
記住我

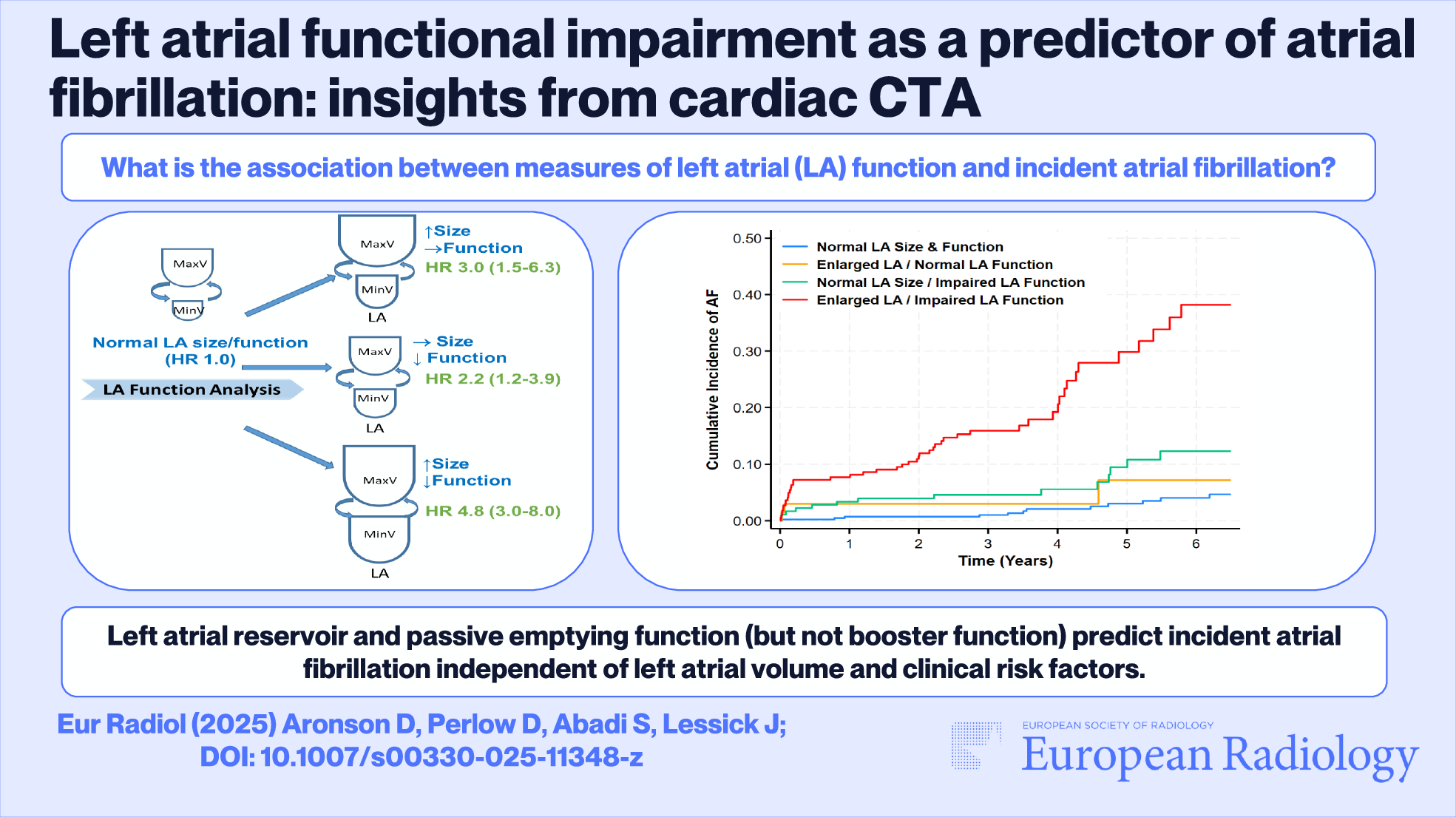

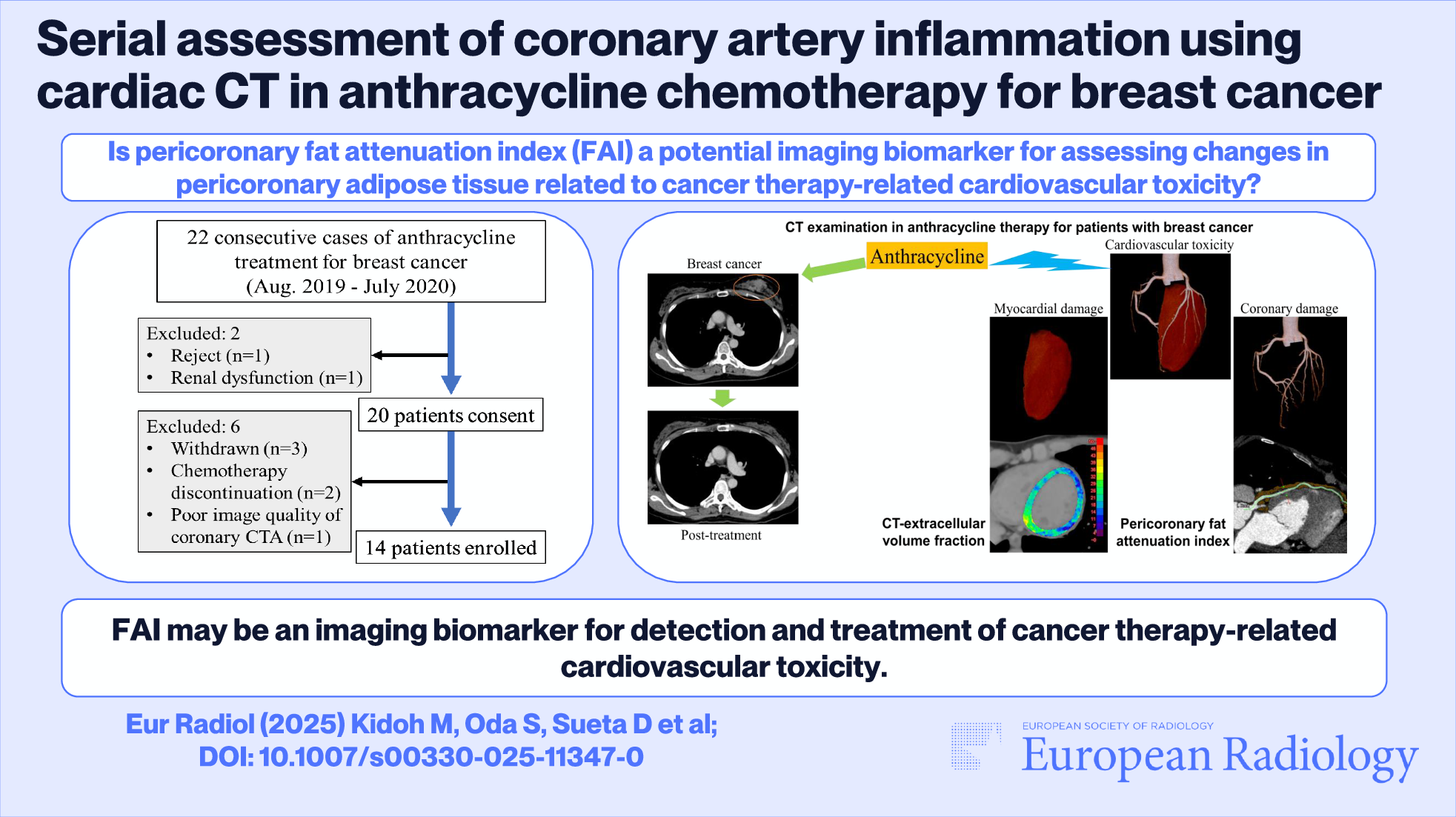
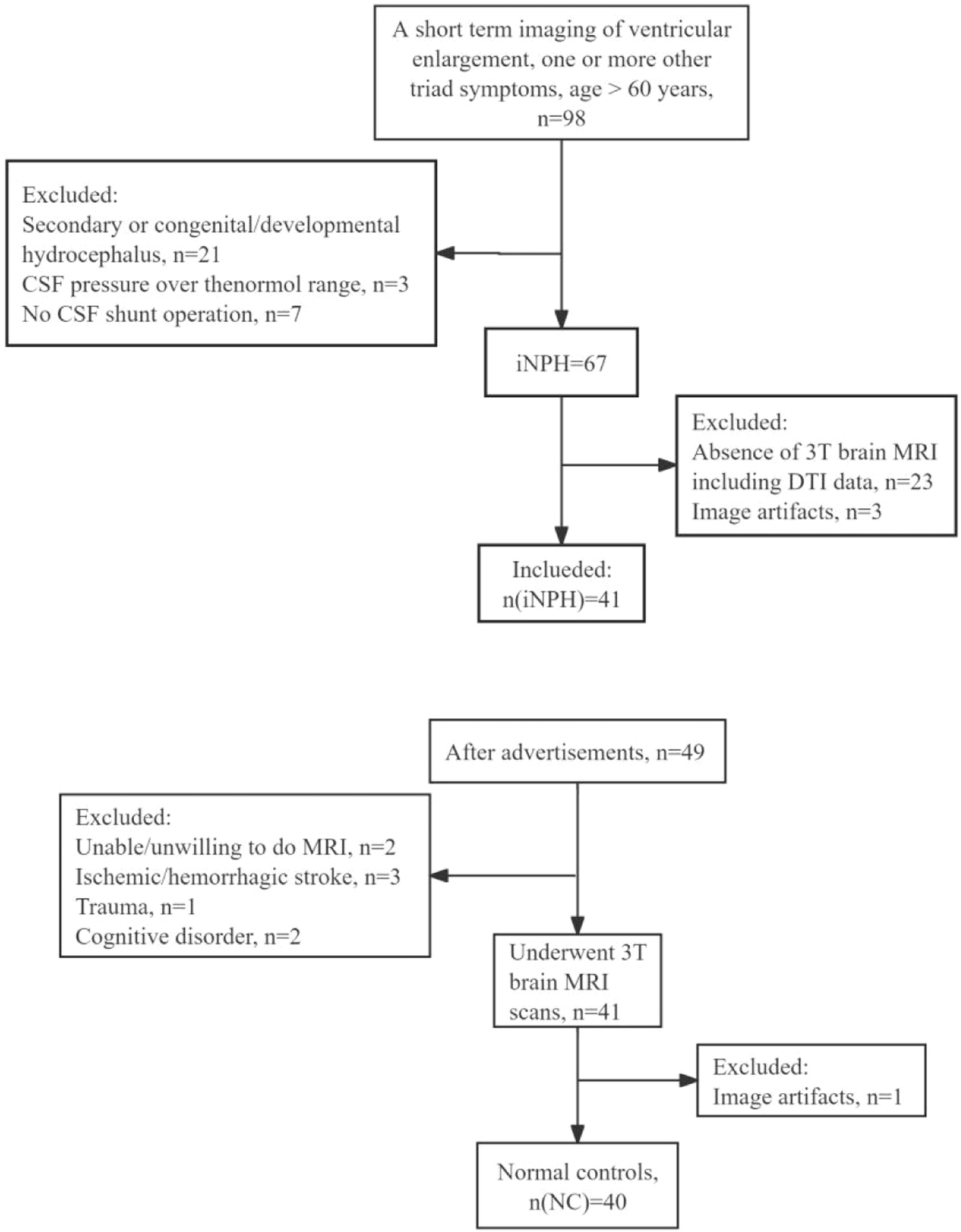

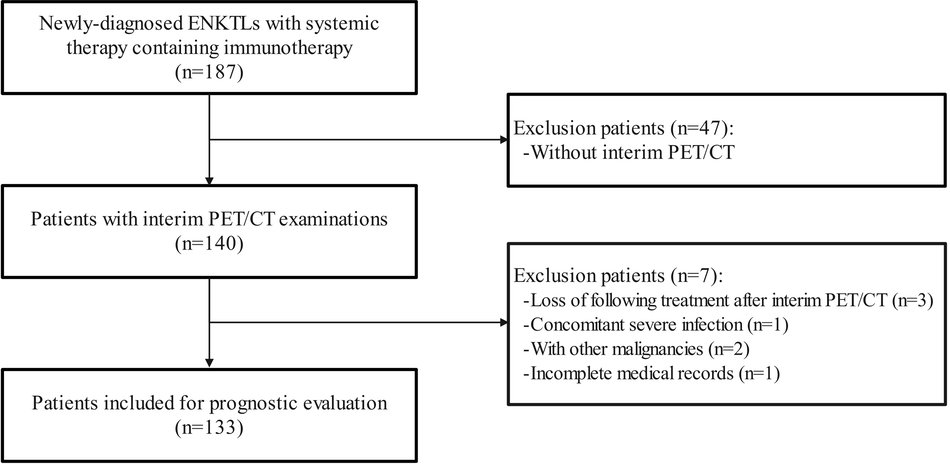
This retrospective study solely used publicly available datasets and did not require institutional review board approval.
Data collectionFor model training, we included several public CXR datasets, collecting a total of 592,580 frontal CXRs (Table 1) [13,14,15,16,17,18,19,20]. The Medical Information Mart for Intensive Care (MIMIC) dataset provides radiologic reports in a free-text form (Dataset 2, n = 217,699), while the other training datasets have multi-class or binary labeling for radiographic abnormalities (Dataset 1, n = 374,881). Some datasets contain information regarding lesions’ location, but this information was not utilized.
