ground truth. With images of size 192 × 192 pixels and the brain typically occupying 70% of the slice height, a threshold of 60 pixels was set to prevent erroneous predictions in different brain regions (e.g., frontal instead of occipital).
• Relative Absolute Area Difference (RAAD) calculated by
RAAD=(TP+FP)-(TP+FN)TP+FN.It compares segmentation area to ground truth, normalized by the latter's area. The optimal value is 0. The RAAD value exceeding –0.5 or 0.5 indicates significant underestimation or overestimation, respectively, rendering the segmentation unsatisfactory.
Establishing satisfactory metric thresholds aided in identifying initial contrast thresholds in model performance analysis before proceeding with further evaluations.
2.2.5 Contrast threshold definitionTo gain an initial estimate of the contrast threshold value, we analyzed the model's performance using the performance thresholds outlined in Section 2.2.4, specifically in relation to contrast. This approach allowed us to categorize the samples based on their contrast, identifying those that perform well or poorly, and enabling the initial determination of the critical Fisher's ratio.
The first method for assessing the contrast threshold in relation to the model's performance involved graphical analysis using a receiver operating characteristic (ROC) curve. This curve plots the true positive rate (TPR) against the false positive rate (FPR), for different thresholds of Fisher's ratio. These two rates are calculated as follows:
TPR=TPTP+FN FPR=FPFP+TN.This approach involves calculating both TPR and FPR using different test sets, while gradually tightening the contrast threshold. By considering all slices, the TPR might be lower compared to when only images with good contrast are considered. In this type of plot, a distinct “elbow” is typically observed in the upper left corner of the curve, which denotes the best compromise between the TPR and FPR, allowing us to detect the best contrast threshold, related to this best compromise, can be identified at the point closest to this elbow. This point ensures a sufficiently high TPR while maintaining acceptable performance.
The second method relied on clustering analysis to identify two distinct groups of slices with varying contrast based on their segmentation performance. The aim is to separate slices that are easy to segment from those that are more difficult. This analysis uses two unsupervised clustering algorithms: the k-means algorithm (34) and the hierarchical clustering algorithm (35). The evaluation metrics (as presented in Section 2.2.4) and Fisher's ratio are used as features after being normalized between 0 and 1 for the clustering algorithms. To determine if there are performance differences correlated to contrast, the resulting centroids of each cluster are compared. The first algorithm, the k-means algorithm, is an iterative process where random cluster centers are assigned, data points are allocated to the closest cluster based on distances, new cluster centers are recalculated, and the process is repeated until stabilization. To mitigate the impact of random initialization, this is repeated 10 times. In contrast, the hierarchical clustering algorithm initially treats each data point as a separate cluster and progressively merges the closest clusters until only two clusters remain. Both algorithms are tested with various distance metrics, such as Euclidean distance (36), squared Euclidean distance (37), Manhattan distance (36), Chebyshev distance (38), and Canberra distance (36). The less variation there is between methods and distances, the more confident the separation is. To determine the best method and distance, two quality measures are used: the purity and silhouette scores. The purity score indicates the percentage of accurately classified objects according to a predefined Fisher's ratio value, while the silhouette score measures the difference between the cohesion within clusters and the distance between clusters. A higher silhouette score, closer to 1, indicates better performance. Since the first method is supervised by a Fisher's ratio threshold and the second is unsupervised, we can assess their correlation. If they are well-correlated, it would confirm the consistency of the selected Fisher's ratio threshold. Additionally, we can vary the threshold used to calculate the purity score to find the value that best correlates with the silhouette score.
2.2.6 Contrast threshold validation and model transferabilityTo validate the contrast threshold found with graphical and clustering methods, we trained a model removing the slices with a Fisher's ratio under this threshold and compared its performances with the one trained with the whole dataset. If the performances are steady even if some data is removed, it means that the removed data did not bring informative knowledge concerning the segmentation task, enabling us to conclude on the critical contrast threshold. Furthermore, this allows for quantifying potential computational cost reduction based on the extent of data removal during the training phase.
