
記住我
It is estimated that about 15 million babies (more than one in ten births) are born prematurely every year, and this number continues to rise (Blencowe et al., 2013). Premature birth often leads to neurological impairments in newborns, including immature brain development and varying degrees of brain injury (Gonzalez-Moreira et al., 2023). Additionally, the early immaturity state of the brain can have long-term effects on neurological development, learning abilities, and behavior during childhood (Ream and Lehwald, 2018; Rogers et al., 2018; Guarini et al., 2010). Effective monitoring of the brain functional maturity in the neonatal period enables timely intervention and the development of optimal treatment plans, improving neurodevelopmental outcomes for preterm infants. Brain functional maturity is reflected by the biological brain age that is functional brain age (FBA). Postmenstrual age (PMA) refers to the age since the mother’s last menstrual period when pregnancy began. The difference between the FBA and PMA, termed as brain age disparity, is a direct biomarker of brain functional maturity in preterm infants (Salih et al., 2023). In preterm infants with normal neurodevelopment, the PMA is the actual FBA. If the difference between them is more than 2 weeks, it indicates that the brain functions of premature infants have delayed or advanced development. Therefore, the accurate prediction of FBA in preterm infants is crucial for enhancing the assessment of neurodevelopment in clinical settings.
Neurological studies have demonstrated that electroencephalography (EEG) contains some markers of the brain functional maturity (Salih et al., 2023). EEG is a noninvasive method used to capture neuronal changes and display brain activity. It is widely utilized for early therapeutic decision-making and predicting neurodevelopmental outcomes in preterm infants. Currently, the primary method for assessing FBA in preterm infants relies on expert visual evaluation of the EEGs (Fogtmann et al., 2017). This approach supplements traditional anatomical measurements such as weight, length, and head circumference, and complements structural information from imaging techniques like cranial ultrasound and MRI (Twanow, 2017). Despite the convenience of EEG monitoring, raw EEG data are extensive and contain numerous artifacts, requiring experienced neurophysiologists to spend considerable time interpreting the data (Mathieson et al., 2016). The complexity of neonatal brain development further complicates the EEG evaluation, requiring years of experience for accurate interpretation, and subjective assessments can lead to inconsistencies among different physicians (Dempsey et al., 2018). Therefore, developing an automatic method to predict the FBA in preterm infants based on EEG is essential to improve the objectivity and quality of perinatal care.
With advancements in signal processing theories and machine learning technologies, researchers have attempted to extract features from EEG signals that reflect subtle changes in neurophysiological function and develop models to automatically predict the FBA of neonates. In these methods, FBA can be successfully predicted by training a regression model using the PMA as the label. Based on EEG, O’Toole et al. employed the spontaneous activity transients (SAT) detection algorithm (Palmu et al., 2010) to extract a linear combination of 41 amplitude, time, and spatial features and developed a support vector regression (SVR) model to estimate the FBA (O'Toole et al., 2016). The difference between the predicted FBA and PMA, that is prediction error, was 1.29 weeks for very preterm infants aged 23–32 weeks PMA. Stevenson et al. later applied this method to a broader PMA range of 24–38 weeks, achieving a prediction error of 1.49 weeks (Stevenson et al., 2017). They also compared data from two different hospitals and achieved a median prediction error of less than 1 week (Stevenson et al., 2020). Using the same feature extraction method, Dong et al. collected extensive EEG data from 1851 subjects and constructed a gradient boosting machine (GBM) model to predict the FBA, achieving a Pearson correlation coefficient (PCC) of 0.904 between the predicted FBA and PMA in normal neonates (Dong et al., 2021). De Wel et al. used visually marked quiet sleep (QS) periods and multiscale entropy features to predict the FBA using a linear regression model, resulting in a prediction error of 1.88 weeks (de Wel et al., 2017). Gschwandtner et al. extracted features from a convolutional neural network to assess the FBA, achieving a disparity of less than 2 weeks between the predicted FBA and PMA in 93.6% of cases (Gschwandtner et al., 2020).
Generally, the recorded EEG signals have several channels. If all channels are used in EEG analysis, some channels unrelated to the predictive goal may degrade model performance and efficiency. Therefore, channel selection is a key stage in the prediction of FBA of preterm infant like other EEG applications, such as depression detection (Shen et al., 2021; Zhang et al., 2022), seizure detection (Duun-Henriksen et al., 2012; Ra et al., 2021), emotion recognition (Yildirim et al., 2021; Javidan et al., 2021; Li et al., 2022), and brain-computer interfaces (Varsehi and Firoozabadi, 2021). In EEG channel selection, commonly used methods include filter, wrapper, and embedded approaches (Baig et al., 2020). Filter methods employ distance measures, statistical measures (Bhattacharyya and Pachori, 2017), and information measures (Qi et al., 2021), providing rapid responses and being classifier independent, though they often fall short in accuracy. Wrapper methods assess channels by training and testing classification algorithms, which can achieve higher accuracy but require more computational resources. Embedded methods can enhance performance by selecting channels during the classifier training phase and depending on specific classifiers. However, most studies on the prediction of FBA in preterm infants have not focused on channel selection, just like the methods mentioned above. Stevenson et al. reduced the number of channels due to the limitations of heterogeneity in electrode across two datasets and extracted features from two bipolar reference channels. Gschwandtner’s study explored 1, 4, and 8 bipolar reference channels, in which symmetric channel configurations were solely focused. However, this approach potentially overlooks other channel combinations that may yield higher accuracy (Gschwandtner et al., 2020). These attempts to reduce electrode channels are due to data limitations or clinical experience rather than optimal channels selection.
Another important stage of EEG based prediction of the FBA is crucial feature selection. Feature selection is essential for eliminating redundant features, improving model performance, and reducing overfitting. In predicting FBA in preterm infants, O’Toole et al. combined and compared features in various domains, such as the time domain, frequency domain, and a combination of both (O'Toole et al., 2016). However, this approach potentially overlooks the impact of individual features on model prediction accuracy. Stevenson et al. used feature label correlation and statistical tests to select features, which was prone to produce noise and often overlooked feature interactions (Stevenson et al., 2017). Dong et al. utilized a gradient boosting machine (GBM) with backward selection (Dong et al., 2021), however, this approach also overlooked the impact of feature interactions on the model’s performance. Overall, these methods lack a systematic approach in identifying the most relevant features for determining the FBA of preterm infants.
In order to better predict the FBA in preterm infants, we propose an automatic prediction framework based on EEG, in which we focus on optimizing channels and features selection. Our study is structured into four main parts. Firstly, we extract features from each channel across the amplitude, range-EEG (rEEG), inter-burst interval (IBI), spectral and nonlinear domains, respectively. Next, we propose a novel channel selection method by combining binary particle swarm optimization (BPSO) with forward addition (FA) and backward elimination (BE) methods. Then, in the feature selection phase, we utilize a feature selection method based on the combination of the PCC, recursive feature elimination (RFE) and SVR model, named PCC-RFE-SVR to enhance the performance prediction model. Lastly, in the model training and prediction phase, we train the most effective models using various regression techniques such as SVR, random forest (RF), gradient boosting decision trees (GBDT) and light gradient boosting machine (LGBM). By using fewer channels and features, the prediction accuracy and model’s portability are significantly improved, while reducing computational complexity and overfitting.
