
記住我
Diabetes, especially type 2 diabetes (T2DM), has become a major global public health challenge. According to the International Diabetes Federation (IDF), approximately 536.6 million people worldwide were living with diabetes in 2021, and this number is projected to rise to 783.2 million by 2045 (1). Diabetes is a major contributor to multiple serious complications, including cardiovascular disease, kidney failure, retinopathy, and lower extremity amputations (2). Such complications pose a threat to patients’ quality of life and impose a significant strain on healthcare systems worldwide (3).
The key risk factors for diabetes include age, genetics, obesity, lack of physical activity, unhealthy eating patterns, and smoking (4). In addition to these traditional factors, a growing body of research is investigating biomarkers associated with metabolic syndrome, such as elevated uric acid levels, low HDL cholesterol, and insulin resistance (5–7). These metabolic indicators are significant contributors to diabetes and have strong connections with cardiovascular disease development. Therefore, identifying biomarkers that can effectively predict diabetes risk is essential for early intervention and prevention of the disease (8, 9).
In recent years, the serum uric acid to high-density lipoprotein cholesterol ratio (UHR) has attracted considerable interest as an emerging metabolic risk indicator. Uric acid (UA), the end product of purine breakdown, primarily eliminated by the kidneys, can, at elevated levels, suppress nitric oxide production, encourage the proliferation of vascular smooth muscle cells, and cause endothelial dysfunction, thereby speeding up the progression of atherosclerosis and insulin resistance (10, 11). Moreover, reduced low-density lipoprotein cholesterol (LDL-C) levels impair its roles in reverse cholesterol transport, as well as its anti-inflammatory and antioxidant properties, exacerbating lipid metabolic disturbances and further promoting the onset of insulin resistance and metabolic syndrome (12, 13). UHR provides a novel perspective for predicting metabolic disease risk by encapsulating the dual effects of elevated uric acid and reduced HDL-C. Existing research indicates that UHR reflects inflammation and metabolic status, demonstrating outstanding assessment abilities in diseases like Hashimoto’s thyroiditis (14), type 2 diabetes (15) or prediabetes (16), metabolic syndrome (17), coronary artery disease (18), and NAFLD (19). For instance, UHR demonstrates high sensitivity and specificity in forecasting the risk of type 2 diabetes onset, and its mechanism is significantly related to insulin resistance, HbA1c, and FPG levels (20, 21). Research on coronary artery disease indicates that elevated UHR levels are significantly correlated with cardiovascular events, with mechanisms possibly involving accelerated atherosclerosis and endothelial dysfunction (22). Thus, UHR may act as a predictor for diabetes and metabolic syndrome and could also be used for early screening of coronary artery disease and other related cardiovascular event risks.
Although previous research has shown a correlation between UHR and the occurrence of diabetes, along with other metabolic conditions, most are small-scale cross-sectional studies, and findings across different races, ages, and genders are still inconsistent. Consequently, long-term follow-up data from large-scale, diverse populations are lacking to determine the general applicability and predictive performance of UHR as a diabetes risk predictor.
This study uses data from the 2005-2018 NHANES cycles to comprehensively assess the relationship between UHR and diabetes risk, while exploring its predictive ability across different populations. It is hypothesized that UHR may serve as an independent predictor of diabetes and exhibit varying predictive effects across different genders, ages, and racial groups. This study aims to provide new insights into the prevention and risk prediction of diabetes.
2 Materials and methods2.1 Data and sample sourcesThis study utilized NHANES data from the National Center for Health Statistics (NCHS). NHANES is a comprehensive survey designed to collect representative information on the health and nutritional status of the U.S. civilian population, encompassing demographics, socioeconomic status, dietary habits, and health-related issues. To ensure sample diversity, NHANES employed a stratified, multistage probability sampling method to select nationally representative participants. The study protocol was approved by the Ethics Review Committee of the CDC’s NCHS, and all participants provided written informed consent. The data are publicly available at https://www.cdc.gov/nchs/nhanes/.
This study primarily analyzed adult health data from the NHANES 2005–2018 cycles. The original cohort included a total of 70,190 participants. We initially excluded individuals under 20 years of age, followed by those missing diabetes diagnostic indicators and UHR data, ultimately including 30,813 participants, of whom 5,020 were diagnosed with diabetes. The sample selection flowchart is shown in Figure 1.
Figure 1. Flow chart.
2.2 UHR (exposure variable)The exposure variable, UHR, was calculated using fasting morning blood sample data obtained from the NHANES 2005-2018 database, which provided measurements of uric acid (UA) and high-density lipoprotein cholesterol (HDL-C). In NHANES, HDL-C was measured using direct immunoassay or precipitation methods, while serum uric acid concentrations were assessed via a timed endpoint method. Specifically, UA was measured using a DxC800 automated chemistry analyzer by calculating the change in absorbance of the chromogenic product formed from the reaction between hydrogen peroxide—produced by uricase oxidation of uric acid—and 4-aminoantipyrine (4-AAP) catalyzed by 3,5-dichloro-2-hydroxybenzenesulfonic acid (DCHBS).
The UHR was determined using the following formula: UHR (%) = [UA (mg/dL)/HDL-C (mg/dL)] × 100.
2.3 Diabetes (outcome variable)The outcome variable was diabetes, assessed based on blood glucose parameters and questionnaires, including glycated hemoglobin (HbA1c), fasting plasma glucose (FPG, mmol/L), random plasma glucose (RPG, mmol/L), 2-hour oral glucose tolerance test (OGTT, mmol/L), physician diagnosis, and the use of antidiabetic medications or insulin. Participants were required to fast for 8 to 24 hours prior to laboratory testing; fasting status was confirmed during the morning examination, and laboratory analyses were performed. Because NHANES did not directly provide random plasma glucose data, plasma glucose levels were interpreted in combination with fasting duration: fasting plasma glucose was considered when fasting time was ≥8 hours, and random plasma glucose when fasting time was <8 hours.
Diabetes was defined by meeting any one of the following criteria: (1) HbA1c ≥6.5%; (2) FPG ≥7.0 mmol/L; (3) RPG ≥11.1 mmol/L or OGTT ≥11.1 mmol/L; (4) having been diagnosed with diabetes by a physician; (5) currently taking antidiabetic medications or insulin. Diabetes and non-diabetes were coded as 1 and 0, respectively.
In this study, we prioritized objective criteria (1), (2), and (3) for the diagnosis of diabetes. Only when data for all three objective indicators were missing did we consider criterion (4) (physician-diagnosed diabetes) and criterion (5) (use of antidiabetic medications or insulin). In our analysis, 28 cases were diagnosed based on criterion (4), and none based on criterion (5). Sensitivity analysis indicated that the proportion of self-reported diagnoses was very small, and the potential information bias from this was negligible.
2.4 CovariatesBased on existing literature and clinical considerations, we included several confounding factors: sex, age, education level, race/ethnicity, poverty income ratio (PIR), body mass index (BMI), blood pressure (BP), drinking status, smoking status, total cholesterol (TC), triglyceride (TG), LDL-C, HDL-C, non-high-density lipoprotein cholesterol (Non-HDL-C), and UA. Race/ethnicity was classified as: Non-Hispanic Asian, Mexican American, Non-Hispanic White, Non-Hispanic Black, Other Hispanic, and Other/Multiracial. Education levels were divided into three categories: Less than high school, High school or GED, and College or above. PIR was categorized into three groups: <1.30, 1.30-3.49, and ≥3.50. BMI was calculated as weight (kg) divided by height squared (m²). Hypertension was defined as self-reported physician-diagnosed hypertension or current use of antihypertensive medications. Drinking and smoking status were determined based on the questionnaire. All covariates were obtained from the NHANES database.