Since we possess additional datasets for stroke lesion segmentation via CT scan, it presents an opportunity to assess the applicability of models trained in the preceding section on the RELATE and APIS datasets. This evaluation aims to determine whether these models can be directly transferred to another database, despite being trained without low-contrast slices. If the outcomes align closely, it reinforces the validity of the threshold, indicating that low-contrast images do not contribute significant information during training, even when the models are deployed on a novel dataset.
3 ResultsAll the pipeline being explained, we can apply it to the HIBISCUS-STROKE dataset to determine the contrast threshold for stroke lesion segmentation on CT scan, to control the quality of the dataset for this task with respect to the 2D U-Net model.
3.1 Image contrast in the two datasetsAs reported in a previous study, we observed a Gaussian distribution of HU values in CT data (39). We assessed normality through histogram analysis and homogeneity via variance comparisons using dispersion plots. This allowed us to employ Fisher's ratio to quantify lesion contrast in our images. Fisher's ratio is calculated for each slice after applying a threshold to the HU of the scanner: pixels with values >80 were eliminated to avoid including the skull, while pixels with values < 15 were also discarded or exclude cerebrospinal fluid and calcifications, as had been similarly implemented in previous studies (40, 41). Subsequently, the slices were normalized between 0 and 1. Given that the lesion is the object of interest, the mean and standard deviation values used in Fisher's ratio calculations corresponded to the HU of the lesion and the HU of the healthy tissue in the ipsilateral hemisphere.
The distribution of Fisher's ratio in the HIBISCUS-STROKE dataset (Figure 3A) revealed a significant imbalance, with a predominance of very low contrast slices, expectedly the most challenging to segment. Examples of such slices are depicted in Figure 4, highlighting the considerable contrast variability evident in CT scans, underscoring the difficulty of the segmentation task.
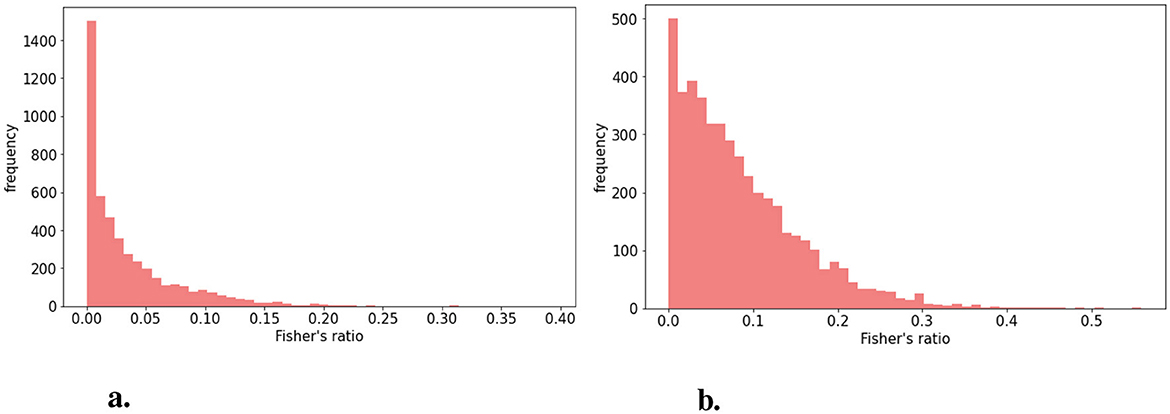
Figure 3. Distribution of Fisher's (A) in the HIBISCUS-STROKE dataset which is highly imbalanced (B) in the RELATE dataset which is less imbalanced and with higher maximum value.

Figure 4. Examples of slices of different lesion contrast with their reference (A) higher contrast (B) lower contrast showing the variability among the dataset and the difficulty of segmentation of stroke lesion segmentation on CT scans.
Similarly, Fisher's ratio was computed for the RELATE dataset, resulting in the distribution depicted in Figure 3B.
3.2 Raw dataset vs. data augmentationTo examine how imbalances in lesion contrast within the dataset affected model performance, we initially compared models trained on raw data with those trained using DA. The Fisher's ratio distribution in the DA dataset is represented in Figure 5. Results outlined in Table 1 indicate that DA consistently enhanced all performance metrics.