In a summary, the contributions of this study are as follows:
(1) Aiming to reduce unrelated channels and enhance the efficiency and accuracy in predicting the FBA in preterm infants, we propose a novel channel selection method that combines BPSO with FA and BE methods. It selects the optimal channels by minimizing the mean absolute error (MAE) between the predicted FBA and the actual FBA.
(2) In order to eliminate redundant features and consider the interactions of the features, we employ the PCC and RFE combined with the SVR method to select effective features from the selected channels.
(3) By optimizing the channels and features, we significantly reduce computational costs and overfitting, and enhance the model’s portability. Moreover, we train different models using advanced regression techniques such as SVR, RF, GBDT and LGBM to validate the performance of the proposed framework. The experimental results show that the proposed framework based on the SVR model provides the best performance for the EEG signals recorded by ourselves from the First Hospital of Jilin University, Norman Bethune.
The rest of this paper is organized as follows. Section 2 presents the materials and methods, including data description and preprocessing, feature extraction, feature normalization, evaluation metrics, channel selection, feature selection, and regression models. Section 3 presents the results of channels and features selection, hyperparameter optimization, performance comparisons, and prediction errors distribution analysis. Section 4 offers a discussion on the findings. Finally, the conclusion and future work directions are presented in Section 5.
2 Materials and methodsThe implementation process of the proposed framework for the FBA prediction of preterm infants based on EEG is shown in Figure 1. First, we collect EEG signals of preterm infants. After removing noise and artifacts by data preprocessing, we segment the preprocessed EEG data into one-hour intervals. Next, these data are divided into balanced training and testing sets across different age groups. Then we extract features from four frequency bands: delta (0.5–4 Hz), theta (4–7 Hz), alpha (7–13 Hz), and beta (13–30 Hz). We combine BPSO with FA and BE methods for channel selection. Following this, significant features are identified using the PCC filtering and RFE combined with the SVR model. Finally, to compare the performance of different models in predicting FBA, we train advanced regression models such as SVR, RF, GBDT, and LGBM. Subsequently, the trained models are then evaluated on the test set to ensure their generalizability and reliability.
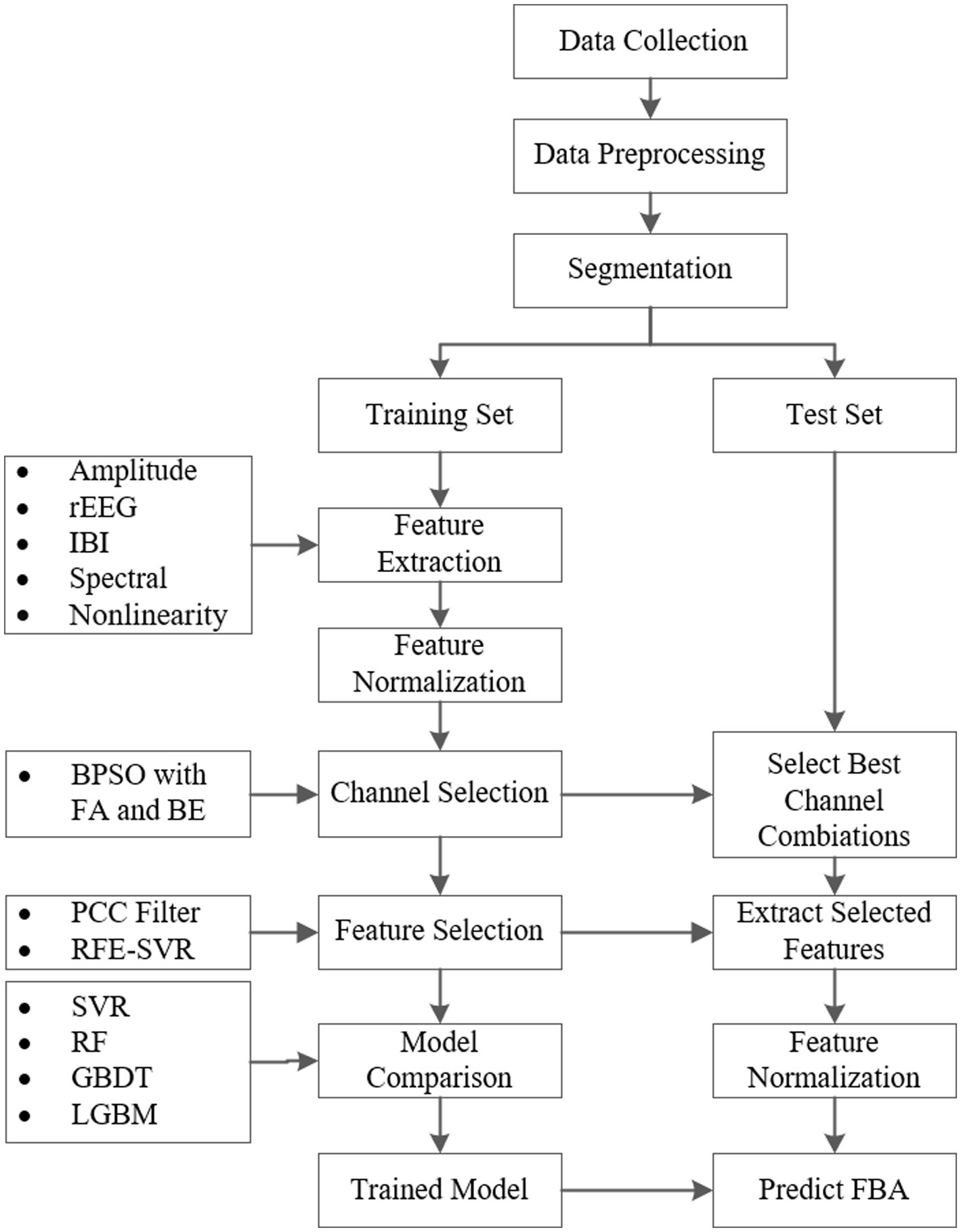
Figure 1. The implementation process of the proposed framework for the FBA prediction of preterm infants based on EEG.
2.1 Data description and preprocessingFrom January 1, 2021, to December 31, 2022, we collected EEG signals of preterm infants treated in the neonatal intensive care unit of the First Hospital of Jilin University, Norman Bethune. Electrodes were placed according to the internationally modified neonatal 10–20 electrode placement system, with Cz as the reference electrode, and EEG signals were recorded using the Nicolet One EEG machine (Natus Medical Inc., Pleasanton, CA, United States) with 12 electrodes (Fp1, Fp2, T3, T4, C3, C4, P3, P4, O1, O2, Cz, and Pz). The specific placement of the electrodes is illustrated in Figure 2A. Each preterm infant was recorded only once, the sampling frequency was set at 500 Hz, with a duration ranging from 5 to 6 h. After the EEG signals were recorded, all identifiable information of the preterm infants was anonymized to ensure privacy, and a randomly generated unique identifier was assigned to each infant.

