Participants and sampling
The present cross-sectional study was conducted on 900 women of reproductive age. Sampling lasted for six months from March 21 to September 23, 2023. The sampling method was community-based and data was collected using multi-stage sampling from health-treatment centers. Health care centers are places where primary health care is provided according to the population covered in different areas of the city. Ten centers were randomly selected from all available health centers and it was ensured that the selected sample could be generalized to a larger population of the target population. Subsequently, among women of reproductive age, sampling continued based on the study’s eligibility criteria until the required sample size was achieved. The eligible criteria included women of reproductive age who had experienced at least one delivery (traumatic or non-traumatic) and had the potential for future pregnancy or re-fertilization. Women’s cooperation to participate in the study was satisfactory. The sample size was estimated at 900 using the formula N = S2 Z2/d2 according to the study by Irani et al. [24], to achieve the objectives of the study. Demographic information and history of pregnancy and childbirth were obtained from the women. In order to identify the history of traumatic childbirth, the DSM-A criterion was used, and Miller’s questionnaire was used to check positive and negative motivations. Incomplete answers to questionnaires led to exclusion from the study. A researcher collected the data from a wide range and separately and privately explained how to answer the questions.
Ethic statements
The proposal of this study was conducted after obtaining the required permit (ID: 4012045) from the Ethics Committee of Mashhad University of Medical Sciences (with the registration code IR.MUMS.NURSE.REC.1401.117). They were assured that participation in the study would be voluntary and information would be kept confidential. Women agreed to participate in the study and all of them provided their informed letter of consent.
Questionnaire
The questionnaires used in this study included Miller’s Childbearing Motivation Questionnaire (CMQ), which has two dimensions [25]. The first dimension of positive childbearing motivation (34 items) includes the joy of pregnancy, birth and childhood (6 questions), traditional parenthood (6 questions), satisfaction with parenting (6 questions), feeling of need and survival (5 questions) and instrumental use of the child (11 questions). In the Persian version of this questionnaire, 7 items have been added to the positive motivations of Miller’s questionnaire, which are taken from the qualitative study of Khadivzadeh and in line with the adaptation of this questionnaire to Iranian culture [26]. The second