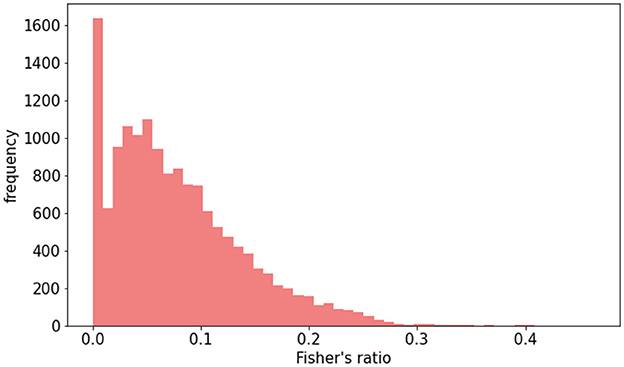
Figure 5. Distribution of Fisher's ratio in augmented HIBISCUS-STROKE dataset in which the imbalance is reduced.
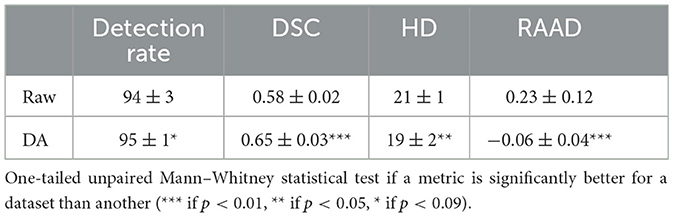
Table 1. Quantitative results of models trained with or without DA.
A more detailed analysis, correlating performance metrics with Fisher's ratio (Figure 6), revealed that models trained with DA consistently outperformed those trained solely on raw data. Notably, this improvement was most pronounced for intermediate contrast values, which aligned with the focus of our DA strategy. Therefore, we decided to consider exclusively the models with DA for the rest of the study.
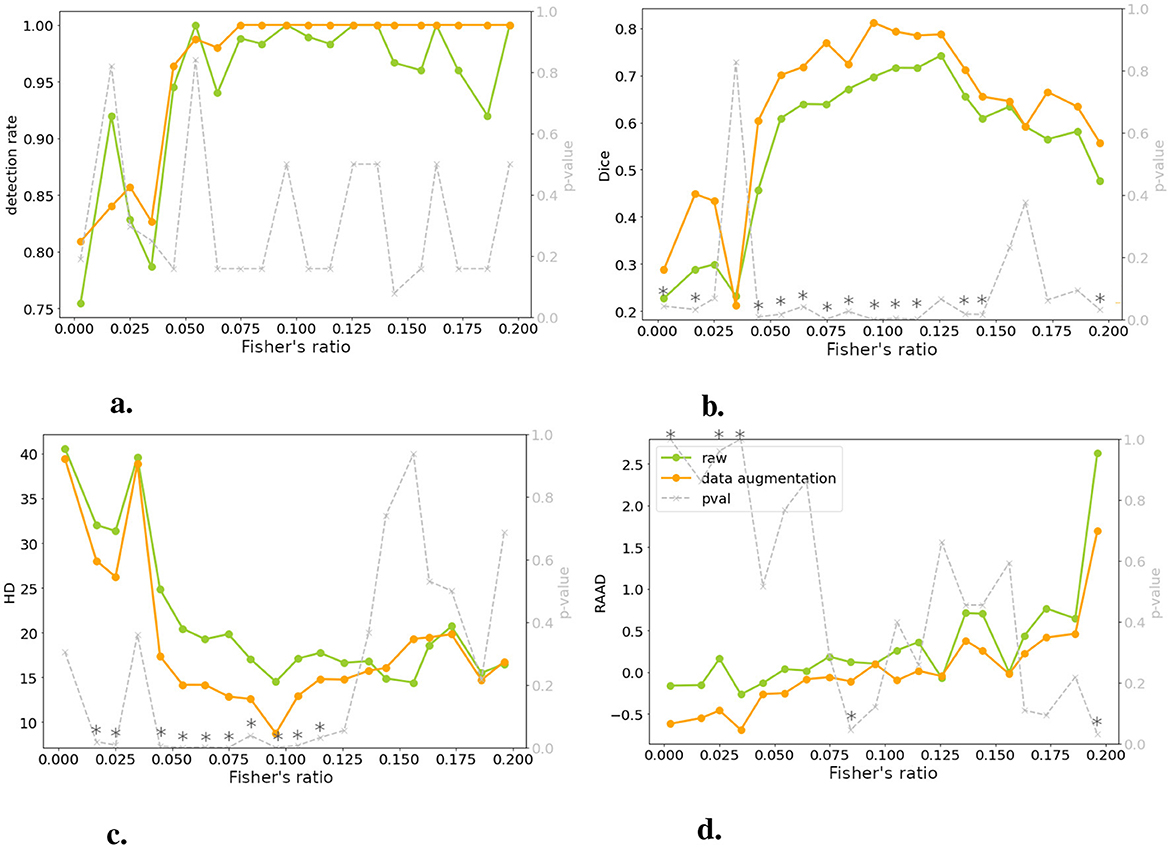
Figure 6. Comparing models trained on raw and DA data for four metrics: performance is plotted against test set image contrast. One-tailed Wilcoxon tests determine if DA-trained model outperforms raw-trained model (gray dotted line, right y-axis; * indicates p < 0.05 or > 0.95). There is no significant differences between raw and DA for a specific range of contrast, meaning that the contraste imbalance does not penalize a specific range of contrast. (A) Detection rate. (B) DSC. (C) HD. (D) RAAD.
3.3 Performance in relation to contrastFigure 6 demonstrated a decline in lesion detection rate, DSC, and HD for slices with a Fisher's ratio below 0.05. Notably, 82% of the undetected lesions in both models (with and without DA) exhibited a Fisher's ratio below 0.05. Similarly, when considering a DSC threshold of 0.1 (as defined in Section 2.2.4), 77% of slices with unsatisfactory DSC had a Fisher's ratio below 0.05. When examining the