
記住我
The Arenaviridae family is formed by the genera Mammarenavirus, Reptarenavirus, Hartmanivirus, Antennavirus and Innmovirus (Radoshitzky et al., 2023). The mammarenaviruses, as the name suggests, infect mammals, mostly rodents, and their geographical distribution is related to their natural reservoirs (Salazar-Bravo et al., 2002; Gonzalez et al., 2007). The genus has been divided into two groups based on its place of origin: Old World (OW) and New World (NW) mammarenaviruses. The former are mainly found in Africa, while the latter are native to the Americas. Some members of the Mammarenavirus genus can infect humans and cause hemorrhagic fever. Examples are the OW viruses Lassa (LASV) and Lujo (LUJV) in West and South Africa (Emonet et al., 2006) and the NW viruses Junin (JUNV), Machupo (MACV), Chapare (CHPV), Guaranito (GTOV) and Sabia (SABV) in South America (Sarute and Ross, 2017). The genera Reptarenavirus and Hartmanivirus have been found in snakes (Hepojoki et al., 2015b), and some members of the genus Reptarenavirus cause Boid Inclusion Body Disease (BIBD) in captive snakes (Stenglein et al., 2012; Hetzel et al., 2013). Antennaviruses, for their part, infect striated frogfish and salmon (Shi et al., 2018; Mordecai et al., 2019), while Innmovirus is the only genus whose natural reservoir is still unknown (Chen et al., 2022; Chen et al., 2023).
Arenaviruses are single-stranded ambisense RNA viruses with some differences between the genera. Mammarenaviruses and reptarenaviruses have a bisegmented RNA with an ambisense coding strategy for 4 proteins: GPC and NP are coded in the S segment and L and Z in the L segment. Hartmaniviruses have a bisegmented RNA with an ambisense S segment coding for the GPC and NP proteins and a negative-sense RNA L segment coding for the L protein, but they have no homolog for the Z protein of mammarenavirus and reptarenavirus. Antennaviruses have genomes consisting of three genomic segments, a negative-sense S segment that encodes NP, an ambisense segment that encodes GPC and an unknown protein, and a negative-sense L segment that encodes the L protein but also has no homologous Z protein. Finally, Innmovirus has three negative-sense RNA segments, the S segment that encodes NP, the intermediate segment that encodes GPC and an unknown protein, and the L segment that encodes the L protein (Hepojoki et al., 2015b; Shi et al., 2018; Chen et al., 2022; Radoshitzky et al., 2023).
The genetic code consists of 64 codons, 61 of which code for amino acids and 3 for stop signals during protein synthesis. Since there are only 20 common amino acids, the genetic code is degenerate, i.e., several codons – synonymous codons – are translated into the same amino acids, with the exception of methionine and tryptophan. However, not all synonymous codons are used with the same frequency, with some organisms favoring some codons over others. This unequal use of codons is referred to as codon usage bias or pattern (Ikemura, 1981; Plotkin and Kudla, 2011; Chaney and Clark, 2015). Codon usage bias is a critical measure of genome evolution and has been found in most organisms, from prokaryotes to eukaryotes and viruses (Sharp and Li, 1987; Plotkin and Kudla, 2011; Belalov and Lukashev, 2013; Chaney and Clark, 2015). Several factors have been found to influence biased codon selection, including gene expression levels, translation, base mutations, genetic drift, transcription factors and the external environment (Bulmer, 1991; Butt et al., 2016; Velazquez-Salinas et al., 2016), with natural selection and mutational pressure in combination with genetic drift being the most important factors (Belalov and Lukashev, 2013).
In viral genomes, codon usage is a driving force for their evolution (Dutta et al., 2020). Some researchers suggest that mutational biases are the primary determinant of codon usage patterns in human RNA viruses (Jenkins and Holmes, 2003; Nasrullah et al., 2015; van Hemert et al., 2016; Tort et al., 2020), while others have identified the dominant influence of natural selection (Wang et al., 2016; Baha et al., 2019; Khandia et al., 2019; Luo et al., 2020). As parasitic organisms, viruses have some features in their genomes that differ from those of prokaryotes and eukaryotes, e.g., they rely on the translational machinery of their hosts for gene expression. This interaction between virus and host influences overall viral survival, adaptation, evasion of the host immune response and evolution (Nasrullah et al., 2015; Rahman et al., 2018; Nguyen et al., 2021).
Relevant human RNA viruses that have already been analyzed for codon usage bias include orthomyxoviruses (Luo et al., 2019), flaviviruses (Jenkins et al., 2001), lyssaviruses (Zhang et al., 2018), bornaviruses (He et al., 2014), polioviruses (Zhang et al., 2011), retroviruses (RoyChoudhury and Mukherjee, 2013) and coronaviruses (Mogro et al., 2022), among others. In contrast, research on arenaviruses is limited to one study on codon adaptation index (CAI) (Sharp and Li, 1987) for OW LASV and LCMV (Pontremoli et al., 2017) and one study on codon usage bias in NW CHPV and SABV (Malhotra and Kumar, 2021).
In this study, we performed an analysis of codon usage bias in the Arenaviridae family, focusing on the three proteins that are common to all members. We used different indices such as Effective Number Codons (ENC) (Wright, 1990), Relative Synonymous Codon Usage (RSCU) and CAI to draw general conclusions that could improve the understanding of the evolutionary pressures controlling the evolution of arenaviruses and their adaptability to different hosts and environments.
Materials and methods Genomic sequencesAll available arenaviruses with complete coding sequences of the three proteins that are common to all members (GPC, NP, and L proteins) were collected and downloaded from the nucleotide database of the National Center for Biotechnology (NCBI, GenBank) using the reference species listed in the ICTV report for the Arenaviridae family (Radoshitzky et al., 2023). The list of virus names, abbreviations, accession numbers and host information can be found in Supplementary Tables 1, 2.
Human coding sequences for constitutive genes that are highly expressed in all tissues were obtained from the Human Protein Atlas. For this purpose, a table of all proteins constitutively expressed in all human tissues was downloaded, the 500 most highly expressed proteins were selected, and their coding sequences were obtained from the protein-coding transcripts of the human genome v.38 using custom Python scripts. For further comparative analysis with lowly expressed constitutive genes in all human tissues, a table of median transcripts per million (TPM) in all tissues (2017/06/05, v8 RNASeqCv1.1.9) was downloaded from GTEx Portal. From this table, Ensembl IDs were extracted where the TPM was non-zero in all tissues, the maximum value did not deviate significantly from the group variance, and the lowest medians were identified. Protein-coding transcripts for the 500 least-expressed human proteins were then obtained from Ensembl release 112 (Harrison et al., 2024) using additional custom Python scripts.
Host coding sequences were obtained from the NCBI nucleotide database for the snake family Boidae (txid: 8572) and the rodent families Muridae (txid: 10066) and Cricetidae (txid: 337677). Due to the lack of coding sequences for Antennariidae (txid: 241819) and the fact that two of the four antennaviruses were found in sockeye and chinook salmon (Oncorhynchus nerka and Oncorhynchus tshawytscha, respectively), the coding sequences for the family Salmonidae (txid: 8015) were chosen instead.
Phylogenetic analysisThe coding sequences for the L and NP proteins of all selected arenaviruses were aligned and concatenated using MAFFT v7 software (Katoh et al., 2019) with default settings. The resulting multiple sequence alignment was used to generate a maximum likelihood phylogenetic tree using IqTree (Trifinopoulos et al., 2016). Default settings were used, and the best fitting model was LG + F + I + G4.
Analysis of synonymous codon usageThe guanidine-cytosine (GC) composition for all viral coding sequences was calculated using the online software CAIcal (Puigbo et al., 2008). This software was also used to analyze the nucleotide composition of the viral sequences and for RSCU and CAI calculations as well as for GC in the third codon position (GC3). ENC was calculated with R scripts using coRdon R software (Elek et al., 2018). Correspondence analysis was performed with the R package FactoMineR (Husson et al., 2008) using the previously calculated RSCU values and presented with the R package factoextra (Kassambara and Mundt, 2020). The R scripts were processed with the software RStudio build 369 23.12.0 (RStudioTeam, 2020).