dimension is negative childbearing motivation (19 items), which includes the areas of fear of becoming a parent (7 questions), parental stress (8 questions) and child care challenges (4 questions). To score the Childbearing Motivation Questionnaire, a 4-point rating scale ranging from totally disagree (score 1) to totally agree (score 4) was used. Validity and reliability of this questionnaire have been investigated in previous studies in the population of Iranian women [27].
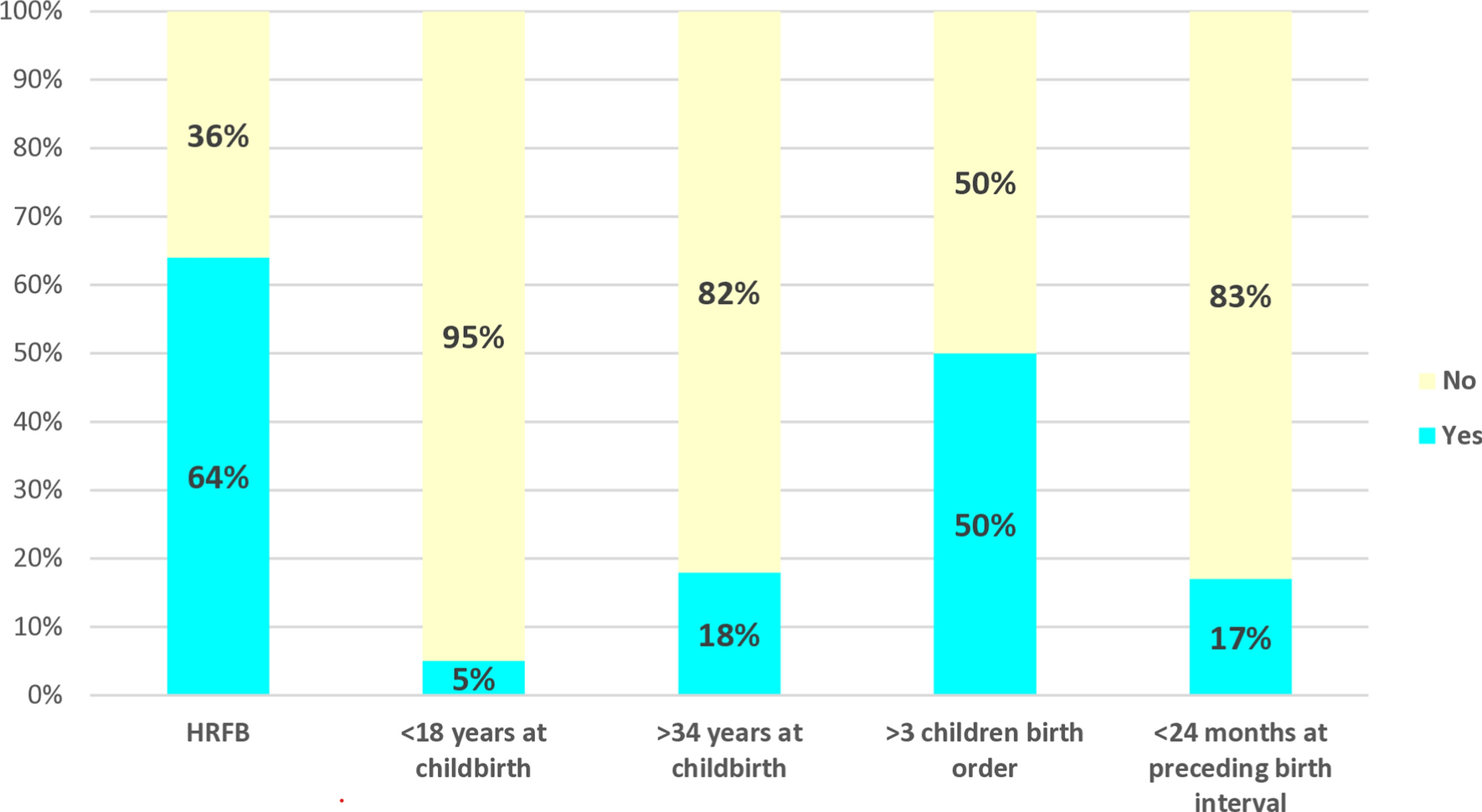
To screen women for traumatic childbirth, a tool aligned with the criteria A of DSM-5 definition of a traumatic event was utilized. This tool assesses the DSM-A through four questions posed to the women. According to this criterion, two fundamental domains of threat (1,2) and emotional (3,4) answer are required for an event to be regarded as a traumatic childbirth. These questions include:
1.
Do you think during labor, your life or your baby’s life was at risk?
2.
Do you think during labor you, or your baby could be physically harmed?
3.
Do you think this childbirth was a hard and uncomfortable experience for you?
4.
During labor or delivery, did you feel panicked, worried, or helpless?
Traumatic childbirth is indicated by positive responses to one of the first two items and one of the last two items. Thus, two affirmative answers from these four questions mark the childbirth as traumatic [7, 28].
The tool for collecting demographic information included questions such as age, education of women and their husbands, place of residence, employment status, drug use by women and their husbands, religious beliefs, level of support from spouses, duration of marriage, and socioeconomic status. Information related to pregnancy and childbirth included questions such as the number of pregnancies, the number of live children, the history of abortion, the history of stillbirth, the number of cesarean sections, and the history of infant hospitalization. These questionnaires were validated by experts and key people after summarizing by the research team. A MSc midwifery explained all three parts of the questionnaires to the women, who then provided their consent and completed the self-report form.
Statistical analyses
The aim of the present study was to build separate predictive models of positive and negative fertility motivation scores in women with a history of traumatic childbirth. Potential predictors are introduced in Table 1. Among the 900 participants, 30 participants did not have a partial response for the positive or negative motivation questionnaire data; missing values were imputed using k = 10 nearest neighbors. To reduce the risk of overfitting and ensure reproducibility, prediction models in nested cross-validation (NCV) were built [29].