HD metric, this proportion increased to 100%. Interpreting RAAD was more complex due to two thresholds concerning underestimation and overestimation of the lesion. When focusing on RAAD values below –0.05, 79% of the slices demonstrated a contrast below the threshold, while overestimation of the lesion area was less prevalent. Generally, the second case (without DA) displayed fewer instances of overestimated slices, as discussed in Section 3.2.
3.4 Graphical analysisTo assess performance at different contrast levels, we employed ROC curve analysis, measuring false positive rate (FPR) and true positive rate (TPR) using various contrast thresholds. Figure 7 illustrates the resulting FPR and TPR, with each point representing a distinct contrast threshold. It may appear counterintuitive that the FPR increases with contrast, as higher contrast is generally associated with easier segmentation. However, Figure 7 reveals that the x-axis labels were significantly compressed compared to the y-axis. It is important to note that despite the increase, the FPR remained consistently below 1% for all contrast levels. Moreover, as discussed in Section 3.3, when contrast is very low, lesions tend to be underestimated, which can lead to a lower FPR. Conversely, as the contrast increases, the trend reverses, indicating a possible increase in false positives.
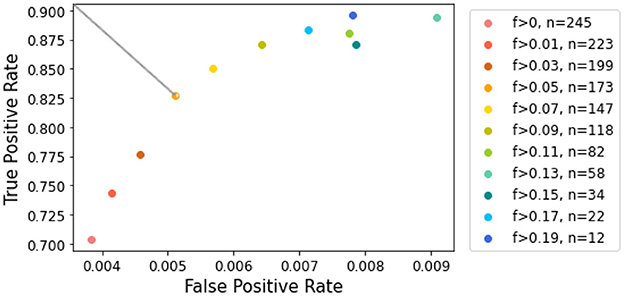
Figure 7. ROC curve for lesion detection given contrast values. The color scale corresponds to contrast values increasing in magnitude. The top left point corresponds to a contrast of 0.05, which allows the most significant gain in true positive rate.