Statistical analysisMost of the results were presented as a violin plot with jitter points (min-max, the horizontal upper, lower bottom and middle lines indicate the 75th percentile or upper quartile, the median and the 25th percentile or lower quartile). The Shapiro–Wilk normality test was applied to the data to decide whether a parametric ordinary one-way analysis of variance (ANOVA) or a non-parametric one-way analysis of variance (ANOVA) (Kruskal–Wallis) should be performed. The results are then followed by either the Tukey, Dunn or Mann–Whitney multiple comparison test to determine significant differences between the groups for parametric or non-parametric analyses. In all cases, p values of less than 0.05 were considered statistically significant. Almost all statistical analyses were performed using Prism 8 software. Statistical analysis of the RSCU was performed using custom Python scripts.
Results Phylogenetic analysisWe constructed a phylogenetic tree of the Arenaviridae family using maximum likelihood and concatenated amino acid sequence alignments of the NP and L proteins of members with fully sequenced genomes. The results showed a tree that has a similar topology to the tree hosted at ICTV using only L (Radoshitzky et al., 2019), although it has some differences, particularly with respect to the phylogenetic distance of the NW mammarenaviruses and reptarenaviruses and the inclusion of newly sequenced genomes (Supplementary Figure S1).
Compositional analysisThe GC% content of GPC, NP and L genes was below 50 for all arenaviruses, with the lowest values for Hartmanivirus at 30/35% and the highest for Antennavirus at 45/50% (Figure 1A). These values are lower than those of the coding sequences of known hosts, namely 52.3% for Homo sapiens, 51.8% for Mus musculus and Rattus norvegicus (Zhang et al., 2004). For snakes and salmonids, only the genomic GC content could be analyzed, which is 42% for Charina bottae (Grismer et al., 2022) and 43.5% for O. nerka (Christensen et al., 2020). These values are similar to the 42% of R. norvegicus and M. musculus and the 41% of H. sapiens. A similar trend can be observed for the GC composition at the third codon position, but with higher overall values, ranging from 30 to almost 60%, depending on the gene and species analyzed (Figure 1B).
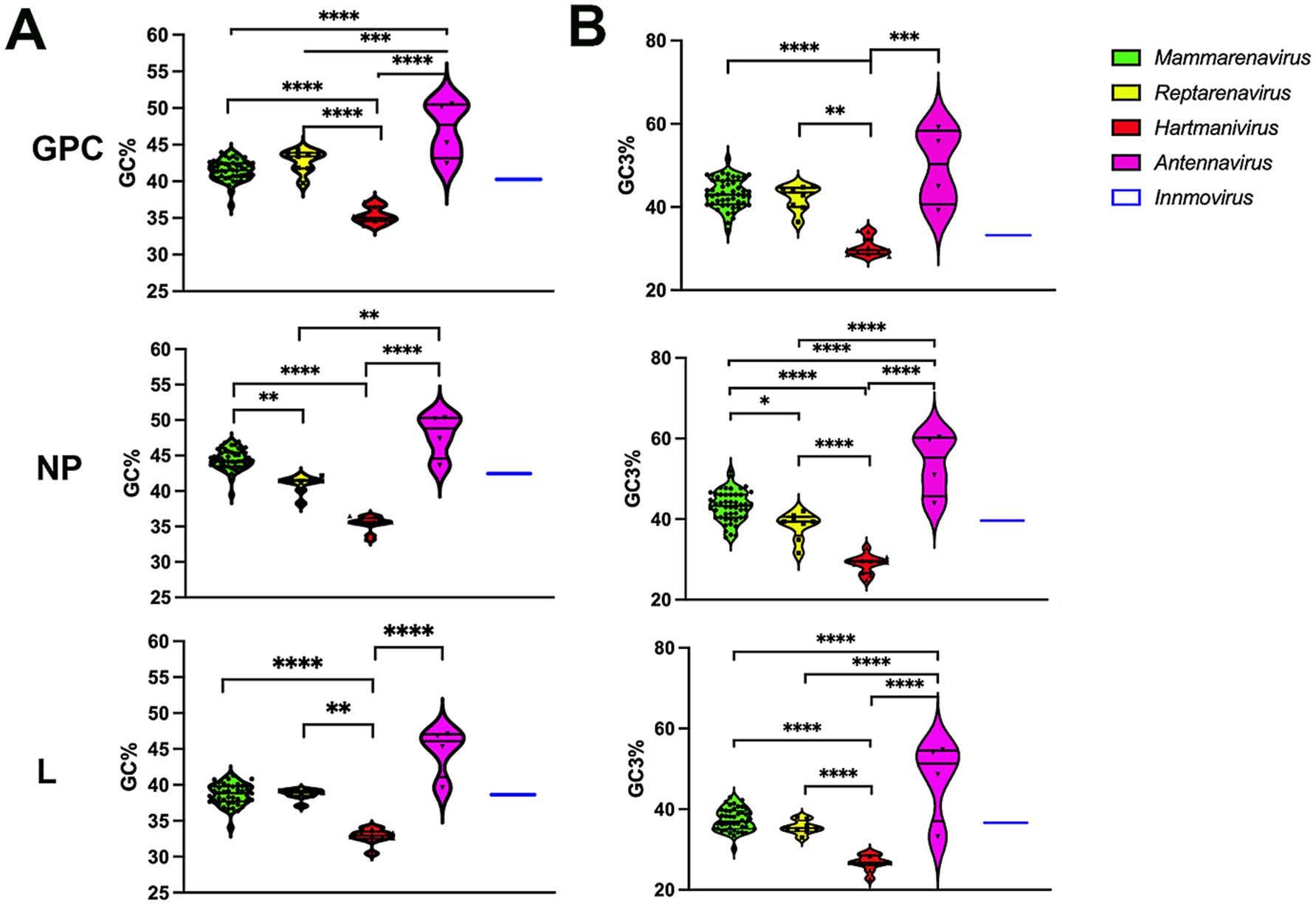
Figure 1. (A) Analysis of the guanine-cytosine composition of arenavirus genera for GPC, NP and L protein sequences. A violin plot shows the GC percentage for the coding sequences of the GPC, NP and L genes of each Arenavirus genus. The middle horizontal line represents the median GC proportion within the genus while top and bottom horizontal lines represent upper and lower quartile, respectively. p values were calculated using either Tukey’s test (GPC) or Dunn’s test (L and NP) for multiple comparisons based on the normality distribution of the data (p* < 0.05, p** < 0.01, p*** < 0.001, p**** < 0.0001). (B) Guanine-cytosine composition at the third codon position of arenavirus genera for GPC, NP and L protein sequences. A violin plot showing the GC percentage at the third codon position for the coding sequences of the GPC, NP and L genes of each Arenavirus genus. p-values were calculated using either Tukey’s test (NP and L) or Dunn’s test (GPC) for multiple comparisons based on the normality distribution of the data (p* < 0.05, p** < 0.01, p*** < 0.001, p**** < 0.0001).
Preferred codonsThe RSCU for the GPC, NP and L genes of the analyzed arenaviruses are listed in Table 1.