2.5 Missing data handlingIn this study, some covariates had missing values, including BMI, TG, SBP, DBP, and LDL. For BMI, TG, SBP, and DBP, the proportion of missing data was less than 10%. We used the k-nearest neighbors (KNN) imputation method to fill in these missing values, with k=5 neighbors, and standardized the relevant variables to ensure the accuracy and stability of the imputation process. For LDL, as the proportion of missing data was greater than or equal to 10%, we chose to retain the variable but exclude the missing values from the analysis, in order to minimize any potential bias arising from the high missing rate. To ensure the robustness of this approach, we also conducted a sensitivity analysis, which demonstrated that neither the imputation nor the exclusion of missing values significantly affected the study’s conclusions, confirming the stability of our findings.
2.6 Statistical methodsData analysis was conducted using DecisionLinnc 1.0 software (23). DecisionLinnc 1.0 is a comprehensive software package that integrates multiple programming languages and is capable of performing various statistical analyses, data processing, and graphical plotting. Given the complex sampling design of the NHANES data, weighted statistical methods were applied.
Participants were divided into two groups based on diabetes status and further categorized into four groups according to UHR quartiles. Continuous variables were assessed using the weighted Student’s t-test or ANOVA, while categorical variables were evaluated with the weighted chi-square test. For continuous variables that did not follow a normal distribution, the weighted Kruskal-Wallis test was used. In the descriptive analysis, continuous variables were expressed as weighted means ± standard deviations, and categorical variables were reported as weighted percentages.
To explore the relationship between UHR and diabetes risk, we initially constructed three multivariate logistic regression models. Before modeling, we evaluated multicollinearity among all covariates using variance inflation factor (VIF) analysis. Model 1 was unadjusted; Model 2 was adjusted for sex, age, and race; and Model 3 included additional adjustments for BMI, PIR, hypertension, smoking and drinking status, SBP, DBP, TC, TG, LDL-C, and non-HDL-C.
Subsequently, we applied LASSO regression to select the variables most significantly associated with diabetes risk, including UHR, age, BMI, sex, and education level, and used these variables to construct an optimized Model 4 to enhance predictive performance and model stability. The nonlinear relationship between UHR and diabetes risk was analyzed using restricted cubic splines (RCS), and the “Intelligent Filtering Restricted Cubic Spline Knot” and “Threshold Effect” techniques were employed to calculate the knot locations and threshold inflection points for each model. The predictive performance of the models was evaluated using ROC curves, decision curve analysis (DCA), and calibration curves, with model stability assessed via the Hosmer-Lemeshow test. A P-value of less than 0.05 in all global statistical tests was considered statistically significant.
Subgroup analysis: To further investigate the association between UHR and diabetes risk across different populations, subgroup analyses were performed on key categorical variables, including sex, race, education level, PIR, hypertension, smoking status, and drinking status. Each subgroup was analyzed using the corresponding multivariate logistic regression model. To control for the risk of Type I error introduced by multiple testing, we applied Bonferroni correction, adjusting the significance level to 0.05/7 = 0.00714. Therefore, in the subgroup analysis, a corrected P-value of less than 0.00714 was considered statistically significant.
3 Results3.1 Baseline characteristics comparison between diabetic and non-diabetic groupsThis study included a total of 30,813 participants, with a mean age of 47.30 years; 25,793 were non-diabetic subjects and 5,020 were diabetic subjects. Compared with the non-diabetic group, individuals with diabetes had higher age, BMI, SBP, INS, TG, UA, and UHR levels (p<0.001), and lower DBP, TC, LDL-C, HDL-C, Non-HDL-C levels (p<0.001). Additionally, significant differences were observed across the two groups in terms of gender, ethnicity, educational attainment, PIR, smoking and drinking behaviors, and hypertension prevalence (p<0.05). Further details can be found in Table 1.
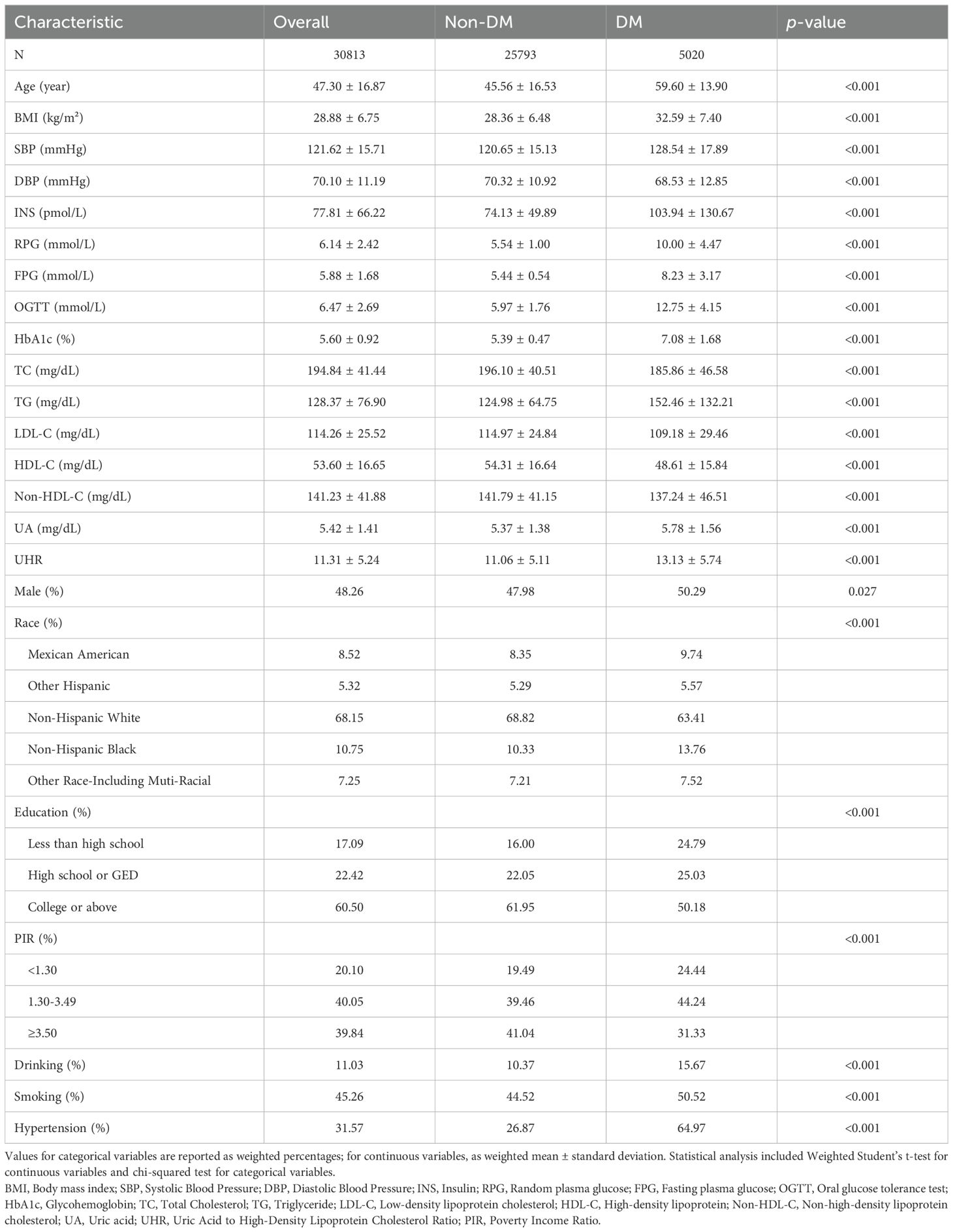
Table 1. Baseline characteristics of participants.
3.2 Association between UHR quartiles and diabetes riskTo explore the relationship between UHR and diabetes risk, participants were categorized into four quartiles (Q1-Q4) based on their UHR values. The results indicated that participants in the higher UHR quartiles had significantly increased BMI, SBP, DBP, INS levels, RPG levels, FPG levels, OGTT levels, HbA1c levels, TG levels, LDL-C levels, Non-HDL-C levels, and UA levels compared to those in the lower UHR quartiles (p<0.001), whereas TC and HDL-C levels were significantly decreased (p<0.001). Moreover, significant differences were also observed in the distribution of gender, ethnicity, education level, PIR, smoking status, and hypertension prevalence (p<0.001). Of particular note, the prevalence of diabetes increased significantly with higher UHR quartiles (6.63% vs. 10.88% vs. 14.15% vs. 18.02%, p<0.001). Details are shown in Table 2.