Figure 2. Overview of electrode placement and PMA distribution in the dataset. (A) Specific placement of electrodes. (B) Histogram of the PMA in the collected dataset.
To ensure the accuracy and reliability of the data, we invited three expert doctors from Jilin University to interpret the EEG data. Based on the consensus reading of these experts, we select preterm infants with normal neurodevelopment as subjects for further study. Ultimately, we obtain EEG data from 92 preterm infants with normal brain development. Normal brain development means that the predicted FBA is consistent with the PMA, which is the actual FBA.
The dataset includes 53 male and 39 female preterm infants. The median birth weight is 1,650 g, ranging from 930 to 2,670 grams. The Apgar scores at 1 and 5 min have median values of 7 (5–9) and 8 (5–10), respectively. The median gestational age at birth is 32.04 weeks, with a range from 26.71 to 36.56 weeks. The median PMA is 34 weeks, with a range spanning from 28 to 40 weeks, as shown in Figure 2B, which displays a histogram illustrating the weekly distribution of infants within this range.
This study employs a bipolar reference method, specifically double banana longitudinal leads and symmetric bipolar references, resulting in a total of 16 bipolar channels. The names and corresponding IDs of these channels are detailed in Table 1. To reduce data complexity while preserving key information, the original EEG signals are first filtered using a 50 Hz notch filter to eliminate power line noise that may be introduced by the environment, and then resampled to 64 Hz. A fifth-order Butterworth filter is applied within the range of 0.5–30 Hz to remove unrelated frequency components. Subsequently, an artifact subspace reconstruction algorithm is employed to remove artifacts for further improving data quality (Chang et al., 2020). After these preprocessing steps, the artifact-free data are segmented into nonoverlapping one-hour segments for further analysis, resulting in a total of 485 one-hour EEG recordings.
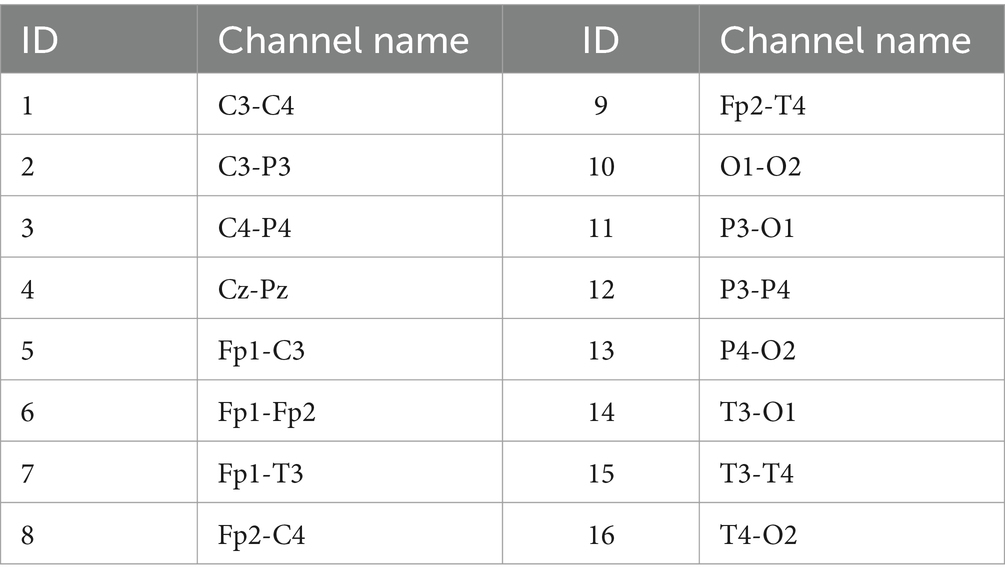
Table 1. IDs and channel names for bipolar reference (ID is convenient for identifying the combination of channel selections below).
To ensure our model’s generalizability and reliability, we divide the data into training and testing sets within each age group in a 7:3 ratio. Importantly, this division is performed based on the unique identifiers assigned to the preterm infants after anonymization, ensuring that EEG data from the same infant does not simultaneously appear in both the training and testing sets. This approach prevents data leakage and maintains the independence of the test set while ensuring a balanced distribution between the two sets.
2.2 Feature extractionTo comprehensively capture the information contained in the EEGs of preterm infants, we reference the feature set proposed by Toole and Boylan (2017), where the features are extracted in the amplitude domain, rEEG domain, IBI domain, frequency domain, and nonlinear domain to obtain multidimensional EEG characteristics. In this study, each one-hour single-channel EEG signal is first divided into 119 epochs, using a sliding rectangular window of 60 s with a 50% overlap. Then each epoch is filtered into delta, theta, alpha, and beta frequency bands, respectively, by a fifth-order Butterworth filter, and specific features are then extracted from each frequency band. The average of the features from all epochs within the same frequency band is taken as the feature value for the corresponding frequency band and channel. Fractal dimension features are extracted at all frequencies. Unlike the feature set proposed by O'Toole et al. (2016), which is simplified by taking the median of features across all channels, this paper retains the features from all channels for subsequent channel selection.
2.2.1 Amplitude domain featuresIn the amplitude domain, amplitude is quantified by signal power and mean envelope. Let yn be the sample signal of the EEG signal of a channel, which is filtered into four frequency bands yin , i=1,2,3,4 , corresponding to the delta, theta, alpha, and beta frequency bands, respectively, by a fifth-order Butterworth filter. The signal power Aipower of the ith frequency band is defined as the average of the squared modulus of the signal over the number of sampling points N.
The envelope ein of the ith frequency band is defined as using the modulus of the signal combined with the Hilbert transform, specifically ein=|yin+jHyin| where H· represents the discrete Hilbert transform. The mean envelope Eimean is defined as the average of the envelope values over N sampling points. Additionally, the standard deviation, skewness, and kurtosis of yin as well as the mean and standard deviation of the envelope ein are extracted in this paper.
2.2.2 rEEG domain featuresThe rEEG feature estimates a peak-to-peak measure of voltage by calculating the difference between the maximum and minimum values for adjacent intervals from the EEG signal, characterizing signal variability over time (O'Reilly et al., 2012). In this study, each epoch is segmented into 2 s with a 50% overlap. The peak-to-peak ranges are computed from all segments, and then feature metrics such as the mean, median, 5th and 95th percentiles (lower margin and upper margin), width (upper margin-lower margin), standard deviation (SD), coefficient of variation (CV), and measure of symmetry are derived from these ranges.