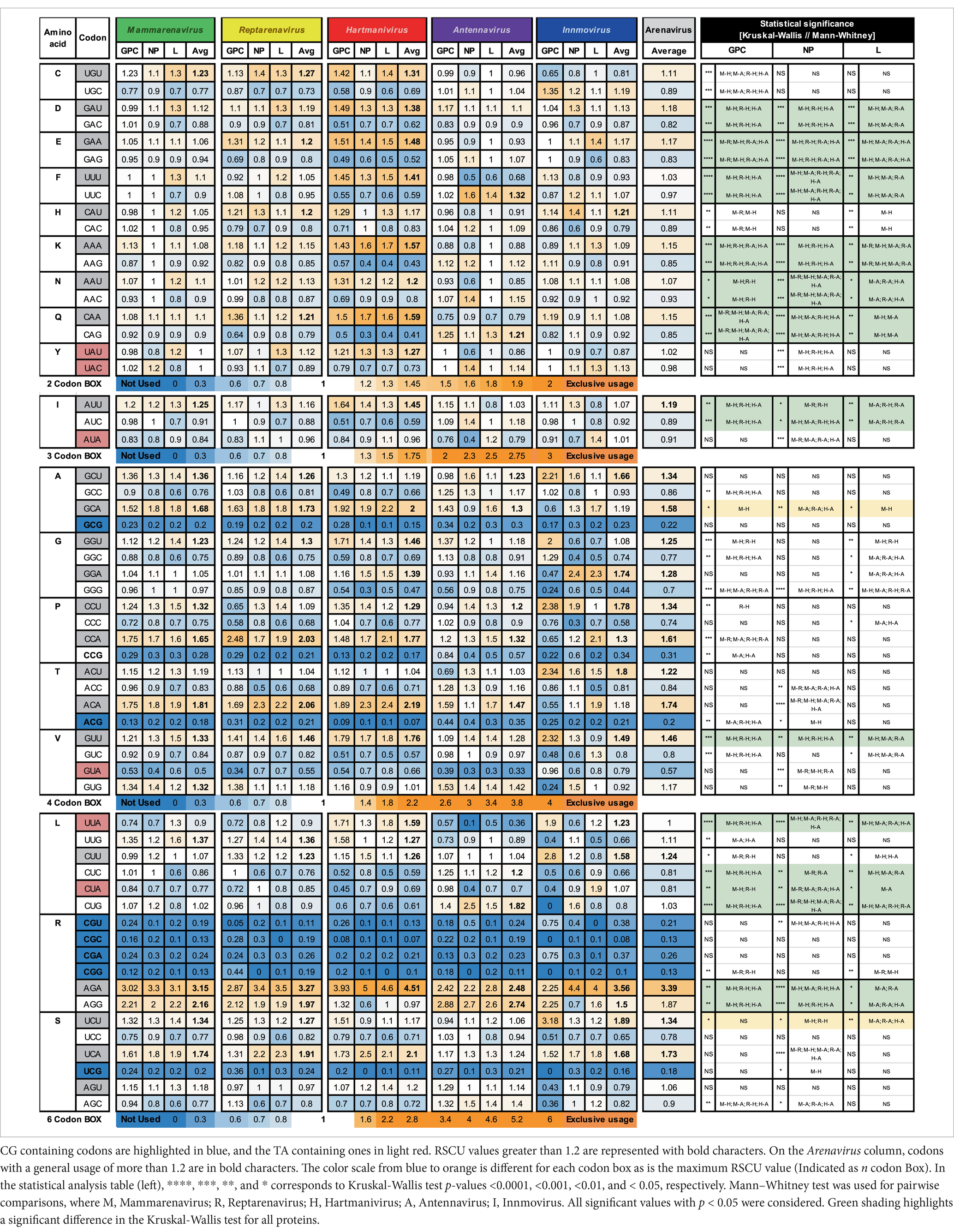
Table 1. Relative synonymous codon usage for arenaviral common proteins, averaged per genus and family.
RSCU values above 1.0 refer to codons that were used more frequently, and values below 1.0 refer to codons that were used less frequently, while a value equal to 1.0 means that all codons were used equally frequently (Sharp and Li, 1987). We observed a general preference for codons with A or U in the third position among the synonymous codons, with 9 amino acids (I, A, G, P, T, V, L, R, and S) having an RSCU value of >1.2 and the rest having either a similar usage (~ 1) or a weaker preference (> 1 but <1.2) in most genera (GC3 < 50, Figure 1B and Table 1), with the exception of Antennavirus, where only amino acids A, P, T and R showed a preference for codons with A/U terminus. Hartmanivirus, on the other hand, showed significantly higher RSCU values for most codons with A/U terminus compared to the other genera, even in the 2 codon boxes (Pairwise significant differences in Hartmanivirus, which have a p-value <0.05, are labeled as M-H, R-H and H-A). In the case of arginine, codons AGA and AGG were generally more represented in all genera than codons in the CG box, which were underrepresented. The statistically significant differences between genera varied between proteins for some codons, with cases in which there were significant differences for only one protein, such as for NP for codons UAU, UAC, ACC, ACA, and CGU; and for GPC for UGU, UGC, CAU, CAC, GCC, CCU, CCA, CCG, and UUG, among others. In addition, all codons with CG or UA dinucleotides in their sequence and certain G-start and C-end codons – which can form CG depending on the codon pair – were underrepresented. RSCU values tended to be similar between the different proteins, with the exception of Innmovirus, where certain codons were overrepresented in some proteins and underrepresented in others, due to insufficient sample size.
Effective number of codonsThe values for the effective number of codons (ENC) range from 20, indicating an extreme bias in the use of codons, as only one codon is used for each amino acid, to 61, indicating that there is no preference and that all possible synonymous codons are used equally (Wright, 1990). We determined the ENC to assess the extent of codon usage bias (Figure 2). A slight codon usage bias was observed for most genera, with ENC values close to 50 for all proteins analyzed. Remarkably, Hartmanivirus showed a significantly lower ENC value (~45) for all proteins, which could be partly explained by the more biased nucleotide composition (Figure 1).
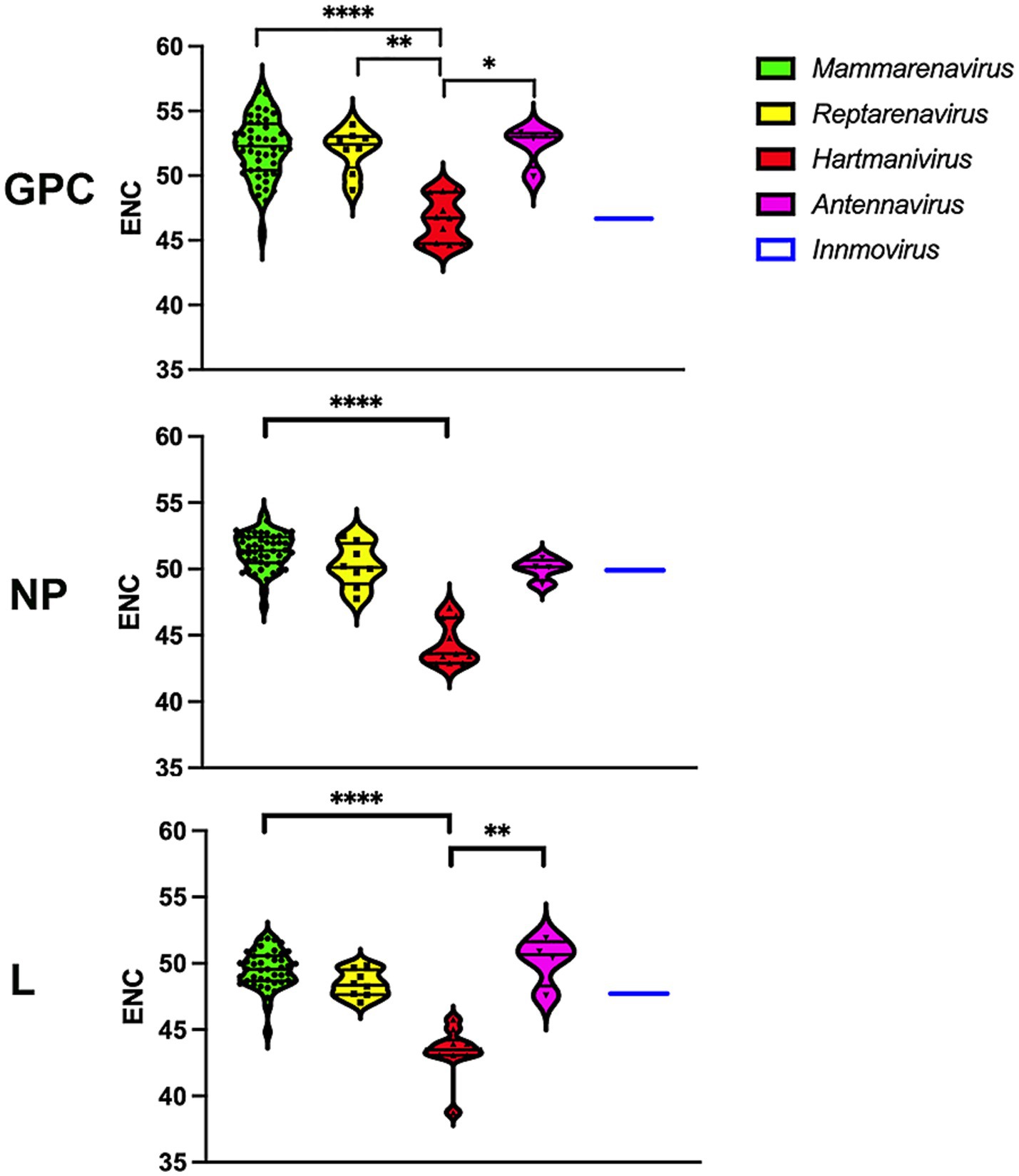
Figure 2. Differences in ENC between arenavirus genera for GPC, NP and L protein sequences. A violin plot shows the ENC for the coding sequences of the GPC, NP and L genes of each arenavirus genus. p-values were calculated in all cases using Dunn’s test for multiple comparisons based on the normality distribution of the data (p* < 0.05, p** < 0.01, p*** < 0.001, p**** < 0.0001).