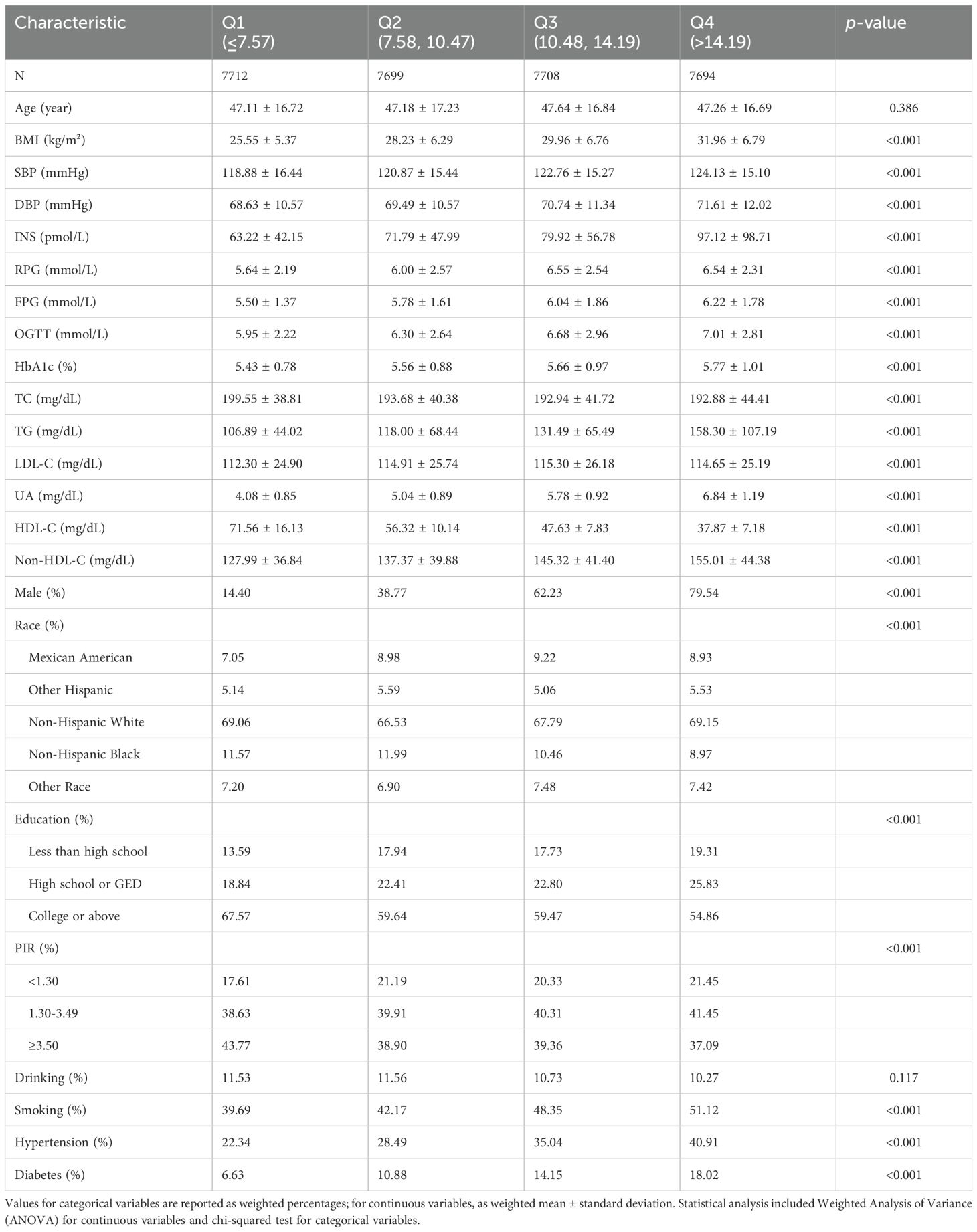
Table 2. Baseline characteristics by UHR quartiles.
Further multivariate logistic regression models were constructed to assess the independent association between UHR and diabetes (see Figure 2). Variance inflation factor (VIF) analysis showed that all variables had GVIF values below 2, well within the common collinearity threshold of 10, indicating no severe multicollinearity issues among the covariates. Thus, the coefficients in the regression model are stable and interpretable, unaffected by multicollinearity. The unadjusted model (Model 1) indicated that UHR was significantly associated with diabetes (p<0.001); participants in the highest quartile (Q4) had a fourfold increased risk of diabetes compared to those in the lowest quartile (Q1) (OR = 4.063, 95% CI: 3.536–4.669, p < 0.001). After adjusting for age, sex, ethnicity, and other factors (Model 2), the association between UHR and diabetes remained significant (p<0.001). Even with additional adjustments for metabolic and lifestyle variables like BMI, TC, TG, LDL-C and Non-HDL-C (Model 3), UHR was still significantly associated with diabetes risk (p<0.001). These findings suggest that higher UHR is positively associated with increased diabetes risk, and this association remains significant even after adjusting for various confounding factors.
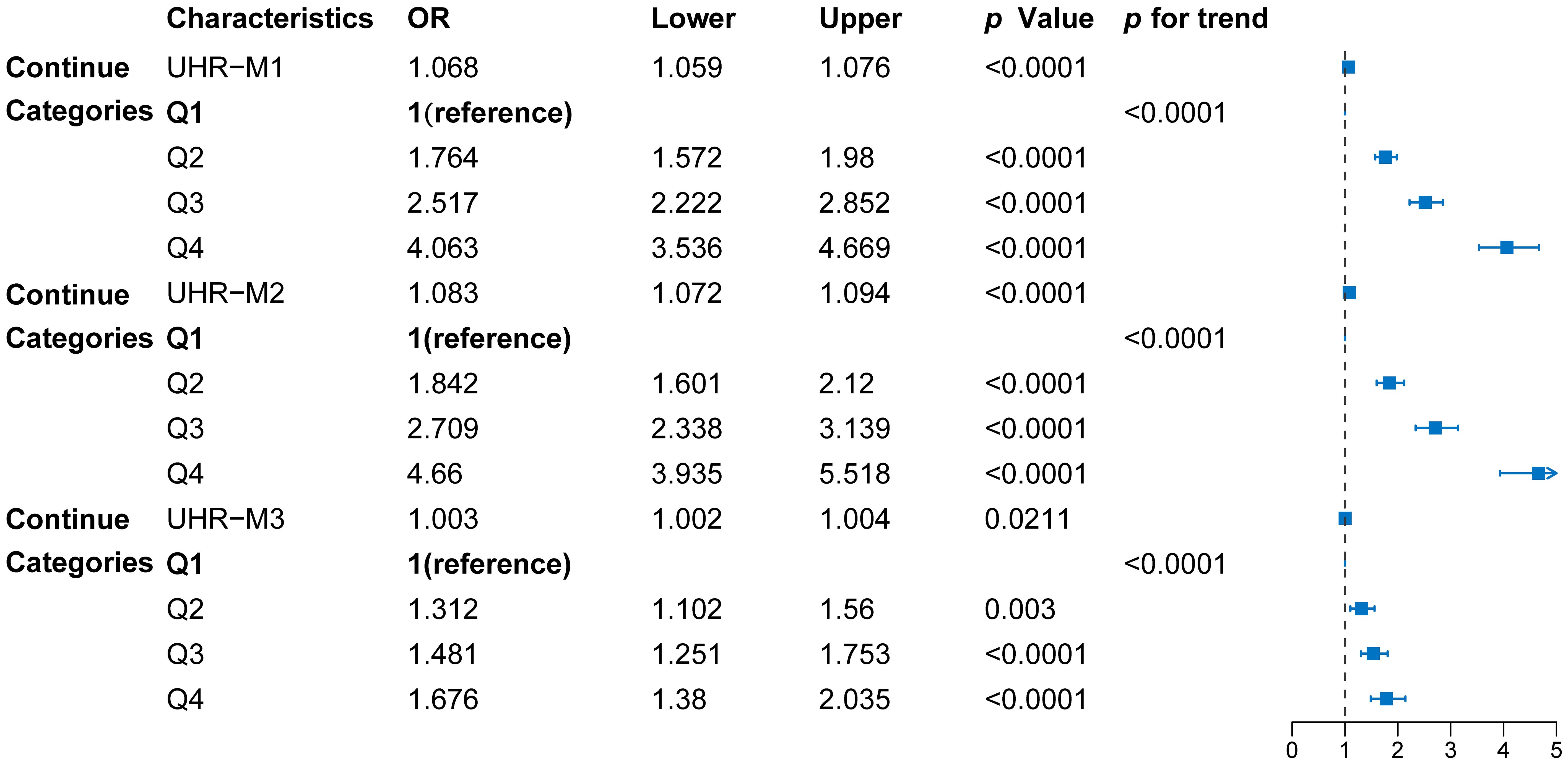
Figure 2. Forest diagram of the association between UHR quartiles and diabetes risk. Model 1: unadjusted; Model 2: adjusted for sex, age, and race; Model 3: adjusted for sex, age, race, BMI, PIR, hypertension, smoking and drinking status, SBP, DBP, TC, TG, LDL-C, and non-HDL-C. Data points represent odds ratios (OR) with 95% confidence intervals (CI), derived from multivariable logistic regression models.