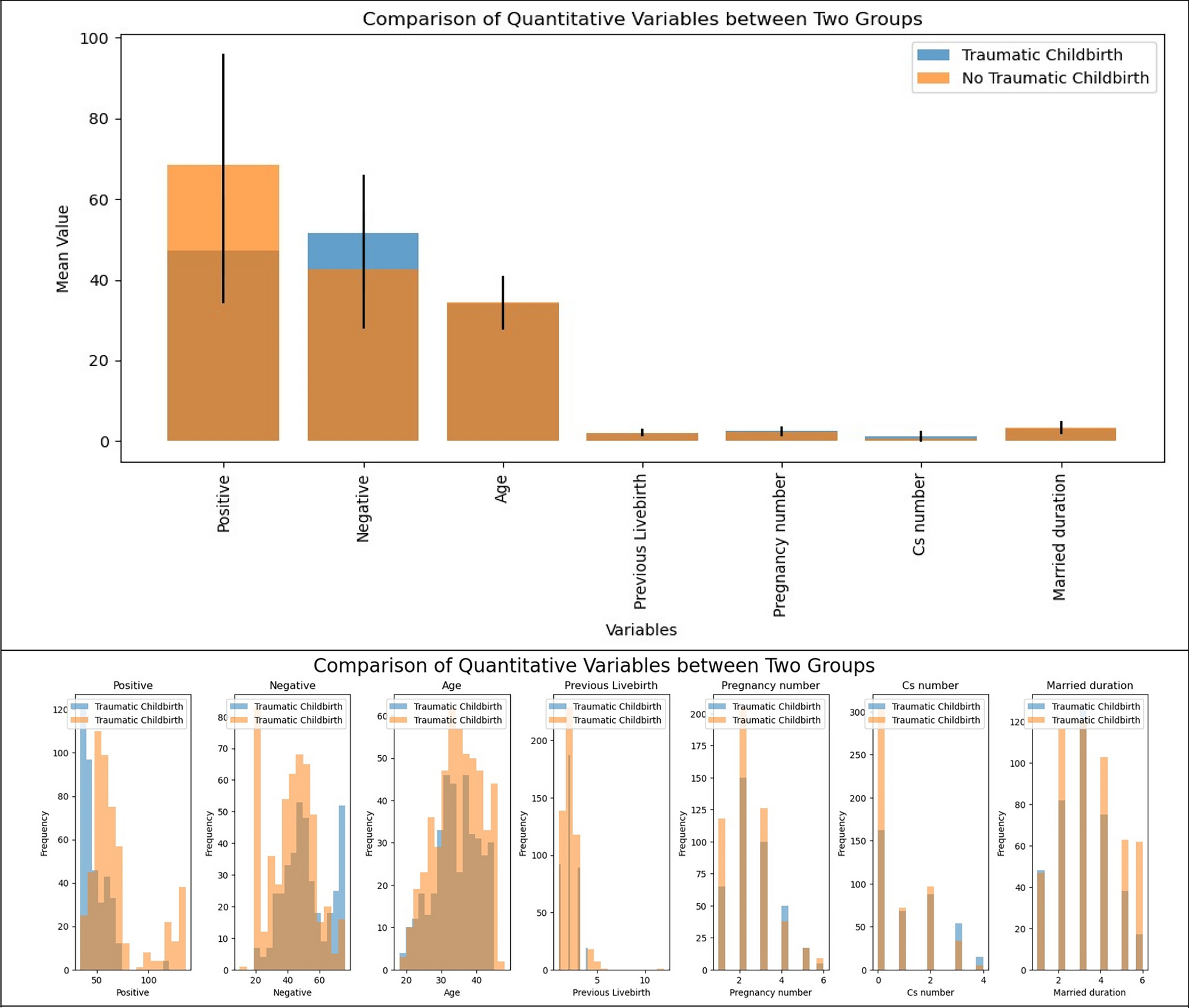
Table 1 The results of demographic information and history of pregnancy and childbirthHyper parameterization
K-fold cross-validation is a hyperparameter setting that enhances model validation and generalization. In this study, k was set to 5, meaning the entire dataset was divided into five parts, with each part serving as a test set while the remaining four parts formed the training set. This approach helps mitigate overfitting by ensuring that the model’s performance is evaluated on unseen data, thus providing a more reliable estimate of its predictive capability. In the outer loop, the dataset was divided as described, while in the inner loop, each training set was used to optimize tuning parameters through standard k-fold cross-validation. The trained models were then used to predict unseen test sets in the outer loop, allowing for the evaluation of model performance. This process was repeated five times, resulting in a total of 25 final models, which facilitated the assessment of variability in model performance and variable selection.