To further investigate the effects of mutational pressure on patterns of codon usage, we generated an ENC plot. Arenavirus genes where codon selection is only affected by mutational pressure fall on or slightly below the expected ENC curve assuming no natural selection calculated as f(GC3) (dos Reis et al., 2004), with the effect of selection on codon usage being greater the further the points are from the curve. We found that all points corresponding to proteins from the different species were below the curve for the expected ENC value for each GC3, as suggested by other researchers (Wright, 1990), with Mammarenavirus and Antennavirus being the furthest apart (Figures 3A,B). In addition, GPC and NP were further apart than L, whose points were visibly closer to the curve. The difference between the ENC values and the expected ENC values under the hypothesis of no selection f(GC3) was compared between genera for each protein (Figure 3B). While mammarenaviruses and reptarenaviruses had the same median f(GC3) ENC value between 5 and 6 for all three proteins, antennaviruses and hartmaniviruses differed significantly from each other in NP and L, with the former having higher median value than the other genera (f(GC3) ENC value >7). These results suggest that factors other than mutational pressure, including natural selection, influence the evolution of codon usage in arenaviruses, and that this effect is more pronounced in antennaviruses and in L and NP when compared to GPC proteins. In contrast, the results for Hartmanivirus indicate a relatively stronger influence of mutational pressure in this genus.
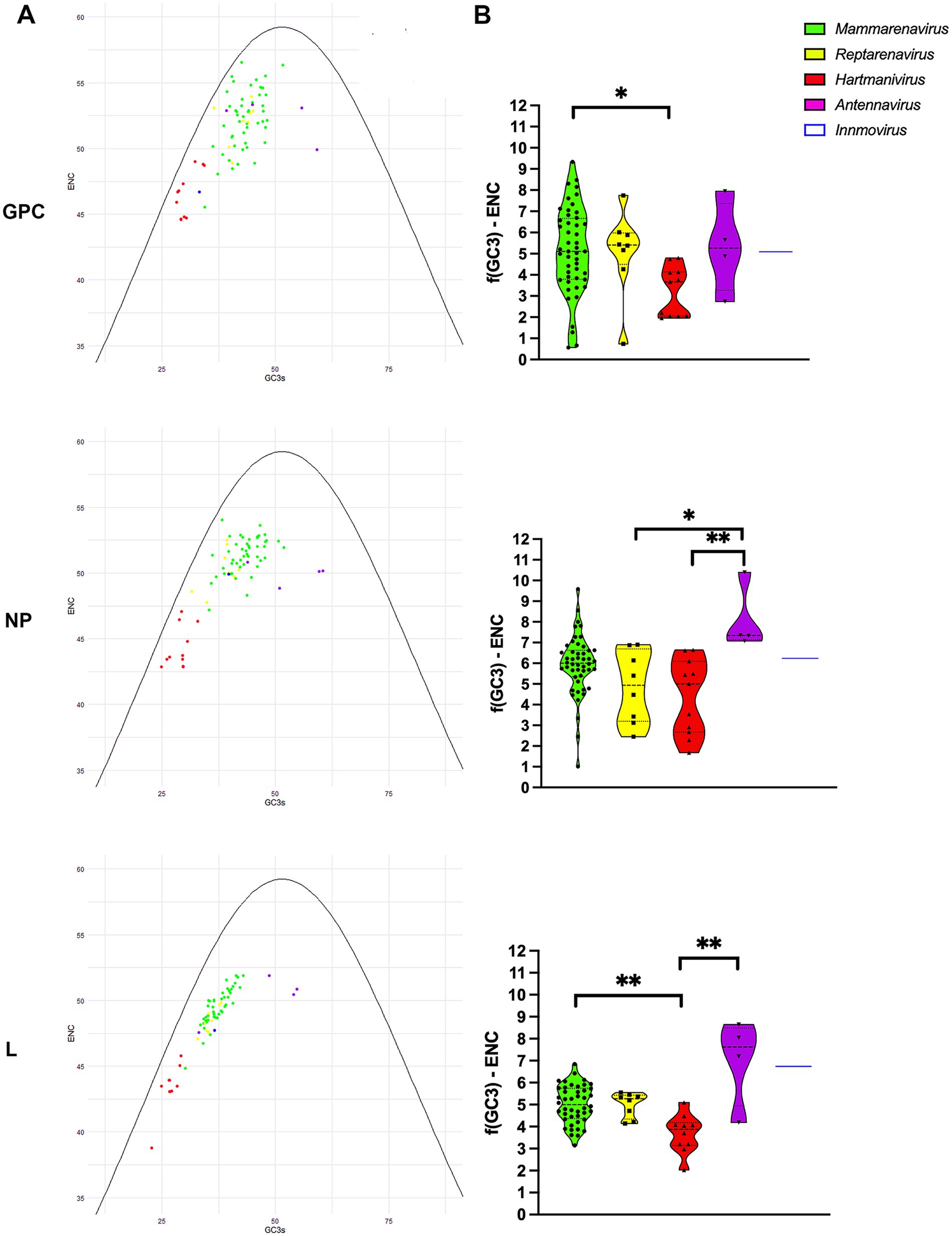
Figure 3. ENC-plot analysis of arenavirus genera for GPC, NP and L protein sequences. (A) The continuous purple curve represents the expected ENC values when the GC3 composition only restricts codon usage bias (no selection). The dots represent the ENC values for each of the coding sequences of all analyzed viruses. Different colors indicate the genera as shown. The color coding is the same in all plots. (B) Difference between the ENC values and the expected ENC values under the hypothesis of no selection. A Kruskal-Wallis test followed by a Dunn’s test was used to compare the data between genera. * and ** correspond to p-values <0.05 and 0.01, respectively.
To further investigate the effects of natural selection on arenaviruses, we constructed neutrality plots for GPC, NP and L protein genes by genus, in which mutational pressure and natural selection pressure are expressed as slopes of the regression line (Nasrullah et al., 2015). We observed an important role of natural selection in shaping codon usage in arenaviruses (Figure 4). In all genera, natural selection explains more than 73% (although in most cases no correlation was found between GC12 and GC3). The genera for which mutational pressure played a greater role were: Reptarenavirus and Antennavirus GPC with 22 and 14% respectively, Antennavirus NP with 11% and Mammarenavirus and Hartmanivirus L with 27 and 21%, respectively.