Table 1 Countries of collection, years of publication, and numbers of frontal chest radiographs in the publicly available datasets used for model training and evaluationAdapting a multimodal LLM to CXRs (CXR-LLaVA)A model influenced by the LLaVA network was developed [7]. LLaVA, which consists of an LLM and an image encoder, converts images into a sequence of image tokens that are then combined with query text tokens for text generation within the LLM. Our primary objective was to fine-tune LLaVA using CXR–radiologic report pairs.
To achieve optimal performance, we developed a custom image encoder from scratch rather than using pretrained weights. We empirically employed the “ViT-L/16” version of the vision transformer as the image encoder. This encoder begins with a convolutional layer that processes 1-channel grayscale CXR images into 1024-dimensional patches. These patches are passed through a series of 24 residual attention blocks, each containing multi-head attention mechanisms and multilayer perceptrons. The output from these blocks is normalized through normalization layers and eventually projected into a higher-dimensional space suitable for multimodal processing. Following the vision encoder, the multimodal projector linearly transforms the 1024-dimensional image tokens into a 4096-dimensional space. These tokens are then integrated into the language model component. In alignment with LLaVA’s framework, we utilized the Large Language Model Meta AI (LLAMA)-2 as our language model [21]. We selected the version with 7 billion parameters due to cost considerations.
The final CXR-LLaVA takes a CXR image and question prompt as input; the image is transformed into image tokens via an image encoder, and the prompt is converted to text tokens through a tokenizer. Both are then fed into a causal language model, which autoregressively generates text responses to the questions. The trained model is available as open-source (https://github.com/ECOFRI/CXR_LLaVA), and its demo can be found at https://radiologist.app/cxr-llava/. Additionally, a comprehensive model card detailing the model’s intended use cases, out-of-scope use, and limitations is provided on the same website to ensure transparency and facilitate further research.