Model
In this study Elastic Net regularization was employed as the model-building algorithm because of its effective feature selection capabilities. This approach is particularly valuable for its ability to discern relevant predictors from complex datasets. Its strength lies in handling correlated variables, making it well-suited for studies focused on intricate factors like fertility motivations [30]. Elastic Net is a combination of two well-known methods, Ridge and Lasso, each with its own advantages and limitations. Ridge works effectively with data that has many features by controlling regression coefficients and reducing the risk of overfitting, but it cannot completely eliminate some unnecessary features. On the other hand, Lasso excels in simplifying models and selecting relevant variables due to its ability to fully eliminate certain predictors. However, it encounters challenges when features are highly correlated. By combining these two approaches, Elastic Net creates a balance between model simplicity and prediction accuracy. In situations where some variables are highly correlated, Elastic Net performs well, identifying and retaining multiple related variables, while Lasso retains only one and discards the others. This capability is particularly valuable for the current study, which aims to identify complex factors such as positive and negative fertility motivations. Another strength of Elastic Net is its use of two tuning parameters, α (alpha) and λ (lambda), which allow control over the model’s behavior. The parameter α, ranging from 0 to 1, governs the similarity of Elastic Net to Ridge and Lasso methods. This flexibility enables researchers to establish a balance between these two approaches according to the study’s needs. The parameter λ serves as a penalty factor, determining how simple or complex the model should be [31]. In this study, Elastic Net was used as a tool to create a reliable predictive model, demonstrating strong performance in both accuracy and interpretability of results. The 1-SE method was employed to select optimal parameters, ensuring that the final model strikes an appropriate balance between predictive accuracy and model complexity. Additionally, the significance of the models was statistically assessed through permutation testing, highlighting the high capability of Elastic Net in providing reliable results. Overall, Elastic Net is utilized in this study as a robust and suitable method due to its feature selection power, balance between accuracy and simplicity, and ability to control complexities within the data, resulting in statistically meaningful and high-performing models.
Accuracy measures
The metrics used in this study include R-squared (R2), which measures the proportion of variance in the dependent variable explained by the independent variables, with values close to 1 indicating optimal model performance. Mean Absolute Error (MAE) calculates the average absolute differences between predicted and actual values, where lower MAE values signify higher accuracy. Root Mean Square Error (RMSE) computes the average magnitude of errors while giving more weight to larger errors, with lower RMSE values reflecting a better model fit to the data. In this process, model parameters are selected based on those closest to the minimum RMSE (the best accuracy). However, increasing model complexity may lead to a slight increase in RMSE values. This balance between accuracy and simplicity is achieved through the determination of optimal parameters, with the combination of parameters evaluated for each training set in the inner loop. Initially, a linear regression model was created using the Elastic Net to determine the regression coefficients for each variable [32].
Then, by changing the values of these coefficients, 25 different models were created. If the mean values of the standard errors (SE) of the regression coefficients were positive or negative (i.e., non-zero coefficients), that model was selected as the predictor. The selected models were evaluated using accuracy measures such as R-squared, MAE and RMSE. To ascertain the significance of models and errors, a permutation test was performed. In this study, pregnancy motivation scores were randomly shuffled and models were retrained using the predictive matrix. This operation was repeated 1000 times [33]. It should be noted that two dependent variables (positive and negative fertility motivations) have been investigated separately and the entire analysis has been performed independently for each.
All analyzes were performed using Python version 3 [34], using pandas, numpy, scipy, sklearn, statsmodels, seaborn and matplotlib libraries. A summary of the used libraries is provided at the end of the study in the Abbreviations section.








留言 (0)