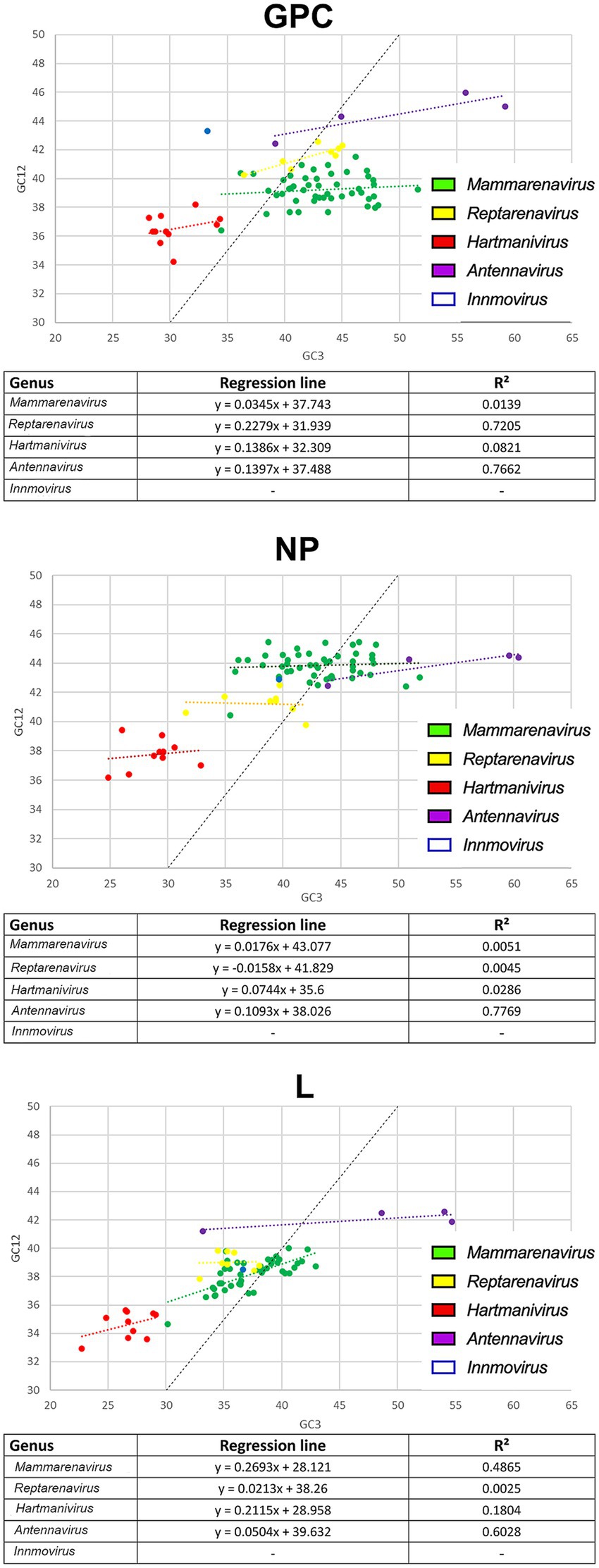
Figure 4. Neutrality plot analysis of arenavirus genera for GPC, NP and L protein sequences. Each genus is shown in a different color. The formula and R2 for the regression line plotted for each genus are indicated below each image.
Comparative host adaptabilityTo investigate whether the observed selection favors optimal codons and thus rapid and efficient translation of viral proteins in the host, we next calculated the CAI (Sharp and Li, 1987) using the CDS of all human genes and the CDS of their natural hosts, the families Boidae, Muridae, Cricetidae, and Salmonidae. CAI values range from 0 to 1, with higher CAI values indicating higher expression levels and greater adaptation to the host (Sharp and Li, 1987). Our results show that CAI levels were highest in H. sapiens and the Boidae family and lowest in the Salmonidae family (Figure 5). It was expected that Mammarenavirus genes in the family Muridae would have lower CAI values than those in the family Cricetidae, since most of their natural hosts belong to the latter. It was also expected that Hartmanivirus and Antennavirus would have higher CAI values in the family Boidae and Salmonidae, respectively, as these are their natural hosts. However, there were also unexpected results, including the fact that: (a) Mammarenavirus proteins had higher CAI values in H. sapiens than in the family Cricetidae; (b) Antennavirus had equal or significantly higher CAI values than mammarenaviruses for the three proteins in H. sapiens, the family Muridae and the family Cricetidae; (c) with the exception of H. sapiens, Reptarenavirus and Hartmanivirus generally showed significant differences between them, even in the family Boidae, the natural host of both genera; and finally (d) the high similarity between Mammarenavirus and Reptarenavirus in all hosts.
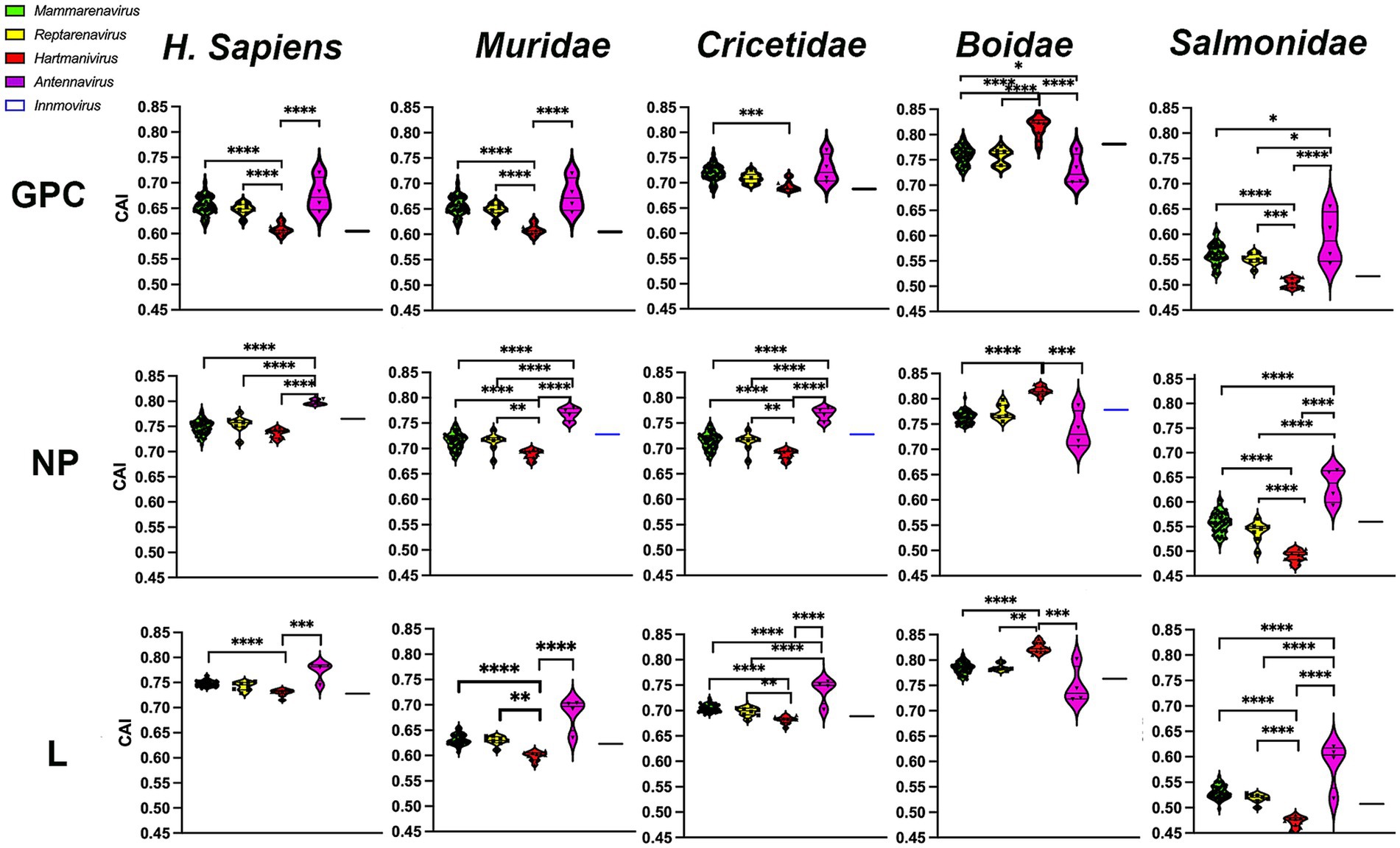
Figure 5. Codon adaptation indices of arenavirus genera for GPC, NP and L protein sequences in different hosts. CAI values were calculated using codon usage tables obtained from sequences of H. sapiens and four different taxonomic animal families. p-values were calculated using Tukey or Dunn tests for multiple comparisons based on the normality distribution of the data (p* < 0.05, p** < 0.01, p*** < 0.001, p**** < 0.0001).