2.2.3 IBI domain featuresThe IBI is a critical feature used to quantify the discontinuous bursting patterns observed in preterm infant EEGs. The IBI is defined as the interval between consecutive bursts of activity, with bursts identified using the burst-detection algorithm proposed by O'Toole et al. (2017). This method detects bursts by analyzing the amplitude of EEG signals, where high-amplitude activity is classified as a burst, and low-amplitude periods are classified as inter-burst intervals (Toole and Boylan, 2017).
To characterize the inter-burst pattern, several IBI-related features are extracted for each EEG channel, including the mean and median durations to reflect typical quiescent periods, the standard deviation and coefficient of variation to measure variability, and the burst ratio to capture the balance between bursts and quiescent periods.
2.2.4 Spectral domain featuresIn the spectral domain, we first apply the Welch periodogram with a hamming window (2 s length, 50% overlap) to estimate the power spectral density (PSD) of the preprocessed EEG signals. Then we extract frequency domain features, including power in each frequency band obtained by short-time Fourier transform, relative power, Wiener entropy, Shannon entropy, differences between consecutive short-time spectral estimates, and spectral edge frequency (the cut-off frequency at which 95% of the spectral power is encompassed). The power in the spectral domain represents the integral of the PSD over the defined band’s frequency range, and relative power is the ratio of the power in a specific frequency band to the total power across all frequencies.
2.2.5 Nonlinear featuresFor the brain’s complex and nonlinear nature, analyzing EEG signals from a nonlinear dynamics perspective may yield significant features that cannot be obtained by time domain and frequency domain analyses. The fractal dimension (FD) features, such as Petrosian, Katz, and Higuchi FD, are the nonlinear features (Esteller et al., 2001). In this paper, we apply the Higuchi method to extract the FD feature for each EEG channel, with the maximum interval between points in the time series of 6.
Table 2 summarizes the domains and specific names of features extracted from each channel, as well as the number of features extracted from each domain, where FB indicates whether the feature is extracted from each frequency band. In total, 86 features are extracted from all domains for each channel.

Table 2. The extracted features from EEG data (FB indicates whether the feature is extracted from each frequency band).
2.3 Feature normalizationThe features extracted from different domains have various scales. To reduce the impact of these various scales on the machine learning model, we apply Z-score normalization to transform all feature data to follow a standard normal distribution. The normalization formula for a feature z is Equation 1.
where μ is the mean and σ is the standard deviation of the feature z. To ensure consistency and reliability, the ? and ? used for Z-score normalization of the test data are derived exclusively from the training data. To preserve the independence of each EEG channel and maintain the validity of subsequent channel selection, Z-score normalization is performed independently for each channel. This approach avoids inter-channel influence and ensures the integrity of the normalization process.
2.4 Evaluation metricsClinically, the allowable prediction error between the predicted FBA and the actual FBA (for normal preterm infants, the actual FBA is consistent with PMA) is defined as ±2 weeks for preterm infants (André et al., 2010). To evaluate the performance of the machine learning models in assessing the functional age of preterm infants, we use the MAE metric, which measures the average prediction error in weeks, providing a clear indication of how close the model’s FBA predictions are to the actual values. A smaller MAE indicates a better model performance. The MAE is defined as Equation 2.
MAE=1K∑k=1K|Yk−Ŷk| (2)where K is the number of samples, Yk is the actual FBA of sample k, and Ŷk is the predicted FBA of sample k .
2.5 Channel selectionIn the field of machine learning, it is a well-known fact that increasing the amount of data does not always correspond to an increase in effective information. This is particularly evident in the analysis of EEG data. Excessive channels may introduce more noise and redundancy, which may result in potentially degrading model performance and reducing its generalizability. Thus, channel selection becomes crucial for increasing the performance of the regression model. Its primary purpose is to identify and extract the most task-relevant channels, thereby reducing feature extraction time, lowering computational costs, avoiding data redundancy and enhancing model generalizability. This process not only helps improve model performance but also makes clinical testing more portable and operationally convenient (Alotaiby et al., 2015).
To effectively perform channel selection, we propose a novel approach by combining a multi-objective optimization algorithm with greedy algorithms, in which we use BPSO along with FA and BE methods to identify the optimal channels. The proposed method is based on SVR as the regression model, with the MAE as the performance evaluation metric. To ensure the accuracy and reliability of the evaluation, we employ 5-fold cross-validation on the training set.
BPSO is a multi-objective optimization method inspired by the social behavior of bird flocks, particularly in their collective search for food. BPSO is particularly suited for addressing discrete binary decision problems such as EEG channel selection (Lee et al., 2008). However, BPSO method may converge prematurely to local optima, particularly in complex search spaces, while it is finding a good initial solution effectively.
FA is a greedy algorithm used for channel selection and dimensionality reduction in EEG data analysis. It begins with an empty set and progressively adds channels, selecting the channel that maximizes a predetermined performance metric at each step, until a specified number of channels is reached or further additions no longer enhance the overall system performance. However, the FA method may be trapped in local optima and might not find the best global solution due to its myopic nature.
BE, similar to FA, is a greedy algorithm but it starts with the full set of channels. It progressively removes the least impactful channels based on a predetermined performance metric in each iteration, until the desired number of channels is maintained or further removals would significantly degrade the performance. Like FA, the BE method can also be limited by local optima and may not effectively explore the solution space to find the best global solution for channel selection.
BPSO method can quickly converge to the global optimal channel combination by exploring a wide search space, while FA and BE methods can optimize the performance metric further by adding or removing redundant channels. We combine BPSO with FA and BE methods to select optimal channels, which fully utilizes the global search capability of BPSO method and the fine-tuning precision of greedy algorithms. This combined approach provides several advantages, such as enhancing search capability through robust global and precise local search mechanisms, improving overall performance by ensuring both broad exploration and fine exploitation of the solution space, reducing redundancy, leading to lower computational costs and enhancing model efficiency. To ensure the independence of channel selection, feature selection is not applied during this process. Instead, the features from multiple channels are concatenated and directly fitted into the SVR model. The procedure of the proposed channel selection method by combining BPSO with FA and BE methods is described in detail in Algorithm 1.
ALGORITHM 1 The proposed channel selection method by combining BPSO with FA and BE algorithm
Additionally, we also utilize two other multi-objective optimization algorithms in place of BPSO to observe the final effects, namely genetic algorithm (GA) and simulated annealing (SA). GA is an optimization technique based on the principles of natural selection, which simulates the process of biological evolution through operations such as selection, crossover, and mutation, thereby iteratively improving the solution (Moctezuma and Molinas, 2020). SA, on the other hand, is a probabilistic optimization method that mimics the physical process of annealing. It explores the solution space in a high-energy state and accepts increases in cost randomly during the cooling process to avoid local optima, progressively refining toward the global optimum as the “temperature” gradually decreases (Jayakumar and Raju, 2010).