Training step 1: constructing and training a CXR-specific image encoderDespite the capabilities of pretrained image encoders in understanding common visual objects, they often fall short in accurately describing radiographic findings. In this section, we propose an image encoder, based on ViT-L/16 and a two-step strategy for training them to learn the radiological context specific to CXR images.
In the first step, a simple classification task was used to train the image encoder (Fig. 1a). The image encoder transformed a CXR image into a representation and then classified an abnormality by adding a simply fully connected layer as a classifier. This classification task enabled the model to learn a fundamental yet crucial ability regarding abnormalities. We used 374,881 image-label pairs from Dataset 1 to train and validate our image encoder. We assigned binary labels: when images had labels associated with pathology, they were labeled as “abnormal,” while those marked as “no finding” were designated “normal.” The detailed implementation and settings are described in the Supplementary material.
Fig. 1
CXR-LLaVA training process. a Initially, the image encoder was trained on a basic classification task to differentiate between normal and abnormal CXRs, thereby acquiring fundamental representations of CXRs. b Subsequently, the model underwent training with pairs of CXRs and their corresponding pathological findings. This training employed the contrastive language-image pre-training (CLIP) strategy to foster shared representations between images and text. c The image encoder was then assimilated into CXR-LLaVA, initiating the alignment of image representations with the large language model (LLM). In this phase, training focused on pairs of CXR images and radiologic reports, with updates confined to the projection layer. d Upon successful alignment of the image encoder with the LLM, an instruction fine-tuning process was undertaken. This involved a variety of radiologic reports and question-answer pairs, aiming to refine the model’s capability to interpret CXRs and facilitate more informative interactions. Please note that the figure abstracts from the detailed neural network information, omitting elements such as tokenizer, batch normalization, projection, and linear classification layers
In the second step, the image encoder was further trained based on the CLIP strategy to learn complex representations of radiological terms (Fig. 1b) [5]. Using the CLIP strategy, the image encoder learned shared representations between image and text by mapping corresponding image and text pairs closer together and non-corresponding pairs further apart. For instance, an image showing signs of “pleural effusion” would have its corresponding text label vector “pleural effusion” mapped closely to its image vector. This ensures that the model can accurately associate the visual features of pleural effusion in CXRs with the correct textual description, thereby enhancing its ability to correctly identify and describe pleural effusion in new, unseen images. We chose pathological labels provided in the dataset, such as “atelectasis,” “pneumonia,” “pleural effusion” and so on. For images with multiple pathological labels, we connected them using commas. The 592,580 image-text pairs from Datasets 1 and 2 were used in the training and validating process. The performance of the trained image encoder was evaluated and compared with the final model; the detailed process and the performance evaluation are described in the Supplementary material.
Training step 2: feature alignment and end-to-end fine-tuning of CXR-LLaVABefore fine-tuning the CXR-LLaVA model, the features from the image encoder, as described in step 1, and language model (i.e., LLaMa-2) were aligned through additional training, where the image encoder and language model weights were frozen, updating only the projection matrix. The aligned image representation was computed by updating the projection matrix using CXR images with refined radiologic reports from Dataset 2 (Fig. 1c).
After aligning the image features, CXR-LLaVA underwent an instruction-tuning process, which was critical for refining the model’s interpretative capabilities (Fig. 1d). This process involved using refined radiology reports and multi-turn question-answer dialogs generated by GPT-4, all based on Dataset 2 (Supplementary materials).
Internal and external test set compositionFor internal model testing, we utilized a randomly selected MIMIC dataset comprising 3000 images and accompanying free-text radiologic reports [19]. These were not used during the model’s training and validation phases. Additionally, we employed the CheXpert test dataset, which consists of 518 images, each binary labeled for 14 findings: atelectasis, cardiomegaly, consolidation, edema, enlarged cardiomediastinum, fracture, lung lesion, lung opacity, no finding, pleural effusion, pleural other, pneumonia, pneumothorax, and support devices [14]. For external model testing, we used a dataset from Indiana University, consisting of 3689 pairs of images and free-text radiologic reports [20].