To further investigate whether codon usage bias tends to be optimally expressed, we performed a CAI calculation with 500 of the most highly expressed proteins in all human tissues (Uhlen et al., 2015), so that higher CAIHHE (HHE: human highly expressed) values could include more accurate and faster translation, in addition to several factors. The results show that most arenavirus proteins have CAIHHE values in the range of 0.7–0.82 (Figure 6), which are similar to those of human proteins (CAIHHE ~ 0.78 on average), regardless of whether they are highly or lowly expressed (HLE: human lowly expressed) (the mean CAIHHE values for HHE and HLE are 0.781 and 0.782 respectively, and are not significantly different in the Mann–Whitney test). Remarkably, the antennaviruses have the highest CAIHHE values for NP and L, while the hartmaniviruses have the lowest values (Figure 6).
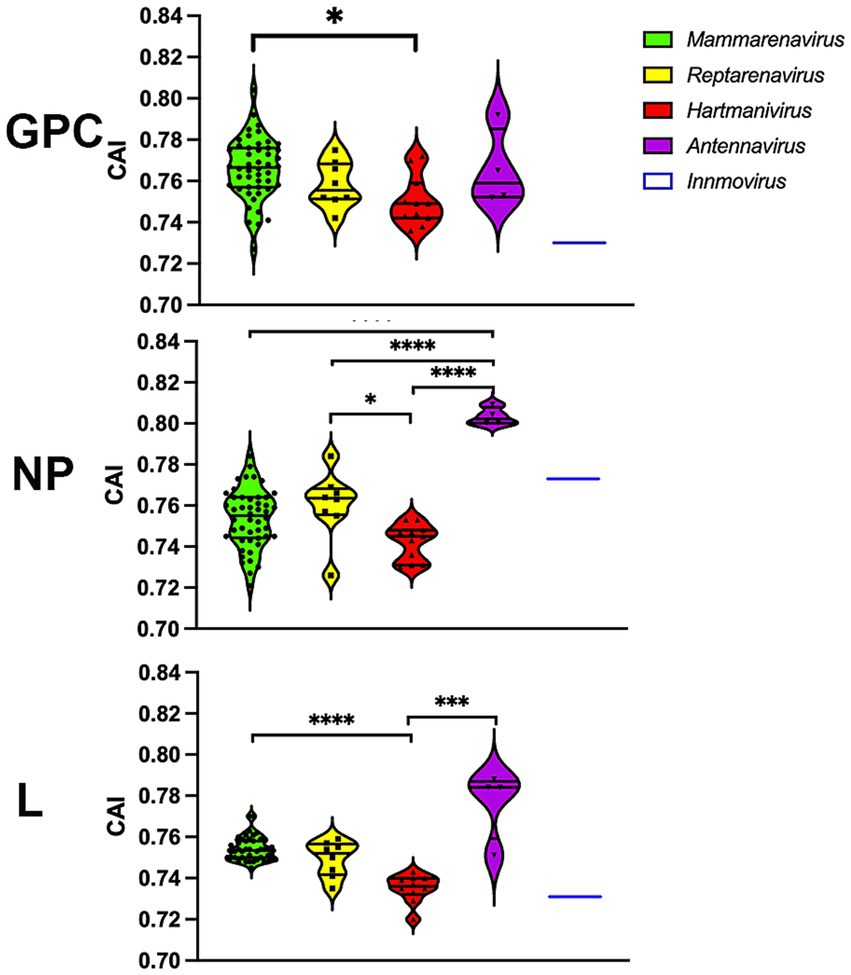
Figure 6. CAI calculated using the 500 most highly constitutively expressed human protein sequences as reference set. p-values were calculated using either Tukey’s (NP and GPC) or Dunn’s (L) tests for multiple comparisons based on the normality distribution of the data (p* < 0.05, p** < 0.01, p*** < 0.001, p**** < 0.0001).
Finally, a correspondence analysis (CA) of the RSCU with the three viral proteins of each virus species and genus was performed to analyze the CUB patterns in more detail. The results showed that Antennavirus members exhibited a broader distribution, while Hartmanivirus showed a higher bias. All host proteins were located in the same region of the CA plot, with Boidae being further away from the other hosts and closer to the Hartmanivirus members. Mammarenaviruses and reptarenaviruses appear to have a similar codon usage bias as they are located close to each other. No clear correlation was found between the codon usage bias of the pathogenic species and the human CUB (Figure 7A). In particular, UUA (L), ACG (T), CGU (R), CGG (R) and CGC (R) were important in defining the CA axes for all arenavirus proteins (Figure 7B). UUA was significantly different for all genera, with Hartmanivirus having the highest and Antennavirus the lowest. In contrast, ACG was the preferred codon for S in Antennavirus. The dimensions in the CA indicate the different sources of variation between a set of multivariate data points. In this case, dimension 1 (Dim1) was different among proteins and explained almost 50% of the variation in L, while NP and GPC had lower values, while dimension 2 (Dim2) explained at most 10% of the variation in all proteins. It is interesting to note that the central axes (0, 0) divide the codons into two clusters: codons with either A or T at the third base position (AT3) on the left and codons with either G or C at the third base position (GC3) on the right (Figure 7B).
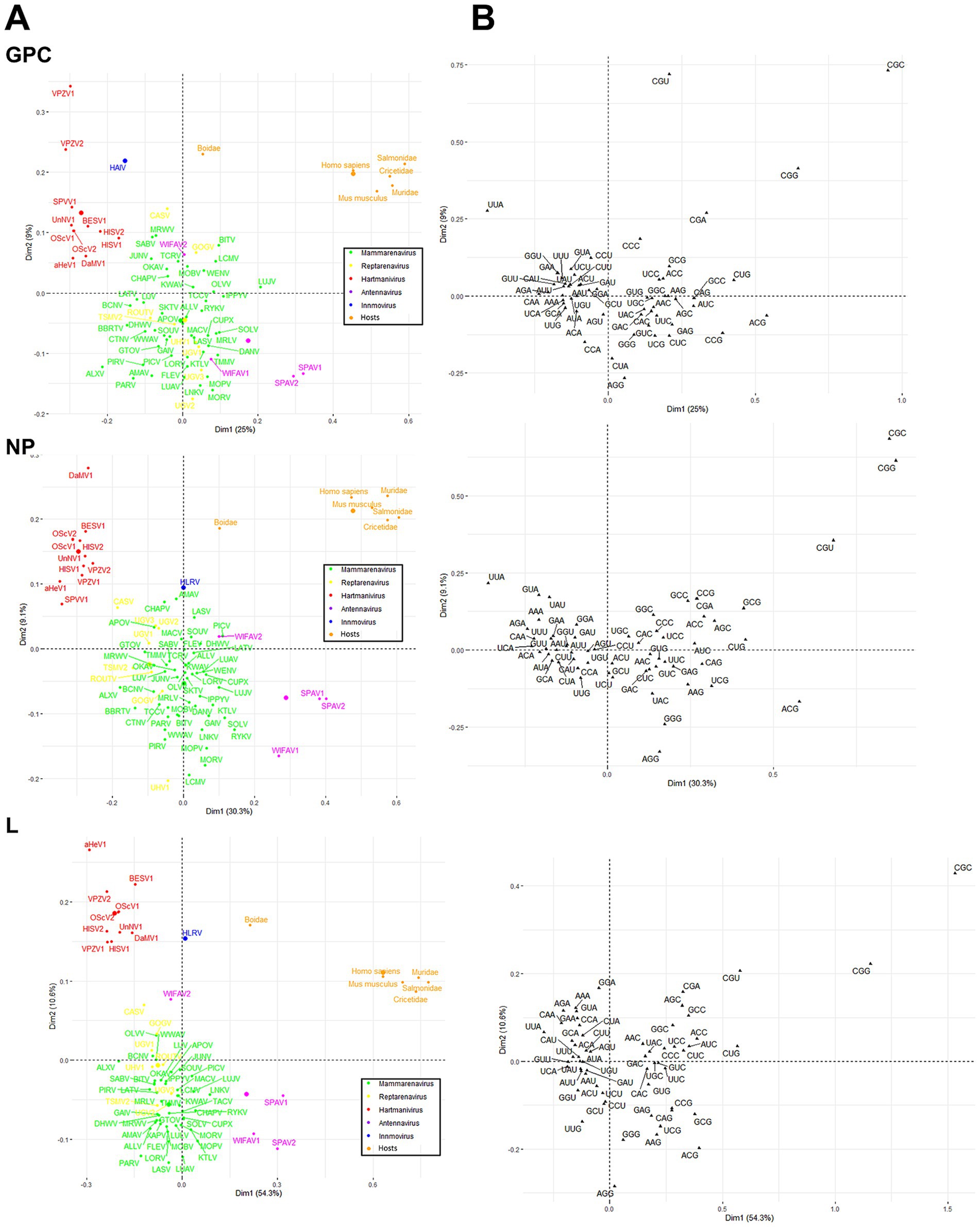
Figure 7. Correspondence analysis of GPC, NP and L protein sequences of arenavirus based on RSCU values. (A) Distribution of the genes of all arenaviruses on the plane corresponding to the coordinates of the first and second major axes. The colors correspond to the different genera as shown. The small dots correspond to the individual species, the large dots to the average per genus. (B) The distribution of synonymous codons is shown along the first and second axis of the correspondence analysis.