2.6 Feature selectionIn the traditional machine learning models, all features are often considered equally important, which may lead to redundancy and reduce the generalization capability of the regression model. We employ a feature selection process by combining a PCC and RFE with an SVR model. This approach focuses on the correlations between features, effectively reducing redundancy and enhancing the model’s effectiveness.
The first step of the feature selection method used in this paper is to analyze the correlation between features using the PCC. The PCC is defined as Equation 3:
PCC=∑i=1KFi−F¯Zi−Z¯∑i=1KFi−F¯2∑i=1KZi−Z¯2 (3)where Fi and Zi are the ith feature of the two kinds of different features respectively, F¯and Z¯ are their respective means, and K is the number of samples. We compute the absolute PCC values for all feature pairs to identify the degree of linear relationship between them. Feature pairs with a high absolute PCC value (greater than 0.9) are considered highly correlated, indicating redundancy. In such cases, one kind of feature from each highly correlated pair is filtered out to ensure that only the most informative and nonredundant features are retained for further analysis.
Following the PCC filtering, we apply RFE and a SVR model as the estimator to select the significant features, which is named PCC-RFE-SVR. The RFE process involves iteratively fitting the model and removing the least important features based on the model’s coefficients until the optimal subset of features is identified. The process of the PCC-RFE-SVR method for feature selection is conducted as follows:
Step 1. Filtering: Use the PCC to filter out redundant features.
Step 2. Initialization: Begin with the set of features obtained after PCC filtering.
Step 3. Model Fitting: Fit the SVR model to the training data using the current set of features.
Step 4. Feature Ranking: Rank the remaining features based on their importance weights derived from the SVR model’s coefficients.
Step 5. Feature Elimination: Remove the least important feature based on the ranking.
Step 6. Iteration: Repeat steps 3 to 5 until the desired number of features is reached.
To determine the optimal features, we employ 5-fold cross-validation on the training set and evaluate the model’s performance using the MAE. This process helps in identifying the most relevant features while minimizing the risk of overfitting.
2.7 Regression modelsTo evaluate the performance of channel and feature selection, we initially employ SVR as the evaluation model. The SVR model is chosen due to its strong generalization ability and effectiveness in handling high-dimensional data, which aligns well with the nature of our dataset. Preliminary experiments also demonstrate that SVR performed well in this condition, justifying its use in the selection processes.
However, to further validate the effectiveness of the selected channels and features and to compare the overall performance of different regression models, we introduce three additional models: RF for its robustness to overfitting, GBDT for its flexibility in capturing nonlinear relationships, and LGBM for its computational efficiency and scalability. By comparing these models under the same channel and feature selection settings, we aim to comprehensively assess the relative effectiveness of each model.
3 Results 3.1 EquipmentThis study is conducted on a Windows operating system, uses Python 3.9, and primarily utilizes the Scikit-learn and MNE libraries for data analysis and processing. All experiments are performed on a computer equipped with an Intel (R) Core (TM) i7-7700K CPU to ensure the smooth progress and reliability of the results.
3.2 Results of channel selectionInitially, an SVR model is used to train on the features extracted from each individual channel, and its performance is evaluated using the MAE of the predicted FBA in preterm infants. Subsequently, by integrating various optimization methods such as FA, BE, BPSO, SA, and GA with the SVR model, we identify the optimal channel combinations under different numbers of channels, and use the MAE to assess and compare the performance of these combinations. The parameters for the SVR model and the methods for channel selection used in the experiments are detailed in Table 3. The SVR model is optimized using grid search, where “np.arange” is a function from the NumPy library used to generate sequences of numbers. For example, np.arange (0.01, 1.1, 0.1) generates a sequence of the C_values starting at 0.01, ending before 1.1, with increments of 0.1. For the SA method, the parameters include the initial temperature (T), cooling rate (α), and number of iterations (L). For the GA method, the parameters include the population size (PS), number of generations (NG), mutation rate (MR), crossover rate (CR), and selection method (SM).

Table 3. Parameters required for channel selection methods.
3.2.1 Performance of single channelWe train the SVR model on each of the 16 channels individually and optimize the model using grid search. The comparison of the MAE of different single channel is shown in Figure 3A. A smaller MAE indicates better regression model performance. In this study, the MAE represents the average prediction error of the FBAs of preterm infants in weeks. The results show that the Fp1-Fp2 channel achieves the best performance, with an MAE of 0.76 in 5-fold cross-validation. Conversely, the Cz-Pz channel has the poorest performance. Figure 3A clearly illustrates the significant differences in performance across different single-channel and shows that different channels have varying impacts on the final prediction results.
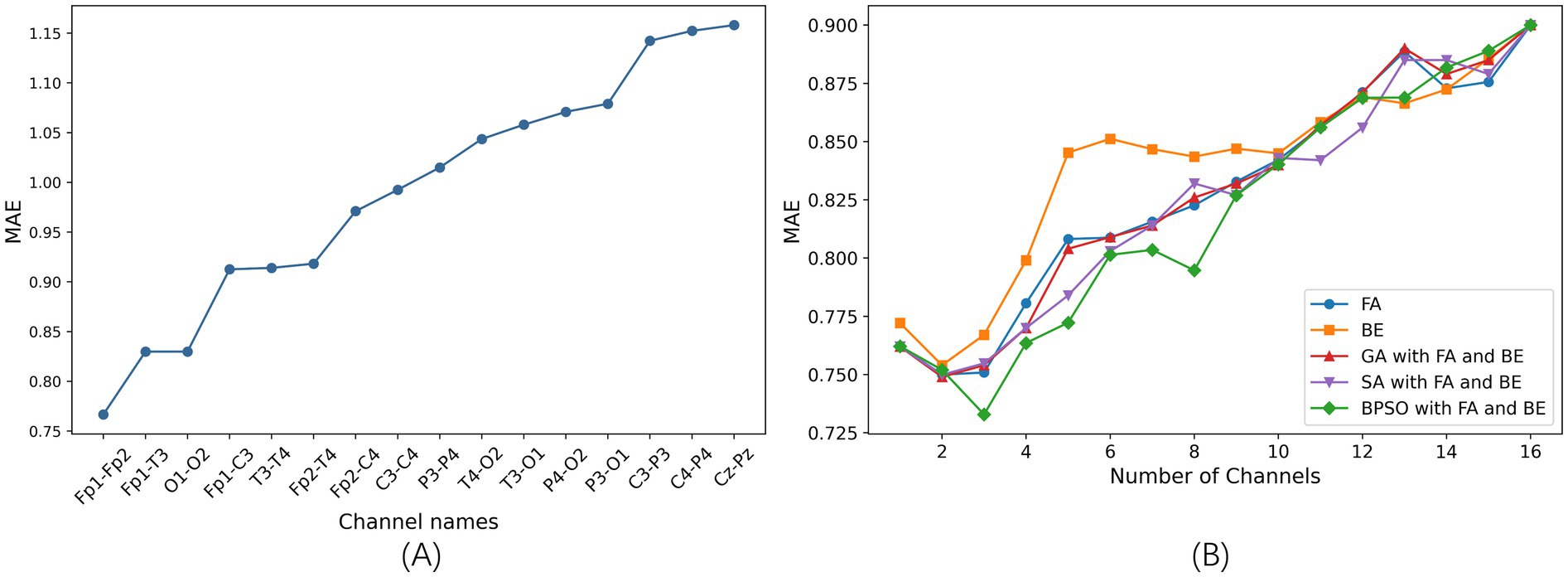
Figure 3. The results of channel selection based on 5-fold cross-validation on the training set. (A) Comparison of the MAE of different single channel based on SVR model (sorted in ascending order). (B) Comparison of the MAE between five channel selection methods based on the SVR model.