When examining the axis scales, particular attention should be given to the TPR. Our analysis showed that removing slices with the lowest contrast has a greater impact on improving TPR during the early stages of elimination. However, beyond a Fisher's ratio of 0.05, further increases in TPR became less noticed. This threshold provided the best balance, retaining a reasonable number of slices while ensuring accurate lesion estimation. Focusing on the cropped ROC curve shown in Figure 7 [following the AUCReshaping method described in Bhat et al. (42)], we observed that the point corresponding to the exclusion of slices with a Fisher's ratio below 0.05 is closest to the top-left corner. This point represents the optimal compromise between TPR and FPR in this range.
3.5 Clustering approachTo further corroborate the Fisher's ratio threshold of 0.05, we used unsupervised clustering methods to determine whether distinct groups could be identified according to lesion contrast.
The quality scores of the clusters, defined in Section 2.2.5, are presented in Table 2. According to the silhouette score, k-means clustering with the Canberra distance yielded the best results. The purity score, which is based on predefined clusters (slices with a Fisher's ratio below or above 0.05), also showed its highest value with k-means using the Canberra distance. This provided an initial validation of the clusters. The correlation between the silhouette score and the purity score is 0.804, further confirming that a Fisher's ratio threshold of 0.05 effectively separated slices based on performance metrics. When considering the variability among the methods, the standard deviation across all purity scores was 0.5%, while it was 0.013 for the silhouette score, accounting for ~0.7% of all possible values. These values indicated the successful separation of data points into two clusters. To further validate the threshold, we examined the correlation between the silhouette score and the purity score across different contrast threshold values. The variation in the R2 coefficient, as shown in Figure 8, demonstrated that the best correlation is achieved with a threshold of 0.05.
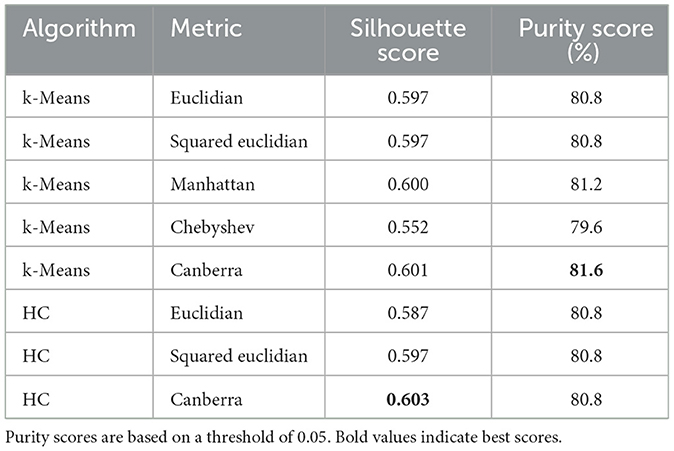
Table 2. Clustering quality scores according to the different methods and metrics used.
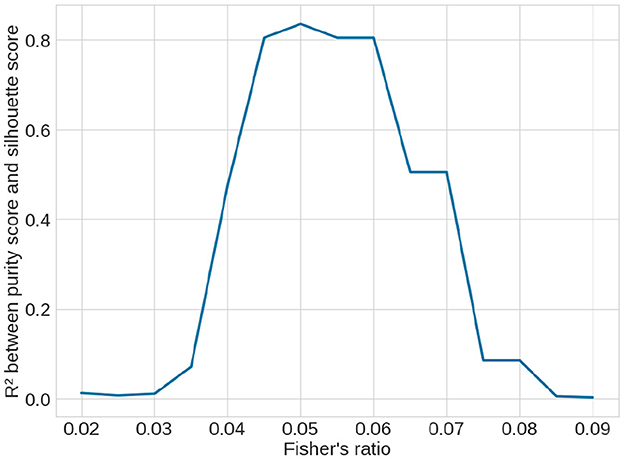
Figure 8. Variation of R2 correlation coefficient between the unsupervised silhouette score and the supervised purity score over the clustering methods (see Table 2) depending on the contrast threshold selected to supervise the purity score. The best coefficient is obtained with a threshold at 0.05, showing that it is the best threshold.