3.3 Subgroup analysis: predictive value of UHR in different populationsTo further investigate the predictive value of UHR for diabetes risk across different populations, we performed subgroup analyses based on factors such as sex, ethnicity, and education level (see Figure 3). The results indicated that the predictive value of UHR was approximately 11% higher in females than in males, with OR values of 1.14 and 1.03, respectively, and the interaction effect was significant (p<0.001). In the racial subgroup analysis, the predictive effect of UHR was slightly higher in non-Hispanic whites compared to other racial groups. Moreover, the predictive value of UHR was enhanced among participants with higher education levels. However, UHR did not exhibit a significant predictive effect in subgroups stratified by PIR, hypertension, smoking and drinking status.
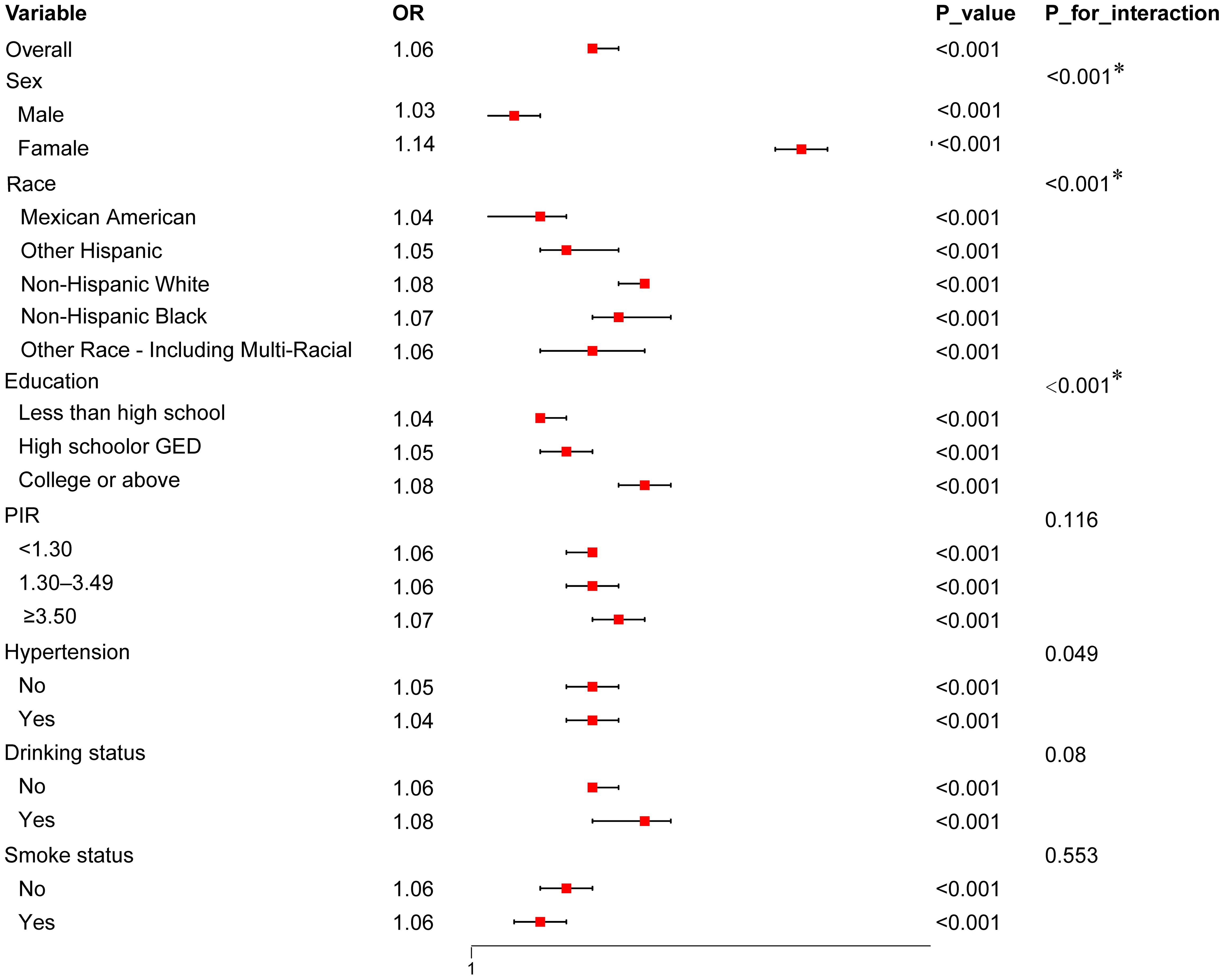
Figure 3. Forest Plot of Subgroup Analysis for the association between UHR and diabetes risk. The plot presents OR with 95% CI across various subgroups, including sex, race, education level, PIR, hypertension status, drinking status, and smoking status. Interaction p-values (P_for_interaction) indicate whether there is a statistically significant difference in the association across subgroups. Only values with *p < 0.00714 (adjusted for multiple comparisons using Bonferroni correction) are considered statistically significant.
3.4 Variable selection via LASSO regressionTo build a more concise and efficient predictive model, we applied LASSO regression to select the variables included (Figure 4). The optimal lambda value was determined via cross-validation (LogLambda_1se = -4.204, Figure 4A), leading to the selection of key variables such as UHR, BMI, age, sex, and education level (Figure 4B). LASSO regression aids in simplifying the model and preventing overfitting, further validating the independent role of UHR as a predictive factor for diabetes risk.