3.2.2 Comparison of optimal channel selection methodsAfter determining the optimal single channel using the SVR model, next step is to find the best combinations of 2–15 channels. We employ proposed BPSO combined with FA and BE methods for channel selection, which is compared with other four channel selection methods: FA, BE, GA combined with FA and BE, and SA combined with FA and BE.
The comparison of the MAE is illustrated in Figure 3B. This figure shows the optimal results for different channel selection methods, with the x-axis representing the number of optimal channel combinations and the y-axis representing the MAE of the FBAs of these combinations in preterm infants. Notably, the MAE is lower when reducing the number of channels compared to using all channels (16 channels), indicating superior performance of channel selection methods. This demonstrates that effective channel selection can significantly improve prediction accuracy, as not all channels contribute positively to the accuracy of the model’s predictions.
Specifically, the BPSO with FA and BE method is notably effective in identifying optimal subsets of channels, achieving the lowest MAE of 0.73 with a three-channel combination. This highlights the critical importance of channel selection in enhancing the efficiency and performance of the model.
Using the proposed channel selection method, the top six channel combinations with the minimum MAEs are shown in Table 4. Table 4 indicates that the optimal performance is achieved using a three-channel combination (Fp1-Fp2, Fp1-T3, Fp2-T4), concentrated in the frontal and temporal lobes. Remarkably, the performance of the single-channel Fp1-Fp2 is also well with the MAE increasing by only 0.03 compared to the best three-channel combination, that is consistent with the result shown in Figure 3A. The specific electrode positions of the top six channel combinations with the minimum MAEs are detailed in Figure 4, where the red lines indicate bipolar references between the two electrodes.
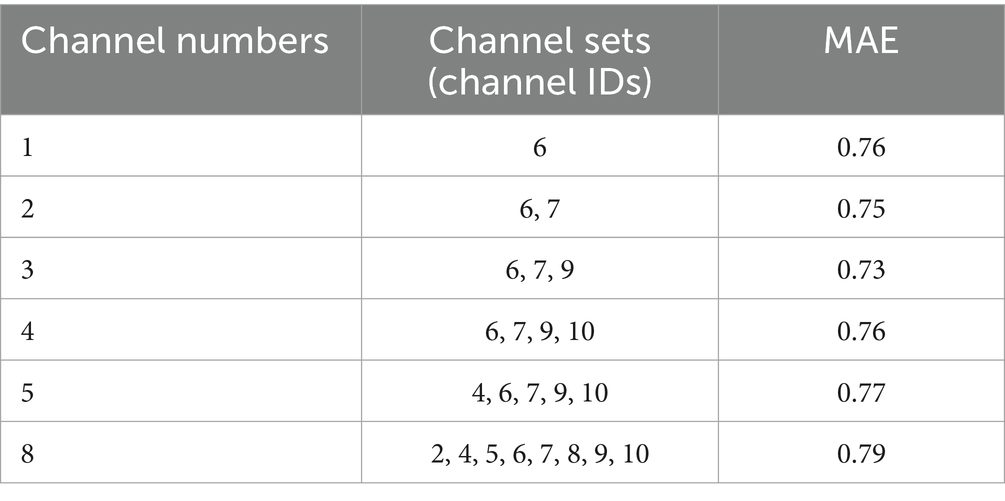
Table 4. Top six channel combinations with the minimum MAEs.
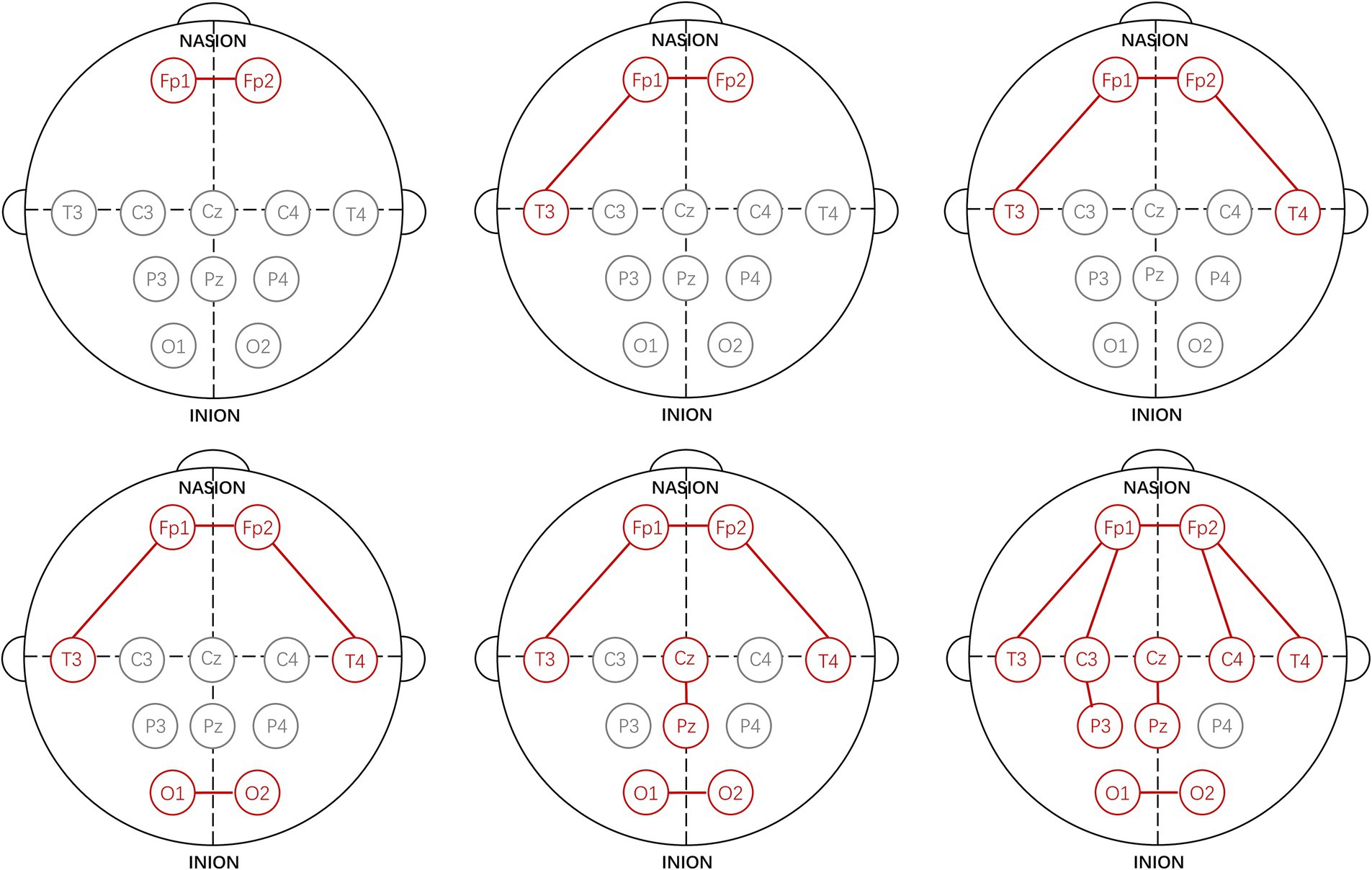
Figure 4. Specific electrode positions of the top six channel combinations with the minimum MAEs.