After examining the clusters shown in Figure 9, it was apparent that the separation based on the Fisher's ratio of 0.05 was not as distinct as anticipated. However, the centroids of the clusters were clearly discernible. The Fisher's ratio means for the two clusters were 0.039 and 0.101, respectively. Nevertheless, there were still some slices with low contrast that were classified alongside well-segmented slices with high contrast. Fortunately, when evaluating the DSC or the HD, these slices exhibited a satisfactory segmentation outcome.
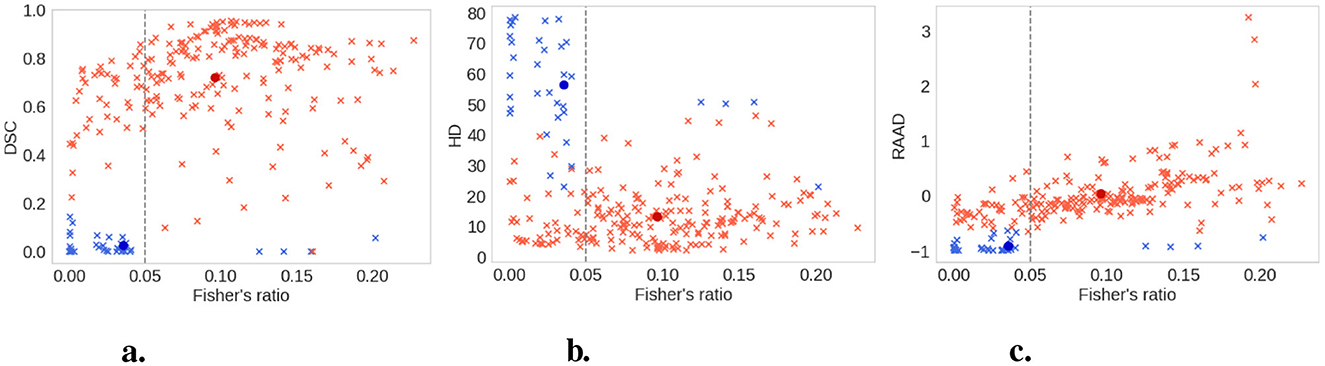
Figure 9. Clusters (good contrast in red and low contrast in blue) with the k-means method and the Canberra distance. All slices are the light crosses, the centroids of the clusters are the dark dots. Vertical dashed line represents Fisher's ratio threshold. The 0.05 threshold is the best value to separate the clusters created by the clustering method. (A) DSC. (B) HD. (C) RAAD.
3.6 ValidationTo validate the defined contrast threshold, we determined whether the slices with low contrast provided useful information. We trained a new model using the same parameters and dataset as in Section 2.2.3, excluding any slices with a Fisher's ratio below 0.05. The hyperparameters were optimized with grid search as detailed in Section 2.2.3. For this reduced dataset, with only 60% allocated for training the parameters of the optimizer were set to β1 = 0.5 and β2 = 0.999, and the learning rate at lr = 0.001. We then compared the results of the models trained with and without the low contrast images on both the entire test dataset and a subset of the test dataset that excluded low-contrast slices: results are presented in Table 3.

Table 3. Comparison of models trained with and without the slices with a Fisher's ratio < 0.05.
Excluding low-contrast slices from the training dataset had little impact on model performance when tested on the full test dataset, and marginally improved the DSC and HD when tested on slices with a Fisher's ratio >0.05. These results indicated that low-contrast slices (i.e., Fisher's ratio < 0.05) did not provide critical knowledge for segmentation. Thus, excluding low-contrast slices could allow for a significant reduction in computational time (from an average training time of 1 h and 50 min for the whole dataset to an average of 1 h and 20 min without the low contrast slices), without significant performance costs.
3.7 Transferability of the modelsTo ensure the reliability of our methodology, we extended our evaluation to both the RELATE and APIS datasets (see Section 2.1.2). Our goal was to investigate whether removing 40% of the training data would impact the transferability of our models to different datasets. We compared the performance of two models: one trained on the entire HIBISCUS-STROKE dataset and the other trained on the same dataset, excluding slices with a Fisher's ratio below 0.05.
Despite training the model without low-contrast slices on a reduced training dataset (40% less data), its performance on RELATE dataset was similar to the model trained on the complete dataset, as indicated in Table 4. Notably, both models achieved performance l
留言 (0)