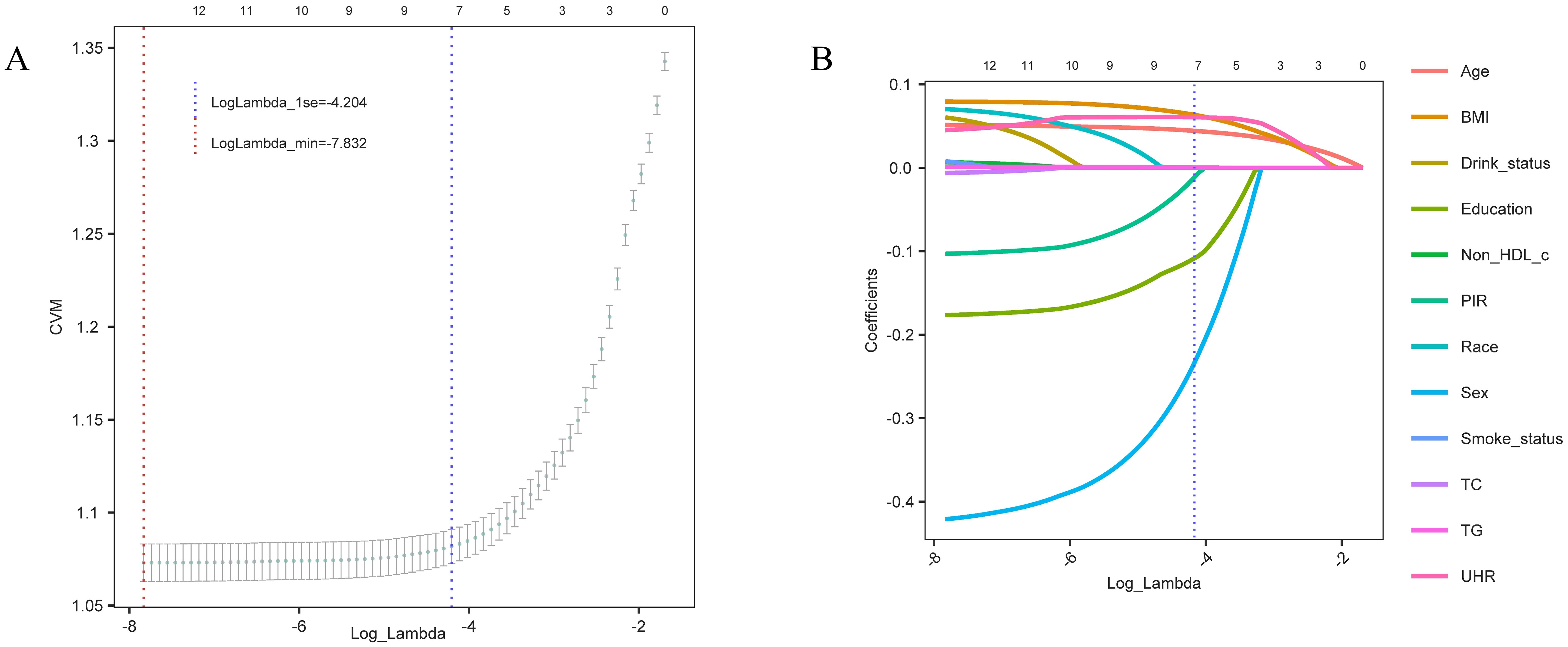
Figure 4. Variable selection trajectory of the LASSO regression model. (A) Cross-validation error (CVM) plot for different Log_Lambda values, with the red dashed line indicating the minimum error (LogLambda_min) and the blue dashed line showing the one-standard-error threshold (LogLambda_1se) for model selection. (B) Coefficient trajectories for each variable as Log_Lambda varies. The blue dashed line represents the selected Log_Lambda (LogLambda_1se), indicating the key predictive variables retained in the final model.
3.5 Multivariate logistic regression models and model evaluationUsing the variables selected via LASSO regression, we constructed multivariate logistic regression models and assessed their predictive capabilities through ROC curves, DCA, and calibration curves. The results indicated that the model including UHR (M1) had a high AUC value (AUC=0.797), suggesting that UHR alone demonstrated good predictive ability for diabetes risk (Figure 5A). The LASSO-selected model (M4) had an AUC of 0.789; although slightly lower than M1, the model exhibited better stability and overall predictive performance. Particularly in the DCA, M4 demonstrated higher net benefits (Figure 5B), and the calibration curve showed good concordance between predicted results and actual observations (Figure 5C). Additionally, the Hosmer-Lemeshow test results showed that the p-values for all models were greater than 0.05, indicating good model fit with no significant differences between predicted and observed values.
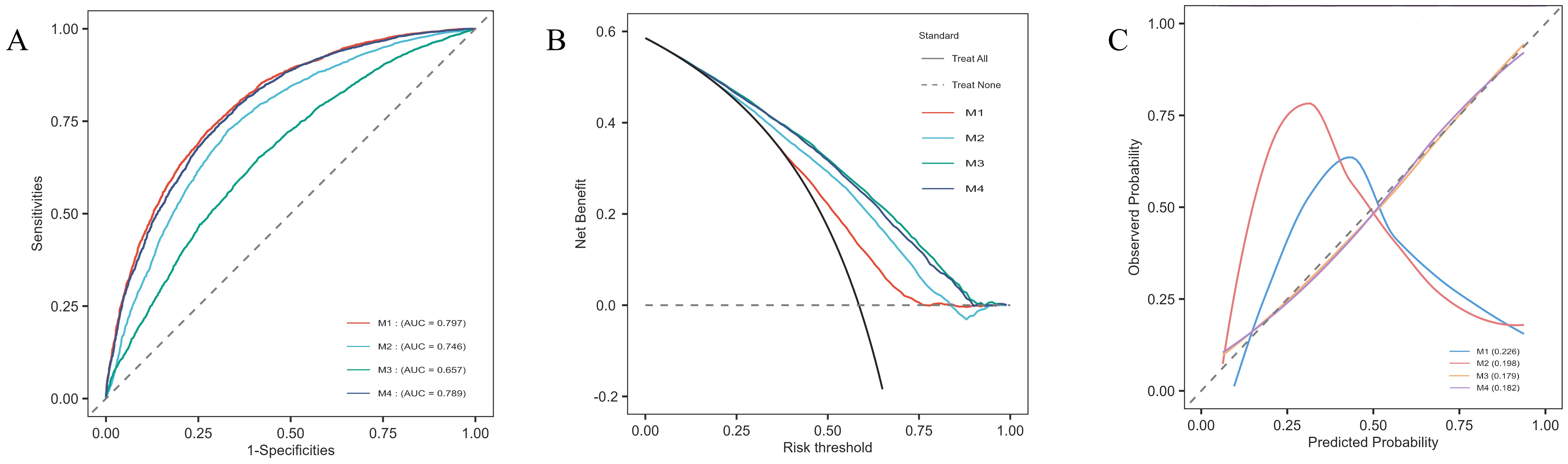
Figure 5. Model evaluation plots for the multivariate logistic regression models. (A) ROC curves for each model, showing the sensitivity and specificity of UHR in predicting diabetes risk, with corresponding AUC values: M1 (0.797), M2 (0.746), M3 (0.657), and M4 (0.789). (B) DCA displaying net benefit across different risk thresholds, comparing the four models. (C) Calibration curves illustrating the agreement between predicted and observed probabilities for each model, demonstrating the calibration accuracy.
Additionally, the nonlinear association between UHR and diabetes risk was confirmed across different models (Figure 6). In the M1 model containing only UHR (Figure 6A), diabetes risk increased progressively as UHR increased. Threshold analysis revealed an inflection point at 10.19 in the model, indicating that when UHR reaches 10.19, although the OR value is still less than 1, the rate of risk increase begins to accelerate; when UHR exceeds 18, the OR value surpasses 1, and the diabetes risk increases significantly. Even after adjusting for age, sex, ethnicity (M2, Figure 6B), and further including metabolic indicators like BMI, TC, TG, LDL-C, Non-HDL-C, and PIR (M3, Figure 6C), the nonlinear association between UHR and diabetes remained significant, with inflection points at 12.27 and 12.29, respectively. In the M4 model, incorporating variables selected via LASSO, the nonlinear association of UHR persisted with an inflection point at 10.00 (Figure 6D), further confirming UHR’s role as an independent predictive marker. The existence of the inflection point suggests that when UHR exceeds 10.00, the rate of risk increase accelerates; when UHR surpasses 18, the risk increases markedly. This offers explicit reference points for clinical intervention.