3.3 Results of feature selectionAfter obtaining the optimal three-channel combination by the proposed channel selection method, we use 86 features from each selected channel, resulting in a feature set with 258 features. In the feature selection phase, we employ the PCC-RFE-SVR method to identify the most appropriate features. Firstly, we remove 147 highly correlated features by the PCC filtering with a threshold of 0.9, so we obtain a feature set with 111 features. This step ensures the removal of redundant features that could negatively impact the model’s performance due to multicollinearity. Then, we apply RFE with the SVR model to further select the significant features. For comparison, we also apply two additional methods: PCC-SVR and RFE-SVR. The PCC-SVR method directly applies SVR after PCC filtering, without further feature refinement, while the RFE-SVR method skips the initial PCC filtering and directly applies RFE with SVR to the entire set of 258 features.
The results of three feature selection methods are shown in Figure 5. As shown, initially, the MAEs of the three methods decrease as the number of features increases. As the number of features further increases, the MAEs of the PCC-SVR and REF-SVR methods change slowly without a clear minimum value, although the MAEs of the REF-SVR method are lower. However, the PCC-RFE-SVR method reaches its minimum value around 26 features. This optimal point represents the feature set where the model achieves the best performance with the lowest MAE, approximately 0.61. Beyond this point, adding more features leads to an increase in MAE, indicating that additional features can introduce noise and redundancy, thereby reducing the model’s performance.
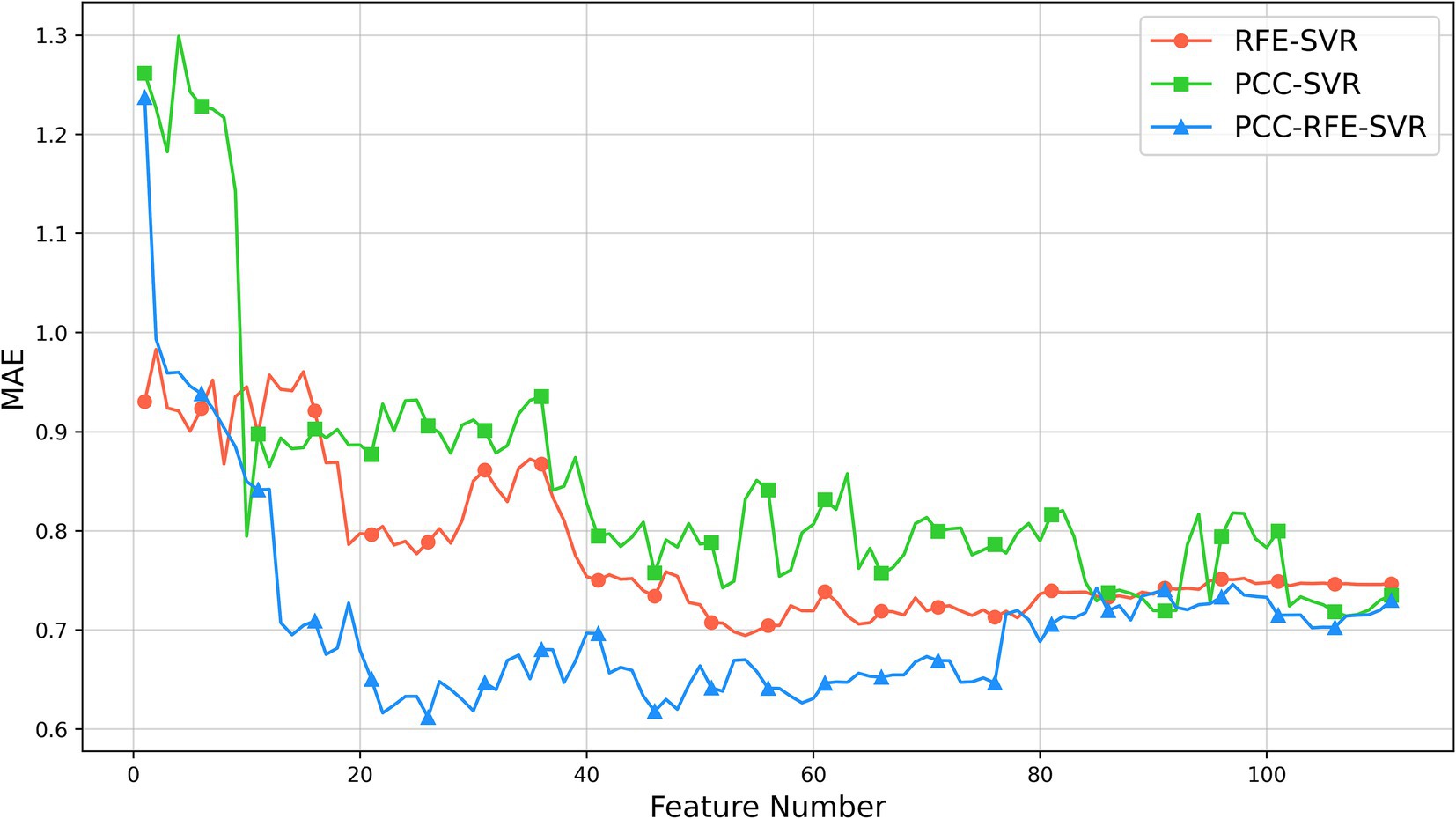
Figure 5. Results of feature selection based on 5-fold cross-validation on the training set.
Table 5 lists the selected features and R2 values, sorted in descending order, where R2 is the coefficient of determination, which is the square of the PCC. R2 is always used to assess the performance of the feature selection method with larger value implying stronger positive correlation. The highest-ranked feature is “Lower margin” from the rEEG domain, located in the Fp2-T4 channel with theta frequency band (4–7 Hz). It has an R2 value of 0.34, indicating a strong positive correlation with the FBA and making it the most significant contributor to improve the model’s performance.