DiscussionOur report provides a comprehensive analysis of codon usage bias for all arenavirus genera. By using a concatenated alignment of the L and NP proteins, we have constructed a phylogenetic tree that determines the distance in clustering between specific species within the family with greater precision than trees constructed using NP or L separately. As reported by Forni et al. (2018), our tree also places NW Arenavirus closer to the common ancestor of Mammarenavirus, and both OW and NW mammarenaviruses are in the same clade as Reptarenavirus, with the common ancestors of Hartmanivirus and Antennavirus being the most distant in the phylogeny. The fact that mammarenaviruses and reptarenaviruses are closer to each other in phylogeny is also reflected in their similarity in genome composition. Based on phylogeographic analyses, the possibility that OW and NW mammarenaviruses descended from a common ancestor that occurred in both Africa and South America has been proposed, with a reptilian arenavirus, such as reptarenaviruses, being an attractive candidate (Forni et al., 2018). Since the full range of natural hosts of mammarenaviruses and reptarenaviruses is unknown, another possibility is that their common ancestor infected a different mammalian host and that snakes are not the reservoir of the reptarenavirus, but an accidental host. This is supported by the analogy with the mammarenavirus, which can infect animal species other than natural hosts, at least in experimental settings, often leading to severe disease and even death (Forni et al., 2018; Pontremoli et al., 2019).
The total nucleotide content of the genome can strongly influence codon usage patterns (Jenkins and Holmes, 2003). Furthermore, van Hemert et al. (2016) suggested that nucleotide bias in RNA virus genomes is the primary determinant of specific codon usage, limiting the role of codon selection and translational control. Our analysis of the nucleotide composition of GPC, NP and L genes revealed that most codons containing the dinucleotide CG are highly repressed and those containing the dinucleotide UA are slightly underrepresented, with this difference being smaller in antennaviruses. This was to be expected as it has been reported for most RNA viruses (Karlin et al., 1994). CpG dinucleotides have been largely removed from the human genome (Cooper and Gerber-Huber, 1985), so that human mRNAs are CpG-repressed, a fact that is largely reflected by CpG suppression in viruses that infect humans, even though their genome composition may not have been shaped by DNA methylation/deamination (Cooper and Gerber-Huber, 1985). The selection pressure that has led to CpG suppression in viral genomes remains unknown (Goncalves-Carneiro et al., 2021). However, there are some reasons that could explain this, at least in part. In vertebrates, there are short, interspersed DNA sequences that deviate significantly from the average genomic pattern because they are GC- and CpG-rich and predominantly unmethylated (Deaton and Bird, 2011). These regions, known as CpG islands (CGI), are often sites of transcription initiation. For promoter function, they destabilize nucleosomes and attract proteins (Angeloni and Bogdanovic, 2021). In addition, CGIs have recently been linked to a gene regulatory mechanism in which CGIs are bound by a protein complex that specifically protects genic transcripts from premature termination, effectively distinguishing between genic and extragenic transcription and allowing normal gene expression (Hughes et al., 2023). It could be hypothesized that viral RNA with a low CG content interacts less with host proteins and is therefore more efficient for viral replication and translation. On the other hand, the antiviral host factor zinc finger protein (ZAP) has been reported to selectively inhibit replication of a variety of viruses by recognizing the CG-rich RNA sequences and activating the viral RNA degradation machinery (Pal et al., 2023). Zap and its analog PARP12 genes arose early in vertebrate divergence and originated in an original gene whose progeny are present in some modern invertebrates such as cnidarians but absent in others such as arthropods (Goncalves-Carneiro et al., 2021), suggesting that it may be a mutational pressure in all known arenaviruses. It is hoped that future studies will clarify the role of CpG suppression in viral genomes.
A weak codon usage bias was observed in all Arenaviridae genera (ENC ~50). Although Hartmanivirus had lower ENC values, the corresponding points in the ENC plot were closer to the curve (predicted ENC value in the absence of natural selection), suggesting a greater effect of compositional and mutational biases compared to the other arenaviruses. The ENC analysis also suggests a more important role of selection in the case of Mammarenavirus and Antennavirus, as also shown by the corresponding neutrality plots. Although a weak codon usage bias has already been reported for the mammarenaviruses CHPV and SABV, it was concluded that mutational pressure has the strongest influence on codon usage bias in both hemorrhagic fever pathogens (Malhotra and Kumar, 2021). The difference between our results could be due to the fact that we created the neutrality plots for each protein and grouped the arenaviruses by genus to obtain more information, as we felt that only three proteins were too few to derive a good regression.
The role of mutation and selection was not the same for each protein in all genera. Our results suggest that although selection pressure remains the most important determinant of codon usage bias, it has a stronger influence on the codon usage bias of GPC and NP than on that of L in mammarenaviruses. The L protein has been described as the main driver of evolution of the genus as it is subject to positive selection at multiple sites and there is evidence that changes in its sequence lead to differential replication efficiency and disease phenotypes in rodents (Pontremoli et al., 2017; Forni et al., 2018), and, in the case of LASV, affect transmissibility or severity of the disease in humans (Pontremoli et al., 2019). It has also been hypothesized that selection pressure acting on arenavirus L proteins confers species-specific increased replication capacity or faster spread kinetics to the virus, facilitating escape from immune surveillance and allowing persistent infection (Sullivan et al., 2015). Interestingly, our results suggest that antennaviruses and reptarenaviruses do not follow this pattern and natural selection plays a relatively more important role than mutational pressure for the L protein.