Comparison with other multimodal LLMsTo evaluate the performance of our model, we compared its results with those of other publicly available multimodal LLMs, including OpenAI’s GPT-4-vision and Google’s Gemini-Pro-Vision. Despite being in a preview state and not being fine-tuned for CXR report generation, these general-purpose models have shown some potential. For instance, GPT-4-vision has demonstrated a limited ability to detect abnormalities in CXRs and the capacity to solve the United States Medical Licensing Examination tests [22, 23]. However, LLaVA-MED, a model fine-tuned for medical image analysis, failed to generate accurate radiologic reports from CXRs, producing nearly identical reports for diverse CXRs, and was therefore excluded from our study. Other models, such as ELIXR and Med-PALM, which claim the ability to interpret CXRs, were not publicly available and thus were not included in this analysis [8, 24] (Supplementary materials).
Internal test set evaluationTo evaluate the performance of radiologic report generation in the MIMIC internal test set, we utilized CheXpert-Labeler to generate pathological labels [14]. This tool analyzes free-text radiologic reports and generates labels such as positive, negative, or uncertain for each pathological finding (atelectasis, cardiomegaly, consolidation, edema, enlarged cardiomediastinum, fracture, lung lesion, lung opacity, no finding, pleural effusion, pleural other, pneumonia, pneumothorax, and support devices). We compared these labels from the model-generated reports with those from the original ground truth reports (Fig. 2a).
Fig. 2
Model evaluation flow diagram. a Evaluation of datasets with ground-truth free-text radiologic reports, including the MIMIC internal test set and the Indiana external test set. Pathologic labels were obtained using the CheXpert-Labeler from both the original reports and the model-generated reports, with a subsequent comparison of these results. b Evaluation of datasets with established ground-truth pathologic labels, specifically the CheXpert internal test set, involved directly generating pathologic labels from the model using a label generation prompt
For the CheXpert test set, which does not contain ground-truth radiologic reports, we instructed the model to generate binary labels for the same 14 findings. These labels were then compared with the ground truth. This dataset is identical to that used in a previous study where the CheXzero model exhibited expert-level pathology detection capabilities [25]. Therefore, we evaluated our model’s performance against both CheXzero and the average diagnostic performance of three board-certified radiologists, as documented in the same publication (Fig. 2b).
External test set evaluation and human radiologist evaluationTo evaluate the model’s performance on the Indiana external test set, we employed the same methodology used for the MIMIC internal test set, which involved comparing the labels generated from the model’s reports with the ground truth (Fig. 2a).
To assess the model’s capability for autonomous or semi-autonomous reporting without human radiologist intervention, an evaluation was conducted involving three human radiologists. From the Indiana external test set, 25 abnormal images and 25 normal images were randomly selected. A total of 50 images were used to create 100 report-image pairs, with each image paired with a model-generated report and a ground truth report. The radiologists were presented with these 100 report-image pairs in a random order for evaluation. They rated the acceptability of each report on a 4-point scale: (1) totally acceptable without any revision, (2) acceptable with minor revision, (3) acceptable with major revision, and (4) unacceptable (Supplementary materials).
Statistical analysisThe model’s performance in generating radiologic reports was assessed using accuracy, sensitivity, specificity, and F1 scores. Cases where the CheXpert-Labeler assigned an “uncertain” label or where the label was not mentioned (missing element) were excluded from our analysis. We included only definite positive or negative labels. Additionally, due to the scarce number of images with labels such as “pleural other” and “fractures,” these were omitted from the analysis. The specific criteria for removing certain labels and the details of the excluded labels are outlined in the accompanying table. To estimate the confidence intervals of the accuracy, sensitivity, specificity, and F1 scores, we utilized non-parametric bootstrapping with 1000 iterations. For the evaluation conducted by human radiologists, the Cochran Q test was employed to determine the statistical significance of differences between the evaluations made by human radiologists and the model.
留言 (0)