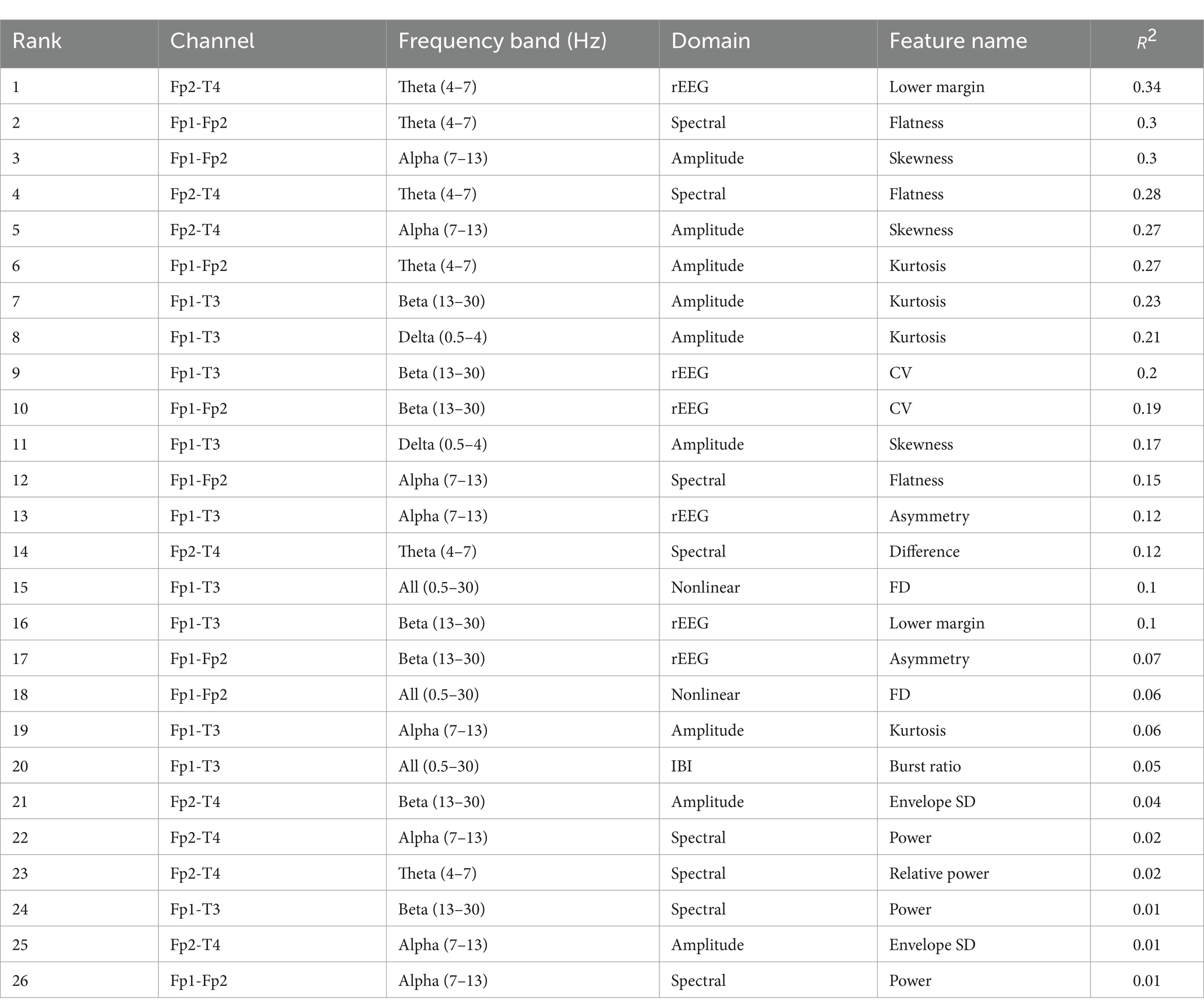
Table 5. R2 values of the 26 features selected by the PCC-RFE-SVR method.
3.4 Performance of different regression modelsThe SVR model is chosen for its advantages in handling high-dimensional data and its strong generalization ability. To further assess the performance of SVR, we compare it with other regression models, including RF, GBDT, and LGBM. Consistency is ensured by using the same regression model for both channel selection and feature selection evaluation, with a 5-fold cross-validation on the training set.
As presented in Table 6, SVR consistently achieves the smallest MAE across all scenarios, regardless of the specific channel and feature selection methods or input configurations. This highlights SVR’s clear advantage in predicting FBA compared to RF, GBDT, and LGBM.
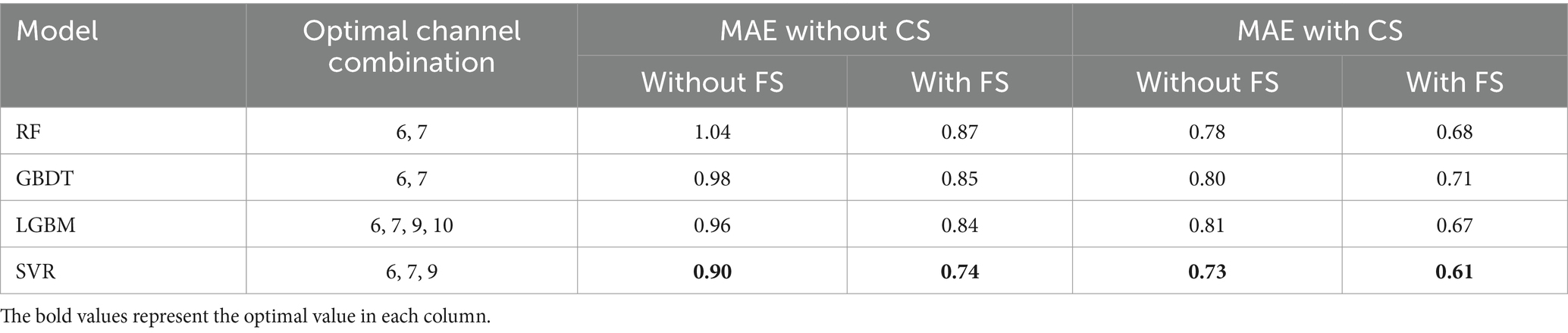
Table 6. Performance comparison of different models with channel and feature selection based on 5-fold cross-validation on the training set (CS, channel selection; FS, feature selection).
3.5 Performance comparison of channel selection and feature selectionIn this study, we assess the proposed framework based on SVR using a feature set generated by concatenating features from different channels. For comparison, two additional cross-channel feature processing techniques, median and mean, are implemented. We evaluate these three methods median, mean and concatenation of processing cross-channel features using SVR, incorporating both channel and feature selection strategies, and apply 5-fold cross-validation on the training set to determine the optimal model, which is subsequently tested on the test set. The results, as shown in Table 7, highlight the outcomes across all experiments.
留言 (0)