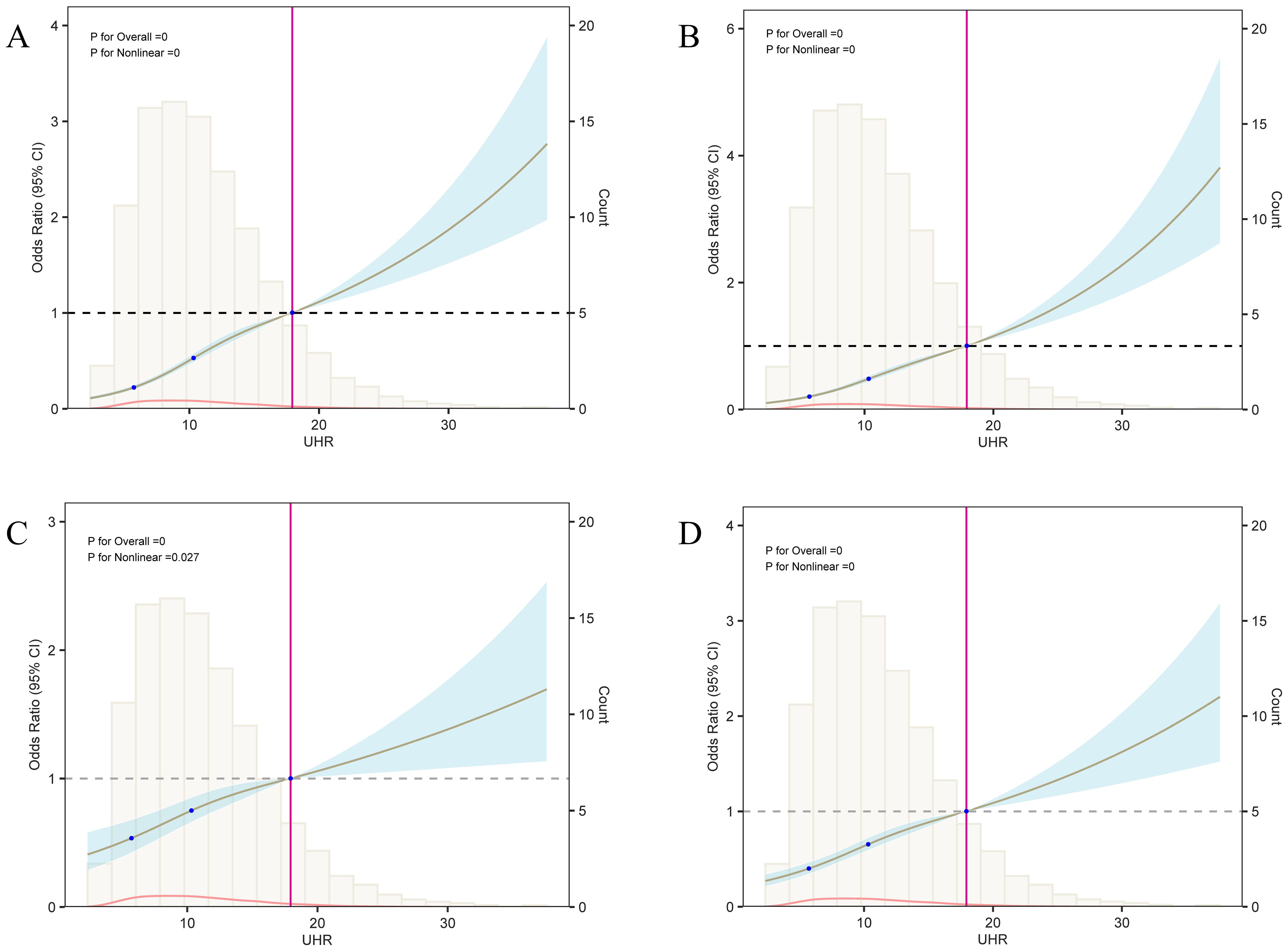
Figure 6. Analysis of the nonlinear relationship between UHR and diabetes risk. This figure presents the results of the restricted cubic spline (RCS) analysis between UHR and diabetes risk; panels (A–D) correspond to the RCS curves of models 1 through 4, respectively. Each model’s three knot positions are located at 5.67, 10.37, and 18. When UHR values exceed 18, the odds ratio (OR) surpasses 1, suggesting a significant increase in diabetes risk. Threshold analysis revealed that the UHR inflection points for models 1 to 4 are 10.19, 12.27, 12.29, and 10.00, respectively, indicating that after these inflection points, the effect of UHR on diabetes risk progressively strengthens.
Finally, a nomogram based on multivariate logistic regression was developed to provide a practical tool for individualized diabetes risk assessment (Figure 7). This model combines UHR, age, BMI, sex, and education level, assisting in providing quantitative references for personalized diabetes risk prediction.
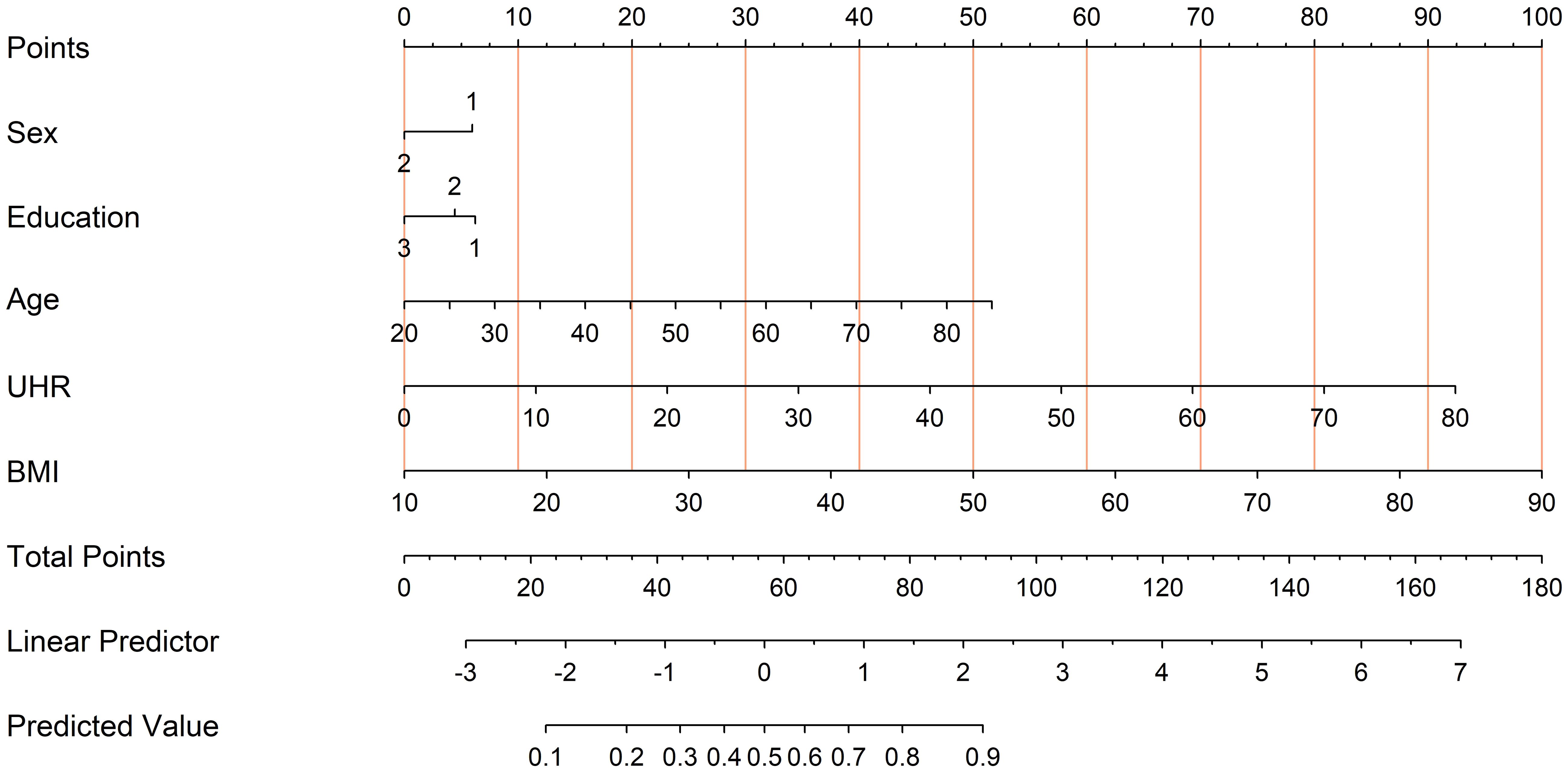
Figure 7. Nomogram derived from the multivariate logistic regression model for diabetes risk prediction. To use the nomogram, locate each predictor’s value (Sex, Education, Age, UHR, and BMI) on its respective axis and draw a line up to the “Points” scale to assign points. Sum all points and find the total on the “Total Points” line. This total corresponds to the predicted probability of diabetes at the bottom of the nomogram.