Our CAI analysis showed good agreement with the general use of host codons, with humans and Boidae scoring higher for most viruses. In particular, hartmaniviruses and antennaviruses showed the highest CAI for all proteins when the proteins of their respective hosts were used as reference sets. Hartmanivirus is also positioned differently in the correspondence analysis as it is closer to the Boidae. This suggests an adaptation to host-specific codons, but does not explain the difference to Reptarenavirus, which has the same hosts, which requires further investigation. Remarkably, Mammarenavirus and Reptarenavirus had very similar nucleotide composition, codon usage bias and CAI values, both of which were markedly different from Hartmanivirus, which had the highest CAI within the Boidae for all its proteins. This reinforces the hypothesis that reptarenaviruses may have an unknown mammalian reservoir. In addition, mammalian cells have been successfully infected with reptarenaviruses (Hepojoki et al., 2015a), and recent data also suggest successful infection in the mouse model (Abba et al., 2017). Furthermore, for mammarenaviruses, there is limited evidence of host-virus co-divergence (Forni et al., 2018), suggesting that the shared host of Reptarenavirus and Hartmanivirus does not reflect a closer evolutionary link and providing another suitable explanation for the difference in codon usage behavior between these two genera.
The CAI was also calculated using a set of highly expressed human proteins as a reference. Since CAI correlates with protein expression (Sharp and Li, 1987), our results suggest that the arenavirus proteins analyzed have the potential for efficient translation in humans, at least in terms of optimizing codon usage. However, since we found no significant difference between CAIHHE and CAIHLE proteins, further studies should be performed to evaluate the expression levels of arenavirus proteins in human hosts.
In hantaviruses, it has been suggested that less adaptation to their hosts allows controlled and sustained infection in their natural reservoirs (Meyer and Schmaljohn, 2000). Such differences between hosts and natural reservoirs could correlate with the severe disease that certain mammarenaviruses cause when infecting humans, as opposed to the milder symptoms of infection in their reservoirs. In support of this hypothesis, we found that arenaviruses generally have lower CAI and CAIHHE in Muridae and Cricetidae than in humans. In addition, codon deoptimization of LCMV GPC and NP was found to produce highly attenuated viruses but still provide protection against wild-type LCMV (Cheng et al., 2015; Cheng et al., 2017). However, disease severity of LASV could not be correlated with significantly different nCAI levels, suggesting, at least for LASV, that disease severity is mainly determined either by interindividual human variability or by viral factors other than nCAI (Pontremoli et al., 2017). Future studies need to consider other factors influencing codon usage bias, as has been hypothesized for other viruses, e.g., geographic location and gene function (Chen et al., 2014; Rahman et al., 2018).
Finally, our correspondence analysis (CA) of individual RSCU codons reveals two clusters similar to those described in human mRNA that are rich in GC3 and AT3 and are associated with stabilization or destabilization of mRNA through interaction with interleukin enhancer binding factor 2 (ILF2) and perhaps ILF3 (Hia et al., 2019). The extent to which these mechanisms are effective in arenaviral RNA infections must be clarified in the future.
ConclusionHere we report the codon usage pattern of the Arenaviridae family common proteins as a whole. We found a weak codon usage bias, as has been reported for other RNA viruses, with ENC and neutrality diagrams indicating an important role of selection in evolution. As with all arenaviruses (and most small eukaryotic viruses), strong repression of CG-containing codons was observed. Antennavirus and Hartmanivirus showed different behavior within the family, both in composition and codon usage pattern. Remarkably, all arenaviruses appear to have codon usage adapted to both H. sapiens and Boidae, and some degree of host adaptation of codon usage patterns was observed for Hartmanivirus and Antennavirus.
Data availability statementThe datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary material.
Author contributionsPT: Writing – original draft, Data curation, Formal analysis, Investigation, Methodology. MF: Data curation, Project administration, Supervision, Writing – review & editing. ML: Data curation, Conceptualization, Validation, Writing – review & editing. RG: Writing – review & editing, Funding acquisition, Supervision, Writing – original draft.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the grant PICT 2020-02702 (RGM) from the Agencia Nacional de Promoción Científica y Tecnológica (ANPCyT), Argentina. The funders had no role in study design, data collection and interpretation, or in the decision to submit the work for publication.
AcknowledgmentsDuring the preparation of this work the author(s) used InstaText (https://instatext.io) in order to improve text. After using this tool, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the publication.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2024.1490076/full#supplementary-material
Footnotes ReferencesAbba, Y., Hassim, H., Hamzah, H., Ibrahim, O. E., Mohd Lila, M. A., and Noordin, M. M. (2017). Pathological vicissitudes and oxidative stress enzyme responses in mice experimentally infected with reptarenavirus (isolate UPM/MY01). Microb. Pathog. 104, 17–27. doi: 10.1016/j.micpath.2017.01.003
PubMed Abstract | Crossref Full Text | Google Scholar
Baha, S., Behloul, N., Liu, Z., Wei, W., Shi, R., and Meng, J. (2019). Comprehensive analysis of genetic and evolutionary features of the hepatitis E virus. BMC Genomics 20:790. doi: 10.1186/s12864-019-6100-8
PubMed Abstract | Crossref Full Text | Google Scholar
Butt, A. M., Nasrullah, I., Qamar, R., and Tong, Y. (2016). Evolution of codon usage in Zika virus genomes is host and vector specific. Emerg. Microbes Infect. 5:e107. doi: 10.1038/emi.2016.106
PubMed Abstract | Crossref Full Text | Google Scholar
Chen, Y. M., Hu, S. J., Lin, X. D., Tian, J. H., Lv, J. X., Wang, M. R., et al. (2023). Host traits shape virome composition and virus transmission in wild small mammals. Cell 186, 4662–4675.e12. doi: 10.1016/j.cell.2023.08.029
PubMed Abstract | Crossref Full Text | Google Scholar
Chen, Y. M., Sadiq, S., Tian, J. H., Chen, X., Lin, X. D., Shen, J. J., et al. (2022). RNA viromes from terrestrial sites across China expand environmental viral diversity. Nat. Microbiol. 7, 1312–1323. doi: 10.1038/s41564-022-01180-2
PubMed Abstract | Crossref Full Text | Google Scholar
Chen, Y., Shi, Y., Deng, H., Gu, T., Xu, J., Ou, J., et al. (2014). Characterization of the porcine epidemic diarrhea virus codon usage bias. Infect. Genet. Evol. 28, 95–100. doi: 10.1016/j.meegid.2014.09.004
PubMed Abstract | Crossref Full Text | Google Scholar
Cheng, B. Y. H., Nogales, A., de la Torre, J. C., and Martinez-Sobrido, L. (2017). Development of live-attenuated arenavirus vaccines based on codon deoptimization of the viral glycoprotein. Virology 501, 35–46. doi: 10.1016/j.virol.2016.11.001
PubMed Abstract | Crossref Full Text | Google Scholar
Cheng, B. Y., Ortiz-Riano, E., Nogales, A., de la Torre, J. C., and Martinez-Sobrido, L. (2015). Development of live-attenuated arenavirus vaccines based on codon deoptimization. J. Virol. 89, 3523–3533. doi: 10.1128/JVI.03401-14
PubMed Abstract | Crossref Full Text | Google Scholar
Christensen, K. A., Rondeau, E. B., Minkley, D. R., Sakhrani, D., Biagi, C. A., Flores, A. M., et al. (2020). The sockeye salmon genome, transcriptome, and analyses identifying population defining regions of the genome. PLoS One 15:e0240935. doi: 10.1371/journal.pone.0240935
PubMed Abstract | Crossref Full Text | Google Scholar
dos Reis, M., Savva, R., and Wernisch, L. (2004). Solving the riddle of codon usage preferences: a test for translational selection. Nucleic Acids Res. 32, 5036–5044. doi: 10.1093/nar/gkh834
PubMed Abstract | Crossref Full Text | Google Scholar
Dutta, R., Buragohain, L., and Borah, P. (2020). Analysis of codon usage of severe acute respiratory syndrome corona virus 2 (SARS-CoV-2) and its adaptability in dog. Virus Res. 288:198113. doi: 10.1016/j.virusres.2020.198113
PubMed Abstract | Crossref Full Text | Google Scholar
Emonet, S., Lemasson, J. J., Gonzalez, J. P., de Lamballerie, X., and Charrel, R. N. (2006). Phylogeny and evolution of old world arenaviruses. Virology 350, 251–257. doi:
留言 (0)