4 DiscussionWhile a few studies have preliminarily explored the relationship between UHR and diabetes (15, 16), comprehensive studies in large-scale populations remain relatively scarce. By analyzing the NHANES 2005-2018 database, this study included 30,813 participants to assess the independence of UHR as a risk predictor for diabetes. We initially performed univariate, multivariate, and subgroup analyses, followed by constructing multivariate logistic regression models. The models’ predictive capabilities were assessed through ROC curves, DCA, and calibration curves. These methods revealed a significant nonlinear relationship between UHR and diabetes risk. Even after accounting for various confounding factors, UHR remained an independent risk indicator for diabetes. The results suggest that UHR may hold potential value for early diabetes risk assessment.
This study found that UHR levels were significantly higher in the diabetes group than in the non-diabetes group, and diabetes prevalence increased markedly with rising UHR levels. Further logistic regression analysis showed that in the unadjusted Model 1, each unit increase in UHR was associated with a 6.8% increase in diabetes risk; individuals in the highest quartile had four times the risk of diabetes compared to those in the lowest quartile. This association remained significant in the adjusted Model 2 and the fully adjusted Model 3, confirming the independence of UHR as a predictor of diabetes risk. These findings align with previous studies, which have demonstrated a close association between UHR and diabetes as well as related metabolic diseases (20, 21). This association may stem from the components of UHR—UA and HDL-C. As the end product of purine metabolism, UA has been shown to be closely related to insulin resistance, oxidative stress, and inflammation (24, 25); elevated UA levels can promote oxidative stress and inflammatory responses, increasing the risk of insulin resistance (26, 27). In contrast, HDL-C exerts anti-inflammatory and antioxidant effects, and its decrease often signifies worsening metabolic dysfunction, which in turn raises the risk of diabetes (28). Therefore, UHR as a composite indicator may reflect the cumulative effects of multiple metabolic abnormalities and serve as an important marker for diabetes and other metabolic diseases.
Additionally, studies have shown that when UHR surpasses a specific threshold, it exhibits significantly higher sensitivity and specificity in prediabetes screening (16). In this study, restricted cubic spline (RCS) analysis demonstrated a significant nonlinear relationship between UHR and diabetes risk, with an approximate threshold at UHR = 10. This suggests that once UHR exceeds this level, the risk of diabetes rises sharply. Such a threshold effect may indicate multiple pathological mechanisms triggered by elevated UHR, including increased oxidative stress, endothelial dysfunction, and systemic inflammation. For instance, excessively high uric acid levels can impair vascular function through oxidative stress and inflammatory responses, while reduced HDL-C levels diminish antioxidant and anti-inflammatory defenses, further exacerbating insulin resistance (29). Similar nonlinear effects have been observed in other metabolic-related diseases, where biomarkers such as waist circumference or blood pressure, once beyond certain thresholds, lead to a marked increase in the risk of metabolic disorders and cardiovascular events, particularly in high-risk individuals (30, 31). Future research should explore the mechanisms underlying the threshold effect of UHR and validate these findings with prospective data to better identify high-risk populations in clinical settings.
This study also evaluated the predictive performance of UHR for diabetes through ROC curves and DCA, showing that UHR has strong predictive ability for diabetes and further confirming its independence as a risk predictor. A nomogram constructed with covariates selected via LASSO regression, incorporating UHR alongside other non-invasive factors (such as sex, age, and BMI), further enhanced its utility in diabetes risk prediction. Compared to single metabolic markers, UHR, as a composite indicator, offers a more comprehensive reflection of complex metabolic disturbances, giving it a unique advantage in risk prediction (32). Previous studies have shown that UHR provides additional metabolic insights beyond traditional diabetes predictors, especially in individuals with multiple metabolic abnormalities (33). Moreover, UHR’s effectiveness has been validated in metabolic diseases like NAFLD and MAFLD, highlighting its potential as a non-invasive screening tool (19, 34). The nomogram developed in this study may serve as a reference for diabetes risk screening in clinical settings and support future efforts to optimize UHR’s predictive performance through multivariable models.
Additionally, subgroup analysis showed that the association between UHR and diabetes risk was significant and consistent across all subgroups, but with stronger predictive effects observed among females, non-Hispanic whites, and individuals with higher education levels. This variation may be related to the metabolic characteristics, lifestyle, or socioeconomic status of each subgroup. For instance, female hormones like estrogen have anti-inflammatory effects and regulate lipid metabolism, which may influence uric acid and HDL-C levels, making UHR a more sensitive predictor of diabetes risk in women (35, 36). Interestingly, a study found that UHR exhibited a stronger predictive value for metabolic syndrome among men than women in non-diabetic populations (17). This suggests that gender differences may impact UHR’s predictive efficacy in various diseases, though systematic studies exploring these differences in diabetic populations remain limited; future research could investigate the underlying reasons for such gender-specific effects. Additionally, differences in lifestyle and genetic factors among non-Hispanic whites may contribute to a more pronounced association between UHR and diabetes risk in this group. Some studies have indicated that non-Hispanic whites exhibit distinct genetic susceptibility to metabolic disorders compared to other ethnicities (37). However, due to the internal diversity within Hispanic populations, with varying health outcomes among subgroups, further validation is needed to confirm UHR’s predictive role for diabetes in non-Hispanic whites. Among individuals with higher education levels, generally healthier lifestyles tend to lower overall health risks, contributing to more stable metabolic indicators (38). However, our findings suggest that elevated UHR in higher-educated groups may serve as a more sensitive indicator of underlying diabetes risk, although whether this sensitivity holds across other educational levels requires further investigation.
Although our subgroup analysis showed that UHR did not exhibit significant predictive effects in groups based on PIR, hypertension, smoking, and drinking status, previous studies suggest that UHR may still hold predictive value within these populations. For instance, one study found a positive correlation between serum UHR levels and hypertension among women of reproductive age, suggesting that UHR could be a potential clinical marker for hypertension (39). Thus, our findings do not rule out the potential of UHR as a predictive marker in hypertensive or other specific populations. Furthermore, PIR primarily reflects socioeconomic status, while smoking and drinking behaviors reflect lifestyle habits, which can vary considerably across different social groups or disease states and may influence the predictive performance of UHR. It should also be noted that these variables were collected through self-reported questionnaires, which may introduce recall bias and affect the results. Overall, UHR’s role may vary in complexity and significance across different populations, warranting further exploration. Future research should aim to investigate UHR’s potential as a metabolic or disease risk predictor in broader populations and under more precise classification standards.
This study utilized large-scale, nationally representative data from the NHANES 2005-2018, which enhances the generalizability of the findings. Through multivariate analysis, subgroup analysis, and multivariate logistic regression models, we effectively controlled for several confounding factors. Non-invasive variables such as sex, age, BMI, and education level were selected using LASSO regression, further improving UHR’s predictive ability for diabetes risk. Subsequently, we evaluated the model’s predictive performance using ROC curves, DCA, and calibration curves, and ultimately visualized UHR’s potential clinical utility in predicting diabetes risk through a nomogram. However, this study also has several limitations. First, as this study is based on cross-sectional NHANES data, we cannot establish a causal relationship between UHR and diabetes risk, and there is a lack of long-term follow-up data to evaluate the long-term predictive effects of UHR. Future research should employ longitudinal cohort studies, such as the approach used by Cai et al., using Cox regression and survival analysis to further verify the role and stability of UHR in predicting long-term diabetes risk (40, 41). Second, due to the significant missing data for variables such as physical activity and dietary patterns in the NHANES 2005-2018 cycles, these factors were not included in the analysis. Future studies should consider shortening the study period, selecting more complete datasets, or adopting effective data imputation methods to more comprehensively assess the impact of these variables on the relationship between UHR and diabetes. Finally, while this study explored the impact of UHR across different populations through subgroup analysis, future research should delve deeper into gender differences and other subgroup mechanisms, and combine mediation analysis to clarify the potential mechanisms through which UHR influences diabetes risk. Additionally, in vitro and in vivo studies could further validate the biological mechanisms underlying UHR’s predictive role, exploring its effects on metabolic and inflammatory pathways to provide stronger foundational evidence for clinical applications.
5 ConclusionThis study suggests that UHR may be an independent predictor of diabetes risk, with the risk of diabetes increasing significantly as UHR levels rise. Multivariate regression, ROC curve, and nonlinear analyses all demonstrated that UHR remains a significant predictor of diabetes risk even after adjusting for various confounding factors. Subgroup analysis revealed differences in UHR’s predictive effect across different populations, with a particularly stronger effect observed in females. Given that UHR is a simple and readily accessible biomarker, its potential application in early diabetes screening warrants further validation and investigation.
Data availability statementPublicly available datasets were analyzed in this study. This data can be found here: https://wwwn.cdc.gov/nchs/nhanes/Default.aspx.
Ethics statementThe studies involving humans were approved by National Center for Health Statistics. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributionsJY: Formal analysis, Methodology, Visualization, Writing – original draft, Writing – review & editing. CZ: Formal analysis, Methodology, Validation, Visualization, Writing – original draft, Writing – review & editing. XL: Investigation, Visualization, Writing – review & editing. CH: Data curation, Visualization, Writing – review & editing. ZH: Data curation, Investigation, Writing – original draft. SL: Data curation, Formal analysis, Supervision, Validation, Writing – review & editing. YQ: Funding acquisition, Methodology, Writing – review & editing.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by the Zhejiang Provincial Natural Science Foundation of China (Grant No. LQ24H270013), the Zhejiang Province Traditional Chinese Medicine Science and Technology Plan Project (No. 2024ZR102), the School-level Scientific Research Fund Talent Project of Zhejiang Chinese Medical University (No. 2022RCZXZK17), and the horizontal (enterprise-related) project of Zhejiang Chinese Medical University (number 2020-ht-837).
AcknowledgmentsWe appreciate the NHANES databases for offering their platform and supplying valuable datasets.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
AbbreviationsOR, Odds Ratio; CI, Confidence interval; NHANES, National Health and Nutrition Examination Survey; DM, Diabetes mellitus; PIR, Poverty Income Ratio; BMI, Body mass index; BP, Blood pressure; DBP, Diastolic Blood Pressure; SBP, Systolic Blood Pressure; TG, Triglyceride; TC, Total Cholesterol; HDL-C, High-density lipoprotein; Non-HDL-C, Non-high-density lipoprotein cholesterol; LDL-C, Low-density lipoprotein cholesterol; HbA1c, Glycohemoglobin; INS, Insulin; RPG, Random plasma glucose; FPG, Fasting plasma glucose; OGTT, Oral glucose tolerance test; UA, Uric acid; UHR, Uric Acid to High-Density Lipoprotein Cholesterol Ratio.
References1. Sun H, Saeedi P, Karuranga S, Pinkepank M, Ogurtsova K, Duncan BB, et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res Clin Pract. (2022) 183:109119. doi: 10.1016/j.diabres.2021.109119
PubMed Abstract | Crossref Full Text | Google Scholar
3. Bommer C, Sagalova V, Heesemann E, Manne-Goehler J, Atun R, Rnighausen T BA, et al. Global economic burden of diabetes in adults: projections from 2015 to 2030. Diabetes Care. (2018) 41:963–70. doi: 10.2337/dc17-1962
PubMed Abstract | Crossref Full Text | Google Scholar
4. Wu Y, Ding Y, Tanaka Y, Zhang W. Risk factors contributing to type 2 diabetes and recent advances in the treatment and prevention. Int J Med Sci. (2014) 11:1185. doi: 10.7150/ijms.10001
PubMed Abstract | Crossref Full Text | Google Scholar
5. Du L, Zong Y, Li H, Wang Q, Xie L, Yang B, et al. Hyperuricemia and its related diseases: mechanisms and advances in therapy. Signal Transduct Target Ther. (2024) 9:212. doi: 10.1038/s41392-024-01916-y
PubMed Abstract | Crossref Full Text | Google Scholar
6. Yuge H, Okada H, Hamaguchi M, Kurogi K, Murata H, Ito M, et al. Triglycerides/HDL cholesterol ratio and type 2 diabetes incidence: Panasonic Cohort Study 10. Cardiovasc Diabetol. (2023) 22:308. doi: 10.1186/s12933-023-02046-5
PubMed Abstract | Crossref Full Text | Google Scholar
7. Holvoet P, Kritchevsky SB, Tracy RP, Mertens A, Rubin SM, Butler J, et al. The metabolic syndrome, circulating oxidized LDL, and risk of myocardial infarction in well-functioning elderly people in the health, aging, and body composition cohort. Diabetes. (2004) 53:1068–73. doi: 10.2337/diabetes.53.4.1068
PubMed Abstract | Crossref Full Text | Google Scholar
8. Ortiz-Mart I Nez M, Gonz A Lez-Gonz A Lez M, Martagon AJ, Hlavinka V, Willson RC, Rito-Palomares M. Recent developments in biomarkers for diagnosis and screening of type 2 diabetes mellitus. Curr Diabetes Rep. (2022) 22:95–115. doi: 10.1007/s11892-022-01453-4
PubMed Abstract | Crossref Full Text | Google Scholar
9. Morze J, Wittenbecher C, Schwingshackl L, Danielewicz A, Rynkiewicz A, Hu FB, et al. Metabolomics and type 2 diabetes risk: an updated systematic review and meta-analysis of prospective cohort studies. Diabetes Care. (2022) 45:1013–24. doi: 10.2337/dc21-1705
PubMed Abstract | Crossref Full Text | Google Scholar
10. Wang J, Qin T, Chen J, Li Y, Wang L, Huang H, et al. Hyperuricemia and risk of incident hypertension: a systematic review and meta-analysis of observational studies. PloS One. (2014) 9:e114259. doi: 10.1371/journal.pone.0114259
PubMed Abstract | Crossref Full Text | Google Scholar
11. Yu W, Cheng J. Uric acid and cardiovascular disease: an update from molecular mechanism to clinical perspective. Front Pharmacol. (2020) 11:582680. doi: 10.3389/fphar.2020.582680
PubMed Abstract | Crossref Full Text | Google Scholar
14. Kurtkulagi O, Tel BCCI, Kahveci G, Bilgin S, Duman TT, Ert U Rk A, et al. Hashimoto’s thyroiditis is associated with elevated serum uric acid to high density lipoprotein-cholesterol ratio. Rom J Intern Med. (2021) 59:403–08. doi: 10.2478/rjim-2021-0023
PubMed Abstract | Crossref Full Text | Google Scholar
15. Aktas G, Kocak MZ, Bilgin S, Atak BM, Duman TT, Kurtkulagi O. Uric acid to HDL cholesterol ratio is a strong predictor of diabetic control in men with type 2 diabetes mellitus. Aging Male. (2020) 23:1098–102. doi: 10.1080/13685538.2019.1678126
留言 (0)